КРАСНОЯРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ ИНСТИТУТ ВЫЧИСЛИТЕЛЬНОГО МОЕДЛИРОВАНИЯ СО РАН Миркес Е.М Учебное пособие по курсу НЕЙРОИНФОРМАТИКА Красноярск 2002
Введение
Рабочая программа по курсу «Нейроинформатика»
НАГРУЗКА
Лекции 32 часа Лабораторные занятия 64 часа Самостоятельная работа 20 часов Всего 116 часовПРОГРАММУ СОСТАВИЛИ:
д.ф.-м.н., профессор А.Н. Горбань,
д.т.н., доцент Е.М. Миркес
к.ф.-м.н., доцент Н.Ю. Сиротинина
ЦЕЛИ И ЗАДАЧИ КУРСА
Цель преподавания дисциплины:
• ознакомить студентов с новой перспективной областью информатики;
• научить студентов квалифицированно использовать аппарат нейронных сетей для решения прикладных задач;
• подготовить студентов к появлению на рынке нейрокомпьютеров.
В результате изучения дисциплины студенты должны:
• знать базовые модели нейронов и нейронных сетей;
• владеть основными парадигмами построения нейронных сетей для решения задач: Сети Кохонена, сетчатки Хопфилда, сети обратного распространения ошибки;
• владеть основными принципами решения прикладных задач распознавания образов, диагностики, управления с помощью нейронных сетей;
• иметь основные представления о структуре мозга и биологических нейронных сетях;
СОДЕРЖАНИЕ КУРСА
Тема 1. Введение. 2 часа
Предмет и задачи курса. Отличия нейрокомпьютеров от компьютеров фон Неймана. Задачи, решаемые в настоящее время с помощью нейронных сетей. Основные направления в нейроинформатике. Очерк истории нейроинформатики.
Тема 2. Сети естественной классификации. 4 часа
Задача естественной классификации. Основные методы решения. Метод динамических ядер и сети Кохонена.
Тема 3. Сети ассоциативной памяти. 6 часов
Сети Хопфилда и их обобщения. Инвариантная обработка изображений (по отношению к переносам, поворотам). Ассоциативная память.
Тема 4. Сети, обучаемые методом обратного распространения ошибки. 16 часов
Идея универсального нейрокомпьютера. Выделение компонентов универсального нейрокомпьютера. Задачник. Методы предобработки. Нейронная сеть (быстрое дифференцирование и метод двойственности). Оценка и интерпретатор ответа. Учитель. Контрастер. Логически прозрачные нейронные сети и получение явных знаний из данных.
Тема 5. Персептрон Розенблатта. 4 часа
Правило Хебба. Персептрон и его обучение. Ограничения и возможности персептрона.
ОСНОВНАЯ ЛИТЕРАТУРА
1. Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. — Новосибирск: Наука. Сибирская издательская фирма РАН, 1996.
2. Миркес Е.М. Нейрокомпьютер. Проект стандарта. Новосибирск: Наука, Сибирская издательская фирма РАН, 1998, 337 С
2. Минский М., Пайперт С. Персептроны. — М.: Мир, 1971. Задания для лабораторных работ
По курсу «Нейроинформатика» студенты выполняют 7 лабораторных работ. Каждая из лабораторных работ преследует свои цели. Все лабораторные выполняются группами по 2–4 человека.
Лабораторная № 1
Цель работы. Целью данной лабораторной работы является демонстрация способности нейронной сети решать неформализованные задачи. Сеть необходимо обучить классификации на два класса по косвенным признакам.
Используемые программы. Лабораторная выполняется на программе clab.
Задание. Данная лабораторная выполняется в несколько этапов.
1. Необходимо выбрать задачу. Примерами таких задач могут служить следующие: «Мужчина/женщина», «Студент/преподаватель», «Студенты живущие дома/в общежитии» и др.
2. Необходимо составить вопросник из 20 косвенных вопросов, по ответам на которые, с точки зрения студента, возможно провести разделение. Список вопросов утверждается преподавателем. Примером косвенного вопроса в задаче «Мужчина/женщина» может служить вопрос «Носите ли Вы дома халат», однако вопросы «Носите ли вы дома юбку» или «Приходится ли Вам по утрам бриться» косвенными считаться не могут.
3. Пронумеровать вопросы по убыванию предполагаемой значимости вопросов для решения задачи.
4. Необходимо проанкетировать не менее 20 человек по составленному вопроснику.
5. На основе анкетирования подготовить файлы Ptn и Pbl в соответствии с требованиями пакета CLAB.
6. Провести пробное обучение. В случае, если нейронная сеть не может обучиться решению задачи проанализировать задачник на предмет непротиворечивости. Если противоречий нет, обратиться к преподавателю.
7. Провести минимизацию задачника.
1.В режиме тестирования предъявить сети все примеры. Расставить «места» значимости всех вопросов в каждом примере (Самый важный — 1, второй по значимости — 2 и т. д.). В следующей таблице приведен пример результатов данного этапа. В таблице рассмотрены результаты только для четырех примеров задачника. При выполнении задания необходимо использовать все примеры.
Пример Вопрос 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 2 1 6 12 10 15 2 7 13 17 3 8 11 16 18 4 20 9 14 5 19 3 17 6 5 8 10 12 3 1 13 15 11 9 7 19 2 4 20 16 18 14 4 8 12 11 3 17 14 6 1 13 16 18 4 7 10 9 2 20 19 15 5 Итого 27 26 31 25 47 34 23 23 42 44 48 36 43 61 30 42 66 67 56 48 Место 14 15 12 16 6 11 17 17 9 7 5 10 9 3 13 8 2 1 4 52. Исключить из задачника (и вопросника) несколько (обычно пять) вопросов, занявших первые места (имеющие наибольшие значения в строке «Итого». В приведенном выше примере следует исключать либо четыре, либо шесть вопросов, поскольку на пятом месте сразу два вопроса — одиннадцатый и двадцатый.
3. Обучить сеть по новому задачнику. Если обучение удалось, то переходим к шагу 7.1. В противном случае возвращаемся к предыдущему задачнику и исключаем меньшее число вопросов. Если не удалось обучить сеть при исключении одного вопроса, то процесс минимизации завершен. Следует отметить, что в силу особенности программной реализации необходимо оставить не менее двух вопросов.
8. Составляется отчет, в который должны входить исходный задачник, таблицы фиксации значимостей, окончательный задачник. В случае, если оставшиеся вопросы по первоначальной классификации являлись не самыми значимыми, желательно включить в отчет анализ причин, по которым они оказались наиболее значимыми. Кроме того, окончательный вариант сети демонстрируется преподавателю.
(обратно)Лабораторная № 2
Цель работы. Освоение работы с сетями Кохонена.
Задание. Необходимо написать программу, имитирующую работу сети Кохонена. Проанализировать задачник, сформированный при выполнении первой лабораторной с помощью написанного имитатора. Сравнить скорость обучения сети при использовании классического алгоритма обучения сетей Кохонена и метода динамических ядер. Построить классификацию на два, три четыре и пять классов. Для каждого класса в каждой классификации определить следующие показатели:
1. Расстояние между классами.
2. Максимальное расстояние от точек класса до ядра класа.
3. Число точек в классе.
4. Число точек каждого из «правильных» классов (например число «мужчин» и «женщин») в каждом классе.
Все результаты отражаются в отчете.
Лабораторная № 3
Цель работы. Сравнить два вида сетей ассоциативной памяти.
Используемые программы. Лабораторная выполняется на программе Hopfield.
Задание.
1. Подобрать пять образов, которые способна запомнить классическая сеть Хопфилда.
2. Определить максимальный уровень шума, при котором сеть продолжает правильно воспроизводить все образы.
3. Определить минимальный радиус контрастирования, при котором сеть может правильно воспроизвести все образы.
4. Определить максимальный уровень шума, при котором отконтрастированная сеть продолжает правильно воспроизводить все образы.
5. Переключить программу в режим работы проекционной сети ассоциативной памяти. И повторить этапы со второго по четвертый.
В отчет включаются все результаты. Кроме того, на основе полученных данных необходимо сформулировать рекомендации по тому, какие виды сетей (из четырех исследованных) предпочтительнее использовать.
Рекомендуется сохранить обучающее множество для использования в следующих лабораторных работах.
Лабораторная № 4
Цель работы. Исследование стратегий обучения нейронных сетей
Используемые программы. Лабораторная выполняется на программе Sigmoid.
Задание. В лабораторной работе требуется обучить нейронную сеть решению задачи распознавания пяти бинарных изображений с использованием четырех различных методов обучения и провести сравнение методов по скорости обучения и надежности работы обученной сети. Основные этапы выполнения работы:
1. Формирование задачника.
2. Установка параметров метода обучения.
3. Обучение нейронной сети.
4. Тестирование обученной нейронной сети (статистический тест).
5. Повторение этапов 2–4 для других методов обучения.
6. Анализ полученных результатов.
Методы обучения:
1. Градиентный с mParTan
2. Градиентный без mParTan
3. Случайный без mParTan
4. Случайный с mParTan
В отчет включаются все полученные результаты (число тактов при обучении сети и результаты статистического теста для всех четырех вариантов стратегии обучения). На основе анализа полученных результатов необходимо сформулировать рекомендации по использованию исследованных стратегий обучения.
Лабораторная № 5
Цель работы. Исследование влияния различных видов функции оценки на обучение нейронных сетей
Используемые программы. Лабораторная выполняется на программе Sigmoid.
Задание. В лабораторной работе требуется обучить нейронную сеть решению задачи распознавания пяти бинарных изображений с использованием различных функций оценки и провести сравнение по скорости обучения и надежности работы обученной сети. Основные этапы выполнения работы те же, что и для лабораторной работы 4.
1. Формирование задачника.
2. Установка параметров оценки.
3. Обучение нейронной сети.
4. Тестирование обученной нейронной сети (статистический тест).
5. Повторение этапов 2–4 для других методов оценки.
6. Анализ полученных результатов.
Исследуемые оценки:
1. Метод наименьших квадратов.
2. Расстояние до множества с уровнем надежности 0,1.
3. Расстояние до множества с уровнем надежности 1,8.
В отчет включаются все полученные результаты (число тактов при обучении сети и результаты статистического теста для всех видов оценки). На основе анализа полученных результатов необходимо сформулировать рекомендации по использованию исследованных оценок.
Лабораторная № 6
Цель работы. Контрастирование нейронных сетей
Используемые программы. Лабораторная выполняется на программе Sigmoid.
Задание. В лабораторной работе требуется провести контрастирование обученной нейронной сети с целью минимизации числа синаптических связей и сравненить надежности функционирования контрастированной и неконтрастированной нейронных сетей. Основные этапы выполнения работы:
1. Формирование задачника.
2. Обучение нейронной сети.
3. Тестирование обученной нейронной сети.
4. Контрастирование обученной нейронной сети.
5. Тестирование контрастированной нейронной сети.
6. Анализ полученных результатов.
Контрастирование нейронной сети проводится до получения минимальной нейронной сети — сети из которой нельзя удалить ни одной связи.
В отчет включаются все полученные результаты (число тактов при обучении сети и результаты статистического теста для всех видов оценки). На основе анализа полученных результатов необходимо сформулировать рекомендации по использованию исследованных оценок.
Лабораторная № 7
Цель работы. Сравнить сети использующие различные виды нейронов.
Используемые программы. Лабораторная выполняется на программах Sigmoid, Pade, Sinus.
Задание. Необходимо обучить нейронные сети, реализованные в программах Sigmoid, Pade и Sinus с максимальным уровнем надежности. Для программы Sigmoid (сигмоидная сеть) максимальным, но недостижимым уровнем надежности является 2. На практике удается обучить сеть с уровнем надежности 1,9–1,98. Для Паде сети (программа Pade) нет ограничения на достижимый уровень надежности, однако в программе установлено ограничение на уровень существенности — 200. В программе Sinus (сеть с синусоидной характеристикой) максимальный уровень надежности 2 является достижимым.
Для каждой сети определяются следующие показатели:
• число тактов обучения;
• результат статистического теста.
Все полученные результаты включаются в отчет. Отчет должен содержать рекомендации по использованию всех видов сетей.
Вопросы к экзамену
1. Основные принципы инженерного направления в нейроинформатике
2. Классическая сеть Хопфилда. Ее свойства и методы расширения возможностей.
3. Проекционная сеть ассоциативной памяти
4. Тензорная сеть ассоциативной памяти
5. Автокорреляторы в обработке изображений. Сети Хопфилда с автокорреляторами.
6. Сети естественной классификации. Метод динамических ядер. Пространственная сеть Кохонена.
7. Бинарные сети. Метод обучения бинарных сетей. Правило Хебба, его достоинства и недостатки.
8. Персептрон Розенблатта. Теорема о достаточности целочисленных коэффициентов.
9. Персептрон Розенблатта. Теорема о достаточности двух слоев.
10. Метод двойственности в обучении нейронных сетей. Основные идеи и ограничения на архитектуру.
11. Метод двойственности в обучении нейронных сетей. Требования к элементам сети. Функционирование синапса, сумматора, нелинейного преобразователя.
12. Метод двойственности в обучении нейронных сетей. Подбор шага, использование методов ускорения обучения нейронных сетей
13. Оценка и интерпретатор ответа
14. Контрастирование нейронных сетей с использованием функции оценки.
15. Контрастирование нейронных сетей. Метод контрастирования сумматоров.
16. Логически прозрачные нейронные сети и метод получения явных знаний из данных.
Лекция 1. Возможности нейронных сетей
Лекция является сокращенной версией лекции А.Н.Горбаня. Полный текст лекции приведен в [59]
Нейробум: поэзия и проза нейронных сетей
В словах «искусственные нейронные сети» слышатся отзвуки фантазий об андроидах и бунте роботов, о машинах, заменяющих и имитирующих человека. Эти фантазии интенсивно поддерживаются многими разработчиками нейросистем: рисуется не очень отдаленное будущее, в котором роботы осваивают различные виды работ, просто наблюдая за человеком, а в более отдаленной перспективе — человеческое сознание и личность перегружаются в искусственную нейронную сеть — появляются шансы на вечную жизнь.
Поэтическая игра воображения вовлекает в работу молодежь, поэзия рекламы создает научную моду и влияет на финансовые вложения. Можете ли Вы четко различить, где кончается бескорыстная творческая игра и начинается реклама? У меня такое однозначное различение не получается: это как вопрос о искренности — можно сомневаться даже в своей собственной искренности.
Итак: игра и мода как важные движущие силы.
В словах «модное научное направление» слышится нечто неоднозначное ‑ то ли пренебрежение, смешанное с завистью, то ли еще что-то. А вообще, мода в науке — это хорошо или плохо? Дадим три ответа на этот вопрос.
1. Мода — это хорошо! Когда в науке появляется новая мода, тысячи исследователей, грустивших над старыми темами, порядком надоевшими еще со времени писания диссертации, со свежим азартом бросаются в дело. Новая мода позволяет им освободиться от личной истории.
Мы все зависим от своего прошлого, от привычных дел и привычных мыслей. Так давайте же приветствовать все, что освобождает нас от этой зависимости! В новой модной области почти нет накопленных преимуществ — все равны. Это хорошо для молодежи.
2. Мода — это плохо! Она противоречит глубине и тщательности научного поиска. Часто «новые» результаты, полученные в погоне за модой, суть всего-навсего хорошо забытые старые, да еще нередко и перевранные. Погоня за модой растлевает, заставляет переписывать старые работы и в новой словесной упаковке выдавать их за свои. Мода ‑ источник сверххалтуры. Примеров тому — тысячи.
«Гений — это терпение мысли». Так давайте же вслед за Ньютоном и другими Великими культивировать в себе это терпение. Не будем поддаваться соблазну моды.
3. Мода в науке — это элемент реальности. Так повелось во второй половине xx века: наука стала массовой и в ней постоянно вспыхивают волны моды. Можно ли относиться к реальности с позиций должного: так, дескать, должно быть, а этак — нет? Наверное, можно, но это уж точно непродуктивно. Волны моды и рекламные кампании стали элементом организации массовой науки и с этим приходится считаться, нравится нам это или нет.
Нейронные сети нынче в моде и поэтическая реклама делает свое дело, привлекает внимание. Но стоит ли следовать за модой? Ресурсы ограничены — особенно у нас, особенно теперь. Все равно всего на всех не хватит. И возникают вопросы:
1. нейрокомпьютер — это интеллектуальная игрушка или новая техническая революция?
2. что нового и полезного может сделать нейрокомпьютер?
За этими вопросами скрыты два базовых предположения:
1. на новые игрушки, даже высокоинтеллектуальные, средств нет;
2. нейрокомпьютер должен доказать свои новые возможности — сделать то, чего не может сделать обычная ЭВМ, — иначе на него не стоит тратиться.
У энтузиастов есть свои рекламные способы отвечать на заданные вопросы, рисуя светлые послезавтрашние горизонты. Но все это в будущем. А сейчас? Ответы парадоксальны:
1. нейрокомпьютеры — это новая техническая революция, которая приходит к нам в виде интеллектуальной игрушки (вспомните — и персональные ЭВМ были придуманы для игры!);
2. для любой задачи, которую может решить нейрокомпьютер, можно построить более стандартную специализированную ЭВМ, которая решит ее не хуже, а чаще всего — даже лучше.
Зачем же тогда нейрокомпьютеры? Вступая в творческую игру, мы не можем знать, чем она кончится, иначе это не Игра. Поэзия и реклама дают нам фантом, призрак результата, погоня за которым ‑ важнейшая часть игры. Столь же призрачными могут оказаться и прозаичные ответы ‑ игра может далеко от них увести. Но и они необходимы ‑ трудно бегать по облакам и иллюзия практичности столь же важна, сколь и иллюзия величия. Вот несколько вариантов прозаичных ответов на вопрос «зачем?» ‑ можно выбрать, что для Вас важнее:
А. Нейрокомпьютеры дают стандартный способ решения многих нестандартных задач. И неважно, что специализированная машина лучше решит один класс задач. Важнее, что один нейрокомпьютер решит и эту задачу, и другую, и третью — и не надо каждый раз проектировать специализированную ЭВМ — нейрокомпьютер сделает все сам и почти не хуже.
Б. Вместо программирования — обучение. Нейрокомпьютер учится — нужно только формировать учебные задачники. Труд программиста замещается новым трудом — учителя (может быть, надо сказать — тренера или дрессировщика). Лучше это или хуже? Ни то, ни другое. Программист предписывает машине все детали работы, учитель — создает «образовательную среду», к которой приспосабливается нейрокомпьютер. Появляются новые возможности для работы.
В. Нейрокомпьютеры особенно эффективны там, где нужно подобие человеческой интуиции — для распознавания образов (узнавания лиц, чтения рукописных текстов), перевода с одного естественного языка на другой и т. п. Именно для таких задач обычно трудно сочинить явный алгоритм.
Г. Гибкость структуры: можно различными способами комбинировать простые составляющие нейрокомпьютеров — нейроны и связи между ними. За счет этого на одной элементной базе и даже внутри «тела» одного нейрокомпьютера можно создавать совершенно различные машины. Появляется еще одна новая профессия — «нейроконструктор» (конструктор мозгов).
Д. Нейронные сети позволяют создать эффективное программное обеспечение для высокопараллельных компьютеров. Для высокопараллельных машин хорошо известна проблема: как их эффективно использовать — как добиться, чтобы все элементы одновременно и без лишнего дублирования вычисляли что-нибудь полезное? Создавая математическое обеспечения на базе нейронных сетей, можно для широкого класса задач решить эту проблему.
Если перейти к еще более прозаическому уровню повседневной работы, то нейронные сети ‑ это всего-навсего сети, состоящие из связанных между собой простых элементов ‑ формальных нейронов. Значительное большинство работ по нейроинформатике посвящено переносу различных алгоритмов решения задач на такие сети.
Ядром используемых представлений является идея о том, что нейроны можно моделировать довольно простыми автоматами, а вся сложность мозга, гибкость его функционирования и другие важнейшие качества определяются связями между нейронами. Каждая связь представляется как совсем простой элемент, служащий для передачи сигнала. Предельным выражением этой точки зрения может служить лозунг: «структура связей — все, свойства элементов — ничто».
Совокупность идей и научно-техническое направление, определяемое описанным представлением о мозге, называется коннекционизмом (по-английски connection — связь). Как все это соотносится с реальным мозгом? Так же, как карикатура или шарж со своим прототипом-человеком ‑ весьма условно. Это нормально: важно не буквальное соответствие живому прототипу, а продуктивность технической идеи.
С коннекционизмом тесно связан следующий блок идей:
1) однородность системы (элементы одинаковы и чрезвычайно просты, все определяется структурой связей);
2) надежные системы из ненадежных элементов и «аналоговый ренессанс» — использование простых аналоговых элементов;
3) «голографические» системы — при разрушении случайно выбранной части система сохраняет свои полезные свойства.
Предполагается, что система связей достаточно богата по своим возможностям и достаточно избыточна, чтобы скомпенсировать бедность выбора элементов, их ненадежность, возможные разрушения части связей.
Коннекционизм и связанные с ним идеи однородности, избыточности и голографичности еще ничего не говорят нам о том, как же такую систему научить решать реальные задачи. Хотелось бы, чтобы это обучение обходилось не слишком дорого.
На первый взгляд кажется, что коннекционистские системы не допускают прямого программирования, то есть формирования связей по явным правилам. Это, однако, не совсем так. Существует большой класс задач: нейронные системы ассоциативной памяти, статистической обработки, фильтрации и др., для которых связи формируются по явным формулам. Но еще больше (по объему существующих приложений) задач требует неявного процесса. По аналогии с обучением животных или человека этот процесс мы также называем обучением.
Обучение обычно строится так: существует задачник — набор примеров с заданными ответами. Эти примеры предъявляются системе. Нейроны получают по входным связям сигналы — «условия примера», преобразуют их, несколько раз обмениваются преобразованными сигналами и, наконец, выдают ответ — также набор сигналов. Отклонение от правильного ответа штрафуется. Обучение состоит в минимизации штрафа как (неявной) функции связей. Примерно четверть нашей книги состоит в описании техники такой оптимизации и возникающих при этом дополнительных задач.
Неявное обучение приводит к тому, что структура связей становится «непонятной» — не существует иного способа ее прочитать, кроме как запустить функционирование сети. Становится сложно ответить на вопрос: «Как нейронная сеть получает результат?» — то есть построить понятную человеку логическую конструкцию, воспроизводящую действия сети.
Это явление можно назвать «логической непрозрачностью» нейронных сетей, обученных по неявным правилам. В работе с логически непрозрачными нейронными сетями иногда оказываются полезными представления, разработанные в психологии и педагогике, и обращение с обучаемой сетью как с дрессируемой зверушкой или с обучаемым младенцем — это еще один источник идей. Возможно, со временем возникнет такая область деятельности — «нейропедагогика» — обучение искусственных нейронных сетей.
С другой стороны, при использовании нейронных сетей в экспертных системах на PC возникает потребность прочитать и логически проинтерпретировать навыки, выработанные сетью. В главе «Контрастер» описаны служащие для этого методы контрастирования — получения неявными методами логически прозрачных нейронных сетей. Однако за логическую прозрачность приходится платить снижением избыточности, так как при контрастировании удаляются все связи кроме самых важных, без которых задача не может быть решена.
Итак, очевидно наличие двух источников идеологии нейроинформатики. Это представления о строении мозга и о процессах обучения. Существуют группы исследователей и научные школы, для которых эти источники идей имеют символическое, а иногда даже мистическое или тотемическое значение.
В работе [56] доказана теорема, утверждающая, что с помощью линейных комбинаций и суперпозиций линейных функций и одной произвольной нелинейной функции одного аргумента можно сколь угодно точно приблизить любую непрерывную функцию многих переменных.
Из этой теоремы следует, что Нейронные сети — универсальные аппроксимирующие устройства и могут с любой точностью имитировать любой непрерывный автомат
Главный вопрос: что могут нейронные сети. Ответ получен: нейронные сети могут все. Остается открытым другой вопрос: как их этому научить?
Лекции 2 и 3. Сети естественной классификации
В данном разделе курса будут рассмотрены сети естественной классификации. Этот класс сетей имеет еще одно название — сети, обучающиеся без учителя. Второе название имеет более широкое распространение, однако, является в корне неверным. В дальнейшем в нашем курсе будет рассмотрена модель универсального нейрокомпьютера в которой будет явно выделен компонент учитель и описаны его функции. В этом смысле данный вид сетей обучается с явно заданным учителем. Когда давалось это название, имелось в виду, что сети данного вида не обучают воспроизведению заранее заданной классификации. Именно поэтому название «Сети естественной классификации» является наиболее точным для данного класса сетей. Наиболее известной сетью данного вида является сеть Кохонена [131, 132].
Содержательная постановка задачи
Достаточно часто на практике приходится сталкиваться со следующей задачей: есть таблица данных (результаты измерений, социологических опросов или обследований больных). Необходимо определить каким закономерностям подчиняются данные в таблице. Следует заметить, что характерный размер таблицы — порядка ста признаков и порядка нескольких сотен или тысяч объектов. Ручной анализ таких объемов информации фактически невозможен.
Первым шагом в решении данной задачи является группировка (кластеризация, классификация) объектов в группы (кластеры, классы) «близких» объектов. Далее исследуются вопросы того, что общего между объектами одной группы, и что отличает их от других групп. Далее будем использовать термин классификация и говорить о классах близких объектов.
Слово близких, в постановке задачи, взято в кавычки, поскольку под близостью можно понимать множество разных отношений близости. Далее будет рассмотрен ряд примеров различных видов близости.
К сожалению, вид близости и число классов приходится определять исследователю, хотя существует набор методов (методы отжига) позволяющих оптимизировать число классов.
Формальная постановка задачи
Рассмотрим множество из m объектов {x}, каждый из которых является n-мерным вектором с действительными координатами (в случае комплексных координат особых трудностей с данным методом также не возникает, но формулы становятся более сложными, а комплексные значения признаков случаются редко).
Зададим пространство ядер классов E, и меру близости dist(a, x), где a — точка из пространства ядер, а x — точка из пространства объектов. Тогда для заданного числа классов k необходимо подобрать k ядер таким образом, чтобы суммарная мера близости была минимальной. Суммарная мера близости записывается в следующем виде:
(1)
где Ki — множество объектов i—го класса.
Сеть Кохонена
Сеть Кохонена для классификации на k классов состоит из k нейронов (ядер), каждый из которых вычисляет близость объекта к своему классу. Все нейроны работают параллельно. Объект считается принадлежащим к тому классу, нейрон которого выдал минимальный сигнал. При обучении сети Кохонена считается, что целевой функционал не задан (отсюда и название «Обучение без учителя»). Однако алгоритм обучения устроен так, что в ходе обучения минимизируется функционал (1), хотя и немонотонно.
Обучение сети Кохонена
Предложенный финским ученым Кохоненом метод обучения сети решению такой задачи состоит в следующем. Зададим некоторый начальный набор параметров нейронов. Далее предъявляем сети один объект x. Находим нейрон, выдавший максимальный сигнал. Пусть номер этого нейрона i. Тогда параметры нейрона модифицируются по следующей формуле:
ai′=λx+(1-λ)ai (2)
Затем сети предъявляется следующий объект, и так далее до тех пор, пока после очередного цикла предъявления всех объектов не окажется, что параметры всех нейронов изменились на величину меньшую наперед заданной точности ε. В формуле (2) параметр λ называют скоростью обучения. Для некоторых мер близости после преобразования (2) может потребоваться дополнительная нормировка параметров нейрона.
Сеть Кохонена на сфере
Рис 1. Три четко выделенных кластера в исходном пространстве сливаются полностью (а) или частично (б) при проецировании на единичную сферу.
Одним из наиболее распространенных и наименее удачных (в смысле практических применений) является сферическая сеть Кохонена. В этой постановке предполагается, что все вектора-объекты имеют единичную длину. Ядра (векторы параметров нейронов) также являются векторами единичной длины. Привлекательность этой модели в том, что нейрон вычисляет очень простую функцию — скалярное произведение вектора входных сигналов на вектор параметров. Недостатком является большая потеря информации во многих задачах. На рис. 1 приведен пример множества точек разбитого на три четко выделенных кластера в исходном пространстве, которые сливаются полностью или частично при проецировании на единичную сферу.
Эта модель позволяет построить простые иллюстрации свойств обучения сетей Кохонена, общие для всех методов. Наиболее иллюстративным является пример, когда в двумерном пространстве множество объектов равномерно распределено по сфере (окружности), причем объекты пронумерованы против часовой стрелке. В начальный момент времени ядра являются противоположно направленными векторами.
Рис. 2. Положение ядер при последовательном предъявлении объектов со скоростью обучения 0,5. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер.
На рис. 2 приведены состояния сети Кохонена перед началом обучения и после каждой эпохи обучения. Эпохой принято называть полный цикл предъявления обучающего множества (всех объектов, по которым проводится обучение). Ядра на рисунках обозначены жирными линиями. Из рисунка видно, что обучение зациклилось — после каждой эпохи сумма квадратов изменений координат всех ядер то уменьшается, то возрастает. В литературе приводится целый ряд способов избежать зацикливания. Один из них — обучать с малым шагом. На рис. 3 приведены состояния сети при скорости обучения 0,01.
Рис. 3. Положение ядер при последовательном предъявлении объектов со скоростью обучения 0,01. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер.
Из анализа рис. 3 видно, что изменения ядер уменьшаются со временем. Однако в случае изначально неудачного распределения ядер потребуется множество шагов для перемещения их к «своим» кластерам (см. рис. 4).
Рис. 4. Обучение сети Кохонена со скоростью 0,01 (107 эпох)
Следующая модификация алгоритма обучения состоит в постепенном уменьшении скорости обучения. Это позволяет быстро приблизиться к «своим» кластерам на высокой скорости и произвести доводку при низкой скорости. Для этого метода необходимым является требование, чтобы последовательность скоростей обучения образовывала расходящийся ряд, иначе остановка алгоритма будет достигнута не за счет выбора оптимальных ядер, а за счет ограниченности точности вычислений. На рис. 5 приведены состояния сети Кохонена при использовании начальной скорости обучения 0,5 и уменьшения скорости в соответствии с натуральным рядом (1, ½, ⅓, …). Уменьшение скорости обучения производилось после каждой эпохи. Из графика изменения суммы квадратов изменений координат ядер видно, что этот метод является лучшим среди рассмотренных. На рис. 6 приведены результаты применения этого метода в случае неудачного начального положения ядер. Распределение объектов выбрано то же, что и на рисунке 4 — два класса по 8 объектов, равномерно распределенных в интервалах [π/4,3 π/4] и [5π/4, 7π/4].
Рис. 5. Положение ядер при последовательном предъявлении объектов со снижением скорости обучения с 0,5 в соответствии с последовательностью 1/n. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер (в логарифмической шкале).
Рис. 6. Обучение сети Кохонена со снижением скорости с 0,5.
Альтернативой методу с изменением шага считается метод случайного перебора объектов в пределах эпохи. Основная идея этой модернизации метода состоит в том, чтобы избежать направленного воздействия.
Рис. 7. Положение ядер при предъявлении объектов в случайном порядке со скоростью обучения 0,5. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер.
Под направленным воздействием подразумевается порядок предъявления объектов, который влечет смещение ядра от оптимального положения в определенную сторону. Именно эффект направленного воздействия приводит к тому, что стандартный метод зацикливается (отметим, что пример с равномерно распределенными по окружности объектами, пронумерованными против часовой стрелки, специально строился для оказания направленного воздействия). Именно из-за направленного воздействия ядра на рис. 6 направлены не строго вертикально. Случайный порядок перебора объектов позволяет избежать, точнее снизить эффект, направленного воздействия. Однако из рис. 7, на котором приведены результаты применения метода перебора объектов в случайном порядке к задаче с равномерно распределенными по окружности объектами, видно, что полностью снять эффект направленного воздействия этот метод не позволяет.
Возможны различные сочетания рассмотренных выше методов. Например, случайный перебор объектов в сочетании с уменьшением скорости обучения. Именно такая комбинация методов является наиболее мощным методом среди методов пообъектного обучения сетей Кохонена.
Метод динамических ядер
Альтернативой методам пообъектного обучения сетей Кохонена является метод динамических ядер, который напрямую минимизирует суммарную меру близости (1). Метод является итерационной процедурой, каждая итерация которой состоит из двух шагов. Сначала задаются начальные значения ядер. Затем выполняют следующие шаги:
Разбиение на классы при фиксированных значениях ядер:
Ki={x: dist(ai, x)≤dist(aj, x)} (3)
Оптимизация значений ядер при фиксированном разбиении на классы:
(4)
В случае равенства в формуле (3) объект относят к классу с меньшим номером. Процедура останавливается если после очередного выполнения разбиения на классы (3) не изменился состав ни одного класса.
Исследуем сходимость метода динамических ядер. На шаге (3) суммарная мера близости (1) может измениться только при переходе объектов из одного класса в другой. Если объект перешел из j-го класса в i-й, то верно неравенство dist(ai, x)≤dist(aj, x). То есть при переходе объекта из одного класса в другой суммарная мера близости не возрастает. На шаге (4) минимизируются отдельные слагаемые суммарной меры близости (1). Поскольку эти слагаемые независимы друг от друга, то суммарная мера близости на шаге (4) не может возрасти. При это если на шаге (4) суммарная мера близости не уменьшилась, то ядра остались неизменными и при выполнении следующего шага (3) будет зафиксировано выполнение условия остановки. И наконец, учитывая, что конечное множество объектов можно разбить на конечное число классов только конечным числом способов, получаем окончательное утверждение о сходимости метода динамических ядер.
Процедура (3), (4) сходится за конечное число шагов, причем ни на одном шаге не происходит возрастания суммарной меры близости.
На первом из рассмотренных выше примеров, с равномерно распределенными по окружности объектами, при любом начальном положении ядер (за исключением совпадающих ядер) метод динамических ядер остановится на втором шаге, поскольку при второй классификации (3) состав классов останется неизменным.
На втором из примеров, рассмотренных выше (см. рис. 4, 6) примеров при том же начальном положении ядер, метод динамических ядер остановится после первого шага, не изменив положения ядер. Однако такое положение ядер не соответствует обычному представлению о «хорошей» классификации. Причина — неудачное начальное положение ядер (созданное специально).
Выбор начального приближения
Как и во многих других итерационных методах, в задаче обучения сети Кохонена и в методе динамических ядер важным является вопрос о хорошем выборе начального приближения (первоначальных значений ядер). Существует множество методов выбора начального приближения.
Наиболее простым способом решения этой задачи в случае, когда ядра являются точками того же пространства, что и объекты, является выбор в качестве начального приближения значений ядер значений объектов. Например первое ядро кладем равным первому объекту, второе — второму и т. д. К сожалению этот метод не работает когда пространство ядер и пространство объектов не совпадают. Далее будут приведены примеры классификаций, в которых пространства ядер и объектов различны.
Самым универсальным способом задания начального положения ядер является задание начального разбиения объектов на классы. При этом в начальном разбиении могут участвовать не все объекты. Далее решая задачу (4) получаем начальные значения ядер. Далее можно использовать метод динамических ядер.
Примеры видов классификации
В данном разделе описаны некоторые виды классификации и соответствующие им меры близости. Приведены формулы решения задачи (4) при использовании метода динамических ядер. Для других видов классификации решение задачи (4) строится аналогично.
Сферическая модель
Один вид классификации — сеть Кохонена на сфере был описан ранее. Получим формулы для решения задачи (4) при мере близости «минус скалярное произведение» (минус перед скалярным произведением нужен для того, чтобы решать задачу минимизации (1) и (4), поскольку, чем ближе векторы, тем больше скалярное произведение).
Обозначим через xij объекты, принадлежащие i-му классу. Учитывая дополнительное условие на значение ядра — его единичную длину — и применяя метод множителей Лагранжа для решения задач поиска условного экстремума, получим следующую задачу:
(5)
Дифференцируя (5) по каждой из координат ядра и по множителю Лагранжа λ, и приравнивая результат дифференцирования к нулю, получим следующую систему уравнений:
(6)
Выразив из первых уравнений ail и подставив результат в последнее выражение найдем λ, а затем найдем координаты ядра:
(7)
Рис. 8. Решение задачи методом динамических ядер
Подводя итог, можно сказать, что новое положение ядра есть среднее арифметическое объектов данного класса, нормированное на единичную длину.
На рис. 8. Приведено решение второго примера методом обучения сети Кохонена с уменьшением скорости с 0,5, а на рис. 9 — решение той же задачи методом динамических ядер. В качестве первоначального значения ядер выбраны два первых объекта.
Рис. 9. Решение задачи с помощью обучения сети Кохонена со снижением скорости обучения с 0,5. График суммарного изменения разностей координат ядер.
Пространственная модель
Эта модель описывает наиболее естественную классификацию. Нейрон пространственной сети Кохонена приведен в главе «Описание нейронных сетей». Ядра являются точками в пространстве объектов. Мера близости — квадрат обычного евклидова расстояния. Обучение сети Кохонена ведется непосредственно по формуле (2). Задача (4) имеет вид:
(8)
Дифференцируя (8) по каждой координате ядра и приравнивая результат к нулю получаем следующую систему уравнений:
Преобразуя полученное выражение получаем
, (9)
где |Ki| — мощность i-го класса (число объектов в классе). Таким образом, оптимальное ядро класса — среднее арифметическое всех объектов класса.
Модель линейных зависимостей
Это первая модель, которая может быть решена методом динамических ядер, но не может быть получена с помощью обучения сети Кохонена, поскольку ядра не являются точками в пространстве объектов. Ядрами в данной модели являются прямые, а мерой близости — квадрат расстояния от точки (объекта) до прямой. Прямая в n—мерном пространстве задается парой векторов: ai = (bi, ci). Первый из векторов задает смещение прямой от начала координат, а второй является направляющим вектором прямой. Точки прямой задаются формулой x = b + tc, где t — параметр, пробегающий значения от минус бесконечности до плюс бесконечности. t имеет смысл длины проекции вектора x-b на вектор c. Сама проекция равна tc. При положительном значении вектор проекции сонаправлен с вектором c, при отрицательном — противоположно направлен. При условии, что длина вектора c равна единице, проекция вычисляется как скалярное произведение (x–b,c). В противном случае скалярное произведение необходимо разделить на квадрат длины c. Мера близости вектора (точки) x определяется как квадрат длины разности вектора x и его проекции на прямую. При решении задачи (4) необходимо найти минимум следующей функции:
Продифференцируем целевую функцию по неизвестным tq, cir, bir и приравняем результаты к нулю.
(10)
Выразим из последнего уравнения в (10) bir:
(11)
В качестве bi можно выбрать любую точку прямой. Отметим, что для любого набора векторов xij и любой прямой с ненулевым направляющим вектором ci на прямой найдется такая точка bi, что сумма проекций всех точек на прямую x = b + tc будет равна нулю. Выберем в качестве bi такую точку. Второе слагаемое в правой части (11) является r-й координатой суммы проекций всех точек на искомую прямую и, в силу выбора точки bi равно нулю. Тогда получаем формулу для определения bi:
(12)
Из первых двух уравнений (10) получаем формулы для определения остальных неизвестных:
(13)
Поиск решения задачи (4) для данного вида классификации осуществляется по следующему алгоритму:
1. Вычисляем bi по формуле (12).
2. Вычисляем t по первой формуле в (13).
3. Вычисляем ci по второй формуле в (13).
4. Если изменение значения ci превышает заданную точность, то переходим к шагу 2, в противном случае вычисления закончены.
Определение числа классов
До этого момента вопрос об определении числа классов не рассматривался. Предполагалось, что число классов задано исходя из каких-либо дополнительных соображений. Однако достаточно часто дополнительных соображений нет. В этом случае число классов определяется экспериментально. Но простой перебор различных чисел классов часто неэффективен. В данном разделе будет рассмотрен ряд методов, позволяющих определить «реальное» число классов.
Для иллюстрации будем пользоваться пространственной моделью в двумерном пространстве. На рис, 10 приведено множество точек, которые будут разбиваться на классы.
Простой подбор
Идея метода состоит в том, что бы начав с малого числа классов постепенно увеличивать его до тех пор, пока не будет получена «хорошая» классификация. Понятие «хорошая» классификация может быть формализовано по разному. При простом подборе классов как правило оперируют таким понятием, как часто воспроизводящийся класс. Проводится достаточно большая серия классификаций с различным начальным выбором классов. Определяются классы, которые возникают в различных классификациях. Считаются частоты появления таких классов. Критерием получения «истинного» числа классов может служить снижение числа часто повторяющихся классов. То есть при числе классов k число часто повторяющихся классов заметно меньше чем при числе классов k – 1 и k + 1. Начинать следует с двух классов.
Рис. 10. Множества точек для классификации
Рис. 11. Разбиение множества на два (а) и три (б) класса
Рассмотрим два примера. На рис. 10 приведены множества точек, которые будут разбиваться на классы. При каждом числе классов проводится 100 разбиений на классы. В качестве начальных значений ядер выбираются случайные точки.
Сначала рассмотрим множество точек, приведенное на рис. 10а. При классификациях на два класса во всех 100 случаях получаем классификацию, приведенную на рис. 11. Таким образом, получено устойчивое (абсолютно устойчивое) разбиение множества точек на два класса.
В принципе можно на этом остановиться. Однако возможно, что мы имеем дело с иерархической классификацией, то есть каждый (или один) из полученных на данном этапе классов может в дальнейшем разбиться на несколько классов. Для проверки этой гипотезы проведем классификацию на три класса. Во всех 100 случаях получаем одно и то же разбиение, приведенное на рис. 11б. Гипотеза об иерархической классификации получила подтверждение. Предпринимаем попытку дальнейшей детализации — строим разбиение на четыре класса. При этом возникают три различных разбиения, приведенных на рис. 12. При этом разбиение, приведенное на рис. 12в возникает всего два раза из 100. Разбиение, приведенное на рис. 12а — 51 раз, на рис. 12б — 47 раз. Если отбросить редкие классы, то получим набор из семи классов. Один из них воспроизводится 98 раз (красное множество на рис. 12а). Остальные шесть классов образуют две тройки. Каждая тройка состоит из двух классов и класса, являющегося их объединением. Из этого анализа напрашивается вывод о том, что число классов равно пяти. Проверяем это предположение.
Рис. 12. Три варианта классификации на четыре класса
Результаты классификации на пять классов приведены на рис. 13. Выделенные на предыдущем этапе пять «маленьких» классов были воспроизведены 84, 67, 64, 68 и 69 раз. Два «больших» класса, выделенных на предыдущем этапе, были воспроизведены 24 и 30 раз. Остальные классы были получены не более чем 4 раза, а большинство по одному разу. Проверим классификацию на 6 классов. Малые классы были получены 75, 70, 53, 43, 44 раза. Один из больших классов — 16 раз. Из остальных классов один был воспроизведен 24 раза, второй — 19 раз. Все другие классы появлялись не более 10 раз. Всего получено 149 классов.
Рис. 13. Различные варианты классификации на пять классов
Таким образом, получена трехуровневая иерархическая классификация: Два класса первого уровня приведены на рис. 11а. Три класса второго уровня — на рис. 11б. Пять классов третьего уровня — на рис. 13а.
Рис. 14. Классификации на два класса
Рис. 15. Типы классификаций на три класса
Рис. 16. Типичные классификации на четыре класса
Проведем туже процедуру для множества точек, приведенного на рис. 10б. При классификации на два класса получим четыре типичных варианта классификаций, приведенных на рис. 14. Всего получено 14 классов. Два класса были получены по 69 раз, два по 18 раз. Остальные не более 6 раз.
Проведем классификацию на три класса. Получим всего два типа классификаций, приведенных на рис. 15. Всего получено 12 классов. Одна тройка классов была воспроизведена 14 раз, вторая — 26 раз, третья — 27 и четвертая — 33 раза. После классификации на четыре класса получены четыре типичных классификации, приведенные на рис. 16. Всего получено 54 класса. Пять из них получены 36, 37, 36, 36 и 57 раз. Еще 4 класса получены 14 раз, два класса — 10 раз, остальные не более 6 раз. При классификации на пять классов получено семь типичных классификаций, приведенных на рис. 17. Всего было получено 49 классов. При этом пять классов были получены 91, 82, 87, 92 и 82 раза. Еще один класс — 8 раз. Остальные классы не более 3 раз. Увеличился разрыв между «редкими» и «частыми» классами. Сократилось число часто повторяющихся классов. Для контроля проведем классификацию на 6 классов. Всего получено 117 классов. Из них пять были получены 86, 81, 57, 76 и 69 раз. Все остальные классы были получены не более 9 раз.
Таким образом, на основе классификаций на четыре, пять и шесть классов можно утверждать, что «реально» существует пять классов.
Методы отжига
Предложенный метод перебора количества классов хорошо работает при небольшом «реальном» числе классов. При достаточно большом числе классов и большом объеме множества точек, которые необходимо разбить на классы, такая процедура подбора становится слишком медленной. Действительно, число пробных классификаций должно быть сравнимо по порядку величины с числом точек. В результате получается большие вычислительные затраты, которые чаще всего тратятся впустую (важны несколько значений числа классов вблизи «реального» числа классов).
Альтернативой методу перебора служит метод отжига. Идея метода отжига состоит в том, что на основе критерия качества класса принимается решение об удалении этого класса, разбиении класса на два или о слиянии этого класса с другим. Если класс «хороший», то он остается без изменений. Существует много различных критериев качества класса. Рассмотрим некоторые из них.
1. Количественный критерий. Класс, в котором менее N точек считается пустым и полежит удалению. Порог числа точек выбирается из смысла задачи и вида меры близости.
2. Критерий равномерности. Средняя мера близости точек класса от ядра должна быть не менее половины или трети от максимума меры близости точек от ядра (радиуса класса). Если это не так, то класс разбивается на два (порождается еще одно ядро вблизи первоначального).
3. Критерий сферической разделимости. Два класса считаются сферически разделимыми, если сумма радиусов двух классов меньше расстояния между ядрами этих классов. Если классы сферически неразделимы, то эти классы сливаются в один.
Очевидно, что третий критерий применим только в тех случаях, когда ядра классов являются точками того же пространства, что и те точки, которые составляют классы. Все приведенные критерии неоднозначны и могут меняться в зависимости от требований задачи. Так вместо сферической разделимости можно требовать эллиптической разделимости и т. д.
Начальное число классов можно задавать по разному. Например, начать с двух классов и позволить сети «самой» увеличивать число классов. Или начать с большого числа классов и позволить сети отбросить «лишние» классы. В первом случае система может остановиться в случае наличия иерархической классификации (пример 1 из предыдущего раздела). Начиная с большого числа классов, мы рискуем не узнать о существовании иерархии классов.
Другим критерием может служить плотность точек в классе. Определим объем класса как объем шара с центром в ядре класса и радиусом равным радиусу класса. Для простоты можно считать объем класса равным объему куба с длинной стороны равной радиусу класса (объем шара будет отличаться от объема куба на постоянный множитель, зависящий только от размерности пространства). Плотностью класса будем считать отношение числа точек в классе к объему класса. Отметим, что этот критерий применим для любых мер близости, а не только для тех случаев, когда ядра и точки принадлежат одному пространству.
Метод применения этого критерия прост. Разбиваем первый класс на два и запускаем процедуру настройки сети (метод динамических ядер или обучение сети Кохонена). Если плотности обоих классов, полученных разбиением одного класса, не меньше плотности исходного класса, то считаем разбиение правильным. В противном случае восстанавливаем классы, предшествовавшие разбиению, и переходим к следующему классу. Если после очередного просмотра всех классов не удалось получить ни одного правильного разбиения, то считаем полученное число классов соответствующим «реальному». Эту процедуру следует запускать с малого числа классов, например, с двух.
Проведем процедуру определения числа классов для множества точек, приведенного на рис. 10а. Результаты приведены на рис. 18. Порядок классов 1-й класс — черный цвет, 2-й класс — синий, 3-й — зеленый, 4-й — красный, 5-й — фиолетовый, 6-й — желтый.
Рассмотрим последовательность действий, отображенную на рис. 18.
Первый рисунок — результат классификации на два класса.
Второй рисунок — первый класс разбит на два. Результат классификации на три класса. Плотности увеличились. Разбиение признано хорошим.
Рис. 18. Результат применения критерия плотности классов для определения числа классов к множеству точек, приведенному на рис. 10а.
Третий рисунок — первый класс разбит на два. Результат классификации на четыре класса. Плотности увеличились. Разбиение признано хорошим.
Четвертый рисунок — первый класс разбит на два. Результат классификации на пять классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к третьему рисунку.
Пятый рисунок — второй класс разбит на два. Результат классификации на пять классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к третьему рисунку.
Шестой рисунок — третий класс разбит на два. Результат классификации на пять классов. Плотности увеличились. Разбиение признано хорошим.
Седьмой рисунок — первый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Восьмой рисунок — второй класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Девятый рисунок — третий класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Десятый рисунок — четвертый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Одинадцатый рисунок — пятый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Двенадцатый рисунок (совпадает с шестым) — окончательный результат.
Рис. 19. Результат применения критерия плотности классов для определения числа классов к множеству точек, приведенному на рис. 10б.
На рис. 19 приведен результат применения плотностного критерия определения числа классов для множества точек, приведенного на рис. 10б.
Лекции 4, 5 и 6. Нейронные сети ассоциативной памяти, функционирующие в дискретном времени
Нейронные сети ассоциативной памяти — сети восстанавливающие по искаженному и/или зашумленному образу ближайший к нему эталонный. Исследована информационная емкость сетей и предложено несколько путей ее повышения, в том числе — ортогональные тензорные (многочастичные) сети. Описаны способы предобработки, позволяющие конструировать нейронные сети ассоциативной памяти для обработки образов, инвариантной относительно групп преобразований. Описан численный эксперимент по использованию нейронных сетей для декодирования различных кодов. Доказана теорема об информационной емкости тензорных сетей.
Описание задачи
Прежде чем заниматься конструированием сетей ассоциативной памяти необходимо ответить на следующие два вопроса: «Как устроена ассоциативная память?» и «Какие задачи она решает?». Когда мы задаем эти вопросы, имеется в виду не устройство отделов мозга, отвечающих за ассоциативную память, а наше представление о макропроцессах, происходящих при проявлении ассоциативной памяти.
Принято говорить, что у человека возникла ассоциация, если при получении некоторой неполной информации он может подробно описать объект, к которому по его мнению относится эта информация. Достаточно хорошим примером может служить описание малознакомого человека. К примеру, при высказывании: «Слушай, а что за парень, с которым ты вчера разговаривал на вечеринке, такой высокий блондин?»— у собеседника возникает образ вчерашнего собеседника, не ограничивающийся ростом и цветом волос. В ответ на заданный вопрос он может рассказать об этом человеке довольно много. При этом следует заметить, что содержащейся в вопросе информации явно недостаточно для точной идентификации собеседника. Более того, если вчерашний собеседник был случайным, то без дополнительной информации его и не вспомнят.
Подводя итог описанию можно сказать, что ассоциативная память позволяет по неполной и даже частично недостоверной информации восстановить достаточно полное описание знакомого объекта. Слово знакомого является очень важным, поскольку невозможно вызвать ассоциации с незнакомыми объектами. При этом объект должен быть знаком тому, у кого возникают ассоциации.
Одновременно рассмотренные примеры позволяют сформулировать решаемые ассоциативной памятью задачи:
Соотнести входную информацию со знакомыми объектами, и дополнить ее до точного описания объекта.
Отфильтровать из входной информации недостоверную, а на основании оставшейся решить первую задачу.
Очевидно, что под точным описанием объекта следует понимать всю информацию, которая доступна ассоциативной памяти. Вторая задача решается не поэтапно, а одновременно происходит соотнесение полученной информации с известными образцами и отсев недостоверной информации.
Нейронным сетям ассоциативной памяти посвящено множество работ (см. например, [75, 77, 80, 86, 114, 130, 131, 153, 231, 247, 296, 312, 329]). Сети Хопфилда являются основным объектом исследования в модельном направлении нейроинформатики.
Формальная постановка задачи
Пусть задан набор из m эталонов — n-мерных векторов {xi}. Требуется построить сеть, которая при предъявлении на вход произвольного образа — вектора x — давала бы на выходе «наиболее похожий» эталон.
Всюду далее образы и, в том числе, эталоны — n-мерные векторы с координатами ±1. Примером понятия эталона «наиболее похожего» на x может служить ближайший к x вектор xi. Легко заметить, что это требование эквивалентно требованию максимальности скалярного произведения векторов x и xi :
Первые два слагаемых в правой части совпадают для любых образов x и xi, так как длины всех векторов-образов равны √n. Таким образом, задача поиска ближайшего образа сводится к поиску образа, скалярное произведение с которым максимально. Этот простой факт приводит к тому, что сравнивать придется линейные функции от образов, тогда как расстояние является квадратичной функцией.
Сети Хопфилда
Наиболее известной сетью ассоциативной памяти является сеть Хопфилда [312]. В основе сети Хопфилда лежит следующая идея — запишем систему дифференциальных уравнений для градиентной минимизации «энергии» H (функции Ляпунова). Точки равновесия такой системы находятся в точках минимума энергии. Функцию энергии будем строить из следующих соображений:
1. Каждый эталон должен быть точкой минимума.
2. В точке минимума все координаты образа должны иметь значения ±1.
Функция
не удовлетворяет этим требованиям строго, но можно предполагать, что первое слагаемое обеспечит притяжение к эталонам (для вектора x фиксированной длины максимум квадрата скалярного произведения (x, xi)² достигается при x= xi…), а второе слагаемое — приблизит к единице абсолютные величины всех координат точки минимума). Величина a характеризует соотношение между этими двумя требованиями и может меняться со временем.
Используя выражение для энергии, можно записать систему уравнений, описывающих функционирование сети Хопфилда [312]:
(1)
Сеть Хопфилда в виде (1) является сетью с непрерывным временем. Это, быть может, и удобно для некоторых вариантов аналоговой реализации, но для цифровых компьютеров лучше воспользоваться сетями, функционирующими в дискретном времени — шаг за шагом.
Построим сеть Хопфилда [312] с дискретным временем. Сеть должна осуществлять преобразование входного вектора x так, чтобы выходной вектор x' был ближе к тому эталону, который является правильным ответом. Преобразование сети будем искать в следующем виде:
(2)
где wi — вес i-го эталона, характеризующий его близость к вектору x, Sign — нелинейный оператор, переводящий вектор с координатами yi в вектор с координатами sign(yi).
Функционирование сети
Сеть работает следующим образом:
1. На вход сети подается образ x, а на выходе снимается образ x'.
2. Если x' ≠ x, то полагаем x = x' и возвращаемся к шагу 1.
3. Полученный вектор x' является ответом.
Таким образом, ответ всегда является неподвижной точкой преобразования сети (2) и именно это условие (неизменность при обработке образа сетью) и является условием остановки.
Пусть j* — номер эталона, ближайшего к образу x. Тогда, если выбрать веса пропорционально близости эталонов к исходному образу x, то следует ожидать, что образ x' будет ближе к эталону xi′, чем x, а после нескольких итераций он станет совпадать с эталоном xi′.
Наиболее простой сетью вида (2) является дискретный вариант сети Хопфилда [312] с весами равными скалярному произведению эталонов на предъявляемый образ:
(3)
Рис. 1. а, б, в — эталоны, г — ответ сети на предъявление любого эталона
О сетях Хопфилда (3) известно [53, 231, 247, 312], что они способны запомнить и точно воспроизвести «порядка 0.14n слабо коррелированных образов». В этом высказывании содержится два ограничения:
• число эталонов не превосходит 0.14n.
• эталоны слабо коррелированны.
Наиболее существенным является второе ограничение, поскольку образы, которые сеть должна обрабатывать, часто очень похожи. Примером могут служить буквы латинского алфавита. При обучении сети Хопфилда (3) распознаванию трех первых букв (см. рис. 1 а, б, в), при предъявлении на вход сети любого их эталонов в качестве ответа получается образ, приведенный на рис. 1 г (все образы брались в рамке 10 на 10 точек).
В связи с такими примерами первый вопрос о качестве работы сети ассоциативной памяти звучит тривиально: будет ли сеть правильно обрабатывать сами эталонные образы (т. е. не искажать их)?
Мерой коррелированности образов будем называть следующую величину:
Зависимость работы сети Хопфилда от степени коррелированности образов можно легко продемонстрировать на следующем примере. Пусть даны три эталона x1, x2, x3 таких, что
(4)
Для любой координаты существует одна из четырех возможностей:
В первом случае при предъявлении сети q-го эталона в силу формулы (3) получаем
так как все скалярные произведения положительны по условию (4). Аналогично получаем в четвертом случае x'j = -1.
Во втором случае рассмотрим отдельно три варианта
так как скалярный квадрат любого образа равен n, а сумма двух любых скалярных произведений эталонов больше n, по условию (4). Таким образом, независимо от предъявленного эталона получаем x'j = 1. Аналогично в третьем случае получаем x'j = -1.
Окончательный вывод таков: если эталоны удовлетворяют условиям (4), то при предъявлении любого эталона на выходе всегда будет один образ. Этот образ может быть эталоном или «химерой», составленной, чаще всего, из узнаваемых фрагментов различных эталонов (примером «химеры» может служить образ, приведенный на рис. 1 г). Рассмотренный ранее пример с буквами детально иллюстрирует такую ситуацию.
Приведенные выше соображения позволяют сформулировать требование, детализирующие понятие «слабо коррелированных образов». Для правильного распознавания всех эталонов достаточно (но не необходимо) потребовать, чтобы выполнялось следующее неравенство
Более простое и наглядное, хотя и более сильное условие можно записать в виде
Из этих условий видно, что, чем больше задано эталонов, тем более жесткие требования предъявляются к степени их коррелированности, тем ближе они должны быть к ортогональным.
Рассмотрим преобразование (3) как суперпозицию двух преобразований:
(5)
Обозначим через
— линейное пространство, натянутое на множество эталонов. Тогда первое преобразование в (5) переводит векторы из Rn в L({xi}). Второе преобразование в (5) переводит результат первого преобразования Px в одну из вершин гиперкуба образов. Легко показать, что второе преобразование в (5) переводит точку Px в ближайшую вершину гиперкуба. Действительно, пусть a и b две различные вершины гиперкуба такие, что a — ближайшая к Px, а b = x'.
Из того, что a и b различны следует, что существует множество индексов, в которых координаты векторов a и b различны. Обозначим это множество через I = {i : ai = -bi}. Из второго преобразования в (5) и того, что b = x', следует, что знаки координат вектора Px всегда совпадают со знаками соответствующих координат вектора b. Учитывая различие знаков i-х координат векторов a и Px при i ∈ I можно записать |ai-(Px)i| = |ai|+|(Px)i| = 1+|(Px)i|. Совпадение знаков i-х координат векторов b и Px при i ∈ I позволяет записать следующее неравенство |bi-(Px)i| = ||bi|-|(Px)i| < 1+|(Px)i|. Сравним расстояния от вершин a и b до точки Px
Полученное неравенство противоречит тому, что a — ближайшая к Px. Таким образом, доказано, что второе преобразование в (5) переводит точку Px в ближайшую вершину гиперкуба образов.
Ортогональные сети
Для обеспечения правильного воспроизведения эталонов вне зависимости от степени их коррелированности достаточно потребовать, чтобы первое преобразование в (5) было таким, что xi = Pxi [67]. Очевидно, что если проектор является ортогональным, то это требование выполняется, поскольку x = Px при x ∈L({xi}), а xj ∈L({xi}) по определению множества L({xi}).
Для обеспечения ортогональности проектора воспользуемся дуальным множеством векторов. Множество векторов V({xi}) называется дуальным к множеству векторов {xi}, если все векторы этого множества vj удовлетворяют следующим требованиям:
1. (xi, vi) = ςij; ςij = 0, при i ≠ j; ςij = 1 при i = j;
2. vj ∈L({xi}).
Преобразование
является ортогональным проектором на линейное пространство L({xi}).
Ортогональная сеть ассоциативной памяти преобразует образы по формуле
(6)
Дуальное множество векторов существует тогда и только тогда, когда множество векторов {xi} линейно независимо. Если множество эталонов {xi} линейно зависимо, то исключим из него линейно зависимые образы и будем рассматривать полученное усеченное множество эталонов как основу для построения дуального множества и преобразования (6). Образы, исключенные из исходного множества эталонов, будут по-прежнему сохраняться сетью в исходном виде (преобразовываться в самих себя). Действительно, пусть эталон x является линейно зависимым от остальных m эталонов. Тогда его можно представить в виде
Подставив полученное выражение в преобразование (6) и учитывая свойства дуального множества получим:
(7)
Рассмотрим свойства сети (6) [67]. Во-первых, количество запоминаемых и точно воспроизводимых эталонов не зависит от степени их коррелированности. Во-вторых, формально сеть способна работать без искажений при любом возможном числе эталонов (всего их может быть до 2n). Однако, если число линейно независимых эталонов (т. е. ранг множества эталонов) равно n, сеть становится прозрачной — какой бы образ не предъявили на ее вход, на выходе окажется тот же образ. Действительно, как было показано в (7), все образы, линейно зависимые от эталонов, преобразуются проективной частью преобразования (6) сами в себя. Значит, если в множестве эталонов есть n линейно независимых, то любой образ можно представить в виде линейной комбинации эталонов (точнее n линейно независимых эталонов), а проективная часть преобразования (6) в силу формулы (7) переводит любую линейную комбинацию эталонов в саму себя.
Если число линейно независимых эталонов меньше n, то сеть преобразует поступающий образ, отфильтровывая помехи, ортогональные всем эталонам.
Отметим, что результаты работы сетей (3) и (6) эквивалентны, если все эталоны попарно ортогональны.
Остановимся несколько подробнее на алгоритме вычисления дуального множества векторов. Обозначим через Γ({xi}) матрицу Грама множества векторов {xi}.
Элементы матрицы Грама имеют вид γij = (xi, xj) (ij-ый элемент матрицы Грама равен скалярному произведению i-го эталона на j-ый). Известно, что векторы дуального множества можно записать в следующем виде:
(8)
где γij-1 — элемент матрицы Γ-1({xi}). Поскольку определитель матрицы Грама равен нулю, если множество векторов линейно зависимо, то матрица, обратная к матрице Грама, а следовательно и дуальное множество векторов существует только тогда, когда множество эталонов линейно независимо.
Для работ сети (6) необходимо хранить эталоны и матрицу Γ-1({xi}).
Рассмотрим процедуру добавления нового эталона к сети (6). Эта операция часто называется дообучением сети. Важным критерием оценки алгоритма формирования сети является соотношение вычислительных затрат на обучение и дообучение. Затраты на дообучение не должны зависеть от числа освоенных ранее эталонов.
Для сетей Хопфилда это, очевидно, выполняется — добавление еще одного эталона сводится к прибавлению к функции H одного слагаемого (x, xm+1)², а модификация связей в сети — состоит в прибавлении к весу ij-й связи числа xim+1xjm+1 — всего n² операций.
Для рассматриваемых сетей с ортогональным проектированием также возможно простое дообучение. На первый взгляд, это может показаться странным — если добавляемый эталон линейно независим от старых эталонов, то, вообще говоря, необходимо пересчитать матрицу Грама и обратить ее. Однако симметричность матрицы Грама позволяет не производить заново процедуру обращения всей матрицы. Действительно, обозначим через Gm — матрицу Грама для множества из m векторов; через Em — единичную матрицу размерности m×m. При обращении матриц методом Гаусса используется следующая процедура:
1 .Запишем матрицу размерности m×2m следующего вида: (Gm|Em).
2. Используя операции сложения строк и умножения строки на ненулевое число преобразуем левую квадратную подматрицу к единичной. В результате получим (Em|Gm-1). Пусть известна Gm-1 — обратная к матрице Грама для множества из m векторов xi. Добавим к этому множеству вектор xm+1. Тогда матрица для обращения матрицы Gm+1 методом Гауса будет иметь вид:
После приведения к единичной матрице главного минора ранга m получится следующая матрица:
где bi — неизвестные величины, полученные в ходе приведения главного минора к единичной матрице. Для завершения обращения матрицы Gm+1 необходимо привести к нулевому виду первые m элементов последней строки и (m +1)-го столбца. Для обращения в ноль i-го элемента последней строки необходимо умножить i-ю строку на (x, xm+1) и вычесть из последней строки. После проведения этого преобразования получим
где , .
b0 = 0 только если новый эталон является линейной комбинацией первых m эталонов. Следовательно b0 ≠ 0. Для завершения обращения необходимо разделить последнюю строку на b0 и затем вычесть из всех предыдущих строк последнюю, умноженную на соответствующее номеру строки bi. В результате получим следующую матрицу
где Fij = Gmij-1-bicj/b0. Поскольку матрица, обратная к симметричной, всегда симметрична получаем ci/b0 = -bi/b0 при всех i. Так как b0 ≠ 0 следовательно bi = -ci.
Обозначим через d вектор ((x1, xm+1), …, (xm, xm+1)), через b — вектор (b1, …, bm). Используя эти обозначения можно записать b = Gm-1d, b0 = (xm+1,xm+1)-(d,b), b0 = (xm+1,xm+1)-(d,b). Матрица Gm+1-1 записывается в виде
Таким образом, при добавлении нового эталона требуется произвести следующие операции:
1. Вычислить вектор d (m скалярных произведений — mn операций, mn≤n²).
2. Вычислить вектор b (умножение вектора на матрицу — m² операций).
3. Вычислить b0 (два скалярных произведения — m+n операций).
4. Умножить матрицу на число и добавить тензорное произведение вектора b на себя (2m² операций).
5. Записать Gm+1-1.
Таким образом эта процедура требует m+n+mn+3m² операций. Тогда как стандартная схема полного пересчета потребует:
1. Вычислить всю матрицу Грама (nm(m+1)/2 операций).
2. Методом Гаусса привести левую квадратную матрицу к единичному виду (2m³+m²-m операций).
3. Записать Gm+1-1.
Всего 2m³+m²–m+nm(m+1)/2 операций, что в m раз больше.
Используя ортогональную сеть (6), удалось добиться независимости способности сети к запоминанию и точному воспроизведению эталонов от степени коррелированности эталонов. Так, например, ортогональная сеть смогла правильно воспроизвести все буквы латинского алфавита в написании, приведенном на рис. 1.
Основным ограничением сети (6) является малое число эталонов — число линейно независимых эталонов должно быть меньше размерности системы n.
Тензорные сети
Для увеличения числа линейно независимых эталонов, не приводящих к прозрачности сети, используется прием перехода к тензорным или многочастичным сетям [75, 86, 93, 293].
В тензорных сетях используются тензорные степени векторов. k-ой тензорной степенью вектора x будем называть тензор x⊗k, полученный как тензорное произведение k векторов x.
Поскольку в данной работе тензоры используются только как элементы векторного пространства, далее будем использовать термин вектор вместо тензор. Вектор x⊗k является nk-мерным вектором. Однако пространство L({x⊗k}) имеет размерность, не превышающую величину , где — число сочетаний из p по q. Обозначим через {x⊗k} множество k-х тензорных степеней всех возможных образов.
Теорема. При k<n в множестве {x⊗k} линейно независимыми являются векторов. Доказательство теоремы приведено в последнем разделе данной главы.
Небольшая модернизация треугольника Паскаля, позволяет легко вычислять эту величину. На рис. 2 приведен «тензорный» треугольник Паскаля. При его построении использованы следующие правила:
1. Первая строка содержит двойку, поскольку при n= 2 в множестве X всего два неколлинеарных вектора.
2. При переходе к новой строке, первый элемент получается добавлением единицы к первому элементу предыдущей строки, второй — как сумма первого и второго элементов предыдущей строки, третий — как сумма второго и третьего элементов и т. д. Последний элемент получается удвоением последнего элемента предыдущей строки.
Рис. 2. “Тензорный” треугольник Паскаля
В табл. 1 приведено сравнение трех оценок информационной емкости тензорных сетей для некоторых значений n и k. Первая оценка — nk — заведомо завышена, вторая — — дается формулой Эйлера для размерности пространства симметричных тензоров и третья — точное значение.
Таблица 1.
Как легко видеть из таблицы, уточнение при переходе к оценке rn,k является весьма существенным. С другой стороны, предельная информационная емкость тензорной сети (число правильно воспроизводимых образов) может существенно превышать число нейронов, например, для 10 нейронов тензорная сеть валентности 8 имеет предельную информационную емкость 511.
Легко показать, что если множество векторов {xi} не содержит противоположно направленных, то размерность пространства L({x⊗k}) равна числу векторов в множестве {xi}.
Сеть (2) для случая тензорных сетей имеет вид
(9)
а ортогональная тензорная сеть
(10)
где rij-1 — элемент матрицы Γ-1({x⊗k}).
Рассмотрим, как изменяется степень коррелированности эталонов при переходе к тензорным сетям (9)
Таким образом, при использовании сетей (9) сильно снижается ограничение на степень коррелированности эталонов. Для эталонов, приведенных на рис. 1, данные о степени коррелированности эталонов для нескольких тензорных степеней приведены в табл. 2.
Таблица 2. Степени коррелированности эталонов, приведенных на рис. 1, для различных тензорных степеней.
Тензорная степень Степень коррелированности Условия CAB CAC CBC CAB+CAC CAB+CBC CAC+CBC 1 0.74 0.72 0.86 1.46 1.60 1.58 2 0.55 0.52 0.74 1.07 1.29 1.26 3 0.41 0.37 0.64 0.78 1.05 1.01 4 0.30 0.26 0.55 0.56 0.85 0.81 5 0.22 0.19 0.47 0.41 0.69 0.66 6 0.16 0.14 0.40 0.30 0.56 0.54 7 0.12 0.10 0.35 0.22 0.47 0.45 8 0.09 0.07 0.30 0.16 0.39 0.37Анализ данных, приведенных в табл. 2, показывает, что при тензорных степенях 1, 2 и 3 степень коррелированности эталонов не удовлетворяет первому из достаточных условий (), а при степенях меньше 8 — второму ().
Таким образом, чем выше тензорная степень сети (9), тем слабее становится ограничение на степень коррелированности эталонов. Сеть (10) не чувствительна к степени коррелированности эталонов.
Сети для инвариантной обработки изображений
Для того, чтобы при обработке переводить визуальные образов, отличающиеся только положением в рамке изображения, в один эталон, применяется следующий прием [91]. Преобразуем исходное изображение в некоторый вектор величин, не изменяющихся при сдвиге (вектор инвариантов). Простейший набор инвариантов дают автокорреляторы — скалярные произведения образа на сдвинутый образ, рассматриваемые как функции вектора сдвига.
В качестве примера рассмотрим вычисление сдвигового автокоррелятора для черно-белых изображений. Пусть дан двумерный образ S размером p×q=n. Обозначим точки образа как sij. Элементами автокоррелятора Ac(S) будут величины , где sij=0 при выполнении любого из неравенств i < 1, i > p, j < 1, j > q. Легко проверить, что автокорреляторы любых двух образов, отличающихся только расположением в рамке, совпадают. Отметим, что aij=a-i,-j при всех i,j, и aij=0 при выполнении любого из неравенств i < 1-p, i > p-1, j < 1-q, j > q-1. Таким образом, можно считать, что размер автокоррелятора равен p×(2q+1).
Автокорреляторная сеть имеет вид
(11)
Сеть (11) позволяет обрабатывать различные визуальные образы, отличающиеся только положением в рамке, как один образ.
Конструирование сетей под задачу
Подводя итоги, можно сказать, что все сети ассоциативной памяти типа (2) можно получить, комбинируя следующие преобразования:
1. Произвольное преобразование. Например, переход к автокорреляторам, позволяющий объединять в один выходной образ все образы, отличающиеся только положением в рамке.
2. Тензорное преобразование, позволяющее сильно увеличить способность сети запоминать и точно воспроизводить эталоны.
3. Переход к ортогональному проектору, снимающий зависимость надежности работы сети от степени коррелированности образов.
Наиболее сложная сеть будет иметь вид:
(12)
где rij-1 — элементы матрицы, обратной матрице Грама системы векторов {F(xi)}⊗k, F(x) — произвольное преобразование.
Возможно применение и других методов предобработки. Некоторые из них рассмотрены в работах [68, 91, 278]
Численный эксперимент
Работа ортогональных тензорных сетей при наличии помех сравнивалась с возможностями линейных кодов, исправляющих ошибки. Линейным кодом, исправляющим k ошибок, называется линейное подпространство в n-мерном пространстве над GF2, все вектора которого удалены друг от друга не менее чем на 2k+1. Линейный код называется совершенным, если для любого вектора n-мерного пространства существует кодовый вектор, удаленный от данного не более, чем на k. Тензорной сети в качестве эталонов подавались все кодовые векторы избранного для сравнения кода. Численные эксперименты с совершенными кодами показали, что тензорная сеть минимально необходимой валентности правильно декодирует все векторы. Для несовершенных кодов картина оказалась хуже — среди устойчивых образов тензорной сети появились «химеры» — векторы, не принадлежащие множеству эталонов.
Таблица 3. Результаты численного эксперимента. МР — минимальное расстояние между эталонами, ЧЭ — число эталонов
№ Размерность Число векторов МР ЧЭ Валентность Число химер Число ответов После обработки сетью расстояние до правильного ответа стало верн. неверн. меньше то же больше 1 10 1024 3 64 3,5 896 128 896 0 856 0 2 7,21 384 640 384 0 348 0 3 10 1024 5 8 3 260 464 560 240 260 60 4 5,15 230 494 530 240 230 60 5 17,21 140 532 492 240 182 70 6 15 32768 7 32 3 15456 17312 15456 0 15465 0 7 5,21 14336 18432 14336 0 14336 0В случае n=10, k=1 (см. табл. 3 и 4, строка 1) при валентностях 3 и 5 тензорная сеть работала как единичный оператор — все входные вектора передавались на выход сети без изменений. Однако уже при валентности 7 число химер резко сократилось и сеть правильно декодировала более 60% сигналов. При этом были правильно декодированы все векторы, удаленные от ближайшего эталона на расстояние 2, а часть векторов, удаленных от ближайшего эталона на расстояние 1, остались химерами. В случае n=10, k=2 (см. табл. 3 и 4, строки 3, 4, 5) наблюдалось уменьшение числа химер с ростом валентности, однако часть химер, удаленных от ближайшего эталона на расстояние 2 сохранялась. Сеть правильно декодировала более 50% сигналов. Таким образом при малых размерностях и кодах, далеких от совершенных, тензорная сеть работает довольно плохо. Однако, уже при n=15, k=3 и валентности, большей 3 (см. табл. 3 и 4, строки 6, 7), сеть правильно декодировала все сигналы с тремя ошибками. В большинстве экспериментов число эталонов было больше числа нейронов.
Таблица 4. Результаты численного эксперимента
№ Число химер, удаленных от ближайшего эталона на: Число неверно распознанных векторов, удаленных от ближайшего эталона на: 1 2 3 4 5 1 2 3 4 5 1 640 256 0 0 0 896 0 0 0 0 2 384 0 0 0 0 384 0 0 0 0 3 0 210 50 0 0 0 210 290 60 0 4 0 180 50 0 0 0 180 290 60 0 5 0 88 50 2 0 0 156 290 60 0 6 0 0 1120 13440 896 0 0 1120 13440 896 7 0 0 0 13440 896 0 0 0 13440 896Подводя итог можно сказать, что качество работы сети возрастает с ростом размерности пространства и валентности и по эффективности устранения ошибок сеть приближается к коду, гарантированно исправляющему ошибки.
Доказательство теоремы
В данном разделе приведено доказательство теоремы о числе линейно независимых образов в пространстве k-х тензорных степеней эталонов.
При построении тензорных сетей используются тензоры валентности k следующего вида:
(13)
где aj — n-мерные вектора над полем действительных чисел.
Если все вектора ai=a, то будем говорить о k-й тензорной степени вектора a, и использовать обозначение a⊗k. Для дальнейшего важны следующие элементарные свойства тензоров вида (13).
1. Пусть и , тогда скалярное произведение этих векторов может быть вычислено по формуле
(14)
Доказательство этого свойства следует непосредственно из свойств тензоров общего вида.
2. Если в условиях свойства 1 вектора являются тензорными степенями, то скалярное произведение имеет вид:
(15)
Доказательство непосредственно вытекает из свойства 1.
3. Если вектора a и b ортогональны, то есть (a,b) = 0, то и их тензорные степени любой положительной валентности ортогональны.
Доказательство вытекает из свойства 2.
4. Если вектора a и b коллинеарны, то есть b = λa, то a⊗k=λka⊗k.
Следствие. Если множество векторов содержит хотя бы одну пару противоположно направленных векторов, то система векторов будет линейно зависимой при любой валентности k.
5. Применение к множеству векторов невырожденного линейного преобразования B в пространстве Rn эквивалентно применению к множеству векторов линейного невырожденного преобразования, индуцированного преобразованием B, в пространстве .
Сюръективным мультииндексом α(L) над конечным множеством L назовем k-мерный вектор, обладающий следующими свойствами:
1. для любого iL существует j∈{1, …, k} такое, что αj=i;
2. для любого j∈{1, …, k} существует i∈L такое, что αj=i.
Обозначим через d(α(L),i) число компонент сюръективного мультииндекса α(L) равных i, через |L| — число элементов множества L, а через Α(L) — множество всех сюръективных мультииндексов над множеством L.
Предложение 1. Если вектор a представлен в виде , где βi — произвольные действительные коэффициенты, то верно следующее равенство
(16)
Доказательство предложения получается возведением в тензорную степень k и раскрытием скобок с учетом линейности операции тензорного умножения.
В множестве , выберем множество X следующим образом: возьмем все (n-1)-мерные вектора с координатами ±1, а в качестве n-й координаты во всех векторах возьмем единицу.
Предложение 2. Множество x является максимальным множеством n-мерных векторов с координатами равными ±1 и не содержит пар противоположно направленных векторов.
Доказательство. Из равенства единице последней координаты всех векторов множества X следует отсутствие пар противоположно направленных векторов. Пусть x — вектор с координатами ±1, не входящий в множество X, следовательно последняя координата вектора x равна минус единице. Так как в множество X включались все (n-1) — мерные вектора с координатами ±1, то среди них найдется вектор, первые n-1 координата которого равны соответствующим координатам вектора x со знаком минус. Поскольку последние координаты также имеют противоположные знаки, то в множестве X нашелся вектор противоположно направленный по отношению к вектору x. Таким образом множество X максимально.
Таким образом в множестве X содержится ровно 2n-1 вектор. Каждый вектор x∈X можно представить в виде , где I⊂{1, …, n-1}. Для нумерации векторов множества X будем использовать мультииндекс I. Обозначим через |I| число элементов в мультииндексе I. Используя введенные обозначения можно разбить множество X на n непересекающихся подмножеств: Pi = {xI, |I|=i}, .
Теорема. При k<n в множестве {x⊗k} линейно независимыми являются
векторов.
Для доказательства этой теоремы потребуется следующая интуитивно очевидная, но не встреченная в литературе лемма.
Лемма. Пусть дана последовательность векторов
a1,a2=a¹2+a²2,a3=a¹3+a²3,…,am=a¹m+a²m
таких, что (ai,a²j)=0 при всех i<j и (a¹i,a²i)=0, a²i≠0 при всех i, тогда все вектора множества {ai} линейно независимы.
Доказательство. Известно, что процедура ортогонализации Грама приводит к построению ортонормированного множества векторов, а все вектора линейно зависящие от предыдущих векторов последовательности обращаются в нулевые. Проведем процедуру ортогонализации для заданной последовательности векторов.
1. b1=a1/||a1||
2. b2=(a2-(a2,b2))/||a2-(a2,b1)b1||. Причем a2-(a2,b1)b1 ≠ 0, так как (a1, a²2)=0, (a¹2-((a2,b1)b1,a²2)=0 и a²2≠0.
…
j.
Причем , так как (ai, a²j)=0, при всех i<j,
и a²j≠0.
…
Доказательство теоремы. Произведем линейное преобразование векторов множества x с матрицей
Легко заметить, что при этом преобразовании все единичные координаты переходят в единичные, а координаты со значением –1 в нулевые. Таким образом .
По пятому свойству заключаем, что число линейно независимых векторов в множествах X и Y совпадает. Пусть 1≤m≤k. Докажем, что yI⊗k при |I|=m содержит компоненту, ортогональную всем yJ⊗k, |J|≤m, J≠I.
Из предложения 1 имеем
(17)
Представим (17) в виде двух слагаемых:
(18)
Обозначим первую сумму в (18) через yI0⊗k. Докажем, что yI0⊗k ортогонален ко всем yJ⊗k, |J|≤m, J≠I, и второй сумме в (18). Так как I≠J, I⊄J, существует q∈I, q∉J.
Из свойств сюръективного мультииндекса следует, что все слагаемые, входящие в yI0⊗k содержат в качестве тензорного сомножителя eq, не входящий ни в одно тензорное произведение, составляющие в сумме yJ⊗k. Из свойства 2 получаем, что (yJ⊗k, yI0⊗k) = 0. Аналогично, из того, что в каждом слагаемом второй суммы L≠I, I⊄L следует ортогональность yI0⊗k каждому слагаемому второй суммы в (18) и, следовательно, всей сумме.
Таким образом yI⊗k содержит компоненту yI0⊗k ортогональную ко всем yJ⊗k, |J|≤m, J≠I и (yJ⊗k-yI0⊗k). Множество тензоров Yk={yI⊗k, |I|≤k} удовлетворяет условиям леммы, и следовательно все тензоры в Yk линейно независимы. Таким образом, число линейно независимых тензоров в множестве не меньше чем
Для того, чтобы показать, что число линейно независимых тензоров в множестве {x⊗k} не превосходит этой величины достаточно показать, что добавление любого тензора из Y к Yk приводит к появлению линейной зависимости. Покажем, что любой yI⊗k при |I|>k может быть представлен в виде линейной комбинации тензоров из Yk. Ранее было показано, что любой тензор yI⊗k может быть представлен в виде (17). Разобьем (17) на три суммы:
(19)
Рассмотрим первое слагаемое в (19) отдельно.
Заменим в последнем равенстве внутреннюю сумму в первом слагаемом на тензоры из Yk:
(20)
Преобразуем второе слагаемое в (19).
(21)
Преобразуя аналогично (21) второе слагаемое в (20) и подставив результаты преобразований в (19) получим
(22)
В (22) все не замененные на тензоры из Yk слагаемые содержат суммы по подмножествам множеств мощностью меньше k. Проводя аналогичную замену получим выражение, содержащее суммы по подмножествам множеств мощностью меньше k-1 и так далее. После завершения процедуры в выражении останутся только суммы содержащие вектора из Yk, то есть yI⊗k будет представлен в виде линейной комбинации векторов из Yk. Теорема доказана.
(обратно) (обратно)Лекция 7.1. Двойственные сети
Начиная с этой лекции и до конца курса будем рассматривать сети, решающие задачу аппроксимации функции.
Многолетние усилия многих исследовательских групп привели к тому, что к настоящему моменту накоплено большое число различных «правил обучения» и архитектур нейронных сетей, способов оценивать и интерпретировать их работу, приемов использования нейронных сетей для решения прикладных задач.
До сих пор эти правила, архитектуры, системы оценки и интерпретации, приемы использования и другие интеллектуальные находки существуют в виде «зоопарка» сетей. Каждая сеть из нейросетевого зоопарка имеет свою архитектуру, правило обучения и решает конкретный набор задач, аналогично тому, как каждое животное в обычном зоопарке имеет свои голову, лапы, хвост и питается определенной пищей. В данном курсе проводится систематизация «зоопарка» и превращение его в «технопарк». То есть переход от разнообразия организмов к разнообразию деталей — это и эффективнее, и экономнее. Процесс накопления зоопарка и последующего преобразования его в технопарк вполне закономерен при возникновении всего нового. Хорошим примером может послужить процесс развития персональных компьютеров. В семидесятых годах, когда они только появились, происходил процесс накопления зоопарка. В то время существовало множество абсолютно несовместимых друг с другом персональных компьютеров (IBM PC, Apple, PDP, HP и др.). В восьмидесятых и начале девяностых годов происходил процесс систематизации и преобразования зоопарка персональных компьютеров в технопарк. Сейчас, придя в хороший магазин, торгующий компьютерами, вы можете из имеющейся в наличии комплектации собрать такой персональный компьютер, какой вам нужен. Вы можете сами выбрать процессор, память, принтер, аудио и видео карты и т. д.
Для представления всего разнообразия нейрокомпьютеров в виде небольшого набора деталей полезен такой подход: каждая нейронная сеть из зоопарка должна быть представлена как реализованная на идеальном нейрокомпьютере, имеющем заданную структуру. В пределах данной структуры вы можете сами выбирать комплектующие — архитектуру сети, предобработчик, интерпретатор ответа и другие компоненты. Несомненно, структура этого идеального нейрокомпьютера со временем будет эволюционировать. Однако преимущества даже от первых шагов стандартизации несомненны.
Эта глава посвящена выделению функциональных компонентов, составляющих универсальный нейрокомпьютер. Основные компоненты нейрокомпьютера выделяются по следующим признакам:
1. Относительная функциональная обособленность: каждый компонент имеет четкий набор функций. Его взаимодействие с другими компонентами может быть описано в виде небольшого числа запросов.
2. Возможность реализации большинства используемых алгоритмов.
3. Возможность взаимозамены различных реализаций любого компонента без изменения других компонентов.
Однако, прежде чем приступать к выделению компонент, опишем рассматриваемый набор нейронных сетей и процесс их обучения.
(обратно)Краткий обзор нейронных сетей
Можно по разному описывать «зоопарк» нейронных сетей. Приведем классификацию нейронных сетей по решаемым ими задачам.
1. Классификация без учителя или поиск закономерностей в данных. Наиболее известным представителем этого класса сетей является сеть Кохонена, реализующая простейший вариант решения этой задачи. Наиболее общий вариант решения этой задачи известен как метод динамических ядер [224, 262].
2. Ассоциативная память. Наиболее известный представитель — сети Хопфилда. Эта задача также позволяет строить обобщения. Наиболее общий вариант описан в [78–80].
3. Аппроксимация функций, заданных в конечном числе точек. К сетям, решающим эту задачу, относятся персептроны, сети обратного распространения ошибки.
В центре нашего внимания будут сети, предназначенные для решения третьей задачи, однако предложенная структура нейрокомпьютера позволяет описать любую сеть. Конечно, невозможно использовать учитель, предназначенный для построения ассоциативной памяти, для решения задачи классификации без учителя и наоборот.
Среди сетей, аппроксимирующих функции, необходимо выделить еще два типа сетей — с дифференцируемой и пороговой характеристической функцией. Дифференцируемой будем называть сеть, каждый элемент которой реализует непрерывно дифференцируемую функцию. Вообще говоря, альтернативой дифференцируемой сети является недифференцируемая, а не пороговая, но на практике, как правило, все недифференцируемые сети являются пороговыми. Отметим, что для того, чтобы сеть была пороговой, достаточно вставить в нее один пороговый элемент.
Основное различие между дифференцируемыми и пороговыми сетями состоит в способе обучения. Для дифференцируемых сетей есть конструктивная процедура обучения, гарантирующая результат, если архитектура сети позволяет ей решит задачу (см. разд. «Оценка способности сети решить задачу» — метод двойственного обучения (обратного распространения ошибки). Следует заметить, что при использовании обучения по методу двойственности так же возникают сложности, типа локальных минимумов. Однако существует набор регулярных процедур, позволяющих с ними бороться (см. [91]). Для обучения пороговых сетей используют правило Хебба или его модификации. Однако, для многослойных сетей с пороговыми элементами правило Хебба не гарантирует обучения. (В случае однослойных сетей — персептронов, доказана теорема о достижении результата в случае его принципиальной достижимости). С другой стороны, в работе [146] доказано, что многослойные сети с пороговыми нейронами можно заменить эквивалентными двухслойными сетями с необучаемыми весами первого слоя.
Выделение компонентов
Первым основным компонентом нейрокомпьютера является нейронная сеть. Относительно архитектуры сети принцип двойственности предполагает только одно — все элементы сети реализуют при прямом функционировании характеристические функции из класса C1(E) (непрерывно дифференцируемые на области определения E, которой, как правило, является вся числовая ось).
Для обучения нейронной сети необходимо наличие задачника. Однако чаще всего, обучение производится не по всему задачнику, а по некоторой его части. Ту часть задачника, по которой в данный момент производится обучение, будем называть обучающей выборкой. Для многих задач обучающая выборка имеет большие размеры (от нескольких сот до нескольких десятков тысяч примеров). При обучении с использованием скоростных методов обучения (их скорость на три-четыре порядка превышает скорость обучения по классическому методу обратного распространения ошибки) приходится быстро сменять примеры. Таким образом, скорость обработки обучающей выборки может существенно влиять на скорость обучения нейрокомпьютера. К сожалению, большинство разработчиков аппаратных средств не предусматривает средств для быстрой смены примеров. Таким образом, задачник выделен в отдельный компонент нейрокомпьютера.
При работе с обучающей выборкой удобно использовать привычный для пользователя формат данных. Однако, этот формат чаще всего непригоден для использования нейросетью. Таким образом, между обучающей выборкой и нейросетью возникает дополнительный компонент нейрокомпьютера — предобработчик. Из литературных источников следует, что разработка эффективных предобработчиков для нейрокомпьютеров является новой, почти совсем не исследованной областью. Большинство разработчиков программного обеспечения для нейрокомпьютеров склонно возлагать функции предобработки входных данных на обучающую выборку или вообще перекладывают ее на пользователя. Это решение технологически неверно. Дело в том, что при постановке задачи для нейрокомпьютера трудно сразу угадать правильный способ предобработки. Для его подбора проводится серия экспериментов. В каждом из экспериментов используется одна и та же обучающая выборка и разные способы предобработки входных данных сети. Таким образом, выделен третий важный компонент нейрокомпьютера — предобработчик входных данных.
Заметим, что если привычный для человека способ представления входных данных непригоден для нейронной сети, то и формат ответов нейронной сети часто малопригоден для человека. Необходимо интерпретировать ответы нейронной сети. Интерпретация зависит от вида ответа. Так, если ответом нейронной сети является действительное число, то его, как правило, приходится масштабировать и сдвигать для попадания в нужный диапазон ответов. Если сеть используется как классификатор, то выбор интерпретаторов еще шире. Большое разнообразие интерпретаторов при невозможности решить раз и навсегда вопрос о преимуществах одного из них над другими приводит к необходимости выделения интерпретатора ответа нейронной сети в отдельный компонент нейрокомпьютера.
С интерпретатором ответа тесно связан еще один обязательный компонент нейрокомпьютера — оценка. Невнимание к этому компоненту вызвано практикой рассматривать метод обратного распространения ошибки в виде алгоритма. Доминирование такой точки зрения привело к тому, что, судя по публикациям, большинство исследователей даже не подозревает о том, что «уклонение от правильного ответа», подаваемое на вход сети при обратном функционировании, есть ни что иное, как производная функции оценки по выходному сигналу сети (если функция оценки является суммой квадратов уклонений). Возможно (и иногда очень полезно) конструировать другие оценки (см. главу «Оценка и интерпретатор ответа»). Нашей группой в ходе численных экспериментов было выяснено, что для обучения сетей-классификаторов функция оценки вида суммы квадратов, пожалуй, наиболее плоха. Использование альтернативных функций оценки позволяет в несколько раз ускорить обучение нейронной сети.
Шестым необходимым компонентом нейрокомпьютера является учитель. Этот компонент может меть множество реализаций. Обзор наиболее часто употребляемых и наиболее эффективных учителей приводится в главе «Учитель».
Принцип относительной функциональной обособленности требует выделения еще одного компонента, названного исполнителем запросов учителя или просто исполнителем. Назначение этого компонента не так очевидно, как всех предыдущих. Заметим, что для всех учителей, обучающих сети по методу обратного распространения ошибки, и при тестировании сети характерен следующий набор операций с каждым примером обучающей выборки:
1. Тестирование решения примера
1. Взять пример у задачника.
2. Предъявить его сети для решения.
3. Предъявить результат интерпретатору ответа.
2. Оценивание решения примера
1. Взять пример у задачника.
2. Предъявить его сети для решения.
3. Предъявить результат оценке.
3. Оценивание решения примера с вычислением градиента.
1. Взять пример у задачника.
2. Предъявить его сети для решения.
3. Предъявить результат оценке с вычислением производных.
4. Предъявить результат работы оценки сети для вычисления градиента.
4. Оценивание и тестирование решения примера.
1. Взять пример у задачника.
2. Предъявить его сети для решения.
3. Предъявить результат оценке.
4. Предъявить результат интерпретатору ответа.
Заметим, что все четыре варианта работы с сетью, задачником, интерпретатором ответа и оценкой легко объединить в один запрос, параметры которого позволяют указать последовательность действий. Таким образом, исполнитель исполняет всего один запрос — обработать пример. Однако выделение этого компонента позволяет исключить необходимость в прямых связях таких компонентов, как контрастер и учитель, с компонентами оценка и интерпретатор ответа, а их взаимодействие с компонентом сеть свести исключительно к запросам связанным с модификацией обучаемых параметров сети.
Последним компонентом, которого необходимо выделить, является контрастер нейронной сети. Этот компонент является надстройкой над учителем. Его назначение — сводить число связей сети до минимально необходимого или до «разумного» минимума (степень разумности минимума определяется пользователем). Кроме того, контрастер, как правило, позволяет свести множество величин весов связей к 2–4, реже к 8 выделенным пользователем значениям. Наиболее важным следствием применения процедуры контрастирования является получение логически прозрачных сетей — сетей, работу которых легко описать и понять на языке логики [76, 83].
Для координации работы всех компонент нейрокомпьютера вводится макрокомпонента Нейрокомпьютер. Основная задача этого компонента — организация интерфейса с пользователем и координация действий всех остальных компонентов.
Запросы компонентов нейрокомпьютера
В этом разделе приводится основной список запросов, которые обеспечивают функционирование нейрокомпьютера. За редким исключением приводятся только запросы, которые генерируются компонентами нейрокомпьютера (некоторые из этих запросов могут поступать в нейрокомпьютер от пользователя). Здесь рассматривается только форма запроса и его смысл. Полный список запросов каждого компонента, детали их исполнения и форматы данных рассматриваются в соответствующих разделах приложения 3.
На рис. 1. приведена схема запросов в нейрокомпьютере. При построении схемы предполагается, что на каждый запрос приходит ответ. Вид ответа описан при описании запросов. Стрелки, изображающие запросы, идут от объекта, инициирующего запрос, к объекту его исполняющему.
Рис 1. Схема запросов в нейрокомпьютере
Запросы к задачнику
Запросы к задачнику позволяют последовательно перебирать все примеры обучающей выборки, обращаться непосредственно к любому примеру задачника и изменять обучающую выборку. Обучающая выборка выделяется путем «раскрашивания» примеров задачника в различные «цвета». Понятие цвета и способ работы с цветами описаны в разделе «Переменные типа цвет и операции с цветами».
Запросы последовательного перебора обучающей выборки:
«Инициировать выдачу примеров цвета К». По этому запросу происходит инициация выдачи примеров К-го цвета.
«Дать очередной пример». По этому запросу задачник возвращает предобработанные данные очередного примера и, при необходимости, правильные ответы, уровень достоверности и другие данные этого примера.
«Следующий пример». По этому запросу задачник переходит к следующему примеру обучающей выборки. Если такого примера нет, то возвращается признак отсутствия очередного примера.
Для непосредственного доступа к примерам задачника служит запрос «Дать пример номер N». Действия задачника в этом случае аналогичны выполнению запроса «Дать очередной пример».
Для изменения обучающей выборки служит запрос «Окрасить примеры в цвет К». Этот запрос используется редко, поскольку изменение обучающей выборки, как правило, осуществляется пользователем при редактировании задачника.
Запрос к предобработчику
Предобработчик сам никаких запросов не генерирует. Единственный запрос к предобработчику — «Предобработать пример» может быть выдан только задачником.
Запрос к исполнителю
«Обработать очередной пример». Вид ответа зависит от параметров запроса.
Запросы к учителю
«Начать обучение сети». По этому запросу учитель начинает процесс обучения сети.
«Прервать обучение сети». Этот запрос приводит к прекращению процесса обучения сети. Этот запрос требуется в случае необходимости остановить обучение сети до того, как будет удовлетворен критерий остановки обучения, предусмотренный в учителе.
«Провести N шагов обучения» — как правило, выдается контрастером, необходим для накопления показателей чувствительности.
Запрос к контрастеру
«Отконтрастировать сеть». Ответом является код завершения операции контрастирования.
Запрос к оценке
Оценка не генерирует никаких запросов. Она выполняет только один запрос — «Оценить пример». Результатом выполнения запроса является оценка примера и, при необходимости, вектор производных оценки по выходным сигналам сети.
Запрос к интерпретатору ответа
Интерпретатор ответа не генерирует никаких запросов. Он выполняет только один запрос — «Интерпретировать ответ». Ответом является результат интерпретации.
Запросы к сети
Сеть не генерирует никаких запросов. Набор исполняемых сетью запросов можно разбить на три группы.
Запрос, обеспечивающий тестирование.
«Провести прямое функционирование». На вход сети подаются данные примера. На выходе сети вычисляется ответ сети, подлежащий оцениванию или интерпретации.
Запросы, обеспечивающие обучение сети.
«Обнулить градиент». При исполнении этого запроса градиент оценки по обучаемым параметрам сети кладется равным нулю. Этот запрос необходим, поскольку при вычислении градиента по очередному примеру сеть добавляет его к ранее вычисленному градиенту по сумме других примеров.
«Вычислить градиент по примеру». Проводится обратное функционирование сети. Вычисленный градиент добавляется к ранее вычисленному градиенту по сумме других примеров.
«Изменить карту с шагами Н1 и H2». Генерируется учителем во время обучения.
Запрос, обеспечивающие контрастирование.
«Изменить карту по образцу». Генерируется контрастером при контрастировании сети.
Таким образом, выделено семь основных компонентов нейрокомпьютера, определены их функции и основные исполняемые ими запросы.
Лекция 7.2. Задачник и обучающее множество
Эта глава посвящена одному из наиболее важных и обделенных вниманием компонентов нейрокомпьютера — задачнику. Важность этого компонента определяется тем, что при обучении сетей всех видов с использованием любых алгоритмов обучения сети необходимо предъявлять примеры, на которых она обучается решению задачи. Источником данных для сети является задачник. Кроме того, задачник содержит правильные ответы для сетей, обучаемых с учителем. Аппаратная реализация этого компонента в общем случае неэффективна.
В этой главе рассматриваются основные структуры и функции компонента задачник. Отметим, что задачник рассматривается только с точки зрения его использования нейронной сетью. Совершенно очевидно, что невозможно предусмотреть всех вариантов интерфейса между пользователем и задачником. Действительно, было бы странно, если бы в одном и том же интерфейсе обрабатывались задачники, содержащие только числовые поля, задачники, содержащие исключительно графическую информацию и задачники смешанного типа.
Структуры данных задачника
С точки зрения нейрокомпьютера задачник представляет собой прямоугольную таблицу, поля которой содержат информацию о входных данных примеров задачи, правильные ответы и другую информацию. На данный момент существует три основных способа хранения однотипных данных — базы данных, электронные таблицы, текстовые файлы. Основными критериями выбора являются удобство в использовании, компактность и универсальность. Поскольку задачник должен хранить однотипные данные и предоставлять их для обработки другим компонентам нейрокомпьютера, а не производить вычисления, то функционально задачник должен являться базой данных. Наиболее подходящим кажется формат табличных (реляционных) баз данных.
В современных операционных системах предусмотрены различные способы обмена данными между приложениями (устройства, передающие информацию с датчиков, так же будем считать приложениями). Наиболее универсальным является обмен в символьном формате. Вопрос конкретной реализации обмена выходит за рамки данной работы, поскольку это чисто технический вопрос. Вне зависимости от того, каким путем и из какого приложения данные попали в задачник, их представление должно быть одинаковым (принятым в данной реализации задачника). То есть, откуда бы не получал данные задачник, остальные компоненты нейрокомпьютера всегда получают данные от задачника в одном и том же виде. Этот вид зафиксирован в приложении при описании стандарта компонента задачник.
Поля задачника
Далее будем полагать, что задачник является реляционной базой данных из одной таблицы или набора параллельных таблиц. Каждому примеру соответствует одна запись базы данных. Каждому данному — одно поле. В данном разделе рассмотрены допустимые типы полей, с точки зрения типа хранящихся в них данных. В разд. «Состав данных задачника» все поля разбиваются по смысловой нагрузке. Все поля базы данных можно разбить на четыре типа — числовые поля, текстовые поля, перечислимые поля и поля типа рисунок.
Числовые поля. Поля числовых типов данных integer, long и real (см. раздел «Стандарт типов данных» в приложении) предназначены для хранения различных чисел. Поля числового типа могут нести любую смысловую нагрузку.
Перечислимые поля. Поля перечислимого типа служат для хранения качественных признаков — полей базы данных, содержащих, как правило, текстовую информацию, но имеющих малое число различных значений. Простейшим примером поля перечислимого типа является поле «пол» — это поле может принимать только два значения — «мужской» или «женский». Поле перечислимого типа не хранит соответствующего текстового значения, вместо него в поле содержится номер значения. Поля перечислимого типа могут быть только входными данными, комментариями или ответами.
Строки (текстовые поля). Поля текстового типа предназначены для хранения тестовой информации. Они могут быть только комментариями.
Рисунок. Поля типа рисунок предназначены для хранения графической информации. В данной работе не устанавливается способ хранения полей типа рисунок. В приложении оговаривается только способ хранения полей типа рисунок на диске для файлов задачника, созданного в нейрокомпьютере. При передаче рисунков предобработчику используется формат, согласованный для предобработчика и задачника.
Состав данных задачника
Компонент задачник является необходимой частью нейрокомпьютера вне зависимости от типа применяемых в нем нейронных сетей. Однако в зависимости от решаемой задачи содержимое задачника может меняться. Так, например, для решения задачи классификации без учителя используют нейросети, основанные на методе динамических ядер [224, 262] (наиболее известным частным случаем таких сетей являются сети Кохонена [131, 132]). Задачник для такой сети должен содержать только массивы входных данных и предобработанных входных данных. При использовании обучаемых сетей, основанных на принципе двойственности, к задачнику необходимо добавить массив ответов сети. Кроме того, некоторые исследователи хотят иметь возможность просмотреть ответы, выданные сетью, массив оценок примера, показатели значимости входных сигналов и, возможно, некоторые другие величины. Поэтому, стандартный задачник должен иметь возможность предоставить пользователю всю необходимую информацию.
Цвет примера и обучающая выборка
Довольно часто при обучении нейронных сетей возникает необходимость использовать в обучении не все примеры задачника, а только часть. Например, такая возможность необходима при использовании метода скользящего контроля для оценки качества обучения сети. Существует несколько способов реализации такой возможности. Кроме того, часто бывает полезно приписать примерам ряд признаков. Так, при просмотре задачника, пользователю полезно видеть степень обученности примера (например, отображать зеленым цветом примеры, которые решаются сетью идеально, желтым — те, которые сеть решает правильно, но не идеально, а красным — те, при решении которых сеть допускает ошибки).
Ту часть задачника, которая в данный момент используется в обучении нейронной сети, будем называть обучающей выборкой. Для выделения из задачника обучающей выборки предлагается использовать механизм «цветов». Если все примеры покрашены в некоторые цвета, то обучающую выборку можно задать, указав цвета примеров, которые необходимо использовать в обучении. В соответствии с предлагаемой схемой, каждый пример покрашен каким-то цветом, а при задании обучающей выборки можно задать комбинацию цветов. Схема работы с цветами детально рассмотрена в разделе «Переменные типа цвет и операции с цветами» приложения.
Выделенную с помощью механизма цветов часть задачника будем далее называть текущей выборкой. Обучающая выборка является частным случаем текущей выборки.
Входные данные
Входные данные — данные, необходимые для решения сетью примера. Входные данные являются массивом. Существует всего несколько видов входных данных. Каждый элемент массива входных данных может быть:
• числом;
• полем с ограниченным числом состояний;
• рисунком.
Комментарии
Пользователю, при работе с задачником, часто бывает необходимо иметь возможность идентифицировать примеры не только по номерам. Например, при работе с медицинскими базами данных полезно иметь поле, содержащее фамилию больного или номер истории болезни. Для этих целей в задачнике может потребоваться хранить массив комментариев, которые не могут быть использованы в обучении. Кроме того, при исключении какого либо входного сигнала из множества входных сигналов, он не исключается из задачника полностью, а переводится в комментарии.
Предобработанные данные
Предобработанные данные — это массив входных сигналов сети, полученный из входных данных после предобработки, выполняемой компонентом предобработчик. Хранение задачником этого массива необязательно. Каждый элемент массива предобработанных данных является действительным числом. Следует отметить, что любая нетривиальная предобработка, как правило, изменяет длину массива.
Правильные ответы
Правильные ответы — массив ответов, которые должна выдать обученная нейронная сеть при решении примера. Этот массив необходим при обучении сетей с учителем. При использовании других видов сетей хранение задачником этого массива необязательно. Элементами массива ответов могут быть как числа, так и поля с ограниченным набором состояний. В первом случае будем говорить о задаче аппроксимации функции, а во втором — о задаче классификации объектов.
Полученные ответы
Полученные ответы — массив ответов, выданных сетью при решении примера. Для задачника хранение этой части примера не обязательно.
Оценки
Оценки — массив оценок, полученных сетью за решение всех подзадач примера (число подзадач равно числу ответов примера). Хранение этого массива задачником не обязательно.
Вес примера
Вес примера — скалярный параметр, позволяющий регулировать интенсивность участия примера в процессе обучения. Для не обучаемых нейронных сетей вес примера может использоваться для учета вклада данных примера в формируемую карту связей. Применение весов примеров зависит от типа используемой сети.
Достоверность ответа
При составлении задачника ответы довольно часто получаются как результат измерения или путем логических выводов в условиях нечеткой информации (например, в медицине). В этих случаях одни ответы имеют большую достоверность, чем другие. Некоторые способы построения оценки или формирования карты связей нейронной сети позволяют использовать эти данные. Достоверность ответа является массивом, поскольку ответ каждой подзадачи данного примера может иметь свою достоверность. Каждый элемент массива достоверностей ответов является действительным числом от нуля до единицы.
Уверенность в ответе
При использовании некоторых видов оценки (см. главу «Оценка и интерпретатор ответа») интерпретатор ответа способен оценить уверенность сети в полученном ответе. Массив коэффициентов уверенности сети в ответах (для каждого ответа свой коэффициент уверенности) может оказаться полезным для пользователя. Каждый элемент массива коэффициентов уверенности в ответе является действительным числом от нуля до единицы.
Рис. 1. Схема данных задачника.
Все перечисленные выше массивы можно разбить на четыре типа по структуре:
• Входные данные. Таких массивов обычно два — массив описания полей данных (содержит описание полей данных: имя поля, его тип и возможно некоторую дополнительную информацию) и собственно массив данных. Причем каждый пример имеет свой массив данных, но массив описания полей данных один для всех примеров задачника. Эти массивы имеют одинаковое число элементов, и их элементы попарно соответствуют друг другу.
• Массив ответов. При обучении с учителем, в задачнике есть, по крайней мере, два массива этого вида — массив описания полей ответов и массив правильных ответов. Кроме того, возможно хранение в задачнике массивов вычисленных ответов, достоверности ответов и уверенности в ответе. Массив описания полей ответов — один для всех примеров задачника. Все остальные массивы данного типа хранятся по одному экземпляру каждого массива на пример.
• Массив комментариев. Таких массивов обычно только два — массив описания полей комментариев и массив комментариев. Массив описания полей комментариев — один на весь задачник, а массив комментариев — один на пример.
На рис. 1 приведено схематическое устройство задачника. Такое представление данных позволяет гибко использовать память. Однако следует учесть, что часть полей может переходить из одного массива в другой. Например, при исключении одного входного данного из использования (см. главу «Контрастер»), соответствующее ему поле переходит из массива входных данных в массив комментариев.
Лекция 8. Предобработчик
Данная глава посвящена компоненту предобработчик. В ней рассматриваются различные аспекты предобработки входных данных для нейронных сетей. Существует множество различных видов нейронных сетей (см. главу «Описание нейронных сетей»). Однако, для большинства нейронных сетей характерно наличие такого интервала входных сигналов, в пределах которого сигналы различимы. Для различных нейронных сетей эти интервалы различны. Большинство работающих с нейронными сетями прекрасно осведомлены об этом их свойстве, но до сих пор не предпринималось никаких попыток как-либо формализовать или унифицировать подходы к предобработке входных сигналов. В данной главе дан один из возможных формализмов этой задачи. За рамками рассмотрения осталась предобработка графической информации. Наиболее мощные и интересные способы предобработки графической информации описаны в [91]. При аппаратной реализации нейрокомпьютера, компонент предобработчик также следует реализовывать аппаратно, поскольку вне зависимости от источника входных данных их надо обрабатывать одинаково. К тому же большинство предобработчиков допускают простую аппаратную реализацию.
В этой главе будут описаны различные виды входных сигналов и способы их предобработки. В качестве примера будут рассмотрены сети с сигмоидными нелинейными преобразователями. Однако, описываемые способы предобработки применимы для сетей с произвольными нелинейными преобразователями. Единственным исключением является раздел «Оценка способности сети решить задачу», который применим только для сетей с нелинейными преобразователями, непрерывно зависящими от своих аргументов.
Наиболее важным в данной являются следующее.
При предобработке качественных признаков не следует вносить недостоверную информацию.
Сформулирована мера сложности нейросетевой задачи.
Выборочная оценка константы Липшица и оценка константы Липшица нейронной сети позволяют легко оценить способность нейронной сети решить поставленную задачу. Эти легко реализуемые процедуры позволяют сэкономить время и силы.
Правильно выбранная предобработка упрощает нейросетевую задачу.
Нейрон
Нейроны, используемые в большинстве нейронных сетей, имеют структуру, приведенную на рис. 1. На рис. 1 использованы следующие обозначения:
x — вектор входных сигналов нейрона;
α — вектор синаптических весов нейрона;
Σ — входной сумматор нейрона;
p = (α,x) — выходной сигнал входного сумматора;
σ — функциональный преобразователь;
y — выходной сигнал нейрона.
Обычно нейронные сети называют по виду функции σ(p). Хорошо известны и наиболее часто используются два вида сигмоидных сетей:
S1: σ(p) = 1/(1+exp(-cp)),
S2: σ(p) = p/(c+|p|),
где c — параметр, называемый «характеристикой нейрона». Обе функции имеют похожие графики.
Каждому типу нейрона соответствует свой интервал приемлемых входных данных. Как правило, этот диапазон либо совпадает с диапазоном выдаваемых выходных сигналов (например для сигмоидных нейронов с функцией S1), либо является объединением диапазона выдаваемых выходных сигналов и отрезка, симметричного ему относительно нуля (например, для сигмоидных нейронов с функцией S2), Этот диапазон будем обозначать как [a,b]
(обратно)Различимость входных данных
Очевидно, что входные данные должны быть различимы. В данном разделе будут приведены соображения, исходя из которых, следует выбирать диапазон входных данных. Пусть одним из входных параметров нейронной сети является температура в градусах Кельвина. Если речь идет о температурах близких к нормальной, то входные сигналы изменяются от 250 до 300 градусов. Пусть сигнал подается прямо на нейрон (синаптический вес равен единице). Выходные сигналы нейронов с различными параметрами приведены в табл. 1.
Таблица 1
Входной сигнал Нейрон типа S1 Нейрон типа S2 c=0.1 c=0.5 c=1 c=2 c=0.1 c=0.5 c=1 c=2 250 1.0 1.0 1.0 1.0 0.99960 0.99800 0.99602 0.99206 275 1.0 1.0 1.0 1.0 0.99964 0.99819 0.99638 0.99278 300 1.0 1.0 1.0 1.0 0.99967 0.99834 0.99668 0.99338Совершенно очевидно, что нейронная сеть просто неспособна научиться надежно различать эти сигналы (если вообще способна научиться их различать!). Если использовать нейроны с входными синапсами, не равными единице, то нейронная сеть сможет отмасштабировать входные сигналы так, чтобы они стали различимы, но при этом будет задействована только часть диапазона приемлемых входных данных — все входные сигналы будут иметь один знак. Кроме того, все подаваемые сигналы будут занимать лишь малую часть этого диапазона. Например, если мы отмасштабируем температуры так, чтобы 300 соответствовала величина суммарного входного сигнала равная 1 (величина входного синапса равна 1/300), то реально подаваемые сигналы займут лишь одну шестую часть интервала [0,1] и одну двенадцатую интервала [-1,1]. Получаемые при этом при этом величины выходных сигналов нейронов приведены в табл. 2.
Таблица 2
Входной сигнал Нейрон типа S1 Нейрон типа S2 c=0.1 c=0.5 c=1 c=2 c=0.1 c=0.5 c=1 c=2 250 (0.83) 0.52074 0.60229 0.69636 0.84024 0.89286 0.62500 0.45455 0.29412 275 (0.91) 0.52273 0.61183 0.71300 0.86057 0.90164 0.64706 0.47826 0.31429 300 (1.0) 0.52498 0.62246 0.73106 0.88080 0.90909 0.66667 0.50000 0.33333Сигналы, приведенные в табл. 2 различаются намного сильнее соответствующих сигналов из табл. 1. Таким образом, необходимо заранее позаботиться о масштабировании и сдвиге сигналов, чтобы максимально полно использовать диапазон приемлемых входных сигналов. Опыт использования нейронных сетей с входными синапсами свидетельствует о том, что в подавляющем большинстве случаев предварительное масштабирование и сдвиг входных сигналов сильно облегчает обучение нейронных сетей. Если заранее произвести операции масштабирования и сдвига входных сигналов, то величины выходных сигналов нейронов даже при отсутствии входных синапсов будут различаться еще сильнее (см. табл. 3).
Таблица 3
Входной сигнал Нейрон типа S1 Нейрон типа S2 c=0.1 c=0.5 c=1 c=2 c=0.1 c=0.5 c=1 c=2 250 (-1) 0.47502 0.37754 0.26894 0.11920 -0.9091 -0.6667 -0.5000 -0.3333 275 (0) 0.50000 0.50000 0.50000 0.50000 0.0000 0.0000 0.0000 0.0000 300 (1) 0.52498 0.62246 0.73106 0.88080 0.9091 0.6667 0.5000 0.3333Величину диапазона различимых входных сигналов можно определять различными способами. На практике в качестве диапазона различимых входных сигналов обычно используется диапазон приемлемых входных данных, исходя из того соображения, что если данные из этого интервала хороши для промежуточных нейронов, то они хороши и для входных.
Другой способ определения различимости входных сигналов приведен в разделе «Оценка способности сети решить задачу».
(обратно)Классификация компонентов входных данных
Информация поступает к нейронной сети в виде набора ответов на некоторый список вопросов. Можно выделить три основных типа ответов (вопросов).
1. Бинарный признак (возможен только один из ответов — истина или ложь).
2. Качественный признак (принимает конечное число значений).
3. Число.
Ответ типа качественный признак — это ответ с конечным числом состояний. Причем нельзя ввести осмысленное расстояние между состояниями. Примером качественного признака может служить состояние больного — тяжелый, средний, легкий. Действительно, нельзя сказать, что расстояние от легкого больного до среднего больше, меньше или равно расстоянию от среднего больного до тяжелого. Все качественные признаки можно в свою очередь разбить на три класса.
1. Упорядоченные признаки.
2. Неупорядоченные признаки.
3. Частично упорядоченные признаки.
Упорядоченным признаком называется такой признак, для любых двух состояний которого можно сказать, что одно из них предшествует другому. Тот факт, что состояние x предшествует состоянию y, будем обозначать следующим образом — x<y. Примером упорядоченного признака может служить состояние больного. Действительно, все состояния можно упорядочить по тяжести заболевания:
легкий больной < средний больной < тяжелый больной
Признак называют неупорядоченным, если никакие два состояния нельзя связать естественным в контексте задачи отношением порядка. Примером неупорядоченного признака может служить ответ на вопрос "Ваш любимый цвет?".
Признак называется частично упорядоченным, если для каждого состояния существует другое состояние, с которым оно связано отношением порядка. Примером частично упорядоченного признака является ответ на вопрос "Какой цвет Вы видите на экране монитора?", преследующий цель определение восприимчивости к интенсивностям основных цветов. Действительно, все множество из шестнадцати состояний разбивается на несколько цепочек:
Черный < Синий < Голубой < Белый;
Черный < Красный < Ярко красный < Белый;
Черный < Зеленый < Ярко зеленый < Белый;
Черный < Фиолетовый < Ярко фиолетовый < Белый
и т. д. Однако, между состояниями Синий и Красный отношения порядка нет.
Известно, что любой частично упорядоченный признак можно представить в виде комбинации нескольких упорядоченных и неупорядоченных признаков. Так, рассмотренный выше частично упорядоченный признак распадается на три упорядоченных признака: интенсивность синего, красного и зеленого цветов. Каждый из этих признаков является упорядоченным (цепочки порядка для этих признаков приведены в первых трех строчках рассмотрения примера). Каждое состояние исходного качественного признака описывается тройкой состояний полученных качественных признаков. Так, например, состояние Фиолетовый описывается в виде (Синий, Красный, Черный).
Исходя из вышесказанного, далее будет рассмотрено только кодирование упорядоченных и неупорядоченных признаков.
Кодирование бинарных признаков
Таблица 4. Кодирование бинарного признака
Смысл значения ложь Значение входного сигнала Истина Ложь Отсутствие заданного свойства при b = 0 a 0 Отсутствие заданного свойства при b ≠ 0 b 0 Наличие другого свойства b aБинарные признаки характеризуются наличием только двух состояний — истина и ложь. Однако даже такие простые данные могут иметь два разных смысла. Значение истина означает наличие у описываемого объекта какого-либо свойства. А ответ ложь может означать либо отсутствие этого свойства, либо наличие другого свойства. В зависимости от смысловой нагрузки значения ложь, и учитывая заданный диапазон [a,b], рекомендуемые способы кодирования бинарного признака приведены в табл. 4.
Кодирование неупорядоченных качественных признаков
Таблица 5. Кодирование неупорядоченного качественного признака
Состояние Вектор входных сигналов α1 (b,a,a,…,a) α2 (a,b,a,…,a) αn (a,a,…,a,b)Поскольку никакие два состояния неупорядоченного признака не связаны отношением порядка, то было бы неразумным кодировать их разными величинами одного входного сигнала нейронной сети. Поэтому, для кодирования качественных признаков рекомендуется использовать столько входных сигналов, сколько состояний у этого качественного признака. Каждый входной сигнал соответствует определенному состоянию. Так если набор всех состояний рассматриваемого признака обозначить через α1, α2, …, αn, то рекомендуемая таблица кодировки имеет вид, приведенный в табл. 5.
Кодирование упорядоченных качественных признаков
Таблица 6. Кодирование упорядоченного качественного признака
Состояние Вектор входных сигналов α1 (b,a,a,…,a) α2 (b,b,a,…,a) αn (b,b,…,b,b)Упорядоченные частные признаки, в отличие от неупорядоченных, имеют отношение порядка между состояниями. Однако кодирование их разными значениями одного входного сигнала неразумно из-за того, что расстояние между состояниями не определено, а такое кодирование эти расстояния задает явным образом. Поэтому, упорядоченные частные признаки рекомендуется кодировать в виде стольких входных сигналов, сколько состояний у признака. Но, в отличие от неупорядоченных признаков, накапливать число сигналов с максимальным значением. Для случая, когда все состояния обозначены через α1 < α2 < … < αn, рекомендуемая таблица кодировки приведена в табл. 6.
Числовые признаки
При предобработке численных сигналов необходимо учитывать содержательное значение признака, расположение значений признака в интервале значений, точность измерения значений признака. Продемонстрируем это на примерах.
Содержательное значение признака. Если входными данными сети является угол между двумя направлениями, например, направление ветра, то ни в коем случае не следует подавать на вход сети значение угла (не важно в градусах или радианах). Такая подача приведет к необходимости «уяснения» сетью того факта, что 0 градусов и 360 градусов одно и тоже. Разумнее выглядит подача в качестве входных данных синуса и косинуса этого угла. Число входных сигналов сети увеличивается, но зато близкие значения признака кодируются близкими входными сигналами.
Точность измерения признака. Так в метеорологии используется всего восемь направлений ветра. Значит, при подаче входного сигнала сети необходимо подавать не угол, а всего лишь информацию о том, в какой из восьми секторов этот угол попадает. Но тогда имеет смысл рассматривать направление ветра не как числовой параметр, а как неупорядоченный качественный признак с восемью состояниями.
Расположение значений признака в интервале значений. Следует рассмотреть вопрос о равнозначности изменения значения признака на некоторую величину в разных частях интервала значений признака. Как правило, это связано с косвенными измерениями (вместо одной величины измеряется другая). Например, сила притяжения двух небесных тел при условии постоянства массы однозначно характеризуется расстоянием между ними. Пусть рассматриваются расстояния от 1 до 100 метров. Легко понять, что при изменении расстояния с 1 до 2 метров, сила притяжения изменится в четыре раза, а при изменении с 99 до 100 метров — в 1.02 раза. Следовательно, вместо подачи расстояния следует подавать обратный квадрат расстояния c'=1/c².
Простейшая предобработка числовых признаков
Как уже отмечалось в разделе «Различимость входных данных» числовые сигналы рекомендуется масштабировать и сдвигать так, чтобы весь диапазон значений попадал в диапазон приемлемых входных сигналов. Эта предобработка проста и задается следующей формулой:
(1)
где [a,b] — диапазон приемлемых входных сигналов, [cmin,cmax] — диапазон значений признака c, c' — предобработанный сигнал, который будет подан на вход сети. Предобработку входного сигнала по формуле (1) будем называть простейшей предобработкой.
Оценка способности сети решить задачу
В данном разделе рассматриваются только сети, все элементы которых непрерывно зависят от своих аргументов (см. главу «Описание нейронных сетей»). Предполагается, что все входные данные предобработаны так, что все входные сигналы сети лежат в диапазоне приемлемых входных сигналов [a,b]. Будем обозначать вектора входных сигналов через xi, а требуемые ответы сети через fi. Компоненты векторов будем обозначать нижним индексом, например, компоненты входного вектора через xij. Будем полагать, что в каждом примере ответ является вектором чисел из диапазона приемлемых сигналов [a,b]. В случае обучения сети задаче классификации требуемый ответ зависит от вида используемого интерпретатора ответа (см. главу «Оценка и Интерпретатор ответа» ).
Нейронная сеть вычисляет некоторую вектор-функцию F от входных сигналов. Эта функция зависит от параметров сети. Обучение сети состоит в подборе такого набора параметров сети, чтобы величина была минимальной (в идеале равна нулю). Для того чтобы нейронная сеть могла хорошо приблизить заданную таблично функцию f необходимо, чтобы реализуемая сетью функция F при изменении входных сигналов с xi на xj могла изменить значение с fi на fj. Очевидно, что наиболее трудным для сети должно быть приближение функции в точках, в которых при малом изменении входных сигналов происходит большое изменение значения функции. Таким образом, наибольшую сложность будет представлять приближение функции f в точках, в которых достигает максимума выражение . Для аналитически заданных функций величина называется константой Липшица. Исходя из этих соображения можно дать следующее определение сложности задачи.
Сложность аппроксимации таблично заданной функцииf, которая в точках xi принимает значения fi, задается выборочной оценкой константы Липшица, вычисляемой по следующей формуле:
(2)
Оценка (2) является оценкой константы Липшица аппроксимируемой функции снизу.
Для того, чтобы оценить способность сети заданной конфигурации решить задачу, необходимо оценить константу Липшица сети и сравнить ее с выборочной оценкой (2). Константа Липшица сети вычисляется по следующей формуле:
(3)
В формулах (2) и (3) можно использовать произвольные нормы. Однако для нейронных сетей наиболее удобной является евклидова норма. Далее везде используется евклидова норма.
В следующем разделе описан способ вычисления оценки константы Липшица сети (3) сверху. Очевидно, что в случае сеть принципиально не способна решить задачу аппроксимации функции f.
Оценка константы Липшица сети
Оценку константы Липшица сети будем строить в соответствии с принципом иерархического устройства сети, описанным в главе «Описание нейронных сетей». При этом потребуются следующие правила.
Для композиции функций f∘g=f(g(x)) константа Липшица оценивается как произведение констант Липшица:
Λf∘g ≤ ΛfΛg (4)
Для вектор-функции f=(f1, f2, … fn) константа Липшица равна:
(5)
Способ вычисления константы Липшица
Для непрерывных функций константа Липшица является максимумом производной в направлении r=(r1, …, rn) по всем точкам и всем направлениям. При этом вектор направления имеет единичную длину:
Напомним формулу производной функции f(x1, …, xn) в направлении r:
(6)
Синапс
Обозначим входной сигнал синапса через x, а синаптический вес через α. Тогда выходной сигнал синапса равен αx. Поскольку синапс является функцией одной переменной, константа Липшица равна максимуму модуля производной — модулю синаптического веса:
Λs=|α| (7)
Умножитель
Обозначим входные сигналы умножителя через x1, x2 Тогда выходной сигнал умножителя равен . Используя (6) получаем . Выражение r1x2+r2x1 является скалярным произведением векторов (r1, r2) и, учитывая единичную длину вектора r, достигает максимума, когда эти векторы сонаправлены. То есть при векторе
Используя это выражение, можно записать константу Липшица для умножителя:
(8)
Если входные сигналы умножителя принадлежат интервалу [a,b], то константа Липшица для умножителя может быть записана в следующем виде:
(9)
Точка ветвления
Поскольку в точке ветвления не происходит преобразования сигнала, то константа Липшица для нее равна единице.
Сумматор
Производная суммы по любому из слагаемых равна единице. В соответствии с (6) получаем:
(10)
поскольку максимум суммы при ограничении на сумму квадратов достигается при одинаковых слагаемых.
Нелинейный Паде преобразователь
Нелинейный Паде преобразователь или Паде элемент имеет два входных сигнала и один выходной. Обозначим входные сигналы через x1, x2. Используя (6) можно записать константу Липшица в следующем виде:
Знаменатель выражения под знаком модуля не зависит от направления, а числитель можно преобразовать так же, как и для умножителя. После преобразования получаем:
(11)
Нелинейный сигмоидный преобразователь
Нелинейный сигмоидный преобразователь, как и любой другой нелинейный преобразователь, имеющий один входной сигнал x, имеет константу Липшица равную максимуму модуля производной:
(12)
Адаптивный сумматор
Для адаптивного сумматора на n входов оценка константы Липшица, получаемая через представление его в виде суперпозиции слоя синапсов и простого сумматора, вычисляется следующим образом. Используя формулу (7) для синапсов и правило (5) для вектор-функции получаем следующую оценку константы Липшица слоя синапсов:
.
Используя правило (4) для суперпозиции функций и оценку константы Липшица для простого сумматора (10) получаем:
ΛA ≤ ΛΣΛL = √n||α||. (13)
Однако, если оценить константу Липшица адаптивного сумматора напрямую, то, используя (6) и тот факт, что при фиксированных длинах векторов скалярное произведение достигает максимума для сонаправленных векторов получаем:
(14)
Очевидно, что оценка (14) точнее, чем оценка (13).
Константа Липшица сигмоидной сети
Рассмотрим слоистую сигмоидную сеть со следующими свойствами:
1. Число входных сигналов — n0.
2. Число нейронов в i-м слое — ni.
3. Каждый нейрон первого слоя получает все входные сигналы, а каждый нейрон любого другого слоя получает сигналы всех нейронов предыдущего слоя.
4. Все нейроны всех слоев имеют вид, приведенный на рис. 1 и имеют одинаковую характеристику.
5. Все синаптические веса ограничены по модулю единицей.
6. В сети m слоев.
В этом случае, учитывая формулы (4), (5), (12) и (14) константу Липшица i-го слоя можно оценить следующей величиной:
Используя формулу (4) получаем оценку константы Липшица всей сети:
Если используется нейроны типа S1, то ΛP=c и оценка константы Липшица сети равна:
Для нейронов типа S2, то ΛP=1/- и оценка константы Липшица сети равна:
Обе формулы подтверждают экспериментально установленный факт, что чем круче характеристическая функция нейрона, тем более сложные функции (функции с большей константой Липшица) может аппроксимировать сеть с такими нейронами.
Предобработка, облегчающая обучение
При обучении нейронных сетей иногда возникают ситуации, когда дальнейшее обучение нейронной сети невозможно. В этом случае необходимо проанализировать причины. Возможно несколько видов анализа. Одной из возможных причин является высокая сложность задачи, определяемая как выборочная оценка константы Липшица.
Для упрощения задачи необходимо уменьшить выборочную оценку константы Липшица. Наиболее простой способ добиться этого — увеличить расстояние между входными сигналами. Рассмотрим пару примеров — xi, xj — таких, что
Определим среди координат векторов xi и xj координату, в которой достигает минимума величина |xil-xjl|, исключив из рассмотрения совпадающие координаты. Очевидно, что эта координата является «узким местом», определяющим сложность задачи. Следовательно, для уменьшения сложности задачи требуется увеличить расстояние между векторами xi и xj, а наиболее перспективной координатой для этого является l-я. Однако увеличение расстояние между xil и xjl не всегда осмыслено. Дело в том, что все параметры, как правило, измеряются с конечной точностью. Поэтому, если величина |xil-xjl| меньше чем точность измерения l-го параметра, значения xil и xjl можно считать совпадающими. Таким образом, для изменения масштаба надо выбирать тот из входных параметров, для которого значение |xil-xjl| минимально, но превышает точность измерения этого параметра.
Таблица 7. Кодирование параметра после разбиения на два сигнала
Предположим, что все входные параметры предобработаны в соответствии с формулой (1). Перенумеруем примеры обучающего множества так, чтобы были верны следующие неравенства: xl1<xl2<,…,xlN, где N — число примеров в обучающем множестве. При этом, возможно, придется исключить ряд пар параметр-ответ с совпадающими значениями параметра. Если в какой-либо из таких пар значения ответов различаются, то это снижает возможную полезность данной процедуры.
Наиболее простой путь — разбить диапазон l-го параметра на два. Зададимся точкой x. Будем кодировать l-й параметр двумя входными сигналами в соответствии с табл. 7. При таком кодировании критерий Липшица, очевидно, уменьшится. Вопрос о выборе точки x может решаться по-разному. Простейший путь — положить x=(a-b)/2. Более сложный, но часто более эффективный — подбор x исходя из требования минимальности критерия Липшица.
Приведенный выше способ уменьшения критерия Липшица не единственный. В следующем разделе рассмотрен ряд способов предобработки, решающих ту же задачу.
(обратно)Другие способы предобработки числовых признаков
В данном разделе будет рассмотрено три вида предобработки числовых признаков — модулярный, позиционный и функциональный. Основная идея этих методов предобработки состоит в том, чтобы сделать значимыми малые отличия больших величин. Действительно, пусть для ответа существенно изменение величины признака на единицу при значении признака порядка миллиона. Очевидно, что простейшая предобработка (1) сделает отличие в единицу неразличимым для нейронной сети при абсолютных значениях порядка миллиона.
Все эти виды предобработки обладают одним общим свойством — за счет кодирования входного признака несколькими сигналами они уменьшают сложность задачи (критерий Липшица).
Модулярная предобработка
Зададимся некоторым набором положительных чисел y1, …, yk. Определим сравнение по модулю для действительных чисел следующим образом:
x mod y = x-y·Int(x/y), (15)
где Int(x) — функция, вычисляющая целую часть величины x путем отбрасывания дробной части. Очевидно, что величина x mod y лежит в интервале (-y, y).
Кодирование входного признака x при модулярной предобработке вектором Z производится по следующей формуле:
(16)
Таблица 8. Пример сигналов при модулярном вводе
x x mod 3 x mod 5 x mod 7 x mod 11 5 2 0 5 5 10 1 0 3 10 15 0 0 1 3Однако модулярная предобработка обладает одним отрицательным свойством — во всех случаях, когда yi≠yr1, при целом r, разрушается отношение предшествования чисел. В табл. 8 приведен пример векторов. Поэтому, модульная предобработка пригодна при предобработке тех признаков, у которых важна не абсолютная величина, а взаимоотношение этой величины с величинами y1, …, yk.
Примером такого признака может служить угол между векторами, если в качестве величин y выбрать yi=π/i.
(обратно)Функциональная предобработка
Функциональная предобработка преследует единственную цель — снижение константы Липшица задачи. В разделе «Предобработка, облегчающая обучение», был приведен пример такой предобработки. Рассмотрим общий случай функциональной предобработки, отображающих входной признак x в k-мерный вектор z. Зададимся набором из k чисел, удовлетворяющих следующим условиям: xmin<y1<…<yk-1<yk<xmax.
Таблица 9. Пример функциональной предобработки числового признака x∈[0,5], при условии, что сигналы нейронов принадлежат интервалу [-1,1]. В сигмоидной предобработке использована φ(x)=x/(1+|x|), а в шапочной — φ(x)=2/(1+x²)-1. Были выбраны четыре точки yi=i.
x z1(x) z2(x) z3(x) z4(x) Линейная предобработка 1.5 0.5 -0.5 -1 -1 3.5 1 1 0.5 -0.5 Сигмоидная предобработка 1.5 0.3333 -0.3333 -0.6 -0.7142 3.5 0.7142 0.6 0.3333 -0.3333 Шапочная предобработка 1.5 0.6 0.6 -0.3846 -0.7241 3.5 -0.7241 -0.3846 0.6 0.6Пусть φ — функция, определенная на интервале [xmin-yk, xmax-y1], а φmin,φmax — минимальное и максимальное значения функции φ на этом интервале. Тогда i-я координата вектора z вычисляется по следующей формуле:
(17)
Линейная предобработка. В линейной предобработке используется кусочно линейная функция:
(18)
Графики функций zi(x) представлены на рис. 2а. Видно, что с увеличением значения признака x ни одна функция не убывает, а их сумма возрастает. В табл. 9 представлены значения этих функций для двух точек — x1=1.5 и x2=3.5.
Сигмоидная предобработка. В сигмоидной предобработке может использоваться любая сигмоидная функция. Если в качестве сигмоидной функции использовать функцию S2, приведенную в разделе «Нейрон» этой главы, то формула (17) примет следующий вид:
Графики функций zi(x) представлены на рис. 2б. Видно, что с увеличением значения признака x ни одна функция не убывает, а их сумма возрастает. В табл. 9 представлены значения этих функций для двух точек x1=1.5 и x2=3.5.
Шапочная предобработка. Для шапочной предобработки используются любые функции, имеющие график в виде «шапочки». Например, функция φ(x)=1/(1+x²).
Графики функций zi(x) представлены на рис. 2 в. Видно, что с увеличением значения признака x ни одна из функций zi(x) , ни их сумма не ведут себя монотонно. В табл. 9 представлены значения этих функций для двух точек x1=1.5 и x2=3.5.
(обратно)Позиционная предобработка
Основная идея позиционной предобработки совпадает с принципом построения позиционных систем счисления. Зададимся положительной величиной y такой, что yk≥(xmin-xmax). Сдвинем признак x так, чтобы он принимал только неотрицательные значения. В качестве сигналов сети будем использовать результат простейшей предобработки y-ичных цифр представления сдвинутого признака x. Формулы вычисления цифр приведены ниже:
(19)
где операция сравнения по модулю действительного числа определена в (15). Входные сигналы сети получаются из компонентов вектора z путем простейшей предобработки.
Составной предобработчик
Поскольку на вход нейронной сети обычно подается несколько входных сигналов, каждый из которых обрабатывается своим предобработчиком, то предобработчик должен быть составным. Представим предобработчик в виде совокупности независимых частных предобработчиков. Каждый частный предобработчик обрабатывает одно или несколько тесно связанных входных данных. Как уже отмечалось ранее, предобработчик может иметь один из четырех типов, приведенных в табл. 10. На входе предобработчик получает вектор входных данных (возможно, состоящий из одного элемента), а на выходе выдает вектор входных сигналов сети (так же возможно состоящий из одного элемента).
Таблица 10. Типы предобработчиков
Тип Описание Number Предобрабатывает числовые входные данные Unordered Предобрабатывает неупорядоченные качественные признаки Ordered Предобрабатывает упорядоченные качественные признаки Binary Обрабатывает бинарные признакиНеобходимость передачи предобработчику вектора входных данных и получения от него вектора входных сигналов связана с тем, что существуют предобработчики получающие несколько входных данных и выдающие несколько входных сигналов. Примером такого предобработчика может служить предобработчик, переводящий набор координат планеты из сферической в декартову.
Для качественных признаков принято кодирование длинными целыми числами. Первое значение равно 1, второе — 2 и т. д. Числовые признаки кодируются действительными числами.
Лекция 9. Описание нейронных сетей
В первой части этой главы описана система построения сетей из элементов. Описаны прямое и обратное функционирование сетей и составляющих их элементов. Приведены три метода построения двойственных сетей и обоснован выбор самодвойственных сетей. Во второй части приведены примеры различных парадигм нейронных сетей, описанные в соответствии с предложенной в первой части главы методикой.
Как уже говорилось главе «Двойственные сети», на данный момент в нейросетевом сообществе принято описывать архитектуру нейронных сетей в неразрывном единстве с методами их обучения. Эта связь не является естественной. Так, в первой части этой главы будет рассматриваться только архитектура нейронных сетей. Во второй части будет продемонстрирована независимость ряда методов обучения нейронных сетей от их архитектуры. Однако, для удобства, во второй части главы архитектуры всех парадигм нейронных сетей будут описаны вместе с методами обучения.
Нейронные сети можно классифицировать по разным признакам. Для описания нейронных сетей в данной главе существенной является классификация по типу времени функционирования сетей. По этому признаку сети можно разбить на три класса.
1. Сети с непрерывным временем.
2. Сети с дискретным асинхронным временем.
3. Сети с дискретным временем, функционирующие синхронно.
В данной работе рассматриваются только сети третьего вида, то есть сети, в которых все элементы каждого слоя срабатывают одновременно и затем передают свои сигналы нейронам следующего слоя.
Конструирование нейронных сетей
Впервые последовательное описание конструирования нейронных сетей из элементов было предложено в книге А.Н. Горбаня [65]. Однако за прошедшее время предложенный А.Н. Горбанем способ конструирования претерпел ряд изменений.
При описании нейронных сетей принято оперировать такими терминами, как нейрон и слой. Однако, при сравнении работ разных авторов выясняется, что если слоем все авторы называют приблизительно одинаковые структуры, то нейроны разных авторов совершенно различны. Таким образом, единообразное описание нейронных сетей на уровне нейронов невозможна. Однако, возможно построение единообразного описания на уровне составляющих нейроны элементов и процедур конструирования сложных сетей из простых.
Элементы нейронной сети
На рис. 1 приведены все элементы, необходимые для построения нейронных сетей. Естественно, что возможно расширение списка нелинейных преобразователей. Однако, это единственный вид элементов, который может дополняться. Вертикальными стрелками обозначены входы параметров (для синапса — синаптических весов или весов связей), а горизонтальными — входные сигналы элементов. С точки зрения функционирования элементов сети сигналы и входные параметры элементов равнозначны. Различие между этими двумя видами параметров относятся к способу их использования в обучении. Кроме того, удобно считать, что параметры каждого элемента являются его свойствами и хранятся при нем. Совокупность параметров всех элементов сети называют вектором параметров сети. Совокупность параметров всех синапсов называют вектором обучаемых параметров сети, картой весов связей или синаптической картой. Отметим, что необходимо различать входные сигналы элементов и входные сигналы сети. Они совпадают только для элементов входного слоя сети.
Из приведенных на рис. 1 элементов можно построить практически любую нейронную сеть. Вообще говоря, нет никаких правил, ограничивающих свободу творчества конструктора нейронных сетей. Однако, есть набор структурных единиц построения сетей, позволяющий стандартизовать процесс конструирования. Детальный анализ различных нейронных сетей позволил выделить следующие структурные единицы:
• элемент — неделимая часть сети, для которой определены методы прямого и обратного функционирования;
• каскад — сеть составленная из последовательно связанных слоев, каскадов, циклов или элементов;
• слой — сеть составленная из параллельно работающих слоев, каскадов, циклов или элементов;
• цикл — каскад выходные сигналы которого поступают на его собственный вход.
Очевидно, что не все элементы являются неделимыми. В следующем разделе будет приведен ряд составных элементов.
Введение трех типов составных сетей связано с двумя причинами: использование циклов приводит к изменению правил остановки работы сети, описанных в разд. «Правила остановки работы сети»; разделение каскадов и слоев позволяет эффективно использовать ресурсы параллельных ЭВМ. Действительно, все сети, входящие в состав слоя, могут работать независимо друг от друга. Тем самым при конструировании сети автоматически закладывается база для использования параллельных ЭВМ.
На рис. 2 приведен пример поэтапного конструирования трехслойной сигмоидной сети.
Составные элементы
Название «составные элементы» противоречит определению элементов. Это противоречие объясняется соображениями удобства работы. Введение составных элементов преследует цель упрощения конструирования. Как правило, составные элементы являются каскадами простых элементов.
Хорошим примером полезности составных элементов может служить использование сумматоров. В ряде работ [36, 53, 107, 127, 289] интенсивно используются сети, нейроны которых содержат нелинейные входные сумматоры. Под нелинейным входным сумматором, чаще всего понимают квадратичные сумматоры — сумматоры, вычисляющие взвешенную сумму всех попарных произведений входных сигналов нейрона. Отличие сетей с квадратичными сумматорами заключается только в использовании этих сумматоров. На рис. 3а приведен фрагмент сети с линейными сумматорами. На рис. 3б — соответствующий ему фрагмент с квадратичными сумматорами, построенный с использованием элементов, приведенных на рис. 1. На (рис. 3в) — тот же фрагмент, построенный с использованием квадратичных сумматоров. При составлении сети с квадратичными сумматорами из простых элементов на пользователя ложится большой объем работ по проведению связей и организации вычисления попарных произведений. Кроме того, рис. 3в гораздо понятнее рис. 3б и содержит ту же информацию. Кроме того, пользователь может изменить тип сумматоров уже сконструированной сети, указав замену одного типа сумматора на другой. На рис. 4 приведены обозначения и схемы наиболее часто используемых составных элементов.
Необходимо отметить еще одну разновидность сумматоров, полезную при работе по конструированию сети — неоднородные сумматоры. Неоднородный сумматор отличается от однородного наличием еще одного входного сигнала, равного единице. На рис. 4 г приведены схема и обозначения для неоднородного адаптивного сумматора. В табл. 1 приведены значения, вычисляемые однородными и соответствующими им неоднородными сумматорами.
Таблица 1. Однородные и неоднородные сумматоры
(обратно)Функционирование сети
Рис. 5 Схема функционирования сети
Прежде всего, необходимо разделить процессы обучения нейронной сети и использования обученной сети. При использовании обученной сети происходит только решение сетью определенной задачи. При этом синаптическая карта сети остается неизменной. Работу сети при решении задачи будем далее называть прямым функционированием.
При обучении нейронных сетей методом обратного распространения ошибки нейронная сеть (и каждый составляющий ее элемент) должна уметь выполнять обратное функционирование. Во второй части этой главы будет показано, что обратное функционирование позволяет обучать также и нейросети, традиционно считающиеся не обучаемыми, а формируемыми (например, сети Хопфилда [312]). Обратным функционированиемназывается процесс работы сети, когда на вход двойственной сети подаются определенные сигналы, которые далее распространяются по связям двойственной сети. При прохождении сигналов обратного функционирования через элемент, двойственный элементу с обучаемыми параметрами, вычисляются поправки к параметрам этого элемента. Если на вход сети, двойственной к сети с непрерывными элементами, подается производная некоторой функции F от выходных сигналов сети, то вычисляемые сетью поправки должны быть элементами градиента функции F по обучаемым параметрам сети. Двойственная сеть строится так, чтобы удовлетворять этому требованию.
Методы построения двойственных сетей
Пусть задана нейронная сеть, вычисляющая некоторую функцию (рис. 5а). Необходимо построить двойственную к ней сеть, вычисляющую градиент некоторой функции H от выходных сигналов сети. В книге А.Н. Горбаня «Обучение нейронных сетей» [65] предложен метод построения сети, двойственной к данной. Пример сети, построенной по методу А.Н. Горбаня, приведен на рис. 5б. Для работы такой сети необходимо, обеспечение работы элементов в трех режимах. Первый режим — обычное прямое функционирование (рис. 5а). Второй режим — нагруженное прямое функционирование (рис. 5б, верхняя цепочка). Третий режим — обратное функционирование.
При обычном прямом функционировании каждый элемент вычисляет выходную функцию от входных сигналов и параметров и выдает ее на выход в сеть для передачи далее.
При нагруженном прямом функционировании каждый элемент вычисляет выходную функцию от входных сигналов и параметров и выдает ее на выход в сеть для передачи далее. Кроме того, он вычисляет производные выходной функции по каждому входному сигналу и параметру и запоминает их (блоки под элементами в верхней цепочке на рис. 5б). При обратном функциони-ровании элементы исход-ной сети выдают на специальные выходы ранее вычисленные производные (связи между верхней и нижней цепочками на рис. 5б), которые далее используются для вычисления градиентов по параметрам и входным сигналам сети двойственной сетью (нижняя цепочка на рис. 5б). Вообще говоря, для хорошей организации работы такой сети требуется одно из следующих устройств. Либо каждый элемент должен получать дополнительный сигнал выдачи запомненных сигналов (ранее вычисленных производных), либо к сети следует добавить элемент, вычисляющий функцию оценки.
Первое решение требует дополнительных линий связи с каждым элементом, за исключением точек ветвления, что в существенно увеличивает (приблизительно в полтора раза) и без того большое число связей. Большое число связей, в свою очередь, увеличивает сложность и стоимость аппаратной реализации нейронной сети.
Второй подход — включение оценки как элемента в нейронную сеть — лишает структуру гибкости, поскольку для замены функции оценки потребуется изменять сеть. Кроме того, оценка будет достаточно сложным элементом. некоторые оценки включают в себя процедуру сортировки и другие сложные операции (см. главу «Оценка и интерпретатор ответа»).
Метод нагруженного функционирования позволяет вычислять не только градиент оценки, но и производные по входным параметрам и сигналам от произвольного функционала от градиента. Для этого строится дважды двойственная сеть. Для работы дважды двойственной сети необходимо, чтобы элементы выполняли дважды двойственное функционирование — вычисляли не только выходной сигнал и производные выходного сигнала по входным сигналам и параметрам, но и матрицу вторых производных выходного сигнала по входным сигналам и параметрам. Кроме того, построение дважды двойственной сети потребует дополнительных затрат от пользователя, поскольку процедура построения двойственной и дважды двойственной сети достаточно понятна, но описывается сложным алгоритмом. При этом построение дважды двойственной сети не является построением сети двойственной к двойственной.
Для унификации процедуры построения сети, двойственной к данной сети, автором разработан унифицированный метод двойственности. В этом методе каждому элементу исходной сети ставится в соответствие подсеть. На рис. 5в приведен пример двойственной сети, построенной по унифицированному методу. Каждый элемент, кроме точки ветвления и сумматора, заменяется на элемент, вычисляющий производную выходной функции исходного элемента по входному сигналу (параметру) и умножитель, умножающий сигнал обратного функционирования на вычисленную производную. Если элемент имеет несколько входов и параметров, то он заменяется на столько описанных выше подсетей, сколько у него входных сигналов и параметров. При этом сигнал обратного функционирования пропускается через точку ветвления.
Двойственная сеть, построенная по этому методу, требует включения в нее оценки как элемента. Достоинством этого метода является универсальность. Для построения дважды двойственной сети достаточно построить сеть двойственную к двойственной. Кроме того, построенная по этому методу сеть имеет меньшее время срабатывания.
Анализ этих двух методов с точки зрения аппаратной реализации, выявил в них следующие недостатки.
• Для реализации обратного функционирования необходимо изменять архитектуру сети, причем в ходе обратного функционирования связи прямого функционирования не используются.
• Необходимо включать в сеть оценку как один из элементов
Для устранения этих недостатков, автором предложен метод самодвойственных сетей. Этот метод не позволяет строить дважды двойственных сетей, что делает его менее мощным, чем два предыдущих. Однако большинство методов обучения не требует использования дважды двойственных сетей, что делает это ограничение не очень существенным. Идея самодвойственных сетей состоит в том, чтобы каждый элемент при прямом функционировании запоминал входные сигналы. А при обратном функционировании вычислял все необходимые производные, используя ранее запомненные сигналы, и умножал их на сигнал обратного функционирования.
Такая модификация делает элементы более сложными, чем в двух предыдущих методах. Однако этот метод дает следующие преимущества по отношению к методу нагруженного функционирования и унифицированному методу двойственности.
• Для элементов не требуется дополнительного управления, поскольку получение сигнала прямого или обратного функционирования инициирует выполнение одной из двух функций.
• Для выполнения обратного функционирования не требуется дополнительных элементов и линий связи между элементами.
• Оценка является независимым от сети компонентом.
Наиболее существенным является второе преимущество, поскольку при аппаратной реализации нейронных сетей наиболее существенным ограничением является число связей. Так в приведенных на рис. 5 сетях задействовано для самодвойственной сети — 6 связей, для сети, построенной по методу нагруженного функционирования — 20 связей, а для сети, построенной по методу унифицированной двойственности — 27 связей. Следует заметить, что с ростом размеров сети данные пропорции будут примерно сохраняться.
Исходя из соображений экономичной и эффективной аппаратной реализации и функционального разделения компонентов далее в данной работе рассматриваются только самодвойственные сети.
Элементы самодвойственных сетей
Если при обратном функционировании самодвойственной сети на ее выход подать производные некоторой функции F по выходным сигналам сети, то в ходе обратного функционирования на входах параметров сети должны быть вычислены элементы градиента функции F по параметрам сети, а на входах сигналов — элементы градиента функции F по входным сигналам. Редуцируя это правило на отдельный элемент, получаем следующее требование к обратному функционированию элемента самодвойственной сети: Если при обратном функционировании элемента самодвойственной сети на его выход подать производные некоторой функции F по выходным сигналам элемента, то в ходе обратного функционирования на входах параметров элемента должны быть вычислены элементы градиента функции F по параметрам элемента, а на входах сигналов — элементы градиента функции F по входным сигналам элемента. Легко заметить, что данное требование автоматически обеспечивает подачу на выход элемента, предшествующего данному, производной функции F по выходным сигналам этого элемента.
Далее в этом разделе для каждого из элементов, приведенных на рис. 1 определены правила обратного функционирования, в соответствии со сформулированными выше требованиями к элементам самодвойственной сети.
Синапс
У синапса два входа — вход сигнала и вход синаптического веса (рис. 6а). Обозначим входной сигнал синапса через x, а синаптический вес через α. Тогда выходной сигнал синапса равен αx. При обратном функционировании на выход синапса подается сигнал ∂F/∂(αx).
На входе синапса должен быть получен сигнал обратного функционирования, равный , а на входе синаптического веса — поправка к синаптическому весу, равная (рис. 6б).
Умножитель
Умножитель имеет два входных сигнала и не имеет параметров. Обозначим входные сигнал синапса через x1, x2. Тогда выходной сигнал умножителя равен x1x2 (рис. 7а). При обратном функционировании на выход умножителя подается сигнал ∂F/∂(x1x2). На входах сигналов x1 и x2 должны быть получены сигналы обратного функционирования, равные и , соответственно (рис. 7б).
Точка ветвления
В отличие от ранее рассмотренных элементов, точка ветвления имеет только один вход и несколько выходов. Обозначим входной сигнал через x, а выходные через x1, x2, …, xn, причем xi=x (рис. 8а). При обратном функционировании на выходные связи точки ветвления подаются сигналы (рис. 8б). На входной связи должен получаться сигнал, равный . Можно сказать, что точка ветвления при обратном функционировании переходит в сумматор, или, другими словами, сумматор является двойственным по отношению к точке ветвления.
Сумматор
Сумматор считает сумму входных сигналов. Обычный сумматор не имеет параметров. При описании прямого и обратного функционирования ограничимся описанием простого сумматора, поскольку функционирование адаптивного и квадратичного сумматора может быть получено как прямое и обратное функционирование сети в соответствии с их схемами, приведенными на рис. 3б и 3в. Обозначим входные сигналы сумматора через x1, x2, …, xn (рис. 9а). Выходной сигнал равен . При обратном функционировании на выходную связь сумматора подается сигнал (рис. 9б). На входных связях должны получаться сигналы, равные
Из последней формулы следует, что все сигналы обратного функционирования, выдаваемые на входные связи сумматора, равны. Таким образом сумматор при обратном функционировании переходит в точку ветвления, или, другими словами, сумматор является двойственным по отношению к точке ветвления.
Нелинейный Паде преобразователь
Нелинейный Паде преобразователь или Паде элемент имеет два входных сигнала и один выходной. Обозначим входные сигналы через x1, x2. Тогда выходной сигнал Паде элемента равен x1/x2 (рис. 10а). При обратном функционировании на выход Паде элемента подается сигнал ∂F/∂(x1/x2).
На входах сигналов x1 и x2 и должны быть получены сигналы обратного функционирования, равные и , соответственно (рис. 10б).
Нелинейный сигмоидный преобразователь
Нелинейный сигмоидный преобразователь или сигмоидный элемент имеет один входной сигнал и один параметр. Сторонники чистого коннекционистского подхода считают, что обучаться в ходе обучения нейронной сети могут только веса связей. С этой точки зрения параметр сигмоидного элемента является не обучаемым и, как следствие, для него нет необходимости вычислять поправку. Однако, часть исследователей полагает, что нужно обучать все параметры всех элементов сети. Исходя из этого, опишем вычисление этим элементом поправки к содержащемуся в нем параметру.
Обозначим входной сигнал через x, параметр через α, а вычисляемую этим преобразователем функцию через σ(α,x) (рис. 11а). При обратном функционировании на выход сигмоидного элемента подается сигнал ∂F/∂σ(α,x).
На входе сигнала должен быть получен сигнал обратного функционирования, равный , а на входе параметра поправка, равная (рис. 11б).
Произвольный непрерывный нелинейный преобразователь
Произвольный непрерывный нелинейный преобразователь имеет несколько входных сигналов, а реализуемая им функция зависит от нескольких параметров. Выходной сигнал такого элемента вычисляется как некоторая функция φ(x,α), где x — вектор входных сигналов, а a — вектор параметров. При обратном функционировании на выходную связь элемента подается сигнал обратного функционирования, равный ∂F/∂φ.
На входы сигналов выдаются сигналы обратного функционирования, равные , а на входах параметров вычисляются поправки, равные
Пороговый преобразователь
Пороговый преобразователь, реализующий функцию определения знака (рис. 12а), не является элементом с непрерывной функцией, и, следовательно, его обратное функционирование не может быть определено из требования вычисления градиента. Однако, при обучении сетей с пороговыми преобразователями полезно иметь возможность вычислять поправки к параметрам. Так как для порогового элемента нельзя определить однозначное поведение при обратном функционировании, предлагается доопределить его, исходя из соображений полезности при конструировании обучаемых сетей. Основным методом обучения сетей с пороговыми элементами является правило Хебба (подробно рассмотрено во второй части главы). Оно состоит из двух процедур, состоящих в изменении «весов связей между одновременно активными нейронами». Для этого правила пороговый элемент при обратном функционировании должен выдавать сигнал обратного функционирования, совпадающий с выданным им сигналом прямого функционирования (рис. 12б). Такой пороговый элемент будем называть зеркальным. При обучении сетей Хопфилда [312], подробно рассмотренном во второй части главы, необходимо использовать «прозрачные» пороговые элементы, которые при обратном функционировании пропускают сигнал без изменения (рис. 12в).
Правила остановки работы сети
При использовании сетей прямого распространения (сетей без циклов) вопроса об остановке сети не возникает. Действительно, сигналы поступают на элементы первого (входного) слоя и, проходя по связям, доходят до элементов последнего слоя. После снятия сигналов с последнего слоя все элементы сети оказываются «обесточенными», то есть ни по одной связи сети не проходит ни одного ненулевого сигнала. Сложнее обстоит дело при использовании сетей с циклами. В случае общего положения, после подачи сигналов на входные элементы сети по связям между элементами, входящими в цикл, ненулевые сигналы будут циркулировать сколь угодно долго.
Существует два основных правила остановки работы сети с циклами. Первое правило состоит в остановке работы сети после указанного числа срабатываний каждого элемента. Циклы с таким правилом остановки будем называть ограниченными.
Второе правило остановки работы сети — сеть прекращает работу после установления равновесного распределения сигналов в цикле. Такие сети будем называть равновесными. Примером равновесной сети может служить сеть Хопфилда [312] (см. разд. «Сети Хопфилда»).
(обратно)Архитектуры сетей
Как уже отмечалось ранее, при конструировании сетей из элементов можно построить сеть любой архитектуры. Однако и при произвольном конструировании можно выделить наиболее общие признаки, существенно отличающие одну сеть от другой. Очевидно, что замена простого сумматора на адаптивный или даже на квадратичный не приведут к существенному изменению структуры сети, хотя число обучаемых параметров увеличится. Однако, введение в сеть цикла сильно изменяет как структуру сети, так и ее поведение. Таким образом можно все сети разбить на два сильно отличающихся класса: ациклические сети и сети с циклами. Среди сетей с циклами существует еще одно разделение, сильно влияющее на способ функционирования сети: равновесные сети с циклами и сети с ограниченными циклами.
Большинство используемых сетей не позволяют определить, как повлияет изменение какого-либо внутреннего параметра сети на выходной сигнал. На рис. 13 приведен пример сети, в которой увеличение параметра α приводит к неоднозначному влиянию на сигнал x2: при отрицательных x1 произойдет уменьшение x2, а при положительных x1 — увеличение. Таким образом, выходной сигнал такой сети немонотонно зависит от параметра α. Для получения монотонной зависимости выходных сигналов сети от параметров внутренних слоев (то есть всех слоев кроме входного) необходимо использовать специальную монотонную архитектуру нейронной сети. Принципиальная схема сетей монотонной архитектуры приведена на рис. 14.
Основная идея построения монотонных сетей состоит в разделении каждого слоя сети на два — возбуждающий и тормозящий. При этом все связи в сети устроены так, что элементы возбуждающей части слоя возбуждают элементы возбуждающей части следующего слоя и тормозят тормозящие элементы следующего слоя. Аналогично, тормозящие элементы возбуждают тормозящие элементы и тормозят возбуждающие элементы следующего слоя. Названия «тормозящий» и «возбуждающий» относятся к влиянию элементов обеих частей на выходные элементы.
Отметим, что для сетей с сигмоидными элементами требование монотонности означает, что веса всех связей должны быть неотрицательны. Для сетей с Паде элементами требование не отрицательности весов связей является необходимым условием бессбойной работы. Требование монотонности для сетей с Паде элементами приводит к изменению архитектуры сети, не накладывая никаких новых ограничений на параметры сети. На рис. 15 приведены пример немонотонной сети, а на рис. 16 монотонной сети с Паде элементами.
Особо отметим архитектуру еще одного класса сетей — сетей без весов связей. Эти сети, в противовес коннекционистским, не имеют обучаемых параметров связей. Любую сеть можно превратить в сеть без весов связей заменой всех синапсов на умножители. Легко заметить, что получится такая же сеть, только вместо весов связей будут использоваться сигналы. Таким образом в сетях без весов связей выходные сигналы одного слоя могут служить для следующего слоя как входными сигналами, так и весами связей. Заметим, что вся память таких сетей содержится в значениях параметров нелинейных преобразователей. Из разделов «Синапс» и «Умножитель» следует, что сети без весов связей способны вычислять градиент функции оценки и затрачивают на это ровно тоже время, что и аналогичная сеть с весами связей.
Модификация синаптической карты (обучение)
Кроме прямого и обратного функционирования, все элементы должны уметь выполнять еще одну операцию — модификацию параметров. Процедура модификации параметров состоит в добавлении к существующим параметрам вычисленных поправок (напомним, что для сетей с непрерывно дифференцируемыми элементами вектор поправок является градиентом некоторой функции от выходных сигналов). Если обозначить текущий параметр элемента черезα, а вычисленную поправку через Δα, то новое значение параметра вычисляется по формуле α'=h1α+h2Δα.
Параметры обучения h1 и h2 определяются компонентом учитель и передаются сети вместе с запросом на обучение. В некоторых случаях бывает полезно использовать более сложную процедуру модификации карты.
Во многих работах отмечается, что при описанной выше процедуре модификации параметров происходит неограниченный рост величин параметров. Существует несколько различных методов решения этой проблемы. Наиболее простым является жесткое ограничение величин параметров некоторыми минимальным и максимальным значениями. При использовании этого метода процедура модификации параметров имеет следующий вид:
Контрастирование и нормализация сети
В последние годы широкое распространение получили различные методы контрастирования или скелетонизации нейронных сетей. В ходе процедуры контрастирования достигается высокая степень разреженности синаптической карты нейронной сети, так как большинство связей получают нулевые веса (см. например [47, 100, 303, 304]).
Очевидно, что при такой степени разреженности ненулевых параметров проводить вычисления так, как будто структура сети не изменилась, неэффективно. Возникает потребность в процедуре нормализации сети, то есть фактического удаления нулевых связей из сети, а не только из обучения. Процедура нормализации состоит из двух этапов:
1. Из сети удаляются все связи, имеющие нулевые веса и исключенные из обучения.
2. Из сети удаляются все подсети, выходные сигналы которых не используются другими подсетями в качестве входных сигналов и не являются выходными сигналами сети в целом.
В ходе нормализации возникает одна трудность: если при описании нейронной сети все нейроны одинаковы, и можно описать нейрон один раз, то после удаления отконтрастированных связей нейроны обычно имеют различную структуру. Компонент сеть должен отслеживать ситуации, когда два блока исходно одного и того же типа уже не могут быть представлены в виде этого блока с различными параметрами. В этих случаях компонент сеть порождает новый тип блока. Правила порождения имен блоков приведены в описании выполнения запроса на нормализацию сети.
Примеры сетей и алгоритмов их обучения
В этом разделе намеренно допущено отступление от общей методики — не смешивать разные компоненты. Это сделано для облегчения демонстрации построения нейронных сетей обратного распространения, позволяющих реализовать на них большинство известных алгоритмов обучения нейронных сетей.
Сети Хопфилда
Классическая сеть Хопфилда [312], функционирующая в дискретном времени, строится следующим образом. Пусть {ei} — набор эталонных образов (i=1, …, m). Каждый образ, включая и эталоны, имеет вид n-мерного вектора с координатами, равными нулю или единице. При предъявлении на вход сети образа x сеть вычисляет образ, наиболее похожий на x. В качестве меры близости образов выберем скалярное произведение соответствующих векторов. Вычисления проводятся по следующей формуле:
Эта процедура выполняется до тех пор, пока после очередной итерации не окажется, что x=x'. Вектор x, полученный в ходе последней итерации, считается ответом. Для нейросетевой реализации формула работы сети переписывается в следующем виде:
или
x'=sign(Ax),
где .
На рис. 17 приведена схема сети Хопфилда [312] для распознавания четырехмерных образов. Обычно сети Хопфилда [312] относят к сетям с формируемой синаптической картой. Однако, используя разработанный в первой части главы набор элементов, можно построить обучаемую сеть. Для построения такой сети используем «прозрачные» пороговые элементы. Ниже приведен алгоритм обучения сети Хопфилда [312].
1. Положим все синаптические веса равными нулю.
2. Предъявим сети первый эталон e¹ и проведем один такт функционирования вперед, то есть цикл будет работать не до равновесия, а один раз (см. рис. 17б).
3. Подадим на выход каждого нейрона соответствующую координату вектора e¹ (см. рис. 17в). Поправка, вычисленная на j-ом синапсе i-го нейрона, равна произведению сигнала прямого функционирования на сигнал обратного функционирования. Поскольку при обратном функционировании пороговый элемент прозрачен, а сумматор переходит в точку ветвления, то поправка равна ei¹ej¹.
4. Далее проведем шаг обучения с параметрами обучения, равными единице. В результате получим αij=ei¹ej¹.
Повторяя этот алгоритм, начиная со второго шага, для всех эталонов получим , что полностью совпадает с формулой формирования синаптической карты сети Хопфилда [312], приведенной в начале раздела.
(обратно)Сеть Кохонена
Сети Кохонена [131, 132] (частный случай метода динамических ядер [224, 262]) являются типичным представителем сетей решающих задачу классификации без учителя. Рассмотрим пространственный вариант сети Кохонена. Дан набор из m точек {xp} в n-мерном пространстве. Необходимо разбить множество точек {xp} на k классов близких в смысле квадрата евклидова расстояния. Для этого необходимо найти k точек αl таких, что , минимально; .
Существует множество различных алгоритмов решения этой задачи. Рассмотрим наиболее эффективный из них.
1. Зададимся некоторым набором начальных точек αl.
2. Разобьем множество точек {xp} на k классов по правилу .
3. По полученному разбиению вычислим новые точки αl из условия минимальности .
Обозначив через |Pi| число точек в i-ом классе, решение задачи, поставленной на третьем шаге алгоритма, можно записать в виде .
Второй и третий шаги алгоритма будем повторять до тех пор, пока набор точек αl не перестанет изменяться. После окончания обучения получаем нейронную сеть, способную для произвольной точки x вычислить квадраты евклидовых расстояний от этой точки до всех точек αl и, тем самым, отнести ее к одному из k классов. Ответом является номер нейрона, выдавшего минимальный сигнал.
Теперь рассмотрим сетевую реализацию. Во первых, вычисление квадрата евклидова расстояния достаточно сложно реализовать в виде сети (рис. 18а). Однако заметим, что нет необходимости вычислять квадрат расстояния полностью. Действительно, .
Отметим, что в последней формуле первое слагаемое не зависит от точки x, второе вычисляется адаптивным сумматором, а третье одинаково для всех сравниваемых величин. Таким образом, легко получить нейронную сеть, которая вычислит для каждого класса только первые два слагаемых (рис. 18б).
Второе соображение, позволяющее упростить обучение сети, состоит в отказе от разделения второго и третьего шагов алгоритма.
Алгоритм классификации.
1. На вход нейронной сети, состоящей из одного слоя нейронов, приведенных на рис. 18б, подается вектор x.
2. Номер нейрона, выдавшего минимальный ответ, является номером класса, к которому принадлежит вектор x.
Алгоритм обучения.
1. Полагаем поправки всех синапсов равными нулю.
2. Для каждой точки множества {xp} выполняем следующую процедуру.
1. Предъявляем точку сети для классификации.
2. Пусть при классификации получен ответ — класс l. Тогда для обратного функционирования сети подается вектор Δ, координаты которого определяются по следующему правилу:
3. Вычисленные для данной точки поправки добавляются к ранее вычисленным.
3. Для каждого нейрона производим следующую процедуру.
1. Если поправка, вычисленная последним синапсом равна 0, то нейрон удаляется из сети.
2. Полагаем параметр обучения равным величине, обратной к поправке, вычисленной последним синапсом.
3. Вычисляем сумму квадратов накопленных в первых n синапсах поправок и, разделив на –2, заносим в поправку последнего синапса.
4. Проводим шаг обучения с параметрами h1=0, h2=-2.
4. Если вновь вычисленные синаптические веса отличаются от полученных на предыдущем шаге, то переходим к первому шагу алгоритма.
В пояснении нуждается только второй и третий шаги алгоритма. Из рис. 18в видно, что вычисленные на шаге 2.2 алгоритма поправки будут равны нулю для всех нейронов, кроме нейрона, выдавшего минимальный сигнал. У нейрона, выдавшего минимальный сигнал, первые n поправок будут равны координатам распознававшейся точки x, а поправка последнего синапса равна единице. После завершения второго шага алгоритма поправка последнего синапса i-го нейрона будет равна числу точек, отнесенных к i-му классу, а поправки остальных синапсов этого нейрона равны сумме соответствующих координат всех точек i — о класса. Для получения правильных весов остается только разделить все поправки первых n синапсов на поправку последнего синапса, положить последний синапс равным сумме квадратов полученных величин, а остальные синапсы — полученным для них поправкам, умноженным на –2. Именно это и происходит при выполнении третьего шага алгоритма.
(обратно)Персептрон Розенблатта
Персептрон Розенблатта [146, 181] является исторически первой обучаемой нейронной сетью. Существует несколько версий персептрона. Рассмотрим классический персептрон — сеть с пороговыми нейронами и входными сигналами, равными нулю или единице. Опираясь на результаты, изложенные в работе [146] можно ввести следующие ограничения на структуру сети.
1. Все синаптические веса могут быть целыми числами.
2. Многослойный персептрон по своим возможностям эквивалентен двухслойному. Все нейроны имеют синапс, на который подается постоянный единичный сигнал. Вес этого синапса далее будем называть порогом. Каждый нейрон первого слоя имеет единичные синаптические веса на всех связях, ведущих от входных сигналов, и его порог равен числу входных сигналов сумматора, уменьшенному на два и взятому со знаком минус.
Таким образом, можно ограничиться рассмотрением только двухслойных персептронов с не обучаемым первым слоем. Заметим, что для построения полного первого слоя пришлось бы использовать 2n нейронов, где n — число входных сигналов персептрона. На рис. 19а приведена схема полного персептрона для трехмерного вектора входных сигналов. Поскольку построение такой сети при достаточно большом n невозможно, то обычно используют некоторое подмножество нейронов первого слоя. К сожалению, только полностью решив задачу можно точно указать необходимое подмножество. Обычно используемое подмножество выбирается исследователем из каких-то содержательных соображений или случайно.
Классический алгоритм обучения персептрона является частным случаем правила Хебба. Поскольку веса связей первого слоя персептрона являются не обучаемыми, веса нейрона второго слоя в дальнейшем будем называть просто весами. Будем считать, что при предъявлении примера первого класса персептрон должен выдать на выходе нулевой сигнал, а при предъявлении примера второго класса — единичный. Ниже приведено описание алгоритма обучения персептрона.
1. Полагаем все веса равными нулю.
2. Проводим цикл предъявления примеров. Для каждого примера выполняется следующая процедура.
1. Если сеть выдала правильный ответ, то переходим к шагу 2.4.
2. Если на выходе персептрона ожидалась единица, а был получен ноль, то веса связей, по которым прошел единичный сигнал, уменьшаем на единицу.
3. Если на выходе персептрона ожидался ноль, а была получена единица, то веса связей, по которым прошел единичный сигнал, увеличиваем на единицу.
4. Переходим к следующему примеру. Если достигнут конец обучающего множества, то переходим к шагу 3, иначе возвращаемся на шаг 2.1.
3. Если в ходе выполнения второго шага алгоритма хоть один раз выполнялся шаг 2.2 или 2.3 и не произошло зацикливания, то переходим к шагу 2. В противном случае обучение завершено.
В этом алгоритме не предусмотрен механизм отслеживания зацикливания обучения. Этот механизм можно реализовывать по разному. Наиболее экономный в смысле использования дополнительной памяти имеет следующий вид.
1. k=1; m=0. Запоминаем веса связей.
2. После цикла предъявлений образов сравниваем веса связей с запомненными. Если текущие веса совпали с запомненными, то произошло зацикливание. В противном случае переходим к шагу 3.
3. m=m+1. Если m<k, то переходим ко второму шагу.
4. k=2k;m=0. Запоминаем веса связей и переходим к шагу 2.
Поскольку длина цикла конечна, то при достаточно большом k зацикливание будет обнаружено.
Для использования в обучении сети обратного функционирования, необходимо переписать второй шаг алгоритма обучения в следующем виде.
2. Проводим цикл предъявления примеров. Для каждого примера выполняется следующая процедура.
2.1. Если сеть выдала правильный ответ, то переходим к шагу 2.5.
2.2. Если на выходе персептрона ожидалась единица, а был получен ноль, то на выход сети при обратном функционировании подаем Δ=-1.
2.3. Если на выходе персептрона ожидался ноль, а была получена единица, то на выход сети при обратном функционировании подаем Δ=1.
2.4. Проводим шаг обучения с единичными параметрами.
2.5. Переходим к следующему примеру. Если достигнут конец обучающего множества, то переходим к шагу 3, иначе возвращаемся на шаг 2.1.
На рис. 19в приведена схема обратного функционирования нейрона второго слоя персептрона. Учитывая, что величины входных сигналов этого нейрона равны нулю или единице, получаем эквивалентность модифицированного алгоритма исходному. Отметим также, что при обучении персептрона впервые встретились не обучаемые параметры — веса связей первого слоя.
(обратно) (обратно) (обратно)Лекция 10. Оценка и интерпретатор ответа
Эта глава посвящена обзору различных видов оценок, способам их вычисления. В ней так же рассмотрен способ определения уровня уверенности сети в выданном ответе и приведен способ построения оценок, позволяющих определять уровень уверенности. Приведен основной принцип проектирования оценки — надо учить сеть тому, что мы хотим от нее получить.
Основные функции, которые должна выполнять оценка:
1. Вычислять оценку решения, выданного сетью.
2. Вычислять производные этой оценки по выходным сигналам сети.
Кроме оценок, в первом разделе этой главы рассмотрен другой, тесно связанный с ней объект — интерпретатор ответа. Основное назначение этого объекта — интерпретировать выходной вектор сети как ответ, понятный пользователю. Однако, при определенном построении интерпретатора и правильно построенной по нему оценке, интерпретатор ответа может также оценивать уровень уверенности сети в выданном ответе.
При частичной аппаратной реализации нейрокомпьютера включение функции оценки в аппаратную часть не эффективно, поскольку оценка является сложным устройством (многие функции оценки включают в себя операции сортировки, и другие аналогичные операции). Однако при аппаратной реализации обученной нейронной сети (даже если предусматривается доучивание сети) аппаратная реализация интерпретатора ответа может оказаться эффективной, поскольку для обученной сети интерпретатор уже не меняется, и по сравнению с оценкой интерпретатор ответа достаточно прост.
Интерпретатор ответа
Как было показано в главе «Описание нейронных сетей», ответ, выдаваемый нейронной сетью, как правило, является числом, из диапазона [a,b]. Если ответ выдается несколькими нейронами, то на выходе сети мы имеем вектор, каждый компонент которого лежит в интервале [a,b]. Если в качестве ответа требуется число из этого диапазона, то мы можем его получить. Однако, в большинстве случаев это не так. Достаточно часто требуемая в качестве ответа величина лежит в другом диапазоне. Например, при предсказании температуры воздуха 25 июня в Красноярске ответ должен лежать в интервале от 5 до 35 градусов Цельсия. Сеть не может дать на выходе такого сигнала. Значит, прежде чем обучать сеть необходимо решить в каком виде будем требовать ответ. В данном случае ответ можно требовать в виде α=(b-a)(T-Tmin)/(Tmax-Tmin)+a, где T — требуемая температура, Tmin и Tmax — минимальная и максимальная температуры, α — ответ, который будем требовать от сети. При интерпретации ответа необходимо проделать обратное преобразование. Если сеть выдала сигнал α, то ответом является величина T=(α-a)(T-Tmin)/(b-a)+Tmin. Таким образом, можно интерпретировать выдаваемый сетью сигнал, как величину из любого, наперед заданного диапазона.
Если при составлении обучающего множества ответ на примеры определялся с некоторой погрешностью, то от сети следует требовать не точного воспроизведения ответа, а попадания в интервал заданной ширины. В этом случае интерпретатор ответа может выдать сообщение о правильности (попадании в интервал) ответа.
Другим, часто встречающимся случаем, является предсказание сетью принадлежности входного вектора одному из заданных классов. Такие задачи называют задачами классификации, а решающие их сети — классификаторами. В простейшем случае задача классификации ставится следующим образом: пусть задано N классов. Тогда нейросеть выдает вектор из N сигналов. Однако, нет единого универсального правила интерпретации этого вектора. Наиболее часто используется интерпретация по максимуму: номер нейрона, выдавшего максимальный по величине сигнал, является номером класса, к которому относится предъявленный сети входной вектор. Такие интерпретаторы ответа называются интерпретаторами, кодирующими ответ номером канала (номер нейрона — номер класса). Все интерпретаторы, использующие кодирование номером канала, имеют один большой недостаток — для классификации на N классов требуется N выходных нейронов. При большом N требуется много выходных нейронов для получения ответа. Однако существуют и другие виды интерпретаторов.
Двоичный интерпретатор. Основная идея двоичного интерпретатора — получение на выходе нейронной сети двоичного кода номера класса. Это достигается двухэтапной интерпретацией:
1. Каждый выходной сигнал нейронной сети интерпретируется как 1, если он больше (a+b)/2, и как 0 в противном случае.
2. Полученная последовательность нулей и единиц интерпретируется как двоичное число.
Двоичный интерпретатор позволяет интерпретировать N выходных сигналов нейронной сети как номер одного из 2N классов.
Порядковый интерпретатор. Порядковый интерпретатор кодирует номер класса подстановкой. Отсортируем вектор выходных сигналов по возрастанию. Вектор, составленный из номеров нейронов последовательно расположенных в отсортированном векторе выходных сигналов, будет подстановкой. Если каждой подстановке приписать номер класса, то такой интерпретатор может закодировать N! классов используя N выходных сигналов.
Уровень уверенности
Часто при решении задач классификации с использованием нейронных сетей недостаточно простого ответа «входной вектор принадлежит K-му классу». Хотелось бы также оценить уровень уверенности в этом ответе. Для различных интерпретаторов вопрос определения уровня уверенности решается по-разному. Однако, необходимо учесть, что от нейронной сети нельзя требовать больше того, чему ее обучили. В этом разделе будет рассмотрен вопрос об определении уровня уверенности для нескольких интерпретаторов, а в следующем будет показано, как построить оценку так, чтобы нейронная сеть позволяла его определить.
1. Кодирование номером канала. Знаковый интерпретатор. Знаковый интерпретатор работает в два этапа.
1. Каждый выходной сигнал нейронной сети интерпретируется как 1, если он больше (a+b)/2, и как 0 в противном случае.
2. Если в полученном векторе только одна единица, то номером класса считается номер нейрона, сигнал которого интерпретирован как 1. В противном случае ответом считается неопределенный номер класса (ответ «не знаю»).
Для того чтобы ввести уровень уверенности для этого интерпретатора потребуем, чтобы при обучении сети для всех примеров было верно неравенство: |-(a+b)/2|≤ε, где i=1,…,N; αi — i-ый выходной сигнал. e — уровень надежности (насколько сильно сигналы должны быть отделены от (a+b)/2 при обучении). В этом случае уровень уверенности R определяется следующим образом:
Таким образом, при определенном ответе уровень уверенности показывает, насколько ответ далек от неопределенного, а в случае неопределенного ответа — насколько он далек от определенного.
2. Кодирование номером канала. Максимальный интерпретатор. Максимальный интерпретатор в качестве номера класса выдает номер нейрона, выдавшего максимальный сигнал. Для такого интерпретатора в качестве уровня уверенности естественно использовать некоторую функцию от разности между максимальным и вторым по величине сигналами. Для этого потребуем, чтобы при обучении для всех примеров обучающего множества разность между максимальным и вторым по величине сигналами была не меньше уровня надежности e. В этом случае уровень уверенности вычисляется по следующей формуле: R=max{1,(αi-αj)/e}, где αi — максимальный, а αj — второй по величине сигналы.
3. Двоичный интерпретатор. Уровень надежности для двоичного интерпретатора вводится так же, как и для знакового интерпретатора при кодировании номером канала.
4. Порядковый интерпретатор. При использовании порядкового интерпретатора в качестве уровня уверенности естественно брать функцию от разности двух соседних сигналов в упорядоченном по возрастанию векторе выходных сигналов. Для этого потребуем, чтобы при обучении для всех примеров обучающего множества в упорядоченном по возрастанию векторе выходных сигналов разность между двумя соседними элементами была не меньше уровня надежности e. В этом случае уровень уверенности можно вычислить по формуле , причем вектор выходных сигналов предполагается отсортированным по возрастанию.
В заключение заметим, что для ответа типа число, ввести уровень уверенности подобным образом невозможно. Пожалуй, единственным способом оценки достоверности результата является консилиум нескольких сетей — если несколько сетей обучены решению одной и той же задачи, то в качестве ответа можно выбрать среднее значение, а по отклонению ответов от среднего можно оценить достоверность результата.
Построение оценки по интерпретатору
Если в качестве ответа нейронная сеть должна выдать число, то естественной оценкой является квадрат разности выданного сетью выходного сигнала и правильного ответа. Все остальные оценки для обучения сетей решению таких задач являются модификациями данной. Приведем пример такой модификации. Пусть при составлении задачника величина , являющаяся ответом, измерялась с некоторой точностью e. Тогда нет смысла требовать от сети обучиться выдавать в качестве ответа именно величину . Достаточно, если выданный сетью ответ попадет в интервал . Оценка, удовлетворяющая этому требованию, имеет вид:
Эту оценку будем называть оценкой числа с допуском e.
Для задач классификации также можно пользоваться оценкой типа суммы квадратов отклонений выходных сигналов сети от требуемых ответов. Однако, эта оценка плоха тем, что, во-первых, требования при обучении сети не совпадают с требованиями интерпретатора, во-вторых, такая оценка не позволяет оценить уровень уверенности сети в выданном ответе. Достоинством такой оценки является ее универсальность. Опыт работы с нейронными сетями, накопленный красноярской группой НейроКомп, свидетельствует о том, что при использовании оценки, построенной по интерпретатору, в несколько раз возрастает скорость обучения.
Для оценок, построенных по интерпретатору потребуется следующая функция оценки
и ее производная
Рассмотрим построение оценок по интерпретатору для четырех рассмотренных в предыдущем разделе интерпретаторов ответа.
1. Кодирование номером канала. Знаковый интерпретатор. Пусть для рассматриваемого примера правильным ответом является k-ый класс. Тогда вектор выходных сигналов сети должен удовлетворять следующей системе неравенств:
где e — уровень надежности.
Оценку, вычисляющую расстояние от точки a в пространстве выходных сигналов до множества точек, удовлетворяющих этой системе неравенств, можно записать в виде:
Производная оценки по i-му выходному сигналу равна
2. Кодирование номером канала. Максимальный интерпретатор. Пусть для рассматриваемого примера правильным ответом является k-ый класс. Тогда вектор выходных сигналов сети должен удовлетворять следующей системе неравенств: αk-e≥αi при i≠k. Оценкой решения сетью данного примера является расстояние от точки a в пространстве выходных сигналов до множества точек, удовлетворяющих этой системе неравенств. Для записи оценки, исключим из вектора выходных сигналов сигнал αk, а остальные сигналы отсортируем по убыванию. Обозначим величину αk-e через β0, а вектор отсортированных сигналов через β1≥β2≥…≥βN-1. Система неравенств в этом случае приобретает вид β0≥βi, при i>1. Множество точек удовлетворяющих этой системе неравенств обозначим через D. Очевидно, что если β0≥β1, то точка b принадлежит множеству D. Если β0<β1, то найдем проекцию точки b на гиперплоскость β0=β1. Эта точка имеет координаты
Если , то точка β¹ принадлежит множеству D. Если нет, то точку b нужно проектировать на гиперплоскость β0=β1=β2. Найдем эту точку. Ее координаты можно записать в следующем виде (b,b,b,β3,…,βN-1). Эта точка обладает тем свойством, что расстояние от нее до точки b минимально. Таким образом, для нахождения величины b достаточно взять производную от расстояния по b и приравнять ее к нулю:
Из этого уравнения находим b и записываем координаты точки β²:
Эта процедура продолжается дальше, до тех пор, пока при некотором l не выполнится неравенство
или пока l не окажется равной N–1. Оценкой является расстояние от точки b до точки
Она равна следующей величине
Производная оценки по выходному сигналу βm равна
Для перехода к производным по исходным выходным сигналам αi необходимо обратить сделанные на первом этапе вычисления оценки преобразования.
3. Двоичный интерпретатор. Оценка для двоичного интерпретатора строится точно также как и для знакового интерпретатора при кодировании номером канала. Пусть правильным ответом является k-ый класс, тогда обозначим через K множество номеров сигналов, которым в двоичном представлении k соответствуют единицы. При уровне надежности оценка задается формулой:
Производная оценки по i-му выходному сигналу равна:
4. Порядковый интерпретатор. Для построения оценки по порядковому интерпретатору необходимо предварительно переставить компоненты вектора a в соответствии с подстановкой, кодирующей правильный ответ. Обозначим полученный в результате вектор через βº. Множество точек, удовлетворяющих условию задачи, описывается системой уравнений , где e — уровень надежности. Обозначим это множество через D. Оценка задается расстоянием от точки b до проекции этой точки на множество D. Опишем процедуру вычисления проекции.
1. Просмотрев координаты точки βº, отметим те номера координат, для которых нарушается неравенство βºi+e≤βºi+1.
2. Множество отмеченных координат либо состоит из одной последовательности последовательных номеров i,i+1,…,i+l, или из нескольких таких последовательностей. Найдем точку β¹, которая являлась бы проекцией точки βº на гиперплоскость, определяемую уравнениями β¹i+e≤β¹i+1, где i пробегает множество индексов отмеченных координат. Пусть множество отмеченных координат распадается на n последовательностей, каждая из которых имеет вид , где m — номер последовательности. Тогда точка β¹ имеет вид:
3. Точка β¹ является проекцией, и следовательно, расстояние от βº до β¹ должно быть минимальным. Это расстояние равно
Для нахождения минимума этой функции необходимо приравнять к нулю ее производные по γm. Получаем систему уравнений
Решая ее, находим
4. Если точка удовлетворяет неравенствам, приведенным в первом пункте процедуры, то расстояние от нее до точки βº является оценкой. В противном случае, повторяем первый шаг процедуры, используя точку β¹ вместо βº; Объединяем полученный список отмеченных компонентов со списком, полученным при поиске предыдущей точки; находим точку β², повторяя все шаги процедуры, начиная со второго.
Отметим, что в ходе процедуры число отмеченных последовательностей соседних индексов не возрастает. Некоторые последовательности могут сливаться, но новые возникать не могут. После нахождения проекции можно записать оценку:
Обозначим через Im m-ую последовательность соседних координат, выделенную при последнем исполнении первого шага процедуры вычисления оценки: Im={im,im+1,…,im+lm}. Тогда производную оценки по выходному сигналу βºi можно записать в следующем виде:
Таким образом, построение оценки по интерпретатору сводится к следующей процедуре.
1. Определяем множество допустимых точек, то есть таких точек в пространстве выходных сигналов, которые интерпретатор ответа будет интерпретировать как правильный ответ со стопроцентным уровнем уверенности.
2. Находим проекцию выданной сетью точки на это множество. Проекцией является ближайшая точка из множества.
3. Записываем оценку как расстояние от точки, выданной сетью, до ее проекции на множество допустимых точек. Оценка обучающего множества. Вес примера
В предыдущем разделе был рассмотрен ряд оценок, позволяющих оценить решение сетью конкретного примера. Однако, ситуация, когда сеть хотят обучить решению только одного примера, достаточно редка. Обычно сеть должна научиться решать все примеры обучающего множества. Ряд алгоритмов обучения, которые будут рассматриваться в главе «Учитель», требуют возможности обучать сеть решению всех примеров одновременно и, соответственно, оценивать решение сетью всех примеров обучающего множества. Как уже отмечалось, обучение нейронной сети — это процесс минимизации в пространстве обучаемых параметров функции оценки. Большинство алгоритмов обучения используют способность нейронных сетей быстро вычислять вектор градиента функции оценки по обучаемым параметрам. Обозначим оценку отдельного примера через Hi, а оценку всего обучающего множества через HOM. Простейший способ получения HOM из Hi — простая сумма. При этом вектор градиента вычисляется очень просто:
Таким образом, используя способность сети вычислять градиент функции оценки решения одного примера, можно получить градиент функции оценки всего обучающего множества.
Обучение по всему обучающему множеству позволяет задействовать дополнительные механизмы ускорения обучения. Большинство этих механизмов будет рассмотрено в главе «Учитель». В этом разделе будет рассмотрен только один из них — использование весов примеров. Использование весов примеров может быть вызвано одной из следующих причин.
Один из примеров плохо обучается.
Число примеров разных классов в обучающем множестве сильно отличаются друг от друга.
Примеры в обучающем множестве имеют различную достоверность.
Рассмотрим первую причину — пример плохо обучается. Под «плохо обучается» будем понимать медленное снижение оценки данного примера по отношению к снижению оценки по обучающему множеству. Для того чтобы ускорить обучение данного примера, ему можно приписать вес, больший, чем у остальных примеров. При этом оценка по обучающему множеству и ее градиент можно записать в следующем виде: где wi — вес i-го примера. Эту функцию оценки будем называть оценкой взвешенных примеров. При этом градиент, вычисленный по оценке решения сетью этого примера, войдет в суммарный градиент с большим весом, и, следовательно, сильнее повлияет на выбор направления обучения. Этот способ применим также и для коррекции проблем, связанных со второй причиной — разное число примеров разных классов. Однако в этом случае увеличиваются веса всем примерам того класса, в котором меньше примеров. Опыт показывает, что использование весов в таких ситуациях позволяет улучшить обобщающие способности сетей.
В случае различной достоверности примеров в обучающем множестве функция взвешенных примеров не применима. Действительно, если известно, что достоверность ответа в k-ом примере в два раза ниже, чем в l-ом, хотелось бы, чтобы обученная сеть выдавала для k-ого примера в два раза меньший уровень уверенности. Этого можно достичь, если при вычислении оценки k-ого примера будет использоваться в два раза меньший уровень надежности. Оценка обучающего множества в этом случае вычисляется по формуле без весов, а достоверность учитывается непосредственно при вычислении оценки по примеру. Такую оценку будем называть оценкой взвешенной достоверности.
Таким образом, каждый пример может иметь два веса: вес примера и достоверность примера. Кроме того, при решении задач классификации каждый класс может обладать собственным весом. Окончательно функцию оценки по обучающему множеству и ее градиент можно записать в следующем виде:
где wi — вес примера, δi — его достоверность.
(обратно)Глобальные и локальные оценки
В предыдущих разделах был рассмотрен ряд оценок. Эти оценки обладают одним общим свойством — для вычисления оценки по примеру, предъявленному сети, достаточно знать выходной вектор, выданный сетью при решении этого примера, и правильный ответ. Такие оценки будем называть локальными. Приведем точное определение.
Определение. Локальной называется любая оценка, являющаяся линейной комбинацией произвольных непрерывно дифференцируемых функций, каждая из которых зависит от оценки только одного примера.
Использование локальных оценок позволяет обучать сеть решению как отдельно взятого примера, так и всего обучающего множества в целом. Однако существуют задачи, для которых невозможно построить локальную оценку. Более того, для некоторых задач нельзя построить даже обучающее множество. Использование нелокальных оценок возможно даже при решении задач классификации.
Приведем два примера нелокальных оценки.
Кинетическая оценка для задачи классификации. Пусть в обучающее множество входят примеры k классов. Требуется обучить сеть так, чтобы в пространстве выходных сигналов множества примеров разных классов были попарно линейно разделимы.
Пусть сеть выдает N выходных сигналов. Для решения задачи достаточно, чтобы в ходе обучения все точки в пространстве выходных сигналов, соответствующие примерам одного класса, собирались вокруг одной точки — центра концентрации класса, и чтобы центры концентрации разных классов были как можно дальше друг от друга. В качестве центра концентрации можно выбрать барицентр множества точек, соответствующих примерам данного класса.
Таким образом, функция оценки должна состоять из двух компонентов: первая реализует притяжение между примерами одного класса и барицентром этого класса, а вторая отвечает за отталкивание барицентров разных классов. Обозначим точку в пространстве выходных сигналов, соответствующую m-му примеру, через αm, множество примеров i-го класса через Ii, барицентр точек, соответствующих примерам этого класса, через Bi (), число примеров в i-ом классе через |Bi|, а расстояние между точками a и b через . Используя эти обозначения, можно записать притягивающий компонент функции оценки для всех примеров i-го класса в виде:
Функция оценки HPi обеспечивает сильное притяжение для примеров, находящихся далеко от барицентра. Притяжение ослабевает с приближением к барицентру. Компонент функции оценки, отвечающий за отталкивание барицентров разных классов, должен обеспечивать сильное отталкивание близких барицентров и ослабевать с удалением барицентров друг от друга. Такими свойствами обладает гравитационное отталкивание. Используя гравитационное отталкивание можно записать второй компонент функции оценки в виде:
Таким образом, оценку, обеспечивающую сближение точек, соответствующих примерам одного класса, и отталкивание барицентров, можно записать в виде:
Вычислим производную оценки по j-му выходному сигналу, полученному при решении i-го примера. Пусть i-ый пример принадлежит l-му классу. Тогда производная имеет вид:
Эту оценку будем называть кинетической. Существует одно основное отличие этой оценки от всех других, ранее рассмотренных, оценок для решения задач классификации. При использовании традиционных подходов, сначала выбирают интерпретатор ответа, затем строят по выбранному интерпретатору функцию оценки, и только затем приступают к обучению сети. Для кинетической оценки такой подход не применим. Действительно, до того как будет закончено обучение сети невозможно построить интерпретатор. Кроме того, использование кинетической оценки, делает необходимым обучение сети решению всех примеров обучающего множества одновременно. Это связанно с невозможностью вычислить оценку одного примера. Кинетическая оценка, очевидно, не является локальной: для вычисления производных оценки по выходным сигналам примера необходимо знать барицентры всех классов, для вычисления которых, в свою очередь, необходимо знать выходные сигналы, получаемые при решении всех примеров обучающего множества.
Интерпретатор для кинетической оценки строится следующим образом. Для построения разделителя i-го и j-го классов строим плоскость, перпендикулярную к вектору (Bi-Bj). Уравнение этой плоскости можно записать в виде
Для определения константы D находим среди точек i-го класса ближайшую к барицентру j-го класса. Подставляя координаты этой точки в уравнение гиперплоскости, получаем уравнение на D. Решив это уравнение, находим величину D1. Используя ближайшую к барицентру i-го класса точку j-го класса, находим величину D2. Искомая константа D находится как среднее арифметическое между D1 и D2. Для отнесения произвольного вектора к i-му или j-му классу достаточно подставить его значения в левую часть уравнения разделяющей гиперплоскости. Если значение левой части уравнения получается больше нуля, то вектор относится к j-му классу, в противном случае — к i-му.
Интерпретатор работает следующим образом: если для i-го класса все разделители этого класса с остальными классами выдали ответ i-ый класс, то окончательным ответом является i-ый класс. Если такого класса не нашлось, то ответ «не знаю». Ситуация, когда для двух различных классов все разделители подтвердили принадлежность к этому классу, невозможна, так как разделитель этих двух классов должен был отдать предпочтение одному из них.
Рассмотренный пример решения задачи с использованием нелокальной оценки позволяет выделить основные черты обучения с нелокальной оценкой:
1. Невозможность оценить решение одного примера.
2. Невозможность оценить правильность решения примера до окончания обучения.
3. Невозможность построения интерпретатора ответа до окончания обучения.
Этот пример является отчасти надуманным, поскольку его можно решить с использованием более простых локальных оценок. Ниже приведен пример задачи, которую невозможно решить с использованием локальных оценок.
Генератор случайных чисел. Необходимо обучить сеть генерировать последовательность случайных чисел из диапазона [0,1]с заданными k первыми моментами. Напомним, что для выборки роль первого момента играет среднее значение, второго — средний квадрат, третьего — средний куб и так далее. Есть два пути решения этой задачи. Первый — используя стандартный генератор случайных чисел подготовить задачник и обучить по нему сеть. Этот путь плох тем, что такой генератор будет просто воспроизводить последовательность чисел, записанную в задачнике. Для получения такого результата можно просто хранить задачник.
Второй вариант — обучать сеть без задачника! Пусть нейросеть принимает один входной сигнал и выдает один выходной. При использовании сети выходной сигнал первого срабатывания сети (первое случайное число) будет служить входным сигналом для второго срабатывания сети и так далее.
Для построения оценки зададимся тремя наборами чисел: Mi — необходимое значение i-го момента, Li — длина последовательности, на которой i-ый момент сгенерированной последовательности должен не более чем на si отличаться от Mi. si — точность вычисления i-го момента.
Выборочная оценка совпадения i-го момента в сгенерированной последовательности на отрезке, начинающемся с j-го случайного числа, вычисляется по следующей формуле:
где αl — выходной сигнал, полученный на l-ом срабатывании сети. Для оценки точности совпадения i-го момента в сгенерированной последовательности на отрезке, начинающемся с j-го случайного числа, воспользуемся оценкой числа с допуском si:
Таким образом, при обучении сети генерации последовательности из N случайных чисел оценку можно записать в следующем виде:
Производная оценки по выходному сигналу l-го срабатывания сети можно записать в следующем виде:
Используя эту оценку можно обучать сеть генерировать случайные числа. Удобство этого подхода к решению задачи обучения генератора случайных чисел в том, что можно достаточно часто менять инициирующий сеть входной сигнал, что позволит сети генерировать не одну, а много различных последовательностей, обладающих всеми необходимыми свойствами.
При использовании предложенной оценки нет никаких гарантий того, что в генерируемой сетью последовательности не появятся сильно скоррелированные подпоследовательности. Для удаления корреляций можно модифицировать оценку так, чтобы она возрастала при появлении корреляций. Рассмотрим две подпоследовательности длинны L, первая из которых начинается с αi, а другая с αi+k. Коэффициент корреляции этих последовательностей записывается в виде:
В этой формуле приняты следующие обозначения: — среднее по последовательности, начинающейся с αi; — средний квадрат последовательности начинающейся с αi. Вычисление такого коэффициента корреляции довольно долгий процесс. Однако вместо выборочных моментов в формулу можно подставить значения моментов, которые последовательность должна иметь. В этом случае формула сильно упрощается:
Добавку для удаления корреляций последовательностей длиной от L1 до L2 и смещенных друг относительно друга на смещения от h1 до h2 можно записать в виде:
При необходимости можно ввести и другие поправки, учитывающие требования к генератору случайных чисел.
Составные интерпретатор ответа и оценка
При использовании нейронных сетей для решения различных задач возникает необходимость получать от сети не один ответ, а несколько. Например, при обучении сети решению задачи диагностики отклонений в реакции на стресс нейронная сеть должна была определить наличие или отсутствие тринадцати различных патологий. Если одна сеть может выдавать только один ответ, то для решения задачи необходимо задействовать тринадцать сетей. Однако в этом нет необходимости. Поскольку каждый ответ, который должна выдавать сеть, имеет только два варианта, то можно использовать для его получения классификатор на два класса. Для такого классификатора необходимо два выходных сигнала. Тогда для решения задачи достаточно получать 26 выходных сигналов: первые два сигнала — для определения первой патологии, третий и четвертый — для второй и так далее. Таким образом, интерпретатор ответа для этой задачи состоит из тринадцати интерпретаторов, а оценка из тринадцати оценок. Более того, нет никаких ограничений на типы используемых интерпретаторов или оценок. Возможна комбинация, например, следующих ответов: число с допуском, классификатор на восемь классов, случайное число.
При использовании таких составных оценок и интерпретаторов каждый из этих компонентов должен следить за тем, чтобы каждая частная оценка или интерпретатор получали на вход те данные, которые им необходимы.
Лекция 11.1. Исполнитель
Компонент исполнитель является служебным. Это означает, что он универсален и невидим для пользователя. В отличие от всех других компонентов исполнитель не выполняет ни одной явной функции в обучении нейронных сетей, а является вспомогательным для компонентов учитель и контрастер. Задача этого компонента — упростить работу компонентов учитель и контрастер. Этот компонент выполняет всего несколько запросов, преобразуя каждый из них в последовательность запросов к различным компонентам. В данной главе содержательно рассмотрены алгоритмы исполнения всех запросов исполнителя.
Как было описано в главе «Двойственные сети», исполнитель выполняет четыре вида запросов.
1. Тестирование решения примера.
2. Оценивание решения примера.
3. Оценивание решения примера с вычислением градиента.
4. Оценивание и тестирование решения примера.
Таблица 1. Параметры запроса для позадачной работы
Название параметра 1 2 3 4 Перейти к следующему примеру +/– +/– +/– +/– Остановиться в конце обучающего множества +/– +/– +/– +/– Вычислять оценку – + + + Интерпретировать ответ + – – + Вычислять градиент – – + – Подготовка к контрастированию – – +/– –Все перечисленные запросы работают с текущей сетью и текущим примером задачника. Однако компоненту задачник необходимо указать, какой пример подлежит обработке. Кроме того, в главе «Оценка и интерпретатор ответа» введен класс оценок, вычисляемых по всему обучающему множеству. Такие оценки позволяют существенно улучшить обучаемость сети и ускорить ее обучение. Нет смысла возлагать перебор примеров на учителя, поскольку это снижает полезность компонента исполнитель. Таким образом, возникает еще четыре вида запросов.
Тестирование решения всех примеров обучающего множества.
Оценивание решения всех примеров обучающего множества.
Оценивание решения всех примеров обучающего множества с вычислением градиента.
Оценивание и тестирование решения всех примеров обучающего множества.
Как уже отмечалось в главе «Двойственные сети», каждую из приведенных четверок запросов можно объединить в один запрос с параметрами. В табл. 1 приведен полный список параметров для первой четверки запросов, а в табл. 2 — для второй.
Таблица 2. Параметры запроса для обучающего множества в целом
Название параметра 5 6 7 8 Вычислять оценку – + + + Интерпретировать ответ + – – + Вычислять градиент – – + – Подготовка к контрастированию – – +/– –Символ «+» означает, что в запросе, номер которого указан в первой строке колонки, возможность, задаваемая данным параметром, должна быть использована. Символ «–» — что связанная с данным параметром возможность не используется. Символы «+/–» означают, что запрос может, как использовать, так и не использовать данную возможность. Отметим, что подготовка к контрастированию может быть задействована, только если производится вычисление градиента, а вычисление градиента невозможно без вычисления оценки. Остальные параметры независимы.
Отбор примеров в обучающее множество, открытие сеанса работы с задачником должны выполняться учителем или контрастером. Исполнитель только организует перебор примеров в обучающем множестве.
При полной или частичной аппаратной реализации нейрокомпьютера компонент исполнитель эффективно реализуется аппаратно, по следующим причинам.
Исполнитель реализует исключительно связные функции по отношению к другим компонентам.
Исполняемые им запросы постоянны и не зависят от реализаций других компонентов нейрокомпьютера.
Этот компонент работает чаще, чем любой другой, и, как следствие, ускорение в работе исполнителя приводит к соизмеримому ускорению работы нейрокомпьютера.
(обратно)Лекция 11.2, 12. Учитель
Этот компонент не является столь универсальным как задачник, оценка или нейронная сеть, поскольку существует ряд алгоритмов обучения жестко привязанных к архитектуре нейронной сети. Примерами таких алгоритмов могут служить обучение (формирование синаптической карты) сети Хопфилда [312], обучение сети Кохонена [ 31, 132] и ряд других аналогичных сетей. Однако в главе «Описание нейронных сетей» приводится способ формирования сетей, позволяющий обучать сети Хопфилда [312] и Кохонена [131, 132] методом обратного распространения ошибки. Описываемый в этой главе компонент учитель ориентирован в первую очередь на обучение двойственных сетей (сетей обратного распространения ошибки).
Что можно обучать методом двойственности
Как правило, метод двойственности (обратного распространения ошибки) используют для подстройки параметров нейронной сети. Однако, как было показано в главе «Описание нейронных сетей», сеть может вычислять не только градиент функции оценки по обучаемым параметрам сети, но и по входным сигналам сети. Используя градиент функции оценки по входным сигналам сети можно решать задачу, обратную по отношению к обучению нейронной сети.
Рассмотрим следующий пример. Пусть есть сеть, обученная предсказывать по текущему состоянию больного и набору применяемых лекарств состояние больного через некоторый промежуток времени. Поступил новый больной. Его параметры ввели сети и она выдала прогноз. Из прогноза следует ухудшение некоторых параметров состояния больного. Возьмем выданный сетью прогноз, заменим значения параметров, по которым наблюдается ухудшение, на желаемые значения. Полученный вектор ответов объявим правильным ответом. Имея правильный ответ и ответ, выданный сетью, вычислим градиент функции оценки по входным сигналам сети. В соответствии со значениями элементов градиента изменим значения входных сигналов сети так, чтобы оценка уменьшилась. Проделав эту процедуру несколько раз, получим вектор входных сигналов, порождающих правильный ответ. Далее врач должен определить, каким способом (какими лекарствами или процедурами) перевести больного в требуемое (полученное в ходе обучения входных сигналов) состояние. В большинстве случаев часть входных сигналов не подлежит изменению (например пол или возраст больного). В этом случае эти входные сигналы должны быть помечены как не обучаемые (см. использование маски обучаемости входных сигналов в главе «Описание нейронных сетей»).
Таким образом, способность сетей вычислять градиент функции оценки по входным параметрам сети позволяет решать вполне осмысленную обратную задачу: так подобрать входные сигналы сети, чтобы выходные сигналы удовлетворяли заданным требованиям.
Кроме того, использование нейронных сетей позволяет ставить новые вопросы перед исследователем. В практике группы «НейроКомп» был следующий случай. Была поставлена задача обучить сеть ставить диагноз вторичного иммунодефицита по данным анализов крови и клеточного метаболизма. Вся обучающая выборка была разбита на два класса: больные и здоровые. При анализе базы данных стандартными статистическими методами значимых отличий обнаружить не удалось. Сеть оказалась не способна обучиться. Далее у исследователя было два пути: либо увеличить число нейронов в сети, либо определить, что мешает обучению. Исследователи выбрали второй путь. При обучении сети была применена следующая процедура: как только обучение сети останавливалось из-за невозможности дальнейшего уменьшения оценки, пример, имеющий наихудшую оценку, исключался из обучающего множества. После того, как сеть обучилась решению задачи на усеченном обучающем множестве, был проведен анализ исключенных примеров. Выяснилось, что исключено около половины больных. Тогда множество больных было разбито на два класса — больные1 (оставшиеся в обучающем множестве) и больные2 (исключенные). При таком разбиении обучающей выборки стандартные методы статистики показали значимые различия в параметрах классов. Обучение сети классификации на три класса быстро завершилось полным успехом. При содержательном анализе примеров, составляющих классы больные1 и больные2, было установлено, что к классу болные1 относятся больные на завершающей стадии заболевания, а к классу больные2 — на начальной. Ранее такое разбиение больных не проводилось. Таким образом, обучение нейронной сети решению прикладной задачи поставило перед исследователем содержательный вопрос, позволивший получить новое знание о предметной области.
Подводя итоги этого раздела, можно сказать, что, используя метод двойственности в обучении нейронных сетей можно:
1. Обучать сеть решению задачи.
2. Подбирать входные данные так, чтобы на выходе нейронной сети был заданный ответ.
3. Ставить вопросы о соответствии входных данных задачника постановке нейросетевой задачи.
Задача обучения сети
С точки зрения математики, задача обучения нейронной сети является задачей минимизации множества функций многих переменных. Речь идет именно о неструктурированном множестве функций, зависящих от одних и тех же переменных. Под переменными понимаются обучаемые параметры сети, а под функциями — оценки решения сетью отдельных примеров. Очевидно, что сформулированная выше задача является как минимум трудно разрешимой, а часто и просто некорректной.
Основная проблема состоит в том, что при оптимизации первой функции, значения других функций не контролируются. И наоборот, при оптимизации всех других функций не контролируется значение первой функции. Если обучение устроено по циклу — сначала оптимизация первой функции, потом второй и т. д., то после завершения цикла значение любой из функций может оказаться не меньше, а больше чем до начала обучения. Такой подход к обучению нейронных сетей привел к появлению различных методов «коррекции» данной трудности. Так, например, появилось правило, что нельзя «сильно» оптимизировать оценку отдельного примера, для того, чтобы при оптимизации сеть «не сильно» забывала остальные примеры. Возникли различные правила «правильного» перебора примеров и т. д. Наиболее ярким примером такого правила является случайный перебор примеров, рекомендованный для обучения сетей, обучаемых без учителя (сетей Кохонена [131, 132]). Однако все эти правила не гарантировали быстрого достижения результата. Более того, часто результат вообще не достигался за обозримое время.
Альтернативой всем правилам «малой оптимизации» и «правильного перебора примеров» является выработка единой функции оценки всего обучающего множества. Правила построения оценки обучающего множества из оценок отдельных примеров приведены в главе «Оценка и интерпретатор ответа».
В случае использования оценки обучающего множества, математическая интерпретация задачи приобретает классический вид задачи минимизации функции в пространстве многих переменных. Для этой классической задачи существует множество известных методов решения [48, 104, 143]. Особенностью обучения нейронных сетей является их способность быстро вычислять градиент функции оценки. Под быстро, понимается тот факт, что на вычисления градиента тратится всего в два-три раза больше времени, чем на вычисление самой функции. Именно этот факт делает градиентные методы наиболее полезными при обучении нейронных сетей. Большая размерность пространства обучаемых параметров нейронной сети (102–106) делает практически неприменимыми все методы, явно использующие матрицу вторых производных.
Описание алгоритмов обучения
Все алгоритмы обучения сетей методом обратного распространения ошибки опираются на способность сети вычислять градиент функции ошибки по обучающим параметрам. Даже правило Хебба использует вектор псевдоградиента, вычисляемый сетью при использовании зеркального порогового элемента (см. раздел «Пороговый элемент» главы «Описание нейронных сетей»). Таким образом, акт обучения состоит из вычисления градиента и собственно обучения сети (модификации параметров сети). Однако, существует множество не градиентных методов обучения, таких, как метод покоординатного спуска, метод случайного поиска и целое семейство методов Монте-Карло. Все эти методы могут использоваться при обучении нейронных сетей, хотя, как правило, они менее эффективны, чем градиентные методы. Некоторые варианты методов обучения описаны далее в этой главе.
Поскольку обучение двойственных сетей с точки зрения используемого математического аппарата эквивалентно задаче многомерной оптимизации, то в данной главе рассмотрены только несколько методов обучения, наиболее используемых при обучении сетей. Более полное представление о методах оптимизации, допускающих использование в обучении нейронных сетей, можно получить из книг по методам оптимизации (см. например [48, 104, 143]).
Краткий обзор макрокоманд учителя
При описании методов используется набор макросов, приведенный в табл. 2. В табл. 2 дано пояснение выполняемых макросами действий. Все макрокоманды могут оперировать с данными как пространства параметров, так и пространства входных сигналов сети. В первой части главы полагается, что объект обучения установлен заранее. В макросах используются понятия и аргументы, приведенные в табл. 1. Список макрокоманд приведен в табл. 2.
Таблица 1. Понятия и аргументы макрокоманд, используемых при описании учителя
Название Смысл Точка Точка в пространстве параметров или входных сигналов. Аналогична вектору. Вектор Вектор в пространстве параметров или входных сигналов. Аналогичен точке. Вектор_минимумов Вектор минимальных значений параметров или входных сигналов. Вектор_максимумов Вектор максимальных значений параметров или входных сигналов. Указатель_на_вектор Адрес вектора. Используется для передачи векторов в макрокоманды. Пустой_указатель Указатель на отсутствующий вектор.При описании методов обучения все аргументы имеют тип, определяемый типом аргумента макрокоманды. Если в описании макрокоманды в табл. 2 тип аргумента не соответствует ни одному из типов, приведенных в табл. 1, то эти аргументы имеют числовой тип.
Таблица 2. Список макрокоманд, используемых для описания учителя
Название Аргументы (типы) Выполняемые действия Модификация_вектора Указатель_на_вектор Старый_Шаг Новый_Шаг Генерирует запрос на модификацию вектора (см. раздел «Провести обучение (Modify)»). Вычислить_градиент Вычисляет градиент функции оценки. Установить_параметры Указатель_на_вектор Скопировать вектор, указанный в аргументе, в текущий вектор. Создать_вектор Указатель_на_вектор Создает экземпляр вектора с неопределенными значениями. Адрес вектора помещается в аргумент. Освободить_вектор Указатель_на_вектор Освобождает память занятую вектором, расположенным по адресу Указатель_на_вектор. Случайный_вектор Указатель_на_вектор В векторе, на который указывает Указатель_на_вектор, генерируется вектор, каждая из координат которого является случайной величиной, равномерно распределенной на интервале между значениями соответствующих координат векторов Вектор_минимумов и Вектор_максимумов. Оптимизация_шага Указатель_на_вектор Начальный_Шаг Производит подбор оптимального шага (см. рис. 3). Сохранить_вектор Указатель_на_вектор Скопировать текущий вектор в вектор, указанный в аргументе. Вычислить_оценку Оценка Вычисляет оценку текущего вектора. Вычисленную величину складывает в аргумент Оценка.Неградиентные методы обучения
Среди неградиентных методов рассмотрим следующие методы, каждый из которых является представителем целого семейства методов оптимизации:
1. Метод случайной стрельбы (представитель семейства методов Монте-Карло).
2. Метод покоординатного спуска (псевдоградиентный метод).
3. Метод случайного поиска (псевдоградиентный метод).
4. Метод Нелдера-Мида.
Метод случайной стрельбы
1. Создать_вектор В1
2. Создать_вектор В2
3. Вычислить_оценку О1
4. Сохранить_вктор В1
5. Установить_параметры В1
6. Случайный_вектор В2
7. Модификация_вектора В2, 0, 1
8. Вычислить_оценку О2
9. Если О2<О1 то переход к шагу 11
10. Переход к шагу 5
11. О1=О2
12. Переход к шагу 4
13. Установить_параметры В1
14. Освободить_вектор В1
15. Освободить_вектор В2
Рис. 1. Простейший алгоритм метода случайной стрельбы
Идея метода случайной стрельбы состоит в генерации большой последовательности случайных точек и вычисления оценки в каждой из них. При достаточной длине последовательности минимум будет найден. Запись этой процедуры на макроязыке приведена на рис. 1
Остановка данной процедуры производится по команде пользователя или при выполнении условия, что О1 стало меньше некоторой заданной величины. Существует огромное разнообразие модификаций этого метода. Наиболее простой является метод случайной стрельбы с уменьшением радиуса. Пример процедуры, реализующей этот метод, приведен на рис. 2. В этом методе есть два параметра, задаваемых пользователем:
Число_попыток — число неудачных пробных генераций вектора при одном радиусе.
Минимальный_радиус — минимальное значение радиуса, при котором продолжает работать алгоритм.
Идея этого метода состоит в следующем. Зададимся начальным состоянием вектора параметров. Новый вектор параметров будем искать как сумму начального и случайного, умноженного на радиус, векторов. Если после Число_попыток случайных генераций не произошло уменьшения оценки, то уменьшаем радиус. Если произошло уменьшение оценки, то полученный вектор объявляем начальным и продолжаем процедуру с тем же шагом. Важно, чтобы последовательность уменьшающихся радиусов образовывала расходящийся ряд. Примером такой последовательности может служить использованный в примере на рис. 2 ряд 1/n.
1. Создать_вектор В1
2. Создать_вектор В2
3. Вычислить_оценку O1
4. Число_Смен_Радиуса=1
5. Радиус=1/Число_Смен_Радиуса
6. Попытка=0
7. Сохранить_вектор В1
8. Установить_параметры В1
9. Случайный_вектор В2
10. Модификация_вектора В2, 1, Радиус
11. Вычислить_оценку О2
12. Попытка=Попытка+1
13. Если 02<01 то переход к шагу 16
14. Если Попытка<=Число_попыток то переход к шагу 8
15. Переход к шагу 18
16. О1=О2
17. Переход к шагу 6
18. Число_Смен_Радиуса= Число_Смен_Радиуса+1
19. Радиус=1/Число_Смен_Радиуса
20. Если радиус >= Минимапьный_радиус то переход к шагу 6
21. Установить_параметры В1
22. Освободить_вектор В1
23. Освободить_вектор В2
Рис. 2. Алгоритм метода случайной стрельбы с уменьшением радиуса
Отмечен ряд случаев, когда метод случайной стрельбы с уменьшением радиуса работает быстрее градиентных методов, но обычно это не так.
Метод покоординатного спуска
Идея этого метода состоит в том, что если в задаче сложно или долго вычислять градиент, то можно построить вектор, обладающий приблизительно теми же свойствами, что и градиент следующим путем. Даем малое положительное приращение первой координате вектора. Если оценка при этом увеличилась, то пробуем отрицательное приращение. Далее так же поступаем со всеми остальными координатами. В результате получаем вектор, в направлении которого оценка убывает. Для вычисления такого вектора потребуется, как минимум, столько вычислений функции оценки, сколько координат у вектора. В худшем случае потребуется в два раза большее число вычислений функции оценки. Время же необходимое для вычисления градиента в случае использования двойственных сетей можно оценить как 2–3 вычисления функции оценки. Таким образом, учитывая способность двойственных сетей быстро вычислять градиент, можно сделать вывод о нецелесообразности применения метода покоординатного спуска в обучении нейронных сетей.
Подбор оптимального шага
Данный раздел посвящен описанию макрокоманды Оптимизация_Шага. Эта макрокоманда часто используется в описании процедур обучения и не столь очевидна как другие макрокоманды. Поэтому ее текст приведен на рис. 3. Идея подбора оптимального шага состоит в том, что при наличии направления в котором производится спуск (изменение параметров) задача многомерной оптимизации в пространстве параметров сводится к одномерной оптимизации — подбору шага. Пусть заданы начальный шаг (Ш2) и направление спуска (антиградиент или случайное) (Н). Тогда вычислим величину О1 — оценку в текущей точке пространства параметров. Изменив параметры на вектор направления, умноженный на величину пробного шага, вычислим величину оценки в новой точке — О2. Если О2 оказалось меньше либо равно О1, то увеличиваем шаг и снова вычисляем оценку. Продолжаем эту процедуру до тех пор, пока не получится оценка, большая предыдущей. Зная три последних значения величины шага и оценки, используем квадратичную оптимизацию — по трем точкам построим параболу и следующий шаг сделаем в вершину параболы. После нескольких шагов квадратичной оптимизации получаем приближенное значение оптимального шага.
1. Создать_вектор В
2. Сохранить_вектор В
3. Вычислить_оценку О1
4. Ш1=0
5. Модификация_вектора Н, 1, Ш2
6. Вычислить_оценку О2
7. Если О1<О2 то переход к шагу 15
8. Ш3=Ш2*3
9. Установить_параметры В
10. Модификация_вектора Н, 1, Ш3
11. Вычислить_оценку О3
12. Если О3>О2 то переход к шагу 21
13. О1=О2 О2=О3 Ш1=Ш2 Ш2=ШЗ
14. Переход к шагу 3
15. ШЗ=Ш2 03=02
16. Ш2=ШЗ/3
17. Установить_параметры В
18. Модификация_вектора Н, 1, Ш2
19. Вычислить_оценку О3
20. Если О2>=О1 то переход к шагу 15
21. Число_парабол=0
22. Ш=((ШЗШЗ-Ш2Ш2)О1+(Ш1Ш1-ШЗШЗ)О2+(Ш2Ш2-Ш1Ш )О3)/(2((ШЗ-Ш2)О1+(Ш1-Ш3)О2 +(Ш2-Ш )О3))
23. Установить_параметры В
24. Модификация_вектора Н, 1, Ш
25. Вычислить_оценку О
26. Если Ш>Ш2 то переход к шагу 32
27. Если О>О2 то переход к шагу 30
28. ШЗ=Ш2 О3=О2 О2=О Ш2=Ш
29. Переход к шагу 36
30. Ш1=Ш О1=О
31. Переход к шагу 36
32. Если О>О2 то переход к шагу 35
33. ШЗ=Ш2 О3=О2 О2=О Ш2=Ш
34. Переход к шагу 36
35. Ш1=Ш О1=О
36. Чиспо_парабол=Число_парабол+1
37. Если Число_парабоп<Максимальное_Число_Парабол то переход к шагу 22
33. Установить_параметры В
39. Модификация_вектора Н, 1, Ш 2
40. Освободить_вектор В
Рис. 3. Алгоритм оптимизации шага
Если после первого пробного шага получилось О2 большее О1, то уменьшаем шаг до тех пор, пока не получим оценку, меньше чем О1. После этого производим квадратичную оптимизацию.
Метод случайного поиска
Этот метод похож на метод случайной стрельбы с уменьшением радиуса, однако в его основе лежит другая идея — сгенерируем случайный вектор и будем использовать его вместо градиента. Этот метод использует одномерную оптимизацию — подбор шага. Одномерная оптимизация описана в разделе «Одномерная оптимизация». Процедура случайного поиска приведена на рис. 4. В этом методе есть два параметра, задаваемых пользователем.
1. Создать_вектор Н
2. Число_Смен_Радиуса=1
3. Попытка=0
4. Радиус=1/Число_Смен_Радиуса
5. Случайный_вектор Н
6. Оптимизация шага Н Радиус
7. Попытка=Попытка+1
8. Если Радиус=0 то Попытка=0
9. Если Попытка<=Число_попыток то переход к шагу 4
10. Число_Смен_Радиуса= Число_Смен_Радиуса+1
11. Радиус=1/Число_Смен_Радиуса
12. Если Радиус>= Минимальный_радиус то переход к шагу 3
13. Освободить_вектор Н
Рис. 4. Алгоритм метода случайного поиска
Число_попыток — число неудачных пробных генераций вектора при одном радиусе.
Минимальный_радиус — минимальное значение радиуса, при котором продолжает работать алгоритм.
Идея этого метода состоит в следующем. Зададимся начальным состоянием вектора параметров. Новый вектор параметров будем искать как сумму начального и случайного, умноженного на радиус, векторов. Если после Число_попыток случайных генераций не произошло уменьшения оценки, то уменьшаем радиус. Если произошло уменьшение оценки, то полученный вектор объявляем начальным и продолжаем процедуру с тем же шагом. Важно, чтобы последовательность уменьшающихся радиусов образовывала расходящийся ряд. Примером такой последовательности может служить использованный в примере на рис. 4 ряд 1/n.
Метод Нелдера-Мида
Этот метод является одним из наиболее быстрых и наиболее надежных не градиентных методов многомерной оптимизации. Идея этого метода состоит в следующем. В пространстве оптимизируемых параметров генерируется случайная точка. Затем строится n- мерный симплекс с центром в этой точке, и длиной стороны l. Далее в каждой из вершин симплекса вычисляется значение оценки. Выбирается вершина с наибольшей оценкой. Вычисляется центр тяжести остальных n вершин. Проводится оптимизация шага в направлении от наихудшей вершины к центру тяжести остальных вершин. Эта процедура повторяется до тех пор, пока не окажется, что оптимизация не изменяет положения вершины. После этого выбирается вершина с наилучшей оценкой и вокруг нее снова строится симплекс с меньшими размерами (например l/2). Процедура продолжается до тех пор, пока размер симплекса, который необходимо построить, не окажется меньше требуемой точности.
Однако, несмотря на свою надежность, применение этого метода к обучению нейронных сетей затруднено большой размерностью пространства параметров.
Градиентные методы обучения
Изучению градиентных методов обучения нейронных сетей посвящено множество работ [47, 65, 90] (сослаться на все работы по этой теме не представляется возможным, поэтому дана ссылка на работы, где эта тема исследована наиболее детально). Кроме того, существует множество публикаций, посвященных градиентным методам поиска минимума функции [48, 104] (как и в предыдущем случае, ссылки даны только на две работы, которые показались наиболее удачными). Данный раздел не претендует на какую-либо полноту рассмотрения градиентных методов поиска минимума. В нем приведены только несколько методов, применявшихся в работе группой «НейроКомп». Все градиентные методы объединены использованием градиента как основы для вычисления направления спуска.
Метод наискорейшего спуска
1. Вычислить_оценку О2
2. О1=О2
3. Вычислить_градиент
4. Оптимизация шага Пустой_указатель Шаг
5. Вычислить_оценку О2
6. Если О1-О2<Точность то переход к шагу 2
Рис. 5. Метод наискорейшего спуска
Наиболее известным среди градиентных методов является метод наискорейшего спуска. Идея этого метода проста: поскольку вектор градиента указывает направление наискорейшего возрастания функции, то минимум следует искать в обратном направлении. Последовательность действий приведена на рис. 5.
Этот метод работает, как правило, на порядок быстрее методов случайного поиска. Он имеет два параметра — Точность, показывающий, что если изменение оценки за шаг метода меньше чем Точность, то обучение останавливается; Шаг — начальный шаг для оптимизации шага. Заметим, что шаг постоянно изменяется в ходе оптимизации шага.
а)
б)
в)
Рис. 6. Траектории спуска при различных конфигурациях окрестности минимума и разных методах оптимизации.
Остановимся на основных недостатках этого метода. Во-первых, эти методом находится тот минимум, в область притяжения которого попадет начальная точка. Этот минимум может не быть глобальным. Существует несколько способов выхода из этого положения. Наиболее простой и действенный — случайное изменение параметров с дальнейшим повторным обучение методом наискорейшего спуска. Как правило, этот метод позволяет за несколько циклов обучения с последующим случайным изменением параметров найти глобальный минимум.
Вторым серьезным недостатком метода наискорейшего спуска является его чувствительность к форме окрестности минимума. На рис. 6а проиллюстрирована траектория спуска при использовании метода наискорейшего спуска, в случае, если в окрестности минимума линии уровня функции оценки являются кругами (рассматривается двумерный случай). В этом случае минимум достигается за один шаг. На рис. 6б приведена траектория метода наискорейшего спуска в случае эллиптических линий уровня. Видно, что в этой ситуации за один шаг минимум достигается только из точек, расположенных на осях эллипсов. Из любой другой точки спуск будет происходить по ломаной, каждое звено которой ортогонально к соседним звеньям, а длина звеньев убывает. Легко показать что для точного достижения минимума потребуется бесконечное число шагов метода градиентного спуска. Этот эффект получил название овражного, а методы оптимизации, позволяющие бороться с этим эффектом — антиовражных.
kParTan
1. Создать_вектор В1
2. Создать_вектор В2
3. Шаг=1
4. Вычислить_оценку О2
5. Сохранить_вектор В1
6. О1=О2
7. N=0
8. Вычислить_градиент
9. Оптимизация_шага Пустой_указатель Шаг
10. N=N+1
11. Если N<k то переход к шагу 8
12. Сохранить_вектор В2
13. В2=В2-В1
14. ШагParTan=1
15. Оптимизация шага В2 ШагParTan
16. Вычислить_оценку О2
17. Если О1-О2<Точность то переход к шагу 5
Рис. 7. Метод kParTan
Одним из простейших антиовражных методов является метод kParTan. Идея метода состоит в том, чтобы запомнить начальную точку, затем выполнить k шагов оптимизации по методу наискорейшего спуска, затем сделать шаг оптимизации по направлению из начальной точки в конечную. Описание метода приведено на рис 7. На рис 6в приведен один шаг оптимизации по методу 2ParTan. Видно, что после шага вдоль направления из первой точки в третью траектория спуска привела в минимум. К сожалению, это верно только для двумерного случая. В многомерном случае направление kParTan не ведет прямо в точку минимума, но спуск в этом направлении, как правило, приводит в окрестность минимума меньшего радиуса, чем при еще одном шаге метода наискорейшего спуска (см. рис. 6б). Кроме того, следует отметить, что для выполнения третьего шага не потребовалось вычислять градиент, что экономит время при численной оптимизации.
Квазиньютоновские методы
Существует большое семейство квазиньютоновских методов, позволяющих на каждом шаге проводить минимизацию в направлении минимума квадратичной формы. Идея этих методов состоит в том, что функция оценки приближается квадратичной формой. Зная квадратичную форму, можно вычислить ее минимум и проводить оптимизацию шага в направлении этого минимума. Одним из наиболее часто используемых методов из семейства одношаговых квазиньютоновских методов является BFGS метод. Этот метод хорошо зарекомендовал себя при обучении нейронных сетей (см. [29]). Подробно ознакомиться с методом BFGS и другими квазиньютоновскими методами можно в работе [48].
Лекции 13, 14. Контрастер
Компонент контрастер предназначен для контрастирования нейронных сетей. Первые работы, посвященные контрастированию (скелетонизации) нейронных сетей появились в начале девяностых годов [64, 323, 340]. Однако, задача контрастирования нейронных сетей не являлась центральной, поскольку упрощение сетей может принести реальную пользу только при реализации обученной нейронной сети в виде электронного (оптоэлектронного) устройства. Только в работе А.Н. Горбаня и Е.М. Миркеса «Логически прозрачные нейронные сети» [83] (более полный вариант работы см. [77]), опубликованной в 1995 году задаче контрастирования нейронных сетей был придан самостоятельный смысл — впервые появилась реальная возможность получать новые явные знания из данных. В связи с тем, что контрастирование нейронных сетей не является достаточно развитой ветвью нейроинформатики, стандарт, приведенный в данной главе, является очень общим.
Задачи для контрастера
Из анализа литературы и опыта работы группы НейроКомп можно сформулировать следующие задачи, решаемые с помощью контрастирования нейронных сетей.
1. Упрощение архитектуры нейронной сети.
2. Уменьшение числа входных сигналов.
3. Сведение параметров нейронной сети к небольшому набору выделенных значений.
4. Снижение требований к точности входных сигналов.
5. Получение явных знаний из данных.
Далее в этом разделе все перечисленные выше задачи рассмотрены более подробно.
Упрощение архитектуры нейронной сети
Стремление к упрощению архитектуры нейронных сетей возникло из попытки ответить на следующие вопрос: «Сколько нейронов нужно использовать и как они должны быть связаны друг с другом?» При ответе на этот вопрос существует две противоположные точки зрения. Одна из них утверждает, что чем больше нейронов использовать, тем более надежная сеть получится. Сторонники этой позиции ссылаются на пример человеческого мозга. Действительно, чем больше нейронов, тем больше число связей между ними, и тем более сложные задачи способна решить нейронная сеть. Кроме того, если использовать заведомо большее число нейронов, чем необходимо для решения задачи, то нейронная сеть точно обучится. Если же начинать с небольшого числа нейронов, то сеть может оказаться неспособной обучиться решению задачи, и весь процесс придется повторять сначала с большим числом нейронов. Эта точка зрения (чем больше — тем лучше) популярна среди разработчиков нейросетевого программного обеспечения. Так, многие из них как одно из основных достоинств своих программ называют возможность использования любого числа нейронов.
X 1 2 3 4 F(X) 5 4 6 3Рис. 1. Аппроксимация табличной функции
Вторая точка зрения опирается на такое «эмпирическое» правило: чем больше подгоночных параметров, тем хуже аппроксимация функции в тех областях, где ее значения были заранее неизвестны. С математической точки зрения задачи обучения нейронных сетей сводятся к продолжению функции заданной в конечном числе точек на всю область определения. При таком подходе входные данные сети считаются аргументами функции, а ответ сети — значением функции. На рис. 1 приведен пример аппроксимации табличной функции полиномами 3-й (рис. 1.а) и 7-й (рис. 1.б) степеней. Очевидно, что аппроксимация, полученная с помощью полинома 3-ей степени больше соответствует внутреннему представлению о «правильной» аппроксимации. Несмотря на свою простоту, этот пример достаточно наглядно демонстрирует суть проблемы.
Второй подход определяет нужное число нейронов как минимально необходимое. Основным недостатком является то, что это, минимально необходимое число, заранее неизвестно, а процедура его определения путем постепенного наращивания числа нейронов весьма трудоемка. Опираясь на опыт работы группы НейроКомп в области медицинской диагностики [18, 49–52, 73, 91, 92, 161, 162, 166, 183–188, 191–209, 256, 296–299, 317, 318, 344–349, 354, 364], космической навигации и психологии можно отметить, что во всех этих задачах ни разу не потребовалось более нескольких десятков нейронов.
Подводя итог анализу двух крайних позиций, можно сказать следующее: сеть с минимальным числом нейронов должна лучше («правильнее», более гладко) аппроксимировать функцию, но выяснение этого минимального числа нейронов требует больших интеллектуальных затрат и экспериментов по обучению сетей. Если число нейронов избыточно, то можно получить результат с первой попытки, но существует риск построить «плохую» аппроксимацию. Истина, как всегда бывает в таких случаях, лежит посередине: нужно выбирать число нейронов большим, чем необходимо, но не намного. Это можно осуществить путем удвоения числа нейронов в сети после каждой неудачной попытки обучения. Наиболее надежным способом оценки минимального числа нейронов является использование процедуры контрастирования. Кроме того, процедура контрастирования позволяет ответить и на второй вопрос: какова должна быть структура сети.
Как уже отмечалось ранее, основная сложность в аппаратной реализации нейронных сетей — большое число связей между элементами. В связи с этим, задача уменьшения числа связей (упрощения архитектуры нейронной сети) приобретает особенную важность. Во многих приложениях, выполненных группой НейроКомп [18, 49–52, 65, 73, 91, 92, 161, 162, 166, 183–188, 191–209, 256, 286, 296–299, 300–302, 317, 318, 344–348, 354, 364, 367] в ходе процедуры контрастирования число связей уменьшалось в 5-10 раз. Кроме того, при этом уменьшалось общее число элементов. Такое кардинальное упрощение архитектуры нейронной сети резко упрощает ее аппаратную реализацию.
Уменьшение числа входных сигналов
При постановке задачи для нейронной сети не всегда удается точно определить сколько и каких входных данных нужно подавать на вход. В случае недостатка данных сеть не сможет обучиться решению задачи. Однако гораздо чаще на вход сети подается избыточный набор входных параметров. Например, при обучении сети постановке диагноза в задачах медицинской диагностики на вход сети подаются все данные, необходимые для постановки диагноза в соответствии с существующими методиками. Следует учесть, что стандартные методики постановки диагнозов разрабатываются для использования на большой территории (например, на территории России). Как правило, при диагностике заболеваний населения какого-нибудь небольшого региона (например города) можно обойтись меньшим набором исходных данных. Причем этот усеченный набор будет варьироваться от одного малого региона к другому. Требуется определить, какие данные необходимы для решения конкретной задачи, поставленной для нейронной сети. Кроме того, в ходе решения этой задачи определяются значимости входных сигналов. Следует заметить, что умение определять значимость входных сигналов представляет самостоятельную ценность.
Сведение параметров нейронной сети к выделенным значениям
При обучении нейронных сетей на универсальных компьютерах параметры сети являются действительными числами из заданного диапазона. При аппаратной реализации нейронной сети не всегда возможно реализовать веса связей с высокой точностью (в компьютерном представлении действительных чисел хранятся первые 6–7 цифр мантиссы). Опыт показывает, что в обученной сети веса многих синапсов можно изменять в довольно широком диапазоне (до полуширины интервала изменения веса) не изменяя качество решения сетью поставленной перед ней задачи. Исходя из этого, умение решать задачу замены значений параметров сети на значения из заданного набора приобретает важный практический смысл.
Снижение требований к точности входных сигналов
При обработке экспериментальных данных полезно знать, что измерение с высокой точностью, как правило, дороже измерения с низкой точностью. Причем достаточно часто получение очередной значащей цифры измеряемого параметра стоит на несколько порядков дороже. В связи с этим задача снижения требований к точности измерения входных параметров сети приобретает смысл.
Получение явных знаний из данных
Одной из главных загадок мышления является то, как из совокупности данных об объекте, появляется знание о нем. До недавнего времени наибольшим достижением в области искусственного интеллекта являлось либо воспроизведение логики человека-эксперта (классические экспертные системы), либо построение регрессионных зависимостей и определение степени зависимости одних параметров от других.
С другой стороны, одним из основных недостатков нейронных сетей, с точки зрения многих пользователей, является то, что нейронная сеть решает задачу, но не может рассказать как. Иными словами из обученной нейронной сети нельзя извлечь алгоритм решения задачи. Таким образом нейронные сети позволяют получать неявные знания из данных.
В домашнем задании I Всесоюзной олимпиады по нейрокомпьютингу, проходившей в мае 1991 года в городе Омске, в исследовательской задаче участникам было предложено определить, как нейронная сеть решает задачу распознавания пяти первых букв латинского алфавита (полный текст задания и наиболее интересные варианты решения приведены в [47]). Это была первая попытка извлечения алгоритма решения задачи из обученной нейронной сети.
В 1995 году была сформулирована идея логически прозрачных сетей, то есть сетей на основе структуры которых можно построить вербальное описание алгоритма получения ответа. Это достигается при помощи специальным образом построенной процедуры контрастирования.
Построение логически прозрачных сетей
Рис. 2. Набор минимальных сетей для решения задачи о предсказании результатов выборов президента США. В рисунке использованы следующие обозначения: буквы «П» и «О» — обозначают вид ответа, выдаваемый нейроном: «П» — положительный сигнал означает победу правящей партии, а отрицательный — оппозиционной; «О» — положительный сигнал означает победу оппозиционной партии, а отрицательный — правящей;
Зададимся классом сетей, которые будем считать логически прозрачными (то есть такими, которые решают задачу понятным для нас способом, для которого легко сформулировать словесное описания в виде явного алгоритма). Например потребуем, чтобы все нейроны имели не более трех входных сигналов.
Зададимся нейронной сетью у которой все входные сигналы подаются на все нейроны входного слоя, а все нейроны каждого следующего слоя принимают выходные сигналы всех нейронов предыдущего слоя. Обучим сеть безошибочному решению задачи.
После этого будем производить контрастирование в несколько этапов. На первом этапе будем удалять только входные связи нейронов входного слоя. Если после этого у некоторых нейронов осталось больше трех входных сигналов, то увеличим число входных нейронов. Затем аналогичную процедуру выполним поочередно для всех остальных слоев. После завершения описанной процедуры будет получена логически прозрачная сеть. Можно произвести дополнительное контрастирование сети, чтобы получить минимальную сеть. На рис. 2 приведены восемь минимальных сетей. Если под логически прозрачными сетями понимать сети, у которых каждый нейрон имеет не более трех входов, то все сети кроме пятой и седьмой являются логически прозрачными. Пятая и седьмая сети демонстрируют тот факт, что минимальность сети не влечет за собой логической прозрачности.
Получение явных знаний
После получения логически прозрачной нейронной сети наступает этап построения вербального описания. Принцип построения вербального описания достаточно прост. Используемая терминология заимствована из медицины. Входные сигналы будем называть симптомами. Выходные сигналы нейронов первого слоя — синдромами первого уровня. Очевидно, что синдромы первого уровня строятся из симптомов. Выходные сигналы нейронов k — о слоя будем называть синдромами k — о уровня. Синдромы k — о первого уровня строятся из симптомов и синдромов более низких уровней. Синдром последнего уровня является ответом.
В качестве примера приведем интерпретацию алгоритма рассуждений, полученного по второй сети приведенной на рис. 2. Постановка задачи: по ответам на 12 вопросов необходимо предсказать победу правящей или оппозиционной партии на выборах Президента США. Ниже приведен список вопросов.
Правящая партия была у власти более одного срока?
Правящая партия получила больше 50 % голосов на прошлых выборах?
В год выборов была активна третья партия?
Была серьезная конкуренция при выдвижении от правящей партии?
Кандидат от правящей партии был президентом в год выборов?
Год выборов был временем спада или депрессии?
Был ли рост среднего национального валового продукта на душу населения больше 2.1 %?
Произвел ли правящий президент существенные изменения в политике?
Во время правления были существенные социальные волнения?
Администрация правящей партии виновна в серьезной ошибке или скандале?
Кандидат от правящей партии — национальный герой?
Кандидат от оппозиционной партии — национальный герой?
Ответы на вопросы описывают ситуацию на момент, предшествующий выборам. Ответы кодировались следующим образом: «да» — единица, «нет» — минус единица. Отрицательный сигнал на выходе сети интерпретируется как предсказание победы правящей партии. В противном случае, ответом считается победа оппозиционной партии. Все нейроны реализовывали пороговую функцию, равную 1, если алгебраическая сумма входных сигналов нейрона больше либо равна 0, и –1 при сумме меньшей 0.
Проведем поэтапно построение вербального описания второй сети, приведенной на рис. 2. После автоматического построения вербального описания получим текст, приведенный на рис. 3. Заменим все симптомы на тексты соответствующих вопросов. Заменим формулировку восьмого вопроса на обратную. Подставим вместо Синдром1_Уровня2 название ответа сети при выходном сигнале 1. Текст, полученный в результате этих преобразований приведен на рис. 4.
Синдром1_Уровня1 равен 1, если выражение Симптом4 + Симптом6 — Симптом 8 больше либо равно нулю, и –1 — в противном случае.
Синдром2_Уровня1 равен 1, если выражение Симптом3 + Симптом4 + Симптом9 больше либо равно нулю, и –1 — в противном случае.
Синдром1_Уровня2 равен 1, если выражение Синдром1_Уровня1 + Синдром2_Уровня1 больше либо равно нулю, и –1 — в противном случае.
Рис. 3. Автоматически построенное вербальное описание
Синдром1_Уровня1 равен 1, если выражение + + больше либо равно нулю, и –1 — в противном случае.
Синдром2_Уровня1 равен 1, если выражение + + больше либо равно нулю, и –1 — в противном случае.
Оппозиционная партия победит, если выражение Синдром1_Уровня1 + Синдром2_Уровня1 больше либо равно нулю.
Рис. 4. Вербальное описание после элементарных преобразований
Заметим, что все три вопроса, ответы на которые формируют Синдром1_Уровня1, относятся к оценке качества правления действующего президента. Поскольку положительный ответ на любой из этих вопросов характеризует недостатки правления, то этот синдром можно назвать синдромом плохой политики. Аналогично, три вопроса, ответы на которые формируют Синдром2_Уровня1, относятся к характеристике политической стабильности. Этот синдром назовем синдромом политической нестабильности.
Тот факт, что оба синдрома первого уровня принимают значение 1, если истинны ответы хотя бы на два из трех вопросов, позволяет избавиться от математических действий с ответами на вопросы. Окончательный ответ может быть истинным только если оба синдрома имеют значение –1.
Используя приведенные соображения, получаем окончательный текст решения задачи о предсказании результатов выборов президента США, приведенный на рис. 5.
Правление плохое, если верны хотя бы два из следующих высказываний: «Была серьезная конкуренция при выдвижении от правящей партии», «Год выборов был временем спада или депрессии», «Правящий президент не произвел существенных изменений в политике».
Ситуация политически нестабильна, если верны хотя бы два из следующих высказываний: «В год выборов была активна третья партия», «Была серьезная конкуренция при выдвижении от правящей партии», «Во время правления были существенные социальные волнения».
Оппозиционная партия победит, если правление плохое или ситуация политически нестабильна.
Рис. 5. Окончательный вариант вербального описания
Таким образом, использовав идею логически прозрачных нейронных сетей и минимальные интеллектуальные затраты на этапе доводки вербального описания, был получен текст решения задачи. Причем процедура получения логически прозрачных нейронных сетей сама отобрала значимые признаки, сама привела сеть к нужному виду. Далее элементарная программа построила по структуре сети вербальное описание.
На рис. 2 приведены структуры шести логически прозрачных нейронных сетей, решающих задачу о предсказании результатов выборов президента США [300–302]. Все сети, приведенные на этом рисунке минимальны в том смысле, что из них нельзя удалить ни одной связи так, чтобы сеть могла обучиться правильно решать задачу. По числу нейронов минимальна пятая сеть.
Заметим, что все попытки авторов обучить нейронные сети со структурами, изображенными на рис. 2, и случайно сгенерированными начальными весами связей закончились провалом. Все сети, приведенные на рис. 2, были получены из существенно больших сетей с помощью процедуры контрастирования. Сети 1, 2, 3 и 4 были получены из трехслойных сетей с десятью нейронами во входном и скрытом слоях. Сети 5, 6, 7 и 8 были получены из двухслойных сетей с десятью нейронами во входном слое. Легко заметить, что в сетях 2, 3, 4 и 5 изменилось не только число нейронов в слоях, но и число слоев. Кроме того, почти все веса связей во всех восьми сетях равны либо 1, либо –1.
Множества повышенной надежности
Алгоритмы контрастирования, рассматриваемые в данной главе, позволяют выделить минимально необходимое множество входных сигналов. Использование минимального набора входных сигналов позволяет более экономично организовать работу нейркомпьютера. Однако у минимального множества есть свои недостатки. Поскольку множество минимально, то информация, несомая одним из сигналов, как правило не подкрепляется другими входными сигналами. Это приводит к тому, что при ошибке в одном входном сигнале сеть ошибается с большой степенью вероятности. При избыточном наборе входных сигналов этого как правило не происходит, поскольку информация каждого сигнала подкрепляется (дублируется) другими сигналами.
Таким образом возникает противоречие — использование исходного избыточного множества сигналов неэкономично, а использование минимального набора сигналов приводит к повышению риска ошибок. В этой ситуации правильным является компромиссное решение — необходимо найти такое минимальное множество, в котором вся информация дублируется. В данном разделе рассматриваются методы построения таких множеств, повышенной надежности. Кроме того, построение дублей второго рода позволяет установить какие из входных сигналов не имеют дублей в исходном множестве сигналов. Попадание такого «уникального» сигнала в минимальное множество является сигналом о том, что при использовании нейронной сети для решения данной задачи следует внимательно следить за правильностью значения этого сигнала.
Формальная постановка задачи
Пусть дана таблица данных, содержащая N записей, каждая из которых содержит M+1 поле. Обозначим значение i-о поля j-й записи через xij, где i=0,…,M, j=1,…,N. Обозначим через V(A,S) задачник, в котором ответы заданы в полях с номерами i∈A, а входные данные содржатся в полях с номерами i∈S. Множество А будем называть множеством ответов, а множество S — множеством входных данных. Минимальное множество входных сигналов, полученное при обучении сети на задачнике V(A,S), обозначим через F(A,S). В случае, когда сеть не удалось обучить решению задачи будем считать, что F(A,S)=∅. Число элементов в множестве A будем обозначать через |A|. Через T(A,S) будем обозначать сеть, обученную решать задачу предсказания всех полей (ответов), номера которых содержатся в множестве A, на основе входных сигналов, номера которых содержатся в множестве S.
Задача. Необходимо построить набор входных параметров, который позволяет надежно решать задачу V({0},{1,…,M}).
Решение задачи будем называть множеством повышенной надежности, и обозачать S•′.
Для решения этой задачи необходимо определит набор параметров, дублирующих минимальный набор S1=F({0},{1,…,M}). Возможно несколько подходов к определению дублирующего набора. В следующих разделах рассмотрены некоторые из них.
Классификация дублей
Возможно два типа дублей — набор входных сигналов, способный заменить определенный входной сигнал или множество сигналов при получении ответа первоначальной задачи, и набор входных сигналов, позволяющий вычислить дублируемый сигнал (множество дублируемых сигналов). Дубли первого типа будем называть прямыми, а дубли второго типа — косвенными.
Возможна другая классификация, не зависящая от ранее рассмотренной. Дубли первого и второго рода будем различать по объекту дублирования. Дубль первого рода дублирует все множество вцелом, а дубль второго рода дублирует конкретный сигнал.
Очевидно, что возможны все четыре варианта дублей: прямой первого рода, косвенный первого рода, прямой второго рода и косвенный второго рода. В следующих разделах будут описаны алгоритмы получения дублей всех вышеперечисленных видов.
Прямой дубль первого рода
Для нахождения прямого дубля первого рода требуется найти такое множество сигналов D что существует сеть T({0},D) и S1∩D=∅. Решение этой задачи очевидно. Удалим из множества входных сигналов те их них, которые вошли в первоначальное минимальное множество входных сигналов S1. Найдем минимальное множествовходных сигналов среди оставшихся. Найденное множество и будет искомым дублем.
Формально описанную выше процедуру можно записать следующей формулой:
D=F({0},{1,…,M}\S1).
Множество повышенной надежности в этом случае можно записать в следующем виде:
Очевидно, что последнюю формулу можно обобщить, исключив из первоначального множества входных сигналов найденное ранее множество повышенной надежности и попытавшись найти минимальное множество среди оставшихся входных сигналов. С другой стороны, для многих нейросетевых задач прямых дублей первого рода не существует. Примером может служить одна из классических тестовых задач — задача о предсказании результатов выборов президента США.
Косвенный дубль первого рода
Для нахождения косвенного дубля первого рода необходимо найти такое множество входных сигналов D что существует сеть T(S1,D) и S1∩D=∅. Другими словами, среди множества входных сигналов, не включающем начальное минимальное множество, нужно найти такие входные сигналы, по которым можно восстановит значения входных сигналов начального минимального множества. Формально описанную выше процедуру можно записать следующей формулой:
D=F(S1,{1,…,M}\S1).
Множество повышенной надежности в этом случае можно записать в следующем виде:
Эта формула так же допускает обобщение. Однако, следует заметить, что косвенные дубли первого рода встречаются еще реже чем прямые дубли первого рода. Соотношение между косвенным и прямым дублем первого рода описываются следующей теоремой.
Теорема 1. Если множество D является косвенным дублем первого рода, то оно является и прямым дублем первого рода.
Доказательство. Построим нейронную сеть, состоящую из последовательно соединенных сетей T(S1,D) и T({0},S1), как показано на рис. 6. Очевидно, что на выходе первой сети будут получены те сигналы, которые, будучи поданы на вход второй сети, приведут к получению на выходе второй сети правильного ответа. Таким образом сеть, полученная в результате объединения двух сетей T(S1,D) и T({0},S1), является сетью T({0},D). Что и требовалось доказать.
Рис. 6. Сеть для получения ответа из косвенного дубля.
Следствие. Если у множества S1 нет прямого дубля первого рода, то у нее нет и косвенного дубля первого рода
Доказательство. Пусть это не так. Тогда существует косвенный дубль первого рода. Но по теореме 1 он является и прямым дублем первого рода, что противоречит условию теоремы. Полученное противоречие доказывает следствие.
Прямой дубль второго рода
Перенумеруем входные сигналы из множества S1={i1,…,ik}, k=|S1|. Множество сигналов, являющееся прямым дублем второго рода для сигнала можно получить найдя минимальное множество для получения ответа, если из исходного множества входных сигналов исключен сигнал . Таким образом прямые дубли второго рода получаются следующим образом:
Dj=F({0},{1,…,M}\{ij}).
Полный прямой дубль второго рода получается объединением всех дублей для отдельных сигналов
Множество повышенной надежности для прямого дубля второго рода можно записать в следующем виде:
Заметим, что при построении прямого дубля второго рода не требовалось отсутствия в нем всех элементов множества S1, как это было при построении прямого дубля первого рода. Такое снижение требований приводит к тому, что прямые дубли второго рода встречаются чаще, чем прямые дубли первого рода. Более того, прямой дубль первого рода очевидно является прямым дублем второго рода. Более точное соотношение между прямыми дублями первого и второго родов дает следующая теорема.
Теорема 2. Полный прямой дубль второго рода является прямым дублем первого рода тогда, и только тогда, когда
(1)
Доказательство. Построим сеть, состоящую из параллельно работающих сетей, T({0},{1,…,M}\{ij}), за которыми следует элемент, выдающтй на выход среднее арифметическое своих входов. Такая сеть очевидно будет решать задачу, а в силу соотношения (1) она будет сетью T({0},{1,…,M}\{S1}). Таким образом, если соотношение (1) верно, то прямой дубль второго рода является прямым дублем первого рода. Необходимость следует непосредственно из определения прямого дубля первого рода.
Косвенный дубль второго рода
Косвенный дубль второго рода для сигнала является минимальным множеством входных сигналов, для которых существует сеть T({i1},{1,…,M}\{i1}). Полный косвенный дубль второго рода строится как объединение косвенных дублей второго рода для всех сигналов первоначального минимального множества:
Dj=F({ij},{1,…,M}\{ij}).
Соотношения между косвенными дублями второго рода и другими видами дублей первого и второго рода задаются теоремами 1, 2 и следующими двумя теоремами.
Теорема 3. Косвенный дубль второго рода всегда является прямым дублем второго рода.
Доказательство данной теоремы полностью аналогично доказательству теоремы 1.
Теорема 4. Полный косвенный дубль второго рода является косвенным дублем первого рода тогда, и только тогда, когда верно соотношение
Доказателство данной теоремы полностью аналогично доказательству теоремы 2.
Косвенный супердубль
Последним рассматриваемым в данной работе видом дубля является косвенный супердубль. Косвенным супердублем будем называть минимальное множество входных сигналов, которое позволяет восстановит все входные сигналы. Косвенный супердубль формально описывается следующей формулой:
D=F({1,…,M},{1,…,M})
Очевидно, что косвенный супердубль является полным косвенным дублем второго рода. Также очевидно, что косвенный супердубль встречается гораздо реже, чем наиболее редкий из ранее рассматриваемых косвенный дубль первого рода.
Процедура контрастирования
Существует два типа процедуры контрастирования — контрастирование по значимости параметров и не ухудшающее контрастирование. В данном разделе описаны оба типа процедуры контрастирования.
Контрастирование на основе показателей значимости
С помощью этой процедуры можно контрастировать, как входные сигналы, так и параметры сети. Далее в данном разделе будем предполагать, что контрастируются параметры сети. При контрастировании входных сигналов процедура остается той же, но вместо показателей значимости параметров сети используются показатели значимости входных сигналов. Обозначим через Χp — показатель значимости p-о параметра; через w0p — текущее значение p-о параметра; через w•p — ближайшее выделенное значение для p-о параметра.
Используя введенные обозначения процедуру контрастирования можно записать следующим образом:
1. Вычисляем показатели значимости.
2. Находим минимальный среди показателей значимости — Χp'.
3. Заменим соответствующий этому показателю значимости параметр w0p′ на w•p′, и исключаем его из процедуры обучения.
4. Предъявим сети все примеры обучающего множества. Если сеть не допустила ни одной ошибки, то переходим ко второму шагу процедуры.
5. Пытаемся обучить полученную сеть. Если сеть обучилась безошибочному решению задачи, то переходим к первому шагу процедуры, в противном случае переходим к шестому шагу.
6. Восстанавливаем сеть в состояние до последнего выполнения третьего шага. Если в ходе выполнения шагов со второго по пятый был отконтрастирован хотя бы один параметр, (число обучаемых параметров изменилось), то переходим к первому шагу. Если ни один параметр не был отконтрастирован, то получена минимальная сеть.
Возможно использование различных обобщений этой процедуры. Например, контрастировать за один шаг процедуры не один параметр, а заданное пользователем число параметров. Наиболее радикальная процедура состоит в контрастировании половины параметров связей. Если контрастирование половины параметров не удается, то пытаемся контрастировать четверть и т. д. Другие варианты обобщения процедуры контрастирования будут описаны при описании решения задач. Результаты первых работ по контрастированию нейронных сетей с помощью описанной процедуры опубликованы в [47, 303, 304].
(обратно)Контрастирование без ухудшения
Пусть нам дана только обученная нейронная сеть и обучающее множество. Допустим, что вид функции оценки и процедура обучения нейронной сети неизвестны. В этом случае так же возможно контрастирование сети. Предположим, что данная сеть идеально решает задачу. В этом случае возможно контрастирование сети даже при отсутствии обучающей выборки, поскольку ее можно сгенерировать используя сеть для получения ответов. Задача не ухудшающего контрастирования ставится следующим образом: необходимо так провести контрастирование параметров, чтобы выходные сигналы сети при решении всех примеров изменились не более чем на заданную величину. Для решения задача редуцируется на отдельный адаптивный сумматор: необходимо так изменить параметры, чтобы выходной сигнал адаптивного сумматора при решении каждого примера изменился не более чем на заданную величину.
Обозначим через xqp p-й входной сигнал сумматора при решении q-о примера; через fq — выходной сигнал сумматора при решении q-о примера; через wp — вес p-о входного сигнала сумматора; через ε — требуемую точность; через n — число входных сигналов сумматора; через m — число примеров. Очевидно, что при решении примера выполняется равенство
Требуется найти такой набор индексов I={i1,…,ik}, что
где αp — новый вес p-о входного сигнала сумматора. Набор индексов будем строить по следующему алгоритму.
1. Положим f(0)=f, x•p=xp, I(0)=∅, J(0)={1,…,n}, k =0.
2. Для всех векторов x•p таких, что p∈J(k), проделаем следующее преобразование: если , то исключаем p из множества обрабатываемых векторов — J(k)=J(k)/{p}, в противном случае нормируем вектор x•p на единичную длину — .
3. Если или J(0)=∅, то переходим к шагу 10.
4. Находим ik+1 — номер вектора, наиболее близкого к f(k) из условия
5. Исключаем ik+1 из множества индексов обрабатываемых векторов: J(k+1)=J(k)/{ik+1}.
6. Добавляем ik+1 в множество индексов найденных векторов: I(k+1)=I(k)∪{ik+1}.
7. Вычисляем не аппроксимированную часть (ошибку аппроксимации) вектора выходных сигналов: .
8. Преобразуем обрабатываемые вектора к промежуточному представлению — ортогонализуем их к вектору , для чего каждый вектор xp(k), у которого p∈J(k) преобразуем по следующей формуле: .
9. Увеличиваем k на единицу и переходим к шагу 2.
10. Если k=0, то весь сумматор удаляется из сети и работа алгоритма завершается.
11. Если k=n+1, то контрастирование невозможно и сумматор остается неизменным.
12. В противном случае полагаем I=I(k) и вычисляем новые веса связей αp(p∈I) решая систему уравнений
13. Удаляем из сети связи с номерами p∈J, веса оставшихся связей полагаем равными αp(p∈I).
Данная процедура позволяет производить контрастирование адаптивных сумматоров. Причем значения, вычисляемые каждым сумматором после контрастирования, отличаются от исходных не более чем на заданную величину. Однако, исходно была задана только максимально допустимая погрешность работы сети в целом. Способы получения допустимых погрешностей для отдельных сумматоров исходя из заданной допустимой погрешности для всей сети описаны в ряде работ [95–97, 168, 210–214, 355].
(обратно)Гибридная процедура контрастирования
Можно упростить процедуру контрастирования, описанную в разд. «Контрастирование без ухудшения». Предлагаемая процедура годится только для контрастирования весов связей адаптивного сумматора (см. разд. «Составные элементы»). Контрастирование весов связей производится отдельно для каждого сумматора. Адаптивный сумматор суммирует входные сигналы нейрона, умноженные на соответствующие веса связей. Для работы нейрона наименее значимым будем считать тот вес, который при решении примера даст наименьший вклад в сумму. Обозначим через xqp входные сигналы рассматриваемого адаптивного сумматора при решении q-го примера. Показателем значимости веса назовем следующую величину: Xqp=|(wp-w•p)·xqp|. Усредненный по всем примерам обучающего множества показатель значимости имеет вид . Производим контрастирование по процедуре, приведенной в разд. «Контрастирование на основе показателей значимости»
В самой процедуре контрастирования есть только одно отличие — вместо проверки на наличие ошибок при предъявлении всех примеров проверяется, что новые выходные сигналы сети отличаются от первоначальных не более чем на заданную величину.
Контрастирование при обучении
Существует еще один способ контрастирования нейронных сетей. Идея этого способа состоит в том, что функция оценки модернизируется таким способом, чтобы для снижения оценки было выгодно привести сеть к заданному виду. Рассмотрим решение задачи приведения параметров сети к выделенным значениям. Используя обозначения из предыдущих разделов требуемую добавку к функции оценки, являющуюся штрафом за отклонение значения параметра от ближайшего выделенного значения, можно записать в виде .
Для решения других задач вид добавок к функции оценки много сложнее.
Определение показателей значимости
В данном разделе описан способ определения показателей значимости параметров и сигналов. Далее будем говорить об определении значимости параметров. Показатели значимости сигналов сети определяются по тем же формулам с заменой параметров на сигналы.
Определение показателей значимости через градиент
Нейронная сеть двойственного функционирования может вычислять градиент функции оценки по входным сигналам и обучаемым параметрам сети.
Показателем значимости параметра при решении q-о примера будем называть величину, которая показывает насколько изменится значение функции оценки решения сетью q-о примера если текущее значение параметра wp заменить на выделенное значение w•p. Точно эту величину можно определить произведя замену и вычислив оценку сети. Однако учитывая большое число параметров сети вычисление показателей значимости для всех параметров будет занимать много времени. Для ускорения процедуры оценки параметров значимости вместо точных значений используют различные оценки [33 , 65 , 91]. Рассмотрим простейшую и наиболее используемую линейную оценку показателей значимости. Разложим функцию оценки в ряд Тейлора с точностью до членов первого порядка:
где H0q — значение функции оценки решения q-о примера при w•=w. Таким образом показатель значимости p-о параметра при решении q-о примера определяется по следующей формуле:
(1)
Показатель значимости (1) может вычисляться для различных объектов. Наиболее часто его вычисляют для обучаемых параметров сети. Однако показатель значимости вида (1) применим и для сигналов. Как уже отмечалось в главе «Описание нейронных сетей» сеть при обратном функционировании всегда вычисляет два вектора градиента — градиент функции оценки по обучаемым параметрам сети и по всем сигналам сети. Если показатель значимости вычисляется для выявления наименее значимого нейрона, то следует вычислять показатель значимости выходного сигнала нейрона. Аналогично, в задаче определения наименее значимого входного сигнала нужно вычислять значимость этого сигнала, а не сумму значимостей весов связей, на которые этот сигнал подается.
Усреднение по обучающему множеству
Показатель значимости параметра Xqp зависит от точки в пространстве параметров, в которой он вычислен и от примера из обучающего множества. Существует два принципиально разных подхода для получения показателя значимости параметра, не зависящего от примера. При первом подходе считается, что в обучающей выборке заключена полная информация о всех возможных примерах. В этом случае, под показателем значимости понимают величину, которая показывает насколько изменится значение функции оценки по обучающему множеству, если текущее значение параметра wp заменить на выделенное значение w•p. Эта величина вычисляется по следующей формуле:
(2)
В рамках другого подхода обучающее множество рассматривают как случайную выборку в пространстве входных параметров. В этом случае показателем значимости по всему обучающему множеству будет служить результат некоторого усреднения по обучающей выборке.
Существует множество способов усреднения. Рассмотрим два из них. Если в результате усреднения показатель значимости должен давать среднюю значимость, то такой показатель вычисляется по следующей формуле:
(3)
Если в результате усреднения показатель значимости должен давать величину, которую не превосходят показатели значимости по отдельным примерам (значимость этого параметра по отдельному примеру не больше чем Χp), то такой показатель вычисляется по следующей формуле:
(4)
Показатель значимости (4) хорошо зарекомендовал себя при использовании в работах группы НейроКомп.
Накопление показателей значимости
Все показатели значимости зависят от точки в пространстве параметров сети, в которой они вычислены, и могут сильно изменяться при переходе от одной точки к другой. Для показателей значимости, вычисленных с использованием градиента эта зависимость еще сильнее, поскольку при обучении по методу наискорейшего спуска (см. раздел «Метод наискорейшего спуска») в двух соседних точках пространства параметров, в которых вычислялся градиент, градиенты ортогональны. Для снятия зависимости от точки пространства используются показатели значимости, вычисленные в нескольких точках. Далее они усредняются по формулам аналогичным (3) и (4). Вопрос о выборе точек в пространстве параметров в которых вычислять показатели значимости обычно решается просто. В ходе нескольких шагов обучения по любому из градиентных методов при каждом вычислении градиента вычисляются и показатели значимости. Число шагов обучения, в ходе которых накапливаются показатели значимости, должно быть не слишком большим, поскольку при большом числе шагов обучения первые вычисленные показатели значимости теряют смысл, особенно при использовании усреднения по формуле (4).
Лекции 15, 16. Персептрон
Персептрон Розенблатта [146, 181] является исторически первой обучаемой нейронной сетью. Существует несколько версий персептрона. Рассмотрим классический персептрон — сеть с пороговыми нейронами и входными сигналами, равными нулю или единице. Будем использовать обозначения, приведенные в работе [146].
Определение персептрона
Персептрон должен решать задачу классификации на два класса по бинарным входным сигналам. Набор входных сигналов будем обозначать n-мерным вектором x. Все элементы вектора являются булевыми переменными (переменными принимающими значения «Истина» или «Ложь»). Однако иногда полезно оперировать числовыми значениями. Будем считать, что значению «ложь» соответствует числовое значение 0, а значению «Истина» соответствует 1.
Персептроном будем называть устройство, вычисляющее следующую функцию:
где αi — веса персептрона, θ — порог, φi — значения входных сигналов, скобки [] означают переход от булевых (логических) значений к числовым значениям по правилам описанным выше. В качестве входных сигналов персептрона могут выступать как входные сигналы всей сети (переменные x), так и выходные значения других персептронов. Добавив постоянный единичный входной сигнал φ0≡1 и положив α0=–θ, персептрон можно переписать в следующем виде:
(1)
Очевидно, что выражение (1) вычисляется одним нейроном с пороговым нелинейным преобразователем (см. главу «Описание нейронных сетей»). Каскад из нескольких слоев таких нейронов называют многослойным персептроном. Далее в этой главе будут рассмотрены некоторые свойства персептронов. Детальное исследование персептронов приведено в работе [146].
Обучение персептрона. Правило Хебба
Персептрон обучают по правилу Хебба. Предъявляем на вход персептрона один пример. Если выходной сигнал персептрона совпадает с правильным ответом, то никаких действий предпринимать не надо. В случае ошибки необходимо обучить персептрон правильно решать данный пример. Ошибки могут быть двух типов. Рассмотрим каждый из них.
Первый тип ошибки — на выходе персептрона 0, а правильный ответ — 1. Для того, чтобы персептрон (1) выдавал правильный ответ необходимо, чтобы сумма в правой части (1) стала больше. Поскольку переменные φi принимают значения 0 или 1, увеличение суммы может быть достигнуто за счет увеличения весов αi. Однако нет смысла увеличивать веса при переменных φi, которые равны нулю. Таким образом, следует увеличить веса αi при тех переменных , которые равны 1. Для закрепления единичных сигналов с φi, следует провести ту же процедуру и на всех остальных слоях.
Первое правило Хебба. Если на выходе персептрона получен 0, а правильный ответ равен 1, то необходимо увеличить веса связей между одновременно активными нейронами. При этом выходной персептрон считается активным. Входные сигналы считаются нейронами.
Второй тип ошибки — на выходе персептрона 1, а правильный ответ равен нулю. Для обучения правильному решению данного примера следует уменьшить сумму в правой части (1). Для этого необходимо уменьшить веса связей αi при тех переменных φi, которые равны 1 (поскольку нет смысла уменьшать веса связей при равных нулю переменных φi). Необходимо также провести эту процедуру для всех активных нейронов предыдущих слоев. В результате получаем второе правило Хебба.
Второе правило Хебба. Если на выходе персептрона получена 1, а правильный ответ равен 0, то необходимо уменьшить веса связей между одновременно активными нейронами.
Таким образом, процедура обучения сводится к последовательному перебору всех примеров обучающего множества с применением правил Хебба для обучения ошибочно решенных примеров. Если после очередного цикла предъявления всех примеров окажется, что все они решены правильно, то процедура обучения завершается.
Нерассмотренными осталось два вопроса. Первый — насколько надо увеличивать (уменьшать) веса связей при применении правила Хебба. Второй — о сходимости процедуры обучения. Ответы на первый из этих вопросов дан в следующем разделе. В работе [146] приведено доказательство следующих теорем:
Теорема о сходимости персептрона. Если существует вектор параметров α, при котором персептрон правильно решает все примеры обучающей выборки, то при обучении персептрона по правилу Хебба решение будет найдено за конечное число шагов.
Теорема о «зацикливании» персептрона. Если не существует вектора параметров α, при котором персептрон правильно решает все примеры обучающей выборки, то при обучении персептрона по правилу Хебба через конечное число шагов вектор весов начнет повторяться.
Доказательства этих теорем в данное учебное пособие не включены.
Целочисленность весов персептронов
В данном разделе будет доказана следующая теорема.
Теорема. Любой персептрон (1) можно заменить другим персептроном того же вида с целыми весами связей.
Доказательство. Обозначим множество примеров одного класса (правильный ответ равен 0) через X0, а другого (правильный ответ равен 1) через X1. Вычислим максимальное и минимальное значения суммы в правой части (1):
Определим допуск ε как минимум из s0 и s1. Положим δ=s/(m+1) , где m — число слагаемых в (1). Поскольку персептрон (1) решает поставленную задачу классификации и множество примеров в обучающей выборке конечно, то δ>0. Из теории чисел известна теорема о том, что любое действительное число можно сколь угодно точно приблизить рациональными числами. Заменим веса αi на рациональные числа так, чтобы выполнялись следующие неравенства |αi-αi'|<δ.
Из этих неравенств следует, что при использовании весов αi' персептрон будет работать с теми же результатами что и первоначальный персептрон. Действительно, если правильным ответом примера является 0, имеем .
Подставив новые веса, получим:
Откуда следует необходимое неравенство
(2)
Аналогично, в случае правильного ответа равного 1, имеем
, откуда, подставив новые веса и порог получим:
Откуда следует выполнение неравенства
(3)
Неравенства (2) и (3) доказывают возможность замены всех весов и порога любого персептрона рациональными числами. Очевидно так же, что при умножении всех весов и порога на одно и тоже ненулевое число персептрон не изменится. Поскольку любое рациональное число можно представить в виде отношения целого числа к натуральному числу, получим
(4)
где αi″ — целые числа. Обозначим через r произведение всех знаменателей . Умножим все веса и порог на r. Получим веса целочисленные αi'''=rαi''. Из (2), (3) и (4) получаем
что и завершает доказательство теоремы.
Поскольку из доказанной теоремы следует, что веса персептрона являются целыми числами, то вопрос о выборе шага при применении правила Хебба решается просто: веса и порог следует увеличивать (уменьшать) на 1.
Двуслойность персептрона
Как уже упоминалось ранее в данной главе возможно использование многослойных персептронов. Однако теоремы о сходимости и зацикливании персептрона, приведенные выше верны только при обучении однослойного персептрона, или многослойного персептрона при условии, что обучаются только веса персептрона, стоящего в последнем слое сети. В случае произвольного многослойного персептрона они не работают. Следующий пример демонстрирует основную проблему, возникающую при обучении многослойных персептронов по правилу Хебба.
Пусть веса всех слоев персептрона в ходе обучения сформировались так, что все примеры обучающего множества, кроме первого, решаются правильно. При этом правильным ответом первого примера является 1. Все входные сигналы персептрона последнего слоя равны нулю. В этом случае первое правило Хебба не дает результата, поскольку все нейроны предпоследнего слоя не активны. Существует множество методов, как решать эту проблему. Однако все эти методы не являются регулярными и не гарантируют сходимость многослойного персептрона к решению даже при условии, что такое решение существует.
В действительности проблема настройки (обучения) многослойного персептрона решается следующей теоремой.
Теорема о двуслойности персептрона. Любой многослойный персептрон может быть представлен в виде двуслойного персептрона с необучаемыми весами первого слоя.
Для доказательства этой теоремы потребуется одна теорема из математической логики.
Теорема о дизъюнктивной нормальной форме. Любая булева функция булевых аргументов может быть представлена в виде дизъюнкции конъюнкций элементарных высказываний и отрицаний элементарных высказываний:
Напомним некоторые свойства дизъюнктивной нормальной формы.
Свойство 1. В каждый конъюнктивный член (слагаемое) входят все элементарные высказывания либо в виде самого высказывания, либо в виде его отрицания.
Свойство 2. При любых значениях элементарных высказываний в дизъюнктивной нормальной форме может быть истинным не более одного конъюнктивного члена (слагаемого).
Доказательство теоремы о двуслойности персептрона. Из теоремы о дизъюнктивной нормальной форме следует, что любой многослойный персептрон может быть представлен в следующем виде:
(5)
В силу второго свойства дизъюнктивной нормальной формы (5) можно переписать в виде
(6)
Переведем в арифметическую форму все слагаемые в (6). Конъюнкция заменяется умножением, а отрицание на разность: . Произведя эту замену в (6) и приведя подобные члены получим:
(7)
где Il — множество индексов сомножителей в l-м слагаемом, αl — число, указывающее сколько раз такое слагаемое встретилось в (6) после замены и раскрытия скобок (число подобных слагаемых).
Заменим i-е слагаемое в (7) персептроном следующего вида:
(8)
Подставив (8) в (7) получим (1), то есть произвольный многослойный персептрон представлен в виде (1) с целочисленными коэффициентами. В качестве персептронов первого слоя используются персептроны вида (8) с необучаемыми весами. Теорема доказана.
Подводя итоги данной главы следует отметить следующие основные свойства персептронов:
1. Любой персептрон может содержать один или два слоя. В случае двухслойного персептрона веса первого слоя не обучаются.
2. Веса любого персептрона можно заменить на целочисленные.
3. При обучении по правилу Хебба после конечного числа итераций возможны два исхода: персептрон обучится или вектор весов персептрона будет повторяться (персептрон зациклится).
Знание этих свойств позволяет избежать «усовершенствований» типа модификации скорости обучения и других, столь же «эффективных» модернизаций.
Приложение 1. Описание пакета программ CLAB (С.Е. Гилев)
Данное приложение является документацией к пакету программ CLAB, разработанной автором программы С.Е. Гилевым.
Описание пакета
Общее описание
Пакет программ CLAB представляет собой программный имитатор нейрокомпьютера, реализованный на IBM PC/AT, и предназначен для решения задач бинарной классификации. Данный пакет программ позволяет создавать и обучать нейросеть для того, чтобы по набору входных сигналов (например, по ответам на заданные вопросы) определить принадлежность объекта к одному из двух классов, которые далее будем условно называть «красными» и «синими».
Пакет программ CLAB может использоваться в задачах медицинской диагностики, психологического тестирования, для предсказания результатов выборов и др.
В данном руководстве не рассматриваются теоретические вопросы (алгоритмы обучения и др.). Для желающих ознакомиться с ними приводится список литературы. Здесь мы ограничимся лишь информацией, необходимой для работы с пакетом.
Нейросеть представляет собой набор нейронов и синапсов. Через синапсы нейрон может получать сигналы от других нейронов, а также входные сигналы, если данный нейрон является входным. Сигналы, полученные нейроном от всех входящих в него синапсов, суммируются и преобразуются в выходной сигнал согласно характеристической функции (в пакете CLAB она имеет вид Y(x)=x/(c+abs(x))). Этот сигнал в следующий момент времени подается на все выходящие из нейрона синапсы.
Для создания нейросети при работе с пакетом CLAB пользователь сам указывает параметры нейросети (число нейронов и др., о чем далее будет рассказано подробно). В таких нейросетях общее число нейронов не должно превышать 64, при этом выходные сигналы снимаются с двух последних нейронов.
Каждому синапсу в нейросети поставлено в соответствие число, называемое весом синапса. Сигнал при прохождении через синапс умножается на его вес. Процесс обучения нейросети состоит в подборе весов синапсов. Они должны быть такими, чтобы после предъявления нейросети определенных входных сигналов получать требуемые выходные сигналы.
Таким образом, для обучения нейросети пользователь должен представить обучающую выборку, т. е. совокупность обучающих примеров. Она размещается в файле, называемом задачником.
Обучение производится путем минимизации целевой функции, штрафующей за отклонение выходных сигналов нейросети от требуемых значений. В пакете CLAB минимизация осуществляется при помощи метода, основанного на так называемой BFGS-формуле и являющегося разновидностью квазиньютоновских методов.
После завершения процесса обучения можно переходить непосредственно к решению задачи, стоящей перед пользователем. На этом этапе работы нейросети предъявляют наборы входных сигналов для классификации исследуемых объектов.
Ptn— файл
Для удобства работы с пакетом создается ptn-файл. Он представляет собой текстовый файл с расширением. ptn.
В ptn-файл вводится информация, описывающая структуру примера. Это число входных сигналов и их имена. Именем входного сигнала может служить его номер. Однако в конкретных задачах, как правило, каждому входному сигналу соответствует некоторая информация, например, текст вопроса, ответ на который и является входным сигналом. Эту информацию можно ввести в ptn-файл в качестве имени сигнала.
При вводе имени сигнала вначале указывается количество входных сигналов, объединенных этим именем. Его можно указать равным 0. В этом случае при работе редактора Editor, имеющегося в пакете CLAB, соответствующая строка с именем будет выводиться на экран, но ввода входного сигнала редактор не потребует. Это позволяет вводить комментарии или пользоваться длинными именами, не входящими в одну строку.
В ptn-файле указываются также имена двух классов — сначала «красного», а затем «синего». Каждое имя должно содержать не более 10 символов.
Кроме этого, в ptn-файл можно ввести дополнительную информацию для этапа обучения. Может оказаться, что в примерах, предъявляемых нейросети для классификации, информация о некоторых входных сигналах будет зачастую отсутствовать. Это может происходить по разным причинам. Например, ответы на некоторые вопросы могут быть неизвестны.
В пакете CLAB имеется средство для обучения нейросети решению задач с такими «дырами» в векторе входных сигналов — так называемый «дырокол». В этом случае следует имена таких входных сигналов пометить в ptn-файле звездочками.
Задачник
Для обучения нейросети пользователь должен создать задачник, т. е. файл, в котором размещается обучающая выборка. В задачник не следует включать примеры с неопределенной принадлежностью к тому или другому классу, а также примеры с неполной информацией о векторе входных сигналов.
При составлении задачника можно пользоваться входящим в пакет редактором editor, который частично контролирует правильность составления задачника.
При работе с редактором на экране высвечиваются два окна — NEURON и VALUE, первое для имен входных сигналов, второе для их значений. В окне NEURON высвечиваются имена входных сигналов, содержащиеся в ptn-файле. Редактор генерирует номера входных сигналов и присваивает входным сигналам нулевые значения. Эти значения высвечиваются в окне VALUE. Пользователь может корректировать на экране содержимое окна VALUE, т. е. вводить нужные значения входных сигналов.
Кроме входных сигналов требуется указать класс примера. Для этого с клавиатуры вводится буква R для «красного» или L для «синего» примера. Класс текущего примера указывается во 2-й строке экрана в виде имени этого класса, заданного в ptn-файле. Если класс примера не указан, то Editor не включит его в задачник.
Если описанный способ составления задачника по каким-либо причинам не устраивает пользователя, то он может воспользоваться для этого другими имеющимися у него средствами. При этом структура задачника должна удовлетворять следующим требованиям.
Задачник должен быть организован по страницам. В начале каждой страницы в отдельной строке следует указать количество сначала «красных», потом «синих» примеров, расположенных на этой странице. Каждое из этих чисел должно быть не больше 20. После каждого примера в отдельной строке вводится буква R или L в зависимости от класса примера.
После составления задачника можно приступать к созданию нейросети и ее обучению.
Создание нейросети
В пакете CLAB имеется программа netgener, предназначенная для генерации нейросети. При обращении к ней она запрашивает имя файла для хранения параметров сети и карты синапсов, а затем просит ввести значения следующих параметров:
SIZE — количество нейронов сети;
TIME — число тактов времени от получения входных сигналов до выдачи результата;
CH — параметр характеристической функции;
STEP — начальный шаг движения по антиградиенту;
HIGH и LOW — параметры, определяющие уровни начальных значений весов синапсов.
Относительно значений вводимых параметров можно дать следующие рекомендации.
Очевидно, что значение параметра SIZE должно быть не меньше числа входных сигналов. Кроме того, оно должно быть не больше 64. Опыт показывает, что лучше задавать его по возможности меньшим. Можно порекомендовать задавать значение параметра SIZE равным сумме числа входных и выходных нейронов (т. е. на 2 большим, чем число входных сигналов).
Значение параметра TIME также лучше задавать по возможности меньшим. Можно задать его равным 3, а в случае необходимости увеличить.
Для параметра CH мы рекомендуем значения от 0,1 до 0,8. Следует заметить, что большие значения этого параметра требуют, как правило, больше времени на обучение, но при этом улучшаются предсказательные возможности нейросети. Другими словами, при малых значениях характеристики нейросеть легко «натаскивается» выдавать правильные ответы для входных векторов, встречавшихся ей в процессе обучения, но способность к экстраполяции на область примеров не включенных в задачник при этом хуже.
Значение параметра STEP можно задавать равным 0,005. В процессе счета программа сама подберет для него нужное значение.
Начальные значения весов синапсов генерируются датчиком псевдослучайных чисел в диапазоне от LOW до HIGH. Рекомендуется задавать значение этих параметров близким к значению параметра CH.
Обучение нейросети
Для обучения нейросети в пакете CLAB содержится программа teacher. Вначале она предлагает пользователю указать имя файла, содержащего карту синапсов, имя ptn-файла и имя файла задачника. Затем программа переходит непосредственно к обучению нейросети на примерах задачника.
Выходные сигналы могут принимать значения в интервале (-1,1). Они интерпретируются как координаты точки внутри квадрата [-1,1]*[-1,1]. Как только программа Teacher приступает к обучению, этот квадрат высвечивается на левой половине экрана. На нем крестиками изображаются ответы нейросети. Для каждого примера координаты крестика соответствуют выходным сигналам нейросети. Цвет крестика (красный либо синий) показывает класс этого примера, указанный в задачнике.
На этом же квадрате указаны два курсора — красный и синий. Стандартное положение красного курсора — в левом нижнем углу, синего — в правом верхнем. В процессе обучения курсоры можно передвигать. Расстояние от крестика до курсора соответствующего цвета показывает правильность ответа — чем меньше это расстояние, тем точнее ответ.
В правой половине экрана высвечиваются две колонки. В левой колонке указываются веса и значения целевой функции для «красных» примеров, в правой колонке — для «синих».
После завершения каждого цикла накопления оценки по примерам с данной страницы в нижней части экрана высвечиваются значения средних оценок для «красных» и «синих» примеров, а также средняя оценка для всех примеров. Если пользователь сочтет эти оценки приемлемыми, то он может перейти к следующей странице задачника.
В пакете CLAB имеются средства, позволяющие вмешиваться в процесс обучения для его ускорения.
Как было сказано выше, пользователь может изменять положение курсоров. Это приводит к изменению вида целевой функции. Такое действие может оказаться полезным в случае, когда на протяжении нескольких циклов обучения подряд оценка существенно не меняется.
Опыт работы с пакетом показывает, что на конечном этапе обучения небольшое улучшение оценки на одной странице задачника может привести к ухудшению оценок на других страницах. Поэтому на этапе доучивания можно сблизить курсоры Это ослабит жесткость требований к разделенности классов.
Можно приблизить курсор к ближайшему крестику того же цвета, т. е. крестику, соответствующему примеру с наименьшей оценкой. Тогда вклад этого примера в суммарный градиент уменьшится, а вклад примеров с худшими оценками увеличится. В результате крестики этого цвета будут собираться более плотной группой.
Изменять относительный вклад градиентов от разных примеров можно также путем изменения их весов. Стандартные значения весов задаются для всех примеров равными 1. Их можно изменять в интервале от 0 (это соответствует полному исключению примера) до 9. Однако задавать большой разброс в значениях весов не рекомендуется. В этом случае при небольшом улучшении оценки примера с большим весом могут существенно ухудшиться оценки других примеров. Опыт показывает, что в большинстве случаев достаточно задать для двух-трех примеров с наихудшими оценками значения весов, равные 2.
В случаях, когда целевая функция достигает локального минимума, возникают тупиковые ситуации — на протяжении многих циклов подряд оценка практически не изменяется. Для выхода из таких ситуаций в пакете CLAB имеется процедура BUMP. Она вносит в карту синапсов случайный вклад, величина которого, называемая уровнем BUMP'а, задается при вызове процедуры.
Отметим интересный эффект, который наблюдался при обучении нейросети с частым применением процедуры BUMP. В этом случае сеть постепенно приобретала помехоустойчивость, т. е. со временем уровень BUMP'ов можно было повышать без существенного ухудшения оценки. Этот эффект можно легко объяснить. Представим целевую функцию как рельеф в многомерном пространстве карт синапсов. Понятно, что применение процедуры BUMP позволяет легко выходить из узких ям и оврагов, но для вывода из широких долин уровень BUMP'ов может оказаться недостаточным. В результате частого применения процедуры сеть закрепляется на широкой долине.
Существует много принципиально различных стратегий для применения процедуры BUMP. Поэтому обучение с ее автоматическим применением не включено в пакет CLAB. Пользователь может сам выбирать стратегию в процессе обучения.
При обучении сети пользователь может столкнуться с тупиковыми ситуациями, когда в верхней части экрана появляются сообщения "zero step" или "infinite step". В этих случаях можно порекомендовать следующие действия: применить процедуру BUMP; изменить положение курсоров; изменить веса примеров; проверить, нет ли в задачнике противоречивых примеров, например, примеров с одинаковыми входными сигналами, но относящихся к разным классам. Если в результате всех этих действий не удалось добиться никаких положительных изменений, то придется вернуться назад и вновь начать обучение сети.
При обучении нейросети можно воспользоваться «дыроколом». Это следует делать в тех случаях, когда нейросети будут предъявляться для классификации объекты, у которых информация о некоторых входных сигналах отсутствует. Имена таких входных сигналов должны быть помечены звездочками в ptn-файле. «Дырокол» позволяет заменять у примеров задачника сигналы на этих входах нулевыми значениями. При этом для обучения предъявляются все варианты расстановки «дыр» по отмеченным входам для каждого примера. Оценка примера представляется суммой оценок по всем вариантам. Наблюдая за процессом обучения, можно заметить определенные закономерности. Распознавать часть примеров нейросеть обучается быстро. При распознавании другой части примеров нейросеть может допускать ошибки, т. е. выходные сигналы нейросети для этих примеров не всегда соответствуют указанным в задачнике. Среди последних могут быть примеры, при распознавании которых нейросеть ошибается почти постоянно. Наличие таких примеров может стать предметом специального исследования. Чтобы проиллюстрировать это, рассмотрим один конкретный пример.
Рассматриваемые ниже эксперименты были проведены американским исследователем Кори Ваксманом и подробно описаны в его работе (см. приложение).
Пакет CLAB использовался для решения задачи предсказания результата выборов президента США. Входные сигналы в этой задаче представлялись в виде ответов на 12 различных вопросов. Эти вопросы касаются экономической и политической ситуации и социальных условий во время выборов, а также личностей кандидатов на пост президента. Выходные сигналы показывали, к какой партии принадлежал победитель выборов — к партии, которая является правящей в настоящий момент, или к оппозиционной. В качестве обучающей выборки использовались результаты выборов с 1860 по 1980 годы.
В ходе обучения было обнаружено, что хуже всего нейросеть обучалась предсказывать результаты выборов 1892, 1880 и 1896 годов.
Кроме этого, были проведены следующие эксперименты. В качестве первоначальной обучающей выборки использовались примеры с результатами двух первых выборов. Примеры с последующими выборами предъявлялись нейросети для классификации. Те примеры, для которых были получены правильные выходные сигналы, включались в обучающую выборку, и вся процедура повторялась. Заканчивалась эта процедура в том случае, когда нейросеть не могла дать правильного ответа ни для одного из оставшихся примеров. В результате серии таких экспериментов были получены группы примеров. Они отличались между собой, но все они содержали те три примера, которые были выделены ранее как наиболее "труднообучаемые".
Таким образом, в ходе обучения нейросети возник вопрос: почему нейросеть упорно предсказывает для некоторых выборов не тот результат, что имел место в действительности? Этот вопрос следует, очевидно, адресовать историкам, для которых он может оказаться темой интересного исследования.
Этот пример показывает, что в процессе обучения нейросети для решения конкретной задачи могут возникать качественно новые задачи. В их основе лежат некоторые отношения между объектами исследования, которые удается установить при помощи нейросети.
Классификация объектов
После завершения процесса обучения нейросеть готова к работе. Ей можно предъявлять для классификации наборы входных сигналов, описывющие некоторые объекты. Но в отличие от примеров задачника, для которых указывался класс объекта, здесь класс объекта неизвестен, и его должна определить нейросеть.
В пакете CLAB для классификации служит программа tester. Сначала она предлагает пользователю выбрать имя файла, содержащего карту синапсов, и имя ptn-файла. Затем программа генерирует нулевые значения для входных сигналов и классифицирует такой объект. На экране, как и всякий раз после тестирования, появляется такая же картинка, как при работе программы Teacher, — крестик, соответствующий выходным сигналам, и оценки. Поскольку пример рассматривается один, а высвечиваются две оценки, поясним, как их трактовать. Красным цветом высвечивается оценка, соответствующая ситуации, в которой данный пример считается принадлежащим к классу «красных», синим цветом — к классу синих.
В нижней части экрана высвечивается указание "press any key" ("нажать любую клавишу"). После того, как пользователь нажмет любую клавишу, программа предложит ввести значения входных сигналов. При этом, как и при составлении задачника, на экране высвечиваются окно NEURON с именами входных сигналов и окно VALUE с их значениями. Кроме этого, высвечиваются еще два окна: одно с надписью "to red" ("к красным"), другое — "to blue" ("к синим"). Они предназначены для так называемых улучшателей. О том, что они собой представляют и для чего нужны, будет подробно рассказано дальше.
Значения входных сигналов, как и для задачника, вводятся в окне VALUE. После того, как всем входным сигналам присвоены нужные значения, следует нажать клавишу «пробел». Тогда программа определит класс данного объекта и представит информацию об этом в виде, описанном выше. Заметим, что если крестик попадает в левую нижнюю часть квадрата, то он изображается красным цветом, если в правую верхнюю — синим.
Ознакомившись с результатами тестирования, можно вновь перейти к вводу значений входных сигналов, нажав любую клавишу. Всю описанную здесь процедуру пользователь может повторять столько раз, сколько потребуется.
Дополнительные возможности нейросети
Как было сказано выше, после классификации объекта на экране наряду с другой информацией высвечиваются два окна — "to red" и "to blue". Каждому входному сигналу ставится в соответствие по числу в каждом из этих окон. Эти числа могут принимать значения в интервале [-1,1]. Таким образом, в этих двух окнах выводятся на экран два вектора. Каждый из них имеет такую же длину, как и вектор входных сигналов. Эти векторы называются улучшателями и представляют собой антиградиенты по входным сигналам. Изменение входных сигналов по указанному таким вектором направлению приводит к улучшению соответствующей оценки. Если изменить значения входных сигналов в направлении, указанном в окне "to red", то улучшится оценка, высвечиваемая красным цветом. Если же изменить значения входных сигналов согласно окну "to blue", то улучшится «синяя» оценка.
Таким образом, один из улучшателей показывает, как можно улучшить оценку объекта, оставив его в том же классе, в который он попал после тестирования. Другой улучшатель показывает, какими воздействиями можно попытаться перевести объект в другой класс.
Кроме этого, для каждого объекта при помощи улучшателей можно сортировать входные сигналы по степени их важности. Для этого после тестирования объекта нужно сравнить абсолютные значения компонент улучшателя. Чем больше такое значение, тем важнее соответствующий ему входной сигнал. При этом улучшатель из окна "to red" позволяет получить сортировку входных сигналов по степени их важности для улучшения «красной» оценки, а из окна "to blue" — "синей".
Знак компоненты улучшателя показывает, в какую сторону следует изменить значение соответствующего входного сигнала. Знак "+" означает увеличить, «-» — уменьшить.
Возможность получить такую сортировку входных сигналов является важным свойством пакета CLAB и может иметь большое значение для ряда практических задач. Покажем это на примере задачи выборов президента США.
В результате решения этой задачи можно оценить шансы на победу в выборах каждого кандидата. Кроме этого, можно определить, какие действия следует предпринять в первую очередь каждой партии, чтобы по возможности обеспечить победу своего кандидата.
Допустим, что программа предсказывает победу кандидата от правящей партии, но оценка при этом является недостаточно хорошей. Возникает вопрос: какие действия следует предпринять правящей партии во время предвыборной кампании, чтобы упрочить положение своего кандидата?
Очевидно, следует ознакомиться с сортировкой вопросов, которая получена при помощи улучшателя соответствующего цвета (т. к. в демонстрационном примере правящей партии сопоставлен красный цвет, то это улучшатель из окна "to red").
Заметим, что в данной задаче лишь часть вопросов допускает, что в результате некоторых действий можно изменить ответы на них. Другие вопросы, которые допускают лишь предопределенные ответы (например, вопрос о том, получила ли правящая партия более 50 % голосов избирателей на прошлых выборах), рассматривать не будем.
Пусть самым важным из рассматриваемых является вопрос о том, была ли серьезная конкуренция на предварительных выборах кандидата от правящей партии. При этом наличие такой конкуренции является плохим фактором для правящей партии. Отсюда следует, что правящая партия должна так строить свою предвыборную политику, чтобы у ее кандидата не было конкурентов внутри партии.
Изменив в нужную сторону значение соответствующего входного сигнала, можно сразу протестировать новый вектор входных сигналов и посмотреть, как изменится оценка.
В данной ситуации возникает и другой вопрос: что предпринять оппозиционной партии, чтобы сделать возможной победу своего кандидата? Ответ на этот вопрос можно получить, ознакомившись с сортировкой вопросов, полученной при помощи другого улучшателя (в данном случае из окна "to blue"). Допустим, что наиболее важным является вопрос о том, была ли активной деятельность третьей партии в год выборов. В этом случае оппозиционной партии имеет смысл финансировать третью партию для повышения ее активности.
Этот пример наглядно показывает, насколько полезной является возможность выяснить, какие вопросы более важны для достижения заданной цели.
Инструкции пользователю по работе с пакетом CLAB
Инсталляция
Пакет CLAB поставляется на дискете в виде саморазархивирующегося файла с именем clab.exe. Для того, чтобы подготовить пакет к работе, нужно выполнить следующие действия.
Для размещения пакета рекомендуется создать директорию, например, с именем CLAB. В эту директорию нужно скопировать с дискеты файл clab.exe. Поскольку в этом файле пакет находится в сжатом виде, его нужно разархивировать. Для этого следует запустить файл на выполнение, т. е. набрать имя clab и нажать клавишу «Enter». В результате в директории CLAB, кроме файла clab.exe, появятся следующие файлы:
clab.doc
editor.exe
netgener.exe
teacher.exe
tester.exe
clab.fnt
elect.pbl
elect.ptn
В файле clab.doc содержится текст настоящей документации. Файлы с расширением. exe содержат рабочие программы пакета. В файлах elect.pbl и elect.ptn содержатся задачник и ptn-файл для демонстрационной задачи. Файл clab.fnt предназначен для загрузки экранного шрифта в графическом режиме.
После этого можно начинать работу с пакетом CLAB.
Файл clab.exe для экономии места можно удалить из директории CLAB, оставив его на дискете.
Если пользователь собирается работать с пакетом не в директории CLAB, а в какой-либо другой директории, то ему следует включить в файл autoexec.bat в оператор path дорожку к созданной директории CLAB.
Обучение работе с пакетом clab на демонстрационной задаче
Работа с пакетом CLAB состоит из следующих шагов:
1) создание ptn-файла;
2) создание задачника;
3) создание нейросети;
4) обучение нейросети;
5) тестирование.
Для этих шагов (кроме первого) в пакете имеются соответствующие программы. Чтобы помочь пользователю приобрести основные навыки работы с этими программами, в пакет включена демонстрационная задача «Выборы президента США».
Рекомендуется начать знакомство с пакетом CLAB с этой задачи. Это не отнимет много времени, но позволит познакомиться со спецификой работы нейроклассификаторов, в частности, данного пакета, а также избавит в дальнейшем от ряда затруднений.
Для данного примера имеются готовые ptn-файл (elect.ptn) и задачник (elect.pbl). Поэтому воспользуемся ими и начнем работу сразу с генерации сети. Вопросы, связанные с созданием ptn-файла и задачника, обсудим позже.
Чтобы создать нейросеть, нужно запустить программу netgener. Эта программа позволяет создать файл для хранения карты синапсов (назовем его test.map) и ввести значения параметров нейросети. Условимся, что в нашей задаче создавать этот файл будем в текущей директории.
Программа netgener в начале работы высвечивает на экране имена поддиректорий и всех файлов, содержащихся в текущей директории. Это позволяет пользователю убедиться, что в данной директории не содержится файла с таким же именем, какое он собирается дать создаваемому файлу.
Далее следует нажать клавишу «пробел». Это означает, что пользователь будет создавать файл в текущей директории, поэтому программа предложит ввести имя файла. На экране появится сообщение
Имя файла следует набирать, начиная с позиции, на которую установлен курсор, т. е. в последней строке сообщения после двоеточия.
Заметим, что в пакете CLAB по умолчанию полагается, что файлы для хранения карт синапсов имеют имена с расширением .map. Поэтому в данном случае набирать имя файла можно без расширения, программа сама добавит к имени файла расширение .map.
После того, как пользователь укажет имя файла, сообщение на экране будет иметь вид
Для ввода имени файла следует нажать клавишу "Enter".
После этого программа переходит к вводу с экрана параметров сети. На экране появляется сообщение
Тем самым пользователю предлагается указать количество нейронов в создаваемой сети. Число 64 во второй строке — это максимальное допустимое количество нейронов.
Для рассматриваемой задачи рекомендуем указать число нейронов, равное 14. Это число есть сумма 12 входных нейронов (по числу входных сигналов) и 2 выходных нейронов.
Набирать на экране значения всех параметров нейросети, которые будут вводиться в программе netgener, следует с позиции, на которую установлен курсор. Для ввода параметров следует нажимать клавишу «Enter». Эти действия повторяются постоянно при вводе значения очередного параметра, запрашиваемого программой. Поэтому ниже мы не будем каждый раз их особо оговаривать, полагая, что пользователь будет их выполнять.
После ввода числа нейронов программа запрашивает значение следующего параметра, и на экране появляется сообщение
Значение параметра TIME указывает число тактов времени от получения входных сигналов до выдачи результата. Число 10 является максимально возможным значением этого параметра. Для рассматриваемой задачи следует ввести значение параметра TIME, равное 3.
Далее программа последовательно запрашивает значения остальных параметров, при этом во второй строке сообщения каждый раз высвечивается значение параметра, которое принимается по умолчанию. Эти значения вполне удовлетворяют нашей задаче, поэтому больше не нужно задавать никаких новых значений, достаточно после каждого сообщения на экране нажимать клавишу "Enter".
Перечислим эти сообщения в порядке их появления на экране, пояснив каждое из них.
После ввода параметра TIME программа запрашивает значение для параметра характеристической функции. На экране высвечивается сообщение
Далее следует сообщение
которым программа запрашивает значение для начального шага движения по антиградиенту. Наконец, последовательно появляются сообщения
в которых программа запрашивает значения соответственно нижнего и верхнего уровней начальных значений весов синапсов.
После этого работа программы netgener закончена. В результате в текущей директории создан файл test.map, в котором содержится карта синапсов для необученной нейросети.
Для обучения нейросети нужно запустить программу teacher. Вначале эта программа просит указать имя файла с картой синапсов. На экране высвечиваются надпись "Choose map" и имена файлов с расширением. map, содержащихся в текущей директории.
Как упоминалось выше, в нашей задаче мы полагаем, что все файлы, необходимые для работы, содержатся в текущей директории. Поэтому для указания имени нужного нам файла (test.map) следует установить курсор на экране на имя этого файла, а затем нажать клавишу «пробел» или клавишу "Enter".
Далее программа просит указать имя ptn-файла. На экране высвечиваются надпись "Choose pattern File" и имена файлов с расширением. ptn, содержащихся в текущей директории.
Для нашей задачи нужно указать файл elect.ptn. Выбор ptn-файла, а затем и выбор задачника осуществляются точно так же, как и выбор файла с картой синапсов.
Для выбора задачника на экране высвечиваются надпись "Choose problembook" и имена файлов с расширением. pbl из текущей директории.
Для данной задачи нужно указать файл с именем elect.pbl.
После этого начинается сам процесс обучения, за которым можно наблюдать на экране. В соответствующем разделе описания пакета CLAB подробно рассказано, какая информация высвечивается на экране в процессе обучения. Напомним, что в левой половине экрана изображаются крестиками выходные сигналы нейросети для каждого примера задачника, а в правой половине экрана высвечиваются оценки для этих примеров
После определения оценки для каждого примера задачника на экране высвечивается крестик, соответствующий этому примеру. При этом крестик, который соответствовал этому примеру ранее, исчезает. Одновременно вместо старой оценки для этого примера высвечивается новая.
В правой верхней части экрана высвечиваются номер текущей страницы задачника (в демонстрационной задаче задачник состоит из одной страницы) и счетчик для красных и синих примеров. Счетчик показывает номера примеров каждого цвета, для которых к настоящему моменту получены оценки.
В нижней части экрана высвечиваются значение средней оценки для всех примеров текущей страницы задачника, а также значения средних оценок отдельно для красных и синих примеров.
Обучение для демонстрационной задачи происходит достаточно быстро и не трбует вмешательства пользователя. В процессе обучения крестики на экране постепенно стягиваются к курсорам соответствующего цвета.
Пользователь должен сам определить, когда закончить процесс обучения. В качестве критерия для этого можно использовать значение средней оценки. Для данной задачи обучение можно заканчивать, когда средняя оценка принимает значение порядка 0,01.
Для того, чтобы закончить обучение и выйти из программы teacher, следует нажать клавишу «Esc». При этом в файле test.map сохранится карта синапсов для обученной нейросети.
Теперь, наконец, можно приступать к тестированию. Оно для рассматриваемой задачи заключается в следующем. Нужно ответить на 12 вопросов. Ответы кодируются следующим образом: 1 — да, –1 — нет, 0 — не знаю. Обученная нейросеть определит, кандидат от какой партии одержит победу в выборах. Правящей партии соответствует красный цвет, оппозиционной — синий.
Ответы на вопросы можно выбрать произвольно, но гораздо интереснее протестировать реальную ситуацию, например, определить, кто победит в выборах 1992 года — Буш или Клинтон.
Для тестирования нужно запустить программу tester. Программа предложит указать имя файла с картой синапсов, а затем имя ptn-файла. Это делается точно так же, как и при работе с программой teacher, поэтому здесь мы не будем описывать эту процедуру.
После этого тестируется пример с нулевыми значениями входных сигналов, поскольку значений входных сигналов мы еще не задали. Картинка, которая появляется на экране всякий раз
после тестирования, описана в разделе "Классификация объектов". Заметим, что для примера с нулевыми входнымы сигналами крестик на экране будет располагаться в центре квадрата, а значения оценок (красной и синей) совпадут.
В нижней части экрана высвечивается указание "press any key". Выполнив его, т. е. нажав любую клавишу, можно перейти к просмотру текущих значений входных сигналов и вводу новых значений для них.
После нажатия любой клавиши на экране, как было рассказано ранее, высвечиваются окно NEURON с именами входных сигналов (они считываются из ptn-файла), окно VALUE со значениями входных сигналов и два окна с улучшателями ("to red" и "to blue").
Press F1 for Help 1 — 'Да', –1 — 'Нет', 0 — 'Не знаю'.
Neuron Value to red to blue Правящая партия была у власти более 1 срока? 1.000 -1.000 1.000 Правящая партия получила больше 50% на прошлых выборах? 1.000 0.651 -0.651 В год выборов была активна третья партия? 1.000 -0.425 0.425 Была серьезная конкуренция при выдвижении от правящей партии? -1.000 -0.586 0.586 Кандидат от правящей партии был президентом в год выборов? 1.000 0.116 -0.116 Был ли год выборов временем спада или депрессии? -1.000 -0.250 0.250 Был ли рост среднего нац. валового продукта на душу населения > 2.1%? 0.000 0.530 -0.530 Произвел ли правящий президент существенные изменения в политике? 1.000 0.404 -0.404 Во время правления были существенные социальные волнения? 1.000 -0.549 0.549 Администрация правящей партии виновна в серьезной ошибке/скандале? -1.000 -0.280 0.280 Кандидат правящей партии — национальный герой? -1.000 0.184 -0.184 Кандидат оппозиционной партии — национальный герой? -1.000 -0.323 0.323Для нашей задачи число входных сигналов равно 12. Их имена представляют собой тексты вопросов. Ответы на них нужно ввести в окне VALUE, закодировав, как было указано выше (заметим, что в верхней строке экрана для этого высвечивается подсказка).
Итак, выбрав вариант ответа на каждый вопрос, т. е. значение соответствующего входного сигнала, можно приступать к их вводу. Для этого нужно нажать клавишу «Enter». Тогда в окне VALUE в строке, на которой был установлен курсор при просмотре, появится мигающий курсор. Это говорит о том, что указанное курсором значение входного сигнала можно редактировать. Для этого нужно набрать значение входного сигнала и для его ввода нажать клавишу «Enter». В результате это значение будет введено, и курсор переместится в следующую строку окна VALUE. Тогда точно так же можно редактировать входной сигнал в этой строке и т. д.
Выход из режима редактирования происходит автоматически после того, как введен самый последний входной сигнал. Если нужно выйти из режима редактирования раньше, то следует нажать клавишу «Esc». После выхода из режима редактирования мигающий курсор исчезнет. Заметим, что редактировать в программе tester можно только содержимое окна VALUE.
После того, как все значения входных сигналов введены, можно протестировать этот пример. Для этого нужно нажать клавишу «пробел». На экране появится результат тестирования. Цвет крестика показывает, кандидат от какой партии имеет больше шансов на победу в выборах. Расстояние от крестика до курсора соответствующего цвета показывает, насколько вероятна победа этого кандидата. Если крестик находится вблизи центра квадрата, то оба кандидата имеют примерно равные шансы на победу. Чем ближе оказывается крестик к курсору соответствующего цвета, тем больше уверенность, с которой можно предсказать победу этого кандидата.
После тестирования можно вновь перейти к просмотру и редактированию входных сигналов, нажав любую клавишу. При этом для примера, который только что был протестирован, высвечиваются значения улучшателей. Об улучшателях было подробно рассказано в разделе "Дополнительные возможности нейросети". Там же были описаны эксперименты с задачей выборов президента. Теперь пользователь может попытаться повторить их сам (определить, какие входные сигналы нужно изменить, чтобы упрочить положение победившего кандидата либо, напротив, обеспечить победу другого кандидата).
Если пользователь хочет определить победителя выборов 1992 года, то ему нужно ввести такие ответы на вопросы, которые соответствуют политической и экономической ситуации в данный момент. Интересно пронаблюдать, как изменялись за последнее время шансы Буша на победу в выборах в зависимости от изменения политической ситуации. До событий в Лос-Анджелесе нейросеть уверенно предсказывала победу Буша. После этих событий (ответ на вопрос о том, были ли значительные социальные волнения, изменился с отрицательного на положительный) преимущество Буша стало совсем незначительным. Наконец, после появления независимого кандидата на пост президента (этот факт можно трактовать как рост активности третьей партии) нейросеть предсказывает поражение Буша и победу Клинтона.
Отметим, что в программе tester для помощи пользователю при редактировании входных сигналов имеется Help.Чтобы получить его, нужно нажать клавишу «F1». После этого на экране появляется таблица, в которой перечислены возможности пользователя при работе с программой tester.
Сделаем небольшие пояснения к этой таблице. Клавиши со стрелками «вверх» и «вниз» используются для передвижения курсора в окне VALUE только при просмотре. В режиме редактирования перемещать курсор этими клавишами из одной строки в другую нельзя, можно лишь пользоваться клавишами со стрелками «влево» и «вправо» для передвижения курсора в соответствующем направлении.
При редактировании значений входных сигналов используются клавиши с цифрами от 0 до 9, а также клавиши "+", «-», "BkSp" и «Del». Пользоваться ими следует точно так же, как и при работе с любым стандартным редактором.
Клавиша «Enter», как было сказано выше, используется для перехода из режима просмотра в режим редактирования, а также при работе в режиме редактирования для ввода каждого отредактированного значения.
Для перехода из режима редактирования в режим прсмотра используется клавиша «Esc», для тестирования — клавиша "пробел".
Чтобы вернуться к работе после просмотра таблицы Help, достаточно нажать любую клавишу. Заметим, что получить Help, нажав клавишу «F1», можно только в режиме просмотра значений входных сигналов.
Для выхода из программы tester нужно одновременно нажать клавиши «Ctrl» и "Q".
После того, как пользователь научится работать с демонстрационной задачей, он может приступать к решению задачи, стоящей перед ним. В настоящем разделе перечислены не все возможности пакета CLAB, а лишь та их часть, которая потребовалась для работы с демонстрационной задачей. Кроме того, такие этапы работы, как создание ptn-файла и создание задачника, здесь не рассматривались вообще. Поэтому ниже приводятся инструкции, содержашие исчерпывающую информацию по работе с пакетом.
Инструкции по созданию ptn-файла
Ptn-файл, как было сказано выше, представляет собой текстовый файл. При его составлении можно пользоваться любым редактором, поэтому пакет CLAB не содержит специальных средств для создания ptn-файла.
Поясним, как составляется ptn-файл. В первой строке первые 10 символов занимает имя класса «красных», следующие 10 символов — имя класса "синих".
Все остальные строки ptn-файла должны иметь следующую структуру. Первым символом строки должен быть либо пробел, Либо символ "*", если пользователь хочет пометить указанный в данной строке входной сигнал для применения «дырокола» при обучении.
Далее указыввается число входных нейронов, имеющих то имя, которое будет содержаться в этой строке. Как было сказано ранее, это число можно указывать равным нулю (см. раздел "Ptn-файл"). Поясним это более подробно. Если имя входного сигнала (например, текст вопроса) не входит в одну строку, то его можно набирать в нескольких строках. При этом нужно число соответствующих этому имени входных нейронов указать только в одной из этих строк, а для остальных строк указать в этой позиции нули.
Заметим, что если пользователь хочет пометить звездочкой входной сигнал с именем, содержащимся более чем в одной строке, то символ "*" нужно указывать в той же строке, в которой указано число входных нейронов, отличное от нуля.
После числа входных нейронов должен быть пробел, а затем может следовать имя входного сигнала. При вводе имени входного сигнала следует помнить, что длина строки не должна превышать 60 символов, иначе при работе с ptn-файлом в программах editor и tester это имя не будет помещаться в соответствующем окне на экране.
Указывая число входных нейронов для каждого имени, мы тем самым задаем общее число входных нейронов для программ пакета CLAB.
В качестве примера ptn-файла пользователь может посмотреть ptn-файл для демонстрационной задачи, который содержится в файле elect.ptn.
Отметим, что составление ptn-файла не является обязательным шагом при работе с пакетом CLAB, он нужен только для удобства пользователя. Если пользователь не создает ptn-файл, то программы, для работы которых он нужен, генерируют стандартный ptn-файл. При этом каждая из таких программ запросит у пользователя число входных сигналов. Именами входных сигналов в стандартном ptn-файле будут их номера.
Инструкции по выбору файлов и директорий при работе с пакетом clab
В процессе работы неоднократно возникает необходимость указать имя файла, который нужен при работе с данной программой, или выбрать директорию, в которой программа будет создавать файл (например, в программе netgener создается файл для хранения карты синапсов, а в программе editor может создаваться файл с задачником). В разделе с описанием демонстрационной задачи рассматривались самые простые случаи, когда при выборе имени файла нужный файл содержался в текущей директории, и его имя высвечивалось на экране. Файл с картой синапсов в программе netgener также создавался в текущей директории. Однако возможны ситуации, когда нужный файл находится в другой директории на текущем диске или на другом диске. Создавать файл также можно в другой директории или на другом диске.
Действия пользователя по переходу в другую директорию и на другой диск являются стандартными для всех программ, поэтому достаточно описать их один раз.
Из текущей директории можно перейти в поддиректорию или наддиректорию. Для этого нужно установить курсор на экране на имя поддиректории или на символ ".." соответственно, а затем нажать клавишу «Enter». В результате указанная директория становится текущей, и на экране высвечиваются имена содержащихся в ней поддиректорий и файлов. Возможно, что эти действия придется повторить несколько раз до тех пор, пока искомая директория не станет текущей.
Для того, чтобы перейти на другой диск, нужно нажать клавишу «Esc». После этого на экране появится сообщение
No file selected
Try again?
Y.
Если после этого нажать клавишу с буквой Y или клавишу «Enter», то программа предложит указать нужный диск, и на экране появится сообщение
Enter drive letter.
Под ним будет высвечиваться буква, соответствующая текущему диску. Для указания нужного диска следует нажать клавишу с буквой, соответствующей этому диску. В результате диск, обозначенный этой буквой, станет текущим. На экране будет высвечиваться содержимое директории, которая была текущей при работе с этим диском в последний раз. После этого можно, если это необходимо, перейти в другую директорию на этом диске. Действия, которые следует при этом выполнить, описаны выше.
Если после сообщения
No file selected
Try again?
Y
нажать клавишу с буквой N, то это будет означать отказ от указания имени файла или выбора директории. В этом случае дальнейшая работа каждой программы зависит от конкретной ситуации, в которой произошел данный отказ. Об этом будет говориться в следующих разделах.
Сделаем одно важное замечание. Обычно файлам, которые создаются для работы с пакетом CLAB, присваиваются имена с соответствующими расширениями (для ptn-файла это расширение .ptn, для файла с задачником — .pbl, для файла с картой синапсов — .map). Однако файлы могут иметь имена с произвольными расширениями.
В тех случаях, когда программа просит выбрать имя файла, на экране во всех директориях на текущем диске высвечиваются только те имена файлов, которые имеют соответствующие расширения (при выборе директории для создания файла на экране высвечиваются имена файлов с любыми расширениями). После перехода на другой диск на экране будут высвечиваться имена файлов уже с любыми расширениями. Поэтому для того, чтобы получить на экране имена файлов с любыми расширениями для директорий на текущем диске, нужно, как и при переходе на другой диск, нажать сначала клавишу «Esc», а затем клавишу с буквой Y или клавишу «Enter». При этом на экране будут высвечиваться соответствующие сообщения. После этого следует нажать клавишу «Enter». В результате на экране будет высвечиваться полное содержимое текущей директории.
Инструкции по работе с программой editor
Программа editor позволяет редактировать имеющийся задачник либо составлять новый. В начале работы данная программа предлагает пользователю выбрать ptn-файл. В случае отказа от его выбора программа создаст стандартный ptn-файл.
Далее программа предлагает выбрать файл с задачником. Если пользователь собирается создавать новый задачник, то ему нужно отказаться от выбора файла с задачником. Если же пользователь намерен редактировать уже имеющийся задачник, то он должен указать имя файла с этим задачником.
После выбора файла с задачником можно приступать к редактированию. Для этого на экране высвечиваются два окна: окно NEURON с именами входных сигналов и окно VALUE со значениями входных сигналов для первого примера с первой страницы задачника.
Во второй строке экрана высвечивается имя класса этого примера. Напомним, что имена классов задаются в ptn-файле. В стандартном ptn-файле классам присваиваются имена «red» и «blue». Если данный пример относится к классу «красных», то имя этого класса будет высвечиваться красными буквами на левом краю строки. Если же пример относится к классу «синих», то имя класса будет высвечиваться синими буквами на правом краю строки. Если в задачнике, кроме класса данного примера, содержался какой-либо комментарий, то этот комментарий также будет высвечиваться на экране рядом с именем класса (например, в файле elect.pbl для демонстрационной задачи в качестве комментария для каждого примера указан год выборов). В правом верхнем углу экрана высвечивается номер страницы задачника. О том, как редактировать задачник, будет рассказано немного ниже.
Если пользователь отказался от выбора файла с задачником, то программа предложит выбрать директорию, в которой будет создаваться новый файл с задачником. В случае отказа от выбора директории произойдет выход из программы. Если же пользователь хочет создать новый задачник, то он должен выбрать директорию, после чего программа предложит ввести имя для файла с задачником. При этом на экране появится сообщение
Enter the Problembook file name.
В следующей строке после этого сообщения высвечивается курсор. Он указывает позицию, с которой нужно набирать имя файла. Для ввода имени файла нужно нажать клавишу «Enter». Заметим, что если пользователь укажет имя без расширения, то к этому имени будет по умолчанию добавлено расширение. pbl.
В результате описанных действий программа создаст задачник, состоящий из так называемого «пустого» примера, т. е. примера с нулевыми входными сигналами, который не принадлежит ни к какому классу. В этот задачник пользователь может вносить нужные примеры.
На экране, как и при редактировании старого задачника, высвечиваются окно NEURON и окно VALUE. В окне VALUE высвечиваются значения входных сигналов для «пустого» примера, т. е. нули. Поскольку класс этого примера неопределен, имя класса не высвечивается.
Дальнейшие действия пользователя одинаковы как при редактировании старого задачника, так и при составлении нового.
Программа editor позволяет редактировать содержимое окна VALUE, т. е. изменять значения входных сигналов. Редактирование содержимого окна VALUE в программе editor ничем не отличается от аналогичной процедуры для программы tester. Поскольку эта процедура подробно описана для демонстрационной задачи, повторно описывать ее мы не будем.
При составлении задачника следует помнить, что для каждого примера должна быть указана его принадлежность к одному из классов, иначе программа editor не включит этот пример в задачник. Для того, чтобы указать класс нового примера или изменить класс старого, нужно нажать клавишу с буквой R (для "красных") или с буквой L (для "синих"). После этого можно набрать комментарий к этому примеру, содержащий не более 20 символов (например, в качестве комментария к примеру можно использовать номер этого примера). Далее следует нажать клавишу «Enter». После этого во второй строке будет высвечиваться имя указанного класса с комментарием, если он был введен.
Для перехода от одного примера к другому в пределах текущей страницы используются клавиши «PgUp», "PgDn", «Home» и «End». Если нажать клавишу «PgUp», то на экране будут высвечиваться значения входных сигналов и имя класса для предыдущего примера, если «PgDn» — то для следующего. Клавиши «Home» и «End» позволяют перейти соответственно к первому или последнему примеру с данной страницы.
Отметим, что в конце страницы после примеров, введенных пользователем, программа editor всегда добавляет «пустой» пример. Этот пример и будет высвечиваться на экране после нажатия клавиши "End".
Программа editor позволяет в любом месте добавить к примерам текущей страницы новый пример. Для этого нужно тот пример, перед которым будет вставляться новый пример, сделать текущим, а затем нажать клавишу с буквой E. В результате на указанном месте будет вставлен «пустой» пример. Он будет высвечиваться на эктане, и пользователь может приступать к его редактированию.
При составлении задачника пользователю необходимо помнить, что на странице задачника должно быть не более 20 примеров, принадлежащих к одному классу. Чтобы не нарушать этого требования, нужно вовремя переходить к новой странице.
Для того, чтобы создать новую страницу, нужно перейти к последнему ("пустому") примеру с данной страницы, а затем нажать клавишу с буквой P. В результате будет создана новая страница (об этом можно узнать по изменению номера страницы на экране) с «пустым» примером. Этот пример будет текущим, и пользователь может приступать к его редактированию.
Точно так же можно разделить страницу перед любым примером. При этом тот пример, который был текущим к моменту нажатия клавиши с буквой P, станет первым примером на новой странице.
Чтобы перейти от текущей страницы задачника к предыдущей или следующей странице, нужно одновременно нажать клавиши «Ctrl» и «PgUp» или «Ctrl» и «PgDn» соответственно. Для перехода к первой странице задачника нужно одновременно нажать клавиши «Ctrl» и «Home», а для перехода к последней — клавиши «Ctrl» и "End".
Если в процессе составления или редактирования задачника возникнет необходимость сохранить текущее состояние задачника, то для этого нужно нажать клавишу "F2".
Для того, чтобы выйти из программы editor, нужно одновременно нажать клавиши «Ctrl» и «Q». Если после последнего сохранения в задачник были внесены изменения, то программа попросит указать, нужно ли их сохранить. При этом на экране появится соббщение
Problembook changed
Save it? [Y].
Если после этого нажать клавишу с буквой Y или клавишу «Enter», то в файле будет сохраняться отредактированный задачник. Если же нажать клавишу с буквой N, то файл не изменится, т. е. останется таким же, каким он был сохранен программой editor в последний раз.
При сохранении задачника всегда создается bak-файл, т. е. файл, сохраняющий состояние задачника на момент предыдущего сохранения (до внесения последних изменений). Этот файл имеет то же имя, что и задачник, но с расширением. bak.
Для удобства пользователя в программе editor имеется Help. Чтобы получить его на экране, нужно нажать клавишу «F1». В нем кратко перечислены описанные выше возможности программы editor. Для выхода из Help'а достаточно нажать любую клавишу.
Составление задачника без использования программы editor
Как уже упоминалось ранее, при составлении задачника необязательно пользоваться программой editor. Для этого можно воспользоваться и другими средствами, например, любым редактором. При этом пользователю нужно руководствоваться определенными правилами, которые при работе с программой editor выполнялись автоматически.
Задачник должен быть организован по страницам. Каждая страница должна иметь следующую структуру. В первой строке указываются два числа, разделенные пробелом. Первое число указывает количество примеров с данной страницы, принадлежащих к классу «красных», второе число — к классу «синих». Каждое из этих чисел не должно быть больше 20.
Далее должны следовать примеры. Каждый пример занимает две строки. В первой строке указываются через пробел значения входных сигналов. Во второй строке буквой R или L указывается класс этого примера. Кроме этого, во второй строке можно ввести комментарий к данному примеру. Текст комментария может иметь произвольную длину, но следует помнить, что при работе с программой editor на экран будут выводиться только первые 20 символов комментария.
Страницы задачника не отделяются друг от друга. После того, как введены все примеры для данной страницы, можно начинать вводить примеры для следующей страницы по тем же правилам. Количество страниц задачника может быть произвольным.
Инструкции по работе с программой netgener
В начале работы программа netgener предлагает выбрать директорию, в которой будет создаваться файл с картой синапсов. При этом, как было сказано при описании демонстрационной задачи, на экране высвечиваются имена поддиректорий и всех файлов, содержащихся в текущей директории. После перехода в нужную директорию следует нажать клавишу «пробел». Это означает, что файл с картой синапсов будет создаваться в данной директории.
Заметим, что если при выборе директории нажать клавишу «Esc», а затем клавишу с буквой N, т. е. отказаться от выбора директории, то произойдет выход из программы netgener без генерации нейросети.
После выбора директории программа предложит ввести имя файла и значения параметров нейросети. Этот этап работы с данной программой подробно рассмотрен в разделе с описанием демонстрационной задачи.
Если имя файла будет указано без точки, то к нему по умолчанию будет добавлено расширение. map. В противном случае пользователь может указать любое расширение. Рекомендации по выбору значений вводимых параметров содержатся в разделе "Создание нейросети".
Инструкции по работе с программой teacher
Вначале программа teacher предлагает пользователю последовательно указать файл с картой синапсов, ptn-файл и файл с задачником. В случае отказа пользователя от выбора файла при выборе файла с картой синапсов или файла с задачником происходит выход из программы, поскольку эти файлы являются обязательными для ее работы. Если же пользователь откажется от выбора ptn-файла, то программа сгенерирует стандартный ptn-файл и продолжит работу.
После выбора файлов начинается процесс обучения. При описании демонстрационной задачи предполагалось, что процесс обучения происходит без вмешательства пользователя. Однако программа teacher, как было сказано ранее, позволяет вмешиваться в процесс обучения (передвигать курсоры, изменять веса, использовать процедуру BUMP). Расскажем, как это сделать.
Для того, чтобы прервать процесс обучения, нужно нажать любую клавишу. После этого в нижней части экрана высвечивается надпись "Wait a bit, please!" (Подождите, пожалуйста!). Можно подождать, когда вместо нее загорится надпись "Change task" (Смените задачу), и затем нажимать нужную клавишу. Можно и не дожидаться смены надписи, а нажать нужную клавишу сразу. В этом случае в дальнейшем будет использоваться карта синапсов, обученная на предыдущем цикле, а градиент, насчитанный частично или полностью в текущем цикле, игнорируется.
Описанные действия выполняются каждый раз при прерывании процесса обучения, поэтому далее мы их не будем упоминать, а будем лишь указывать, какая клавиша используется для управления процессом обучения в каждом случае.
Если нажать клавишу «F1», то на экране появится Help для программы teacher. В нем перечислены клавиши, которые можно использовать для вмешательства в процесс обучения, и даны краткие пояснения. Чтобы продолжить обучение после просмотра Help'а, достаточно нажать любую клавишу.
В процессе обучения может возникнуть необходимость сохранить текущую карту синапсов. Для этого нужно нажать клавишу «F2». Тогда в файле, который используется для хранения карты синапсов, будут сохраняться значения весов синапсов, полученные к текущему циклу обучения, а процесс обучения будет продолжаться.
Чтобы переместить курсоры, нужно нажать клавишу «F3». После этого при помощи клавиш со стрелками «вверх», "вниз", «вправо» и «влево» можно передвигать курсоры в соответствующих этим стрелкам направлениях. Первым можно передвигать курсор, соответствующий текущему примеру. Если в момент прерывания насчитывалась оценка для «красного» примера, то можно передвигать красный курсор, если для «синего» примера, то синий. После того, как этот курсор установлен на нужное место, можно приступать к перемещению другого курсора. Для этого нужно нажать клавишу «Tab». Для того, чтобы продолжить процесс обучения после перемещения курсоров, нужно нажать клавишу "Enter".
Для изменения весов примеров нужно нажать клавишу «F4». После этого в правой части экрана, где высвечиваются веса и оценки для примеров с текущей страницы задачника, появится курсор. Он высвечивается на текущем примере. Передвигать курсор вверх и вниз следует при помощи клавиш с соответствующими стрелками, а с «красных» примеров на «синие» и обратно при помощи клавиш со стрелками «вправо» и «влево». После того, как курсор установлен на нужном примере, можно задавать новый вес этому примеру. Это делается нажатием клавиши с цифрой, указывающей этот вес (от 0 до 9). После того, как установлен вес для одного примера, можно перейти к установлению весов для других примеров. Чтобы продолжить обучение с новыми весами, нужно нажать клавишу "Enter".
Если задачник состоит из нескольких страниц, то для перехода к обучению нейросети на примерах со следующей страницы нужно нажать клавишу «F5». При этом на экране будет высвечиваться номер этой страницы. После последней страницы переход осуществляется к первой странице задачника.
Для того, чтобы применить процедуру BUMP, нужно нажать клавишу «F6». Тогда на экране появится сообщение
Are you to Bump? (y or n)
Если нажать клавишу с буквой N, то BUMP не выполнится. Если же нажать клавишу с буквой Y, то программа попросит ввести уровень BUMP'а, и на экране появится сообщение
Enter Bump Level (0<L<1):
После двоеточия указывается текущее значение этого параметра. Если его нужно изменить, то новое значение нужно набирать, начиная с позиции, на которую установлен курсор. Далее следует нажать клавишу «Enter», после чего продолжится обучение.
Для применения «дырокола» нужно нажать клавишу «F7». После этого программа запрашивает, сколько входных сигналов могут одновременно иметь неопределенные значения. При этом на экране появляется сообщение
How many entries are to set as 'unknown'?
Это число вводится точно так же, как и значение параметра Bump Level при вызове процедуры BUMP. После этого нажимается клавиша «Enter». Заметим, что это число не рекомендуется задавать слишком большим (больше 3), иначе время обучения может существенно возрасти.
Чтобы можно было применить «дырокол», в ptn-файле должны быть отмеченные звездочками имена входных сигналов. Если в ptn-файле звездочек нет, то программа проигнорирует описанные выше действия, и обучение будет продолжаться без «дыр». Если число звездочек в ptn-файле меньше, чем число «дыр», указанное при вызове «дырокола», то при обучении число «дыр» будет считаться равным числу звездочек.
В программе teacher предусмотрена возможность обучать нейросеть по примерам со всех страниц задачника в случае, если задачник состоит из нескольких страниц. Для этого нужно нажать клавишу «F8». При этом значения весов и оценок, которые высвечивались в правой части экрана при постраничном обучении, высвечиваться не будут. Заметим, что обучение по всем страницам задачника происходит быстрее, чем последовательное обучение по отдельным страницам. Но в этом случае пользователь получает меньше информации, т. к. не высвечиваются оценки для каждого примера. Кроме того, ограничиваются возможности по управлению процессом обучения (нельзя изменять веса примеров).
Рекомендуем пользователю на некоторое время вернуться к демонстрационной задаче и при обучении применить описанные здесь возможности программы teacher. Это позволит ему оценить, к каким последствиям приводят различные формы вмешательства в процесс обучения. Поскольку нейросеть в демонстрационной задаче обучается быстро, эти эксперименты не займут много времени и вместе с тем позволят приобрести полезный опыт.
Для выхода из программы teacher следует нажать клавишу «Esc». При этом в файле с картой синапсов, который был указан в начале работы с данной программой, будет сохраняться карта синапсов для обученной нейросети.
Инструкции по работе с программой tester
Вначале программа tester предлагает выбрать файл с картой синапсов и ptn-файл. В случае отказа пользователя от выбора файла действия программы tester аналогичны действиям программы teacher, т. е. при отказе от выбора файла с картой синапсов происходит выход из программы, а при отказе от выбора ptn-файла программа генерирует стандартный ptn-файл и продолжает работу.
Дальнейшая работа программы tester подробно описана в разделе с описанием демонстрационной задачи.
Приложение 2. Описание программ пакета «Нейроучебник»
Все программы пакета «Нейроучебник» имеют общий интерфейс. Данное описание сформировано на основе системы помощи пакета.
Сервисные функции
В данном разделе собраны описания сервисных функций общего назначения.
Работа с подсказкой
При работе с подсказкой на экране появляется окно, название которого совпадает с названием высвеченного раздела. В окне цветом, отличным от цвета основного текста, выделены ссылки. Одна из ссылок выделена цветом, отличным от цветов текста и остальных ссылок. Это выделенная ссылка.
Приведем список всех клавиш, используемых при работе с подсказкой:
F1 Переход в этот раздел подсказки. SHIFT-F1 Переход в главный каталог разделов подсказки. ALT-F1 Переход к предыдущему разделу. ENTER Переход к подразделу по выделенной ссылке. TAB Выделить следующую ссылку. SHIFT-TAB Выделить предыдущую ссылку. ↑↓ Сдвинуть содержимое подсказки на строку вниз или вверх. PgUp Сдвинуть содержимое подсказки на страницу вверх. PgDown Сдвинуть содержимое подсказки на страницу вниз. HOME Перейти к началу раздела. END Перейти к концу раздела. ESC Закончить работу с подсказкой.Смена цветов
На экране изображено окно, в правой части которого даны названия цветов, которые можно изменить.
В правой части Окна находятся подокна "Цвет текста", "Цвет фона", и "Образец текста".
В подокне "Цвет текста" черной точкой отмечен прямоугольник цвета букв.
В подокне "Цвет фона" черной точкой отмечен прямоугольник цвета фона.
В подокне "Образец текста" дан пример текста, написанного атрибутами (цвет фона и цвет текста) из верхних окон.
Выбрав курсором нужный цвет в правом списке нажмите ENTER. После этого Вы можете установить любую комбинацию фона и текста, пользуясь стрелками внутри окон "Цвет текста", "Цвет фона" и кнопкой TAB для перехода между ними. Если Вы раздумали менять цвет, то нажмите ESC.
Когда Вы подберете подходящую комбинацию цветов фона и текста нажмите ENTER. Чтобы закончить работу по подбору цветов нужно нажать ESC. После этого на нижней границе окна появляется вопрос: "Хотите запомнить измененные цвета?(y,n)". Если Вы нажмете «N», то сделанные Вами изменения будут действовать только во время текущего сеанса работы с программой. Если Вы ответите «Y», то измененные цвета будут запомнены в файле, содержащем эту программу. Это приведет к тому, что сделанные изменения сохранятся до следующего изменения.
Выбор файла
При выборе файла на экране появляется окно "Выбор файла", содержащее окна «Диски», "Каталоги", «Файлы». Внизу окна "Выбор файла" выводится информация о текущей дорожке и маске файлов.
Сразу после начала выбора файла, Вы находитесь в окне выбора диска. Выбор осуществляется при помощи стрелок «Влево», "Вправо" и клавиши ENTER. Если диск доступен и содержит файлы с заданной маской или каталоги, то после нажатия ENTER курсор переместится в окно «Каталоги» или «Файлы». Если окна «Каталоги» и «Файлы» не пусты, то выйти из режима выбора диска можно при помощи стрелок «Вверх», "Вниз" или клавиши TAB.
В окне «Каталоги» Вы можете выбрать нужный каталог и перейти в него при помощи стрелок «Вверх», "Вниз" и клавиши ENTER. Стрелка «Влево» переводит Вас в окно «Диски», а стрелка «Вправо» и клавиша TAB в окно «Файлы». При нажатии алфавитно-цифровой клавиши курсор перемещается на первый каталог, начинающийся на эту букву, или, если такого нет, на каталог, начинающийся на следующую за ней букву.
В окне «Файлы» выбор производится так же, как и в окне «Каталоги», за исключением того, что стрелка «Влево» переводит Вас в окно «Каталоги», а стрелка «Вправо» и клавиша TAB в окно "Диски".
Если Вы решили отказаться от выбора файлов — нажмите ESC.
Вертикальное меню
При работе с вертикальным меню, выбор пункта осуществляется при помощи стрелок «Вверх» и «Вниз», клавиш HOME, END, ENTER и соответствующих выделенным в пунктах буквам, а так же при помощи горячих клавиш.
Если вертикальное меню является подменю горизонтального меню, то стрелки «Влево» и «Вправо» переводят Вас в левое и правое соседнее подменю, если оно есть.
Для выхода из меню, без каких либо действий нажмите ESC.
Горизонтальное меню
При работе с горизонтальным меню, выбор пункта осуществляется при помощи стрелок «Влево», "Вправо" и «Вниз», клавиш HOME, END, ENTER и соответствующих выделенным в пунктах буквам, а так же при помощи горячих клавиш.
Если текущий пункт горизонтального меню имеет подменю, то стрелка «Вниз» и клавиша ENTER переводят Вас в подменю.
Для выхода из меню без каких либо действий нажмите ESC.
Приветствие
В окне приветствие приведены название данной программы, список спонсоров разработки и координаты группы «Нейрокомп», создавшей для Вас этот пакет. Более подробная информация о данной программе находится в разделе " О себе".
О себе
Программа Hopfield.
Эта программа является первой программой из серии обучающих программ по нейрокомпьютингу. В данной программе реализована одна из наиболее простых и, в тоже время, наиболее наглядных идеологий нейронных сетей — идеология сетей Хопфилда. Это единственная идеология нейронных сетей распознавания образов, которая не является классификационной по своей сути. Это, однако, часто приводит к эффекту ложной памяти, то есть на некоторые входные данные обученная сеть в качестве ответа выдает химеры — образы, не входившие в обучающее множество. Идеология сетей Хопфилда предполагает простой алгоритм построения синаптической карты. Говоря точнее, веса связей между нейронами не подстраиваются в ходе обучения, а вычисляются по заданному правилу при предъявлении обучающего множества. В данной программе реализованы два алгоритма вычисления синаптической карты — классический алгоритм Хопфилда и проекционный алгоритм, который повышает запоминающую способность сети Хопфилда. Конкретные характеристики о структуре сети, нейрона и других элементов программы Вы найдете в соответствующих разделах данного справочного материала.
Программа Pade.
Эта программа является пятой из серии обучающих программ по нейрокомпьютингу. В данной программе реализована полносвязная сеть с рациональными (Паде — в честь изобретателя Паде аппроксимации) нейронами. Эта сеть может обучаться различными способами. От сети, имитируемой программой SIGMOID, сеть программы PADE отличается только типом нейронов. Конкретные данные о структуре сети, нейрона и других элементов программы Вы найдете в соответствующих разделах данного справочного материала.
Программы Sigmoid и Sinus
Эти программа являются четвертой и шестой из серии обучающих программ по нейрокомпьютингу. В данной программе реализована полносвязная сеть с сигмоидными (синусоидными) нейронами. Эта сеть может обучаться различными способами. Конкретные данные о структуре сети, нейрона и других элементов программы Вы найдете в соответствующих разделах данного справочного материала.
Цвет
Это подменю служит для настройки программы на конкретную машину и конкретного пользователя. Наиболее уязвимым местом PC является разнородность используемых мониторов. Подстройка цветов позволяет сделать программу легко адаптируемой к любой машине. Более подробно о смене цветов смотрите в разделе Смена цветов.
Закончить работу
Выполнение этой функции приводит к немедленному завершению работы. При этом обучающее множество и синаптическая карта теряются. Для того чтобы избежать потерь, необходимо воспользоваться функциями запомнить обучающее множество и запомнить карту.
Главный индекс
Режимы работы программы
Основной режим
Редактирование задачи
Тестирование
Обучение
Контрастирование
Основные объекты
Стандартный задачник
Обучающее множество
Задача
Нейрон
Нейронная сеть
Синаптическая карта
Все программы кроме программыHopfield
Параметры сети
Число нейронов в сети
Число срабатываний сети
Характеристика нейронов
Параметры метода обучения
Использовать MParTan
Организация обучения
Вычисление направления
Способ оценивания
Уровень УДАРА
Параметры контрастирования
Норма для исключения
Норма для включения
Количество контрастируемых связей
Количество замораживаемых связей
Количество размораживаемых связей
Число циклов накопления критерия
Набор выделенных значений (1/2^n)
Методы предобработки
Чистый образ
Сдвиговый автокоррелятор
Автокоррелятор сдвиг+отражение
Автокоррелятор сдвиг+вращение
Автокоррелятор сдвиг+вращение+отражение
Основной режим
Основной режим работы позволяет Вам изменять обучающее множество, читать, записывать синаптическую карту, обучать нейронную сеть, тестировать ее, а также выполнять ряд других функций.
В верхней строке экрана находится основное меню программы. Ниже находятся поля пяти задач обучающего множества и тестовой задачи. Под полями задач приведен краткий список горячих клавиш и их функций. Ниже приведен полный список горячих клавиш и их функций для основного режима:
←→ Смена активной задачи. Активная задача отличается цветами рамки и заголовка. ↑↓ Смена активного примера в поле задачи. Home Сделать активным первый пример задачи. End Сделать активным последний пример задачи. ENTER Перейти в режим редактирования задачи. DELETE Удалить пример. F1 Высветить справочную информацию. Отметим, что эта клавиша работает во всех режимах. F2 Открыть стандартный задачник. F3 Запомнить обучающее множество. F4 Прочитать обучающее множество. F5 Тест обучающего множества. CTRL-F5 Тест текущего тестового примера. ALT-F5 Тест тестовой задачи. SHIFT-F5 Тест статистический (Кроме программы Hopfield). F6 Обучение нейронной сети. ALT-F6 Случайное изменение карты. CTRL-F6 Контрастирование. F7 Запомнить карту. F8 Прочитать карту. CTRL-F8 Редактировать карту. ALT-F8 Сгенерировать новую карту (Кроме программы Hopfield). F9 Выйти в меню. F10 Закончить работу. ALT-C Записать изображение активного примера активной задачи в карман.Кроме того, часть функций может быть выполнена только через выход в меню. Выбрав нужный пункт в меню и нажав F1 Вы получите справку о выполняемой им функции.
(обратно)Обучающее множество
Обучающее множество — это совокупность всех примеров задач 1,…,5. Обучающее множество может рассматриваться как целое (См. разделы Запомнить обучающее множество, Тест обучающего множества и Прочитать обучающее множество) или как совокупность задач (См. разделы Задача, Удалить задачу и Редактирование задачи). Программа предоставляет Вам возможность создавать, редактировать, записывать и читать обучающее множество.
Запомнить обучающее множество
При выполнении функции "Запомнить обучающее множество" на экран выводится запрос "Введите имя файла для запоминания" и предлагается имя последнего записанного или прочитанного файла обучающего множества. Все файлы обучающих множеств ВСЕГДА имеют расширение".PBL". Это необходимо учитывать при создании таких файлов средствами отличными от данной программы. При ответе на запрос можно не набирать расширение файла, поскольку оно будет заменено стандартным.
Прочитать обучающее множество
При чтении обучающего множества на экране появляется окно выбора файла. Вы должны выбрать нужный Вам файл или отказаться от чтения. При зачтении нового обучающего множества старое — стирается.
Открыть стандартный задачник
Функция открытия стандартного задачника предназначена для подготовки файла стандартного задачника к просмотру. Все файлы стандартных задачников имеют расширение ".TSK" и НЕСОВМЕСТИМЫ по формату с файлами обучающего множества. Программа не предусматривает средств создания и редактирования стандартных задачников. Если Вас интересует создание новых стандартных задачников, воспользуйтесь программами TaskBook и Pbl2Tsk.
Очистить обучающее множество
Эта функция производит операцию Удаления задачи со всеми задачами Обучающего множества.
Стандартный задачник
Стандартный задачник служит для облегчения создания обучающего множества и никак не влияет на обучение нейронной сети. Поэтому можно менять стандартный задачник во время обучения сети, не опасаясь влияния этой смены на ход обучения. Открытие стандартного задачника возможно несколькими способами:
• нажатием кнопки F2 в основном режиме работы;
• нажатием кнопки F2 во время просмотра стандартного задачника при редактировании задачи;
• через пункт "Открыть стандартный задачник" в подменю "Обучающее множество".
После открытия стандартного задачника Вы получаете возможность выбирать из него изображения и вводить их в обучающее множество или в число примеров тестовой задачи.
Задача
Под задачей понимается совокупность примеров, которые Вы отнесли к одному классу изображений. На экране вся информация о задаче отображается в окне "Задача #", где # — номер задачи. В окне «Задача» можно выделить следующие объекты:
• номер текущего примера;
• данные текущего примера;
• вес текущего примера;
• оценка текущего примера;
• ответ текущего примера;
• средняя оценка по всем примерам задачи.
Первые пять объектов относятся к примерам и меняются при просмотре примеров. Средняя оценка является характеристикой всей задачи в целом. Номер примера служит для идентификации примеров внутри задачи. Поле данных примера содержит задаваемую Вами в режиме редактирования задачи исходную информацию для сети. Поле ответа содержит ответ сети на предъявленный Вами пример. Для получения более полной информации о полях "вес текущего примера", "оценка текущего примера" и "средняя оценка по всем примерам задачи" смотрите разделы Вес примера и Оценка примера.
Просмотр примеров
Просмотр примеров активной задачи осуществляется в основном режиме при помощи клавиш «Вверх» и «Вниз». При этом в окне задачи появляются соответствующие поля номер примера, данные примера, вес примера, оценка примера, ответ примера.
Редактирование задачи
Режим редактирования задачи имеет свой набор горячих клавиш. Горячие клавиши основного режима НЕ действуют. В режиме редактирования задачи Вы можете создавать новые примеры или редактировать старые. Ниже приведен список горячих клавиш режима редактирования задачи и описание их функций:
←→↑↓ Перемещение курсора. Пробел Поставить/стереть точку. CTRL-← Сдвинуть изображение влево CTRL-→ Сдвинуть изображение вправо PAGEUP Сдвинуть изображение вверх PAGEDOWN Сдвинуть изображение вниз F1 Справочная информация F2 Просмотр стандартного задачника F3 Инвертирование изображения F4 Затенение изображения F5 Инвертирующий шум CTRL-F5 Изменить уровень инвертирующего шума F6 Добавляющий шум CTRL-F6 Изменить уровень добавляющего шума F7 Гасящий шум CTRL-F7 Изменить уровень гасящего шума DELETE Очистить изображение В Ввести новый вес примера П Повернуть изображение на 90 градусов по часовой стрелке О Отразить изображение относительно вертикальной оси ALT-C Записать текущее изображение в карман ALT-P Заменить текущее изображение хранящимся в кармане.Просмотр стандартного задачника
Просмотр стандартного задачника осуществляется с помощью клавиш «Вправо» и «Влево». Для введения текущего изображения в обучающее множество необходимо нажать ENTER, после чего программа перейдет обратно в режим редактирования задачи. Если Вы хотите отказаться от ввода задачи из стандартного задачника — нажмите ESC.
Вес примера
Вес примера является задаваемой Вами величиной, влияющей на вклад данного примера в изменение синаптической карты при обучении. Чем больше вес примера (вес не может превышать 1 и быть меньше 0), тем весомее вклад данного примера в синаптическую карту и наоборот.
Оценка примера
Программа Hopfield.
В данной программе оценка примера выполняет чисто информационные функции и равна числу несовпадающих точек в исходном изображении и ответе.
Все программы, кроме программы Hopfield.
В данной программе оценка примера может вычисляться по одному из двух правил Метода наименьших квадратов или Расстояния до множества. Кроме того, при тестировании примеров тестовой задачи в окне «Оценка» отображается уровень уверенности сети в решении предъявленного примера. Уровень надежности вычисляется по формулам, приведенным в разделах Метод наименьших квадратов и Расстояния до множества.
Затенение изображения
При исполнении команды "Затенить изображение", при редактировании задачи или, во всех программах, кроме программы Hopfield, во время Статистического теста с тенью, необходимо затенить часть изображения. Затенение осуществляется по следующему алгоритму:
При помощи генератора случайных чисел генерируется уравнение прямой, проходящей через изображение.
Та часть изображения, которая не содержит точку с координатами (5,5) стирается.
Затенение изображения — одно из четырех предоставляемых этой программой искажений изображения. Остальные искажения описаны в разделах: Добавляющий шум, Инвертирующий шум, Гасящий шум.
Добавляющий шум
При исполнении команды "Добавляющий шум", при редактировании задачи или, во всех программах, кроме программы Hopfield, во время Статистического теста с добавляющим шумом производится наложение на изображение добавляющего шума. Алгоритм «зашумления» с заданным уровнем добавляющего шума:
Для каждой точки изображения генерируется случайное число из диапазона (0,1).
Если это число меньше либо равно заданному уровню шума, то в изображение добавляется соответствующая точка.
Добавляющий шум — одно из четырех предоставляемых этой программой искажений изображения. Остальные искажения описаны в разделах: Затенение изображения, Инвертирующий шум, Гасящий шум.
Инвертирующий шум
При исполнении команды "Инвертирующий шум", при редактировании задачи или, во всех программах, кроме программы Hopfield, во время Статистического теста с инвертирующим шумом производится наложение на изображение инвертирующего шума. Алгоритм «зашумления» с заданным уровнем Инвертирующего шума:
Для каждой точки изображения генерируется случайное число из диапазона (0,1).
Если это число меньше либо равно заданному уровню шума, то в изображении инвертируется соответствующая точка.
Инвертирующий шум — одно из четырех предоставляемых этой программой искажений изображения. Остальные искажения описаны в разделах: Затенение изображения, Добавляющий шум, Гасящий шум.
Гасящий шум
При исполнении команды "Гасящий шум", при редактировании задачи или, во всех программах, кроме программы Hopfield, во время Статистического теста с гасящим шумом производится наложение на изображение гасящего шума. Алгоритм «зашумления» с заданным уровнем Гасящего шума:
Для каждой точки изображения генерируется случайное число из диапазона (0,1).
Если это число меньше либо равно заданному уровню шума, то в изображении гасится соответствующая точка.
Гасящий шум — одно из четырех предоставляемых этой программой искажений изображения. Остальные искажения описаны в разделах: Затенение изображения, Добавляющий шум, Инвертирующий шум.
Удалить пример
Эта функция удаляет активный пример активной задачи. Если после этого примеров не остается, то заводится пустой пример. Таким образом, все задачи всегда содержат хотя бы один пример.
Первый пример
Эта функция делает активным первый пример активной задачи.
Последний пример
Эта функция делает активным последний пример активной задачи.
Удалить задачу
Эта функция удаляет все примеры активной задачи и заводит один пустой пример.
(обратно)Нейронная сеть
Программа Hopfield
Нейронная сеть в данной программе является полносвязной (каждый нейрон связан с каждым, в том числе и с самим собой), однородной (все нейроны одинаковы), стонейронной (поскольку в сетях Хопфилда каждой точке изображения соответствует свой нейрон, а в этой программе используются изображения 10*10) сетью Хопфилда. Алгоритм формирования Синаптической карты описан в разделах "Параметры" и "Обучение". Алгоритм функционирования каждого нейрона описан в разделе "Нейрон".
Все программы кроме программыHopfield
Сеть, имитируемая данной программой, является полносвязной (каждый нейрон получает на каждом шаге сигналы со всех нейронов), с выделенными связями для получения входных данных. Подробная схема нейрона приведена в разделе Нейрон. Число нейронов в сети может варьироваться от 5 до 10 (см Число нейронов в сети). Число обменов сигналами между нейронами может варьироваться от 2 до 5 (см. Число срабатываний сети).
Нейрон
Программа Hopfield.
В данной программе все нейроны сети одинаковы и очень просты. Обозначив вектор сигналов сети через a[i] (i=1,…,100), а элементы синаптической карты — синаптические веса — через X[ij], работу нейрона можно описать следующими формулами:
J[i]= Сумма по j от 1 до 100 (a[j]*X[ij])
a'[i]= 1, если J[i]>0; 0, если J[i]<0.
a'[i] — новый сигнал i-ого нейрона.
Программа Pade.
Схема рационального нейрона представлена на рисунке ниже. Он состоит из шести частей: входных синапсов (x[i,j], y[i,j]), сумматоров (N,D) и функционального преобразователя (F).
Схема действия i-го нейрона проста — в каждый момент времени со всех нейронов на него поступают сигналы. Перед сумматором каждый сигнал умножается на синаптический вес x[i,j] для сумматора N и y[i,j] для сумматора D. Индекс i показывает номер нейрона получающего, а индекс j — номер передавшего сигнал. Отметим, что в силу ограничений, принятых в данной модели нейронной сети, все синаптические веса неотрицательны. После этого сигналы поступают на сумматоры. Вычисленные сумматорами сигналы передаются на функциональный преобразователь F. В данной программе все нейроны одинаковы (во всем, кроме синаптических весов, поскольку они являются характеристиками не нейронов, а нейронной сети в целом) и преобразуют сигнал по следующему правилу: F = N / (C + D), где С — Характеристика нейрона
В программах Sinus и Sigmoid нейроны отличаются только видом функционального преобразователя. Схема нейрона представлена на рисунке ниже. Он состоит из четырех частей: входных синапсов (x[i,j]), сумматора (N) и функционального преобразователя.
Схема действия i-го нейрона проста — в каждый момент времени со всех нейронов на него поступают сигналы. Перед сумматором каждый сигнал умножается на синаптический вес x[i,j]. Индекс i показывает номер нейрона получающего, а индекс j — номер — передавшего сигнал. Отметим, что в силу ограничений, принятых в данной модели нейронной сети, все синаптические веса не могут по абсолютной величине превосходить 1. После этого сигналы поступают на сумматор. Вычисленный сумматором сигнал передается на функциональный преобразователь. В данной программе все нейроны одинаковы (во всем, кроме синаптических весов, поскольку они являются характеристиками не нейронов, а нейронной сети в целом) и преобразуют сигнал по следующему правилу:
F = Sin(Т)
(программа Sinus).
А = N / (C + |N|)
(программа Sigmoid).
где С — Характеристика нейрона
Синаптическая карта
Синаптическая карта является важнейшей частью нейронной сети. Она задает веса, с которыми передаются сигналы от одних нейронов к другим. Синаптическая карта формируется при обучении нейронной сети, Случайном изменении карты, Контрастировании, а для программ, отличных от программы Hopfield, и при Редактировании карты, Генерации новой карты.
Запомнить карту
При выполнении этой функции на экран выводится запрос "Введите имя файла для запоминания". Все файлы карт имеют расширение".MAP", которое можно не набирать при ответе на запрос.
Прочитать карту
При чтении карты на экране появляется окно выбора файла. Вы должны выбрать нужный Вам файл или отказаться от чтения.
Редактировать карту
Эта функция позволяет «увидеть» на экране синаптическую карту и изменить, в соответствии с вашими желаниями значения отдельных связей. Ниже приведен список клавиш, позволяющих Вам редактировать карту:
F1 помощь; ←→↑↓ перемещение курсора; PgUp на страницу вверх; PgDown на страницу вниз; ^← на 10 влево; ^→ на 10 вправо; HOME в начало; END в конец; ENTER редактировать; Пробел заморозить/разморозить связь (Кроме программы Hopfield); ENTER редактировать.Далее для всех программ, кроме программыHopfield.
Операция замораживания (размораживания) связи позволяет исключить (подключить ранее исключенную) эту связь из процесса обучения. Связи могут быть заморожены либо при редактировании карты, либо при контрастировании.
Опишем формат отображения синаптической карты на экран. В первом столбце идут номера входных сигналов (в случае отсутствия предобработки это единица для позиции, где есть точка и –1 — для остальных). Точки изображения нумеруются, как показано в следующей таблице:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100Кроме того, к вектору входных сигналов любого примера каждой задачи добавляется сигнал с номером 0 и значением 1). Во второй колонке находятся значения синаптических весов, на которые будут подаваться соответствующие входные сигналы. В третьей колонке стоят номера нейронов, сигналы с которых будут подаваться на синапсы, веса которых указаны в четвертой колонке.
В программе Pade, во второй колонке находятся значения синаптических весов сумматора числителя функционального элемента, на которые будут подаваться соответствующие первой колонке входные сигналы. В третьей колонке находятся значения синаптических весов сумматора знаменателя функционального элемента, на которые будут подаваться соответствующие первой колонке входные сигналы. В четвертой колонке стоят номера нейронов, сигналы с которых будут подаваться на синапсы, веса которых указаны в пятой (сумматор числителя) и шестой (сумматор знаменателя) колонках.
Сгенерировать новую карту
Выполнение этой функции приводит к замене текущей синаптической карты на случайную, с указанными Вами параметрами. Если Вы указали уровень синапсов равным L, то каждый синапс будет получен с помощью случайной величины, равномерно распределенной внутри интервала [-L,L] (для программыPade — в интервале [0,L]).
Случайное изменение карты
Выполнение этой функции приводит к изменению всех весов синаптической карты на случайную величину, равномерно распределенную в диапазоне [-L,L], где L — задается в меню Параметры, в пункте Уровень УДАРА. Для каждого синаптического веса генерируется своя случайная поправка.
Контрастирование карты
Программа Hopfield.
Эта процедура удаляет из сети «лишние» связи. Вы можете задать понятие лишних связей, задав параметры контрастирования в меню Параметры.
Все программы, кроме программы Hopfield.
Эта процедура удаляет из сети «лишние» связи, замораживает медленно обучающиеся и размораживает ранее замороженные или отконтрастированные. Вы можете задать понятие лишних, медленных и подлежащих размораживанию связей задав значения параметров контрастирования в меню Параметры. Ниже приведена схема процедуры контрастирования:
Накопление показателей чувствительности
↓
Выделение размораживаемых связей
↓
Контрастирование связей
↓
Замораживание связей
↓
Размораживание выделенных связей
Накопление показателей чувствительности для размораживания (Норма для включения) и для замораживания и контрастирования (Норма для исключения) ведется раздельно в ходе указанного Вами числа (Число циклов накопления критерия) тактов обучения сети по методу Усредненного антиградиентного спуска.
После накопления показателей чувствительности определяются связи подлежащие размораживанию — Количество размораживаемых связей с самым большим показателем чувствительности. Отметим, что связи только отмечаются, но не размораживаются.
Среди обучаемых связей выделяем Количество контрастируемых связей с самыми маленькими модернизированными показателями чувствительности. Модернизация производится по следующему алгоритму:
Для каждой неотконтрастированной связи определяем расстояние до ближайшего выделенного значения.
Умножаем показатель чувствительности этой связи на вычисленное расстояние.
Величины отобранных связей заменяем ближайшим выделенным значением и замораживаем (исключаем из обучения).
Среди незамороженных (обучаемых) связей находим Количество замораживаемых связей и замораживаем, не изменяя их величин.
Связи, включенные в список подлежащих размораживанию на втором шаге алгоритма, размораживаем, не изменяя их величин.
(обратно)Параметры
Программа Hopfield
В этом подменю, Вы можете установить параметры Метода обучения, Контрастирования и Уровень УДАРА.
Все программы, кроме программыHopfield.
В меню «Параметры» Вы можете задать следующие параметры:
Параметры сети
Число нейронов в сети
Число срабатываний сети
Характеристика нейронов
Параметры метода обучения
Использовать MParTan
Организация обучения
Вычисление направления
Способ оценивания
Уровень УДАРА
Параметры контрастирования
Норма для исключения
Норма для включения
Количество контрастируемых связей
Количество замораживаемых связей
Количество размораживаемых связей
Число циклов накопления критерия
Набор выделенных значений (1/2^n)
Методы предобработки
Чистый образ
Сдвиговый автокоррелятор
Автокоррелятор сдвиг+отражение
Автокоррелятор сдвиг+вращение
Автокоррелятор сдвиг+вращение+отражение
Параметры метода обучения
Программа Hopfield
Этот пункт позволяет Вам выбрать один из двух заложенных в программу алгоритмов построения синаптической карты по обучающему множеству. Если Вы выбрали "Классический Хопфилд", то формирование происходит так, как описано в разделе обучение. Если Вы предпочли "Проекционный Хопфилд", то производится предварительная обработка обучающего множества. Входные данные, задаваемые каждым примером, можно рассматривать как стомерный вектор. Процедура предварительной обработки состоит в ортонормировании системы векторов, задаваемых всеми примерами обучающего множества. Отметим, что при тестировании предобработка отсуствует.
Все программы, кроме программыHopfield.
В этом меню Вы можете задать следующие параметры метода обучения:
Использовать MParTan
Организация обучения
Вычисление направления
Способ оценивания
Уровень УДАРА
Использовать MParTan
Все программы, кроме программы Hopfield.
При построении метода обучения Вы пользуетесь следующей схемой:
Использовать MParTan Да или Нет
↓
Процедура спуска
↓
Организация обучения Усредненная Позадачная Задаче номер
↓
Вычисление направления Случайный спуск Градиентный спуск
↓
Метод оценивания Метод наименьших квадратов Расстояние до множества
↓
Нейронная сеть
Входными параметрами процедуры MParTan являются:
1. Начальная карта.
2. Процедура вычисления Направления спуска.
3. Локальное обучающее множество.
4. Процедура вычисления оценки.
Процедура ParTan работает по следующему алгоритму:
1. Запоминаем текущую карту и оценку текущего Обучающего множества, определяемую в соответствии с тремя более низкими уровнями схемы.
2. Используя процедуру вычисления Направления спуска, вычисляет направление спуска и производит спуск в этом направлении. Этот шаг алгоритма выполняется дважды.
3. Запоминаем текущую карту и оценку текущего Обучающего множества,
4. Делаем спуск в направлении, ведущем из первой запомненной карты во вторую.
5. Если оценка не равна 0, то повторяем всю процедуру сначала.
Процедура MParTan несколько отличается от предыдущей, но ее описание слишком сложно. Однако в ее основе лежит та же идея. Если Вы не используете MParTan, то используется следующая процедура
1. Используя процедуру вычисления Направления спуска, вычисляет направление спуска и производит спуск в этом направлении.
2. Если оценка не равна 0, то повторяем всю процедуру сначала.
Организация обучения
Все программы, кроме программы Hopfield.
При построении метода обучения Вы пользуетесь следующей схемой:
Использовать MParTan Да или Нет
↓
Процедура спуска
↓
Организация обучения Усредненная Позадачная Задаче номер
↓
Вычисление направления Случайный спуск Градиентный спуск
↓
Метод оценивания Метод наименьших квадратов Расстояние до множества
↓
Нейронная сеть
Под организацией обучения будем понимать способ порождения обучающего множества для одного шага обучения. Исторически самым первым был способ позадачного обучения. Если быть более точным — то попримерного. Процедура попримерного обучения состоит из следующих шагов:
1. Подаем на вход сети задачу.
2. Получаем ответ.
3. Вычисляем оценку.
Производим корректировку сети. (Процедура спуска)
Таким образом, локальное обучающее множество для процедур MParTan, Процедура спуска и Вычисление направления состоит только из одного примера.
Алгоритмы получения локального обучающего множества для различных способов организации обучения:
Попримерный Для каждого шага обучения новый пример. Позадачный Для первого шага обучения — все примеры первой задачи, для второго второй и т. д. Задаче номер N На всех шагах обучения локальное обучающее множество состоит из всех примеров N-ой задачи. Усредненный Локальное обучающее множество совпадает с полным, то есть включает в себя все примеры всех пяти задач обучающего множества.Вычисление направления
Все программы, кроме программы Hopfield.
При построении метода обучения Вы пользуетесь следующей схемой:
Использовать MParTan Да или Нет
↓
Процедура спуска
↓
Организация обучения Усредненная Позадачная Задаче номер
↓
Вычисление направления Случайный спуск Градиентный спуск
↓
Метод оценивания Метод наименьших квадратов Расстояние до множества
↓
Нейронная сеть
Данная программа предусматривает два способа вычисления направления спуска. Первый способ известен как Случайный поиск, а второй как метод наискорейшего спуска. В первом случае в качестве направления спуска используется случайный вектор, а во втором — вектор антиградиента функции оценки.
Уровень УДАРА
Этот пункт позволяет задать параметр Случайного изменения карты. Уровень УДАРА должен лежать в пределах от 0.001 до 1.
Процедура спуска
Все программы, кроме программы Hopfield.
При построении метода обучения Вы пользуетесь следующей схемой:
Использовать MParTan Да или Нет
↓
Процедура спуска
↓
Организация обучения Усредненная Позадачная Задаче номер
↓
Вычисление направления Случайный спуск Градиентный спуск
↓
Метод оценивания Метод наименьших квадратов Расстояние до множества
↓
Нейронная сеть
Входными параметрами процедуры спуска являются
1. Начальная карта.
2. Направление спуска.
3. Локальное обучающее множество.
4. Процедура вычисления оценки.
Алгоритм процедуры спуска:
1. Вычисляем оценку по локальному обучающему множеству (Е1).
2. Делаем пробный шаг, добавляя к начальной карте вектор направления спуска умноженный на шаг S.
3. Вычисляем оценку по локальному обучающему множеству (Е2).
4. Если Е2<E1, то увеличиваем шаг S, полагаем E1=E2 и повторяем шаги алгоритма 1–4 до тех пор, пока не станет E2>E1. Карта, которой соответствует оценка E1,и является результатом работы процедуры.
5. Если после первого выполнения шага 3 оказалось, что E2>E1, то уменьшаем шаг S, полагаем E1=E2 и повторяем шаги алгоритма 1–3 и 5 до тех пор, пока не станет E2<E1. Карта, которой соответствует оценка E1, и является результатом работы процедуры.
Метод оценивания
Все программы, кроме программыHopfield.
При построении метода обучения Вы пользуетесь следующей схемой:
Использовать MParTan Да или Нет
↓
Процедура спуска
↓
Организация обучения Усредненная Позадачная Задаче номер
↓
Вычисление направления Случайный спуск Градиентный спуск
↓
Метод оценивания Метод наименьших квадратов Расстояние до множества
↓
Нейронная сеть
В данной программе принят способ кодирования ответа номером канала: номер того из пяти ответных нейронов, который выдал на последнем такте функционирования наибольший сигнал, задает номер класса, к которому сеть отнесла предъявленный образ. Оценка, таким образом, может быть вычислена только для задачи, ответ которой известен.
Данная программа предусматривает два различных способа оценивания решения. Различие в способах оценки связано с различием требований, накладываемых на обученную сеть. Пусть пример относится к N-ой задаче. Тогда требования можно записать так:
Метод наименьших квадратов (Программа Pade)
N-ый нейрон должен выдать на выходе 1.
Остальные нейроны должны давать на выходе 0 (как можно более близкое к 0 число).
Метод наименьших квадратов (Программы Sigmoid и Sinus).
N-ый нейрон должен выдать на выходе 1 (поскольку сигнал 1 для нейрона невозможен (см. Нейрон), то число как можно более близкое к 1).
Остальные нейроны должны давать на выходе –1 (как можно более близкое к –1 число).
Расстояние до множества
В этом случае требование только одно — разница между выходным сигналом N-го нейрона и выходными сигналами остальных нейронов должна быть не меньше уровня надежности.
Таким образом, для Метода наименьших квадратов оценка примера N-ой задачи равна
H = (Сумма по I<>N от 1 до 5 (A[I]+1)^2)) + (A[N]-1)^2
и является обычным Евклидовым расстоянием от правильного ответа до ответа, выданного сетью.
Как следует из названия второго метода оценивания, вычисляемая по этому способу оценка равна расстоянию от выданного сетью ответа до множества правильных ответов. Множество правильных ответов для примера N-ой задачи задается неравенствами
A[N]-R > A[I], для всех I<>N.
Предобработка входных данных
Все программы, кроме программы Hopfield.
Входные данные задачи распознавания черно-белых изображений представляют собой последовательность 0 и 1 (есть точка — 1, нет — 0). Такие данные не всегда оптимальны для решения задачи распознавания. В связи с этим возникает задача предобработки данных. Возможны различные виды предобработки — преобразования Фурье, построение различных инвариантов и т. п. В этой программе предусмотрено несколько видов предобработки:
Чистый образ
Сдвиговый автокоррелятор
Автокоррелятор сдвиг+отражение
Автокоррелятор сдвиг+вращение
Автокоррелятор сдвиг+вращение+отражение
В результате предобработки получается не только более информативный вектор входных сигналов, но иногда и вектор меньшей размерности. Кроме того, вектор входных сигналов, полученный предобработкой типа "сдвиговый автокоррелятор" является инвариантным к сдвигу.
Чистый образ
Все программы, кроме программы Hopfield.
Это «пустая» предобработка — никакой предобработки не производится.
Сдвиговый автокоррелятор
Все программы, кроме программы Hopfield.
Основная идея этого метода предобработки — сделать вектор входных сигналов нейронной сети инвариантным к сдвигу. Другими словами, два вектора, соответствующие одному и тому же образу, расположенному в разных местах шаблона 10*10, после предобработки этим способом должны совпадать! Рассмотрим подробно метод вычисления автокоррелятора. Пусть дано изображение X. x[i,j] — точка изображения в i-ом ряду и j-ом столбце. Будем считать x[i,j]=0, если хотя бы один индекс (i или j) находится вне пределов интервала (1,10). Элемент автокоррелятора A — a[l,k] вычисляется по формуле:
a[l,k] = Сумма по i от 1 до 10 (Сумма по j от 1 до 10 < x[i,j]*x[i+l,j+k] >)
Другими словами, a[l,k] — число точек совпадающих при наложении изображения X на это же, но сдвинутое на вектор (l,k) изображение. Легко заметить, что ненулевыми могут быть только элементы автокоррелятора A с индексами –9<=l,k<=9. Однако a[l,k]=a[-l, –k] Таким образом можно рассматривать только часть коррелятора с индексами –9<=i<=9 и 0<=j<=9. Если Вы задаете размер автокоррелятора m*n, то входными сигналами для сети будут служить элементы a[i,j] при — (n-1)<=i<=(n-1), 0<=j<=m-1.
Автокоррелятор сдвиг+отражение
Все программы, кроме программы Hopfield.
Этот метод предобработки в качестве исходных данных использует сдвиговый автокоррелятор. Идея вычисления автокоррелятора сдиг+отражение (S) очень проста: Сложим значения, соответствующие симметричным точкам, и будем считать их новыми значениями. s[k,l]=a[k,l]+a[k, –l]. Очевидно, что автокоррелятор S инвариантен относительно сдвига и отражения. Кроме того, можно ограничиться только элементами с неотрицательными индексами. Если Вы задали размеры автокоррелятора m*n, то входными сигналами сети будут s[l,k] при 0<=l<=n-1, 0<=k<=m.
Автокоррелятор сдвиг+вращение
Все программы, кроме программы Hopfield.
Этот метод предобработки в качестве исходных данных использует сдвиговый автокоррелятор. Идея вычисления автокоррелятора очень проста: поворачиваем автокоррелятор A на 90 градусов относительно элемента a[0,0] и получаем элемент автокоррелятора R умножением соответствующих элементов — r[p,q]=a[p,q]*a[q, –p]. Очевидно, что автокоррелятор R инвариантен относительно сдвига и поворота на 90 градусов. Кроме того, можно ограничиться только элементами с неотрицательными индексами. Если вы задали размеры автокоррелятора m*n, то входными сигналами сети будут s[l,k] при 0<=l<=n-1, 0<=k<=m.
Автокоррелятор сдвиг+вращение+отражение
Все программы, кроме программы Hopfield.
Этот метод предобработки в качестве исходных данных использует автокоррелятор сдвиг+вращение. Идея вычисления автокоррелятора сдвиг+вращение+отражение (C) очень проста: Сложим значения, соответствующие симметричным точкам, и будем считать их новыми значениями. c[k,l]=r[k,l]+r[k, –l]. Очевидно, что автокоррелятор C инвариантен относительно сдвига, вращения и отражения. Кроме того, можно ограничиться только элементами с неотрицательными индексами. Если вы задали размеры автокоррелятора m*n, то входными сигналами сети будут с[l,k] при 0<=l<=n-1, 0<=k<=m.
Параметры нейронной сети
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам изменять структуру нейронной сети. Вы можете изменить такие важнейшие параметры сети, как
Число нейронов в сети
Число срабатываний сети
Характеристика нейронов
Число нейронов в сети
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам изменять число нейронов в сети от 5 до 10. Подробно структура сети и нейрона описана в разделах Нейронная сеть и Нейрон.
Число срабатываний сети
Все программы, кроме программы Hopfield.
Наиболее широкую известность получили нейронные сети слоистой архитектуры. В таких сетях за время решения примера сигнал только один раз попадает на нейроны каждого слоя. Имитируемая данной программой сеть является полносвязной сетью — каждый нейрон передает сигнал всем другим (в том числе и себе). Однако любую полносвязную сеть можно представить в виде слоистой сети с идентичными слоями. В рамках такого представления число срабатываний сети равно числу слоев нейронной сети, следующих за входным слоем. Число срабатываний сети может изменяться от 1 до 5.
Характеристика нейронов
Программа Sigmoid
В разделе Нейрон описана структура работы нейрона. В функциональном преобразователе нейрона, работающем по формуле F = R / (C+|R|), присутствует величина С, называемая характеристикой нейрона. Этот пункт меню позволяет Вам изменять эту величину от 0.001 до 5.
ПрограммаSinus не имеет параметра Характеристика нейрона
ПрограммаPade
В разделе Нейрон описана структура работы нейрона. В функциональном преобразователе нейрона, работающем по формуле F = N / (C+D) присутствует величина С, называемая характеристикой нейрона. Этот пункт меню позволяет Вам изменять эту величину в пределах от 0.001 до 5.
Параметры контрастирования
Программа Hopfield.
Если Вы посмотрите на синаптическую карту (воспользуйтесь клавишей <CTRL-F8> для перехода в режим Редактирования карты), то заметите, что большая часть синаптических весов мала и одинакова по величине. Процедура контрастирования (вызывается нажатием клавиш <CTRL-F6>) позволяет исключить часть связей из функционирования. Вам предлагается два способа исключения «лишних» связей:
Меньше х.ххх все синаптические веса, меньшие числа х.ххх по абсолютной величине устанавливаются равными 0. Число х.ххх должно лежать в интервале от 0 до 1. Дальше хх все синаптические веса связей с нейронами, удаленными от данного более чем на хх устанавливаются равными 0. По этому алгоритму обрабатываются последовательно все нейроны. Расстояние определяется как сумма модулей разности индексов двух нейронов (сумма расстояния по горизонтали и по вертикали). Например, расстояние между вторым нейроном пятой строки и шестым нейроном первой строки равно |2–6|+|5–1|=8. Задаваемый Вами радиус контрастирования хх должен принадлежать интервалу от 1 до 18.Все программы, кроме программы Hopfield.
Это подменю позволяет Вам определить понятие «лишних» и "медленно обучаемых" связей, а также связей подлежащих возвращению в обучаемое состояние, путем задания следующих параметров процедуры Контрастирования:
Норма для исключения
Норма для включения
Количество контрастируемых связей
Количество замораживаемых связей
Количество размораживаемых связей
Число циклов накопления критерия
Набор выделенных значений (1/2^n)
Норма для исключения
Все программы, кроме программы Hopfield.
При накоплении показателей чувствительности для исключения из обучения связей программа позволяет использовать три варианта нормы:
Показатель чувствительности связи равен максимуму модуля соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Показатель чувствительности связи равен сумме модулей соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Показатель чувствительности связи равен сумме соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Норма для включения
Все программы, кроме программы Hopfield.
При накоплении показателей чувствительности для включения в обучение связей программа позволяет использовать три варианта нормы:
Показатель чувствительности связи равен максимуму модуля соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Показатель чувствительности связи равен сумме модулей соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Показатель чувствительности связи равен сумме соответствующего элемента векторов антиградиента по всем циклам накопления критерия.
Количество контрастируемых связей
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам задать число связей, подлежащих Контрастированию.
Количество замораживаемых связей
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам задать число связей, подлежащих Замораживанию.
Количество размораживаемых связей
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам задать число связей, подлежащих Размораживанию.
Число циклов накопления критерия
Все программы, кроме программы Hopfield.
Этот пункт меню позволяет Вам задать число циклов обучения для накопления показателей чувствительности для процедуры Контрастирования.
Набор выделенных значений (1/2^n)
Все программы, кроме программы Hopfield.
Процедура контрастирования (вызывается нажатием клавиш <CTRL-F6>) позволяет Вам исключить часть связей из функционирования, а остальные связи привести к небольшому числу выделенных значений. Этот пункт позволяет Вам задать набор выделенных значений. Ниже приведена таблица соответствия набора выделенных значений задаваемому Вами параметру:
Программа Pade
Параметр Значения 0 0. 1 0, 1. 2 0, ½, 1. 3 0, ¼, 2/4, ¾, 1. 4 0, ⅛, 2/8, ⅜, …, ⅞, 1. 5 0, 1/16, 2/16, …, 15/16, 1. 6 0, 1/32, 2/32, …, 31/32, 1. 7 0, 1/64, 2/64, …, 63/64, 1. 8 0, 1/128, 2/128, …, 127/128, 1.Программы Sinus и Sigmoid
Параметр Значения 0 0. 1 0, ±1. 2 0, ±½, ±1. 3 0, ±¼, ±2/4, ±¾, ±1. 4 0, ±⅛, ±2/8, ±⅜, …, ±⅞, ±1. 5 0, ±1/16, ±2/16, …, ±15/16, ±1. 6 0, ±1/32, ±2/32, …, ±31/32, ±1. 7 0, ±1/64, ±2/64, …, ±63/64, ±1. 8 0, ±1/128, ±2/128, …, ±127/128, ±1.Показать все параметры
Все программы, кроме программыHopfield.
Этот пункт меню позволяет Вам увидеть на экране все параметры, задаваемые в меню "Параметры":
Параметры сети
Число нейронов в сети
Число срабатываний сети
Характеристика нейронов
Параметры метода обучения
Использовать MParTan
Организация обучения
Вычисление направления
Способ оценивания
Уровень УДАРА
Параметры контрастирования
Норма для исключения
Норма для включения
Количество контрастируемых связей
Количество замораживаемых связей
Количество размораживаемых связей
Число циклов накопления критерия
Набор выделенных значений (1/2^n)
Методы предобработки
Чистый образ
Сдвиговый автокоррелятор
Автокоррелятор сдвиг+отражение
Автокоррелятор сдвиг+вращение
Автокоррелятор сдвиг+вращение+отражение
Кроме того, на экран выводится число тактов функционирования сети уже затраченных на обучение и средняя оценка по обучающему множеству.
(обратно)Обучение
Программа Hopfield.
При вычислении синаптической карты в данной программе предусмотрено использование одного из двух заложенных алгоритмов. Выбор алгоритма производится в подменю "Параметры" главного меню. Там же описана процедура предварительной обработки обучающего множества в случае применения алгоритма "Проекционный Хопфилд". В этом разделе описана общая для обоих алгоритмов процедура вычисления элемента синаптической карты по векторам обучающего множества. Поскольку мы имеем дело со стонейронной нейронной сетью, исходные данные любого примера можно представить в виде стомерного вектора. Обозначим вектора соответствующие обучающему множеству через A[1],…,A[k], вес l-ого примера — W[l], а ij-ый элемент синаптической карты — X[ij]. Тогда алгоритм вычисления синаптической карты можно представить в виде формулы:
X[ij] = Сумма по l от 1 до k (A[l][i]*A[l][j]*W[l])
Все программы, кроме программыHopfield.
В данной программе реализован «генетический» подход к формированию стратегии обучения. У Вас в руках ряд процедур, с помощью которых Вы можете подобрать стратегию обучения сети. Ниже приведена таблица всех возможных режимов
№ Использовать MParTan Организация обучения Вычисление направления Способ оценивания Допустимость 1 Да Средн. Антиградиент МНК Допустим 2 Да Средн. Антиградиент РДМ Допустим 3 Да Средн. Случайное МНК Допустим 4 Да Средн. Случайное РДМ Допустим 5 Да Позад. Антиградиент МНК Недопустим 6 Да Позад. Антиградиент РДМ Недопустим 7 Да Позад. Случайное МНК Недопустим 8 Да Позад. Случайное РДМ Недопустим 9 Да Зад. N Антиградиент МНК Допустим 10 Да Зад. N Антиградиент РДМ Допустим 11 Да Зад. N Случайное МНК Допустим 12 Нет Зад. N Случайное РДМ Допустим 13 Нет Средн. Антиградиент МНК Допустим 14 Нет Средн. Антиградиент РДМ Допустим 15 Нет Средн. Случайное МНК Допустим 16 Нет Средн. Случайное РДМ Допустим 17 Нет Позад. Антиградиент МНК Допустим 18 Нет Позад. Антиградиент РДМ Допустим 19 Нет Позад. Случайное МНК Допустим 20 Нет Позад. Случайное РДМ Допустим 21 Нет Зад. N Антиградиент МНК Допустим 22 Нет Зад. N Антиградиент РДМ Допустим 23 Нет Зад. N Случайное МНК Допустим 24 Нет Зад. N Случайное РДМ ДопустимОбозначения, использованные в таблице:
Средн. — Обучение по усредненной оценке (градиенту);
Позад. — Позадачное обучение;
Зад. # — Обучение задаче номер;
Случайно — Случайный спуск;
Антиградиент — Градиентный спуск;
МНК — Оценка типа Метода наименьших квадратов;
РДМ — Оценка типа Расстояние до множества.
Задать процедуру обучения Вы можете в меню Параметры, в подменю метода
Тест
В режиме Тест Вы можете проверить навыки нейронной сети. Возможно несколько видов тестирования: Тест обучающего множества, при котором проверяется правильность ответов сети при предъявлении ей примеров из обучающего множества; Тест текущего тестового примера, при котором проверяется решение сетью активного примера в тестовой задаче; Тест тестовой задачи — проверка решения сетью всех примеров тестовой задачи; все программы, кроме программыHopfield — Статистический тест — проверка сети на устойчивость к искажениям.
Тест обучающего множества
Часто бывает важно знать, какие ответы дает сеть при предъявлении ей примеров из обучающего множества. Это бывает полезно при выявлении «плохих» задач и во многих других случаях. После проведения Теста обучающего множества каждому примеру из обучающего множества ставится в соответствие ответ. Результаты теста можно узнать, просмотрев обучающее множество.
Тест текущего тестового примера
При работе с обученной нейронной сетью часто бывает важно узнать ее ответ на пример, не входящий в обучающее множество. Для этой цели предназначены режимы Тест текущего тестового примера и Тест тестовой задачи. Чтобы проверить реакцию сети на интересующий Вас пример Вы должны ввести этот пример в окне «Тест» и выполнить Тест текущего тестового примера.
Тест тестовой задачи
Этот режим служит для проверки навыков обученной нейронной сети. Чтобы проверить реакцию сети на интересующие Вас примеры, Вы должны ввести их все в окне «Тест» и выполнить Тест тестовой задачи.
Тест статистический
Все программы, кроме программы Hopfield.
При работе с нейронными сетями большой интерес представляет вопрос об устойчивости полученных навыков к различным искажениям. Для исследования этого вопроса и предназначен статистический тест обучающего множества. В режиме статистического теста Вы можете
Убрать меню с экрана
Провести Полный статистический тест
Провести Статистический тест с тенью
Провести Статистический тест с добавляющим шумом
Провести Статистический тест с инвертирующим шумом
Провести Статистический тест с гасящим шумом
Задать параметры теста
Сохранить результаты на диске
Прочитать с диска результаты работы
Очистить таблицу тестов
Закончить работу со статистическим тестом
Убрать меню с экрана
Все программы, кроме программы Hopfield.
Этот пункт позволяет «спрятать» меню, закрывающее часть полезной информации на Экране статистического теста. Чтобы вернуть меню на экран необходимо нажать любую клавишу.
Экран статистического теста
Все программы, кроме программы Hopfield.
В первой строке экрана отображается название тестируемого обучающего множества, во второй строке — имя тестируемой карты, в третьей — число предъявлений на один пример (см. Задать параметры теста). Ниже расположены таблицы результатов четырех тестов: Статистического теста с тенью, Статистического теста с добавляющим шумом, Статистического теста с инвертирующим шумом, Статистического теста с гасящим шумом. Результаты представлены в виде двух строк заголовка и таблицы. Первая строка заголовка содержит имя теста. Для тестов с шумами во второй строке дан уровень шума (см. Затенение изображения, Инвертирующий шум, Добавляющий шум, Гасящий шум). Ниже приведена расшифровка данных таблицы.
Статистический тест с добавляющим шумом (1) Уровень добавляющего шума — 0.200(2) 1(3) 2 3 4 5 1(4) (5)16 0 0 4 0 2 0 12 0(6) 8 >0 3 0 0 20 0 0 4 0 0 0 20 0 5 0 0 0 0 0Цифрами в круглых скобках обозначены следующие объекты:
(1) Имя теста.
(2) Параметр теста (уровень шума).
(3) Номер класса ответа (за что приняли)
(4) Номер тестируемой задачи (что предъявляли)
(5) Число предъявлений 1-ой задачи, которые были распознаны как 1-ый образ
(6) Число предъявлений 2-ой задачи, которые были распознаны как 4-ый образ
Полный статистический тест
Все программы, кроме программы Hopfield.
Проведение полного статистического теста включает в себя проведение последовательно четырех тестов: Статистического теста с тенью, Статистического теста с добавляющим шумом, Статистического теста с инвертирующим шумом, Статистического теста с гасящим шумом. Причем параметры тестов задаются при помощи пункта Задать параметры теста. Вся полученная в ходе тестирования информация отображается в соответствующих полях Экрана статистического теста
Статистический тест с тенью
Все программы, кроме программы Hopfield.
При выполнении этого теста каждый пример обучающего множества искажается при помощи затенения изображения и предъявляется нейронной сети для распознавания. С каждым примером эта процедура проделывается заданное (см. Задать параметры теста) число раз. Результаты теста отображаются в таблице результатов. Если Вас интересует, какое число ошибок было сделано при предъявлении каждого примера обучающего множества, то Вам необходимо выйти из режима тестирования и просмотреть обучающее множество. В поле «Оценка» отображается доля правильных ответов на каждый пример. Необходимо помнить, что эти данные отражают результаты только ПОСЛЕДНЕГО теста!
Статистический тест с добавляющим шумом
Все программы, кроме программы Hopfield.
При выполнении этого теста каждый пример обучающего множества искажается при помощи Добавляющего шума с уровнем, заданным при помощи пункта Задать параметры теста, и предъявляется нейронной сети для распознавания. С каждым примером эта процедура проделывается заданное (см. Задать параметры теста) число раз. Результаты теста отображаются в таблице результатов. Если Вас интересует, какое число ошибок было сделано при предъявлении каждого примера обучающего множества, то Вам необходимо выйти из режима тестирования и просмотреть обучающее множество. В поле «Оценка» отображается доля правильных ответов на каждый пример. Необходимо помнить, что эти данные отражают результаты только ПОСЛЕДНЕГО теста!
Статистический тест с инвертирующим шумом
Все программы, кроме программы Hopfield.
При выполнении этого теста каждый пример обучающего множества искажается при помощи Инвертирующего шума с уровнем, заданным при помощи пункта Задать параметры теста, и предъявляется нейронной сети для распознавания. С каждым примером эта процедура проделывается заданное (см. Задать параметры теста) число раз. Результаты теста отображаются в таблице результатов. Если Вас интересует, какое число ошибок было сделано при предъявлении каждого примера обучающего множества, то Вам необходимо выйти из режима тестирования и просмотреть обучающее множество. В поле «Оценка» отображается доля правильных ответов на каждый пример. Необходимо помнить, что эти данные отражают результаты только ПОСЛЕДНЕГО теста!
Статистический тест с гасящим шумом
Все программы, кроме программы Hopfield.
При выполнении этого теста каждый пример обучающего множества искажается при помощи Гасящего шума с уровнем, заданным при помощи пункта Задать параметры теста, и предъявляется нейронной сети для распознавания. С каждым примером эта процедура проделывается заданное (см. Задать параметры теста) число раз. Результаты теста отображаются в таблице результатов. Если Вас интересует, какое число ошибок было сделано при предъявлении каждого примера обучающего множества, то Вам необходимо выйти из режима тестирования и просмотреть обучающее множество. В поле «Оценка» отображается доля правильных ответов на каждый пример. Необходимо помнить, что эти данные отражают результаты только ПОСЛЕДНЕГО теста!
Задать параметры теста
Все программы, кроме программы Hopfield.
При исполнении этого пункта у Вас последовательно запрашиваются "Число искажений на пример" — сколько различных экземпляров искажений каждого примера будет предъявляться сети для распознавания; "Уровень добавляющего шума" — для Статистического теста с добавляющим шумом (см. Добавляющий шум); "Уровень инвертирующего шума" — для Статистического теста с инвертирующим шумом (см. Инвертирующий шум); "Уровень гасящего шума" — для Статистического теста с гасящим шумом (см. Гасящий шум).
Сохранить результаты на диске
Все программы, кроме программы Hopfield.
Этот пункт позволяет сохранить на диске точную копию Экрана статистического теста. Отметим, что информация о доле правильных ответов на каждый пример, отображаемая в поле «Оценка» обучающего множества НЕ СОХРАНЯЕТСЯ!
Прочитать с диска результаты работы
Все программы, кроме программы Hopfield.
При выполнении этого пункта с диска считывается сохраненная при помощи пункта Сохранить результаты на диске тестовая информация. Отметим, что информация о доле правильных ответов на каждый пример, отображаемая в поле «Оценка» обучающего множества НЕ СОХРАНЯЕТСЯ на диске, и при чтении НЕ ВОССТАНАВЛИВАЕТСЯ!
Очистить таблицу тестов
Все программы, кроме программы Hopfield.
Исполнение этого пункта приводит к потере текущей тестовой информации, и очистке полей данных тестов на Экране статистического теста. Если Вы хотите сохранить результаты теста на диске, то воспользуйтесь пунктом Сохранить результаты на диске.
Закончить работу со статистическим тестом
Все программы, кроме программы Hopfield.
Исполнение этого пункта приводит к выходу из статистического теста. При этом результаты теста сохраняются до проведения другого тестирования или выхода из программы. Если Вы хотите сохранить результаты теста на диске, то воспользуйтесь пунктом Сохранить результаты на диске.
(обратно) (обратно)Приложение 3. Стандарт нейрокомпьютера
В этом приложении описаны стандарты двух уровней. Стандарт первого уровня это стандарт на языки описания всех компонентов нейрокомпьютера, за исключением компонента исполнитель. Компонент исполнитель не имеет стандарта первого уровня в следствие своей универсальности. Стандарт второго уровня — описание запросов, выполняемых каждым компонентом. Структура приложения. В первой части приложения описаны общие для всех компонентов элементы стандарта. В каждой следующей части описывается стандарт первого или второго уровня для каждого компонента.
Общий стандарт
Этот раздел содержит описание элементов стандарта, общих для всех компонентов нейрокомпьютера.
Стандарт типов данных
При описании запросов, структур данных, стандартов компонентов нейрокомпьютера необходимо использовать набор первичных типов данных. Поскольку в разных языках программирования типы данных называются по-разному, введем единый набор обозначений для них.
Таблица 1. Типы данных для всех компонентов нейрокомпьютера
Тип Длина (байт) Значения Описание Color 2 Используется для задания цветов. Является совокупностью из 16 элементарных (битовых) флагов. См. раздел «Цвет и операции с цветами». Real 4 от ±1.5 e-45 до ±3.4 e38 Действительное число. Величина из указанного диапазона… В дальнейшем называется «действительное». RealArray 4*N Массив действительных чисел. PrealArray 4 Используется для передачи массивов между компонентами. Имеет значение адреса массива действительных чисел. Integer 2 от –32768 до 32767 Целое число из указанного диапазона. В дальнейшем называется «целое». IntegerArray 2*N Массив целых чисел. PintegerArray 4 Используется для передачи массивов между компонентами. Имеет значение адреса массива целых чисел. Long 4 от –2147483648 до 2147483647 Целое число из указанного диапазона. В дальнейшем называется «длинное целое». LongArray 4*N Массив длинных целых чисел. PlongArray 4 Используется для передачи массивов между компонентами. Имеет значение адреса массива длинных целых чисел. Logic 1 True, False Логическая величина. Далее называется «логическая». Logic 1 True, False Логическая величина. Далее называется «логическая». LogicArray N Массив логических переменных. PlogicArray 4 Используется для передачи массивов между компонентами. Имеет значение адреса массива логических переменных. FuncType 4 Адрес функции. Используется при необходимости передать функцию в качестве аргумента. Visual 4 Отображаемый элемент. Служит для адресации отображаемых элементов в интерфейсных функциях. Тип значений зависит от реализации библиотеки интерфейсных функций и не может изменяться пользователем иначе, чем через вызов интерфейсной функции. String 256 Строка символов. PString 4 Адрес строки символов. Служит для передачи строк в запросах Pointer 4 Не типизованный указатель (адрес). Этот тип совместим с любым типизованным указателям.Числовые типы данных integer, long и real предназначены для хранения различных чисел. Переменные числовых типов допускаются в языках описания всех компонентов нейрокомпьютера. При необходимости записать в один массив числовые переменные различного типа следует использовать функции приведения типов, описанные в разделе «Приведение типов»
Строка. Символьный тип данных предназначен для хранения комментариев, названий полей, имен сетей, оценок и другой текстовой информации. Все строковые переменные занимают 256 байт и могут включать в себя до 255 символов. Первый байт строки содержит длину строки. В переменных типа строка возможен доступ к любому символу как к элементу массива. При этом длина имеет индекс ноль, первый символ — 1 и т. д.
Указатель на строку. При передаче данных между компонентами сети и процедурами в пределах одного компонента удобно вместо строки передавать указатель на строку, поскольку указатель занимает всего четыре байта. Для этой цели служит тип указатель на строку.
Логический тип используется для хранения логических значений. Значение истина задается предопределенной константой true, значение ложь — false.
Массивы. В данном стандарте предусмотрены массивы четырех типов — логических, целочисленных, длинных целых и действительных переменных. Длины массивов определяются при описании, но все массивы переменных одного типа относятся к одному типу, в отличие от языков типа Паскаль. Использование функций приведения и преобразования типов позволяют получать из этих массивов структуры произвольной сложности. Элементы массивов всегда нумеруются с единицы.
Вне зависимости от типа массива нулевой элемент массива имеет тип Long и содержит длину массива в элементах. На рис. 1 приведена схема распределения памяти всех типов массивов, каждый из которых содержит шесть элементов.
Все массивы, как правило, используется только в пределах одного компонента. При передаче массивов между компонентами или между процедурами в пределах одного компонента используются указатели на массивы.
Адрес функции. Этот тип используется для передачи функции в качестве аргумента. Переменная типа functype занимает четыре байта и является адресом функции. В зависимости от реализации по этому адресу может лежать либо начало машинного кода функции, либо начало текста функции. В случае передачи текста функции первые восемь байт по переданному адресу содержат слово «function».
Отображаемый элемент. Переменные типа visual (отображаемый элемент) Служат для адресации отображаемых элементов в интерфейсных функциях. Тип значений зависит от реализации библиотеки интерфейсных функций и не может изменяться пользователем иначе, чем через вызов интерфейсной функции. Особо следует отметить, что библиотека интерфейсных функций не является частью ни одного из компонентов.
(обратно)Переменные типа цвет и операции с цветами
Использование цветов позволяет гибко разбивать множества на подмножества. В нейрокомпьютере возникает необходимость в разбиении на подмножества (раскрашивании) задачника. В этом разделе описывается стандарт работы с переменными типа цвет.
Значение переменной типа цвет (color)
Переменная типа цвет представляет собой двухбайтовое беззнаковое целое. Однако основное использование предполагает работу не как с целым числом, а как с совокупностью однобитных флагов. При записи на диск используется символьное представление двоичной записи числа с ведущими нулями и разбиением на четверки символом «.» (точка), предваряемая заглавной буквой «B» латинского алфавита, или символьное представление шестнадцатеричной записи числа с ведущими нулями, предваряемая заглавной буквой «H» латинского алфавита. В табл. 2 приведена нумерация флагов (бит) переменной типа Color, их шестнадцатеричное, десятичное и дво ичное значение. При использовании в учителе или других компонентах может возникнуть необходимость в присвоении некоторым из флагов или их комбинаций имен. На такое именование не накладывается никаких ограничений, хотя возможно будет выработан стандарт и на названия часто используемых цветов (масок, совокупностей флагов).
Таблица 2. Нумерация флагов (бит) переменной типа Color
Номер Шестнадцатиричная запись Десятичная запись Двоичная запись 0 H0001 1 B.0000.0000.0000.0001 1 H0002 2 B.0000.0000.0000.0010 2 H0004 4 B.0000.0000.0000.0100 3 H0008 8 B.0000.0000.0000.1000 4 H0010 16 B.0000.0000.0001.0000 5 H0020 32 B.0000.0000.0010.0000 6 H0040 64 B.0000.0000.0100.0000 7 H0080 128 B.0000.0000.1000.0000 8 H0100 256 B.0000.0001.0000.0000 9 H0200 512 B.0000.0010.0000.0000 10 H0400 1024 B.0000.0100.0000.0000 11 H0800 2048 B.0000.1000.0000.0000 12 H1000 4096 B.0001.0000.0000.0000 13 H2000 8192 B.0010.0000.0000.0000 14 H4000 16384 B.0100.0000.0000.0000 15 H8000 32768 B.1000.0000.0000.0000Операции с переменными типа цвет (color)
Таблица 3. Предопределенные константы операций с переменными типа Цвет (Color)
Код Обозначение Вычисляемое выражение Тип результата Пояснение 1 CEqual A=B Logic Полное совпадение. 2 CIn A And B = A Logic A содержится в В. 3 CInclude A And B = B Logic А содержит В. 4 CExclude A And B = 0 Logic A и В взаимоисключающие. 5 CIntersect A And B <> 0 Logic А и В пересекаются. 6 COr A Or B Сolor Побитное включающее или. 7 CAnd A And B Color Побитное и. 8 CXor A Xor B Color Побитное исключающее или 9 CNot Not A Color Побитное отрицаниеВ табл. 3 приведены операции с переменными типа Color. Первые пять операций могут использоваться только для сравнения переменных типа Color, а остальные четыре операции — для вычисления выражений типа Color.
В ряде запросов необходимо указать тип операции над цветом. Для передачи таких параметров используется переменная типа Integer. В качестве значений передается содержимое соответствующей ячейки столбца код табл. 3.
(обратно)Приведение и преобразование типов
Есть два пути использовать переменную одного типа как переменную другого типа. Первый путь состоит в преобразовании значения к заданному типу. Так, для преобразования целочисленной переменной к действительному типу, достаточно просто присвоить переменной действительного типа целочисленное значение. С обратным преобразованием сложнее, поскольку не ясно что делать с дробной частью. В табл. 4 приведены все типы, которые можно преобразовать присваиванием переменной другого типа. В табл. 5 приведены все функции преобразования типов.
Таблица 4. Преобразование типов прямым присваиванием переменной значения выражения
Тип переменной Тип выражения Пояснение Real Real, Integer, Long Значение преобразуется к плавающему виду. При преобразовании значения выражения типа Long возможна потеря точности. Long Integer, Long При преобразовании типа Integer, действуют следующие правила. Значение переменной помещается в два младших байта. Если значение выражения больше либо равно нолю, то старшие байты равны H0000, в противном случае старшие байты равны HFFFF. Integer Integer, Long При преобразовании выражения типа Long значение двух старших байт отбрасывается.Таблица 5. Функции преобразования типов
Имя функции Тип аргумента Тип результата Описание Real Real, Integer, Long Real Аналогично прямому присваиванию Integer Integer, Long Integer Аналогично прямому присваиванию Long Integer, Long Long Аналогично прямому присваиванию Str Real, Long, Integer String Представляет числовой аргумент в виде символьной строки в десятичном виде Round Real Long Округляет действительное значение до ближайшего длинного целого. Если значение действительного выражения выходит за диапазон длинного целого, то результат равен нулю. Truncate Real Long Преобразует действительное значение в длинное целое путем отбрасывания дробной части. Если значение действительного выражения выходит за диапазон длинного целого, то результат равен нулю. LVal String Long Преобразует длинное целое из символьного представления во внутреннее. RVal String Real Преобразует действительное число из символьного представления во внутреннее. StrColor Color String Преобразует внутреннее представление переменной типа Color в соответствии с разд. «Значение переменной типа цвет» ValColor String Color Преобразует символьное представление переменной типа Color во внутреннее. Color Integer Color Интерпретирует целое число как значение типа Color.При вычислении числовых выражений действуют следующие правила преобразования типов:
1. Выражения вычисляются слева на право.
2. Если два операнда имеют один тип, то результат имеет тот же тип.
3. Если аргументы имеют разные типы, то выражение имеет старший из двух типов. Список числовых типов по убыванию старшинства: Real, Long, Integer.
4. Результат операции деления действительных чисел (операция «/») всегда имеет тип Real, вне зависимости от типов аргументов.
В отличие от преобразования типов приведение типов позволяет по-разному интерпретировать одну область памяти. Функция приведения типа применима только к переменным или элементам массива (преобразование типов применимо и к выражениям). Рекомендуется использовать приведение типов только для типов, имеющих одинаковую длину. Например, Integer и Color или Real и Long. Список функций приведения типов приведен в табл. 6.
Таблица 6. Функции приведения типов
Название Тип результата Описание Treal Real Четыре байта, адресуемые приводимой переменной, интерпретируются как действительное число. Tinteger Integer Два байта, адресуемые приводимой переменной, интерпретируются как целое число. Tlong Long Четыре байта, адресуемые приводимой переменной, интерпретируются как длинное целое. TrealArray RealArray Область памяти, адресуемая приводимой переменной, интерпретируются как массив действительных чисел. TPRealArray PRealArray Четыре байта, адресуемые приводимой переменной, интерпретируются как указатель на массив действительных чисел. TintegerArray IntegerArray Область памяти, адресуемая приводимой переменной, интерпретируются как массив целых чисел. TPIntegerArray PIntegerArray Четыре байта, адресуемые приводимой переменной, интерпретируются как указатель на массив целых чисел. TlongArray LongArray Область памяти, адресуемая приводимой переменной, интерпретируются как массив длинных целых. TPLongArray PLongArray Четыре байта, адресуемые приводимой переменной, интерпретируются как указатель на массив длинных целых. Tlogic Logic Адресуемый приводимой переменной байт интерпретируются как логическая переменная. TlogicArray LogicArray Область памяти, адресуемая приводимой переменной, интерпретируются как массив логических переменных. TPLogicArray LogicArray Четыре байта, адресуемые приводимой переменной, интерпретируются как указатель на массив логических переменных. TColor Color Два байта, адресуемые приводимой переменной, интерпретируются как переменная типа цвет. TFuncType FuncType Четыре байта, адресуемые приводимой переменной, интерпретируются как адрес функции. TPointer Pointer Четыре байта, адресуемые приводимой переменной, интерпретируются как адрес. Tstring String 256 байт области памяти, адресуемой приводимой переменной, интерпретируются как строка символов. TPString PString Четыре байта, адресуемые приводимой переменной, интерпретируются как указатель на строку символов. Tvisual Visual Четыре байта, адресуемые приводимой переменной, интерпретируются как отображаемый элемент.Следующие примеры иллюстрируют использование преобразования и приведения типов:
При вычислении следующих четырех выражений, получаются различные результаты
4096 * 4096 = 0
Поскольку константа 4096 имеет тип Integer, а 4096 * 4096 = 16777216 = 256 * 65536, то есть младшие два байта результата равны нулю.
Long(4096 * 4096) = 0
Поскольку оба сомножителя имеет тип Integer, то и выражение имеет тип Integer. Следовательно, результат умножения равен нулю, который затем преобразуется к типу Long.
Long(4096) * 4096 = 16777216
Поскольку первый сомножитель имеет тип длинное целое, то и выражение имеет тип длинное целое.
4096.0 * 4096 = 1.677722E+7
Поскольку первый сомножитель имеет тип Real, то и выражение имеет тип Real. Из-за недостатка точности произошла потеря точности в седьмом знаке.
В следующем примере, используя приведение типов, в массив действительных чисел A размером в 66 элементов складываются: действительное число в первый элемент массива; длинное целое во второй элемент массива и символьную строку в элементы с 3 по 66.
A[1] = 1.677722E+7
TLong(A[2]) = 16777216
TString(A[3]) = ‘Пример приведения типов’
Необходимо отметить, что элементы массива A, начиная со второго, после выполнения приведенного выше фрагмента программы не рекомендуется использовать как действительные числа, поскольку элемент A[2] содержит значение 2.350988Е-38, а элемент A[5] — значение –4.577438Е-18. Значение элементов, начиная с A[8] (символьная строка ‘Пример приведения типов’ содержит 23 символа и занимает 24 байта, то есть шесть элементов массива) вообще не зависят от приведенного фрагмента программы и содержат «мусор», который там находился ранее.
В списке типов определены только одномерные массивы. Однако, при необходимости, возможно использование двумерных массивов. Для этого в одномерный массив A необходимо поместить указатели на одномерные массивы. При этом I,J-й элемент двумерного массива записывается в виде:
TPRealArray(A[I])^[J]
В этом примере использована функция приведения типов TPRealArray, указывающая, что I-й элемент массива A нужно интерпретировать как указатель на одномерный массив действительных чисел, и операция «^» указывающая, что вместо указателя на массив TPRealArray(A[I]) используется массив, на который он указывает.
Таким образом, использование функций приведения типов позволяет из одномерных массивов строить структуры произвольной сложности. В языках программирования, таких как C и Паскаль, существует возможность строить пользовательские типы данных. При разработке стандарта эти возможности были исключены, поскольку использование пользовательских типов, облегчая написание программ, сильно затрудняет разработку компилятора или интерпретатора, а при использовании этого языка для описания компонентов нейрокомпьютера необходимость в пользовательских типах данных возникает чрезвычайно редко. Например, при описании примеров всех компонентов, приведенных в данной работе, такая необходимость ни разу не возникла.
(обратно)Операции
В данном разделе приведены все операции, которые могут быть использованы при построении выражений различного типа. В табл. 7 приведены операции, которые допустимы в целочисленных выражениях (выражениях типа Integer или Long). В табл. 8 — список, дополняющий список операций из табл. 7 до полного списка операций, допустимых в выражениях действительного типа. В табл. 9 — операции, допустимые при построении логических выражений. В табл. 10 — для выражений типа символьная строка. В табл. 3 — для выражений типа Color. Если операндом может быть любой числовой тип, то вместо перечисления всех числовых типов (Integer, Real, Long) указывается слово «числовой»
Таблица 7. Операции, допустимые в целочисленных выражениях
Приоритет Обозначение Тип 1-го операнда Тип 2-го операнда Тип результата Название операции 1 * Integer Integer Integer Умножение 1 * Long Integer Long Умножение 1 * Integer Long Long Умножение 1 * Long Long Long Умножение 1 Div Integer Integer Integer Целочисленное деление 1 Div Integer Long Long Целочисленное деление 1 Div Long Integer Long Целочисленное деление 1 Div Long Long Long Целочисленное деление 1 Mod Integer Integer Integer Остаток от деления 1 Mod Long Integer Long Остаток от деления 1 Mod Integer Long Long Остаток от деления 1 Mod Long Long Long Остаток от деления 2 + Integer Integer Integer Сложение 2 + Integer Long Long Сложение 2 + Long Integer Long Сложение 2 + Long Long Long Сложение 2 – Integer Integer Integer Вычитание 2 – Integer Long Long Вычитание 2 – Long Integer Long Вычитание 2 – Integer Long Long Вычитание 2 – Long Integer Long Вычитание 2 – Long Long Long Вычитание 3 And Integer Integer Integer Побитное И 3 And Long Long Long Побитное И 3 Or Integer Integer Integer Побитное включающее ИЛИ 3 Or Long Long Long Побитное включающее ИЛИ 3 Xor Integer Integer Integer Побитное исключающее ИЛИ 3 Xor Long Long Long Побитное исключающее ИЛИ 3 Not Integer Integer Integer Побитное отрицание 3 Not Long Long Long Побитное отрицаниеТаблица 8. Операции, дополняющие список операций из табл. 7 до полного списка операций, допустимых в выражениях действительного типа.
Приоритет Обозначение Тип 1-го операнда Тип 2-го операнда Тип результата Название операции 1 * Real числовой Real Умножение 1 / числовой числовой Real Деление 1 RMod числовой числовой Real Остаток от деления 2 + Real числовой Real Сложение 2 – Real числовой Real ВычитаниеТаблица 9. Операции, допустимые при построении логических выражений
Приоритет Обозначение Тип 1-го операнда Тип 2-го операнда Тип результата Название операции 1 > числовой числовой Logic Больше 1 < числовой числовой Logic Меньше 1 >= числовой числовой Logic Больше или равно 1 <= числовой числовой Logic Меньше или равно 1 = числовой числовой Logic Равно 1 <> числовой числовой Logic Не равно 2 And Logic Logic Logic Логическое И 2 Or Logic Logic Logic Логическое включающее ИЛИ 2 Xor Logic Logic Logic Логическое исключающее ИЛИ 2 Not Logic Logic Logic Логическое отрицаниеТаблица 10. Операции для выражений типа символьная строка
Приоритет Обозначение Тип 1-го операнда Тип 2-го операнда Тип результата Название операции 1 + String String String Конкатенация (сцепка) строк.Во всех таблицах операции размещаются по убыванию приоритета. Для каждой операции указаны допустимые типы операндов, и тип результата, в зависимости от типов операндов.
В табл. 8 приводится необычная операция RMod — остаток от деления действительных чисел. Результат этой функции равен разности между первым операндом и вторым операндом, умноженным на целую часть отношения первого операнда ко второму.
Кроме операций, приведенных в табл. 3 и табл. 7–10, определены две взаимно обратные операции для работы с адресами и указателями:
^ — ставится после переменной типа указатель. Означает, что вместо указателя в выражении используется переменная или массив, на который указывает этот указатель. Не допускается после переменных типа Pointer.
@ — ставится перед именем переменной любого типа. Означает, что в выражении участвует не переменная, а адрес переменной. Используется при присвоении адресов переменных или массивов переменным типа указатель.
Предопределенные константы
При описании различных компонентов возникает необходимость в использовании некоторого набора стандартизированных констант. Стандартность набора констант особенно необходима при обмене между компонентами. Все константы, приведенные в табл. 11, описываются в тех разделах, где они используются. В табл. 11 для каждой константы указывается ее тип, значение и названия разделов, в которых она описывается.
Таблица 11. Предопределенные константы
Идентификатор Тип Значение Раздел Шестнад. Десят. BackInSignals Integer H0005 5 Запросы к компоненту сеть BackOutSignals Integer H0006 6 Запросы к компоненту сеть BackРarameters Integer H0007 7 Запросы к компоненту сеть Binary Integer H0001 1 Запросы компонента интерпретатор ответа BinaryPrep Integer H0000 0 Запросы компонента предобработчик BynaryCoded Integer H0003 3 Запросы компонента интерпретатор ответа CAnd Integer H0007 7 Операции с переменными типа цвет (Color) Cascad Integer H0002 2 Запросы к компоненту сеть CEqual Integer H0001 1 Операции с переменными типа цвет (Color) CExclude Integer H0004 4 Операции с переменными типа цвет (Color) CicleFor Integer H0003 3 Запросы к компоненту сеть CicleUntil Integer H0004 4 Запросы к компоненту сеть CIn Integer H0002 2 Операции с переменными типа цвет (Color) CInclude Integer H0003 3 Операции с переменными типа цвет (Color) CIntersect Integer H0005 5 Операции с переменными типа цвет (Color) CNot Integer H0009 9 Операции с переменными типа цвет (Color) COr Integer H0006 6 Операции с переменными типа цвет (Color) CXor Integer H0008 8 Операции с переменными типа цвет (Color) Element Integer H0000 0 Запросы к компоненту сеть Empty Integer H0000 0 Запросы компонента интерпретатор ответа EmptyPrep Integer H0003 3 Запросы компонента предобработчик False Logic H00 FuncPrep Integer H0005 5 Запросы компонента предобработчик InSignalMask Integer H0003 3 Запросы к компоненту сеть InSignals Integer H0000 0 Запросы к компоненту сеть Layer Integer H0001 1 Запросы к компоненту сеть MainVisual Visible Интерфейсные функции Major Integer H0002 2 Запросы компонента интерпретатор ответа mIntegerArray Integer H0002 2 Функции управления памятью mLogicArray Integer H0001 1 Функции управления памятью mLongArray Integer H0004 4 Функции управления памятью ModPrep Integer H0004 4 Запросы компонента предобработчик mRealArray Integer H0004 4 Функции управления памятью Null Pointer H00000000 нет Ordered Integer H0002 2 Запросы компонента предобработчик OutSignals Integer H0001 1 Запросы к компоненту сеть Parameters Integer H0002 2 Запросы к компоненту сеть ParamMask Integer H0004 4 Запросы к компоненту сеть PositPrep Integer H0006 6 Запросы компонента предобработчик tbAnswers Integer H0004 4 Язык описания задачника tbCalcAnswers Integer H0006 6 Язык описания задачника tbCalcReliability Integer H0007 7 Язык описания задачника tbColor Integer H0001 1 Язык описания задачника tbComment Integer H000A 10 Язык описания задачника tbEstimation Integer H0009 9 Язык описания задачника tbInput Integer H0002 2 Язык описания задачника tbPrepared Integer H0003 3 Язык описания задачника tbReliability Integer H000 5 Язык описания задачника tbWeight Integer H0008 8 Язык описания задачника True Logic HFF 255 (-1) UnknownLong Integer H0000 0 Неопределенные значения UnknownReal Real нет 1E-40 Неопределенные значения UnOrdered Integer H0001 1 Запросы компонента предобработчик UserType Integer HFFFF –1 Структурная единица, определенная пользователем.Три предопределенные константы, приведенные в табл.11, не описываются ни в одном разделе данной работы. Это константы общего пользования. Их значение:
True — значение истина для присваивания переменным логического типа.
False — значение ложь для присваивания переменным логического типа.
Null — пустой указатель. Используется для сравнения или присваивания переменным всех типов указателей.
Интерфейсные функции
Часто при обучении и тестировании нейронных сетей возникает необходимость отображать на экран некоторую информацию. Например, число предъявлений примеров сети, максимальную оценку и т. п. Вряд ли разумно использовать язык описания компонентов нейрокомпьютера для описания интерфейса. Это противоречит требованию переносимости текста описания компонентов между разными платформами и операционными системами. Для облегчения создания интерфейса, с одной стороны, и обеспечения универсальности описания компонентов нейрокомпьютера, с другой, предложен набор интерфейсных функций. Поддержку этих функций несложно организовать в любой операционной среде и на любой платформе.
В основу набора интерфейсных функций положен принцип объектно-ориентированной машины потока событий. Примером таких систем может служить инструментальная библиотека объектов (классов) Turbo Vision фирмы Борланд, или оконный интерфейс Windows фирмы Майкрософт. Предлагаемый в данном разделе набор интерфейсных функций беднее любой из выше названных интерфейсных библиотек, но позволяет организовать достаточно красивый и удобный интерфейс.
Структура данных интерфейсных функций
Элементом данных в структуре интерфейса является отображаемый элемент. Каждый отображаемый элемент имеет свои координаты относительно начала владельца — отображаемого элемента, содержащего данный. Владельцем отображаемого элемента может являться одно из окон или диалогов или главный элемент. Главный отображаемый элемент является предопределенным и обозначается переменной MainVisual. В программах компонентов нейрокомпьютера не допускается изменение значения переменной MainVisual. Эту переменную стоит рассматривать как константу, однако, в отличие от всех остальных констант ее значение определяется не данным стандартом, а разработчиком библиотеки интерфейсных функций.
В данной работе не рассматривается способ реализации интерфейсных функций и не обсуждаются значения переменных типа Visible. По этому ставится единственное условие — переменные типа Visible могут изменять свои значения только при вызове интерфейсных функций или при присваивании им значений другой переменной того же типа.
Все отображаемые элементы создаются интерфейсными функциями, называющимися, так же как и сам отображаемый элемент. Интерфейсные функции создающие отображаемые элементы возвращают значения типа Visible. Если при вызове создающей отображаемый элемент функции элемент не был создан, то функция возвращает значение Null.
Соглашение о передаче значений отображаемым элементам
Отображаемые элементы могут быть связаны с обычными переменными. В следующих разделах описаны отображаемые элементы, для которых должна быть установлена такая связь. При изменении значения связанной переменной программным путем для отображения этого изменения должна быть вызвана функция Refresh, с переменной типа Visible данного элемента в качестве параметра. При связывании переменной и отображаемого элемента необходимо совпадение типа переменной с связываемым переменной этого отображаемого элемента.
Перечень отображаемых элементов
Название элемента: Window (окно).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла окна относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры окна.
ScrollX, ScrollY — Целочисленные параметры, задающие наличие у окна горизонтальной и вертикальной полосы прокрутки. Если значение параметра равно нулю, то соответствующая полоса прокрутки отсутствует, при любом другом значении параметра в окно включается соответствующая полоса прокрутки.
Text — Название окна.
Описание элемента. Элемент Window может являться владельцем любых других отображаемых элементов, кроме элементов типа Dialog. При вызове функции Refresh, с элементом типа Window в качестве параметра, обновляется изображение не только самого окна, но и всех отображаемых элементов, для которых это окно является владельцем. Для отображения созданного окна на экране необходимо вставить его (вызвать функцию Insert, с данным окном в качестве второго параметра.) в отображенное на экран окно, диалог или в отображаемый элемент MainVisible. Для того чтобы убрать окно с экрана, необходимо вызвать функцию Delete, с данным окном в качестве параметра. Для уничтожения окна необходимо вызвать функцию Erase, с данным окном в качестве параметра. При этом уничтожаются так же и все отображаемые элементы, для которых данное окно являлось владельцем.
Название элемента: Dialog (Диалог).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла окна диалога относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры окна диалога.
ScrollX, ScrollY — Целочисленные параметры, задающие наличие у окна диалога горизонтальной и вертикальной полосы прокрутки. Если значение параметра равно нулю, то соответствующая полоса прокрутки отсутствует, при любом другом значении параметра в окно диалога включается соответствующая полоса прокрутки.
Text — Название окна диалога.
Описание элемента. Элемент Dialog может являться владельцем любых других отображаемых элементов. Этот элемент является модальным, то есть во время работы диалога невозможен вызов меню, переход в другие окна и диалоги и т.д. Если одновременно активно несколько диалогов, то модальным является последний по порядку отображения на экране. При закрытии текущего диалога модальность переходит к предыдущему и т.д. При вызове функции Refresh, с элементом типа Dialog в качестве параметра, обновляется изображение не только самого окна диалога, но и всех отображаемых элементов, для которых этот диалог является владельцем. Для отображения созданного диалога на экране необходимо вставить его (вызвать функцию Insert, с данным диалогом в качестве второго параметра.) в отображаемый элемент MainVisible. С этого момента диалог становится модальным. Он остается модальным либо до вставки в MainVisible другого диалога, либо до закрытия диалога. Если модальность потеряна диалогом из-за запуска следующего диалога, то при закрытии последнего диалога статус модальности восстанавливается. Для того чтобы закрыть диалог, необходимо вызвать функцию Delete, с данным диалогом в качестве параметра. Для уничтожения диалога необходимо вызвать функцию Erase, с данным диалогом в качестве параметра. При этом уничтожаются так же и все отображаемые элементы, для которых данный диалог являлся владельцем.
Название элемента: Label (метка).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла метки относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры метки.
Text — текст метки.
Описание элемента. Элемент Label не может являться владельцем других отображаемых элементов. Этот элемент не связан с переменными. Как правило, он используется для организации отображения в окне или диалоге статической информации или в качестве подписи поля ввода. Если метка связана с полем ввода, то передача управления этой метке автоматически влечет за собой передачу управления связанному с ней полю. Для организации связи метки с полем необходимо вызвать функцию Link, передав ей в качестве первого параметра метку, а вторым параметром тот элемент, с которым необходимо установить связь. Связь может быть установлена только с одним элементом. При повторном вызове функции Link устанавливается связь с новым элементом, а связь с прежним элементом разрывается. Для включения метки в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и меткой в качестве второго параметра. Для уничтожения метки необходимо вызвать функцию Erase, с данной меткой в качестве параметра.
Название элемента: StringVisible (строковый элемент).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Size — размер поля.
Описание элемента. Элемент StringVisible не может являться владельцем других отображаемых элементов. Этот элемент должен быть связан с переменной типа String. Для установления связи используется функция Data со строковым элементом в качестве первого параметра и адресом переменной в качестве второго параметра. Как правило, строковый элемент связывают с меткой. Для организации связи метки со строковым элементом необходимо вызвать функцию Link, передав ей в качестве первого параметра метку, а вторым параметром строковый элемент. Для включения строкового элемента в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и строковым элементом в качестве второго параметра. Для уничтожения строки необходимо вызвать функцию Erase, с данным строковым элементом в качестве параметра. Параметр Size задает максимальный размер вводимой строки в символах.
Название элемента: RealVisible (LongVisible) (числовой элемент).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Min, Max — минимальное и максимальное допустимые значения.
Size — размер поля.
Описание элемента. Элементы RealVisible и LongVisible служат для ввода действительных и длинных целых чисел, соответственно. Любой такой элемент должен быть связан с переменной соответствующего типа (Real или Long) и не может являться владельцем других отображаемых элементов. Для установления связи используется функция Data с числовым элементом в качестве первого параметра и адресом переменной в качестве второго параметра. Как правило, числовой элемент связывают с меткой. Для организации связи метки с числовым элементом необходимо вызвать функцию Link, передав ей в качестве первого параметра метку, а вторым параметром числовой элемент. Для включения числового элемента в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и числовым элементом в качестве второго параметра. Для уничтожения числового элемента необходимо вызвать функцию Erase, с данным числовым элементом в качестве параметра.
Название элемента: RadioButtons (переключатели).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Описание элемента. Элемент RadioButtons служит для задания значения параметрам, которые могут принимать только несколько значений (например, два значения – истина или ложь). Процедура создания элемента RadioButtons сложнее, чем для ранее рассмотренных процедур. Кроме вызова функции RadioButtons, создающей элемент, необходимо несколько раз вызвать функцию AddItem, с элементом RadioButtons в качестве первого аргумента и подписью переключателя в качестве второго аргумента. Элемент RadioButtons должен быть связан с переменной типа Long и не может являться владельцем других отображаемых элементов. Для установления связи используется функция Data с элементом RadioButtons в качестве первого параметра и адресом переменной в качестве второго параметра. Элемент RadioButtons интерпретирует данные, содержащиеся в переменной, следующим образом: первому флагу соответствует младший бит переменной, второму следующий по старшинству и т. д. Элемент не может включать более 32 флагов. Биты с номерами большими числа флагов очищаются (заменяются нулями). Как правило, элемент RadioButtons связывают с меткой. Для организации связи метки с элементом RadioButtons необходимо вызвать функцию Link, передав ей в качестве первого параметра метку, а вторым параметром элемент RadioButtons. Для включения элемента RadioButtons в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и элементом RadioButtons в качестве второго параметра. Для уничтожения элемента RadioButtons необходимо вызвать функцию Erase, с данным элементом RadioButtons в качестве параметра.
Название элемента: CheckBoxes (группа флагов).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Описание элемента. Элемент CheckBoxes служит для задания значения параметрам, которые являются совокупностью битовых флагов. Процедура создания группы флагов аналогична созданию элемента RadioButtons. Кроме вызова функции CheckBoxes, создающей элемент, необходимо несколько раз вызвать функцию AddItem, с элементом CheckBoxes в качестве первого аргумента и названием флага в качестве второго аргумента. Элемент CheckBoxes должен быть связан с переменной типа Long и не может являться владельцем других отображаемых элементов. Для установления связи используется функция Data с элементом CheckBoxes в качестве первого параметра и адресом переменной в качестве второго параметра. Элемент CheckBoxes интерпретирует данные, содержащиеся в переменной, следующим образом: если значение переменной равно единице, то включен первый переключатель, если двум – то второй, трем – первые два и т. д. Если значение переменной меньше либо равно нулю или больше либо равно два в степени числа переключателей, то оно заменяется на единицу. Как правило, элемент CheckBoxes связывают с меткой. Для организации связи метки с элементом CheckBoxes необходимо вызвать функцию Link, передав ей в качестве первого параметра метку, а вторым параметром элемент CheckBoxes. Для включения группы флагов в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и элементом CheckBoxes в качестве второго параметра. Для уничтожения элемента CheckBoxes необходимо вызвать функцию Erase, с данным элементом CheckBoxes в качестве параметра.
Название элемента: Button(кнопка).
Параметры при создании:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Macro — Адрес функции, вызываемой при нажатии кнопки. В зависимости от реализации по этому адресу может лежать либо начало машинного кода функции, либо начало текста функции. В случае передачи текста функции первые восемь байт по переданному адресу содержат слово «Function».
Описание элемента. Кнопка служит для запуска макроса, который выполняет некоторые действия, являющиеся реакцией на нажатие кнопки. Кнопка не может быть связана с переменными и не может являться владельцем других отображаемых элементов. Для включения кнопки элемента в окно или диалог, необходимо вызвать функцию Insert, с окном или диалогом в качестве первого параметра и кнопкой в качестве второго параметра. Для уничтожения кнопки необходимо вызвать функцию Erase, с данной кнопкой в качестве параметра.
Перечень интерфейсных функций
В данном разделе дано описание всех интерфейсных функций. Приводится синтаксис описания на общем подмножестве языков описания компонентов нейрокомпьютера. Функции приведены в алфавитном порядке. Следует отметить, что, как и в языках описания всех компонентов нейрокомпьютера все аргументы передаются функциям по ссылке (передается не значение аргумента, а его адрес).
AddItem
Function AddItem(Elem: Visible; Text: String): Logic;
Описание аргументов:
Elem — Отображаемый элемент типа CheckBoxes или RadioButtons.
Text — Название переключателя или флага.
Описание функции:
Эта функция добавляет название переключателя (если первый аргумент типа RadioButtons) или флага (CheckBoxes) к списку элемента, передаваемого функции первым аргументом. Если первый элемент не является элементом типа CheckBoxes или RadioButtons, то функция возвращает значение ложь (False). В случае успешного завершения операции добавления в список функция возвращает значение истина (True). В противном случае возвращается значение ложь (False).
Button
Function Button(BeginX, BeginY, SizeX, SizeY: Long; Macro: PString): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Macro — Адрес функции, вызываемой при нажатии кнопки.
Описание функции:
Эта функция создает отображаемый элемент типа Button. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
CheckBoxes
Function CheckBoxes(BeginX, BeginY, SizeX, SizeY: Long): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Описание функции:
Эта функция создает отображаемый элемент типа CheckBoxes с пустым списком переключателей. Для добавления переключателей следует воспользоваться функцией AddItem. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
Data
Function Data(Element: Visible; Var Datum): Logic;
Описание аргументов:
Element — Отображаемый элемент, который связывается с переменной.
Datum — Адрес переменной.
Описание функции:
Эта функция связывает отображаемый элемент (Element) с перемнной Datum. Если элемент Element не допускает установления связи с переменной, то функция возвращает значение ложь (False). В противном случае она устанавливает связь между элементом и переменной и возвращает значение истина (True). Отметим, что функция не проверяет типа переменной. Если вместо адреса переменной типа длинное целое был дан адрес переменной действительного типа, то эта переменная будет интерпретироваться как длинное целое (см. разд. «Функции приведения типов»). Важно отметить, что производится приведение переменной, а не преобразование ее значения.
Delete
Function Delete(Owner, Element: Visible): Logic;
Описание аргументов:
Owner — Отображаемый элемент типа окно или диалог, из которого происходит удаление.
Element — Удаляемый элемент.
Описание функции:
Эта функция удаляет отображаемый элемент (Element) из его владельца (Owner). Если элемент Owner не является окном или диалогом, или если он не является владельцем элемента Element, то функция возвращает значение ложь (False). В противном случае она удаляет элемент из владельца и возвращает значение истина (True). Отметим, что элемент удаляется, но не уничтожается. Если нет переменной, содержащей удаляемый элемент, то элемент «потеряется», то есть он станет недоступным из программы, но будет занимать память.
Dialog
Function Dialog(BeginX, BeginY, SizeX, SizeY, ScrollX, ScrollY: Long; Text: String): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
ScrollX, ScrollY — Целочисленные параметры, задающие наличие у окна горизонтальной и вертикальной полосы прокрутки. Если значение параметра равно нулю, то соответствующая полоса прокрутки отсутствует, при любом другом значении параметра в окно включается соответствующая полоса прокрутки.
Text — Название окна.
Описание функции:
Эта функция создает отображаемый элемент типа диалог. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null. После создания диалог является пустым.
Erase
Function Erase(Element: Visible): Logic;
Описание аргументов:
Element — Уничтожаемый элемент.
Описание функции:
Эта функция уничтожает отображаемый элемент (Element). Если аргумент Element является окном или диалогом, то уничтожаются так же все отображаемые элементы, для которых элемент Element является владельцем. Если операция завершена успешно, то функция возвращает значение истина (True). В противном случае — значение ложь (False). Если выполнение функции завершилось неуспешно (функция вернула значение ложь), то элемент может быть поврежден и его дальнейшее использование не гарантирует корректной работы.
Insert
Function Insert(Owner, Element: Visible): Logic;
Описание аргументов:
Owner — Отображаемый элемент типа окно или диалог, в который производится вставка.
Element — Вставляемый элемент.
Описание функции:
Эта функция вставляет отображаемый элемент (Element) в элемент (Owner). Если элемент Owner не является окном или диалогом, или если Element является диалогом, то функция возвращает значение ложь (False). Такие же действия производятся, в случае, если аргумент Owner совпадает с MainVisible, а Element не является окном или диалогом. В противном случае она вставляет элемент в Owner и возвращает значение истина (True). Вставка окна или диалога в MainVisible вызывает отображение его на экране, а в случае, если вставляется диалог, то ему передается управление.
Label
Function Label(BeginX, BeginY, SizeX, SizeY: Long; Text: String): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Text — текст метки.
Описание функции:
Эта функция создает отображаемый элемент типа Label. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
Link
Function Link(Element, Labels: Visible): Logic;
Описание аргументов:
Owner — Отображаемый элемент, связываемый с меткой.
Element — Отображаемый элемент — метка.
Описание функции:
Эта функция устанавливает связь между меткой Labels и отображаемым элементом Element. Если элемент Labels не является меткой, то функция возвращает значение ложь (False). В противном случае она устанавливает связь и возвращает значение истина (True).
LongVisible
Function LongVisible(BeginX, BeginY, SizeX, SizeY, Min, Max, Size: Long): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Min, Max — минимальное и максимальное допустимые значения.
Size — размер поля в символах.
Описание функции:
Эта функция создает отображаемый элемент типа LongVisible для редактирования и ввода значений типа Long. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
RadioButtons
Function RadioButtons(BeginX, BeginY, SizeX, SizeY: Long): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Описание функции:
Эта функция создает отображаемый элемент типа RadioButtons с пустым списком флагов. Для добавления переключателей следует воспользоваться функцией AddItem. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
RealVisible
Function RealVisible (BeginX, BeginY, SizeX, SizeY: Long; Min, Max: Real; Size: Long): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Min, Max — минимальное и максимальное допустимые значения.
Size — размер поля в символах.
Описание функции:
Эта функция создает отображаемый элемент типа RealVisible для редактирования и ввода значений типа Real. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
Refresh
Function Refresh(Element: Visible): Logic;
Описание аргументов:
Element — Отображаемый элемент.
Описание функции:
Эта функция обновляет изображение элемента Element на экране. Если операция прошла успешно, то функция возвращает значение истина (True). В противном случае она возвращает значение ложь (False).
StringVisible
Function StringVisible (BeginX, BeginY, SizeX, SizeY, Size: Long): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
Size — размер поля в символах.
Описание функции:
Эта функция создает отображаемый элемент типа StringVisible для редактирования и ввода символьных строк. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null.
Window
Function Window(BeginX, BeginY, SizeX, SizeY, ScrollX, ScrollY: Long; Text: String): Visible;
Описание аргументов:
BeginX, BeginY — Координаты верхнего левого угла элемента относительно владельца.
SizeX, SizeY — Горизонтальный и вертикальный размеры элемента.
ScrollX, ScrollY — Целочисленные параметры, задающие наличие у окна горизонтальной и вертикальной полосы прокрутки. Если значение параметра равно нулю, то соответствующая полоса прокрутки отсутствует, при любом другом значении параметра в окно включается соответствующая полоса прокрутки.
Text — Название окна.
Описание функции:
Эта функция создает отображаемый элемент типа окно. Если создание прошло успешно, то возвращается значение этого элемента (типы значений не оговариваются стандартом, но, как правило, это адрес соответствующей структуры). Если создание элемента завершилось не удачно, то возвращается значение Null. После создания окно является пустым.
(обратно)Строковые функции
В этом разделе описан набор функций для работы со строками, которые могут использоваться в языках описания всех компонентов нейрокомпьютера.
Function SubStr(S: String; Origin, Leng: Integer): String;
Описание аргументов
S — строка, из которой выделяется фрагмент.
Origin — начальная позиция выделяемого фрагмента в строке S
Leng — длина выделяемого фрагмента.
Выделяет из строки S фрагмент, начинающийся с позиции Origin и длиной Leng символов. Если строка короче чем Origin, то результатом является пустая строка. Если строка длиннее чем Origin символов, но короче чем Origin+Leng символов, то результатом является фрагмент строки S с символа Origin и до конца строки S.
Function Pos(S1, S2: String): Integer
Описание аргументов
S1 — строка, в которой ищется вхождение строки S2.
S2 — строка, вхождение которой ищется.
Функция Pos возвращает номер первого символа в строке S1, начиная с которого, в строке S1 полностью содержится строка S2. Если строка S2 ни разу не встретилась в строке S1, то результат равен нулю.
Function Len(S: String): Integer
Описание аргументов
S — строка, длина которой вычисляется.
Функция Len возвращает длину (число символов) строки S
(обратно)Описание языка описания компонентов
В табл. 12 приведен список ключевых слов, общих для всех языков описания компонентов нейрокомпьютера. Кроме того, к ключевым словам относятся типы данных, приведенные в табл. 1; обозначения операций, приведенные в табл. 3, 7, 8, 9, 10; названия функций преобразования (табл. 5) и приведения типов (табл. 6); идентификаторы предопределенных констант, приведенные в табл. 11; имена интерфейсных функций, приведенных в разделе «Перечень интерфейсных функций»; имена элементарных функций, приведенных в табл.13; обозначения строковых функций, приведенных в разделе «Строковые функции» и обозначения функций управления памятью из раздела «Функции управления памятью».
Таблица 12. Ключевые слова, общие для всех языков описания компонент нейрокомпьютера.
Ключевое слово Краткое описание Begin Начало описания тела процедуры, или операторных скобок. By Часть оператора цикла с шагом. Предшествует шагу цикла. Do Завершающая часть операторов цикла. Else Часть условного оператора. Предшествует оператору, выполняемому, если условие ложно. End Конец описания тела процедуры или операторных скобок. For Заголовок оператора цикла с шагом. Function Заголовок описания функции. Global Начало блока описания глобальных переменных. GoTo Начало оператора перехода. If Начало условного оператора. Include Предшествует имени файла, целиком вставляемого в это место описания. Label Начало описания меток Name Предшествует имени статической переменной. SetParameters Признак раздела установления значений параметров. Static Начало блока описания статических переменных. Then Часть условного оператора. Предшествует оператору, выполняемому, если условие истинно. To Часть оператора цикла с шагом. Предшествует верхней границе цикла. Var Начало блока описания переменных. While Заголовок оператора цикла по условию.Таблица 13. Элементарные функции, допустимые в языках описания компонент нейрокомпьютера
Имя Значение Sin Синус Cos Косинус Tan Тангенс Atan Арктангенс Sh Гиперболический синус Ch Гиперболический косинус Th Гиперболический тангенс Lg Логарифм двоичный Ln Логарифм натуральный Exp Экспонента Sqrt Квадратный корень Sqr Квадрат Abs Абсолютное значение Sign Знак аргумента (0 — минус)Передача аргументов функциям
Во всех языках описания компонентов все параметры передаются по ссылке (передается не значение аргумента, а его адрес). Если в качестве фактического аргумента указано выражение, то значение выражения помещается интерпретатором (или компилятором) во временную переменную, имеющую тип, совпадающий с типом формального аргумента, а адрес временной переменной передается в качестве фактического аргумента.
Имена структурных единиц компонентов
Компоненты предобработчик, сеть, оценка и интерпретатор ответа имеют иерархическую структуру. Часть запросов может быть адресована не всему компоненту, а его структурной единице любого уровня. Для точного указания адресата запроса используется полное имя структурной единицы, которое строится по следующему правилу:
1. Имя компонента является полным именем компонента.
2. Полное имя младшей структурной единицы строится путем добавления справа к имени старшей структурной единицы точки, псевдонима младшей структурной единицы и номера экземпляра младшей структурной единицы, если младших структурных единиц с таким псевдонимом несколько.
Иногда при построении описания компонента требуется однозначное имя структурной единицы. В качестве однозначного имени можно использовать полное имя, но такой подход лишает возможности вставлять подготовленные структурные единицы в структуры более высокого уровня. Для этого вводится понятие однозначного имени структурной единицы: в описании структурной единицы A однозначным именем структурной единицы B, являющейся частью структурной единицы A, является полное имя структурной единицы B, из которого исключено полное имя структурной единицы A.
Способ описания синтаксических конструкций
Для описания синтаксиса языков описаний компонентов используется расширенная Бэкусова нормальная форма. Описание синтаксиса языка с помощью БНФ состоит в расшифровке понятий от более сложных к более простым. Каждое предложение БНФ состоит из двух частей, разделенных символами «::=» (два двоеточия, за которыми следует знак равенства). Наиболее подходящим названием для этого разделителя является слово «является» в отличие от «равно» или «присвоить» в языках программирования. Слева от разделителя находится объясняемое понятие, справа — конструкция разъясняющая это понятие. Например, предложение
<Имя переменной>::= <Идентификатор>
означает, что объясняемое понятие — <Имя переменной> является идентификатором. Заметим, что порядок предложений в БНФ описания синтаксиса языка не имеет значения. Однако традиционно сложилось так, что БНФ начинают с наиболее сложных понятий.
При описании синтаксиса языка с помощью БНФ используются следующие понятия и обозначения.
Нетерминальным символом называется понятие, которое должно быть раскрыто в пределах данной БНФ. Нетерминальным символом является произвольный набор символов, заключенный в угловые скобки, например <Имя>. Нетерминальный символ раскрыт, если в пределах БНФ встретилось предложение, в котором этот нетерминальный символ стоит в левой части.
Терминальным символом называется понятие, которое не требует раскрытия. Примерами терминальных символов являются буквы, цифры и ключевые слова описываемого языка. Терминальные символы не заключаются в угловые скобки и набраны курсивом, например Имя.
Подмножеством терминальных символов является набор ключевых слов языка. Для удобства ключевые слова набраны полужирным шрифтом, например, Имя.
В прямых квадратных скобках приводятся необязательные части синтаксических конструкций. Например предложение
<Целое число>::= [—] <Положительное целое число>
означает, что целым числом является положительное целое число (знак минус, стоящий в квадратных скобках, опущен как необязательный) или положительное целое число, перед которым стоит знак минус (знак минус, стоящий в квадратных скобках, задействован). Отметим, что квадратные скобки, набранные курсивом, являются терминальными символами.
Набор из нескольких синтаксических конструкций, разделенных символом «|» и заключенных в прямые фигурные скобки задают конструкцию выбора одной и только одной из перечисленных в фигурных скобках конструкций. Например, предложение
<Буква>::= { A | B |C | D | E | F | G | H | I | J | K |L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z }
означает, что понятие буква является одной из заглавных букв латинского алфавита. Отметим, что фигурные скобки, набранные курсивом, являются терминальными символами.
В целях сокращения описания в тех случаях, когда БНФ описание понятия сложно, а неформальное описание просто и однозначно, в БНФ описание включаются фрагменты неформального описания таких понятий.
Кроме того в данную модификацию БНФ включены нетерминальные символы с параметрами. В теле нетерминального символа параметры набраны полужирным курсивом. В качестве примера приведем набор предложений, описывающих формальные аргументы:
<Список формальных аргументов>::= <Формальный аргумент> [; <Список формальных аргументов>]
<Формальный аргумент>::= <Список имен аргументов>:<Скалярный тип>
<Список имен аргументов>::= <Имя аргумента> [,<Список имен аргументов>]
<Имя аргумента>::= <Идентификатор>
<Аргумент типа Тип> — одно из следующих понятий:
имя аргумента, который при описании формальных аргументов имел тип Тип
имя элемента аргумента-массива, если элементы массива имеют тип Тип
результат приведения произвольного аргумента или элемента аргумента-массива к типу Тип.
В этом фрагменте содержится предложение, раскрывающее понятие <Аргумент типа Тип>, являющееся нетерминальным символом с параметром. Из последнего предложения легко понять, что представляет собой понятие <Аргумент типа Тип>. Для описания этого понятия в соответствии с требованиями стандартной БНФ пришлось бы описывать отдельно следующие понятия: <Аргумент типа long>, <Аргумент типа real>, <Аргумент типа integer>, <Аргумент типа color>, <Аргумент типа logic>, <Аргумент типа string>, <Аргумент типа prealarray>, <Аргумент типа pintegerarray>, <Аргумент типа plongarray>, <Аргумент типа plogicarray>, <Аргумент типа pstring>, <Аргумент типа visual>, <Аргумент типа pointer>, <Аргумент типа functype>. Кроме того, пришлось бы отказаться от простой и понятной конструкции описания формальных аргументов. Ниже приведена часть конструкции описания формальных аргументов, которую пришлось бы включить в БНФ. В данном фрагменте приведена расшифровка только одного понятия — <Аргумент типа long>. Остальные нераскрытые понятия описываются аналогично. Понятия <Идентификатор> и <Номер элемента> считаются раскрытыми ранее.
<Список формальных аргументов>::= <Формальный аргумент> [; <Список формальных аргументов>]
<Формальный аргумент>::= {<Формальный аргумент типа Long> | <Формальный аргумент типа Real> | <Формальный аргумент типа Integer> | <Формальный аргумент типа Color> | <Формальный аргумент типа Logic> | <Формальный аргумент типа String> | <Формальный аргумент типа PRealArray> | <Формальный аргумент типа PIntegerArray> | <Формальный аргумент типа PLongArray> | <Формальный аргумент типа PLogicArray> | <Формальный аргумент типа PString> | <Формальный аргумент типа Visual> | <Формальный аргумент типа Pointer> | <Формальный аргумент типа FuncType>}
<Формальный аргумент типа Long>::= <Список имен аргументов типа Long>: Long;
<Список имен аргументов типа Long>::= <Имя аргумента типа Long> [,<Список имен аргументов типа Long>]
<Имя аргумента типа Long>::= <Идентификатор>
<Аргумент типа Long>::= {<Имя аргумента типа Long> | <Имя аргумента типа PLongArray>^[ <Номер элемента>] | TLong( <Имя произвольного аргумента>) }
<Имя произвольного аргумента>::= <Имя аргумента типа Long>, <Имя аргумента типа Real>, <Имя аргумента типа Integer>, <Имя аргумента типа Color>, <Имя аргумента типа Logic>, <Имя аргумента типа String>, <Имя аргумента типа PRealArray>, <Имя аргумента типа PIntegerArray>, <Имя аргумента типа PLongArray>, <Имя аргумента типа PLogicArray>, <Имя аргумента типа PString>, <Имя аргумента типа Visual>, <Имя аргумента типа Pointer>, <Имя аргумента типа FuncType>
Третье четвертое и пятое предложения данного фрагмента пришлось бы повторить для каждого из остальных тринадцати типов аргументов. Поскольку приведенные в книге БНФ описания языков призваны задать и объяснить синтаксис языка, а не служить исходным кодом компилятора компиляторов, автор счел возможным отступить от канонов БНФ, тем более, что для профессионала в области языков программирования не составит большого труда заменить неформальные конструкции на точные формальные фрагменты.
Описание общих синтаксических конструкций
В данном разделе приведено описание общего подмножества языков описания компонентов. В некоторых случаях, когда БНФ описание понятия сложно, а неформальное описание просто и однозначно, в БНФ описание включаются фрагменты неформального описания таких понятий.
Список синтаксических конструкций общего назначения:
<Идентификатор>::= <Буква> [<Символьная строка>]
<Буква>::= {a | b |c | d |e |f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y |z | A | B |C | D | E | F | G | H | I | J | K |L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z }
<Символьная строка>::= {<Буква> | <Цифра> | _ } [<Символьная стока>]
<Цифра>::= {0 | 1 | 2 | 3 | 4 | 5 | 6 |7 |8 |9 }
<Число>::= {<Целое число> | <Действительное число>}
<Целое число>::= [—] <Положительное целое число>
<Положительное целое число>::= <Цифра> [<Положительное целое число>]
<Действительное число>::= <Целое число>[.<Положительное целое число>][e<Целое число>]
<Целочисленная константа>::= {<Предопределенная константа типа Integer> | < Предопределенная константа типа Long> | <Целое число>}
<Цветовая константа>::= H <Шестнадцатеричная цифра> <Шестнадцатеричная цифра> <Шестнадцатеричная цифра> <Шестнадцатеричная цифра>
<Шестнадцатеричная цифра>::= {0 | 1 | 2 | 3 | 4 | 5 | 6 |7 |8 |9 | A | B |C | D | E | F }
<Строковая константа>::= “<Строка произвольных символов>”
<Логическая константа>::= {True | False}
<Строка произвольных символов> — Последовательность произвольных символов из набора ANSI. В этой последовательности допускаются символы национальных алфавитов. При необходиости включить в эту конструкцию символ кавычек, он должен быть удвоен.
<Скалярный тип>::= {Long|Real|Integer|Color|Logic|String|PRealArray|PIntegerArray|PLongArray|PLogicArray|PString|Visual|Pointer|FuncType}
<Тип массива>::= { RealArray|IntegerArray|LongArray|LogicArray}
<Константа типа Тип> — константа имеющая тип Тип.
Список синтаксических конструкций для формальных аргументов:
<Список формальных аргументов>::= <Формальный аргумент> [; <Список формальных аргументов>]
<Формальный аргумент>::= <Список имен аргументов>:<Скалярный тип>
<Список имен аргументов>::= <Имя аргумента> [,<Список имен аргументов>]
<Имя аргумента>::= <Идентификатор>
<Аргумент типа Тип> — одно из следующих понятий:
имя аргумента, который при описании формальных аргументов имел тип Тип
имя элемента аргумента-массива, если элементы массива имеют типТип
результат приведения произвольного аргумента или элемента аргумента-массива к типу Тип.
Синтаксические конструкции описания переменных:
<Описание переменных>::= Var<Список описаний однотипных переменных>
<Список описаний однотипных переменных>::= <Тип переменной> <Список переменных>; [<Список описаний однотипных переменных>]
<Список переменных>::= <Имя переменной> [, <Список переменных>]
<Имя переменной>::= <Идентификатор>
<Тип переменной>::= {<Скалярный тип> | <Тип массива>[ <Целочисленноеконстантное выражение>] }
<Переменная типа Тип> — одно из следующих понятий:
имя переменной, которая при описании переменных имела тип Тип
имя элемента массива, если элементы массива имеют типТип
результат приведения произвольной переменной или элемента массива к типу Тип.
Синтаксическая конструкция описания глобальных переменных (доступна только в языках описания компонентов учитель и контрастер):
<Описание глобальных переменных>::= Global<Список описаний однотипных переменных>
Синтаксические конструкции описания статических переменных
Статические переменные, как правило, служат для описания параметров компонентов нейрокомпьютера. Использование в именах переменных только символов латинского алфавита и цифр делает идентификаторы универсальными, но неудобными для всех пользователей, кроме англо-говорящих. Для удобства всех остальных пользователей в описании статических переменных предусмотрена возможность использовать дополнительные имена для статических переменных. Однако эти имена служат только для построения интерфейса и не могут быть использованы в описании тела соответствующего компонента. Кроме того, статической переменной можно при описании задать значение по умолчанию.
<Описание статических переменных>::= Static <Список описаний статических переменных>
<Список описаний статических переменных>::= <Описание статической переменной>; [<Список описаний статических переменных>]
<Описание статической переменной>::= <Тип переменной> <Имя переменной> [Name <Имя статической переменной>] [Default <Значение по умолчанию>]
<Имя статической переменной>::= <Строковая константа>
<Значение по умолчанию>::= <Константное выражение типа <Тип переменной>>
Синтаксические конструкции описания функций
<Описание функций>::= <Описание функции> [<Описание функций>]
<Описание функции>::= <Заголовок функции> <Описание переменных> <Описание меток> <Тело функции>
<Заголовок функции>::= Function<Имя функции>[( <Список формальных аргументов>)]: <Скалярный тип>;
<Описание меток>::= Label<Список меток>;
<Список меток>::= <Имя метки> [, <Список меток>]
<Имя метки>::= <Идентификатор>
<Тело функции>::= Begin<Составной оператор> End;
<Составной оператор>::= [<Имя метки>:] <Оператор> [; <Составной оператор>]
<Оператор>::= {<Оператор присваивания> | <Оператор ветвления> | <Оператор цикла> | <Оператор перехода> | <Операторные скобки>}
<Оператор присваивания>::= <Допустимое имя переменной> =<Выражение>
<Оператор ветвления>::= If<Логическое выражение> Then<Оператор> [Else<Оператор>]
<Оператор цикла>::= { <Цикл For> | <Цикл While> }
<Цикл For>::= For<Имя переменной> = <Целочисленное выражение> To<Целочисленное выражение> [By<Целочисленное выражение>] Do <Оператор>
<Цикл While>::= While<Логическое выражение> Do <Оператор>
<Оператор перехода>::= GoTo <Имя метки>
<Операторные скобки>::= Begin<Составной оператор> End
<Функция типа Тип > — функция, возвращающая величину типа Тип.
<Допустимое имя переменной> — допустимой переменной являются все переменные, описанные в данной функции или в данном процедурном блоке, глобальные переменные данного компонента. Для возвращения значения функции, в левой части оператора присваивания должно стоять имя функции.
Синтаксические конструкции описания выражений:
<Выражение>::= { <Выражение типа Long> | <Выражение типа Real> | <Выражение типа Integer> | <Выражение типа Color> | <Выражение типа Logic> | <Выражение типа String>|<Выражение типа Pointer>}
<Целочисленное выражение>::= { <Выражение типа Long> | <Выражение типа Integer>}
<Выражение типа Тип>::= [<Префиксная операция типа Тип>] <Операнд типа Тип> [<Операция типа Тип> <Операнд типа Тип>]
<Операция типа Long>::= {+| —| *|Div| Mod| And| Or| Xor}
<Операция типа Real>::= {+| —| *|/| RMod }
<Операция типа Integer>::= {+| —| *|Div| Mod| And| Or| Xor}
<Операция типа Color>::= {COr| CAnd| CXor}
<Операция типа Logic>::= {And| Or| Xor}
<Операция типа String>::= +
<Префиксная операция типа Long>::= { —| Not }
<Префиксная операция типа Real>::= —
<Префиксная операция типа Integer>::= { —| Not }
<Префиксная операция типа Color>::= CNot
<Префиксная операция типа Logic>::= Not
<Операнд типа Logic>::=::= {<Результат сравнения> | <Выражение типа Logic> | ( <Выражение типа Logic>) | <Константа типа Logic> | <Переменная типа Logic> | <Аргумент типа Logic> | <Вызов функции типа Logic>}
<Результат сравнения типов Long, Integer, Real>::= ( <Выражение типаLong, Integer, Real> {> | < | >= | <= | = | <>} <Выражение типаLong, Integer, Real> )
<Результат сравнения типаColor>::= ( <Выражение типа Color> {CEqual | CIn | CInclude | CExclude | CIntersect} <Выражение типа Color> )
<Результат сравнения типа String>::= ( <Выражение типаString> {= | <>} <Выражение типаString> )
<Операнд типа Тип>::= {<Выражение типа Тип> | ( <Выражение типа Тип>) | <Константа типа Тип> | <Переменная типа Тип> | <Аргумент типа Тип> | <Вызов функции типа Тип>}
<Вызов функции типа Тип>::= <Имя функции типа Тип> [( <Список фактических аргументов>)]
<Список фактических аргументов>::= <Выражение> [,<Список фактических аргументов>]
<Константное выражение типа Тип> — <Выражение типа Тип> в операндах которого не могут фигурировать переменные и функции, описанные пользователем.
<Числовое выражение>::= { <Выражение типа Long> | <Выражение типа Real> | <Выражение типа Integer>}
Синтаксические конструкции задания значений статическим переменным
Эта конструкция служит для задания значений параметрам (статическим переменным) компонентов. Для компонента сеть она может встречаться не только при описании главной сети, но и при описании любой составной подсети. В специальных выражениях типа Тип могут участвовать только стандартные функции и аргументы той структурной единицы, в которой находится блок задания значений статическим переменным. При этом специальное выражение, задающее значение параметра должно иметь тип, совместимый с типом статической переменной, которой присваивается это значение.
<Установление параметровСтруктурной единицы>::= <Однозначное имя Структурной единицы> [[ [<Переменная цикла>:] <Начальный номер> [..<Конечный номер> [:<Шаг>]]]] SetParameters <Список значений параметров>
<Переменная цикла>::= <Идентификатор>
<Начальный номер>::= <Константное выражение типа Long>
<Конечный номер>::= <Константное выражение типа Long>
<Шаг>::= <Константное выражение типа Long>
<Список значений параметров>::= <Значение параметра> [,<Список значений параметров>]
<Значение параметра>::= <Специальное выражение типа Тип>
<Специальное выражение типа Тип>::= [<Префиксная операция типа Тип>] <Специальный операнд типа Тип> [<Операция типа Тип> <Специальный операнд типа Тип>]
<Специальный операнд типа Тип >::= {<Специальное выражение типа Тип >|<Константатипа Тип>|<Переменная цикла>|(<Специальное выражение типа Тип >|<Аргумент типа Тип> | <Вызов функции типа Тип>)>
Синтаксические конструкции описания распределения сигналов или параметров:
Данная конструкция имеет четыре аргумента, имеющих следующий смысл:
Данное — сигнал или параметр.
Объект — предобработчик, интерпретатор, оценка, сеть.
Подобъект— частный предобработчик, частный интерпретатор, частная оценка, подсеть.
<Идентификатор данных>— одно из ключевых слов signals, parameters, data, insignals, outsignals.
<Описание распределения Данных, Объекта, Подобъекта,<Идентификатор данных>>::= Connections<Описание групп соответствийДанных>
<Описание групп соответствийДанных>::= <Описание группы соответствийДанных> [;<Описание групп соответствийДанных>]
<Описание группы соответствийДанных>::= <Блок сигналов Подобъекта> <=> {<Блок сигналов Объекта> | <Блок сигналов Подобъекта>}
<Блок сигналов Подобъекта>::= <Описатель сигналов Подобъекта> [;<Блок сигналов Подобъекта>]
<Описатель сигналов Подобъекта>::= { For<Переменная цикла> = <Начальный номер> To<Конечный номер> [Step <Шаг>] Do <Блок сигналов Подобъекта> End| <Список Данных Подобъекта>}
<Переменная цикла>::= <Идентификатор>
<Список Данных Подобъекта>::= <ДанноеПодобъекта>[; <Список ДанныхПодобъекта>]
<ДанноеПодобъекта>::= <Псевдоним>[[ <Номер экземпляра>]].<Идентификатор данных>[[ <Номер Данного>]]
<Номер экземпляра>::= {<Специальное выражение типа Long>| [+:]<Начальный номер> [..<Конечный номер> [:<Шаг>]]}
<Номер Данного> {<Специальное выражение типа Long>| [+:]<Начальный номер> [..<Конечный номер> [:<Шаг>]]}
<Блок ДанныхОбъекта>::= <Описатель ДанныхОбъекта> [; <Блок ДанныхОбъекта>]
<Описатель ДанныхОбъекта>::= { For<Переменная цикла> = <Начальный номер> To<Конечный номер> [Step <Шаг>] Do <Блок ДанныхОбъекта> End| <Список ДанныхОбъекта> }
<Список Данных Объекта>::= <ДанноеОбъекта>[; <Список ДанныхОбъекта>]
<ДанноеОбъекта>::= <Идентификатор данных>[[ <Номер Данного>]]
Комментарии
Для понятности описаний компонентов в них необходимо включать комментарии. Комментарием является любая строка (или несколько строк) символов, заключенных в фигурные скобки. Комментарий может находиться в любом месте описания компонента. При интерпретации или компиляции описания комментарии игнорируются (исключаются из текста).
Область действия переменных
Все идентификаторы состоят из произвольных комбинаций латинских букв, цифр и подчерков. Первым символом имени обязательно является буква. Использование букв только латинского алфавита связано с тем, что коды, используемые большинством компьютеров, имеют одинаковую кодировку для букв латинского алфавита, тогда как для букв национальных алфавитов других стран кодировка различна не только от компьютера к компьютеру но и от одной операционной системы к другой.
Заглавные и прописные буквы не различаются ни в именах, ни в ключевых словах.
Языки описания некоторых компонентов позволяют описывать глобальные переменные. Эти переменные доступны во всех функциях и процедурных блоках данного компонента. Функциям и процедурным блокам других компонентов эти переменные недоступны. Все остальные переменные (описанные в блоках Var и Static) являются локальными и доступны только в пределах той функции или процедурного блока, в котором они описаны. Статические переменные сохраняют свое значение между вызовами функций или процедурных блоков, тогда как переменные, описанные в блоках Var не сохраняют. В некоторых компонентах определены стандартные переменные и массивы (см. например описание языка описания нейронных сетей). В таких разделах область доступности предопределенных переменных оговаривается отдельно.
Переменная Error является глобальной для всех компонентов. Глобальной является также переменная ErrorManager. Однако не рекомендуется использование этих переменных путем прямого обращения к ним. Для получения значения переменной Error служит запрос GetError, исполняемый макрокомпонентом нейрокомпьютер.
Основные операторы
Оператор присваивания состоит из двух частей, разделенных знаком “=“. В левой части оператора присваивания могут участвовать имена любых переменных. В выражении, стоящем в правой части оператора присваивания могут участвовать любые переменные, аргументы процедурного блока и константы. В случае несоответствия типа выражения в правой части и типа переменной в левой части оператора присваивания производится приведение типа. Все выражения вычисляются слева на право с учетом старшинства операций.
Оператор ветвления. Оператор ветвления состоит из трех частей, каждая из которых начинается соответствующим ключевым словом. Первая часть — условие, начинается с ключевого слова If и содержит логическое выражение. В зависимости от значения вычисленного логического выражения выполняется Then часть (истина) или Else часть (ложь). Третья (Else) часть оператора может быть опущена. Каждая из выполняемых частей состоит из ключевого слова и оператора. При необходимости выполнить несколько операторов, необходимо использовать операторные скобки Begin End.
Цикл For имеет следующий вид:
For Переменная_цикла = Начальное_значение To Конечное_значение [By Шаг] Do <Оператор>
Переменная цикла должна быть одного из целочисленных типов. В ходе выполнения оператора она пробегает значения от Начальное_значение до Конечное_значение с шагом Шаг. Если описание шага опущено, то шаг равен единице. При каждом значении переменной цикла из диапазона выполняется оператор, являющийся телом цикла. Если в теле цикла необходимо выполнить несколько операторов, то необходимо воспользоваться операторными скобками. Допускается любое число вложенных циклов. Выполнение цикла в зависимости от соотношения между значениями Начальное_значение, Конечное_значение и Шаг приведено в табл. 14.
Таблица 14. Способ выполнения цикла в зависимости от значений параметров цикла.
Конечное значение Шаг Способ выполнения >Начального значения >0 Цикл выполняется пока переменная цикла ≤ Конечного значения <Начального значения >0 Тело цикла не выполняется =Начальному значению ≠0 Тело цикла выполняется один раз >Начального значения <0 Тело цикла не выполняется <Начального значения <0 Цикл выполняется пока переменная цикла ≥ Конечного значения Любое =0 Тело цикла не выполняетсяЦикл While. Тело цикла выполняется до тех пор, пока верно логическое выражение. Проверка истинности логического выражения производится перед выполнением тела цикла. Если тело цикла должно содержать более одного оператора, то необходимо использовать операторные скобки.
Описание распределения сигналов
Раздел описания распределения сигналов начинается с ключевого слова Connections. За ключевым словом Connections следует одна или несколько групп соответствий. Каждая группа соответствий состоит из правой и левой частей, разделенных символами «<=>«и описывает соответствие имен сигналов (параметров) различных структурных единиц. Каждая часть группы соответствий представляет собой список сигналов (параметров) или интервалов сигналов (параметров), разделенных между собой символом «;». Указанные в левой и правой частях сигналы (параметры) отождествляются. Если при указании сигнала (параметра) не указано имя подобъекта, то это сигнал (параметр) описываемого объекта. Использование интервала сигналов (параметров) в правой или левой части группы соответствий равносильно перечислению сигналов (параметров), с номерами, входящими в интервал, начиная с начального номера c шагом, указанным после символа «:». Если шаг не указан, то он полагается равным единице. Число сигналов в правой и левой частях группы соответствий должно совпадать. Если интервал пуст (например [2..1:1]), то описываемая им группа сигналов считается отсутствующей и пропускается. При использовании в описании соответствий явных циклов, во всех выражениях внутри цикла возможно использование переменной цикла. При этом подразумевается следующий порядок перечисления: Сначала изменяется номер в самом правом интервале, далее во втором справа, и т. д. В последнюю очередь изменяются значения переменных цикла явных циклов в порядке их вложенности (переменная самого внутреннего цикла меняется первой и т. д.). Рассмотрим следующий пример описания группы соответствий блока, содержащего две сети Net с 3 входами каждая. Ниже приведено две различных структуры связей по несколько эквивалентных вариантов описания.
Случай 1. Естественный порядок связей.
Вариант 1.
InSignals[1] <=> Net[1].InSignals[1]
InSignals[2] <=> Net[1].InSignals[2]
InSignals[3] <=> Net[1].InSignals[3]
InSignals[4] <=> Net[2].InSignals[1]
InSignals[5] <=> Net[2].InSignals[2]
InSignals[6] <=> Net[2].InSignals[3]
Вариант 2.
InSignals[1..6] <=> Net[1..2].InSignals[1..3]
Вариант 3.
InSignals[1];InSignals[2];InSignals[3];InSignals[4];InSignals[5];InSignals[6] <=> For I=1 To 3 Do For J=1 To 2 Do Net[J].InSignals[I] End End
Случай 2. Другой порядок связей.
Вариант 1.
InSignals[1] <=> Net[2].InSignals[3]
InSignals[2] <=> Net[1].InSignals[3]
InSignals[3] <=> Net[2].InSignals[2]
InSignals[4] <=> Net[1].InSignals[2]
InSignals[5] <=> Net[2].InSignals[1]
InSignals[6] <=> Net[1].InSignals[1]
Вариант 2.
InSignals[1..6] <=> For I=3 To 1 Step -1 Do Net[2..1:-1].InSignals[I] End
Вариант 3.
InSignals[6..1:-2]; InSignals[5..1:-2]<=> For I=1 To 3 Do For J=1 To 2 Do Net[J].InSignals[I] End End
Функции управления памятью
Для создания массивов и освобождения занимаемой ими памяти используются следующие функции:
Создание массива.
Function NewArray(Type: Integer; Size: Long): PRealArray;
Описание аргументов:
Type — задает размер элемента массива и является одной из предопределенных констант, приведенных в табл. 15.
Size — число элементов в массиве.
Описание исполнения.
1. Если аргумент Type не совпадает ни с одной из предопределенных констант, приведенных в табл. 15, то возвращается значение Null, исполнение функции завершается.
2. Создается массив, занимающий Size*Type+4 байта.
3. Адрес массива возвращается как результат.
Таблица 15. Предопределенные константы типов элементов массивов
Идентификатор Значение Описание mRealArray 4 Размер элемента — 4 байта mIntegerArray 2 Размер элемента — 2 байта mLongArray 4 Размер элемента — 4 байта mLogicArray 1 Размер элемента — 1 байтОсвобождение массива.
Function FreeArray(Type: Integer; Array: PRealArray): Logic;
Описание аргументов:
Type — задает размер элемента массива и является одной из предопределенных констант, приведенных в табл. 15.
Array — адрес массива. Память, занимаемая этим массивом, должна быть освобождена.
Описание исполнения.
1. Если аргумент Type не совпадает ни с одной из предопределенных констант, приведенных в табл. 15, то возвращается значение False, исполнение функции завершается.
2. Освобождается память размером TReal(Array[0])*Type+4 байта.
3. Аргументу Array присваивается значение Null
Пересоздание массива.
Function ReCreateArray(Type: Integer; Array: PRealArray; Size: Long): Logic;
Описание аргументов:
Type — задает размер элемента массива и является одной из предопределенных констант, приведенных в табл. 15.
Array — адрес массива.
Size — число элементов в массиве.
Описание исполнения.
1. Если аргумент Type не совпадает ни с одной из предопределенных констант, приведенных в табл. 15, то возвращается значение False, исполнение функции завершается.
2. Если аргумент Array не равен Null, и TReal(Array[0]) равен Size, то возвращается значение True, выполнение функции завершается.
3. Если аргумент Array не равен Null, и TReal(Array[0]) не равен Size, то освобождается память размером TReal(Array[0])*Type+4 байта. Аргументу Array присваивается значение Null
4. Аргументу Array присваивается значение NewArray(Type,Size), возвращается значение True, исполнение функции завершается.
(обратно)Использование памяти
Ряд запросов, исполняемых различными компонентами, возвращают в качестве ответа указатели на массивы. В этих случаях действуют следующие правила:
1. Если компонент получил пустой указатель (Null), то он сам создает массив необходимой длины.
2. Если передан непустой указатель, но существующей длины массива недостаточно, то компонент освобождает память, занятую под переданный массив и создает новый массив необходимой длины.
3. Освобождение памяти после использования массива лежит на вызывающем компоненте.
Если одному из компонентов не хватает памяти для выполнения запроса, то этот компонент может передать макрокомпоненту нейрокомпьютер запрос на дополнительную память. В этом случае макрокомпонент нейрокомпьютер передает всем компонентам запрос FreeMemory. При исполнении данного запроса каждый компонент должен освободить всю память, не являющуюся абсолютно необходимой для работы. Например, компонент задачник может для быстроты обработки держать в памяти все обучающее множество. Однако абсолютно необходимой является память, достаточная для хранения в памяти одного примера.
Запрос на освобождение памяти исполняется каждым компонентом и не включен в описания запросов компонентов, приведенные в следующих разделах.
Обработка ошибок
Схема обработки ошибок достаточно проста по своей идее — каждый новый обработчик ошибок может обрабатывать только часть ошибок, а обработку остальных может передать ранее установленному обработчику. Пользователь может организовать обработку ошибок и не прибегая к установке обработчика ошибок — обработчик ошибок по умолчанию почти во всех случаях устанавливает номер последней ошибки в переменную Error, которая может быть считана с помощью запроса GetError и обработана прямо в компоненте, выдавшем запрос.
Если обработчик ошибок устанавливает номер последней ошибки в переменной Error, то все запросы, поступившие после момента установки, завершаются неуспешно. Это состояние сбрасывается при вызове запроса «дать номер ошибки».
Процедура обработки ошибок
Процедура обработки ошибок должна удовлетворять следующим требованиям:
• Это должна быть процедура с дальним типом адресации. Формат описания процедуры обработки ошибок
Far;ErrorFunc(Long ErrorNumber)
• После обработки ошибок процедура может вызвать ранее установленный обработчик ошибок. Адрес ранее установленного обработчика ошибок процедура обработки ошибок получает в ходе следующей процедуры:
• Вызов процедуры с нулевым номером ошибки означает, что в следующем вызове будет передан адрес старой процедуры обработки ошибок.
• Значение аргумента ErrorNumber при вызове, следующем непосредственно за вызовом с нулевым номером ошибки, должно интерпретироваться как адрес старой процедуры обработки ошибок.
Ниже приведено описание запросов, связанных с обработкой ошибок и исполняемых макрокомпонентом нейрокомпьютер.
Установить обработчик ошибок (OnError)
Описание запроса:
Pascal:
Function OnError(NewError: ErrorFunc): Logic;
C:
Logic OnError(ErrorFunc NewError)
Описание аргументов:
NewError — адрес новой процедуры обработки ошибок.
Назначение — устанавливает новый обработчик ошибок.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Вызов NewError с аргументом 0 — настройка на установку цепочки обработки ошибок.
3. Вызов NewError с аргументом ErrorManager (вместо длинного целого передается адрес старой процедуры обработки ошибок).
4. ErrorManager:= NewError
Дать номер ошибки (GetError)
Описание запроса:
Pascal:
Function GetError: Integer;
C:
Integer GetError()
Назначение — возвращает номер последней необработанной ошибки и сбрасывает ее.
Описание исполнения.
1. GetError:= Error
2. Error:= 0
Списки ошибок, возникающих в различных компонентах, даны в разделах «Ошибки компоненты …», в соответствующих разделах. Все номера ошибок каждого компонента являются трехзначными числами и начинаются с номера компонента, указанного в колонке «Ошибка» табл. 16.
(обратно)Запросы, однотипные для всех компонентов
Таблица 16. Префиксы компонентов
Префикс Компонент Запроса Ошибки ex 0 Исполнитель tb 1 Задачник pr 2 Предобработчик nn 3 Сеть es 4 Оценка ai 5 Интерпретатор ответа in 6 Учитель cn 7 КонтрастерРяд запросов обрабатывается всеми компонентами, кроме компонента исполнитель, носящего вспомогательный характер. Один из таких запросов — FreeMemory — был описан в разделе «Управление памятью», а два запроса, связанных с обработкой ошибок — в разделе «Обработка ошибок». В данном разделе приводятся описания остальных запросов, имеющих одинаковый смысл для всех компонентов. В отличие от ранее описанных запросов эти запросы опираются на структуру исполняющего компонента, поэтому к имени запроса добавляется префикс, задающий компонента. Список префиксов приведен в табл. 16. Единственным исключением из числа компонентов, исполняющих перечисленные в данном разделе запросы, является компонент исполнитель.
Все описываемые в данном разделе запросы можно разбить на четыре группы:
1. Установление текущего компонента.
2. Запросы работы со структурой компонента.
3. Запросы на получение или изменение параметров структурной единицы.
4. Запуск редактора компонента.
Все имена запросов начинаются с символов «xx», которые необходимо заменить на префикс из табл. 16 чтобы получить имя запроса для соответствующего компонента. При указании ошибок используется символ «n», который нужно заменить на соответствующий префикс ошибки из табл. 16.
Далее данном разделе компонентом также называются экземпляры компонента, а не только часть программы. Например, одна из загруженных нейронных сетей, а не только программный компонент сеть.
Запрос на установление текущего компонента
К этой группе запросов относится один запрос — xxSetCurrent — не исполняемый компонентом задачник.
Сделать текущей (xxSetCurrent)
Описание запроса:
Pascal:
Function xxSetCurrent(CompName: PString): Logic;
C:
Logic xxSetCurrent(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя компонента, которого надо сделать текущим.
Назначение — ставит указанного в параметре CompName компонента из списка загруженных компонентов на первое место в списке.
Описание исполнения.
1. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
2. Указанный в аргументе CompName компонент переносится в начало списка.
Запросы, работающие со структурой компонента
К этой группе относятся запросы, позволяющие выяснить структуру компонента, прочитать ее или сохранить на диске.
Добавление нового экземпляра (xxAdd)
Описание запроса:
Pascal:
Function xxAdd(CompName: PString): Logic;
C:
Logic xxAdd(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя файла компонента или адрес описания компонента.
Назначение — добавляет новый экземпляр компонента в список компонентов.
Описание исполнения.
1. Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя компонента и после пробела имя файла, содержащего компонента. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания компонента ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
2. Экземпляр компонента считывается из файла или из памяти и добавляется первым в список компонентов (становится текущим).
3. Если считывание завершается по ошибке, то возникает ошибка n02 — ошибка считывания компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
Удаление экземпляра компонента (xxDelete)
Описание запроса:
Pascal:
Function xxDelete(CompName: PString): Logic;
C:
Logic xxDelete(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую полное имя компонента.
Назначение — удаляет указанного в параметре CompName компонента из списка компонентов.
Описание исполнения.
1. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
Заметим, что попытка удаления младшей структурной единицы приводит к удалению всего компонента содержащего данную структурную единицу.
Запись компонента (xxWrite)
Описание запроса:
Pascal:
Function xxWrite(CompName: PString; FileName: PString): Logic;
C:
Logic xxWrite(PString CompName, PString FileName)
Описание аргументов:
CompName — указатель на строку символов, содержащую имя компонента.
FileName — имя файла или адрес памяти, куда надо записать компонента.
Назначение — сохраняет в файле или в памяти компонента, указанного в аргументе CompName.
Описание исполнения.
1. Если в качестве аргумента CompName дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является текущий компонент.
2. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Если в качестве аргумента FileName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя файла, для записи компонента. В противном случае FileName должен содержать пустой указатель. В этом случае запрос вернет в нем указатель на область памяти, куда будет помещено описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то в текст будет включено ключевое слово Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
4. Если во время сохранения компонента возникнет ошибка, то генерируется ошибка n03 — ошибка сохранения компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
Вернуть имена структурных единиц (xxGetStructNames)
Описание запроса:
Pascal:
Function xxGetStructNames(CompName: PString; Var Names: PRealArray): Logic;
C:
Logic xxGetStructNames(PString CompName, RealArray* Names)
Описание аргументов:
CompName — указатель на строку символов, содержащую имя компонента или полное имя его структурной единицы.
Names — массив указателей на имена структурных единиц.
Назначение — возвращает имена всех компонентов в списке компонентов или имена всех структурных единиц структурной единицы, указанной в аргументе CompName.
Описание исполнения.
1. Если в качестве аргумента CompName дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является соответствующий программный компонент. В качестве ответа в указателе Names возвращается массив, каждый элемент которого является указателем на не подлежащую изменению символьную строку, содержащую имя компонента из списка. После адреса имени последнего компонента следует пустой указатель. Выполнение запроса успешно завершается.
2. Если имя компонента, переданное в аргументе CompName, не найдено в списке компонентов, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Возвращается массив, каждый элемент которого является указателем на не подлежащую изменению символьную строку, содержащую псевдоним структурной единицы, являющейся частью структурной единицы, указанной в аргументе CompName. Имена структурных единиц перечисляются в порядке следования в разделе описания состава структурной единицы, имя которой указано в аргументе CompName. Если одна из структурных единиц задана в описании состава несколькими экземплярами, то имя каждого экземпляра возвращается отдельно. После указателя на имя последней структурной единицы следует пустой указатель.
Вернуть тип структурной единицы (xxGetType)
Описание запроса:
Pascal:
Function xxGetType(CompName, TypeName: PString; Var TypeId: Integer): Logic;
C:
Logic xxGetType(PString CompName, PString TypeName, Integer TypeId)
Описание аргументов:
CompName — указатель на строку символов, содержащую полное имя структурной единицы.
TypeName — возвращает указатель на строку символов, содержащую имя структурной единицы, данное ей при описании.
TypeId — одна из предопределенных констант, соответствующая типу структурной единицы.
Назначение — возвращает имя и тип структурной единицы.
Описание исполнения.
1. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
2. В переменной TypeId возвращается тип структурной единицы. Значения предопределенных констант, соответствующих различным типам структурных единиц различных компонентов приведены в табл. 11 и в соответствующих разделах, содержащих описания компонентов.
3. Если структурная единица является стандартной, то указателю TypeName присваивается значение пустого указателя. Если структурная единица имеет пользовательский тип (значение аргумента TypeId равно –1), то указатель TypeName устанавливается на строку, содержащую имя, данное указанной в аргументе CompName структурной единице при ее описании.
Запросы на изменение параметров
К группе запросов на изменение параметров относятся три запроса: xxGetData — получить параметры структурной единицы. xxGetName — получить названия параметров и xxSetData — установить значения параметров структурной единицы.
Получить параметры (xxGetData)
Описание запроса:
Pascal:
Function xxGetData(CompName: PString; Var Param: PRealArray): Logic;
C:
Logic xxGetData(PString CompName, PRealArray* Param)
Описание аргументов:
CompName — указатель на строку символов, содержащую полное имя структурной единицы.
Param — адрес массива параметров.
Назначение — возвращает массив параметров структурной единицы, указанной в аргументе CompName.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся значения параметров. Параметры заносятся в массив в порядке описания в разделе описания статических переменных. Статические переменные, описанные вне описания структурных единиц, считаются параметрами компонента.
Получить имена параметров (xxGetName)
Описание запроса:
Pascal:
Function xxGetName(CompName: PString; Var Param: PRealArray): Logic;
C:
Logic xxGetName(PString CompName, PRealArray* Param)
Описание аргументов:
CompName — указатель на строку символов, содержащую полное имя структурной единицы.
Param — адрес массива указателей на названия параметров.
Назначение — возвращает массив указателей на названия параметров структурной единицы, указанной в аргументе CompName.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся адреса символьных строк, содержащих названия параметров.
Установить параметры (xxSetData)
Описание запроса:
Pascal:
Function xxSetData(CompName: PString; Param: PRealArray): Logic;
C:
Logic xxSetData(PString CompName, PRealArray Param)
Описание аргументов:
CompName — указатель на строку символов, содержащую полное имя структурной единицы.
Param — адрес массива параметров.
Назначение — заменяет значения параметров структурной единицы, указанной в аргументе CompName, на значения, переданные, в аргументе Param.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если список компонентов пуст или имя компонента, переданное в аргументе CompName, в этом списке не найдено, то возникает ошибка n01 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Параметры, значения которых хранятся в массиве, адрес которого передан в аргументе Param, передаются указанной в аргументе CompName структурной единице.
4. Если исполняющим запрос компонентом является интерпретатор ответа (aiSetData), то генерируется запрос SetEstIntParameters к компоненту оценка. Аргументы генерируемого запроса совпадают с аргументами исполняемого запроса.
Инициация редактора компоненты
К этой группе запросов относится запрос, который инициирует работу не рассматриваемых в данной работе компонентов — редакторов компонентов.
Редактировать компонент (xxEdit)
Описание запроса:
Pascal:
Procedure xxEdit(CompName: PString);
C:
void xxEdit(PString CompName)
Описание аргумента:
CompName — указатель на строку символов — имя файла или адрес памяти, содержащие описание редактируемого компонента.
Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя компонента и после пробела имя файла, содержащего описание компонента. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания компонента ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
Если в качестве аргумента CompName передан пустой указатель или указатель на пустую строку, то редактор создает новый экземпляр компонента.
Задача, используемая в примерах
В разделах, посвященных описанию предобработчика, задачника, интерпретатора ответа и оценки в качестве примера используется метеорологическая задача. Входная база данных содержит значения следующих показателей:
Температура воздуха — действительное число, изменяющееся от 273 до 393 градусов Кельвина.
Облачность — бинарный признак, означающий наличие (2) или отсутствие облачности (1).
Направление ветра — неупорядоченный качественный признак, принимающий одно из восьми значений: 1 — северный, 2 — северо-восточный, 3 — восточный, и т. д.
Осадки — упорядоченный качественный признак, принимающий следующие значения: 1 — без осадков, 2 — слабые осадки, 3 — сильные осадки.
В качестве ответов требуется предсказать значения тех же показателей через 8 часов.
Стандарт первого уровня компонента задачник
В этом разделе приводится описание хранения задачника на внешнем носителе.
Язык описания задачника
В языке описания задачника используется ряд ключевых слов, специфических для этого языка. Эти ключевые слова приведены в табл. 17.
Таблица 17. Ключевые слова специфические для языка описания задачника
Идентификатор Краткое описание TaskBook Заголовок описания задачника Picture Поле типа рисунок Structure Заголовок описания структуры задачника Source Описание источника данных Field Начало описания поля External Описание внешнего источника данныхСписок предопределенных констант языка описания задачника приведен в табл. 18. Эти константы используются при указании типа вектора, к которому принадлежит описываемое поле, при указании используемых векторов в запросе на открытие сеанса и при указании типа вектора в запросах на получение или занесение данных.
Таблица 18. Предопределенные константы
Идентификатор Значение Смысл tbColor 1 Цвет примера tbInput 2 Входной сигнал tbPrepared 3 Предобработанные данные tbAnswers 4 Правильные ответы tbReliability 5 Достоверность ответа tbCalcAnswers 6 Полученные ответы tbCalcReliability 7 Уверенность в ответе tbWeight 8 Вес примера tbEstimation 9 Оценки tbComment 10 КомментарииБНФ языка описания задачника
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание задачника>::= <Заголовок задачника> <Описание структуры задачника> <Описание источника данных> <Конец описания задачника>
<Заголовок задачника>::= TaskBook <Имя задачника>
<Имя задачника>::= <Идентификатор>
<Описание структуры задачника>::= <Заголовок описания структуры> <Описание полей> <Описание цвета><Описание веса> <Конец описания структуры>
<Заголовок описания структуры>::= Structure
<Описание цвета>::= Field<Имя поля цвет> tbColor Color End Field
<Имя поля цвет>::= <Константа типа String>
<Описание веса>::=Field<Имя поля вес> tbWeight Real End Field
<Имя поля вес>::= <Константа типа String>
<Описание полей>::= <Описание поля> [<Описание полей>]
<Описание поля>::= Field<Имя поля> <Тип вектора> {<Описание целого поля> | <Описание действительного поля> | <Описание перечислимого поля> | <Описание поля рисунка> | <Описание текстового поля>} End Field
<Имя поля>::= <Константа типа String>
<Тип вектора>::= {tbInput | tbAnswers | tbReliability | tbCalcAnswers | tbCalcReliability | tbEstimation}
<Описание целого поля>::= {Long | Integer}
<Описание действительного поля>::= Real
<Описание перечислимого поля>::= Enumerated<Список имен значений> ;
<Список имен значений>::= <Имя значения> [, <Список имен значений>]
<Имя значения>::= <Константа типа String>
<Описание текстового поля>::= String <Максимальная длина строки>
<Максимальная длина строки>::= <Константа типа Integer>
<Описание поля рисунка>::= Picture <Размер памяти для рисунка>
<Размер памяти для рисунка>::= <Константа типа Long>
<Конец описания структуры>::= End Structure
<Описание источника данных>::= Source {<Внешний источник> | <Подготовлено в задачнике>}
<Внешний источник>::= <Имя приложения, которому нужно передать запрос> <SQL — запрос>
<Имя приложения, которому нужно передать запрос>::= <Константа типа String>
<SQL — запрос>::= <Константа типа String>
<Подготовлено в задачнике> — В соответствии с порядком описания полей выводятся символьные представления полей, разделенные символом табуляции (байтом содержащим код 9). Примеры (в терминологии баз данных — записи) разделяются символом конца абзаца (переводом строки — байтом, содержащим код 13). Поля рисунки выводятся в виде последовательности <Размер памяти для рисунка> целых чисел, разделенных пробелами, каждое из которых является десятичным представлением числа (от 0 до 255), содержащегося в соответствующем байте области памяти, отведенной для хранения рисунка.
<Конец описания задачника>::= End TaskBook
Описание языка описания задачника
В этом разделе приведено подробное описание дополнительной информации (информации, следующей за типом данных поля) для полей, в блоках описания которых она используется.
Перечислимый тип поля. При использовании перечислимого типа поля в векторах данных хранятся не сами значения, а их номера. Для отображения в редакторе задачника значений полей их необходимо брать из блока описания поля. В списке имен значений блока описания перечислимого поля хранятся символьные константы, первая из которых содержит название состояния, соответствующее неопределенному значению поля; вторая — первому из значений, которые может принимать поле, и т. д.
Строка. Поля типа строка предназначены для хранения символьных строк фиксированной длины. Длина строки задается значением параметра <Максимальная длина строки>.
Таблица 19. Значение первых семи байт поля типа рисунок
Величина Значение Б2 * 256 + Б1 Положительное целое число, задающее размер рисунка по горизонтали в пикселях. Б4 * 256 + Б3 Положительное целое число, задающее размер рисунка по вертикали в пикселях. (Б7 * 256 + Б6) * 256 + Б5 Число цветов, использованных в рисункеРисунок. Поля типа рисунок предназначены для хранения графической информации. Первые семь байт поля имеют смысл, приведенный в табл. 19. В таблице принято обозначение Б1 — величина, хранящаяся в первом байте, Б2 — во втором и т. д. Рисунок разворачивается по строкам, начиная с левого верхнего угла, в непрерывный массив, размером (Б2*256+Б1)(Б4*256+Б3).
Если число цветов равно единице (черно-белое изображение), то каждый следующий байт содержит восемь пикселей изображения. Самый младший бит восьмого байта соответствует левому верхнему пикселю рисунка. Если число цветов равно трем, то каждый байт, начиная с восьмого, содержит информацию о четырех пикселях. Младшие два бита задают левый верхний пиксель рисунка. Если число цветов от 4 до 15, то каждый байт, начиная с восьмого, содержит информацию о двух пикселях. Младшие четыре бита задают левый верхний пиксель рисунка. Если число цветов от 16 до 255, то каждый байт, начиная с восьмого, содержит информацию об одном пикселе. Значение в восьмом байте соответствует левому верхнему пикселю рисунка. При числе цветов от 256 до 65535 каждые два байта, начиная с восьмого, содержат информацию об одном пикселе (первый пиксель имеет цвет номер Б9*256+Б8). Значение в восьмом и девятом байтах соответствует левому верхнему пикселю рисунка. При числе цветов от 65535 до 16777215 каждые три байта, начиная с восьмого, содержат информацию об одном пикселе (первый пиксель имеет цвет номер (Б10*256+Б9)*256+Б8). Значение в восьмом, девятом и десятом байтах соответствует левому верхнему пикселю рисунка.
Альтернативный способ записи рисунка. Предложенный выше способ хорош своей простотой и плох большим объемом данных. Большинство графических форматов файлов (например gif) обеспечивают высокую степень компрессии графической информации. Для использования этой возможности при записи поля графической информации на диск предлагается альтернативный формат. В этом формате первые два байта должны быть нулевыми. Поскольку в основном формате записи рисунков эти два байта формировали размер рисунка по горизонтали, нулевая ширина рисунка служит признаком использования альтернативного формата. Следующие пять байт хранят ascii коды типа графического формата. Используются коды заглавных букв латинского алфавита. Если тип графического стандарта содержит менее пяти символов (pcx, gif), то тип дополняется символами пробела справа. Следующие четыре байта, с восьмого по одиннадцатый, содержат число байт в графическом файле. Начиная с двенадцатого байта, идет информация, содержавшаяся в графическом файле.
Сопоставление элементов векторов правильных ответов, достоверности, вычисленных ответов, уверенности и оценки производится по следующему правилу. Первому полю типа правильный ответ соответствуют первое поле типа достоверность, первое поле типа вычисленный ответ, первое поле типа уверенность, первое поле типа оценка, второму — вторые и т. д.
Неопределенные значения
В практике работы большинство таблиц данных не полны. То есть, часть данных в примерах задачника не известна. Задачник должен однозначно указать предобработчику неизвестные данные. Для этих целей для каждого типа входных данных определено специальное значение — неопределенное. Для передачи неизвестных значений используются следующие величины: 10-40 для действительных чисел и 0 для всех типов качественных признаков.
Пример описания задачника
В этом разделе приведено описания простого задачника для прогнозирования курса американского доллара к рублю. Задачник содержит три примера. В разделе описания данных вместо символа табуляции использован символ «®», а вместо символа конца абзаца — «¶».
TaskBook CursValuty
Structure
Field" Цвет" tbColor Color End Field
Field" Вес" tbWeight Real End Field
Field" Дата" tbCommentReal End Field
Field" Текущий курс" tbInputReal End Field
Field" Курс на следующий день" tbAnswersReal End Field
Field" Достоверность курса" tbReliabilityReal End Field
Field" Предсказанный курс" tbCalcAnswersReal End Field
Field" Надежность предсказания" tbCalcReliabilityReal End Field
Field" Оценка предсказания" tbEstimation Real End Field
End Structure
Source
HFFFF®1.0®01.01.97®5773®5774®1.0®5775®0.1®0.07¶
HFFFF®1.0®02.01.97®5774®5776®1.0®5777®0.01®0.7¶
HFFFF®1.0®03.01.97®5776®5778®1.0®5779®0.2®0.007¶
End TaskBook
(обратно) (обратно)Стандарт второго уровня компонента задачник
В этом разделе описаны все запросы компонента задачник в виде процедур и функций. При описании используется синтаксис языков Turbo Pascal и С. В Паскаль варианте приведены заголовки функций и процедур. В С варианте — прототипы функций. Большинство запросов, реализуется в виде функций, сообщающих о корректности завершения операции.
Предполагается возможность одновременной работы нескольких сеансов одного задачника. Например, допускается редактирование задачника и одновременное обучение сети по тому же задачнику.
Все запросы к компоненту задачник можно разбить на следующие группы.
1. Чтение и запись задачника.
2. Начало и конец сеанса.
3. Перемещение по примерам.
4. Определение, получение и изменение данных.
5. Окраска примеров.
6. Установление структуры Задачника.
7. Добавление и удаление примеров.
8. Обработка ошибок.
Чтение и запись задачника
К этой группе запросов относятся запросы, работающие со всем задачником в целом. Эти запросы считывают задачник, сохраняют задачник на диске или выгружают ранее считанный или созданный задачник.
Прочитать задачник (tbAdd)
Описание запроса:
Pascal:
Function tbAdd(CompName: PString): Logic;
C:
Logic tbAdd(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя файла задачника.
Назначение — служит для считывания задачника.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в данный момент считан задачник, то генерируется запрос tbDelete. Если запрос tbDelete завершается неуспешно, то генерируется внутренняя ошибка 104 — попытка считывания задачника при открытых сеансах ранее считанного задачника. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Первые четыре символа строки CompName составляют слово File. Остальная часть строки содержит имя компонента и после пробела имя файла, содержащего компонент.
4. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 102 — ошибка чтения задачника. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
Записать задачник (tbWrite)
Описание запроса:
Pascal:
Function tbWrite(CompName, FileName: PString): Logic;
C:
Logic tbWrite(PString CompName, PString FileName)
Описание аргументов:
CompName — указатель на строку символов, содержащую имя задачника.
FileName — имя файла, куда надо записать компонента.
Назначение — сохраняет задачник в файле.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса отсутствует считанный задачник, то возникает ошибка 101 — запрос при отсутствии задачника, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Задачник записывается в файл FileName под именем CompName.
4. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 103 — ошибка записи задачника. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
Закрыть задачник (tbDelete)
Описание запроса:
Pascal:
Function tbDelete: Logic;
C:
Logic tbDelete()
Назначение — удаляет из памяти ранее считанный задачник.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если есть открытые сеансы, то возникает ошибка 105 — закрытие задачника при открытых сеансах. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Задачник закрывается. Запрос успешно завершается.
Начало и конец сеанса
К этой группе запросов относятся два запроса, открывающие и закрывающие сеансы работы с задачником.
Начало сеанса (InitSession)
Описание запроса:
Pascal:
Function InitSession(NewColor: Color; Oper: Integer; Var Handle: Integer): Logic;
C:
Logic InitSession(Color NewColor, Integer Oper, Integer* Handle)
Описание аргументов:
NewColor — цвет для отбора примеров задачника в текущую выборку.
Oper — операция для отбора в текущую выборку. Должна быть одной из констант CEqual, CIn, CInclude, Cxclude, CIntersect
Handle — номер сеанса. Начальное значение не важно. В этом аргументе возвращается номер сеанса.
Назначение — начинает сеанс. Отбирает текущую выборку.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Oper является недопустимым, то возникает ошибка 106 — недопустимый код операции при открытии сеанса, управление передается обработчику ошибок. Сеанс не открывается. Возвращается значение ложь.
3. Создается новый сеанс (в одно-сеансовых задачниках просто инициируется сеанс). Номер сеанса заносится в аргумент Handle.
4. Значения аргументов NewColor и Oper сохраняются во внутренних переменных задачника
5. Указателю текущего примера присваивается состояние «до первого примера»
6. InitSession:= Next(Handle) — результат выполнения запроса совпадает с результатом выполнения вызванного запроса «Следующий пример».
Конец сеанса (EndSession)
Описание запроса:
Pascal:
Procedure EndSession(Handle: Integer);
C:
void EndSession(Integer Handle)
Назначение — закрывает сеанс.
Описание аргументов:
Handle — номер сеанса.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Освобождается вся память, взятая для выполнения сеанса. После этого сеанс завершается.
Перемещение по примерам
В эту группу запросов входят запросы позволяющие управлять положением текущего указателя в текущей выборке.
В начало (Home)
Описание запроса:
Pascal:
Function Номе(Handle: Integer): Logic;
C:
Logic Номе(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — делает текущим первый пример текущей выборки.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Указателю на текущий пример присваивается значение «до первого примера»
4. Home:= Next(Handle) — результат выполнения запроса совпадает с результатом выполнения вызванного запроса «Следующий»
В конец (End)
Описание запроса:
Pascal:
Function End(Handle: Integer): Logic;
C:
Logic End(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — делает текущим последний пример текущей выборки.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Указателю на текущий пример присваивается значение «после последнего примера»
4. Home:= Prev(Handle) — результат выполнения запроса совпадает с результатом выполнения вызванного запроса «Предыдущий»
Следующий (Next)
Описание запроса:
Pascal:
Function Next(Handle: Integer): Logic;
C:
Logic Next(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — делает текущим следующий пример текущей выборки.
Описание исполнения.
Если Error <> 0, то выполнение запроса прекращается.
1. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
2. Если значение указателя равно «после последнего примера», то возникает ошибка 108 — переход за конечную границу текущей выборки, и управление передается обработчику ошибок. В случае возврата управления в запрос, происходит немедленный выход из запроса с возвращением значения ложь.
3. Если значение указателя текущего примера равно «до первого примера», то присваиваем указателю адрес первого примера задачника. Если адрес в переменной в задачнике нет примеров, то возникает ошибка 108 — переход за конечную границу текущей выборки, и управление передается обработчику ошибок. В случае возврата управления в запрос, происходит немедленный выход из запроса с возвращением значения ложь. В противном случае переходим к шагу 6
4. Указатель перемещается на следующий пример задачника. Если следующего примера задачника нет, то указателю присваивается значение «после последнего примера».
5. Переходим к шагу 5, если не верно условие: NewColo) And Last, NewColor — аргументы запроса InitSession, которым был открыт данный сеанс.
6. Next:= Not Last (Переход к следующему примеру завершился удачно, если указатель не установлен в значение «после последнего примера»).
Предыдущий (Prev)
Описание запроса:
Pascal:
Function Prev(Handle: Integer): Logic;
C:
Logic Prev(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — делает текущим предыдущий пример текущей выборки.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Если значение указателя равно «до первого примера», то возникает ошибка 109 — переход за начальную границу текущей выборки, и управление передается обработчику ошибок. В случае возврата управления в запрос, происходит немедленный выход из запроса с возвращением значения ложь.
4. Если значение указателя равно «после последнего примера», то присваиваем указателю адрес последнего примера задачника. Если в задачнике нет примеров, то возникает ошибка 109 — переход за начальную границу текущей выборки, и управление передается обработчику ошибок. В случае возврата управления в запрос, происходит немедленный выход из запроса с возвращением значения ложь.
5. В противном случае шаг 7.
6. Указатель перемещается на предыдущий пример задачника. Если предыдущего примера задачника нет, то указателю присваивается значение «до первого примера».
7. Шаг 6 повторяется до тех пор, пока не выполнится условие: First
8. Next:= Not Last (Переход к следующему примеру завершился удачно, если указатель не установлен в значение «после последнего примера»).
Конец (Last)
Описание запроса:
Pascal:
Function Last(Handle: Integer): Logic;
C:
Logic Last(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — возвращает значение истина, если текущим является состояние «после последнего примера», и ложь — в противном случае.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Возвращает значение истина, если текущим является состояние «после последнего примера», и ложь — в противном случае.
Начало (First)
Описание запроса:
Pascal:
Function First(Handle: Integer): Logic;
C:
Logic First(Integer Handle)
Описание аргументов:
Handle — номер сеанса.
Назначение — возвращает значение истина, если текущим является состояние «перед первым примером», и ложь в противном случае.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Возвращает значение истина, если текущим является состояние «перед первым примером», и ложь в противном случае.
Пример номер (Example)
Описание запроса:
Pascal:
Function Example(Number: Long; Handle: Integer): Logic;
C:
Logic Example(Long Number, Integer Handle)
Описание аргументов:
Number — номер примера, который должен быть сделан текущим. Нумерация примеров ведется с единицы.
Handle — номер сеанса.
Назначение — делает текущим пример текущей выборки с указанным номером.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Указатель устанавливается в состояние «до первого примера».
4. Number раз выполняем запрос Next.
5. Example:= Not Last (Если не установлено состояние «после последнего примера», то запрос выполнен успешно).
Определение, получение и изменение данных
К данной группе запросов относятся запросы позволяющие получать данные из задачника, заносить данные в задачник и сбросить предобработку (необходимо выполнить данный запрос после изменений в данных или предобработчике, если задачник хранит векторы предобработанных данных)
Дать пример (Get)
Описание запроса:
Pascal:
Function Get(Handle: Integer; Var Data: PRealArray; What: Integer): Logic;
C:
Logic Get(Integer Handle, PRealArray* Data, Integer What)
Описание аргументов:
Handle — номер сеанса;
Data — указатель на массив, в котором должны быть возвращены данныt;
What — одна из предопределенных констант tbColor, tbInput, tbPrepared, tbAnswers, tbReliability, tbCalcAnswers, tbCalcReliability, tbWeight, tbEstimation, tbComment
Назначение — возвращает указанную в запросе информацию.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Если аргумент What имеет недопустимое значение, то возникает ошибка 110 — неверный тип вектора в запросе Get. Управление передается обработчику ошибок. Выполнение запроса прекращается.
4. Если текущий указатель указывает на одно из состояний «до первого примера» или «после последнего примера», то возникает ошибка 111 — попытка чтения до или после текущей выборки. Управление передается обработчику ошибок. Запрос завершается неуспешно.
5. Если в аргументе What указан вектор предобработанных данных, но в текущем примере он отсутствует, то генерируется запрос предобработать данные. Если предобработка завершается успешно, то полученный вектор предобработанных данных включается в пример, в противном случае выполнение запроса прекращается. Возвращается значение ложь.
6. В элементы массива, на который указывает аргумент Data, копируются данные из того вектора данных текущего примера, который указан в аргументе What. Если требуемый вектор в задачнике отсутствует, то возникает ошибка 112 — данные отсутствуют и запрос завершается со значением ложь. В противном случае запрос успешно завершается.
Обновить данные (Put)
Описание запроса:
Pascal:
Function Put(Handle: Integer; Data: PRealArray; What: Integer): Logic;
C:
Logic Put(Integer Handle, PRealArray Data, Integer What)
Описание аргументов:
Handle — номер сеанса
Data — указатель на массив, в котором переданы данные, которые должны быть занесены в задачник.
What — одна из предопределенных констант tbColor, tbInput, tbPrepared, tbAnswers, tbReliability, tbCalcAnswers, tbCalcReliability, tbWeight, tbEstimation, tbComment
Назначение — обновить данные текущего примера
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Если аргумент What имеет недопустимое значение, то возникает ошибка 113 — неверный тип вектора в запросе Put. Управление передается обработчику ошибок. Выполнение запроса прекращается.
4. Если текущий указатель указывает на одно из состояний «до первого примера» или «после последнего примера», то возникает ошибка 111 — попытка чтения до или после текущей выборки. Управление передается обработчику ошибок. Запрос завершается неуспешно.
5. Если устанавливается вектор входных данных, то для текущего примера должен быть освобожден вектор предобработанных данных.
6. В данные примера копируются значения, указанные в массиве Data. Запрос успешно завершается.
Сбросить предобработку (RemovePrepare)
Описание запроса:
Pascal:
Procedure RemovePrepare;
C:
void RemovePrepare()
Назначение — отмена предобработки всех ранее предобработанных примеров.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. У всех примеров задачника освобождаются вектора предобработанных данных.
Окраска примеров
В данный раздел помещены запросы для работы с цветами. Отметим, что цвет примера, возвращаемый запросом GetColor можно получить также с помощью запроса Get.
Дать цвет примера (GetColor)
Описание запроса:
Pascal:
Function GetColor(Handle: Integer): Color;
C:
Logic GetColor(Integer Handle)
Описание аргументов:
Handle — номер сеанса
Назначение — возвращает цвет текущего примера.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Если текущий указатель указывает на одно из состояний «до первого примера» или «после последнего примера», то возникает ошибка 111 — попытка чтения до или после текущей выборки. Управление передается обработчику ошибок. Запрос завершается неуспешно.
4. Возвращается цвет текущего примера.
Покрасить пример (PaintCurrent)
Описание запроса:
Pascal:
Function PaintCurrent(Handle: Integer; NewColor, ColorMask: Color; Oper: Integer): Logic;
C:
Logic PaintCurrent(Integer Handle, Color NewColor, Color ColorMask, Integer Oper)
Описание аргументов:
Handle — номер сеанса.
NewColor — новый цвет для окраски примера.
ColorMask — маска цвета для окраски примера.
Oper — операция, используемая при окраске примера. Должна быть одной из констант COr, CAnd, CXor, CNot.
Назначение — изменяет цвет текущего примера.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если аргумент Handle некорректен возникает ошибка 107 — неверный номер сеанса. Управление передается обработчику ошибок. Выполнение запроса прекращается.
3. Если Oper некорректен, то возникает ошибка 114 — неверная операция окраски примера. Управление передается обработчику ошибок. Запрос завершается со значением ложь.
4. Новый цвет примера:= (Старый цвет примера And ColorMask) Oper NewColor
Ошибки компонента задачника
В табл. 20 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом задачник, и действия стандартного обработчика ошибок.
Таблица 20. Ошибки компонента задачник и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 101 Запрос при отсутствии задачника Занесение номера в Error 102 Ошибка чтения задачника Занесение номера в Error 103 Ошибка записи задачника Занесение номера в Error 104 Попытка считывания задачника при открытых сеансах ранее считанного задачника Занесение номера в Error 105 Закрытие задачника при открытых сеансах Занесение номера в Error 106 Недопустимый код операции при открытии сеанса Занесение номера в Error 107 Неверный номер сеанса Занесение номера в Error 10 Переход за конечную границу текущей выборки Игнорируется 109 Переход за начальную границу текущей выборки Игнорируется 110 Неверный тип вектора в запросе Get Занесение номера в Error 111 Попытка чтения до или после текущей выборки Занесение номера в Error 112 Данные отсутствуют Игнорируется 113 Неверный тип вектора в запросе Put Занесение номера в Error 114 Неверная операция окраски примера Занесение номера в ErrorСтандарт первого уровня компонента предобработчик
Данный раздел посвящен описанию стандарта языка описания и хранения на внешнем носителе компонента предобработчик. Поскольку крайне редко встречаются случаи, когда сеть получает один входной сигнал, предобработчик всегда является составным. Построение предобработчика происходит в редакторе предобработчика. Для описания предобработчика предлагается использовать специальный язык.
Неопределенные значения
В практике работы большинство таблиц данных не полны. То есть, часть данных в примерах задачника неизвестна. Задачник должен однозначно указать предобработчику неизвестные данные. Для этих целей для каждого типа входных данных определено специальное значение — неопределенное. Для передачи неизвестных значений используются следующие величины: 10-40 для действительных чисел и 0 для всех типов качественных признаков.
Стандартные предобработчики
В большинстве случаев достаточно использовать стандартные предобработчики, список которых приведен в табл. 11. Ниже в данном разделе приведено описание параметров стандартных предобработчиков.
Все стандартные предобработчики получают в качестве аргументов массивы входной информации и входных сигналов. Кроме того, они содержат различные наборы параметров. Алгоритмы выполнения стандартных предобработчиков приведены в разделе «Пример описания предобработчика». Далее описаны наборы параметров стандартных предобработчиков. Все параметры должны быть описаны как статические переменные.
Предобработка бинарного признака (BinaryPrep). Предобработка производится в соответствии с табл. 4. главы «Предобработчик» Принимает одно входное данное и генерирует один входной сигнал. Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown — значение сигнала, который будет выдан, если значение входного признака не определено (0). По умолчанию эта величина равна (MinSignals+MaxSignals)/2.
Type — тип предобработки бинарного признака. Если значение параметра Type — истина, то производится предобработка по типу «Наличие другого свойства», если ложь, то по типу «Отсутствие заданного свойства». По умолчанию значение этого параметра равно истина.
Предобработка неупорядоченного качественного признака (UnOrdered). Предобработка производится в соответствии с табл. 5 главы «Предобработчик». Принимает одно входное данное и генерирует Num входных сигналов. Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown — значение сигналов, которые будут выданы, если значение входного признака не определено (0). По умолчанию эта величина равна (MinSignals+MaxSignals)/2.
Num — число состояний качественного признака (число генерируемых входных сигналов). По умолчанию значение этого параметра равно 2.
Предобработка упорядоченного качественного признака (Ordered). Предобработка производится в соответствии с табл. 6 главы «Предобработчик». Принимает одно входное данное и генерирует Num входных сигналов. Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown — значение сигналов, которые будут выданы, если значение входного признака не определено (0). По умолчанию эта величина равна (MinSignals+MaxSignals)/2
Num — число состояний качественного признака (число генерируемых входных сигналов). По умолчанию значение этого параметра равно 2.
Простейший предобработчик (EmptyPrep). Предобработка производится в соответствии с формулой (1). Принимает одно входное данное и генерирует один входной сигнал. Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown — значение сигнала, который будет выдан, если значение входного признака не определено (10-40). По умолчанию эта величина равна 0.
MinData, MaxData — значения нижней и верхней границ интервала изменения входных данных, соответственно. По умолчанию эти величины равны –1 и 1, соответственно. Эти значения могут быть определены поиском минимального и максимального значений по задачнику, однако предобработчик не может выполнить эту процедуру.
Модулярный предобработчик (ModPrep). Предобработка производится в соответствии с формулой (16). Принимает одно входное данное и генерирует столько входных сигналов, сколько элементов в массиве y (нулевой элемент массива содержит число элементов). Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown— значение сигналов, которые будут выданы, если значение входного признака не определено (10-40). По умолчанию эта величина равна 0.
Y — массив величин, используемых для предобработки (см. раздел « Модулярная предобработка»).
Функциональный предобработчик (FuncPrep). Предобработка производится в соответствии с формулой (17). Принимает одно входное данное и генерирует столько входных сигналов, сколько элементов в массиве y (нулевой элемент массива содержит число элементов). Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown— значение сигналов, которые будут выданы, если значение входного признака не определено (10-40). По умолчанию эта величина равна 0.
MinData, MaxData — значения нижней и верхней границ интервала изменения функции F от входных данных, соответственно. По умолчанию эти величины равны –1 и 1, соответственно. Эти значения могут быть определены поиском минимального и максимального значений функции по задачнику, однако предобработчик не может выполнить эту процедуру.
Y — массив величин, используемых для предобработки (см. раздел «Функциональная предобработка»).
F — имя однопараметрической функции действительного типа (ее адрес) используемой для предобработки.
Позиционный предобработчик (PositPrep). Предобработка производится в соответствии с формулой (19). Принимает одно входное данное и генерирует num входных сигналов. Предобработчик содержит следующие параметры.
MinSignals, MaxSignals — значения нижней и верхней границ интервала приемлемых входных сигналов, соответственно. По умолчанию эти величины равны –1 и 1, соответственно.
Unknown— значение сигналов, которые будут выданы, если значение входного признака не определено (10-40). По умолчанию эта величина равна 0.
Y — основание системы счисления (см. раздел «Функциональная предобработка»). По умолчанию эта величина равна 2.
Num — число цифр в представлении входного сигнала. По умолчанию эта величина равна 2.
Язык описания предобработчика
Предобработчик является составным объектом. В состав этого объекта входят частные предобработчики, правила распределения входных данных и входных сигналов сети между частными предобработчиками. Предобработчик при выполнении запроса на предобработку вектора входных данных получает на входе вектор исходных данных, а возвращает вектор входных сигналов сети.
Каждый частный интерпретатор ответа получает на входе вектор входных данных, которые он предобрабатывает, а на выходе дает вектор входных сигналов сети. Каждый частный интерпретатор описывается в виде процедурного блока.
В табл. 22 приведен список ключевых слов языка описания предобработчика, дополняющий список ключевых слов, приведенных в разделе «Общий стандарт». Кроме того, ключевыми словами являются имена стандартных предобработчиков, приведенные в табл. 21.
Таблица 21. Стандартные предобработчики
Идентификатор Параметры Тип Описание BinaryPrep MinSignals, MaxSignals: Real; Unknown: Real; Type: Logic. Binary Бинарный признак. Предобработка в соответствии с табл. 4 главы «Предобработчик». UnOrdered MinSignals, MaxSignals: Real; Unknown: Real; Num: Long Unordered Неупорядоченный качественный признак. Предобработка в соответствии с табл. 5 главы «Предобработчик». Ordered MinSignals, MaxSignals: Real; Unknown: Real; Num: Long Ordered Упорядоченный качественный признак. Предобработка в соответствии с табл. 6 главы «Предобработчик». EmptyPrep MinData, MaxData, Unnown, MinSignals, MaxSignals: Real Number Простейшая предобработка в соответствии с формулой (1) главы «Предобработчик». ModPrep MinSignals, MaxSignals: Real; Unknown: Real; Y: RealArray Number Модулярная предобработка в соответствии с формулой (16) главы «Предобработчик». FuncPrep MinSignals, MaxSignals, Unknown: Real; Y: RealArray; F: FuncType Number Функциональная предобработка в соответствии с формулой (17) главы «Предобработчик». PositPrep MinSignals, MaxSignals, Unnown, Y: Real; Num: Long Number Позиционная предобработка в соответствии с формулой (19) главы «Предобработчик».Таблица 22. Ключевые слова языка описания предобработчика.
Идентификатор Краткое описание Connections Начало блока описания распределения входных данных и сигналов. Contents Начало блока описания состава интерпретатора. Data Имя, по которому адресуются входные данные, начало блока описания входных данных Include Предшествует имени файла, целиком вставляемого в это место описания. NumberOf Функция. Возвращает число обрабатываемых частным предобработчиком входных данных или сигналов. Prep Начало заголовка описания частного предобработчика. Preparator Заголовок раздела файла, содержащий описание интерпретатора. Signals Имя, по которому адресуются входные сигналы; начало блока описания сигналов.БНФ языка описания предобработчика
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание предобработчика>::= <Заголовок> [<Описание функций>] [<Описание частных предобработчиков>] <Описание состава> [<Установление параметров>] [<Описание сигналов>] [<Описание данных>] [<Описание распределения сигналов>] [<Описание распределения данных>] <Конец описания предобработчика>
<Заголовок>::= Preparator <Имя предобработчика> ( <Список формальных аргументов>)
<Имя предобработчика>::= <Идентификатор>
<Описание частных предобработчиков>::= <Описание частного предобработчика> [<Описание частных предобработчиков>]
<Описание частного предобработчика>::= <Заголовок описания предобработчика> [<Описание статических переменных>] [<Описание переменных>] <Тело предобработчика>
<Заголовок описания предобработчика>::= Prep <Имя частного предобработчика> ([(<Список формальных аргументов>)])
<Имя частного интерпретатора>::= <Идентификатор>
<Тело предобработчика>::= Begin <Составной оператор> End
<Описание состава>::= Contents <Список имен предобработчиков>;
<Список имен предобработчиков>::= <Имя предобработчика> [,<Список имен предобработчиков>]
<Имя предобработчика>::= <Псевдоним>: {<Имя ранее описанного интерпретатора> | <Имя стандартного интерпретатора>} [[ <Число экземпляров >]] [(<Список фактических аргументов>)]
<Псевдоним>::= <Идентификатор>
<Число экземпляров >::= <Целое число>
<Имя ранее описанного интерпретатора>::= <Идентификатор>
<Имя стандартного интерпретатора>::= <Идентификатор>
<Установление параметров>::= <Установление параметров Частного предобработчика> [;<Установление параметров>]
<Описание сигналов>::= Signals <Константное выражение типа Long >
<Описание данных>::= Data<Константное выражение типа Long >
<Описание распределения сигналов>::= <Описание распределения Сигналов, Предобработчика, Частного предобработчика, Signals>
<Описание распределения данных>::= <Описание распределения Данных, Предобработчика, Частного предобработчика, Data>
<Конец описания предобработчика>::= End Preparator
Описание языка описания предобработчика
Структура описания предобработчика имеет вид: заголовок; описание функций; описание частных предобработчиков; описание состава; установление параметров; описание сигналов; описание данных; описание распределения сигналов; описание распределения данных; конец описания предобработчика.
Заголовок состоит из ключевого слова Preparator и имени предобработчика и служит для обозначения начала описания предобработчика в файле, содержащем несколько компонентов нейрокомпьютера.
Описание функций — фрагмент описания, в котором описаны функции, необходимые для работы предобработчиков.
Описание частного предобработчика — это описание процедуры, вычисляющей входные сигналы нейронной сети по входным данным. Формальные аргументы служат для задания размерностей обрабатываемых векторов. При выполнении частный предобработчик получает в качестве аргументов два вектора — входных данных и входных сигналов. Формально, при исполнении частный предобработчик имеет описание следующего вида:
Pascal:
Procedure Preparator(Data, Signals: PRealArray);
C:
void Preparator(PRealArray Data; PRealArray Signals);
В разделе описания состава перечисляются частные предобработчики, входящие в состав предобработчика. Признаком конца раздела служит символ «;».
В необязательном разделе установления параметров производится задание значений параметров (статических переменных) частных предобработчиков. После ключевого слова SetParameters следует список значений параметров в том порядке, в каком параметры были объявлены при описании частного интерпретатора (для стандартных интерпретаторов порядок параметров соответствует порядку, приведенному в описании стандартных предобработчиков в разделе «Стандартные предобработчики»). При использовании одного оператора задания параметров для задания параметров нескольким экземплярам одного частного предобработчика после ключевого словаsetparameters указывается столько выражений, задающих значения параметров, сколько необходимо для одного экземпляра.
В необязательном разделе «описание сигналов» указывается число сигналов, вычисляемых предобработчиком. Если этот раздел опущен, то полагается, что число вычисляемых предобработчиком сигналов равно сумме сигналов, вычисляемых всеми частными предобработчиками. В константном выражении возможно использование функции NumberOf, аргументом которой является имя частного предобработчика (или его псевдоним) и ключевое слово Signals, в качестве второго аргумента.
В необязательном разделе «описание данных» указывается число входных данных, предобрабатываемых предобработчиком. Если этот раздел опущен, то полагается, что число предобрабатываемых предобработчиком данных равно сумме данных, предобрабатываемых всеми частными предобработчиками. В константном выражении возможно использование функции NumberOf, аргументом которой является имя частного предобработчика (или его псевдоним) и ключевое слово Data, в качестве второго аргумента.
В необязательном разделе описания распределения сигналов (данных) указывается для каждого частного предобработчика какие сигналы (входные данные) из общего вектора сигналов (данных) передаются ему для обработки.
Наиболее часто встречающиеся интерпретаторы объявлены стандартными. Для стандартных интерпретаторов описание частных интерпретаторов отсутствует.
Кроме того, в любом месте описания интерпретатора могут встречаться комментарии, заключенные в фигурные скобки.
Пример описания предобработчика
В этом разделе приведены два примера описания одного и того же предобработчика для метеорологической задачи. Используется следующий состав предобработчика: первый элемент вектора входных данных (температура воздуха) обрабатывается простейшим предобработчиком (EmptyPrep); второй (облачность) — бинарным предобработчиком (BinaryPrep); третий (направление ветра) — предобработчиком неупорядоченных качественных признаков (UnOrdered); четвертый (осадки) — предобработчиком неупорядоченных качественных признаков (Ordered).
В первом примере приведено описание дубликатов всех стандартных предобработчиков. Во втором — использованы стандартные предобработчики.
Пример 1.
Preparator Meteorology
Function Sigmoid(X Real): Real;
Begin
Sigmoid = X / (1 + Abs(X))
End;
Prep BinaryPrep1() {Предобработка бинарного признака}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name"Значение сигнала, если значение входного признака не определено";
Logic Type Name "Тип предобработки бинарного признака";
Begin
If TLong(Data[1]) = UnknownLong Then Signals[1] = Unknown
Else Begin
If Type Then Begin
If TLong(Data[1]) = 1 Then Signals[1] = 0 Else Begin
If MaxSignals =0 Then Signals[1] = MinSignals
Else Signals[1] = MaxSignals
End
Else Begin
If TLong(Data[1]) = 1 Then Signals[1] = MinSignals
Else Signals[1] = MaxSignals
End
End
End
{Предобработка упорядоченного качественного признака}
Prep UnOrdered1(Num : Long)
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name"Значение сигнала, если значение входного признака не определено";
Var
Integer I;
Begin
If TLong(Data[1]) = UnknownLong Then Begin
For I = 1 To Num Do
Signals[I] = Unknown
End Else Begin
For I = 1 To Num Do
Signals[I] = MinSignals
Signals[TLong(Data[1])] = MaxSignals
End
End
Prep Ordered1(Num : Long) {Предобработка упорядоченного качественного признака}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name"Значение сигнала, если значение входного признака не определено";
Var
Integer I;
Begin
If TLong(Data[1]) = UnknownLong Then Begin
For I = 1 To Num Do
Signals[I] = Unknown
End Else Begin
For I = 1 To TLong(Data[1]) Do
Signals[I] = MaxSignals
For I = TLong(Data[1])+1 To Num Do
Signals[I] = MinSignals
End
End
Prep EmptyPrep1() {Предобработчик, осуществляющий масштабирование и сдвиг сигнала}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name"Значение сигнала, если значение входного признака не определено";
Real MinData Name"Значения нижней границы интервала изменения входных данных";
Real MaxData Name"Значения верхней границы интервала изменения входных данных";
Begin
If Data[1] = UnknownReal Then Signals[1] = Unknown
Else Signals[1] = (Data[1] – MinData) * (MaxSignals – MinSignals) / (MaxData – MinData) + MinSignals
End
Prep ModPrep1(Num : Long) {Модулярный предобработчик}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name "Значение сигнала, если значение входного признака не определено";
RealArray[Num] Y Name "Массив величин, используемых для предобработки"
Var
Integer I;
Begin
If Data[1] = UnknownReal Then Begin
For I = 1 To Num Do
Signals[I] = Unknown
End Else Begin
For I = 1 To Num Do
Signals[I] = (Data[1] RMod Y[I] + Y[I]) * (MaxSignals – MinSignals) / (2 * Y[I]) + MinSignals
End
Prep FuncPrep1(Num : Long; F : FuncType) {Функциональный предобработчик}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов";
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов";
Real Unknown Name "Значение сигнала, если значение входного " +
"признака не определено";
Real MinData Name "Значения нижней границы интервала изменения значений функции F ";
Real MaxData Name "Значения верхней границы интервала изменения значений функции F";
RealArray[Num] Y Name "Массив величин, используемых для предобработки"
Var
Integer I;
Begin
If Data[1] = UnknownReal Then Begin
For I = 1 To Num Do
Signals[I] = Unknown
End Else Begin
For I = 1 To Num Do
Signals[1] = (F(Data[1] – Y[1] – MinData) * (MaxSignals – MinSignals) / (MaxData – MinData) + MinSignals
End
Prep PositPrep1(Num : Long) {Позиционный предобработчик}
Static
Real MinSignals Name "Нижняя граница интервала приемлемых сигналов"
Real MaxSignals Name "Верхняя граница интервала приемлемых сигналов"
Real Unknown Name"Значение сигнала, если значение входного признака не определено";
Real Y Name "Основание системы счисления"
Var
Integer I;
Real W, Q;
Begin
If Data[1] = UnknownReal Then Begin
For I = 1 To Num Do
Signals[I] = Unknown
End Else Begin
W = Data[1];
For I = 1 To Num Do Begin
Q = W RMod Y;
Signals[I] = Q * (MaxSignals – MinSignals) / Y + MinSignals;
W = (W - Q) / Y
End;
End
Contents Temp : EmptyPrep1, Cloud : BinaryPrep1, Wind : UnOrdered1(8), Rain : Ordered1(3);
{Для всех предобработчиков приемлемые значения входных сигналов лежат в интервале от -1 до 1. В случае неопределенного значения во входных данных все сигналы данного предобработчика полагаются равными нулю. Входные данные первого предобработчика меняются от 273 до 293}
Temp SetParameters -1, 1, 1E-40, 273, 293;
CloudSetParameters -1, 1, 0, True;
Wind SetParameters -1, 1, 0;
RainSetParameters -1, 1, 0
Signals NumberOf(Signals,Temp) + NumberOf(Signals, Cloud) + NumberOf(Signals, Wind(8)) + NumberOf(Signals, Rain(3))
Data NumberOf(Data,Temp) + NumberOf(Data, Cloud) + NumberOf(Data,Wind(8)) + NumberOf(Data, Rain(3))
Connections
Temp.Data <=> Data[1];
Cloud.Data <=> Data[2];
Wind.Data <=> Data[3];
Rain.Data <=> Data[4];
Temp.Signals <=> Signals[1];
Cloud.Signals <=> Signals[2];
Wind.Signals[1..8] <=> Signals[3..10];
Rain.Signals[1..3] <=> Signals[11..13]
End Preparator
Пример 2.
Preparator Meteorology
Contents Temp : EmptyPrep, Cloud : BinaryPrep, Wind : UnOrdered(8), Rain : Ordered(3);
Temp SetParameters -1, 1, 1E-40, 273, 293
End Preparator
Стандарт второго уровня компонента предобработчик
Запросы к компоненту предобработчик можно разбить на пять групп:
1. Предобработка.
2. Изменение параметров.
3. Работа со структурой.
4. Инициация редактора предобработчика.
5. Обработка ошибок.
Поскольку нейрокомпьютер может работать одновременно с несколькими сетями, то и компонент предобработчик должна иметь возможность одновременной работы с несколькими предобработчиками. Поэтому большинство запросов к предобработчику содержат явное указание имени предобработчика. Ниже приведено описание всех запросов к компоненту предобработчик. Каждый запрос является логической функцией, возвращающей значение истина, если запрос выполнен успешно, и ложь — при ошибочном завершении исполнения запроса.
В запросах второй и третьей группы при обращении к частным интерпретаторам используется следующий синтаксис:
<Полное имя частного интерпретатора>::= <Имя интерпретатора>.
<Псевдоним частного интерпретатора> [[<Номер экземпляра>]]
При вызове ряда запросов используются предопределенные константы. Их значения приведены в табл. 23.
Таблица 23. Значения предопределенных констант компонента предобработчик
Название Значение Значение BinaryPrep 0 Стандартный предобработчик бинарных признаков UnOrdered 1 Стандартный предобработчик неупорядоченных качественных признаков Ordered 2 Стандартный предобработчик упорядоченных качественных признаков. EmptyPrep 3 Стандартный простейший предобработчик ModPrep 4 Стандартный модулярный предобработчик FuncPrep 5 Стандартный функциональный предобработчик PositPrep 6 Стандартный позиционный предобработчик UserType -1 Предобработчик, определенный пользователем.Запрос на предобработку
Единственный запрос первой группы выполняет основную функцию компонента предобработчик — предобрабатывает входные данные, вычисляя вектор входных сигналов.
Предобработать вектор сигналов (prepare)
Описание запроса:
Pascal:
Function Prepare(CompName: PString; Data: PRealArray; Var Signals: PRealArray): Logic;
C:
Logic Prepare(PString CompName, PRealArray Data; PRealArray* Signals)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя предобработчика.
Data — массив входных данных.
Signals — вычисляемый массив входных сигналов.
Назначение — предобрабатывает массив входных данных Data, вычисляя массив входных сигналов Signals используя предобработчик, указанный в параметре CompName.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента CompName дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является текущий предобработчик — первый в списке предобработчиков компонента предобработчик.
3. Если список предобработчиков компонента предобработчик пуст или имя предобработчика, переданное в аргументе CompName в этом списке не найдено, то возникает ошибка 201 — неверное имя предобработчика, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Производится предобработка предобработчиком, имя которого было указано в аргументе CompName.
5. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 204 — ошибка предобработки. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
(обратно)Остальные запросы
Ниже приведен список запросов к компоненту предобработчик, исполнение которых описано в разделе «Общий стандарт»:
prSetCurrent — Сделать предобработчик текущим
prAdd — Добавление нового предобработчика
prDelete — Удаление предобработчика
prWrite — Запись предобработчика
prGetStructNames — Вернуть имена структурных единиц предобработчика
prGetType — Вернуть тип структурной единицы предобработчика
prGetData — Получить параметры предобработчика
prGetName — Получить имена параметров предобработчика
prSetData — Установить параметры предобработчика
prEdit — Редактировать предобработчик
OnError — Установить обработчик ошибок
GetError — Дать номер ошибки
FreeMemory — Освободить память
В запросе prGetType в переменной TypeId возвращается значение одной из предопределенных констант, перечисленных в табл. 23.
Ошибки компонента предобработчик
В табл. 24 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом предобработчик, и действия стандартного обработчика ошибок.
Таблица 24. Ошибки компонента предобработчик и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 201 Неверное имя предобработчика Занесение номера в Error 202 Ошибка считывания предобработчика Занесение номера в Error 203 Ошибка сохранения предобработчика Занесение номера в Error 204 Ошибка предобработки Занесение номера в ErrorСтандарт первого уровня компонента сеть
Данный раздел посвящен описанию стандарта хранения компонента сеть на внешних носителях.
Структура компонента
Рассмотрим более подробно структуры данных сети. Как уже было описано ранее, сеть строится иерархически от простых подсетей к сложным. Простейшими подсетями являются элементы. Подсеть каждого уровня имеет свое имя и тип. Существуют следующие типы подсетей: элемент, каскад, слой, цикл с фиксированным числом тактов функционирования и цикл, функционирующий до тех пор, пока не выполнится некоторое условие. Последние четыре типа подсетей будем называть блоками. Имена подсетей определяются при конструировании. В разделе «Имена структурных единиц компонентов» приведены правила построения полного и однозначного имен подсети. В качестве примера рассмотрим сеть, конструирование которой проиллюстрировано в главе «Описание нейронных сетей» на рис. 2. В описании сети NW однозначное имя первого нейрона второго слоя имеет вид K[2].SN.N[1]. При описании слоя однозначное имя первого нейрона записывается как N[1]. В квадратных скобках указываются номер экземпляра подсети, входящей в непосредственно содержащую ее структуру в нескольких экземплярах.
Сигналы и параметры
При использовании контрастирования для изменения структуры сети и значений обучаемых параметров другим компонентам бывает необходим прямой доступ к сигналам и параметрам сети в целом или отдельных ее подсетей. Для адресации входных и выходных сигналов используются имена InSignals и OutSignals, соответственно. Таким образом, для получения массива входных сигналов второго слоя сети, приведенной на рис. 2, необходимо запросить массив NW.K[2].InSignals, а для получения выходного сигнала всей сети можно воспользоваться любым из следующего списка имен:
• NW.OutSignals;
• NW.N.OutSignals.
Для получения конкретного сигнала из массива сигналов необходимо в конце в квадратных скобках указать номер сигнала. Например, для получения третьего входного сигнала второго слоя сети нужно указать следующее имя — NW.K[2].InSignals[3].
Для получения доступа к параметрам нужно указать имя подсети, к чьим параметрам нужен доступ и через точку ключевое слово Parameters. При необходимости получить конкретный параметр, его номер в квадратных скобках записывается после ключевого слова Parameters.
Обучаемые и не обучаемые параметры и сигналы
При обучении параметров и сигналов (использование обучения сигналов описано во введении) возникает необходимость обучать только часть из них. Так, например, при описании обучения персептрона во второй части главы «Описание нейронных сетей» было отмечено, что обучать необходимо только веса связей второго слоя. Для реализации этой возможности используются два массива логических перемен-ных — маска обучаемых параметров и маска обучаемых входных сигналов.
Дополнительные переменные
При описании структуры сетей необходимо учитывать следующую дополнительные переменные, доступные в методах Forw и Back. Для каждой сети при прямом функционировании определен следующий набор переменных:
• InSignals[K] — массив из K действительных чисел, содержащих входные сигналы прямого функционирования.
• OutSignals[N] — массив из N действительных чисел, в которые заносятся выходные сигналы прямого функционирования.
• Parameters[M] — массив из M действительных чисел, содержащих параметры сети.
При выполнении обратного функционирования сети доступны еще три массива:
• Back.InSignals[K] — массив из K действительных чисел, параллельный массиву InSignals, в который заносятся выходные сигналы обратного функционирования.
• Back.OutSignals[N] — массив из N действительных чисел, параллельный массиву OutSignals, содержащий входные сигналы обратного функционирования.
• Back.Parameters[M] — массив из M действительных чисел, параллельный массиву Parameters, в который заносятся вычисленные при обратном функционировании поправки к параметрам сети.
При обучении (модификации параметров или входных сигналов) доступны все переменные обратного функционирования и еще два массива:
• InSignalMask[K] — массив из K логических переменных, параллельный массиву InSignals, содержащий маску обучаемости входных сигналов.
• ParamMask[M] — массив из M логических переменных, параллельный массиву Parameters, содержащий маску обучаемости параметров.
Стандарт языка описания сетей
Язык описания нейронных сетей предназначен для хранения сетей на диске. Следует отметить, что в отличии от таких компонентов, как предобработчик входных сигналов, оценка или задачник описание даже простой сети имеет большой размер. С другой стороны, многие подсети являются стандартными для большинства сетей. Для компонента сеть нет смысла вводить небольшой набор стандартных элементов и подсетей, поскольку этот набор может легко расширяться. Более эффективным является выделение часто употребляемых подсетей в отдельные библиотеки, подключаемые к описаниям конкретных сетей. В приведенных в этом разделе примерах описания нейронных сетей выделен ряд библиотек.
Ключевые слова языка
В табл. 25 приведен список ключевых слов специфических для языка описания сетей.
Таблица 25. Ключевые слова языка описания сетей.
Идентификатор Краткое описание Back Метод, осуществляющий обратное функционирование подсети. Префикс сигналов обратного функционирования. Block Тип аргумента подсети. Означает, что аргумент является подсетью. Cascad Тип подсети — каскад. Connections Начало блока описания связей подсети. Contents Начало блока описания состава подсети. DefaultType Тип параметров по умолчанию. Element Тип подсети — элемент. Forw Метод, осуществляющий прямое функционирования подсети. InSignalMask Имя, по которому адресуются маски обучаемости входных сигналов подсети. InSignals Имя, по которому адресуются входные сигналы подсети; начало блока описания входных сигналов. Layer Тип подсети — слой. Loop Тип подсети — цикл, выполняемый указанное число раз. MainNet Начало описания главной сети NetLib Начало описания библиотеки подсетей. NetWork Начало описания сети NumberOf Функция (запрос). Возвращает число параметров или сигналов в подсети. OutSignals Имя, по которому адресуются выходные сигналы подсети; начало блока описания выходных сигналов. ParamDef Заголовок определения типа параметров. Рarameters Имя, по которому адресуются параметры подсети; начало блока описания параметров. ParamMask Имя, по которому адресуются маски обучаемости параметров подсети. ParamType Заголовок описания типа параметров. Until Тип подсети — цикл, выполняемый до тех пор пока не выполнится условие. Used Начало списка подключаемых библиотек подсетейБНФ языка описания сетей
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание библиотеки подсетей>::= <Заголовок библиотеки> <Описание подсетей> <Конец описания библиотеки>
<Заголовок библиотеки>::= NetLib<Имя библиотеки> [Used <Список имен библиотек>]
<Имя библиотеки>::= <Идентификатор>
<Список имен библиотек>::= <Имя используемой библиотеки> [,<Список имен библиотек>]
<Имя используемой библиотеки>::= <Идентификатор>
<Описание подсетей>::= <Описание подсети> [<Описание подсетей>]
<Описание подсети>::= {<Описание элемента> | <Описание блока> | <Описание функций>}
<Описание элемента>::= <Заголовок описания элемента> <Описание сигналов и параметров> [<Описание типов параметров>] [<Определение типов параметров>] [<Описание статических переменных>] [<Установление значений статических переменных>] <Описание методов> <Конец описания элемента>
<Заголовок описания элемента>::= Element<Имя элемента> [( <Список формальных аргументов>)]
<Имя элемента>::= <Идентификатор>
<Описание сигналов и параметров>::= <Описание входных сигналов> <Описание выходных сигналов> [<Описание параметров>]
<Описание входных сигналов>::= InSignals<Константное выражение типа Long>
<Описание выходных сигналов>::= OutSignals<Константное выражение типа Long>
<Описание параметров>::= Parameters<Константное выражение типа Long>
<Описание типов параметров>::= <Описание типа параметров> [<Описание типов параметров>]
<Описание типа параметров>::= ParamType<Имя типа параметра><Список>
<Имя типа параметра>::= <Идентификатор>
<Список>::= {Parameters[ <Начальный номер> [..<Конечный номер> [<Шаг>]]] | InSignals[ <Начальный номер> [..<Конечный номер> [<Шаг>]]] } [;<Список>]
<Определение типов параметров>::= <Определение типа параметра> [<Определение типов параметров>]
<Определение типа параметра>::= ParamDef<Имя типа параметра> <Минимальное значение> <Максимальное значение>
<Минимальное значение>::= <Константное выражение типа Real>
<Максимальное значение>::= <Константное выражение типа Real>
<Установление значений статических переменных>::= <Установление параметров Подсети> [;<Установление значений статических переменных>]
<Описание методов>::= <Описание функционирования вперед> <Описание функционирования назад>
<Описание функционирования вперед>::= Forw [<Описание переменных>] <Тело метода>
<Тело метода>::= Begin<Составной оператор> End
<Описание функционирования назад>::= Back[<Описание переменных>] <Тело метода>
<Конец описания элемента>::= End<Имя элемента>
<Описание блока>::= <Заголовок описания блока> <Описание состава> <Описание сигналов и параметров> [<Описание статических переменных>] [<Установление значений статических переменных>] <Описание связей> [<Определение типов параметров>] <Конец описания блока>
<Заголовок описания блока>::= {<Описание каскада> | <Описание слоя> | <Описание цикла с фиксированным числом шагов> | <Описание цикла по условию>}
<Описание каскада>::=Cascad<Имя блока> [( <Список формальных аргументов блока>)]
<Имя блока>::= <Идентификатор>
<Список формальных аргументов блока>::= {<Список формальных аргументов> | <Аргумент — подсеть>} [;<Список формальных аргументов блока>]
<Аргумент — подсеть>::= <Список имен аргументов — подсетей>: Block
<Список имен аргументов — подсетей>::= <Имя аргумента — подсети> [,<Список имен аргументов — подсетей>]
<Имя аргумента — подсети>::= <Идентификатор>
<Описание слоя>::=Layer<Имя блока> [( <Список формальных аргументов блока>)]
<Описание цикла с фиксированным числом шагов>::=Loop<Имя блока> [( <Список формальных аргументов блока>)] <Число повторов цикла>
<Число повторов цикла>::= <Константное выражение типа Long>
<Описание цикла по условию>::=Until<Имя блока> [( <Список формальных аргументов блока>)]: <Выражение типа Logic>
<Описание состава>::= Contents <Список имен подсетей>
<Список имен подсетей>::= <Имя подсети> [,<Список имен подсетей>]
<Имя подсети>::= <Псевдоним>: {<Имя ранее описанной подсети> [( <Список фактических аргументов блока>)] [[ <Число экземпляров>]] | <Имя аргумента — подсети> [[ <Число экземпляров >]]}
<Псевдоним>::= <Идентификатор>
<Число экземпляров >::= <Константное выражение типа Long>
<Имя ранее описанной подсети>::= <Идентификатор>
<Список фактических аргументов блока>::= <Фактический аргумент блока> [,<Список фактических аргументов блока>]
<Фактический аргумент блока>::= {<Фактический аргумент> | <Имя аргумента — подсети>}
<Описание связей>::= {<Описание распределения Входных сигналов, Блока, Подсети, InSignals > | <Описание распределения Выходных сигналов, Блока, Подсети, OutSignals > | <Описание распределения Параметров, Блока, Подсети, Parameters >}
<Конец описания блока>::=End<Имя блока>
<Конец описания библиотеки>::= End NetLib
<Описание сети>::= <Заголовок описания сети> <Описание подсетей> <Описание главной сети> <Массивы параметров и масок сети> <Конец описания сети>
<Заголовок описания сети>::= NetWork<Имя сети> [Used <Список имен библиотек>]
<Имя сети>::= <Идентификатор>
<Описание главной сети>::= MainNet<Имя ранее описанной подсети> [( <Список фактических аргументов блока>)]
<Массивы параметров и масок сети>::= <Массив параметров> <Массив маски обучаемости параметров>
<Массив параметров>::= Parameters <Значения параметров>;
<Значения параметров>::= <Действительное число> [, <Значения параметров>]
<Массив маски обучаемости параметров>::= ParamMask<Значения маски>;
<Значения маски>::= <Константа типа Logic> [,<Значения маски>]
<Конец описания сети>::= End NetWork
Описание языка описания сетей
В этом разделе приводится детальное описание языка описания сетей, дополняющее БНФ, приведенную в предыдущем разделе и описание общих конструкций, приведенное в разделе «Общий стандарт».
Описание и область действия переменных
Вспомогательные переменные могут потребоваться при описании прямого и обратного функционирования элементов. Переменная действует только в пределах той процедуры, в которой она описана. Кроме явно описанных переменных, в методе Forw доступны также сигналы прямого функционирования и параметры элемента, а в методе Back — входные и выходные сигналы прямого функционирования, выходные сигналы обратного функционирования, параметры элемента и градиент по параметрам элемента. Во всех методах доступны аргументы элемента.
Статические переменные, описываемые после ключевого слова Static, уникальны для каждого экземпляра элемента или блока, и доступны только в пределах блока. Эти переменные могут потребоваться для вычисления условий в цикле типа Until. Возможно использование таких переменных в элементах, например, для хранения предыдущего состояния элемента. Кроме того, в статической переменной можно хранить значения не обучаемых параметров.
Методы Forw и Back для блоков
Методы Forw и Back для блоков не описываются в языке описания сетей. Это связано с тем, что при выполнении метода Forw блоком происходит вызов метода Forw составляющих блок подсетей (для элементов — метода Forw) в порядке их описания в разделе описания состава блока. При выполнении метода Back происходит вызов методов Back составляющих блок подсетей в порядке обратном порядку их описания в разделе описания состава блока.
Описание элементов
Описание элемента состоит из следующих основных разделов: заголовка элемента, описания сигналов и параметров, описания статических переменных и описания методов. Заголовок элемента имеет следующий синтаксис:
Element Имя_Элемента (Аргументы элемента)
Аргументы элемента являются необязательной частью заголовка. В следующем разделе приведены описания нескольких элементов. Отметим, что сигмоидный элемент описан двумя способами: с принципиально не обучаемой (S_NotTrain) и с обучаемой (S_Train) характеристикой.
Раздел описания сигналов и параметров следует сразу после заголовка элемента и состоит из указания числа входных и выходных сигналов и числа параметров элемента. Если у элемента отсутствуют параметры, то указание числа параметров можно опустить. В следующем разделе приведены элементы как имеющие параметры (S_Train, Adaptiv_Sum, Square_Sum), так и элементы без параметров (Sum, S_NotTrain, Branch). Концом раздела описания сигналов и параметров служит одно из ключевых слов ParamType, ParamDef, Forw или Back.
Описание типов параметров является необязательной частью описания элемента и начинается с ключевого слова ParamType. Если раздел описания типов параметров отсутствует, то все параметры этого элемента считаются параметрами типа DefaultType. Если в сети должны присутствовать параметры разных типов (например с разными ограничениями на минимальное и максимальное значение) необходимо описать типы параметров. Концом этого раздела служит одно из ключевых слов ParamDef, Forw или Back.
Раздел определения типов параметров является необязательным разделом в описании элемента и начинается с ключевого слова ParamDef. В каждой строке этого раздела можно задать минимальную и масимальную границы изменения одного типа параметров. Если в описании сети встречаются параметры неопределенного типа то этот тип считается совпадающим с типом DefaultType. Описание типа не обязано предшествовать описанию параметров этого типа. Так например, определение типа параметров может находиться в описании главной сети. Концом этого раздела служит одно из ключевых слов Forw или Back.
Раздел описания методов состоит из описания двух методов: Forw и Back. Описание метода состоит из заголовка, раздела описания переменных и тела метода. Заголовок имеет вид ключевого слова Forw или Back для соответствующего метода. Раздел описания переменных состоит из ключевого слова Var, за которым следуют описания однотипных переменных, каждое из которых заканчивается символом «;». Необходимо понимать, что описание заголовков методов это не описание заголовка (прототипа) функции, выполняющей тело метода. Ниже приведен синтаксис заголовков методов Forw и Back на момент вызова:
Pascal:
Procedure Forw(InSignals, OutSignals, Parameters: PRealArray);
Procedure Back(InSignals, OutSignals, Parameters, Back.InSignals, Back.OutSignals, Back.Parameters: PRealArray);
C
void Forw(PRealArray InSignals, PRealArray OutSignals, PRealArray Parameters)
void Back(PRealArray InSignals, PRealArray OutSignals, PRealArray Parameters, PRealArray Back.InSignals, PRealArray Back.OutSignals, PRealArray Back.Parameters)
В методе Forw в левой части оператора присваивания могут фигурировать имена любых переменных и элементов предопределенного массива выходных сигналов (OutSignals). В выражении, стоящем в правой части оператора присваивания могут участвовать любые переменные, аргументы элемента и элементы предопределенных массивов входных сигналов (InSignals) и параметров (Parameters).
В методе Back в левой части оператора присваивания могут фигурировать имена любых переменных, элементов предопределенных массивов входных сигналов обратного функционирования (Back.InSignals) и параметров (Back.Parameters). В выражении, стоящем в правой части оператора присваивания, могут участвовать любые переменные, аргументы элемента и элементы предопределенных массивов входных (InSignals) и выходных (OutSignals) сигналов и параметров (Parameters). Отметим важную особенность вычисления поправок к параметрам. Поскольку один и тот же параметр может использоваться несколькими элементами, при вычислении поправки к параметру вычисленное значение нужно не присваивать соответствующему элементу массива Back.Parameters, а добавлять. При этом в теле метода элементы массива Back.Parameters не могут фигурировать в правой части оператора присваивания. Эта особенность вычисления поправок к параметрам обрабатывается компонентом сеть.
Описание элемента завершается ключевым словом End за которым следует имя элемента.
Пример описания элементов
NetBibl Elements; {Библиотека элементов}
Element Synaps {Обычный синапс}
InSignals 1 {Один входной сигнал}
OutSignals 1 {Один выходной сигнал}
Parameters 1 {Один параметр – вес связи}
Forw {Начало описания прямого функционирования}
Begin {Выходной сигнал – произведение входного сигнала на параметр}
OutSignals[1] = InSignals[1] * Parameters[1]
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Begin {Поправка к входному сигналу – произведение поправки к выходному сигналу на параметр}
Back.InSignals[1]= Back.OutSignals[1] * Parameters[1];
{Поправка к параметру – сумма ранее вычисленной поправки к параметру на произведение поправки к обратному сигналу на входной сигнал}
Back.Parameters[1]= Back.Parameters[1] + Back.OutSignals[1] * InSignals[1]
End {Конец описания обратного функционирования}
End Synaps {Конец описания синапса}
Element Branch(N : Long) {Точка ветвления на N выходных сигналов}
InSignals 1 {Один входной сигнал}
OutSignals N {N выходных сигналов}
Forw {Начало описания прямого функционирования}
Var Long I; {I – длинное целое – индекс}
Begin
For I=1 To N Do {На каждый из N выходных сигналов передаем}
OutSignals[I] = InSignals[1] {входной сигнал}
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var {Описание локальных переменных}
Long I; {I – длинное целое – индекс}
Real R; {R – действительное – для накопления суммы}
Begin
R = 0;
For I=1 To N Do {Поправка ко входному сигналу равна сумме}
R = R + Back.OutSignals[I]; {поправок выходных сигналов}
Back.InSignals[1] = R
End {Конец описания обратного функционирования}
End Branch {Конец описания точки ветвления}
Element Sum(N Long) {Простой сумматор на N входов}
InSignals N {N входных сигналов}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования}
Var {Описание локальных переменных}
Long I; {I – длинное целое – индекс}
Real R; {R – действительное – для накопления суммы}
Begin
R = 0;
For I=1 To N Do {Выходной сигнал равен сумме входных}
R = R + InSignals[I];
OutSignals[1] = R
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var Long I; {I – длинное целое – индекс}
Begin
For I=1 To N Do {Поправка к каждому входному сигналу равна}
Back.InSignals[I] = Back.OutSignals[1] {поправке выходного сигнала}
End {Конец описания обратного функционирования}
End Sum {Конец описания простого сумматора}
Element Mul {Умножитель}
InSignals 2 {Два входных сигнала}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования}
Begin
OutSignals[1] =InSignals[1] * InSignals[2] {Выходной сигнал равен произведению входных сигналов}
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Begin
{Поправка к каждому входному сигналу равна произведению поправки выходного сигнала на другой входной сигнал}
Back.InSignals[1] = Back.OutSignals[1] * InSignals[2];
Back.InSignals[2] = Back.OutSignals[1] * InSignals[1]
End {Конец описания обратного функционирования}
End Mul {Конец описания умножителя}
Element S_Train {Обучаемый гиперболический сигмоидный элемент}
InSignals 1 {Один входной сигнал}
OutSignals 1 {Один выходной сигнал}
Parameters 1 {Один параметр – характеристика}
Forw {Начало описания прямого функционирования}
Begin
{Выходной сигнал равен отношению входного сигнала к сумме параметра и абсолютной величины входного сигнала}
OutSignals[1] =InSignals[1] / (Parameters[1] +Abs(InSignals[1])
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var Real R; {R – действительное}
Begin
{R – вспомогательная величина для вычисления поправок, равная отношению поправки выходного сигнала к квадрату суммы параметра и абсолютной величины входного сигнала}
R= Back.OutSignals[1] / Sqr(Parameters[1] +Abs(InSignals[1]);
{Поправка к входному сигналу равна произведению вспомогательной величины на параметр}
Back.InSignals[1] = R *Parameters[1];
{Поправка к параметру равна сумме ранее вычисленной величины поправки и произведения вспомогательной величины на входной сигнал}
Back.Parameters[1] = Back.Parameters[1] + R * InSignals[1]
End {Конец описания обратного функционирования}
End S_Train {Конец описания обучаемого гиперболического сигмоидного элемента}
Element S_NotTrain(Char : Real) {Не обучаемый гиперболический сигмоидный элемент Char – характеристика}
InSignals 1 {Один входной сигнал}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования}
Begin
{Выходной сигнал равен отношению входного сигнала к сумме характеристики и абсолютной величины входного сигнала}
OutSignals[1] =InSignals[1] / (Char +Abs(InSignals[1])
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Begin
{Поправка к входному сигналу равна отношению произведения поправки выходного сигнала на характеристику к квадрату суммы характеристики и абсолютной величины входного сигнала}
Back.InSignals[1] =Back.OutSignals[1] * Char / Sqr(Char +Abs(InSignals[1]);
End {Конец описания обратного функционирования}
End S_NotTrain {Конец описания гиперболического сигмоидного элемента}
Element Pade(Char : Real) {Паде преобразователь Char – характеристика}
InSignals 2 {Два входных сигнала}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования}
Begin
{Выходной сигнал равен отношению первого входного сигнала к сумме характеристики и второго входного сигнала}
OutSignals[1] =InSignals[1] / (Char+InSignals[2])
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var Real R; {R – действительное}
Begin
{Вспомогательная величина равна поправке к первому входному сигналу – отношению поправки выходного сигнала к сумме характеристики и второго входного сигнала}
R= Back.OutSignals[1] / (Char+ InSignals[2]);
Back.InSignals[1] = R;
{Поправка ко второму входному сигналу равна минус отношению произведения первого входного сигнала на поправку выходного сигнала к квадрату суммы характеристики и второго входного сигнала}
Back.InSignals[2] = -R *OutSignals[1];
End {Конец описания обратного функционирования}
End Pade {Конец описания Паде преобразователя}
Element Sign_Mirror {Зеркальный пороговый элемент}
InSignals 1 {Один входной сигнал}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования }
Begin
If InSignals[1] > 0 Then OutSignals[1] =1 {Выходной сигнал равен 1, если входной сигнал}
Else OutSignals[1] =0 {больше нуля, и нулю в противном случае}
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Begin
Back.InSignals[1] = OutSignals[1]; {Поправка к входному сигналу равна выходному сигналу}
End {Конец описания обратного функционирования}
End Sign_Mirror {Конец описания зеркального порогового элемента}
Element Sign_Easy {Прозрачный пороговый элемент}
InSignals 1 {Один входной сигнал}
OutSignals 1 {Один выходной сигнал}
Forw {Начало описания прямого функционирования}
Begin
If InSignals[1] > 0 Then OutSignals[1] =1 {Выходной сигнал равен 1, если входной сигнал больше}
Else OutSignals[1] =0 {нуля, и нулю в противном случае}
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Begin
{Поправка к входному сигналу равна поправке к выходному сигналу}
Back.InSignals[1] = Back.OutSignals[1];
End {Конец описания обратного функционирования}
End Sign_Easy {Конец описания прозрачного порогового элемента}
Element Adaptiv_Sum(N: Long) {Адаптивный сумматор на N входов}
InSignals N {N входных сигналов}
OutSignals 1 {Один выходной сигнал}
Parameters N {N параметров – весов связей}
Forw {Начало описания прямого функционирования}
Var {Описание локальных переменных}
Long I; {I – длинное целое – индекс}
Real R; {R – действительное – для накопления суммы}
Begin
R = 0; {Выходной сигнал равен скалярному}
For I=1 To N Do {произведению массива входных сигналов}
R = R + InSignals[I] * Parameters[I]; {на массив параметров}
OutSignals[1] = R
End {Конец описания обратного функционирования}
Back {Начало описания обратного функционирования}
Var Long I; {I – длинное целое – индекс}
Begin
For I=1 To N Do Begin
{Поправка к I-у входному сигналу равна сумме ранее вычисленной поправки и произведения поправки выходного сигнала на I-й параметр}
Back.InSignals[I] = Back.OutSignals[1] * Parameters[I];
{Поправка к I-у параметру равна произведению поправки выходного сигнала на I-й входной сигнал}
Back. Parameters[I] = Back. Parameters[I] + Back.OutSignals[1] * InSignals[I]
End
End {Конец описания обратного функционирования}
End Adaptiv_Sum {Конец описания адаптивного сумматора}
Element Adaptiv_Sum_Plus(N: Long) {Адаптивный неоднородный сумматор на N входов}
InSignals N {N входных сигналов}
OutSignals 1 {Один выходной сигнал}
Parameters N+1 {N+1 параметр – веса связей}
Forw {Начало описания прямого функционирования}
Var {Описание локальных переменных}
Long I; {I – длинное целое – индекс}
Real R; {R – действительное – для накопления суммы}
Begin
R = Parameters[N+1]; {Выходной сигнал равен сумме N+1 параметра}
For I=1 To N Do {и скалярного произведения массива входных}
R = R + InSignals[I] * Parameters[I]; {сигналов на массив параметров}
OutSignals[1] = R
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var Long I; {I – длинное целое – индекс}
Begin
For I=1 To N Do Begin
{Поправка к I-у входному сигналу равна произведению поправки выходного сигнала на I-й параметр}
Back.InSignals[I] = Back.OutSignals[1] * Parameters[I];
{Поправка к I-у параметру равна сумме ранее вычисленной поправки и произведения поправки выходного сигнала на I-й входной сигнал}
Back. Parameters[I] = Back. Parameters[I] + Back.OutSignals[1] * InSignals[I]
End;
{Поправка к (N+1)-у параметру равна сумме ранее вычисленной поправки и попраки к выходному сигналу}
Back.Parameters[N+1] = Back.Parameters[N+1] + Back.OutSignals[1]
End {Конец описания обратного функционирования}
End Adaptiv_Sum_Plus {Конец описания неоднородного адаптивного сумматора}
Element Square_Sum(N: Long) {Квадратичный сумматор на N входов}
InSignals N {N входных сигналов}
OutSignals 1 {Один выходной сигнал}
Parameters (Sqr(N) + N) Div 2 {N(N+1)/2 параметров – весов связей}
Forw {Начало описания прямого функционирования}
Var {Описание локальных переменных}
Long I,J,K; {I,J,K – переменные типа длинное целое }
Real R; {R – действительное – для накопления суммы}
Begin
K = 1; {K – номер обрабатываемого параметра}
R = 0;
For I = 1 To N Do {I,J – номера входных сигналов}
For J = I To N Do Begin
R = R + InSignals[I] * InSignals[J] * Parameters[K];
K = K + 1
End;
{Выходной сигнал равен сумме всех попарных произведений входных сигналов, умноженных на соответствующие параметры}
OutSignals[1] = R
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования }
Var {Описание локальных переменных}
Long I, J, K; {I,J,K – переменные типа длинное целое }
Real R; {R – действительное}
Vector W; {Массив для накопления промежуточных величин}
Begin
For I = 1 To N Do W[I] = 0;
K = 1; {K – номер обрабатываемого параметра}
For I = 1 To N Do
For J = I To N Do Begin
{Поправка к параметру равна сумме ранее вычисленной поправки и произведения поправки к входному сигналу на произведение сигналов, прошедших через этот параметр при прямом функционировании}
Back.Parameters[K] = Back.Parameters[K] + Back.OutSignals[1] * InSignals[I] *InSignals[J];
R = Back.OutSignals[1] * Parameters[K];
W[I] = W[I] + R * InSignals[J];
W[J] = W[J] + R * InSignals[I];
K = K + 1
End;
For I = 1 To N Do
{Поправка к входному сигналу равна произведению поправки к выходному сигналу на сумму всех параметров, через которые этот сигнал проходил при прямом функционировании, умноженных на другие входные сигналы, так же прошедшие через эти параметры при прямом функционировании}
Back.InSignals[1] = W[I]
End {Конец описания прямого функционирования}
End Square_Sum {Конец описания квадратичного сумматора}
Element Square_Sum_Plus(N: Long) {Неоднородный квадратичный сумматор на N входов}
InSignals N {N входных сигналов}
OutSignals 1 {Один выходной сигнал}
Parameters (Sqr(N) + 3 * N) Div 2 + 1 {N(N+3)/2+1 весов связей}
Forw {Начало описания прямого функционирования}
Var {Описание локальных переменных}
Long I, J, K; {I,J,K – переменные типа длинное целое }
Real R; {R – действительное – для накопления суммы}
Begin
K = 2 * N+1; {K – номер обрабатываемого параметра}
R = Parameters[Sqr(N) + 3 * N) Div 2 + 1];
For I = 1 To N Do Begin
R = R + InSignals[I] * Parameters[I] + Sqr(InSignals[I]) * Parameters[N + I];
For J = I + 1 To N Do Begin
R = R + InSignals[I] * InSignals[J] * Parameters[K];
K = K + 1
End
End
{Выходной сигнал равен сумме всех попарных произведений входных сигналов, умноженных на соответствующие параметры, плюс сумме всех входных сигналов умноженных на соответствующие параметры, плюс последний параметр}
OutSignals[1] = R
End {Конец описания прямого функционирования}
Back {Начало описания обратного функционирования}
Var {Описание локальных переменных}
Long I, J, K; {I,J,K – переменные типа длинное целое}
Real R; {R – действительное – для накопления суммы}
Vector W; {Массив для накопления промежуточных величин}
Begin
For I = 1 To N Do W[I] = 0;
K = 2 * N + 1; {K – номер обрабатываемого параметра}
For I = 1 To N Do Begin
Back.Parameters[I] = Back.Parameters[I] + Back.OutSignals[1] * InSignals[I];
Back.Parameters[N + I] = Back.Parameters[N + I] + Back.OutSignals[1] * Sqr(InSignals[I]);
W[I] = W[I] + Back.OutSignals[1] * (Parameters[I] + 2 * Parameters[N + I] * InSignals[I])
For J = I + 1 To N Do Begin
Back.Parameters[K] = Back.Parameters[K] + Back.OutSignals[1] * InSignals[I] *InSignals[J];
R = Back.OutSignals[1] * Parameters[K];
W[I] = W[I] + R * InSignals[J];
W[J] = W[J] + R * InSignals[I];
K = K + 1
End
End;
For I = 1 To N Do Back.InSignals[1] = W[I]
End {Конец описания обратного функционирования}
End Square_Sum_Plus {Конец описания адаптивного квадратичного сумматора}
End NetBibl
Описание блоков
Описание блока состоит из пяти основных разделов: заголовка описания блока, описания сигналов и параметров, описания состава, описания связей и конца описания блока. Существует два типа блоков — каскад и слой (Layer). Различие между этими двумя типами блоков состоит в том, что подсети, входящие в состав слоя, функционируют параллельно и независимо друг от друга, тогда как составляющие каскад подсети функционируют последовательно, причем каждая следующая подсеть использует результаты работы предыдущих подсетей. В свою очередь существует три вида каскадов — простой каскад (Cascad), цикл с фиксированным числом шагов (Loop) цикл по условию (Until). Различие между тремя видами каскадов очевидно — простой каскад функционирует один раз, цикл Loop функционирует указанное в описании число раз, а цикл Until функционирует до тех пор, пока не выполнится указанное в описании условие. В условии, указываемом в заголовке цикла Until, возможно использование сравнений массивов или интервалов массивов сигналов. Например, запись
InSignals=OutSignals
эквивалентна следующей записи
InSignals[1..N]=OutSignals[1..N]
которая эквивалентна вычислению следующей логической функции:
Function Equal(InSignals, OutSignals: RealArray): Logic;
Var
Long I;
Logic L
Begin
L = True
For i = 1 To n Do L = L And (InSignals[I] = OutSignals[I]);
Equal = L
End
Раздел описания состава следует сразу после заголовка блока за разделом описания сигналов и параметров и начинается с ключевого слова Contents, за которым следуют имена подсетей (блоков или элементов) со списками фактических аргументов, разделенные запятыми. Все имена подсетей должны предваряться псевдонимами. В дальнейшем указание псевдонима полностью эквивалентно указанию имени подсети со списком фактических аргументов или без, в зависимости от контекста. Признаком конца раздела описания состава подсети служит имя подсети за списком фактических аргументов которого не следует запятая.
Раздел описания сигналов и параметров следует за разделом описания состава и состоит из указания числа входных и выходных сигналов и числа параметров блока. В константных выражениях, указывающих число входных и выходных сигналов и параметров можно использовать дополнительно функцию NumberOf с двумя параметрами. Первым параметром является одно из ключевых слов InSignals, OutSignals, Parameters, а вторым — имя подсети со списком фактических аргументов. Функция NumberOf возвращает число входных или выходных сигналов или параметров (в зависимости от первого аргумента) в подсети, указанной во втором аргументе. Использование этой функции необходимо в случае использования блоком аргументов-подсетей. Концом раздела описания сигналов и параметров служит одно из ключевых слов ParamDef, Static или Connections.
Раздел определения типов параметров является необязательным разделом в описании блока и начинается с ключевого слова ParamDef. В каждой строке этого раздела можно задать минимальную и максимальную границы изменения одного типа параметров. Если в описании сети встречаются параметры неопределенного типа, то этот тип считается совпадающим с типом DefaultType. Описание типа не обязано предшествовать описанию параметров этого типа. Так, например, определение типа параметров может находиться в описании главной сети. Концом этого раздела служит одно из ключевых слов Connections.
Раздел описания связей следует за разделом описания сигналов и параметров и начинается с ключевого слова Connections. В разделе «Описание распределения сигналов» детально описано распределение связей.
Раздел конца описания блока состоит из ключевого слова End, за которым следует имя блока.
Пример описания блоков
При описании блоков используются элементы, описанные в библиотеке Elements, приведенной в разделе «Пример описания элементов».
NetBibl SubNets Used Elements;
{Библиотека подсетей, использующая библиотеку Elements}
{Сигмоидный нейрон с произвольным сумматором на N входов}
Cascad NSigm(aSum : Block; N : Long; Char : Real)
{В состав каскада входит произвольный сумматор на N входов и сигмоидный нейрон с необучаемой характеристикой}
Contents aSum(N), S_NotTrain(Char)
InSignals NumberOf(InSignals, aSum(N)) {Число входных сигналов определяет сумматор}
OutSignals 1 {Один выходной сигнал}
Parameters NumberOf(Parameters, aSum(N)) {Число параметров определяет сумматор}
Connections
{Входные сигналы каскада – входные сигналы сумматора}
InSignals[1..NumberOf(InSignals, aSum(N))] <=> aSum.InSignals[1..NumberOf(InSignals, aSum(N))]
{Выход сумматроа – вход нелинейного преобразователя}
aSum.OutSignals <=> S_NotTrain.InSignals
{Выход преобразователя – выход каскада}
OutSignals <=> S_NotTrain.OutSignals
Parameters[1..NumberOf(Parameters, aSum(N))] <=> aSum.Parameters[1..NumberOf(Parameters, aSum(N))]
End {Конец описания сигмоидного нейрона с произвольным сумматором}
{Слой сигмоидных нейронов с произвольными сумматорами на N входов}
Layer Lay1(aSum : Block; N,M : Long; Char : Real)
Contents Sigm: NSigm(aSum,N,Char)[M] {В состав слоя входит M нейронов}
InSignals M * NumberOf(InSignals, Sigm)
{Число входных сигналов определяется как взятое M раз число входных сигналов нейронов. Вместо имени нейрона используем псевдоним}
OutSignals M {Один выходной сигнал на нейрон}
Parameters M * NumberOf(Parameters, Sigm)
{Число параметров определяется как взятое M раз число параметров нейронов}
Connections
{Первые NumberOf(InSignals, NSigm(aSum,N,Char)) сигналов первому нейрону, и т.д.}
InSignals[1..M *NumberOf(InSignals, Sigm)] <=> Sigm[1..M].InSignals[1..NumberOf(InSignals, Sigm)]
{Выходные сигналы нейронов - выходные сигналы сети}
OutSignals[1..M]<=> Sigm[1..M].OutSignals
{Параметры слоя – параметры нейронов}
Parameters[1..M *NumberOf(Parameters, Sigm)] <=> Sigm[1..M].Parameters[1..NumberOf(Parameters, Sigm)]
End {Конец описания слоя сигмоидных нейронов с произвольным сумматором}
{Слой точек ветвления}
Layer BLay(N,M : Long)
Contents Branch(N)[M] {В состав слоя входит M точек ветвления}
InSignals M {По одному входному сигналу на точку ветвления}
OutSignals M * N {N выходных сигналов у каждой точки ветвления}
Connections
InSignals[1..M] <=> Branch[1..M].InSignals {По одному входу на точку ветвления}
{Выходные сигналы в порядке первый с каждой точки ветвления, затем второй и т.д. }
OutSignals[1..N * M]<=> Branch[+:1..M].OutSignals[1..N]
End {Конец описания слоя Точек ветвления}
{Полный слой сигмоидных нейронов с произвольными сумматорами на N входов}
Cascad FullLay(aSum : Block; N,M : Long; Char : Real)
Contents Br: BLay1(M,N), Ne: Lay1(aSum,N,M,Char) {Слой точек ветвления и слой нейронов}
InSignals N {Число входных сигналов – число точек ветвления}
OutSignals M {Один выходной сигнал на нейрон}
Parameters NumberOf(Parameters, Ne)
{Число параметров определяется как взятое M раз число параметров нейронов}
Connections
{Входные сигналы – слою точек ветвления}
InSignals[1..N]<=> Br.InSignals[1..N]
{Выходные сигналы нейронов - выходные сигналы сети}
OutSignals[1..M]<=> Ne.OutSignals[1..M]
{Параметры слоя – параметры нейронов}
Parameters[1..NumberOf(Parameters, Ne)] <=> Ne.Parameters[1..NumberOf(Parameters, Ne)]
{Выход слоя точек ветвления – вход слоя нейронов}
Br.OutSignals[1..N * M] <=> Ne.InSignals[1..N * M]
End {Конец описания слоя сигмоидных нейронов с произвольным сумматором}
{Сеть с сигмоидными нейронами и произвольными сумматорами, содержащая
Input – число нейронов на входном слое;
Output – число нейронов на выходном слое (число выходных сигналов);
Hidden – число нейронов на H>0 скрытых слоях;
N – число входных сигналов
все входные сигналы подаются на все нейроны входного слоя}
Cascad Net1(aSum : Block; Char : Real; Input, Output, Hidden, H, N : Long)
{Под тремя разными псевдонимами используется одна и та же подсеть с разными параметрами}
Contents
In: FullLay(aSum,N,Input,Char),
Hid1: FullLay(aSum,Input,Hidden,Char)
Hid2: FullLay(aSum,Hidden,Hidden,Char)[H-1] {Пусто при H=1}
Out: FullLay(aSum,Hidden,Output,Char)
InSignals N {Число входных сигналов – N}
OutSignals Output {Один выходной сигнал на нейрон}
{Число параметров определяется как сумма чисел параметров всех подсетей}
Parameters NumberOf(Parameters, In)+NumberOf(Parameters, Hid1) + (H-1)*NumberOf(Parameters, Hid2) + NumberOf(Parameters, Out)
Connections
{Входные сигналы – входному слою}
InSignals[1..N]<=> In.InSignals[1..N]
{Выходные сигналы нейронов - с выходного слоя сети}
OutSignals[1..Output]<=> Out.OutSignals[1.. Output]
{Параметры сети последовательно всем подсетям}
Parameters[1..NumberOf(Parameters,In)] <=> In.Parameters[1..NumberOf(Parameters, In)]
Parameters[NumberOf(Parameters,In)+1..NumberOf(Parameters,In) +> NumberOf(Parameters, Hid1)] <=> Hid1.Parameters[1..NumberOf(Parameters, Hid1)]
Parameters[NumberOf(Parameters,In)+NumberOf(Parameters, Hid1)]+1 .. NumberOf(Parameters,In)+NumberOf(Parameters, Hid1) + (H-1) *NumberOf(Parameters, Hid2)] <=> Hid2[1..H-1].Parameters[1..NumberOf(Parameters, Hid2)]
Parameters[NumberOf(Parameters,In)+NumberOf(Parameters, Hid1)] + (H-1) *NumberOf(Parameters, Hid2)+1 .. NumberOf(Parameters,In) + NumberOf(Parameters,Hid1)+(H-1)*NumberOf(Parameters,Hid2) + NumberOf(Parameters, Out)] <=> Out.Parameters[1..NumberOf(Parameters, Out)]
{Передача сигналов от слоя к слою}
{От входного к первому скрытому слою}
In.OutSignals[1..Input] <=> Hid1.InSignals[1..Input]
{От первого скрытого слоя}
Hid1.OutSignals[1..Hidden] <=> Hid2[1].InSignals[1..Hidden]
{Между скрытыми слоями. При H=1 эта запись пуста}
Hid2[1..H-2].OutSignals[1.. Hidden] <=> Hid2[2..H-1].InSignals[1.. Hidden]
{От скрытых – к выходному}
Hid2[H-1].OutSignals[1.. Hidden] <=> Out.InSignals[1.. Hidden]
End
{Полносвязная сеть с M сигмоидными нейронами на К тактов функционирования с невыделенным входным слоем на M сигналов}
Loop Circle(aSum : Block; Char : Real; M, K : Long) K
Contents Net: FullLay(aSum,M,M,Char)
InSignals M {Число входных сигналов – N}
OutSignals M {Один выходной сигнал на нейрон}
Parameters NumberOf(Parameters, Net) {Число параметров определяется слоем FullLay}
Connections
InSignals[1..M] <=> Net.InSignals[1..M] {Входные сигналы цикла – входы слоя}
OutSignals[1..M] <=> Net.OutSignals[1.. M] {Выходы слоя – выходы цикла}
{Параметры определяет слой}
Parameters[1..NumberOf(Parameters,Net)] <=> Net.Parameters[1..NumberOf(Parameters,Net)]
Net.OutSignals[1..M] <=> Net.InSignals[1..M] {Замыкаем выход на вход}
End {Конец описания слоя сигмоидных нейронов с произвольным сумматором}
{Полносвязная сеть с М сигмоидными нейронами на К тактов функционирования с выделенным входным слоем на N сигналов. Все входные сигналы подаются на вход каждого нейрона входного слоя. Все параметры ограничены по абсолютному значению единицей}
Cascad Net2: (aSum : Block; Char : Real; M, K, N : Long)
Contents
In: FullLay(aSum,N,M,Char), {Входной слой}
Net: Circle(aSum,Char,M,K) {Полносвязная сеть}
InSignals N {Число входных сигналов – N}
OutSignals M {Один выходной сигнал на нейрон}
{Число параметров определяется как сумма чисел параметров всех подсетей}
Parameters NumberOf(Parameters, In)+NumberOf(Parameters, Net)
ParamDef DefaultType -1 1
Connections
InSignals[1..N]<=> In.InSignals[1..N] {Входные сигналы – входному слою}
{Выходные сигналы нейронов - с выходного слоя сети}
OutSignals[1..M]<=> Net.OutSignals[1.. M]
{Параметры сети последовательно всем подсетям}
Parameters[1..NumberOf(Parameters, In)] <=> In.Parameters[1..NumberOf(Parameters, In)]
Parameters[NumberOf(Parameters,In)+1..NumberOf(Parameters,In)+NumberOf(Parameters, Net)] <=> Net.Parameters[1..NumberOf(Parameters, Net)]
{Передача сигналов от слоя к слою}
In.OutSignals[1..M] <=> Net.InSignals[1..M] {От входного к циклу}
Net.OutSignals[1..M] <=> Net.InSignals[1..M] {От первого скрытого слоя}
End
{Нейрон сети Хопфилда из N нейронов}
Cascad Hopf(N : Long)
Contents Sum(N),Sign_Easy {Сумматор и пороговый элемент}
InSignals N {Число входных сигналов – N}
OutSignals 1 {Число выходных сигналов – 1}
Parameters NumberOf(Parameters,Sum(N)) {Число параметров – N}
Connections
InSignals[1..N] <=> Sum.InSignals[1..N] {Входы нейрона – входы сумматора}
{Выходной сигнал нейрона – выходной сигнал порогового элемета}
OutSignals <=> Sign_Easy.OutSignals
{Параметры нейрона – парамеры сумматора}
Parameters[1..NumberOf(Parameters, Sum(N))] <=> Sum.Parameters[1..NumberOf(Parameters, Sum(N))]
{Выход сумматора на вход порогового элемента}
Sum.OutSignals <=> Sign_Easy.InSignals
End
{Слой нейронов Хопфилда}
Layer HLay(N : Long)
Contents Hop: Hopf(N)[N] {В состав слоя входит N нейронов}
InSignals N * N {N нейронов по N входных сигналов}
OutSignals N {Один выходной сигнал на нейрон}
Parameters N * NumberOf(Parameters, Hop)
Connections
{NumberOf(InSignals, Hop) сигналов первому нейрону, и т.д.}
InSignals[1..Sqr(N)] <=> Hop[1..N].InSignals[1..N]
{Выходные сигналы нейронов - выходные сигналы сети}
OutSignals[1..N]<=> Hop[1..N].OutSignals
{Параметы слоя – параметры нейронов}
Parameters[1..N *NumberOf(Parameters, Hop)] <=> Hop[1..N].Parameters[1..NumberOf(Parameters, Hop)]
End
{Сеть Хопфилда из N нейронов}
Until Hopfield(N : Long) InSignals=OutSignals
Contents BLay(N,N),HLay(N) {Слой точек ветвления и слой нейронов}
InSignals N {Число входных сигналов – N}
OutSignals N {Число выходных сигналов – N}
Parameters N * NumberOf(Parameters,HLay(N)) {Число параметров – N*N}
Connections
{Входные сигналы – точкам ветвления}
InSignals[1..N]<=> BLay.InSignals[1..N]
{Выходные сигналы нейронов – выходные сигналы сети}
OutSignals[1..N]<=> HLay.OutSignals[1..N]
Parameters[1..N*NumberOf(Parameters, HLay(N))] <=> HLay.Parameters[1..N*NumberOf(Parameters, HLay(N))]
{Выход точек ветвления на вход нейронов}
BLay.OutSignals[1..Sqr(N)] <=> HLay.InSignals[1..Sqr(N)]
{Замыкаем конец на начало}
HLay.OutSignals[1..N] <=> BLay.InSignals[1..N]
End
End NetLib
NetWork HopUsed SubNets; {Сеть Хопфилда на пять нейронов}
MainNet Hopfield(5)
Parameters 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
ParamMask -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1;
End NetWork
Сокращение описания сети
Предложенный в предыдущих разделах язык описания многословен. В большинстве случаев за счет хорошей структуризации сети можно опустить все разделы описания блока кроме раздела состава. В данном разделе описывается генерация по умолчанию разделов описания сигналов и параметров, и описания связей. Использование механизмов умолчания позволяет сильно сократить текст описания сети.
Раздел описания сигналов и параметров
Для всех видов блоков число параметров определяется как сумма чисел параметров всех подсетей, перечисленных в разделе описания состава. Это может приводить к лишним записям, но не повлияет на работу сети. Примером лишней записи может служить генерируемая запись:
Parameters M * NumberOf(Parameters,Branch(N))
в описании слоя точек ветвления, поскольку точки ветвления не имеют параметров.
Число входных сигналов блока определяется по следующим правилам:
• для слоя число входных сигналов равно сумме числа входных сигналов всех подсетей, перечисленных в разделе описания состава;
• для каскадов всех видов число входных сигналов блока равно числу входных сигналов подсети, стоящей первой в списке подсетей в разделе описания состава.
Число выходных сигналов блока определяется по следующим правилам:
• для слоя число выходных сигналов равно сумме числа выходных сигналов всех подсетей, перечисленных в разделе описания состава;
• для каскадов всех видов число выходных сигналов блока равно числу выходных сигналов подсети, стоящей последней в списке подсетей в разделе описания состава;
Описания всех сетей, приведенные в предыдущем разделе полностью соответствуют правилам генерации. В качестве более общего примера приведем раздел описания сигналов и параметров двух условных блоков.
Layer A
Contents Net1, Net2[K], Net3
InSignals NumberOf(InSignals,Net1)+K*NumberOf(InSignals,Net2) + NumberOf(InSignals,Net3)
OutSignals NumberOf(OutSignals,Net1)+K*NumberOf(OutSignals,Net2) + NumberOf(OutSignals,Net3)
Parameters NumberOf(Parameters,Net1) + K*NumberOf(Parameters,Net2)+NumberOf(Parameters,Net3)
Cascad B
Contents Net1, Net2[K], Net3
InSignals NumberOf(InSignals,Net1)
OutSignals NumberOf(OutSignals,Net3)
Parameters NumberOf(Parameters,Net1) + K*NumberOf(Parameters,Net2)+NumberOf(Parameters,Net3)
Раздел описания связей
Раздел описания связей может быть разбит на пять подразделов.
1. Установление связи входных сигналов блока с входными сигналами подсетей.
2. Установление связи выходных сигналов блока с выходными сигналами подсетей.
3. Установление связи параметров блока с параметрами подсетей.
4. Установление связи между выходными сигналами одних подсетей и входными сигналами других подсетей.
5. Замыкание выхода блока на вход блока.
Для слоя раздел описания связей строится по следующим правилам.
1. Все подсети получают входные сигналы в порядке перечисления подсетей в разделе описания состава — первая часть массива входных сигналов слоя отдается первой подсети, следующая — второй и т. д. Если какая-либо подсеть в разделе описания состава указана с некоторым не равным единице числом экземпляров, то считается, что экземпляры этой подсети перечислены в списке в порядке возрастания номера.
2. Выходные сигналы подсетей образуют массив выходных сигналов слоя также в порядке перечисления подсетей в разделе описания состава — первая часть массива выходных сигналов слоя состоит из выходных сигналов первой подсети, следующая — второй и т. д. Если какая-либо подсеть в разделе описания состава указана с некоторым не равным единице числом экземпляров, то считается, что экземпляры этой подсети перечислены в списке в порядке возрастания номера.
3. Подразделы установления связи между выходными сигналами одних подсетей и входными сигналами других подсетей и замыкания выхода блока на вход для слоя отсутствуют.
Для каскадов раздел описания связей строится по следующим правилам:
1. Входные сигналы блока связываются с входными сигналами первой подсети в списке подсетей в разделе описания состава. Если для первой подсети указано не единичное число экземпляров, то все входные сигналы связываются с входными сигналами первого экземпляра подсети.
2. Выходные сигналы блока связываются с выходными сигналами последней подсети в списке подсетей в разделе описания состава. Если для последней подсети указано не единичное число экземпляров, то все выходные сигналы связываются с выходными сигналами последнего (с максимальным номером) экземпляра подсети.
3. Массив параметров блока образуется из массивов параметров подсетей в порядке перечисления подсетей в разделе описания состава — первая часть массива параметров блока состоит из параметров первой подсети, следующая — второй и т. д. Если какая-либо подсеть в разделе описания состава указана с некоторым не равным единице числом экземпляров, то считается, что экземпляры этой подсети перечислены в списке в порядке возрастания номера.
4. Выходные сигналы каждой подсети, кроме последней связываются с входными сигналами следующей подсети в списке подсетей в разделе описания состава. Если какая-либо подсеть в разделе описания состава указана с некоторым не равным единице числом экземпляров, то считается, что экземпляры этой подсети перечислены в списке в порядке возрастания номера.
5. Для блоков типа Cascad замыкание выхода блока на вход блока отсутствует. Для блоков типов Loop и Until замыкание выхода блока на вход блока достигается путем установления связей между выходными сигналами последней подсети в списке подсетей в разделе описания состава с входными сигналами первой подсети в списке подсетей в разделе описания состава. Если какая-либо подсеть в разделе описания состава указана с некоторым не равным единице числом экземпляров, то считается, что экземпляры этой подсети перечислены в списке в порядке возрастания номера.
Описания всех сетей, приведенные в предыдущем разделе полностью соответствуют правилам генерации. В качестве более общего примера приведем раздел описания сигналов и параметров трех условных блоков.
Layer A
Contents Net1, Net2[K], Net3
InSignals[1..NumberOf(InSignals,Net1)+K*NumberOf(InSignals,Net2)+NumberOf(InSignals,Net3)] <=> Net1.InSignals[1..NumberOf(InSignals,Net1)],
Net2[1..K].InSignals[1..NumberOf(InSignals,Net2)],Net3.InSignals[1..NumberOf(InSignals,Net3)]
OutSignals[1..NumberOf(OutSignals,Net1) + K*NumberOf(OutSignals,Net2)+NumberOf(OutSignals,Net3)] <=> Net1.OutSignals[1..NumberOf(OutSignals,Net1)],
Net2[1..K].OutSignals[1..NumberOf(OutSignals,Net2)],
Net3.OutSignals[1..NumberOf(OutSignals,Net3)]
Parameters[1..NumberOf(Parameters,Net1) + K*NumberOf(Parameters,Net2)+NumberOf(Parameters,Net3)] <=> Net1.Parameters[1..NumberOf(Parameters,Net1)],
Net2[1..K].Parameters[1..NumberOf(Parameters,Net2)],
Net3.Parameters[1..NumberOf(Parameters,Net3)]
Cascad B
Contents Net1, Net2[K], Net3
InSignals[1..NumberOf(InSignals,Net1)] <=> Net1. InSignals[1..NumberOf(InSignals,Net1)]
OutSignals[1..NumberOf(OutSignals,Net3)] <=> Net3.OutSignals[1..NumberOf(OutSignals,Net3)]
Parameters[1..NumberOf(Parameters,Net1) + K*NumberOf(Parameters,Net2)+NumberOf(Parameters,Net3)] <=> Net1.Parameters[1..NumberOf(Parameters,Net1)],
Net2[1..K].Parameters[1..NumberOf(Parameters,Net2)],
Net[3].Parameters[1..NumberOf(Parameters,Net3)]
Net1. OutSignals[1..NumberOf(OutSignals,Net1)],
Net2[1..K].OutSignals[1..NumberOf(OutSignals,Net2)] <=> Net2[1..K].InSignals[1..NumberOf(InSignals,Net2)],Net3.InSignals[1..NumberOf(InSignals,Net3)]
Loop C N
Contents Net1, Net2[K], Net3
InSignals[1..NumberOf(InSignals,Net1)] <=> Net1. InSignals[1..NumberOf(InSignals,Net1)]
OutSignals[1..NumberOf(OutSignals,Net3)] <=> Net3.OutSignals[1..NumberOf(OutSignals,Net3)]
Parameters[1..NumberOf(Parameters,Net1) + K*NumberOf(Parameters,Net2)+NumberOf(Parameters,Net3)] <=> Net1.Parameters[1..NumberOf(Parameters,Net1)],
Net2[1..K].Parameters[1..NumberOf(Parameters,Net2)],
Net[3].Parameters[1..NumberOf(Parameters,Net3)]
Net1.OutSignals[1..NumberOf(OutSignals,Net1)],
Net2[1..K].OutSignals[1..NumberOf(OutSignals,Net2)] <=> Net2[1..K].InSignals[1..NumberOf(InSignals,Net2)],
Net3.InSignals[1..NumberOf(InSignals,Net3)]
Net3.OutSignals[1..NumberOf(OutSignals,Net3)] <=> Net1.InSignals[1..NumberOf(InSignals,Net1)]
Частично сокращенное описание
Если описываемый блок должен иметь связи, устанавливаемые не так, как описано в разделе «Раздел описания связей», то соответствующий раздел описания блока может быть описан явно полностью или частично. Если какой либо раздел описан частично, то действует следующее правило: те сигналы, параметры и их связи, которые описаны явно, берутся из явного описания, а те сигналы, параметры и их связи, которые не фигурируют в явном описании берутся из описания по умолчанию. Так, в приведенном в разделе «Пример описания блоков» описании слоя точек ветвления BLay невозможно использование генерируемого по умолчанию подраздела установления связи выходных сигналов блока с входными сигналами подсетей. Возможно следующее сокращенное описание.
{Слой точек ветвления}
Layer BLay(N,M : Long)
Contents Branch(N)[M] {В состав слоя входит M точек ветвления}
Connections
{Выходные сигналы в порядке первый с каждой точки ветвления, затем второй и т.д. }
OutSignals[1..N * M]<=> Branch[+:1..M].OutSignals[1..N]
End {Конец описания слоя Точек ветвления}
Пример сокращенного описания блоков
При описании блоков используются элементы, описанные в библиотеке Elements, приведенной в разд. «Пример описания элементов».
NetBibl SubNets Used Elements; {Библиотека подсетей, использующая библиотеку Elements}
{Сигмоидный нейрон с произвольным сумматором на N входов}
Cascad NSigm(aSum : Block; N : Long; Char : Real)
{В состав каскада входит произвольный сумматор на N входов и сигмоидный нейрон с необучаемой характеристикой}
Contents aSum(N), S_NotTrain(Char)
End
{Слой сигмоидных нейронов с произвольными сумматорами на N входов}
Layer Lay1(aSum : Block; N,M : Long; Char : Real)
Contents Sigm: NSigm(aSum,N,Char)[M] {В состав слоя входит M нейронов}
End
{Слой точек ветвления}
Layer BLay(N,M : Long)
Contents Branch(N)[M] {В состав слоя входит M точек ветвления}
Connections
{Выходные сигналы в порядке первый с каждой точки ветвления, затем второй и т.д.}
OutSignals[1..N * M] <=> Branch[+:1..M].OutSignals[1..N]
End
{Полный слой сигмоидных нейронов с произвольными сумматорами на N входов}
Cascad FullLay(aSum : Block; N,M : Long; Char : Real)
Contents BLay1(M,N), Lay1(aSum,N,M,Char) {Слой точек ветвления и слой нейронов}
End {Конец описания слоя сигмоидных нейронов с произвольным сумматором}
{Сеть с сигмоидными нейронами и произвольными сумматорами, содержащая
Input – число нейронов на входном слое;
Output – число нейронов на выходном слое (число выходных сигналов);
Hidden – число нейронов на H>0 скрытых слоях;
N – число входных сигналов
все входные сигналы подаются на все нейроны входного слоя}
Cascad Net1(aSum : Block; Char : Real; Input, Output, Hidden, H, N : Long)
{Под тремя разными псевдонимами используется одна и таже подсеть с разными параметрами. Использование псевдонимов необходимо даже при сокращенном описании}
Contents
In: FullLay(aSum,N,Input,Char),
Hid1: FullLay(aSum,Input,Hidden,Char)
Hid2: FullLay(aSum,Hidden,Hidden,Char)[H-1] {Пусто при H=1}
Out: FullLay(aSum,Hidden,Output,Char)
End
{Полносвязная сеть с M сигмоидными нейронами на К тактов функционирования с невыделенным входным слоем на M сигналов. Все параметры ограничены по абсолютному значению единицей}
Loop Circle(aSum : Block; Char : Real; M, K : Long) K
Contents
FullLay(aSum,M,M,Char)
ParamDef DefaultType -1 1
End
{Полносвязная сеть с М сигмоидными нейронами на К тактов функционирования с выделенным входным слоем на N сигналов.
Cascad Net2: (aSum : Block; Char : Real; M, K, N : Long)
Contents
In: FullLay(aSum,N,M,Char), {Входной слой}
Net: Circle(aSum,Char,M,K) {Полносвязная сеть}
End
Cascad Hopf(N : Long) {Нейрон сети Хопфилда из N нейронов}
Contents Sum(N),Sign_Easy {Сумматор и пороговый элемент}
End
{Слой нейронов Хопфилда}
Layer HLay(N : Long)
Contents Hop: Hopf(N)[N] {В состав слоя входит N нейронов}
End
{Сеть Хопфилда из N нейронов}
Until Hopfield(N : Long) InSignals=OutSignals
Contents BLay(N,N),HLay(N) {Слой точек ветвления и слой нейронов}
End
End NetLib
Стандарт второго уровня компонента сеть
В данном разделе рассмотрены все запросы, исполняемые компонентом сеть. Прежде чем приступать к описанию стандарта запросов компонента сеть следует выделить выполняемые им функции. Что должен делать компонент сеть? Очевидно, что прежде всего он должен уметь выполнять такие функции, как функционирование вперед (работа обученной сети) и назад (вычисление вектора поправок или градиента для обучения), модернизацию параметров (обучение сети) и входных сигналов (обучение примера). Кроме того компонент сеть должен уметь читать сеть с диска и записывать ее на диск. Необходимо так же предусмотреть возможность создавать сеть и редактировать ее структуру. Эти две функциональные возможности не связаны напрямую с работой (функционированием и обучением) сети. Таким образом, необходимо выделить сервисную компоненту — редактор сетей. Компонент редактор сетей позволяет создавать и изменять структуру сети, модернизировать обучаемые параметры в «ручном» режиме.
Запросы к компоненту сеть
Запросы к компоненту сеть можно разбить на пять групп:
1. Функционирование.
2. Изменение параметров.
3. Работа со структурой.
4. Инициация редактора и конструктора сетей.
5. Обработка ошибок.
Поскольку компонент сеть может работать одновременно с несколькими сетями, большинство запросов к сети содержат явное указание имени сети. Отметим, что при генерации запросов в качестве имени сети можно указывать имя любой подсети. Таким образом, иерархическая структура сети, описанная в стандарте языка описания сетей, позволяет работать с каждым блоком или элементом сети как с отдельной сетью. Ниже приведено описание всех запросов к компоненту сеть. Каждый запрос является логической функцией, возвращающей значение истина, если запрос выполнен успешно, и ложь — при ошибочном завершении исполнения запроса.
Таблица 26. Значения предопределенных констант
Название Величина Значение InSignals 0 Входные сигналы прямого функционирования OutSignals 1 Выходные сигналы прямого функционирования Рarameters 2 Параметры InSignalMask 3 Маска обучаемости входных сигналов ParamMask 4 Маска обучаемости параметров BackInSignals 5 Входные сигналы обратного функционирования BackOutSignals 6 Выходные сигналы обратного функционирования BackРarameters 7 Поправки к параметрам Element 0 Тип подсети — элемент Layer 1 Тип подсети — слой Cascad 2 Тип подсети — простой каскад CicleFor 3 Тип подсети — цикл с заданным числом проходов CicleUntil 4 Тип подсети — цикл по условиюПри вызове ряда запросов используются предопределенные константы. Их значения приведены в табл. 26.
(обратно)Запросы на функционирование
Два запроса первой группы позволяют проводить прямое и обратное функционирование сети. По сути эти запросы эквивалентны вызову методов Forw и Back сети или ее элемента.
Выполнить прямое Функционирование (Forw)
Описание запроса:
Pascal:
Function Forw (Net: PString; InSignals: PRealArray): Logic;
C:
Logic Forw(PString Net, PRealArray InSignals)
Описание аргумента:
Net — указатель на строку символов, содержащую имя сети.
InSignals — массив входных сигналов сети.
Назначение — проводит прямое функционирование сети, указанной в параметре Net.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Вызывается метод Forw сети, имя которой было указано в аргументе Net.
4. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 304 — ошибка прямого функционирования. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
Выполнить обратное Функционирование (Back)
Описание запроса:
Pascal:
Function Back(Net: PString; BackOutSignals: PRealArray): Logic;
C:
Logic Back(PString Net, PRealArray BackOutSignals)
Описание аргумента:
Net — указатель на строку символов, содержащую имя сети.
BackOutSignals — массив производных функции оценки по выходным сигналам сети.
Назначение — проводит обратное функционирование сети, указанной в параметре Net.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Вызывается метод Back сети, имя которой было указано в аргументе Net.
5. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 305 — ошибка обратного функционирования. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
Запросы на изменение параметров
Ко второй группе запросов относятся четыре запроса: Modify — модификация параметров, обычно называемая обучением, ModifyMask — модификация маски обучаемых синапсов, NullGradient — обнуление градиента и RandomDirection — сгенерировать случайное направление спуска.
Провести обучение (Modify)
Описание запроса:
Pascal:
Function Modify(Net: PString; OldStep, NewStep: Real; Tipe: Integer; Grad: PRealArray): Logic;
C:
Logic Modify(PString Net, Real OldStep, Real NewStep, Integer Tipe, PRealArray Grad)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
OldStep, NewStep — параметры обучения.
Tipe — одна из констант InSignals или Parameters.
Grad — адрес массива поправок или пустой указатель.
Назначение — проводит обучение параметров или входных сигналов сети, указанной в параметре Net.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Если аргумент Grad содержит пустой указатель, то поправки берутся из массива Back.Parameters или Back.InputSignals в зависимости от значения аргумента Tipe.
5. В зависимости от значения аргумента Tipe для каждого параметра или входного сигнала P, при условии, что соответствующий ему элемент маски обучаемости, соответствующей аргументу Tipe равен –1 (значение истина) выполняется следующая процедура:
• P1=P*OldStep+DP*NewStep
• Если для типа, которым описан параметр P, заданы минимальное и максимальное значения, то:
• P2=Pmin, при P1
• P2=Pmax, при P1>Pmax
• P2=P1 в противном случае
Изменить маску обучаемости (ModifyMask)
Описание запроса:
Pascal:
Function ModifyMask(Net: PString; Tipe: Integer; NewMask: PLogicArray): Logic;
C:
Logic Modify(PString Net, Integer Tipe, PLogicArray NewMask)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
Tipe — одна из констант InSignals или Parameters.
NewMask — новая маска обучаемости.
Назначение — Заменяет маску обучаемости параметров или входных сигналов сети, указанной в параметре Net.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. В зависимости от значения параметра Tipe заменяет маску обучаемости параметров или входных сигналов на переданную в параметре NewMask.
Обнулить градиент (NullGradient)
Описание запроса:
Pascal:
Function NullGradient(Net: PString): Logic;
C:
Logic NullGradient(PString Net)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
Назначение — производит обнуление градиента сети, указанной в параметре Net.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Обнуляются массивы Back.Parameters и Back.OutSignals.
Случайное направление спуска (RandomDirection)
Описание запроса:
Pascal:
Function RandomDirection(Net: PString; Range: Real): Logic;
C:
Logic RandomDirection(PString Net, Real Range)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
Range — относительная ширина интервала, на котором должны быть распределены значения случайной величины.
Назначение — генерирует вектор случайных поправок к параметрам сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
3. Если список сетей компонента сеть пуст или имя сети, переданное в аргументе Net в этом списке не найдено, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Замещают все значения массива Back.Parameters на случайные величины. Интервал распределения случайной величины зависит от типа параметра, указанного при описании сети (ParamType) и аргумента Range. Полуширина интервала определяется как произведение полуширины интервала допустимых значений параметра, указанных в разделе ParamDef описания сети на величину Range. Интервал распределения случайной величины определяется как [–Полуширина; Полуширина].
Запросы, работающие со структурой сети
К третьей группе относятся запросы, позволяющие изменять структуру сети. Часть запросов этой группы описана в разд. «Остальные запросы».
Вернуть параметры сети (nwGetData)
Описание запроса:
Pascal:
Function nwGetData(Net: PString; DataType: Integer; Var Data: PRealArray): Logic;
C:
Logic nwGetData(PString Net, Integer DataType, PRealArray* Data)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
DataType — одна из восьми предопределенных констант, описывающих тип данных сети.
Data — возвращаемый массив параметров сети.
Назначение — возвращает параметры, входные или выходные сигналы сети, указанной в аргументе Net.
Описание исполнения.
1. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является перавя сеть в списке сетей компонента сеть.
2. Если имя сети, переданное в аргументе Net не найдено в списке сетей компонента сеть или этот список пуст, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Если значение, переданное в аргументе DataType больше семи или меньше нуля, то возникает ошибка 306 — ошибочный тип параметра сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. В массиве Data возвращаются указанные в аргументе DataType параметры сети.
Установить параметры сети (nwSetData)
Описание запроса:
Pascal:
Function nwSetData(Net: PString; DataType: Integer; Var Data: RealArray): Logic;
C:
Logic nwSetData(PString Net, Integer DataType, RealArray* Data)
Описание аргументов:
Net — указатель на строку символов, содержащую имя сети.
DataType — одна из восьми предопределенных констант, описывающих тип данных сети.
Data — массив параметров для замещения текущего массива параметров сети.
Назначение — замещает параметры, входные или выходные сигналы сети, указанной в аргументе Net на значения из массива Data.
Описание исполнения.
1. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
2. Если имя сети, переданное в аргументе Net не найдено в списке сетей компонента сеть или этот список пуст, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Если значение, переданное в аргументе DataType больше семи или меньше нуля, то возникает ошибка 306 — ошибочный тип параметра сети, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Значения параметров (входных или выходных сигналов) сети заменяются на значения из массива Data. Если длинны массива Data недостаточно для замены значений всех параметров (входных или выходных сигналов), то замещаются только столько элементов массива параметров (входных или выходных сигналов) сколько элементов в массиве Data. Если длинна массива Data больше длинны массива параметров (входных или выходных сигналов), то заменяются все элементы вектора параметров (входных или выходных сигналов), а лишние элементы массива Data игнорируются.
Нормализовать сеть (NormalizeNet)
Описание запроса:
Pascal:
Function NormalizeNet(Net: PString): Logic;
C:
Logic NormalizeNet(PString Net)
Описание аргумента:
Net — указатель на строку символов, содержащую имя сети.
Назначение — нормализация сети, указанной в аргументе Net.
Описание исполнения.
1. Если в качестве аргумента Net дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая сеть в списке сетей компонента сеть.
2. Если имя сети, переданное в аргументе Net не найдено в списке сетей компонента сеть или этот список пуст, то возникает ошибка 301 — неверное имя сети, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Из сети удаляются связи, имеющие нулевой вес и исключенные из обучения. Нумерация сигналов и параметров сохраняется.
4. Из структуры сети удаляются «немые» участки — элементы и блоки, выходные сигналы которых не являются выходными сигналами сети в целом и не используются в качестве входных сигналов другими подсетями. Нумерация сигналов и параметров сохраняется.
5. Производится замена элементов, ставших «прозрачными» — путем замыкания входного сигнала на выходной, удаляются простые однородные сумматоры с одним входом и точки ветвления с одним выходом; адаптивные однородные сумматоры с одним входом заменяются синапсами. Нумерация сигналов и параметров сохраняется.
6. В каждом блоке производится замена имен подсетей на псевдонимы.
7. Производится изменение нумерации сигналов и параметров сети.
Остальные запросы
Ниже приведен список запросов, исполнение которых описано в разделе «Общий стандарт»:
nwSetCurrent — Сделать сеть текущей
nwAdd — Добавление сети
nwDelete — Удаление сети
nwWrite — Запись сети
nwGetStructNames — Вернуть имена подсетей
nwGetType — Вернуть тип подсети
nwEdit — Редактировать компоненту сеть
OnError — Установить обработчик ошибок
GetError — Дать номер ошибки
FreeMemory — Освободить память
В запросе nwGetType в переменной TypeId возвращается значение одной из предопределенных констант, перечисленных в табл. 26.
Следует заметить, что два запроса nwGetData (Получить параметры) и nwSetData (Установить параметры) имеют название, совпадающее с названием запросов, описанных в разделе «Общий стандарт», но они имеют другой набор аргументов.
Ошибки компонента сеть
В табл. 27 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом сеть, и действия стандартного обработчика ошибок.
Таблица 27. Ошибки компонента сеть и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 301 Неверное имя сети Занесение номера в Error 302 Ошибка считывания сети Занесение номера в Error 303 Ошибка сохранения сети Занесение номера в Error 304 Ошибка прямого функционирования Занесение номера в Error 30 Ошибка обратного функционирования Занесение номера в Error 306 Ошибочный тип параметра сети Занесение номера в ErrorСтандарт первого уровня компонента интерпретатор ответа
Данный раздел посвящен описанию стандарта записи на диск компонента интерпретатор ответов. Построение интерпретатора происходит в редакторе интерпретаторов ответа. Интерпретатор ответа всегда является составным, даже если выходом является один ответ. В состав этого объекта входят частные интерпретаторы. Кроме того, описание интерпретатора должно включать в себя правила распределения выходных сигналов сети между частными интерпретаторами и расположения ответов частных интерпретаторов в едином массиве ответов. Таким образом, интерпретатор ответа при выполнении запроса на интерпретацию массива выходных сигналов сети получает на входе массив выходных сигналов сети, а возвращает два массива — ответов и коэффициентов уверенности.
Каждый частный интерпретатор ответа получает на входе массив сигналов (возможно из одного элемента), которые он интерпретирует, а на выходе возвращает два числа — ответ и коэффициент уверенности в этом ответе.
В табл. 28 приведен список ключевых слов, специфических для языка описания интерпретатора ответов. Наиболее часто встречающиеся интерпретаторы объявлены стандартными. Для стандартных интерпретаторов описание частных интерпретаторов отсутствует. Список стандартных интерпретаторов приведен в табл. 29.
Таблица 28. Ключевые слова языка описания интерпретаторов ответа.
Ключевое слово Краткое описание Answer Ответ. Connections Начало блока описания распределения сигналов и ответов. Contents Начало блока описания состава интерпретатора. Include Предшествует имени файла, целиком вставляемого в это место описания. Interpretator Заголовок раздела файла, содержащий описание интерпретатор. NumberOf Функция. Возвращает число интерпретируемых частным интерпретатором сигналов. Reliability Коэффициент уверенности. Signals Имя, по которому адресуются интерпретируемые сигналы; начало блока описания сигналов. SetParameters Процедура установления значений параметров.Таблица 29. Стандартные частные интерпретаторы.
Название Параметры Аргументы Описание Empty B — множитель C — смещение Интерпретирует один сигнал А. Ответом является величина О=А*В+С Binary E — уровень надежности N — число сигналов (классов) Кодирование номером канала. Знаковый интерпретатор Major E — уровень надежности N — число сигналов (классов) Кодирование номером канала. Максимальный интерпретатор. BynaryCoded E — уровень надежности N — число сигналов (классов) Двоичный интерпретатор.БНФ языка описания интерпретатора
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание интерпретатора>::= <Заголовок> [<Описание функций>] <Описание частных интерпретаторов> <Описание состава> [<Установление параметров>] [<Описание сигналов>] [<Описание распределения сигналов>] [<Описание распределения ответов>] <Конец описания интерпретатора>
<Заголовок>::= Interpretator<Имя интерпретатора>
<Имя интерпретатора>::= <Идентификатор>
<Описание частных интерпретаторов>::= <Описание частного интерпретатора> [<Описание частных интерпретаторов>]
<Описание частного интерпретатора>::= <Заголовок описания интерпретатора> [<Описание статических переменных >] [<Описание переменных>] <Тело интерпретатора>
<Заголовок описания интерпретатора>::= Inter <Имя частного интерпретатора>: (<Список формальных аргументов>)
<Имя частного интерпретатора>::= <Идентификатор>
<Тело интерпретатора>::= Begin <Составной оператор> End
<Описание состава>::= Contents <Список имен интерпретаторов>;
<Список имен интерпретаторов>::= <Имя интерпретатора> [,<Список имен интерпретаторов >]
<Имя интерпретатора>::= <Псевдоним>: {<Имя ранее описанного интерпретатора> | <Имя стандартного интерпретатора>} [[ <Число экземпляров >]][( <Список фактических аргументов>)]
<Псевдоним>::= <Идентификатор>
<Число экземпляров >::= <Целое число>
<Имя ранее описанного интерпретатора>::= <Идентификатор>
<Имя стандартного интерпретатора>::= <Идентификатор>
<Установление параметров>::= <Установление параметров Частного интерпретатора> [;<Установление параметров>]
<Описание сигналов>::= Signals <Константное выражение типаLong >
<Описание распределения сигналов>::= <Описание распределения Сигналов,Интерпретатора, Частного интерпретатора,Signals>
<Описание распределения ответов>::= <Описание распределения Ответов,Интерпретатора, Частного интерпретатора,Answer>
<Конец описания интерпретатора>::= End Interpretator
Описание языка описания интерпретаторов
Структура описания интерпретатора имеет вид: заголовок, описание частных интерпретаторов, описание состава, описание сигналов, описание распределения сигналов, описание распределения ответов, конец описания интерпретатора.
Заголовок состоит из ключевого слова Interpretator и имени интерпретатора и служит для обозначения начала описания интерпретатора в файле, содержащем несколько компонентов нейрокомпьютера.
Описание частного интерпретатора — это описание процедуры, вычисляющей две величины: ответ и уверенность в ответе. Отметим, что уверенность в ответе имеет смысл только для оценок с уровнем надежности. В остальных случаях интерпретатор ответа может вычислять аналогичную величину, но эта величина не является коэффициентом уверенности в ответе в точном смысле. Отметим, что при описании частного интерпретатора его аргументом, как правило, является число интерпретируемых сигналов. При выполнении частный интерпретатор получает в качестве аргументов массив интерпретируемых сигналов и две действительные переменные для возвращения вычисленных ответа и уверенности в ответе. Формально, при исполнении, частный интерпретатор имеет описание следующего вида:
Pascal:
Procedure Interpretator(Signals: PRealArray; Var Answer, Reliability: Real);
C:
void Interpretator(PRealArray Signals, Real* Answer, Real* Reliability);
В разделе описания состава перечисляются частные интерпретаторы, входящие в состав интерпретатора. Признаком конца раздела служит символ «;».
В необязательном разделе установления параметров производится задание значений параметров (статических переменных) частных интерпретаторов. После ключевого слова SetParameters следует список значений параметров в том порядке, в каком параметры были объявлены при описании частного интерпретатора (для стандартных интерпретаторов порядок параметров указан в табл. 29). При использовании одного оператора задания параметров для задания параметров нескольким экземплярам одного частного интерпретатора после ключевого словаsetparameters указывается столько выражений, задающих значения параметров, сколько необходимо для одного экземпляра. Например, если в блоке описания состава содержится 10 экземпляров двоичного интерпретатора на 15 интерпретируемых сигналов — myint: binarycoded(15)[10], то после ключевого слова setparameters должно быть только одно выражение:
MyInt[I:1..10] SetParameters 0.01*I
В данном примере первый интерпретатор будет иметь уровень надежности равный 0.01, второй — 0.02 и т. д.
В необязательном разделе описание сигналов указывается число сигналов, интерпретируемых интерпретатором. Если этот раздел опущен, то полагается, что число интерпретируемых интерпретатором сигналов равно сумме сигналов, интерпретируемых всеми частными интерпретаторами. В константном выражении может вызываться функция NumberOf, аргументом которой является имя частного интерпретатора (или его псевдоним) с указанием фактических аргументов.
В необязательном разделе описания распределения сигналов для каждого частного интерпретатора указывается, какие сигналы из общего интерпретируемого массива передаются ему для интерпретации. Если этот раздел отсутствует, то считается, что каждый следующий частный интерпретатор получает следующий фрагмент общего вектора выходных сигналов. В примере 1 данный раздел описывает распределение сигналов по умолчанию.
В необязательном разделе описания распределения ответов для каждого частного интерпретатора указывается, какой элемент массива ответов он вычисляет. Если этот раздел опущен, то считается, что первый частный интерпретатор вычисляет первый элемент массива ответов, второй — второй элемент и т. д. Массив уровней надежностей всегда параллелен массиву ответов. В примере 1 данный раздел описывает распределение ответов по умолчанию.
Кроме того, в любом месте описания интерпретатора могут встречаться комментарии, заключенные в фигурные скобки.
Пример описания интерпретатора
В этом разделе приведены два примера описания одного и того же интерпретатора следующего состава: первый сигнал интерпретируется как температура путем умножения на 10 и добавления 273; следующие два сигнала интерпретируются как наличие облачности, используя знаковый интерпретатор; следующие три сигнала интерпретируются как направление ветра, используя двоичный интерпретатор (восемь румбов); последние три сигнала интерпретируются максимальным интерпретатором как сила осадков (без осадков, слабые осадки, сильные осадки). В первом примере приведено описание дубликатов всех стандартных интерпретаторов. Во втором — использованы стандартные интерпретаторы.
Пример 1.
Interpretator Meteorology
{Интерпретатор осуществляющий масштабирование и сдвиг сигнала}
Inter Empty1()
Static
Real B Name "Масштабный множитель";
Real C Name "Сдвиг начала отсчета";
Begin
Answer = Signals[1] * B + C;
Reliability = 0
End
{Кодирование номером канала. Знаковый интерпретатор}
Inter Binary1 : (N : Long)
Static
Real E Name "Уровень надежности";
Var
Long A, B, I;
Real Dist;
Begin
Dist = E;
B = 0; {Число единиц}
A = 0; {Номер единицы}
For I = 1 To N Do Begin
If Abs(Signals[I]) < Dist Then Dist =Abs(Signals[I]);
If Signals[I] > 0 Then Begin A = I; B = B + 1; End;
End;
If B <> 1 Then Answer = 0 Else Answer = A
Reliability = Abs(Dist / E)
End
{Кодирование номером канала. Максимальный интерпретатор.}
Inter Major1 : (N : Long)
Static
Real E Name "Уровень надежности";
Var
Real A, B;
Long I, J;
Begin
A = -1.E+30; {Максимальный сигнал}
B = -1.E+30; {Второй по величине сигнал}
J = 0; {Номер максимального сигнала}
For I = 1 To N Do Begin
If Signals[I] > A Then Begin B = A; A = Signals[I]; J=I; End
Else If Signals[I] > B Then B = Signals[I];
End;
Answer = J;
If A – B > E Then Reliability = 1 Else Reliability = (A – B) / E;
End
Inter BynaryCoded1 : (N : Long)
Static
Real E Name "Уровень надежности";
Var
Long A, I;
Real Dist;
Begin
Dist = E;
A = 0; {Ответ}
For I = 1 To N Do Begin
If Abs(Signals[I]) < Dist Then Dist =Abs(Signals[I]);
A = A * 2;
If Signals[I] > 0 Then A = A + 1;
End;
Answer = A;
Reliability = Abs(Dist / E)
End
Contents Temp : Empty1, Cloud : Binary1(2), Wind : BynaryCoded1(3), Rain : Major1(3);
Temp SetParameters 10, 273;
Cloud SetParameters 0.1;
Wind SetParameters 0.2;
Rain SetParameters 0.15
Signals NumberOf(Signals,Temp) +NumberOf(Signals, Cloud) +
1 NumberOf(Signals, Wind) + NumberOf(Signals, Rain)
Connections
Temp.Signals <=> Signals[1];
Cloud.Signals[1..2] <=> Signals[2; 3];
Wind.Signals[1..3] <=> Signals[4..6];
Rain.Signals[1..3] <=> Signals[7..9]
Temp.Answer <=> Answer[1];
Cloud.Answer[1..2] <=> Answer[2];
Wind.Answer[1..3] <=> Answer[3];
Rain.Answer[1..3] <=> Answer[4]
End Interpretator
Пример 2.
Interpretator Meteorology
Contents Temp : Empty, Cloud : Binary(2), Wind : BynaryCoded(3), Rain : Major(3);
Temp SetParameters 10, 273;
Cloud SetParameters 0.1;
Wind SetParameters 0.2;
Rain SetParameters 0.15
End Interpretator
Стандарт второго уровня компонента интерпретатор ответа
Запросы к компоненту интерпретатор ответа можно разбить на пять групп:
1. Интерпретация.
2. Изменение параметров.
3. Работа со структурой.
4. Инициация редактора и конструктора интерпретатора ответа.
5. Обработка ошибок.
Поскольку нейрокомпьютер может работать одновременно с несколькими сетями, то и компонент интерпретатор ответа должен иметь возможность одновременной работы с несколькими интерпретаторами. Поэтому большинство запросов к интерпретатору содержат явное указание имени интерпретатора ответа. Ниже приведено описание всех запросов к компоненту интерпретатор ответа. Каждый запрос является логической функцией, возвращающей значение истина, если запрос выполнен успешно, и ложь — при ошибочном завершении исполнения запроса.
В запросах второй и третьей группы при обращении к частным интерпретаторам используется следующий синтаксис:
<Полное имя частного интерпретатора>::=<Имя интерпретатора>.<Псевдоним частного интерпретатора> [[ <Номер экземпляра>]]
При вызове ряда запросов используются предопределенные константы. Их значения приведены в табл. 30.
Таблица 30. Значения предопределенных констант компонентов интерпретатор ответа и оценка
Название Величина Значение Empty 0 Интерпретирует один сигнал как действительное число. Binary 1 Кодирование номером канала. Знаковый интерпретатор Major 2 Кодирование номером канала. Максимальный интерпретатор. BynaryCoded 3 Двоичный интерпретатор. UserType –1 Интерпретатор, определенный пользователем.Запрос на интерпретацию
Единственный запрос первой группы выполняет основную функцию компонента интерпретатор ответа — интерпретирует массив сигналов.
Интерпретировать массив сигналов (interpretate)
Описание запроса:
Pascal:
Function Interpretate(IntName: PString; Signals: PRealArray; Var Reliability, Answers: PRealArray): Logic;
C:
Logic Interpretate(PString IntName, PRealArray Signals, PRealArray* Reliability, PRealArray* Answers)
Описание аргумента:
IntName — указатель на строку символов, содержащую имя интерпретатора ответа.
Signals — массив интерпретируемых сигналов.
Answers — массив ответов.
Reliability — массив коэффициентов уверенности в ответе.
Назначение — интерпретирует массив сигналов Signals, используя интерпретатор ответа, указанный в параметре IntName.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента IntName дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первый интерпретатор ответа в списке интерпретаторов компонента интерпретатор.
3. Если список интерпретаторов компонента интерпретатор пуст или имя интерпретатора ответа, переданное в аргументе IntName в этом списке не найдено, то возникает ошибка 501 — неверное имя интерпретатора ответа, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Производится интерпретация ответа интерпретатором ответа, имя которого было указано в аргументе IntName.
5. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 504 — ошибка интерпретации. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
(обратно)Остальные запросы
Ниже приведен список запросов, исполнение которых описано в разделе «Общий стандарт»:
aiSetCurrent — Сделать интерпретатор ответа текущим
aiAdd — Добавление нового интерпретатора ответа
aiDelete — Удаление интерпретатора ответа
aiWrite — Запись интерпретатора ответа
aiGetStructNames — Вернуть имена частных интерпретаторов
aiGetType — Вернуть тип частного интерпретатора
aiGetData — Получить параметры частного интерпретатора
aiGetName — Получить имена параметров частного интерпретатора
aiSetData — Установить параметры частного интерпретатора
aiEdit — Редактировать интерпретатор ответа
OnError — Установить обработчик ошибок
GetError — Дать номер ошибки
FreeMemory — Освободить память
В запросе aiGetType в переменной TypeId возвращается значение одной из предопределенных констант, перечисленных в табл. 30.
При исполнении запроса aiSetData генерируется запрос SetEstIntParameters к компоненте оценка. Аргументы генерируемого запроса совпадают с аргументами исполняемого запроса
Ошибки компонента интерпретатор ответа
В табл. 31 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом интерпретатор ответа, и действия стандартного обработчика ошибок.
Таблица 31. Ошибки компонента интерпретатор ответа и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 501 Неверное имя интерпретатора ответа Занесение номера в Error 502 Ошибка считывания интерпретатора ответа Занесение номера в Error 503 Ошибка сохранения интерпретатора ответа Занесение номера в Error 504 Ошибка интерпретации Занесение номера в ErrorСтандарт первого уровня компонента оценка
Данный раздел посвящен описанию стандарта хранения на диске описания компонента оценка. Построение оценки происходит в редакторе оценок. В данном стандарте предлагается ограничиться рассмотрением только локальных оценок, поскольку использование нелокальных (глобальных) оценок сильно усложняет компонент оценка, а область применения нелокальных оценок узка по сравнению с локальными оценками.
Оценка всегда является составной, даже если ответом сети является одна величина. В состав этого объекта входят частные оценки. Кроме того, в описание оценки включаются правила распределения выходных сигналов сети между частными оценками и расположения оценок, вычисляемых частными оценками, в едином массиве оценок. Кроме того, различные частные оценки могут иметь разную значимость. В этом случае общая оценка определяется как сумма частных оценок с весами, задающими значимость.
Таким образом, оценка при выполнении запроса на оценивание массива выходных сигналов сети получает на входе массив выходных сигналов сети, массив правильных ответов и массив их достоверностей, а возвращает два массива — массив оценок и массив производных оценки по выходным сигналам сети — и величину суммарной оценки. Возможны два режима оценивания: оценивание без вычисления массива производных оценки по выходным сигналам сети, и оценивание с вычислением массива производных.
Каждая частная оценка получает на входе свой массив сигналов (возможно из одного элемента), правильный ответ и его достоверность, а на выходе вычисляет оценку и, при необходимости, массив производных оценки по выходным сигналам сети.
В табл. 32 приведен список ключевых слов специфических для языка описания оценок. Наиболее часто встречающиеся частные оценки объявлены стандартными. Для стандартных оценок описание частных оценок отсутствует. Список стандартных оценок приведен в табл. 33.
Таблица 32. Ключевые слова языка описания оценок.
Ключевое слово Краткое описание Answer Правильный ответ. Back Массив производных оценки по оцениваемым сигналам. Contents Начало блока описания состава оценки. Direv Признак необходимости вычисления производных. Est Заголовок описания частной оценки. Estim Переменная действительного типа, для возвращения вычисленной оценки. Estimation Заголовок раздела файла, содержащий описание оценки. Include Предшествует имени файла, целиком вставляемого в это место. Link Указывает интерпретатор ответа, связанный с оценкой. NumberOf Функция. Возвращает число интерпретируемых частным интерпретатором сигналов. Reliability Достоверность правильного ответа. Signals Имя, по которому адресуются интерпретируемые сигналы; начало блока описания сигналов. Weight Вес частной оценки. Weights Начало блока описания весов частных оценок.Таблица 33. Стандартные частные оценки.
Название Параметры Аргументы Описание Empty B — множитель C — смещение Оценивает один сигнал А, вычисляя расстояние до правильного ответа с учетом нормировки. Binary E — уровень надежности N — число сигналов. Кодирование номером канала. Соответствует знаковому интерпретатору. Major E — уровень надежности N — число сигналов. Кодирование номером канала. Соответствует максимальному интерпретатору. BynaryCoded E — уровень надежности N — число сигналов. Соответствует двоичному интерпретатору.БНФ языка описания оценок
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание оценки>::= <Заголовок> [<Описание функций>] <Описание частных оценок> <Описание состава> [<Связывание с интерпретаторами>] [<Установление параметров>] [<Описание весов>] [<Описание сигналов>] [<Описание распределения сигналов>] [<Описание распределения оценок>] <Конец описания оценки>
<Заголовок>::= Estimation<Имя оценки>
<Имя оценки>::= <Идентификатор>
<Описание частных оценок>::= <Описание частной оценки> [<Описание частных оценок>]
<Описание частной оценки>::= <Заголовок описания оценки> [<Описание статических переменных>] [<Описание переменных>] <Тело оценки>
<Заголовок описания оценки>::= Est <Имя частной оценки> (<Список формальных аргументов>)
<Имя частной оценки>::= <Идентификатор>
<Тело оценки>::= Begin <Составной оператор> End
<Описание состава>::= Contents <Список имен оценок>;
<Список имен оценок>::= <Имя оценки> [,<Список имен оценок >]
<Имя оценки>::= <Псевдоним>: {<Имя ранее описанной оценки> | <Имя стандартной оценки>} [( <Список фактических аргументов>)] [[ <Число экземпляров>]]
<Псевдоним>::= <Идентификатор>
<Число экземпляров >::= <Целое число>
<Имя ранее описанной оценки>::= <Идентификатор>
<Имя стандартной оценки>::= <Идентификатор>
<Установление параметров>::= <Установление параметров Частной оценки> [;<Установление параметров>]
<Связывание с интерпретаторами>::= <Псевдоним> [[ <Начальный номер> [..<Конечный номер> [:<Шаг>]]]] Link<Псевдоним интерпретатора> [[ <Начальный номер> [..<Конечный номер> [:<Шаг>]]]]
<Псевдоним интерпретатора>::= <Идентификатор>
<Описание весов>::= Weights<Список весов>;
<Список весов>::= <Вес> [,<Список весов>]
<Вес>::= <Действительное число>
<Описание сигналов>::= Signals <Константное выражение типаLong >
<Описание распределения сигналов>::= <Описание распределения Сигналов,Оценки, Частной оценки,Signals>
<Описание распределения ответов>::= <Описание распределения Ответов,Оценки, Частной оценки,Answer>
<Конец описания оценки>::= End Estimation
Описание языка описания оценок
Структура описания оценки имеет вид: заголовок, описание функций, описание частных оценок, описание состава, описание связей с интерпретаторами, описание сигналов, описание распределения сигналов, описание распределения ответов, конец описания оценки.
Заголовок состоит из ключевого слова Estimation и имени оценки и служит для обозначения начала описания оценки в файле, содержащем несколько компонент нейрокомпьютера.
Описание частной оценки — это описание процедуры, вычисляющей оценку и, при необходимости, массив производных оценки по выходным сигналам сети. Отметим, что при описании частной оценки его аргументом, как правило, является число оцениваемых сигналов. При выполнении частная оценка получает в качестве аргументов массив оцениваемых сигналов, признак необходимости вычисления производных, правильный ответ, достоверность правильного ответа, действительную переменную для возвращения вычисленной оценки и массив для возвращения производных. Формально, при исполнении частная оценка имеет описание следующего вида:
Pascal:
Procedure Estimation(Signals, Back: PRealArray; Direv: Logic; Answer,reliability: real; var estim: real);
C:
void Estimation(PRealArray Signals, PRealArray Back, Logic Direv, Real Answer,real reliability, real* estim);
Отметим одну важную особенность выполнения тела частной оценки. Оператор присваивания значения элементу массива производных, означает добавление этого значения к величине, ранее находившейся в этом массиве. Например, запись Back[I] = A, означает выполнение следующего оператора Back[I] = Back[I] + A. Это связано с тем, что один и тот же сигнал может быть задействован в нескольких частных оценках и производная общей функции оценки равна сумме производных частных оценок по этому сигналу.
В разделе описания состава перечисляются частные оценки, входящие в состав оценки. Признаком конца раздела служит символ «;».
В необязательном разделе установления параметров производится задание значений параметров частных оценок. После ключевого слова SetParameters следует список значений параметров в том порядке, в каком параметры (статические переменные) были объявлены при описании частной оценки (для стандартных оценок порядок параметров указан в табл. 33). При использовании одного оператора задания параметров для задания параметров нескольким экземплярам одной частной оценки после ключевого словаsetparameters указывается столько выражений, задающих значения параметров, сколько необходимо для одного экземпляра. Например, если в блоке описания состава содержится 10 экземпляров двоичной оценки на 15 оцениваемых сигналов — MyEst: BinaryCoded(15)[10], то после ключевого слова setparameters должно быть только одно выражение:
MyEst[I:1..10] SetParameters0.01*I
В данном примере первая оценка будет иметь уровень надежности равный 0.01, вторая — 0.02 и т. д.
В необязательном разделе описания связей с интерпретаторами можно указать интерпретатор ответа, связанный с данной оценкой. Для связи интерпретатор и оценка должны иметь одинаковое число параметров и одинаковый порядок их описания. Так, в приведенном ниже примере, невозможно связывание оценки Temp с одноименным интерпретатором из-за различия в числе параметров. Если в левой части выражения Link указан диапазон оценок, то в правой части должен быть указан диапазон, содержащий столько же интерпретаторов. Указание связи влечет идентичность параметров оценки и связанного с ней интерпретатора ответов. Идентичность обеспечивается при исполнении запросов aiSetData и esSetData.
В необязательном разделе описания весов указываются веса частных оценок. Если этот раздел опущен, то все частные оценки равны единице, то есть все частные оценки имеют равную значимость.
В необязательном разделе описания сигналов указывается число сигналов, оцениваемых всеми частными оценками. Если этот раздел опущен, то полагается, что число оцениваемых оценкой сигналов равно сумме сигналов, оцениваемых всеми частными оценками. В константном выражении может вызываться функция NumberOf, аргументом которой является имя частной оценки (или ее псевдоним) с указанием фактических аргументов.
В необязательном разделе описания распределения сигналов для каждой частной оценки указывается, какие сигналы из общего оцениваемого массива передаются ей для оценивания. Если этот раздел опущен, то считается, что каждая следующая частная оценка получает следующий фрагмент массива сигналов. Порядок следования частных оценок соответствует порядку их перечисления в разделе описания состава. В примере 1 раздел описания распределения сигналов задает распределение сигналов по умолчанию. Массив производных оценки по выходным сигналам сети параллелен массиву сигналов.
В необязательном разделе описания распределения ответов для каждой частной оценки указывается какой элемент массива ответов будет ей передан. Если этот раздел опущен, то считается, что каждая следующая частная оценка получает следующий элемент массива ответов. Порядок следования частных оценок соответствует порядку их перечисления в разделе описания состава. В примере 1 раздел описания распределения ответов задает распределение сигналов по умолчанию. Массивы достоверностей ответов и вычисленных оценок параллельны массиву ответов.
Кроме того, в любом месте описания оценки могут встречаться комментарии, заключенные в фигурные скобки.
Пример описания оценки
В этом разделе приведены два примера описания одной и той же оценки следующего состава: первый сигнал интерпретируется как температура путем умножения на 10 и добавления 273; следующие два сигнала интерпретируются как наличие облачности, используя знаковый интерпретатор; следующие три сигнала интерпретируются как направление ветра, используя двоичный интерпретатор (восемь румбов); последние три сигнала интерпретируются максимальным интерпретатором как сила осадков (без осадков, слабые осадки, сильные осадки). Для трех последних интерпретаторов используются соответствующие им оценки типа расстояние до множества. В первом примере приведено описание дубликатов всех стандартных оценок. Во втором — использованы стандартные оценки.
Пример 1.
Estimation Meteorology
Est Empty1() {Оценка для интерпретатора, осуществляющего масштабирование и сдвиг сигнала}
Static
Real B Name "Масштабный множитель";
Real C Name "Сдвиг начала отсчета";
Real E Name "Требуемаяточность совпадения";
Var
Real A;
Begin
A = Signals[1] – (Answer – C) / B;
D = E * Reliability; {Допуск определяем произведением}
If Abs(A)<D Then Estim = 0
Else If A > 0 Then Begin
Estim =Weight * Sqr(A – D) / 2;
If Direv Then Back[1] = Weight * (A – D);
End Else Begin
Estim =Weight * Sqr(A + D) / 2;
If Direv Then Back[1] = Weight * (A + D);
End
End
{Кодирование номером канала. Оценка для знакового интерпретатора.}
Est Binary1(N : Long)
Static
Real E Name "Уровень надежности";
Var
Long I, J;
Real A, B, C;
Begin
J = Answer; {Правильный ответ – номер правильного класса}
B = 0;
C = E * Reliability; {Допуск определяем произведением}
For I = 1 To N Do
If I = J Then Begin
If Signals[I] < С Then Begin
B = B + Sqr(Signals[I] – С);
If Direv Then Back[I] = 2 * Weight * (Signals[I]-С);
End;
End Else Begin
If Signals[I] > -C Then Begin
B = B + Sqr(Signals[I] + C);
If Direv Then Back[I] = 2 * Weight * (Signals[I] + C);
End
End;
Estim = Weight*B
End
{Кодирование номером канала. Оценка для максимального интерпретатора.}
Est Major1(N : Long)
Static
Real E Name "Уровень надежности";
Var
Real A, B;
Long I, J, K, Ans;
RealArray[N+1] Al,Ind;
Begin
Ans = Answer;
Ind[1] = Ans;
Al[1] = Signals[Ans] – E *Reliability;
Ind[N+1] = 0;
Al[N+1] = -1.e40;
K:=1;
For I = 1 To N Do
If I <> Ans Then Begin
Al[K] = Signals[I];
Ind[K] = I;
K = K + 1;
End; {Подготовлен массив сигналов}
For I = 2 To N-1 Do Begin
A = Al[I];
K = I;
For J = I+1 To N Do
If Al[J] > A Then Begin
K = J;
A = Al[J];
End; {Найден следующий по величине}
Al[K] = Al[I];
Al[I] = A;
J = Ind[K];
Ind[K] = Ind[I];
Ind[I] = J;
End; {Массивы отсортированы}
A = Al[1]; {Сумма первых I членов}
I = 1;
While (A / I <= Al[I+1]) Do Begin
A = A + Al[I];
I = I + 1;
End; {В конце цикла I-1 равно числу корректируемых сигналов}
B = A / I; {B – величина, к которой должны стремиться}
A = 0; {корректируемые сигналы}
For J = 1 To I Do Begin
A = A + Sqr(Al[J] – B);
If Direv Then Back[Ind[J]] = -2* Weight * (Al[J] – B);
End;
Estim = Weight * A
End;
Est BynaryCoded1: (N : Long) {Оценка для кодирования номером канала}
Static
Real E Name "Уровень надежности";
Var
Long I, J, A, K;
Real B, C;
Begin
A = Answer;
B = 0;
C = E * Reliability; {Допуск определяем произведением}
For I = N To 1 By -1 Do Begin
J = A / 2;
K = A – 2 * J;
A = J;
If A = 1 Then Begin
If Signals[I] < C Then Begin
B = B + Sqr(Signals[I] – C);
If Direv Then Back[I] = 2 * Weight * (Signals[I]-C);
End;
End Else Begin
If Signals[I] > -C Then Begin
B = B + Sqr(Signals[I] + C);
If Direv Then Back[I] = 2 * Weight * (Signals[I] + C);
End;
End;
Estim = Weight*B
End
Contents Temp : Empty1, Cloud : Binary1(2), Wind : BynaryCoded1(3), Rain : Major1(3);
Cloud Link Meteorology.Cloud {Связываем оценки с интерпретаторами}
Wind Link Meteorology.Wind
Rain Link Meteorology.Rain
Temp SetParameters 10, 273; {Устанавливаем значения параметров оценок}
Cloud SetParameters 0.1; {и интерпретаторов}
Wind SetParameters 0.2;
Rain SetParameters 0.15
Weights 1, 1, 1, 1
Signals NumberOf(Signals,Temp) +NumberOf(Signals, Cloud) + NumberOf(Signals, Wind) + NumberOf(Signals, Rain)
Connections
Temp.Signals <=> Signals[1];
Cloud.Signals[1..2] <=> Signals[2; 3];
Wind.Signals[1..3] <=> Signals[4..6];
Rain.Signals[1..3] <=> Signals[7..9]
Temp.Answer <=> Answer[1];
Cloud.Answer[1..2] <=> Answer[2];
Wind.Answer[1..3] <=> Answer[3];
Rain.Answer[1..3] <=> Answer[4]
End Estimation
Пример 2.
Estimation Meteorology
Contents Temp : Empty, Cloud : Binary(2), Wind : BynaryCoded(3), Rain : Major(3);
Cloud Link Meteorology.Cloud {Связываем оценки с интерпретаторами}
Wind Link Meteorology.Wind
Rain Link Meteorology.Rain
Temp SetParameters 10, 273; {Устанавливаем значения параметров оценок}
Cloud SetParameters 0.1; {и интерпретаторов}
Wind SetParameters 0.2;
Rain SetParameters 0.15
End Estimation
Стандарт второго уровня компонента оценка
Запросы к компоненте оценка можно разбить на пять групп:
1. Оценивание.
2. Изменение параметров.
3. Работа со структурой.
4. Инициация редактора и конструктора оценки.
5. Обработка ошибок.
Поскольку нейрокомпьютер может работать одновременно с несколькими сетями, то и компонент оценка должен иметь возможность одновременной работы с несколькими оценками. Поэтому большинство запросов к оценке содержат явное указание имени оценки. Ниже приведено описание всех запросов к компоненту оценка. Каждый запрос является логической функцией, возвращающей значение истина, если запрос выполнен успешно, и ложь — при ошибочном завершении исполнения запроса.
В запросах второй и третьей группы при обращении к частным оценкам используется следующий синтаксис:
<Полное имя частной оценки>::= <Имя оценки>.<Псевдоним частной оценки> [[ <Номер экземпляра>]]
При вызове ряда запросов используются предопределенные константы. Их значения приведены в табл. 30.
Запрос на оценивание
Единственный запрос первой группы выполняет основную функцию компонента оценка — вычисляет оценку и, если требуется, массив производных оценки по оцениваемым сигналам.
Оценить массив сигналов (Estimate)
Описание запроса:
Pascal:
Function Estimate(EstName: PString; Signals, Back, Answers, Reliability: PRealArray; Direv: Logic; Var Estim: Real): Logic;
C:
Logic Estimate(PString EstName, PRealArray Signals, PRealArray* Back, PRealArray Answers, PRealArray Reliability, Logic Direv,real* estim)
Описание аргумента:
EstName — указатель на строку символов, содержащую имя оценки.
Signals — указатель на массив оцениваемых сигналов.
Back — указатель на массив производных оценки по оцениваемым сигналам.
Answers — указатель на массив правильных ответов.
Reliability — указатель на массив достоверностей правильных ответов.
Direv — признак необходимости вычисления производных (False — не вычислять).
Estim — вычисленная оценка.
Назначение — вычисляет оценку массива сигналов Signals, используя оценку, указанную в параметре EstName.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в качестве аргумента EstName дан пустой указатель, или указатель на пустую строку, то исполняющим запрос объектом является первая оценка в списке оценок компонента оценка.
3. Если список оценок компонента оценка пуст или имя оценки, переданное в аргументе EstName, в этом списке не найдено, то возникает ошибка 401 — неверное имя оценки, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Производится вычисление оценки оценкой, имя которой было указано в аргументе EstName.
5. Если во время выполнения запроса возникает ошибка, то генерируется внутренняя ошибка 404 — ошибка оценивания. Управление передается обработчику ошибок. Выполнение запроса прекращается. В противном случае выполнение запроса успешно завершается.
Остальные запросы
Ниже приведен список запросов, исполнение которых описано в разделе «Общий стандарт»:
esSetCurrent — Сделать оценку текущим
esAdd — Добавление новой оценки
esDelete — Удаление оценки
esWrite — Запись оценки
esGetStructNames — Вернуть имена частных оценок
esGetType — Вернуть тип частной оценки
esGetData — Получить параметры частной оценки
esGetName — Получить имена параметров частной оценки
esSetData — Установить параметры частной оценки
esEdit — Редактировать оценку
OnError — Установить обработчик ошибок
GetError — Дать номер ошибки
FreeMemory — Освободить память
В запросе esGetType в переменной TypeId возвращается значение одной из предопределенных констант, перечисленных в табл. 30.
Кроме того, во второй группе запросов есть запрос SetEstIntParameters аналогичный запросу esSetData, но определяющий частную оценку, параметры которой изменяются, по полному имени связанного с ней интерпретатора ответа.
Установить параметры (SetEstIntParameters)
Описание запроса:
Pascal:
Function SetEstIntParameters(IntName: PString; Param: PRealArray): Logic;
C:
Logic SetEstIntParameters(PString IntName, PRealArray Param)
Описание аргументов:
IntName — указатель на строку символов, содержащую полное имя частного интерпретатора ответа.
Param — адрес массива параметров.
Назначение — заменяет значения параметров частной оценки, связанной с интерпретатором ответа, указанного в аргументе IntName, на значения, переданные, в аргументе Param.
Описание исполнения.
1. Запрос передается всем частным оценкам всех оценок в списке оценок компонента оценка.
2. Если частная оценка связана с частным интерпретатором ответа, имя которого указано в аргументе IntName, то текущие значения параметров частной оценки заменяются на значения, хранящиеся в массиве, адрес которого передан в аргументе Param.
Ошибки компонента оценка
В табл. 34 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом оценка, и действия стандартного обработчика ошибок.
Таблица 34. Ошибки компонента оценка и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 401 Неверное имя оценки Занесение номера в Error 402 Ошибка считывания оценки Занесение номера в Error 403 Ошибка сохранения оценки Занесение номера в Error 404 Ошибка вычисления оценки Занесение номера в ErrorСтандарт второго уровня компонента исполнитель
В данном разделе описаны запросы исполнителя с алгоритмами их исполнения. При описании запросов используется аргумент Instruct, являющийся целым числом, принимающим значение одной из предопределенных констант, приведенных в табл. 35, или суммы любого числа этих констант. Аргумент Instruct является совокупностью шести битовых флагов.
Таблица 35. Предопределенные константы компонента исполнитель
Название Идентификатор Значение Десят. Шестн. Вычислять оценку Estimate 1 H0001 Интерпретировать ответ Interpret 2 H0002 Вычислять градиент Gradient 4 H0004 Подготовка к контрастированию Contrast 8 H0008 Перейти к следующему примеру NextExample 16 H0010 Остановиться в конце обучающего множества StopOnEnd 32 H0020 Устанавливать ответы PutAnswers 64 H0040 Устанавливать оценки PutEstimations 128 H0080 Устанавливать уверенность в ответе PutReliability 256 H0100В запросах не указываются используемые сеть, оценка и интерпретатор ответа, поскольку компонент исполнитель всегда использует текущие сеть, оценку и интерпретатор ответа.
Позадачная обработка (TaskWork)
Описание запроса:
Pascal:
Function TaskWork(Instruct, Handle: Integer; Var Answers, Reliability: PRealArray; Var Estim: Real): Logic;
C:
Logic TaskWork(Integer Instruct, Integer Handle, PRealArray* Answers, PRealArray* Reliability; Real* Estim)
Описание аргументов:
Instruct — содержит инструкции о способе исполнения.
Handle — номер сеанса в задачнике.
Answers — указатель на массив вычисленных ответов.
Reliability — указатель на массив коэффициентов уверенности сети в ответах.
Estim — оценка решения примера.
Назначение — производит обработку одного примера.
Переменные, используемые при исполнении запроса
InArray, RelArray — адреса массивов для обменов с задачником.
Back — адрес массива для обменов с оценкой.
Описание исполнения.
Если в любой момент исполнения запроса возникает ошибка при исполнении запросов к другим компонентам, то исполнение запроса прекращается, возвращается значение ложь, ошибка компонента исполнитель не генерируется.
1. Если в аргументе Instruct установлен бит Gradient и не установлен бит Estimate, то выполнение запроса прекращается, и генерируется ошибка 001 — Некорректное сочетание флагов в аргументе Instruct.
2. Если в аргументе Instruct установлен бит Gradient, то генерируется запрос к сети NullGradient с аргументом Null.
3. Если в аргументе Instruct установлен бит NextExample, то генерируется запрос к задачнику Next с аргументом Handle. (Переход к следующему примеру)
4. Генерируется запрос к задачнику Last с аргументом Handle. (Проверка, существует ли пример)
5. Если запрос Last вернул значение истина, то
1. Если в аргументе Instruct установлен бит StopOnEnd, то исполнение запроса прекращается, возвращается значение ложь. (Примера нет, переход на начало не нужен)
2. Генерируется запрос к задачнику Home с аргументом Handle. (Переход на начало обучающего множества)
6. Переменной InArray присваивается значение Null и генерируется запрос к задачнику Get с аргументами Handle, InArray, tbPrepared (Получает от задачника предобработанные входные сигналы)
7. Генерируется запрос к сети Forw, с аргументами Null, InArray (выполняется прямое функционирование сети).
8. Освобождается массив InArray
9. Присваивает переменной Data значение Null и генерирует запрос к сети GetNetData с аргументами Null, OutSignals, Data (Получает от сети выходные сигналы).
10. Если в аргументе Instruct установлен бит Interpret, то
1. Генерируется запрос к интерпретатору ответа Interpretate с аргументами Data, Answers, Reliability. (Производит интерпретацию ответа)
2. Если в аргументе Instruct установлен бит PutAnswers, то генерируется запрос к задачнику Put с аргументами Handle, Answers, tbCalcAnswers (Передает задачнику вычисленные ответы)
3. Если в аргументе Instruct установлен бит PutReliability, то генерируется запрос к задачнику Put с аргументами Handle, Reliability, tbCalcReliability (Передает задачнику вычисленные коэффициенты уверенности в ответе)
11. Если в аргументе Instruct установлен бит Gradient, то создается массив Back того же размера, что и Data. В противном случае переменной Back присваивается значение Null.
12. Если в аргументе Instruct установлен бит Estimate, то
1. Переменной InArray присваивается значение Null и генерируется запрос к задачнику Get с аргументами Handle, InArray, tbAnswers (Получает от задачника правильные ответы)
2. Переменной RelArray присваивается значение Null и генерируется запрос к задачнику Get с аргументами Handle, RelArray, tbCalcReliability(Получает от задачника достоверности ответов)
3. Генерируется запрос к оценке Estimate с аргументами Data, Back, InArray, RelArray, Direv, Estim. Вместо Direv передается ноль, если в аргументе Instruct установлен бит Gradient, и 1 в противном случае. (Вычисляет оценку примера и, возможно, производные)
4. Если в аргументе Instruct установлен бит PutEstimations, то генерируется запрос к задачнику Put с аргументами Handle, Estim, tbEstimations (Передает задачнику оценку примера)
5. Освобождает массивы InArray и RelArray.
13. Если в аргументе Instruct установлен бит Gradient, то генерируется запрос к сети Back, с аргументами Null, Back. Освобождает массив Back. (Выполняется обратное функционирование сети)
14. Освобождается массив Data.
15. Если в аргументе Instruct установлен бит Contrast, то генерируется запрос к контрастеру ContrastExample с аргументом истина.
16. Завершает исполнение, возвращая значение истина
Обработка обучающего множества (TaskSetWork)
Описание запроса:
Pascal:
Function TaskSetWork(Instruct, Handle: Integer; Var Tasks: Integer; Var Correct: PRealArray; Var Estim: Real): Logic;
C:
Logic TaskSetWork(Integer Instruct, Integer Handle, Integer* Tasks, PRealArray* Correct, Real* Estim)
Описание аргументов:
Instruct — содержит инструкции о способе исполнения.
Handle — номер сеанса в задачнике.
Tasks — число примеров в обучающем множестве.
Correct — указатель на массив, первый элемент которого равен числу правильных ответов на первую подзадачу и т. д.
Estim — средняя оценка решения всех примеров обучающего множества.
Назначение — производит обработку всех примеров обучающего множества.
Переменные, используемые при исполнении запроса
InArray, AnsArray, RelArray — адреса массивов для обменов с задачником.
Answers — указатель на массив вычисленных ответов.
Reliability — указатель на массив коэффициентов уверенности сети в ответах.
Back — адрес массива для обменов с оценкой.
Work — рабочая переменная типа Real для подсчета суммарной оценки.
Weight — рабочая переменная типа Real для веса примера.
Описание исполнения.
Если в любой момент исполнения запроса возникает ошибка при исполнении запросов к другим компонентам, то исполнение запроса прекращается, освобождаются все созданные в нем массивы, возвращается значение ложь, ошибка компонента исполнитель не генерируется.
Значение бит NextExample и StopOnEnd в аргументе Instruct игнорируются.
1. Если в аргументе Instruct установлен бит Gradient и не установлен бит Estimate, то выполнение запроса прекращается, и генерируется ошибка 001 — Некорректное сочетание флагов в аргументе Instruct.
2. Если в аргументе Instruct установлен бит Interpret, то создаются массивы Answers и Reliability того же размера, что и Correct
3. Выполняется следующий фрагмент программы (Обнуление массива количеств правильных ответов)
1. For I = 1 To TLong(Correct[0]) Do
2. Correct[I] = 0
4. Обнуляем счетчик числа примеров: Tasks = 0
5. Обнуляем суммарную оценку: Work = 0
6. Переменной Back присваивается значение Null.
7. Присваивает переменной Data значение Null и генерирует запрос к сети GetNetData с аргументами Null, OutSignals, Data. (Получает от сети выходные сигналы, для выяснения размерности массива Data. Сами значения сигналов не нужны)
8. Если в аргументе Instruct установлен бит Gradient, то
1. Генерируется запрос к сети NullGradient с аргументом Null.
2. Создается массив Back того же размера, что и Data.
9. Генерируется запрос к задачнику Home с аргументом Handle. (Переход на начало обучающего множества)
10. Переменной InArray присваивается значение Null и генерируется запрос к задачнику Get с аргументами Handle, InArray, tbPrepared (Создаем массив InArray для получения от задачника предобработанных входных сигналов)
11. Переменной AnsArray присваивается значение Null и генерируется запрос к задачнику Get с аргументами Handle, AnsArray, tbAnswers (Создаем массив AnsArray для получения от задачника правильных ответов)
12. Если в аргументе Instruct установлен бит Estimate, то создается массив RelArray того же размера, что и AnsArray.
13. Генерируется запрос к задачнику Last с аргументом Handle. (Проверка, существует ли пример)
14. Если запрос Last вернул значение ложь, то
1. Tasks = Tasks + 1
2. Генерируется запрос к задачнику Get с аргументами Handle, InArray, tbPrepared (Получает от задачника предобработанные входные сигналы)
3. Генерируется запрос к сети Forw, с аргументами Null, InArray. (Выполняется прямое функционирование сети)
4. Генерирует запрос к сети GetNetData с аргументами Null, OutSignals, Data. (Получает от сети выходные сигналы)
5. Если в аргументе Instruct установлен бит Interpret, то
1. Генерируется запрос к интерпретатору ответа Interpretate с аргументами Data, Answers, Reliability. (Производит интерпретацию ответа)
2. Если в аргументе Instruct установлен бит PutAnswers, то генерируется запрос к задачнику Put с аргументами Handle, Answers, tbCalcAnswers (Передает задачнику вычисленные ответы)
3. Если в аргументе Instruct установлен бит PutReliability, то генерируется запрос к задачнику Put с аргументами Handle, Reliability, tbCalcReliability (Передает задачнику вычисленные коэффициенты уверенности в ответе)
4. Генерируется запрос к задачнику Get с аргументами Handle, AnsArray, tbAnswers (Получает от задачника правильные ответы)
5. Выполняется следующий фрагмент программы (Подсчитываются правильно полученные ответы)
1. For I = 1 To TLong(Correct[0]) Do
2. If Answers[I] = AnsArray[I] Then TLong(Correct[I]) = TLong(Correct[I]) + 1
6. Если в аргументе Instruct установлен бит Estimate, то
1. Если в аргументе Instruct не установлен бит Interpret, то генерируется запрос к задачнику Get с аргументами Handle, AnsArray, tbAnswers (Получает от задачника правильные ответы)
2. Генерируется запрос к задачнику Get с аргументами Handle, RelArray, tbCalcReliability (Получает от задачника достоверности ответов)
3. Генерируется запрос к оценке Estimate с аргументами Data, Back, AnsArray, RelArray, Direv, Estim. Вместо Direv передается ноль, если в аргументе Instruct установлен бит Gradient, и 1 в противном случае. (Вычисляет оценку примера и, возможно, производные)
4. Генерируется запрос к задачнику Get с аргументами Handle, Weight, tbWeight (Получает от задачника вес примера)
5. Work = Work + Estim * Weight (Подсчитываем суммарную оценку)
6. Если в аргументе Instruct установлен бит PutEstimations, то генерируется запрос к задачнику Put с аргументами Handle, Estim, tbEstimations (Передает задачнику оценку примера)
7. Если в аргументе Instruct установлен бит Gradient, то генерируется запрос к сети Back, с аргументами Null, Back. (Выполняется обратное функционирование сети)
8. Если в аргументе Instruct установлен бит Contrast, то генерируется запрос к контрастеру ContrastExample с аргументом ложь.
9. Генерируется запрос к задачнику Next с аргументом Handle. (Переход к следующему примеру)
10. Переход к шагу 13 алгоритма.
15. Вычисляем среднюю оценку: If Tasks = 0 Then Estim = 0 Else Estim = Work / Task
16. Если в аргументе Instruct установлен бит Contrast, то генерируется запрос к контрастеру ContrastExample с аргументом истина.
17. Освобождаются массивы Data, AnsArray и InArray.
18. Если в аргументе Instruct установлен бит Estimate, то освобождается массив и RelArray.
19. Если в аргументе Instruct установлен бит Interpret, то освобождаются массивы Answers и Reliability.
20. Если Back <> Null освобождается массив Back.
21. Завершает исполнение, возвращая значение истина
Ошибки компонента исполнитель
В табл. 36 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом исполнитель, и действия стандартного обработчика ошибок.
Таблица 36. Ошибки компонента исполнитель и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 001 Некорректное сочетание флагов в аргументе Instruct. Занесение номера в ErrorСтандарт первого уровня компонента учитель
В этом разделе приводится стандарт языка описания компонента учитель. Поскольку часть алгоритмов обучения жестко привязана к архитектуре сети, то в следующем разделе предложен способ опознания «своих» сетей.
Способ опознания сети для методов, привязанных к архитектуре сети
Для опознания типа сети рекомендуется использовать первый параметр сети. Для этого архитектуре сети приписывается уникальный номер, типа Long. Уникальность может поддерживаться, например, за счет использования генератора случайных чисел. Кроме того, при описании параметров сети следует задать отдельный тип параметров для первого параметра и указать минимальную границу равной максимальной и равной номеру архитектуры сети. Также необходимо указать в маске параметров, что этот параметр является необучаемым. Учитель, прежде чем выполнить любую операцию с сетью, читает параметры сети, и проверяет первый параметр сети, интерпретируемый как переменная типа Long, на совпадение с хранимым в учителе номером архитектуры. В случае несовпадения номера в параметрах сети с номером в учителе, учитель генерирует внутреннюю ошибку 601 — несовместимость сети и учителя.
Если учитель работает с сетями любой архитектуры, то процедура опознания архитектуры сети не нужна.
Список стандартных функций
В этом разделе описаны стандартные функции, специфические для компонента учитель. Эти функции соответствуют макросам, использованным в главе «Учитель». Заголовки функций даны на языке описания учителя.
Установить объект обучения (SetInstructionObject)
Заголовок функции:
Function SetInstructionObject (What: Integer; Net: PString): Logic;
Описание аргументов
What может принимать следующие значения (предопределенные константы, приведенные в табл. 11):
Parameters — для обучения параметров сети;
InSignals — для обучения входных сигналов.
Net — имя нейронной сети, которая будет обучаться.
Возможно обучение одного из двух объектов — параметров сети или входных сигналов. Объект обучения должен быть задан до начала собственно обучения. По умолчанию обучается первая сеть в списке нейронных сетей компонента сеть. При необходимости в качестве объекта обучения может быть задана часть сети (см. главу «Описание нейронных сетей»). При сохранении учителя в файле сети объект обучения хранится вместе с учителем. Функция возвращает значение истина, если ее выполнение завершено успешно. В противном случае (например, указанная сеть отсутствует в списке сетей компонента сеть) возвращается значение ложь.
Создание массива (CreateArray)
Заголовок функции:
Function CreateArray: PRealArray;
Аргументов нет.
Функция возвращает указатель на массив, пригодный для хранения массива обучаемых параметров (входных сигналов) сети. Если массив создать не удалось, то возвращается пустой указатель.
Освободить массив (EraseArray)
Заголовок функции:
Function EraseArray(Vec: PRealArray): Logic;
Описание аргументов
Vec — указатель на массив. При вызове содержит адрес освобождаемого массива.
После выполнения функции в аргументе Vec содержится пустой указатель. В случае невозможности освобождения памяти функция генерирует внутреннюю ошибку 604 — некорректная работа с памятью, передает управление обработчику ошибок, выполнение функции завершается, возвращается значение ложь. В противном случае возвращается значение истина.
Случайный массив (RandomArray)
Заголовок функции:
Function RandomArray(Vec: PRealArray): Logic;
Описание аргументов
Vec — указатель на массив. При входе в макрос содержит адрес существующего массива.
В ходе выполнения функции для каждого элемента массива параметров генерируется случайное значение. Для генерации используется генератор случайных чисел, равномерно распределенных на отрезке от нуля до единицы. После получения случайной величины a она преобразуется по формуле a′ = a(amax–amin)–amin к случайной величине, распределенной на отрезке [amin, amax]. Величины amin и amax для параметров сети определяются их типом (см. раздел «Описание элементов»). Для входных сигналов принимается amin=–1, amax=1. Если обучаемым объектом являются параметры, то генерация случайного массива производится путем генерации запроса RandomDirection компонента сеть. Если при выполнении функции возникла ошибка, то генерируется внутренняя ошибка 605 — ошибка при исполнении внешнего запроса, управление передается обработчику ошибок, функция возвращает значение ложь. В противном случае возвращается значение истина.
Модификация массива (Modify)
Заголовок функции:
Function Modify(Direct: PRealArray; OldStep, NewStep: Real): Logic;
Описание аргументов
Direct — указатель на массив направления модификации сети.
OldStep — вес старого массива параметров в модифицированном.
NewStep — вес массива направления модификации в модифицированном массиве параметров.
Эта функция генерирует запрос на модификацию параметров сети (см. раздел «Провести обучение (Modify)»). Вызов запроса имеет вид:
Modify(Net, OldStep, NewStep, Tipe, Direct)
Аргументами запроса являются:
Net — указатель на пустую строку (используется сеть по умолчанию).
OldStep, NewStep — аргументы функции.
Tipe — значение аргумента What в запросе InstructionObject.
Direct — аргумент функции.
Аргумент функции Direct может быть пустым указателем. В этом случае для модификации используется массив градиента, хранящийся вместе с сетью. В случае возникновения ошибки в ходе модификации сети (запрос Modify возвращает значение ложь) генерируется внутренняя ошибка 605 — ошибка при исполнении внешнего запроса, управление передается обработчику ошибок, функция возвращает значение ложь. В противном случае возвращается значение истина.
Оптимизация шага (Optimize)
Заголовок функции:
Function Optimize (Direct: PRealArray; Step: Real): Real;
Описание аргументов
Direct — указатель на массив направления модификации сети.
Step — начальный шаг в направлении Direct.
Действия, выполняемые функцией Optimize, описаны в разделе «Подбор оптимального шага». В случае возникновения ошибки при выполнении функции она генерирует внутреннюю ошибку 605 — ошибка при исполнении внешнего запроса, передает управление обработчику ошибок, функция возвращает значение 0. В противном случае возвращается значение оценки при оптимальном шаге. Следует отметить, что после завершения выполнения функции, параметры сети соответствуют результату выполнения функции Modify(Direct, 1, Step), где Step — значение оптимального шага.
Сохранить массив (SaveArray)
Заголовок функции:
Function SaveArray(Vec: PRealArray): Logic;
Описание аргументов
Vec — указатель на массив.
Функция генерирует запрос nwGetData. После выполнения функции в массиве, на который указывает аргумент Vec, содержится текущий массив параметров. В случае возникновения ошибки в ходе выполнения функции генерируется внутренняя ошибка 605 — ошибка при исполнении внешнего запроса, управление передается обработчику ошибок, функция возвращает значение ложь. В противном случае возвращается значение истина.
Установить параметры (SetArray)
Заголовок функции:
Function SetArray(Vec: PRealArray): Logic;
Описание аргументов
Vec — указатель на массив, содержащий параметры, которые необходимо установить.
Функция генерирует запрос nwSetData.После выполнения функции параметры сети совпадают с параметрами, содержащимися в массиве, на который указывает аргумент Vec. В случае возникновения ошибки в ходе выполнения функции генерируется внутренняя ошибка 605 — ошибка при исполнении внешнего запроса, управление передается обработчику ошибок, функция возвращает значение ложь. В противном случае возвращается значение истина.
Вычислить оценку (Estimate)
Заголовок функции:
Function Estimate(Handle: Integer; All: Logic): Real;
Описание аргументов
Handle — номер сеанса задачника.
All — признак обучения по всему обучающему множеству.
Функция генерирует запрос к исполнителю на вычисление оценки. Если аргумент All содержит значение истина, то обучение производится по всему обучающему множеству, в противном случае — позадачно. В случае возникновения ошибки при выполнении функции он генерирует внутреннюю ошибку 605 — ошибка при исполнении внешнего запроса, передает управление обработчику ошибок, функция возвращает значение 0. В противном случае возвращается значение вычисленной оценки.
Вычислить градиент (CalcGradient)
Заголовок функции:
Function CalcGradient(Handle: Integer; All: Logic): Real;
Описание аргументов
Handle — номер сеанса задачника.
All — признак обучения по всему обучающему множеству.
Функция генерирует запрос к исполнителю на вычисление градиента. Если аргумент All содержит значение истина, то обучение производится по всему обучающему множеству, в противном случае — позадачно. В случае возникновения ошибки при выполнении функции он генерирует внутреннюю ошибку 605 — ошибка при исполнении внешнего запроса, передает управление обработчику ошибок, функция возвращает значение 0. В противном случае возвращается значение вычисленной оценки.
Запустить запрос (GenerateQuest)
Заголовок функции:
Function GenerateQuest(Name: PString; Arguments: PRealArray): Logic
Описание аргументов
Name — указатель на символьную строку, содержащую имя запроса.
Arguments — массив, содержащий адреса аргументов запроса.
Функция генерирует запрос к макрокомпоненту нейрокомпьютер на исполнение запроса, имя которого указано в аргументе Name, с аргументами, адреса которых указаны в аргументе Arguments. Действуют следующие ограничения. В строке, содержащей имя запроса должно содержаться только одно слово — имя запроса. Ведущие и хвостовые пробелы подавляются. В массиве Arguments должно содержаться ровно столько элементов, сколько аргументов у генерируемого запроса. В массив Arguments всегда складываются адреса аргументов, даже если в запрос данный аргумент передается по значению.
(обратно)Язык описания учителя
В отличие от таких компонентов как оценка, сеть и интерпретатор ответа, учитель не является составным объектом. Однако учитель может состоять из множества функций, вызывающих друг друга. Собственно учитель — это процедура, управляющая обучением сети. Ключевые слова, специфические для языка описания учителя приведены в табл. 37.
Библиотеки функций учителя
Библиотеки функций учителя содержат описание функций, необходимых для работы одного или нескольких учителей. Использование библиотек позволяет избежать дублирования функций в различных учителях. Описание библиотеки функций аналогично описанию учителя, но не содержит главной процедуры.
Таблица 37. Ключевые слова специфические для языка описания учителя
Идентификатор Краткое описание Main Начало главной процедуры Instructor Заголовок описания учителя InstrLib Заголовок описания библиотеки функций Used Подключение библиотек функций Init Начало блока инициации InstrStep Начало блока одного шага обучения Close Начало блока завершения обученияБНФ языка описания учителя
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание библиотеки>::= <Заголовок библиотеки> <Описание глобальных переменных> <Описание функций> <Конец описания библиотеки>
<Заголовок библиотеки>::= InstrLib <Имя библиотеки> [Used <Список имен библиотек>]
<Имя библиотеки>::= <Идентификатор>
<Список имен библиотек>::= <Имя используемой библиотеки> [,<Список имен библиотек>]
<Имя используемой библиотеки>::= <Идентификатор>
<Конец описания библиотеки>::= EndInstrLib
<Описание учителя>::= <Заголовок учителя> <Описание глобальных переменных> <Описание функций> <Главная процедура> <Конец описания учителя>
<Заголовок учителя>::= Instructor <Имя библиотеки> [Used <Список имен библиотек>]
<Главная процедура>::= Main<Описание статических переменных> <Описание переменных> <Блок инициации> <Блок шага обучения> <Блок завершения>
<Блок инициации>::= Init <Тело функции>
<Блок шага обучения>::= InstrStep <Выражение типа Logic> <Тело функции>
<Блок завершения>::= Close<Тело функции>
<Конец описания учителя> End Instructor
Описание языка описания учителя
Язык описания учителя является наиболее простым из всех языков описания компонент. Фактически все синтаксические конструкции этого языка описаны в разделе «Общий стандарт». В теле функции, являющемся частью главной процедуры недопустим оператор возврата значения, поскольку главная процедура не является функцией. Три раздела главной функции — блок инициации, блок одного шага обучения и блок завершения являются фрагментами одной процедуры. Выделение этих разделов необходимо для выполнения запроса «Выполнить N шагов обучения». Выполнение главной процедуры происходит следующим образом. Выполняется блок инициации. Выполнение блока одного шага обучения сети производится до тех пор, пока не наступит одно из следующих событий:
1. программа выйдет из блока одного шага обучения сети прямым переходом на метку в другом разделе;
2. нарушится условие, указанное в конструкции InstStep;
3. компонент учитель получит запрос «Прервать обучение сети»;
4. в случае выполнения запроса «Выполнить N шагов обучения» блок одного шага обучения сети выполнен N раз.
Далее выполняется блок завершения обучения.
Пример описания учителя
В данном разделе приведены описания некоторых методов обучения, описанных в разделе «Описание алгоритмов обучения».
Пример 1.
Instructor RandomFire; {Метод случайной стрельбы с уменьшением радиуса}
Main {Обучение ведется по всему обучающему множеству}
Label Exit, Exit1;
Static
Integer Try Name "Число попыток при одном радиусе" Default 5;
Real MinRadius Name "Минимальный радиус, при котором + "продолжается работа"Default 0.001;
String NetName Name "Имя сети" Default "";
Integer What Name "Что обучать" Default Parameters;
Color InstColor Name "Цвет примеров обучающего множества" Default HFFFF; {По умолчанию}
Integer OperColor Name "Операция для отбора цветов" Default CIn;
Var {все примеры, в цвете которых есть хоть один единичный бит}
PRealArray Map, DirectMap; {Для хранения текущего и случайного массивов параметров}
Real Est1, Est2; {Для хранения текущей и случайной оценки}
Real Radius; {Текущий радиус}
Integer TryNum, RadiusNum; {Число попыток, номер использованного радиуса}
Integer Handle; {Номер сеанса задачника}
String QName; {Имя запроса}
Init
Begin
If Not SetInstructionObject(What, @NetName) Then GoTo Exit; {Задаем объекты обучения}
QName = "InitSession"; {Задаем имя запроса}
Map = NewArray(mRealArray, 3); {Создаем массив для аргументов запроса}
If Map = Null Then GoTo Exit;
TPointer(Map^[1]) = @InstColor; {Заносим адрес первого аргумента}
TPointer(Map^[2]) = @OperColor; {Заносим адрес второго аргумента}
TPointer(Map^[3]) = @Handle; {Заносим адрес третьего аргумента}
If Not GenerateQuest(@QName, Map) Then GoTo Exit;{Открываем сеанс работы с задачником}
If Not FreeArray(mRealArray, Map) Then GoTo Exit; {Освобождаем массив для аргументов}
{Собственно начало обучения}
Map = CreateArray; {Создаем вспомогательные массивы}
DirectMap= CreateArray;
If Map = Null Then GoTo Exit;
If DirectMap= Null Then GoTo Exit;
Est1 = Estimate(Handle, True);
If Error <> 0 Then GoTo Exit;
RadiusNum = 1; {Обрабатываем первый радиус}
Radius = 1 / RadiusNum; {Вычисляем первый радиус}
If Not SaveArray(Map) Then GoTo Exit; {Сохраняем начальный массив параметров}
End
InstrStep Radius > MinRadius {Обработка с одним радиусом – один шаг обучения}
Begin
TryNum = 0;
While TryNum < Try Do Begin
If Not SetArray(Map) Then GoTo Exit; {Устанавливаем лучший массив параметров}
If Not RandomArray(DirectMap) Then GoTo Exit; {Генерируется новый массив параметров}
If Not Modify(DirectMap, 1, Radius) Then GoTo Exit; {Модифицируем массив параметров}
Est2 = Estimate(Handle, True);
If Error <> 0 Then GoTo Exit;
If Est1>Est2 Then Begin
If Not SaveArray(Map) Then GoTo Exit; {Сохраняем лучший массив параметров}
Est1 = Est2;
TryNum = 0;
End Else TryNum = TryNum + 1; {Увеличиваем счетчик отказов}
End
RadiusNum = RadiusNum + 1; {Обрабатываем следующий радиус}
Radius = 1 / RadiusNum; {Вычисляем следующий радиус}
End
Close
Begin
Exit:
If Not SetArray(Map) Then; {Восстанавливаем лучший массив параметров}
If Not EraseArray(Мар1) Then; {Освобождаем вспомогательные массивы}
If Not EraseArray(Мар2) Then;
QName = "CloseSession"; {Задаем имя запроса}
Map = NewArray(mRealArray, 1); {Создаем массив для аргументов запроса}
If Map = Null Then GoTo Exit1;
TPointer(Map^[1]) = @Handle; {Заносим адрес единственного аргумента}
If Not GenerateQuest(@QName, Map) Then;{Открываем сеанс работы с задачником}
If Not FreeArray(mRealArray, Map) Then; {Освобождаем массив для аргументов}
Exit1:
End
End Instructor
Пример 2. Библиотека функций
InstrLib Library1; {Библиотека содержит функции для следующего учителя}
{Метод наискорейшего спуска}
Function SDM( Handle : Integer; Step : Real) : Real;
Label Exit, Endd;
Var
Real Est;
Begin
Est = CalcGradient(Handle, True);
If Error <> 0 Then GoTo Exit;
Est =Optimize(Null, Step); {Вызываем функцию подбора оптимального шага}
If Error <> 0Then GoTo Exit;
SDM = Est;
GoTo Endd;
Exit:
SDM = 0;
Endd:
End
{Метод случайного поиска}
Function RDM( Handle : Integer; Step : Real) : Real;
Label Exit, Endd;
Var
Real Est;
PRealArray : Direction;
Begin
Direction = CreateArray; {Создаем вспомогательный массив}
If Direction = Null Then GoTo Exit;
If Not RandomArray(Direction) Then GoTo Exit; {Генерируется новый массив параметров}
If Error <> 0 Then GoTo Exit;
Est =Optimize(Direction, Step); {Вызываем функцию подбора оптимального шага}
If Error <> 0 Then GoTo Exit;
RDM = Est;
GoTo Endd;
Exit:
RDM = 0;
Endd:
End
End InstrLib
Пример 3. Антиовражная процедура обучения.
Instructor kParTan Used Library1; {Антиовражная процедура обучения kParTan}
Main {Обучение ведется по всему обучающему множеству}
Label Exit, Exit1;
Static
Color InstColor Name "Цвет примеров обучающего множества"
Default HFFFF; {По умолчанию}
Integer OperColor Name "Операция для отбора цветов" Default CIn;
{все примеры, в цвете которых есть хоть один единичный бит }
String NetName Name "Имя сети" Default "";
Integer What Name "Что обучать" Default Parameters;
{По умолчанию 2ParTan}
Integer k Name "Число шагов между ParTan шагами" Default 2;
Real AccuracyName "Требуемый минимум оценки"Default 0.00001;
Logic Direction Name "Случайное направление или антиградиент"
11 Default True; {Если истина,то антиградиент }
Var
Integer Handle; {Номер сеанса задачника}
String QName; {Имя запроса}
PRealArray Map1, DirectMap; {Для текущего массива параметров и ParTan направления}
Real Step, ParTanStep; {Длины шагов для оптимизации шага}
Real Est1, Est2; {Для хранения текущей и случайной оценки}
Long I;
Init
Begin
If Not SetInstructionObject(What, @NetName) Then GoTo Exit; {Задаем объекты обучения}
QName = "InitSession"; {Задаем имя запроса}
Map1 = NewArray(mRealArray, 3);{Создаем массив для аргументов запроса}
If Map = Null Then GoTo Exit;
TPointer(Map^[1]) = @InstColor; {Заносим адрес первого аргумента}
TPointer(Map^[2]) = @OperColor; {Заносим адрес второго аргумента}
TPointer(Map^[3]) = @Handle; {Заносим адрес третьего аргумента}
If Not GenerateQuMap(@QName, Map) Then GoTo Exit;{Открываем сеанс работы с задачником}
If Not FreeArray(mRealArray, Map) Then GoTo Exit;{Освобождаем массив для аргументов}
{Собственно начало обучения}
Map = CreateArray; {Создаем вспомогательные массивы}
DirectMap= CreateArray;
If Map = Null Then GoTo Exit;
If DirectMap = Null Then GoTo Exit;
Est1 = Accuracy*10; {Задаем оценку, не удовлетворяющую требованию точности}
Step = 0.005; {Задаем начальное значение шагу}
End
InstrStep Est > Accuracy
Begin
If Not SaveArray(Map1) Then GoTo Exit; {Сохраняем начальный массив параметров}
For I = 1 To k Do Begin {Выполняем k межпартанных шагов}
If Direct Then Est = SDM(Handle, Step) Else Est = RDM(Handle, Step);
If Error <> 0 Then GoTo Exit;
End;
If Not SaveArray(DirectMap) Then GoTo Exit; {Сохраняем конечный массив параметров}
For I = 1 To TLong(Map^[0]) Do
DirectMap^[I] = DirectMap^[I] - Map^[I]; {Вычисляем направление ParTan шага}
ParTanStep = 1; {Задаем начальное значение ParTan шагу}
Est =Optimize(DirectMap, ParTanStep); {Вызываем функцию подбора оптимального шага}
If Error <> 0 Then GoTo Exit;
End
Close
Begin
Exit:
If Not EraseArray(Мар) Then; {Освобождаем вспомогательные массивы}
If Not EraseArray(DirectMap) Then;
QName = "CloseSession"; {Задаем имя запроса}
Map = NewArray(mRealArray, 1); {Создаем массив для аргументов запроса}
If Map = Null Then GoTo Exit1;
TPointer(Map^[1]) = @Handle; {Заносим адрес единственного аргумента}
If Not GenerateQuest(@QName, Map) Then;{Открываем сеанс работы с задачником}
If Not FreeArray(mRealArray, Map) Then; {Освобождаем массив для аргументов}
Exit1:
End
End Instructor
Стандарт второго уровня компонента учитель
Компонент учитель одновременно работает только с одним учителем. Запросы к компоненту учитель можно разбить на следующие группы.
1. Обучение сети.
2. Чтение/запись учителя.
3. Инициация редактора учителя.
4. Работа с параметрами учителя.
Обучение сети
К данной группе относятся три запроса — обучить сеть (InstructNet), провести N шагов обучения (NInstructSteps) и прервать обучение (CloseInstruction).
Обучить сеть (InstructNet)
Описание запроса:
Pascal:
Function InstructNet: Logic;
C:
Logic InstructNet()
Аргументов нет.
Назначение — производит обучение сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Выполняется главная процедура загруженного учителя.
4. Если во время выполнения запроса возникает ошибка, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 605 — ошибка исполнения учителя, управление передается обработчику ошибок, а обработка запроса прекращается.
5. Если во время выполнения запроса возникает ошибка, а значение переменной Error не равно нулю, то обработка запроса прекращается.
Провести N шагов обучения (NInstructSteps)
Описание запроса:
Pascal:
Function NInstructNet(N: Integer): Logic;
C:
Logic NInstructNet(Integer N)
Описание аргумента:
N — число выполнений блока одного шага обучения сети.
Назначение — производит обучение сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Выполняется блок инициации главной процедуры загруженного учителя, N раз выполняется блок одного шага обучения, выполняется блок завершения обучения.
4. Если во время выполнения запроса возникает ошибка, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 605 — ошибка исполнения учителя, управление передается обработчику ошибок, а обработка запроса прекращается.
5. Если во время выполнения запроса возникает ошибка, а значение переменной Error не равно нулю, то обработка запроса прекращается.
Прервать обучение (CloseInstruction)
Описание запроса:
Pascal:
Function CloseInstruction: Logic;
C:
Logic CloseInstruction()
Аргументов нет.
Назначение — прерывает обучение сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Если в момент получения запроса не выполняется ни один из запросов обучить сеть (InstructNet) или провести N шагов обучения (NInstructSteps), то возникает ошибка 606 — неверное использование запроса на прерывание обучения, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Завершается выполнение текущего шага обучения сети.
5. Выполняется блок завершения обучения сети.
6. Если во время выполнения запроса возникает ошибка, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 605 — ошибка исполнения учителя, управление передается обработчику ошибок, а обработка запроса прекращается.
7. Если во время выполнения запроса возникает ошибка, а значение переменной Error не равно нулю, то обработка запроса прекращается.
Чтение/запись учителя
В данном разделе описаны запросы, позволяющие загрузить учителя с диска или из памяти, выгрузить учителя и сохранить текущего учителя на диске или в памяти.
Прочитать учителя (inAdd)
Описание запроса:
Pascal:
Function inAdd(CompName: PString): Logic;
C:
Logic inAdd(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя файла компонента или адрес описания компонента.
Назначение — читает учителя с диска или из памяти.
Описание исполнения.
1. Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя компонента и после пробела имя файла, содержащего компоненту. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания компонента ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
2. Если в данный момент загружен другой учитель, то выполняется запрос inDelete. Учитель считывается из файла или из памяти.
3. Если считывание завершается по ошибке, то возникает ошибка 602 — ошибка считывания учителя, управление передается обработчику ошибок, а обработка запроса прекращается.
Удаление учителя (inDelete)
Описание запроса:
Pascal:
Function inDelete: Logic;
C:
Logic inDelete()
Аргументов нет.
Назначение — удаляет загруженного в память учителя.
Описание исполнения.
1. Если список в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя учителя, управление передается обработчику ошибок, а обработка запроса прекращается.
Запись компонента (inWrite)
Описание запроса:
Pascal:
Function inWrite(Var FileName: PString): Logic;
C:
Logic inWrite(PString* FileName)
Описание аргументов:
CompName — указатель на строку символов, содержащую имя компонента.
FileName — имя файла или адрес памяти, куда надо записать компонент.
Назначение — сохраняет учителя в файле или в памяти.
Описание исполнения.
1. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
2. Если в качестве аргумента FileName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя файла для записи компонента. В противном случае FileName должен содержать пустой указатель. В этом случае запрос вернет в нем указатель на область памяти, куда будет помещено описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то в текст будет включено ключевое слово Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
3. Если во время сохранения компонента возникнет ошибка, то возникает ошибка 603 — ошибка сохранения компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
Инициация редактора учителя
К этой группе запросов относится запрос, который инициирует работу не рассматриваемого в данной работе компонента — редактора учителя.
Редактировать компонент (inEdit)
Описание запроса:
Pascal:
Procedure inEdit(CompName: PString);
C:
void inEdit(PString CompName)
Описание аргумента:
CompName — указатель на строку символов — имя файла или адрес памяти, содержащие описание учителя.
Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя учителя и после пробела имя файла, содержащего описание учителя. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание учителя в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
Если в качестве аргумента CompName передан пустой указатель или указатель на пустую строку, то редактор создает нового учителя.
Работа с параметрами учителя
В данном разделе описаны запросы, позволяющие изменять параметры учителя.
Получить параметры (ingetdata)
Описание запроса:
Pascal:
Function inGetData(Var Param: PRealArray): Logic;
C:
Logic inGetData(PRealArray* Param)
Описание аргумента:
Param — адрес массива параметров.
Назначение — возвращает вектор параметров учителя.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся значения параметров. Параметры заносятся в массив в порядке описания в разделе описания статических переменных.
Получить имена параметров (inGetName)
Описание запроса:
Pascal:
Function inGetName(Var Param: PRealArray): Logic;
C:
Logic inGetName(PRealArray* Param)
Описание аргумента:
Param — адрес массива указателей на названия параметров.
Назначение — возвращает вектор указателей на названия параметров учителя.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся адреса символьных строк, содержащих названия параметров.
Установить параметры (inSetData)
Описание запроса:
Pascal:
Function inSetData(Param: PRealArray): Logic;
C:
Logic inSetData(PRealArray Param)
Описание аргументов:
Param — адрес массива параметров.
Назначение — заменяет значения параметров учителя на значения, переданные, в аргументе Param.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса учитель не загружен, то возникает ошибка 601 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Параметры, значения которых хранятся в массиве, адрес которого передан в аргументе Param, передаются учителю.
Обработка ошибок
В табл. 38 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом учитель, и действия стандартного обработчика ошибок.
Таблица 38. Ошибки компонента учитель и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 601 Несовместимость сети и учителя Занесение номера в Error 602 Ошибка считывания учителя Занесение номера в Error 603 Ошибка сохранения учителя Занесение номера в Error 604 Некорректная работа с памятью Занесение номера в Error 605 Ошибка исполнения учителя Занесение номера в Error 606 Неверное использование запроса на прерывание обучения Занесение номера в ErrorСтандарт первого уровня компонента контрастер
В этом разделе приводится стандарт языка описания компонента контрастер. Компонент контрастер во многом подобен компоненту учитель. Так в языке описания компонента контрастер допускается использование функций, описанных в разделе «Список стандартных функций».
Язык описания контрастера
В отличие от таких компонент как оценка, сеть и интерпретатор ответа, контрастер не является составным объектом. Однако, контрастер может состоять из множества функций, вызывающих друг друга. Собственно контрастер — это процедура, управляющая процессом контрастирования. Ключевые слова, специфические для языка описания контрастера приведены в табл. 39
Библиотеки функций контрастера
Таблица 39. Ключевые слова для языка описания контрастера
Ключевое слово Краткое описание 1. Main Начало главной процедуры 2. Contrast Заголовок описания контрастера 3. ContrLib Заголовок описания библиотеки функций 4. Used Подключение библиотек функций 5. ContrastFunc Глобальная переменная типа функция.Библиотеки функций контрастера содержат описание функций, необходимых для работы одного или нескольких контрастеров. Использование библиотек позволяет избежать дублирования функций в различных контрастерах. Описание библиотеки функций аналогично описанию контрастера, но не содержит главной процедуры.
БНФ языка описания контрастера
Обозначения, принятые в данном расширении БНФ и описание ряда конструкций приведены в разделе «Описание языка описания компонентов».
<Описание библиотеки>::= <Заголовок библиотеки> <Описание глобальных переменных> <Описание функций> <Конец описания библиотеки>
<Заголовок библиотеки>::= ContrLib <Имя библиотеки> [Used <Список имен библиотек>]
<Имя библиотеки>::= <Идентификатор>
<Список имен библиотек>::= <Имя используемой библиотеки> [,<Список имен библиотек>]
<Имя используемой библиотеки>::= <Идентификатор>
<Конец описания библиотеки>::= EndContrLib
<Описание контрастера>::= <Заголовок контрастера> <Описание глобальных переменных> <Описание функций> <Главная процедура> <Конец описания контрастера>
<Заголовок контрастера>::= Contrast <Имя библиотеки> [Used <Список имен библиотек>]
<Главная процедура>::= Main<Описание статических переменных> <Описание переменных> <Тело функции>
<Конец описания контрастера> End Contrast
Описание языка описания контрастера
Язык описания контрастера является наиболее простым из всех языков описания компонент. Фактически все синтаксические конструкции этого языка описаны в разделе «Общий стандарт». В теле функции, являющемся частью главной процедуры недопустим оператор возврата значения, поскольку главная процедура не является функцией.
Контрастер имеет одну глобальную предопределенную переменную ContrastFunc. Эта переменная должна обязательно быть определена — ей нужно присвоить адрес функции, которая будет вызываться каждый раз после того, как нейронная сеть вычислит градиент после решения одного примера. Функция, адрес которой присваивается переменной ContrastFunc должна быть объявлена следующим образом:
Function MyContrast(TheEnd: Logic): Logic;
Значения аргумента TheEnd имеют следующий смысл: истина — обучение ведется позадачно или закончен просмотр обучающего множества; ложь — обработан еще один пример обучающего множества при обучении по всему задачнику в целом. Следует учесть, что при обучении по всему обучающему множеству в целом, нейронная сеть накапливает градиенты всех примеров, так что при первом вызове функции в сети хранится градиент функции оценки по результатам решения первого примера; при втором — результатам решения первых двух примеров и т. д. Функция возвращает значение ложь, если в ходе ее работы произошла ошибка. В противном случае она возвращает значение истина.
Значение переменной ContrastFunc присваивается оператором присваивания:
ContrastFunc = MyContrast
Если значение переменной ContrastFunc не задано, то она указывает на используемую по умолчанию функцию EmptyContrast, которая просто возвращает значение истина.
Стандарт второго уровня компонента контрастер
Компонента контрастер одновременно работает только с одним контрастером. Запросы к компоненте контрастер можно разбить на следующие группы.
1. Контрастирование сети.
2. Чтение/запись контрастера.
3. Инициация редактора контрастера.
4. Работа с параметрами контрастера.
Контрастирование сети
К данной группе относятся три запроса — контрастировать сеть (ContrastNet), прервать контрастирование (CloseContrast) и контрастировать пример (ContrastExample).
Контрастировать сеть(ContrastNet)
Описание запроса:
Pascal:
Function ContrastNet: Logic;
C:
Logic ContrastNet()
Аргументов нет.
Назначение — производит контрастирование сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Выполняется главная процедура загруженного контрастера.
4. Если во время выполнения запроса возникает ошибка, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 705 — ошибка исполнения контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
5. Если во время выполнения запроса возникает ошибка, а значение переменной Error не равно нулю, то обработка запроса прекращается.
Прервать контрастирование (CloseContrast)
Описание запроса:
Pascal:
Function CloseContrast: Logic;
C:
Logic CloseContrast()
Аргументов нет.
Назначение — прерывает контрастирование сети.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Если в момент получения запроса не выполняется запрос ContrastNet, то возникает ошибка 706 — неверное использование запроса на прерывание контрастирования, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Завершается выполнение текущего шага контрастирования сети.
5. Если во время выполнения запроса возникает ошибка, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 705 — ошибка исполнения контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
6. Если во время выполнения запроса возникает ошибка, а значение переменной Error не равно нулю, то обработка запроса прекращается.
Контрастировать пример (ContrastExample)
Описание запроса:
Pascal:
Function ContrastExample(TheEnd: Logic): Logic;
C:
Logic ContrastExample(Logic TheEnd)
Описание аргумента:
TheEnd — значение аргумента имеет следующий смысл: ложь — обработан еще один пример обучающего множества при обучении по всему задачнику в целом.
Назначение — извлекает из сети необходимые для вычисления показателей значимости параметры.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Вызывает функцию, адрес которой хранится в переменной ContrastFunc, передавая ей аргумент TheEnd в качестве аргумента.
3. Если функция ContrastFunc возвращает значение ложь, а значение переменной Error равно нулю, то генерируется внутренняя ошибка 705 — ошибка исполнения контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
4. Если функция ContrastFunc возвращает значение ложь, а значение переменной Error не равно нулю, то обработка запроса прекращается.
5. Запрос в качестве результата возвращает возвращенное функцией ContrastFunc значение.
Чтение/запись контрастера
В данном разделе описаны запросы позволяющие, загрузить контрастер с диска или из памяти, выгрузить контрастера и сохранить текущего контрастера на диске или в памяти.
Прочитать контрастера (cnAdd)
Описание запроса:
Pascal:
Function cnAdd(CompName: PString): Logic;
C:
Logic cnAdd(PString CompName)
Описание аргумента:
CompName — указатель на строку символов, содержащую имя файла компонента или адрес описания компонента.
Назначение — читает контрастера с диска или из памяти.
Описание исполнения.
1. Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя компонента и после пробела имя файла, содержащего компонент. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания компонента ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
2. Если в данный момент загружен другой контрастер, то выполняется запрос cnDelete. Контрастер считывается из файла или из памяти.
3. Если считывание завершается по ошибке, то возникает ошибка 702 — ошибка считывания контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
Удаление контрастера (cnDelete)
Описание запроса:
Pascal:
Function cnDelete: Logic;
C:
Logic cnDelete()
Аргументов нет.
Назначение — удаляет загруженного в память контрастера.
Описание исполнения.
1. Если список в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
Запись контрастера (cnWrite)
Описание запроса:
Pascal:
Function cnWrite(Var FileName: PString): Logic;
C:
Logic cnWrite(PString* FileName)
Описание аргументов:
CompName — указатель на строку символов, содержащую имя контрастера.
FileName — имя файла или адрес памяти, куда надо записать контрастера.
Назначение — сохраняет контрастера в файле или в памяти.
Описание исполнения.
1. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
2. Если в качестве аргумента FileName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя файла, для записи компонента. В противном случае FileName должен содержать пустой указатель. В этом случае запрос вернет в нем указатель на область памяти, куда будет помещено описание компонента в формате для записи на диск. Если описание не вмещается в одну область памяти, то в текст будет включено ключевое слово Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
3. Если во время сохранения компонента возникнет ошибка, то возникает ошибка 703 — ошибка сохранения контрастера, управление передается обработчику ошибок, а обработка запроса прекращается.
Инициация редактора контрастера
К этой группе запросов относится запрос, который инициирует работу не рассматриваемого в данной работе компонента — редактора контрастера.
Редактировать контрастера (cnEdit)
Описание запроса:
Pascal:
Procedure cnEdit(CompName: PString);
C:
void cnEdit(PString CompName)
Описание аргумента:
CompName — указатель на строку символов — имя файла или адрес памяти, содержащие описание контрастера.
Если в качестве аргумента CompName дана строка, первые четыре символа которой составляют слово File, то остальная часть строки содержит имя контрастера и после пробела имя файла, содержащего описание контрастера. В противном случае считается, что аргумент CompName содержит указатель на область памяти, содержащую описание контрастера в формате для записи на диск. Если описание не вмещается в одну область памяти, то допускается включение в текст описания ключевого слова Continue, за которым следует четыре байта, содержащие адрес следующей области памяти.
Если в качестве аргумента CompName передан пустой указатель или указатель на пустую строку, то редактор создает нового контрастера.
Работа с параметрами контрастера
В данном разделе описаны запросы, позволяющие изменять параметры контрастера.
Получить параметры (cnGetData)
Описание запроса:
Pascal:
Function cnGetData(Var Param: PRealArray): Logic;
C:
Logic cnGetData(PRealArray* Param)
Описание аргумента:
Param — адрес массива параметров.
Назначение — возвращает вектор параметров контрастера.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся значения параметров. Параметры заносятся в массив в порядке описания в разделе описания статических переменных.
Получить имена параметров (cnGetName)
Описание запроса:
Pascal:
Function cnGetName(Var Param: PRealArray): Logic;
C:
Logic cnGetName(PRealArray* Param)
Описание аргумента:
Param — адрес массива указателей на названия параметров.
Назначение — возвращает вектор указателей на названия параметров.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. В массив, адрес которого передан в аргументе Param, заносятся адреса символьных строк, содержащих названия параметров.
Установить параметры (cnSetData)
Описание запроса:
Pascal:
Function cnSetData(Param: PRealArray): Logic;
C:
Logic cnSetData(PRealArray Param)
Описание аргументов:
Param — адрес массива параметров.
Назначение — заменяет значения параметров контрастера на значения, переданные, в аргументе Param.
Описание исполнения.
1. Если Error <> 0, то выполнение запроса прекращается.
2. Если в момент получения запроса контрастер не загружен, то возникает ошибка 701 — неверное имя компонента, управление передается обработчику ошибок, а обработка запроса прекращается.
3. Параметры, значения которых хранятся в массиве, адрес которого передан в аргументе Param, передаются контрастеру.
Обработка ошибок
В табл. 40 приведен полный список ошибок, которые могут возникать при выполнении запросов компонентом контрастер, и действия стандартного обработчика ошибок.
Таблица 40. Ошибки компонента контрастер и действия стандартного обработчика ошибок.
№ Название ошибки Стандартная обработка 701 Несовместимость сети и контрастера Занесение номера в Error 702 Ошибка считывания контрастера Занесение номера в Error 703 Ошибка сохранения контрастера Занесение номера в Error 704 Некорректная работа с памятью Занесение номера в Error 705 Ошибка исполнения контрастера Занесение номера в Error 706 Неверное использование запроса на прерывание контрастирования Занесение номера в ErrorЛИТЕРАТУРА
1. Айвазян С.А., Бежаева З.И., Староверов О.В. Классификация многомерных наблюдений. — М.: Статистика, 1974.— 240 с.
2. Айзерман М.А., Браверман Э.М., Розоноэр Л.И. Метод потенциальных функций в теории обучения машин. М.: Наука, 1970.— 383 с.
3. Анастази А. Психологическое тестирование. М. Педагогика, 1982. Книга 1. 320 с.; Книга 2. 360 с.
4. Андерсон Т. Введение в многомерный статистический анализ. — М.: Физматгиз, 1963. 500 с.
5. Андерсон Т. Статистический анализ временных рядов. М.: Мир, 1976. 755 с.
6. Ануфриев А.Ф. Психодиагностика как деятельность и научная дисциплина // Вопросы психологии, 1994, № 2. С. 123–130.
7. Аркадьев А.Г., Браверман Э.М. Обучение машины классификации объектов. — М.: Наука, 1971.— 172 с.
8. Ахапкин Ю.К., Всеволдов Н.И., Барцев С.И. и др. Биотехника — новое направление компьютеризации. Серия "Теоретическая и прикладная биофизика", М: изд. ВИНИИТИ, 1990. 144 с.
9. Барцев С.И. Некоторые свойства адаптивных сетей. Препринт ИФ СО АН СССР, Красноярск, 1987, № 71Б, 17 с.
10. Барцев С.И., Гилев С.Е., Охонин В.А. Принцип двойственности в организации адаптивных систем обработки информации// Динамика химических и биологических систем, Новосибирск, Наука, 1989, с. 6–55.
11. Барцев С.И., Ланкин Ю.П. Моделирование аналоговых адаптивных сетей. Препринт Института биофизики СО РАН, Красноярск, 1993, № 203Б, 36 с.
12. Барцев С.И., Ланкин Ю.П. Сравнительные свойства адаптивных сетей с полярными и неполярными синапсами. Препринт Института биофизики СО РАН, Красноярск, 1993, № 196Б, 26 с.
13. Барцев С.И., Машихина Н.Ю., Суров С.В. Нейронные сети: подходы к аппаратной реализации. Препринт ИФ СО АН СССР, Красноярск, 1990, № 122Б, 14 с.
14. Барцев С.И., Охонин В.А. Адаптивные сети обработки информации. Препринт ИФ СО АН СССР, Красноярск, 1986, № 59Б, 20 с.
15. Барцев С.И., Охонин В.А. Адаптивные сети, функционирующие в непрерывном времени // Эволюционное моделирование и кинетика, Новосибирск, Наука, 1992, с. 24–30.
16. Беркинблит М.Б., Гельфанд И.М., Фельдман А.Г. Двигательные задачи и работа параллельных программ // Интеллектуальные процессы и их моделирование. Организация движения. — М.: Наука, 1991.— С. 37–54.
17. Боннер Р.Е. Некоторые методы классификации // Автоматический анализ изображений. — М.: Мир, 1969.— С. 205–234.
18. Борисов А.В., Гилев С.Е., Головенкин С.Е., Горбань А.Н., Догадин С.А., Коченов Д.А., Масленникова Е.В., Матюшин Г.В., Миркес Е.М., Ноздрачев К.Г., Россиев Д.А., Савченко А.А., Шульман В.А. Нейроимитатор «multineuron» и его применения в медицине. // Математическое обеспечение и архитектура ЭВМ: Материалы научно-технической конференции "Проблемы техники и технологий XXI века", 22–25 марта 1994 г. / КГТУ. Красноярск, 1994. С. 14–18.
19. Браверман Э.М., Мучник И.Б. Структурные методы обработки эмпирирических данных. — М.: Наука. Главная редакция физико-математической литературы. 1983. — 464 с.
20. Букатова И.Л. Эволюционное моделирование и его приложения. — М.: Наука, 1979.— 231 с.
21. Бурлачук Л.Ф., Коржова Е.Ю. К построению теории "измеренной индивидуальности" в психодиагностике // Вопросы психологии 1994, n5. С. 5–11.
22. Вавилов Е.И., Егоров Б.М., Ланцев В.С., Тоценко В.Г. Синтез схем на пороговых элементах. — М.: Сов. радио, 1970.
23. Вапник В.Н., Червоненкис А.Ф. Теория распознавания образов. — М.: Наука, 1974.
24. Веденов А.А. Моделирование элементов мышления. — М.: Наука, 1988.
25. Гаврилова Т.А., Червинская К.Р., Яшин А.М. Формирование поля знаний на примере психодиагностики // Изв. АН СССР. Техн. кибернетика, 1988, № 5.— С. 72–85.
26. Галушкин А.И. Синтез многослойных схем распознавания образов. — М.: Энергия, 1974.
27. Галушкин А.И., Фомин Ю.И. Нейронные сети как линейные последовательные машины. — М.: Изд-во МАИ, 1991.
28. Гельфанд И.М., Цетлин М.Л. О математическом моделировании механизмов центральной нервной системы // Модели структурно-функциональной организации некоторых биологических систем. — М.: Наука, 1966.— С. 9–26.
29. Гилев С.Е. "Сравнение методов обучения нейронных сетей", // Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, сс. 80–81.
30. Гилев С.Е. "Сравнение характеристических функций нейронов", // Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, 1995, с. 82
31. Гилев С.Е. Forth-propagation — метод вычисления градиентов оценки // Тезисы докладов II Всероссийского рабочего семинара "Нейроинформатика и ее приложения" (Красноярск, 7-10 октября 1994 г.) / Красноярск: Изд-во КГТУ, 1994, с. 36–37.
32. Гилев С.Е. Автореф. дисс. канд. физ. — мат. наук // Красноярск, КГТУ, 1997.
33. Гилев С.Е. Алгоритм сокращения нейронных сетей, основанный на разностной оценке вторых производных целевой функции // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 45–46.
34. Гилев С.Е. Гибрид сети двойственности и линейной сети// Нейроинформатика и нейрокомпьютеры/ тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 25.
35. Гилев С.Е. Метод получения градиентов оценки по подстроечным параметрам без использования back propagation // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 91–100.
36. Гилев С.Е. Нейросеть с квадратичными сумматорами// Нейроинформатика и нейрокомпьютеры/ тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 11–12.
37. Гилев С.Е., Горбань А.Н. “Плотность полугрупп непрерывных функций”.— 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 7–9.
38. Гилев С.Е., Горбань А.Н. О полноте класса функций, вычислимых нейронными сетями. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 1. Изд. Института математики СО РАН. С. 6.
39. Гилев С.Е., Горбань А.Н., Миркес Е.М. Малые эксперты и внутренние конфликты в обучаемых нейронных сетях // Доклады Академии Наук СССР. — 1991.— Т.320, N.1.— С. 220–223.
40. Гилев С.Е., Горбань А.Н., Миркес Е.М., Коченов Д.А., Россиев Д.А. "Определение значимости обучающих параметров для принятия нейронной сетью решения об ответе"// Нейроинформатика и нейрокомпьютеры/ тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 8.
41. Гилев С.Е., Горбань А.Н., Миркес Е.М., Коченов Д.А., Россиев Д.А. "Нейросетевая программа MultiNeuron"// Нейроинформатика и нейрокомпьютеры/ тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 9.
42. Гилев С.Е., Горбань А.Н., Миркес Е.М., Новоходько А.Ю. "Пакет программ имитации различных нейронных сетей"// Нейроинформатика и нейрокомпьютеры/ тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 7.
43. Гилев С.Е., Коченов Д.А., Миркес Е.М., Россиев Д.А. Контрастирование, оценка значимости параметров, оптимизация их значений и их интерпретация в нейронных сетях // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 66–78.
44. Гилев С.Е., Миркес Е.М. Обучение нейронных сетей // Эволюционное моделирование и кинетика. Новосибирск: Наука, 1992. С. 9–23.
45. Гилев С.Е., Миркес Е.М., Новоходько А.Ю., Царегородцев В.Г., Чертыков П.В. Проект языка описания нейросетевых автоматов // Тезисы докладов II Всероссийского рабочего семинара "Нейроинформатика и ее приложения" (Красноярск, 7-10 октября 1994 г.) / Красноярск: Изд-во КГТУ, 1994, с. 35.
46. Гилева Л.В., Гилев С.Е., Горбань А.Н. Нейросетевой бинарный классификатор «clab» (описание пакета программ). Красноярск: Ин-т биофизики СО РАН, 1992. 25 c. Препринт № 194 Б.
47. Гилева Л.В., Гилев С.Е., Горбань А.Н., Гордиенко П.В., Еремин Д.И., Коченов Д.А., Миркес Е.М., Россиев Д.А., Умнов Н.А. Нейропрограммы. Учебное пособие: В 2 ч. // Красноярск, Красноярский государственный технический университет, 1994.260 с.
48. Гилл Ф., Мюррей У., Райт М. Практическая оптимизация. М.: Мир,1985. 509 с.
49. Головенкин С.Е., Горбань А.Н., Шульман В.А., Россиев Д.А., Назаров Б.Н., Мосина В.А., Зинченко О.П., Миркес Е.М., Матюшин Г.В., Бугаенко Н.Н. База данных для апробации систем распознавания и прогноза: осложнения инфаркта миокарда // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 47.
50. Головенкин С.Е., Назаров Б.В., Матюшин Г.В., Россиев Д.А., Шевченко В.Ф., Зинченко О.П., Токарева И.М. Прогнозирование возникновения мерцательной аритмии в острый и подострый периоды инфаркта миокарда с помощью компьютерных нейронных сетей // Актуальные проблемы реабилитации больных с сердечно-сосудистыми заболеваниями. Тез. докл. симпозиума 18–20 мая 1994 г., "Красноярское Загорье", Красноярск.1994.— С.28.
51. Головенкин С.Е., Россиев Д.А., Назаров Б.В., Шульман В.А., Матюшин Г.В., Зинченко О.П. Прогнозирование возникновения фибрилляции предсердий как осложнения инфаркта миокарда с помощью нейронных сетей // Диагностика, информатика и метрология — 94.— Тез. научно-технической конференции (г. Санкт-Петербург, 28–30 июня 1994 г.).С.-Петербург. — 1994.— С.349.
52. Головенкин С.Е., Россиев Д.А., Шульман В.А., Матюшин Г.В., Шевченко В.Ф. Прогнозирование сердечной недостаточности у больных со сложными нарушениями сердечного ритма с помощью нейронных сетей // Диагностика, информатика и метрология — 94.— Тез. научно-технической конференции (г. Санкт-Петербург, 28–30 июня 1994 г.). — С.-Петербург. — 1994.С.350–351.
53. Голубь Д.Н., Горбань А.Н. Многочастичные сетчатки для ассоциативной памяти. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 3. Изд. Института математики СО РАН. С. 271.
54. Горбань А.Н, НейроКомп или 9 лет нейрокомпьютерных исследований в Красноярске // Актуальные проблемы информатики, прикладной математики и механики, ч. 3, Новосибирск — Красноярск: из-во СО РАН, 1996. — с. 13–37.
55. Горбань А.Н. Алгоритмы и программы быстрого обучения нейронных сетей. // Эволюционное моделирование и кинетика. Новосибирск: Наука, 1992. С. 36–39.
56. Горбань А.Н., Обобщенная аппроксимационная теорема и вычислительные возможности нейронных сетей // Сибирский журнал вычислительной математики / РАН. Сиб. Отд. — Новосибирск, 1998. — т. 1, № 1, — с. 11–24.
57. Горбань А.Н. Быстрое дифференцирование сложных функций и обратное распространение ошибки // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 54–56.
58. Горбань А.Н. Быстрое дифференцирование, двойственность и обратное распространение ошибки / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
59. Горбань А.Н. Возможности нейронных сетей / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
60. Горбань А.Н. Двойственность в сетях автоматов // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 32–66.
61. Горбань А.Н. Мы предлагаем для контроля качества использовать нейрокомпьютеры // Стандарты и качество, 1994, № 10, с. 52.
62. Горбань А.Н. Нейрокомп // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 3–31.
63. Горбань А.Н. Нейрокомпьютер, или Аналоговый ренессанс. Мир ПК, 1994. № 10. С. 126–130.
64. Горбань А.Н. Обобщение аппроксимационной теоремы cтоуна // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 59–62.
65. Горбань А.Н. Обучение нейронных сетей. М.: изд. СССР-США СП «ParaGraph», 1990. 160 с. (English Translation: AMSE Transaction, Scientific Siberian, A, 1993. Vol. 6. Neurocomputing. PP. 1-134).
66. Горбань А.Н. Проблема скрытых параметров и задачи транспонированной регрессии // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 57–58.
67. Горбань А.Н. Проекционные сетчатки для обработки бинарных изображений. // Математическое обеспечение и архитектура ЭВМ / Материалы научно-технической конференции "Проблемы техники и технологий XXI века", 22–25 марта 1994 г., Красноярск: изд. КГТУ, 1994. С. 50–54.
68. Горбань А.Н. Размытые эталоны в обучении нейронных сетей // Тезисы докладов II Всероссийского рабочего семинара "Нейроинформатика и ее приложения" (Красноярск, 7-10 октября 1994 г.) / Красноярск: Изд-во КГТУ, 1994, с. 6–9.
69. Горбань А.Н. Решение задач нейронными сетями / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
70. Горбань А.Н. Системы с наследованием и эффекты отбора. // Эволюционное моделирование и кинетика. Новосибирск: Наука, 1992. С. 40–71.
71. Горбань А.Н. Точное представление многочленов от нескольких переменных с помощью линейных функций, операции суперпозиции и произвольного нелинейного многочлена от одного переменного // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 63–65.
72. Горбань А.Н. Этот дивный новый компьютерный мир. Заметки о нейрокомпьютерах и новой технической революции // Математическое обеспечение и архитектура ЭВМ / Материалы научно-технической конференции "Проблемы техники и технологий XXI века", 22–25 марта 1994 г., Красноярск: изд. КГТУ, 1994. С. 42–49.
73. Горбань А.Н., Дружинина Н.В., Россиев Д.А. “Нейросетевая интерпретация спектрофотометрического способа исследования содержания меланина в ресницах и подсчет значимости обучающих параметров неросети с целью диагностики увеальных меланом”.— 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 94.
74. Горбань А.Н., Кошур В.Д. Нейросетевые модели и методы решения задач динамики сплошных сред и физики взаимодействующих частиц // 10 Зимняя школа по механике сплошных сред (тезисы докладов) / Екатеринбург: УрО РАН, 1995. С. 75–77.
75. Горбань А.Н., Миркес Е.М. Компоненты нейропрограмм // тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 17
76. Горбань А.Н., Миркес Е.М. Логически прозрачные нейронные сети для производства знаний из данных. Вычислительный центр СО РАН в г. Красноярске. Красноярск, 1997. 12 с., библиогр. 12 назв. (Рукопись деп. в ВИНИТИ 17.07.97, № 2434-В97)
77. Горбань А.Н., Миркес Е.М. Нейронные сети ассоциативной памяти, функционирующие в дискретном времени. Вычислительный центр СО РАН в г. Красноярске. Красноярск, 1997. 23 с., библиогр. 8 назв. (Рукопись деп. в ВИНИТИ 17.07.97, № 2436-В97)
78. Горбань А.Н., Миркес Е.М. “Информационная емкость тензорных сетей”.— 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 22–23.
79. Горбань А.Н., Миркес Е.М. “Помехоустойчивость тензорных сетей”.— 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 24–25.
80. Горбань А.Н., Миркес Е.М. «Тензорные сети ассоциативной памяти». — 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 20–21.
81. Горбань А.Н., Миркес Е.М. Кодирование качественных признаков для нейросетей // Тезисы докладов II Всероссийского рабочего семинара "Нейроинформатика и ее приложения" (Красноярск, 7-10 октября 1994 г.) / Красноярск: Изд-во КГТУ, 1994, с. 29.
82. Горбань А.Н., Миркес Е.М. Контрастирование нейронных сетей, тезисы докладов iii Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, сс. 78-79
83. Горбань А.Н., Миркес Е.М. Логически прозрачные нейронные сети, Нейроинформатика и ее приложения: тезисы докладов III Всеросийского семинара, Красноярск: Изд-во КГТУ, с. 32
84. Горбань А.Н., Миркес Е.М. Нейросетевое распознавание визуальных образов «eye» (описание пакета программ) Красноярск: Ин-т биофизики СО РАН, 1992. 36 c. Препринт № 193 Б.
85. Горбань А.Н., Миркес Е.М. Оценки и интерпретаторы ответа для сетей двойственного функционирования. Вычислительный центр СО РАН в г. Красноярске. Красноярск, 1997. 24 с., библиогр. 8 назв. (Рукопись деп. в ВИНИТИ 25.07.97, № 2511-В97)
86. Горбань А.Н., Миркес Е.М. Функциональные компоненты нейрокомпьютера // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 79–90.
87. Горбань А.Н., Миркес Е.М., Свитин А.П. Метод мультиплетных покрытий и его использование для предсказания свойств атомов и молекул. — Журнал физ. химии, 1992. Т. 66, № 6. С. 1503–1510.
88. Горбань А.Н., Миркес Е.М., Свитин А.П. Полуэмпирический метод классификации атомов и интерполяции их свойств. // Математическое моделирование в химии и биологии. Новые подходы. Новосибирск: Наука, 1992. С. 204–220.
89. Горбань А.Н., Новоходько А.Ю. Нейронные сети в задаче транспонированной регрессии. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 2. Изд. Института математики СО РАН. С. 160–161.
90. Горбань А.Н., Новоходько А.Ю., Царегородцев В.Г. «Нейросетевая реализация транспонированной задачи линейной регрессии»:.— 4 Всероссийский рабочий семинар “Нейроинформатика и ее приложения”, 5–7 октября 1996 г., Тезисы докладов. Красноярск: изд. КГТУ, 1996, с. 37–39.
91. Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере // Новосибирск: Наука, 1996.— 276 с.
92. Горбань А.Н., Россиев Д.А., Бутакова Е.В., Гилев С.Е., Головенкин С.Е., Догадин С.А., Коченов Д.А., Масленикова Е.В., Матюшин Г.В., Миркес Е.М., Назаров Б.В., Ноздрачев К.Г., Савченко А.А., Смирнова С.В., Чертыков П.А., Шульман В.А. Медицинские и физиологические применения нейроимитатора «MultiNeuron» // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 101–113.
93. Горбань А.Н., Россиев Д.А., Головенкин С.Е., Шульман В.А., Матюшин Г.В. Нейросистема прогнозирования осложнений инфаркта миокарда. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 1. Изд. Института математики СО РАН. С. 40.
94. Горбань А.Н., Россиев Д.А., Коченов Д.А. Применение самообучающихся нейросетевых программ. Раздел 1. Введение в нейропрограммы: Учебно-методическое пособие для студентов специальностей 22.04 и 55.28.00 всех форм обучения. Красноярск: Изд-во СТИ, 1994. 24 с.
95. Горбань А.Н., Сенашова М.Ю. Метод обратного распространения точности. Препринт ВЦ СО РАН, Красноярск, 1996, № 17, 8 с.
96. Горбань А.Н., Сенашова М.Ю. Погрешности в нейронных сетях. Вычислительный центр СО РАН в г. Красноярске. Красноярск, 1997. 38 с., библиогр. 8 назв. (Рукопись деп. в ВИНИТИ 25.07.97, № 2509-В97)
97. Горбань А.Н., Сенашова М.Ю. Погрешности в нейронных сетях. Рукопись деп. в ВИНИТИ, 25.07.97, № 2509-В97, 1997, 38 с.
98. Горбань А.Н., Фриденберг В.И. Новая игрушка человечества. МИР ПК, 1993, № 9. С. 111–113.
99. Горбань А.Н., Хлебопрос Р.Г. Демон Дарвина. Идея оптимальности и естественный отбор. М.: Наука, 1988. 208 с.
100. Гордиенко П.В. Стратегии контрастирования // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 69.
101. Грановская Р.М., Березная И.Я. Интуиция и искусственный интеллект. — Л.: ЛГУ, 1991.— 272 с.
102. Гутчин И.Б., Кузичев А.С. Бионика и надежность. М.: Наука, 1967.
103. Демиденко Е.З. Линейная и нелинейная регрессия. — М.: Финансы и статистика, 1981.— 302 с.
104. Деннис Дж. мл., Шнабель Р. Численные методы безусловной оптимизации и решения нелинейных уравнений. М.: Мир, 1988. 440 с.
105. Дертоузос М. Пороговая логика. — М.: Мир, 1967.
106. Джордж Ф. Мозг как вычислительная машина. М. Изд-во иностр. лит., 1963. 528 с.
107. Дианкова Е.В., Квичанский А.В., Мухамадиев Р.Ф., Мухамадиева Т.А., Терехов С.А. Некоторые свойства нелинейных нейронных сетей. Исследование трехнейронной модели// Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, 1995, с. 86
108. Дискусия о нейрокомпьютерах / Под ред. В.И.Крюкова. Пущино, 1988.
109. Дорофеюк А.А. Алгоритмы автоматической классификации (обзор). — Автоматика и телемеханика, 1971, № 12. С. 78–113.
110. Доррер М.Г., Горбань А.Н., Копытов А.Г., Зенкин В.И. Психологическая интуиция нейронных сетей // Нейроинформатика и ее приложения: Материалы iii Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 114–127.
111. Дуда Р., Харт П. Распознавание образов и анализ сцен. М.: Мир, 1976.— 512 с.
112. Дунин-Барковский В.Л. Информационные процессы в нейронных структурах. — М.: Наука, 1978.
113. Дунин-Барковский В.Л.Нейрокибернетика, нейроинформатика, нейрокомпьютеры / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
114. Дунин-Барковский В.Л. Нейронные схемы ассоциативной памяти // Моделирование возбудимых структур. Пущино: изд. ЦБИ, 1975. С. 90–141.
115. Дюк В.А. Компьютерная психодиагностика. Санкт-Петербург: Братство, 1994.— 364 с.
116. Ермаков С.В., Мышов К.Д., Охонин В.А. К вопросу о математическом моделировании базового принципа мышления человека. Препринт ИБФ СО РАН, Красноярск, 1992, № 173Б, 36 с.
117. Журавлев Ю.И. Об алгебраическом подходе к решению задач распознавания и классификации // Проблемы кибернетики. — М.: Наука, 1978, вып. 33.— С. 5–68.
118. Загоруйко Н.Г. Методы распознавания и их применение. М.: Сов. радио, 1972.— 206 с.
119. Загоруйко Н.Г., Елкина В.Н., Лбов Г.С. Алгоритмы обнаружения эмпирических закономерностей. — Новосибирск: Наука, 1985.— 110 с.
120. Захарова Л.Б., Полонская М.Г., Савченко А.А. и др. Оценка антропологического напряжения пришлого населения промышленной зоны Заполярья (биологический аспект) // Препринт ИБФ СО РАН. Красноярск, 1989. № 110Б. 52 с.
121. Захарова Л.М., Киселева Н.Е. Мучник И.Б., Петровский А.М., Сверчинская Р.Б. Анализ развития гипертонической болезни по эмпирическим данным. — Автоматика и телемеханика, 1977, № 9. С. 114–122.
122. Ивахненко А.Г. «Персептроны». — Киев: Наукова думка, 1974.
123. Ивахненко А.Г. Самообучающиеся системы распознавания и автоматического регулирования. — Киев: Техника, 1969.— 392 с.
124. Искусственный интеллект: В 3-х кн. Кн. 1. Системы общения и экспертные системы: Справочник / под ред. Э.В.Попова. — М.: Радио и связь, 1990.— 464 с.
125. Искусственный интеллект: В 3-х кн. Кн. 2. Модели и методы: Справочник / под ред. Д.А. Поспелова. — М.: Радио и связь, 1990.— 304 с.
126. Итоги науки и техники. Сер. "Физ. и Матем. модели нейронных сетей" /Под ред. А.А.Веденова. — М.: Изд-во ВИНИТИ, 1990-92 — Т. 1–5.
127. Квичанский А.В., Дианкова Е.В., Мухамадиев Р.Ф., Мухамадиева Т.А. Программный продукт nnn для исследования свойств нелинейных сетей в компьютерном эксперименте // Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, 1995, с. 10
128. Кендалл М., Стьюарт А. Статистические выводы и связи. 11 М.: Наука, 1973.— 900 с.
129. Кирдин А.Н., Новоходько А.Ю., Царегородцев В.Г. Скрытые параметры и транспонированная регрессия/ Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
130. Костюк Ф.Ф. Инфаркт миокарда. Красноярск: Офсет, 1993. 224 с.
131. Кохонен Т. Ассоциативная память. — М.: Мир, 1980.
132. Кохонен Т. Ассоциативные запоминающие устройства. — М.: Мир, 1982.
133. Коченов Д.А., Миркес Е.М. "Определение чувствительности нейросети к изменению входных сигналов", тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 61
134. Коченов Д.А., Миркес Е.М. "Синтез управляющих воздействий", тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 31
135. Коченов Д.А., Миркес Е.М., Россиев Д.А. Автоматическая подстройка входных данных для получения требуемого ответа нейросети // Проблемы информатизации региона. Труды межрегиональной конференции (Красноярск, 27–29 ноября 1995 г.). Красноярск, 1995.— С.156.
136. Коченов Д.А., Миркес Е.М., Россиев Д.А. Метод подстройки параметров примера для получения требуемого ответа нейросети // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.39.
137. Коченов Д.А., Россиев Д.А. Аппроксимация функций класса С[a,b] нейросетевыми предикторами // Тезисы докладов рабочего семинара "Нейроинформатика и нейрокомпьютеры", Красноярск, 8-11 октября 1993 г., Красноярск. — 1993.— С.13.
138. Крайзмер Л.П., Матюхин С.А., Майоркин С.Г. Память кибернетических систем (Основы мнемологии). — М.: Сов. радио, 1971.
139. Куссуль Э.М., Байдык Т.Н. Разработка архитектуры нейроподобной сети для распознавания формы объектов на изображении // Автоматика. — 1990.— № 5.— С. 56–61.
140. Кушаковский М.С. Аритмии сердца. Санкт-Петербург: Гиппократ, 1992. 544 с.
141. Лбов Г.С. Методы обработки разнотипных экспериментальных данных. — Новосибирск: Наука, 1981.— 157 с.
142. Лоули Д., Максвелл А. Факторный анализ как статистический метод. — М.: Мир, 1967.— 144 с.
143. Мазуров В.Д. Метод комитетов в задачах оптимизации и классификации. — М.: Наука, Гл. ред. физ. — мат. лит., 1990. 248 с.
144. МакКаллок У.С., Питтс В. Логическое исчисление идей, относящихся к нервной активности // Нейрокомпьютер, 1992. №|3, 4. С. 40–53.
145. Масалович А.И. От нейрона к нейрокомпьютеру // Журнал доктора Добба. — 1992.— N.1.— С. 20–24.
146. Минский М., Пайперт С. Персептроны. — М.: Мир, 1971.
147. Миркес Е.М. Глобальные и локальные оценки для сетей двойственного функционирования. Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, сс. 76-77
148. Миркес Е.М. Использование весов примеров при обучении нейронных сетей. тезисы докладов III Всероссийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 75
149. Миркес Е.М. Логически прозрачные нейронные сети и производство явных знаний из данных / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998. С. 283–292
150. Миркес Е.М. Нейроинформатика и другие науки // Вестник КГТУ, 1996, вып. 6, с. 5–33.
151. Миркес Е.М. Нейронные сети ассоциативной памяти / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998. С. 264–282.
152. Миркес Е.М. Обучение сетей с пороговыми нейронами. Тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 72
153. Миркес Е.М. Оценки и интерпретаторы ответа для сетей двойственного функционирования. Тезисы докладов III Всероссийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, сс. 73-74
154. Миркес Е.М., Свитин А.П. Применение метода ассоциативных сетей для прогнозирования переносов заряда при адсорбции молекул. // Эволюционное моделирование и кинетика. Новосибирск: Наука, 1992. С. 30–35.
155. Миркес Е.М., Свитин А.П., Фет А.И. Массовые формулы для атомов. // Математическое моделирование в химии и биологии. Новые подходы. Новосибирск: Наука, 1992. С. 199–204.
156. Миркин Б.Г. Анализ качественных признаков и структур. М.: Статистика, 1980.— 319 с.
157. Мкртчян С.О. Проектирование логических устройств ЭВМ на нейронных элементах. — М.: Энергия, 1977.
158. Мостеллер Ф., Тьюки Дж. Анализ данных и регрессия. — М.: Финансы и статистика, 1982.— 239 с.
159. Муллат И.Э. Экстремальные подсистемы монотонных систем. I, II, III. — Автоматика и телемеханика, 1976, № 5. С. 130–139; 1976, № 8. С. 169–178; 1977, № 1. С. 143–152.
160. Мучник И.Б. Анализ структуры экспериментальных графов. — Автоматика и телемеханика, 1974, № 9. С. 62–80.
161. Мызников А.В., Россиев Д.А., Лохман В.Ф. Нейросетевая экспертная система для оптимизации лечения облитерирующего тромбангиита и прогнозирования его непосредственных исходов // Ангиология и сосудистая хирургия. — 1995.— N 2.— С.100.
162. Мызников А.В., Россиев Д.А., Лохман В.Ф. Прогнозирование непосредственных результатов лечения облитерирующего тромбангиита с помощью нейронных сетей // В сб.: Молодые ученые — практическому здравоохранению. Красноярск, 1994.— С. 42.
163. Назаров Б.В. Прогностические аспекты некоторых нарушений ритма и проводимости при остром инфаркте миокарда: Автореф. дис…. канд. мед. наук. Новосибирск, 1982. 22 с.
164. Назимова Д.И., Новоходько А.Ю., Царегородцев В.Г. Нейросетевые методы обработки информации в задаче прогнозирования климатических параметров. // Математические модели и методы их исследования: Междунар. конференция. Тезисы докладов. Красноярск: изд. Краснояр. гос. ун-та. С. 135.
165. Назимова Д.И., Новоходько А.Ю., Царегородцев В.Г. Нейросетевые методы обработки информации в задаче восстановления климатических данных // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 124.
166. Народов А.А., Россиев Д.А., Захматов И.Г. Оценка компенсаторных возможностей головного мозга при его органических поражениях с помощью искусственных нейронных сетей // В сб.: Молодые ученые — практическому здравоохранению. — Красноярск, 1994.— С.30.
167. Научное открытие в России…. — Красноярский комсомолец (газета), Красноярск, 1992, 11 августа, № 86.
168. Нейроинформатика / А.Н.Горбань, В.Л.Дунин-Барковский, А.Н.Кирдин, Е.М.Миркес, А.Ю.Новоходько, Д.А.Россиев, С.А.Терехов, М.Ю.Сенашова, В.Г.Царегородцев. Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
169. Николаев П.П. Методы представления формы объектов в задаче константного зрительного восприятия / Интеллектуальные процессы и их моделирование. Пространственно-временная организация. — М.: Наука, 1991.— С. 146–173.
170. Николаев П.П. Трихроматическая модель констант восприятия окраски объектов // Сенсорные системы. 1990. Т.4 Вып. 4. С. 421–442.
171. Нильсен Н. Обучающиеся машины. — М.: Мир, 1967.
172. Новоходько А.Ю., Царегородцев В.Г. Нейросетевое решение транспонированной задачи линейной регрессии // Тезисы докладов четвертой международной конференции "Математика, компьютер, образование". — Москва, 1997.
173. Охонин В.А. Вариационный принцип в теории адаптивных сетей. Препринт ИФ СО АН СССР, Красноярск, 1987, № 61Б, 18 с.
174. Парин В.В., Баевский Р.М. Медицина и техника. — М.: Знание, 1968.— С. 36–49.
175. Переверзев-Орлов В.С. Советчик специалиста. Опыт разработки партнерской системы // М.: Наука, 1990.— 133 с.
176. Петров А.П. Аксиоматика игры "в прятки" и генезис зрительного пространства / Интеллектуальные процессы и их моделирование. Пространственно-временная организация. — М.: Наука, 1991.— С. 174–182.
177. Питенко А.А. Нейросетевое восполнение пробелов данных в ГИС // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 140.
178. Позин И.В. Моделирование нейронных структур. — М.: Наука, 1970.
179. Пшеничный Б.Н., Данилин Ю.М. Численные методы в экстремальных задачах. М.:Наука, 1975. 319 с.
180. Распознавание образов и медицинская диагностика / под ред. Ю.М. Неймарка. — М.: Наука, 1972.— 328 с.
181. Розенблатт Ф. Принципы нейродинамики. Перцептрон и теория механизмов мозга. М.: Мир, 1965. 480 с.
182. Россиев А.А. Генератор 0-таблиц в среде Windows-95 // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 151.
183. Россиев Д.А, Захматов И.Г. Оценка компенсаторных возможностей головного мозга при его органических поражениях (опыт применения нейросетевого векторного предиктора) // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7–10 октября 1994 г. Красноярск. — 1994. 17 С.42.
184. Россиев Д.А. Медицинская нейроинформатика / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
185. Россиев Д.А. Нейросетевые самообучающиеся экспертные системы в медицине // Молодые ученые — практическому здравоохранению. — Красноярск, 1994.— С.17.
186. Россиев Д.А., Бутакова Е.В. Нейросетевая диагностика и дифференциальная диагностика злокачественных опухолей сосудистой оболочки глаза // Нейроинформатика и ее приложения: Материалы iii Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 167–194.
187. Россиев Д.А., Бутакова Е.В. Ранняя диагностика злокачественных опухолей сосудистой оболочки глаза с использованием нейронных сетей // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 10 октября 1994 г. Красноярск. — 1994.— С.44.
188. Россиев Д.А., Винник Н.Г. Предсказание «удачности» предстоящего брака нейросетевыми экспертами // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.С.45.
189. Россиев Д.А., Гилев С.Е., Коченов Д.А. "Multineuron, Версии 2.0 и 3.0", тезисы докладов III Всеросийского семинара "Нейроинформатика и ее приложения", Красноярск: Изд-во КГТУ, с. 14
190. Россиев Д.А., Гилев С.Е., Коченов Д.А… Нейроэмулятор "Multineuron". Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 1. Изд. Института математики СО РАН. С. 45.
191. Россиев Д.А., Головенкин С.Е. Прогнозирование осложнений инфаркта миокарда с помощью нейронных сетей // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.С.40.
192. Россиев Д.А., Головенкин С.Е., Назаров Б.В., Шульман В.А., Матюшин Г.В. Определение информативности медицинских параметров с помощью нейронной сети // Диагностика, информатика и метрология — 94.— Тез. научно-технической конференции (г. Санкт-Петербург, 28–30 июня 1994 г.).С.-Петербург. — 1994.— С.348.
193. Россиев Д.А., Головенкин С.Е., Шульман В.А., Матюшин Г.В. Использование нейронных сетей для прогнозирования возникновения или усугубления застойной сердечной недостаточности у больных с нарушениями ритма сердца // Тезисы докладов рабочего семинара "Нейроинформатика и нейрокомпьютеры", Красноярск, 8-11 октября 1993 г., Красноярск. — 1993.— С.16.
194. Россиев Д.А., Головенкин С.Е., Шульман В.А., Матюшин Г.В. Прогнозирование осложнений инфаркта миокарда нейронными сетями // Нейроинформатика и ее приложения: Материалы III Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 128–166.
195. Россиев Д.А., Догадин С.А., Масленикова Е.В., Ноздрачев К.Г., Борисов А.Г. Обучение нейросетей выявлению накопленной дозы радиоактивного облучения // Тезисы докладов рабочего семинара "Нейроинформатика и нейрокомпьютеры", Красноярск, 8-11 октября 1993 г., Красноярск. — 1993.— С.15.
196. Россиев Д.А., Догадин С.А., Масленникова Е.В., Ноздрачев К.Г., Борисов А.Г. Выявление накопленной дозы радиоактивного облучения с помощью нейросетевого классификатора // Современные проблемы и методологические подходы к изучению влияния факторов производственной и окружающей среды на здоровье человека (Тез. докл. республиканской конф.). — Ангарск-Иркутск: изд. "Лисна".1993.— С. 111–112.
197. Россиев Д.А., Коченов Д.А. Пакет программ «Multineuron» — «Configurator» — «Tester» для конструирования нейросетевых приложений // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.30.
198. Россиев Д.А., Мызников А.А. Нейросетевое моделирование лечения и прогнозирование его непосредственных результатов у больных облитерирующим тромбангиитом // Нейроинформатика и ее приложения: Материалы iii Всероссийского семинара, 6–8 октября 1995 г. Ч. 1/Под ред. А.Н.Горбаня; Красноярск: Изд-во КГТУ, 1995. С. 194–228.
199. Россиев Д.А., Мызников А.В. Прогнозирование непосредственных результатов лечения облитерирующего тромбангиита с помощью нейронных сетей // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.41.
200. Россиев Д.А., Савченко А.А., Гилев С.Е., Коченов Д.А. Применение нейросетей для изучения и диагностики иммунодефицитных состояний// Нейроинформатика и нейрокомпьютеры/ Тезисы докладов рабочего семинара 8-11 октября 1993 г., Красноярск/ Институт биофизики СО РАН, 1993. С. 32.
201. Россиев Д.А., Суханова Н.В., Швецкий А.Г. Нейросетевая система дифференциальной диагностики заболеваний, прояляющихся синдромом "острого живота" // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.43.
202. Савченко А.А., Догадин С.А., Ткачев А.В., Бойко Е.Р., Россиев Д.А. Обследование людей в районе возможного радиоактивного загрязнения с помощью нейросетевого классификатора // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.46.
203. Савченко А.А., Митрошина Л.В., Россиев Д.А., Догадин С.А. Моделирование с помощью нейросетевого предиктора реальных чисел иммуноэндокринного взаимодействия при заболеваниях щитовидной железы // Тезисы докладов рабочего семинара "Нейроинформатика и нейрокомпьютеры", Красноярск, 8-11 октября 1993 г., Красноярск. — 1993.— С.18.
204. Савченко А.А., Россиев Д.А., Догадин С.А., Горбань А.Н. Нейротехнология для обследования людей в районе возможного радиоактивного загрязнения. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 1. Изд. Института математики СО РАН. С. 46–47.
205. Савченко А.А., Россиев Д.А., Захарова Л.Б. Применение нейросетевого классификатора для изучения и диагностики вилюйского энцефалита // Тезисы докладов рабочего семинара "Нейроинформатика и нейрокомпьютеры", Красноярск, 8-11 октября 1993 г., Красноярск. — 1993.— С.17.
206. Савченко А.А., Россиев Д.А., Ноздрачев К.Г., Догадин С.А. Обучение нейросетевого классификатора дифференцировать пол человека по метаболическим и гормональным показателям // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.С.47.
207. Савченко А.А., Россиев Д.А., Ноздрачев К.Г., Догадин С.А. Подтверждение с помощью нейросетевого классификатора существования гомеостатических уровней в группе практически здоровых людей // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.— С.49.
208. Савченко А.А., Россиев Д.А., Ноздрачев К.Г., Догадин С.А., Гилев С.Е. Нейроклассификатор, дифференцирующий пол человека по метаболическим и гормональным показателям. Второй Сибирский конгресс по Прикладной и Индустриальной Математике, посвященный памяти А.А.Ляпунова (1911–1973), А.П.Ершова (1931–1988) и И.А.Полетаева (1915–1983). Новосибирск, июнь 1996. Тезисы докладов, часть 1. Изд. Института математики СО РАН. С. 47.
209. Савченко А.А., Смирнова С.В., Россиев Д.А. Применение нейросетевого классификатора для изучения и диагностики аллергических и псевдоаллергических реакций // Нейроинформатика и ее приложения. Тез. докл. Всероссийского рабочего семинара 7 — 10 октября 1994 г. Красноярск. — 1994.С. 48.
210. Сенашова М.Ю. Метод обратного распространения точности с учетом независимости погрешностей сигналов сети // Тез. конф. молодых ученых Красноярского научного центра. — Красноярск, Президиум КНЦ СО РАН, 1996, сс.96–97.
211. Сенашова М.Ю. Метод обратного распространения точности. // Нейроинформатика и ее приложения. Тез. докл. IV Всероссийского семинара, 5–7 октября, 1996 г. Красноярск; КГТУ. 1996, с.47
212. Сенашова М.Ю. Погрешности в нейронных сетях / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
213. Сенашова М.Ю. Упрощение нейронных сетей: приближение значений весов синапсов при помощи цепных дробей. Вычислительный центр СО РАН в г. Красноярске. Красноярск, 1997. 11 с., библиогр. 6 назв. (Рукопись деп. в ВИНИТИ 25.07.97, № 2510-В97)
214. Сенашова. М.Ю. Упрощение нейронных сетей. Использование цепных дробей для приближения весов синапсов. // Нейроинформатика и ее приложения: Тезисы докладов v Всероссийского семинара, 3–5 октября, 1997 г., Красноярск; КГТУ. 1997, с. 165–166.
215. Соколов Е.Н., Вайткявичус Г.Г. Нейроинтеллект: от нейрона к нейрокомпьютеру. М.: Наука, 1989. 238 с.
216. Степанян А.А., Архангельский С.В. Построение логических схем на пороговых элементах. Куйбышевское книжное изд-во, 1967.
217. Судариков В.А. Исследование адаптивных нейросетевых алгоритмов решения задач линейной алгебры // Нейрокомпьютер, 1992. № 3,4. С. 13–20.
218. Тарасов К.Е., Великов В.К., Фролова А.И. Логика и семиотика диагноза (методологические проблемы). — М.: Медицина, 1989.— 272 с.
219. Терехов С.А. Нейросетевые информационные модели сложных инженерных систем / Нейроинформатика Новосибирск: Наука, Сибирская издательская фирма РАН, 1998.
220. Транспьютерные и нейронные ЭВМ. /Под ред. В.К.Левина и А.И.Галушкина — М.: Российский Дом знаний, 1992.
221. Уидроу Б., Стирнз С. Адаптивная обработка сигналов. М.: Мир, 1989. 440 с.
222. Уоссермен Ф. Нейрокомпьютерная техника. — М.: Мир, 1992.
223. Федотов Н.Г. Методы стохастической геометрии в распознавании образов. — М.: Радио и связь, 1990.— 144 с.
224. Фор А. Восприятие и распознавание образов. — М.: Машиностроение, 1989.— 272 с.
225. Фролов А.А., Муравьев И.П. Информационные характеристики нейронных сетей. — М.: Наука, 1988.
226. Фролов А.А., Муравьев И.П. Нейронные модели ассоциативной памяти. — М.: Наука, 1987.— 160 с.
227. Фу К. Структурные методы в распознавании образов. — М.: Мир, 1977.— 320 с.
228. Фукунга К. Введение в статистическую теорию распознавания образов. — М.: Наука, 1979.— 367 с.
229. Хартман Г. Современный факторный анализ. — М.: Статистика, 1972.— 486 с.
230. Химмельблау Д. Прикладное нелинейное программирование. М.: Мир, 1975. 534 с.
231. Хинтон Дж. Е. Обучение в параллельных сетях / Реальность и прогнозы искусственного интеллекта. — М.: Мир, 1987.— С. 124–136.
232. Царегородцев В.Г. Транспонированная линейная регрессия для интерполяции свойств химических элементов // Нейроинформатика и ее приложения. Тезисы докладов 5 Всероссийского семинара, 3–5 октября 1997 г. / Под ред. А.Н.Горбаня. Красноярск: изд. КГТУ, 1997. С. 177–178.
233. Цыганков В.Д. Нейрокопьютер и его применение. — М.: "Сол Систем", 1993.
234. Цыпкин Я.З. Основы теории обучающихся систем. М.: Наука, 1970. 252 с.
235. Шайдуров В.В. Многосеточные методы конечных элементов. — М.: Наука, 1989.
236. Шварц Э., Трис Д. Программы, умеющие думать // Бизнес Уик. — 1992.— n.6.— С. 15–18.
237. Шенк Р., Хантер Л. Познать механизмы мышления / Реальность и прогнозы искусственного интеллекта. — М.: Мир, 1987.— С. 15–26.
238. Щербаков П.С. Библиографическая база данных по методам настройки нейронных сетей // Нейрокомпьютер, 1993. № 3,4. С. 5–8.
239. Aleksander I., Morton H. The logic of neural cognition // Adv. Neural Comput.- Amsterdam etc., 1990.- PP. 97-102.
240. Alexander S. Th. Adaptive Signal Processing. Theory and Applications. Springer. 1986. 179 p.
241. Allen J., Murray A.. Development of a neural network screening aid for diagnosing lower limb peripheral vascular disease from photoelectric plethysmography pulse waveforms // Physiol. Meas.- 1993.- V.14, N.1.- P.13-22.
242. Amari Sh., Maginu K. Statistical Neurodynamics of Associative Memory // Neural Networks, 1988. V.1. N1. P. 63-74.
243. Arbib M.A. Brains, Machines, and Mathematics. Springer, 1987. 202 p.
244. Astion M.L., Wener M.H., Thomas R.G., Hunder G.G., Bloch D.A. Application of neural networks to the classification of giant cell arteritis // Arthritis Reum.- 1994.- V.37, N.5.- P.760-770.
245. Aynsley M., Hofland A., Morris A.J. et al. Artificial intelligence and the supervision of bioprocesses (real-time knowledge-based systems and neural networks) // Adv. Biochem. Eng. Biotechnol.- 1993.- N.48.- P.1-27.
246. Baba N. New Topics in Learning Automate Theory and Applications. Springer, 1985. 131 p. (Lec. Not. Control and Information, N71).
247. Barschdorff D., Ester S., Dorsel T et al. Phonographic diagnostic aid in heart defects using neural networks // Biomed. Tech. Berlin.- 1990.- V.35, N.11.- P.271-279.
248. Bartsev S.I., Okhonin V.A. Optimization and Monitoring Needs: Possible Mechanisms of Control of Ecological Systems. Nanobiology, 1993, v.2, p.165-172.
249. Bartsev S.I., Okhonin V.A. Self-learning neural networks playing "Two coins"// Proc. of International Workshop "Neurocomputers and attention II", Manchester Univ.Press, 1991, p.453-458.
250. Bartsev S.I., Okhonin V.A. The algorithm of dual functioning (back-propagation): general approuch, versions and applications. Preprint of Biophysics Institute SB AS USSR, Krasnoyarsk, 1989, №107B, 16 p.
251. Bartsev S.I., Okhonin V.A. Variation principle and algorithm of dual functioning: examples and applications// Proc. of International Workshop "Neurocomputers and attention II", Manchester Univ.Press, 1991, p.445-452.
252. Baxt W.G. A neural network trained to identify the presence of myocardial infarction bases some decisions on clinical associations that differ from accepted clinical teaching // Med. Decis. Making.- 1994.- V.14, N.3.- P.217-222.
253. Baxt W.G. Analysis of the clinical variables driving decision in an artificial neural network trained to identify the presence of myocardial infarction // Ann. Emerg. Med.- 1992.- V.21, N.12.- P.1439-1444.
254. Baxt W.G. Complexity, chaos and human physiology: the justification for non-linear neural computational analysis // Cancer Lett.- 1994.- V.77, N.2-3.- P.85-93.
255. Baxt W.G. Use of an artificial neural network for the diagnosis of myocardial infarction // Ann. Intern. Med.- 1991.- V.115, N.11.- P.843-848.
256. Borisov A.G., Gilev S.E., Golovenkin S.E., Gorban A.N., Dogadin S.A., Kochenov D.A., Maslennikova E.V., Matyushin G.V., Mirkes Ye.M., Nozdrachev K.G., Rossiyev D.A., Savchenko A.A., Shulman V.A. "MultiNeuron" neural simulator and its medical applications // Modelling, Measurement & Control, C.- 1996.- V.55, N.1.- P.1-5.
257. Bruck J., Goodman J. W. On the power of neural networks for solving hard problems // J. Complex.- 1990.- 6, № 2.PP. 129-135.
258. Budilova E.V., Teriokhin A.T. Endocrine networks // The RNNS/IEEE Symposium on Neuroinformatics and Neurocomputers, Rostov-on-Don, Russia, October 7-10, 1992.- Rostov/Don, 1992.- V.2.- P.729-737.
259. Carpenter G.A., Grossberg S. A Massivly Parallel Architecture for a Self-Organizing Neural Pattern Recognition Machine. - Computer Vision, Graphics, and Image Processing, 1987. Vol. 37. PP. 54-115.
260. Connectionism in Perspective/Ed. by R. Pfeifer, Z. Schreter, F.Fogelman-Soulie and L. Steels. North-Holland, 1989. 518 p.
261. Cybenko G. Approximation by superposition of a sigmoidal function. - Mathematics of Control, Signals, and Systems, 1989. Vol. 2. PP. 303–314.
262. Diday E., Simon J.C. Clustering analysis, (dans Digital Pattern Recognition), Redacteur: K.S.F.U., Springer Verlag, Berlin, 1980, P. 47-93.
263. Disordered Systems and biological Organization/Ed. by Bienenstock F., Fogelman-Soulie G. Weisbuch. Springer, 1986. 405 p.
264. Dorrer M.G., Gorban A.N., Kopytov A.G., Zenkin V.I. Psychological intuition of neural networks. Proceedings of the WCNN'95 (World Congress on Neural Networks'95, Washington DC, July 1995). PP. 193-196.
265. Dorrer M.G., Gorban A.N., Zenkin V.I. Neural networks in psychology: classical explicit diagnoses // Neuroinformatics and Neurocomputers, Proceedings of the second RNNS-IEEE Simposium, Rostov-na-Donu, September 1995. PP. 281-284.
266. Draper N. R. Applied regression analysis bibliographi update 1988-89 // Commun. Statist. Theory and Meth.- 1990.1990.- 19, № 4.- PP. 1205-1229.
267. Ercal F., Chawla A., Stoeker W.V. et al. Neural network diagnosis of malignant melanoma from color images // IEEE Trans. Biomed. Eng.- 1994.- V.41, N.9.- P.837-845.
268. Ferretti C., Mauri G. NNET: some tools for neural Networks simulation // 9th Annu. Int. Phoenix Conf. Comput. and Commun., Scottsdate, Ariz., March 21-23, 1990.- Los Alamitos (Calif.) etc., 1990.- PP. 38-43.
269. Filho E.C.D.B.C., Fairhurst M.C., Bisset D.L. Adaptive pattern recognition using goal seeking neurons // Pattern Recogn. Lett.- 1991.- 12, № 3.- PP. 131-138.
270. Floyd C.E.Jr., Lo J.Y., Yun A.J. et al. Prediction of breast cancer malignancy using an artificial neural network // Cancer.- 1994.- V.74, N.11.- P.2944-2948.
271. Forbes A.B., Mansfield A.J. Neural implementation of a method for solving systems of linear algebraic equations // Nat. Phys. Lab. Div. Inf. Technol. and Comput. Rept.- 1989.№ 155.- PP. 1-14.
272. Fu H.C., Shann J.J. A fuzzy neural network for knowledge learning // Int. J. Neural Syst.- 1994.- V.5, N.1.- P.13-22.
273. Fukushima K. Neocognitron: A self-organizing Neural Network model for a Mechanism of Pattern Recognition uneffected by shift in position // Biological Cybernetics.1980. V. 36, № 4. PP. 193-202.
274. Fulcher J. Neural networks: promise for the future? // Future Generat. Comput. Syst.- 1990-1991.- 6, № 4.- PP. 351-354.
275. Gallant A.R., White H. There exist a neural network that does not make avoidable mistakes. - IEEE Second International Coferense on Neural Networks, San Diego, CA, New York: IEEE Press, vol. 1, 1988. PP. 657–664.
276. Gecseg F. Products of Automata. Springer, 1986. 107 p.
277. Gemignani M. C. Liability for malfunction of an expert system // IEEE Conf. Manag. Expert Syst. Program and Proj., Bethesda, Md. Sept. 10-12, 1990: Proc.- Los Alamitos (Calif.) etc., 1990.- PP. 8-15.
278. Genis C. T. Relaxation and neural learning: points of convergence and divergence // J. Parallel and Distrib. Comput.- 1989.- 6, № 2.- PP. 217-244.
279. George N., Wang hen-ge, Venable D.L. Pattern recognition using the ring-wedge detector and neural-network software: [Pap.] Opt. Pattern Recogn. II: Proc. Meet., Paris, 26-27 Apr., 1989 // Proc. Soc. Photo-Opt. Instrum. Eng.- 1989.- PP. 96-106.
280. Gilev S.E. A non-back-propagation method for obtaining the gradients of estimate function // Advances in Modelling & Analysis, A, AMSE Press, 1995. Vol. 29, № 1. PP. 51-57.
281. Gilev S.E., Gorban A.N. On Completeness of the Class of Functions Computable by Neural Networks, Proc. of the World Congress on Neural Networks, Sept. 15-18, 1996, San Diego, CA, Lawrence Erlbaum Associates, 1996, pp. 984-991.
282. Gilev S.E., Gorban A.N., Kochenov D.A., Mirkes Ye.M., Golovenkin S.E., Dogadin S.A., Nozdrachev K.G., Maslennikova E.V., Matyushin G.V., Rossiev D.A., Shulman V.A., Savchenko A.A. "MultiNeuron" neural simulator and its medical applications // Proceedings of International Conference on Neural Information Processing, Oct. 17-20, 1994, Seoul, Korea.- V.2.- P.1261-1264.
283. Gilev S.E., Gorban A.N., Mirkes E.M. Internal Conflicts in Neural Networks // Transactions of IEEE-RNNS Simposium (Rostov-on-Don, September 1992). V.1. PP. 219-226.
284. Gilev S.E., Gorban A.N., Mirkes E.M. Several Methods for Accelerating the Traning Process of Neural Networks in Pattern Recognition. - Advances in Modelling & Analysis, A, AMSE Press, V. 12, No. 4, 1992, pp. 29-53.
285. Gilev S.E., Gorban A.N., Mirkes E.M. Small Experts and Internal Conflicts in Leanable Neural Networks // Advances in Modelling & Analysis.- AMSE Press.- 1992.- V.24, No. 1.P.45-50.
286. Gileva L.V., Gilev S.E. Neural Networks for binary classification// AMSE Transaction, Scientific Siberian, A, 1993, Vol. 6. Neurocomputing, pp. 135-167.
287. Gindi G.R., Darken C.J., O’Brien K.M. et al. Neural network and conventional classifiers for fluorescence-guided laser angioplasty // IEEE Trans. Biomed. Eng.- 1991.- V.38, N.3.- P.246-252.
288. Gluck M.A., Parker D.B., Reifsnider E.S. Some Biological Implications of a Differential-Hebbian Learning Rule. - Psychobiology, 1988. Vol. 16. No. 3. PP. 298-302.
289. Golub D.N. and Gorban A.N. Multi-Particle Networks for Associative Memory, Proc. of the World Congress on Neural Networks, Sept. 15-18, 1996, San Diego, CA, Lawrence Erlbaum Associates, 1996, pp. 772-775.
290. Gorban A.N., Novokhodko A.Yu.. Neural Networks In Transposed Regression Problem, Proc. of the World Congress on Neural Networks, Sept.15-18, 1996, San Diego, CA, Lawrence Erlbaum Associates, 1996, pp. 515-522.
291. Gorban A.N. Neurocomputing in Siberia // Advances in Modelling & Analysis.- AMSE Press.- 1992.- V.34(2).P.21-28.
292. Gorban A.N. Systems with inheritance and effects of selection.- Scientific Siberian A, Volume 1. Ecology, AMSE Press, ISBN: 2-909214-04-4, 1992, pp. 82-126
293. Gorban A.N., Mirkes Ye.M. and Wunsch D.C. II High order ortogonal tensor networks: Information capacity and reliability // ICNN97 (The 1997 IEEE International Conference on Neural Networks), Houston, IEEE, 1997. PP. 1311-1314.
294. Gorban A.N., Mirkes Ye.M. Functional Components of Neurocomputer. Труды третьей международной конференции "Математика, компьютер, образование". - Москва, 1996. с.352-359.
295. Gorban A.N., Mirkes Ye.M. Functional components of neurocomputer. 3-d International conference "Mathematics, computer, education", Dubna, Jan. 1996. Abstracts, p. 160.
296. Gorban A.N., Rossiev D.A., Butakova E.V., Gilev S.E., Golovenkin S.E., Dogadin S.A., Dorrer M.G., Kochenov D.A., Kopytov A.G., Maslennikova E.V., Matyushin G.V., Mirkes Ye.M., Nazarov B.V., Nozdrachev K.G., Savchenko A.A., Smirnova S.V., Shulman V.A., Zenkin V.I. Medical, psychological and physiological applications of MultiNeuron neural simulator. Neuroinformatics and Neurocomputers, Proceedings of the second RNNS-IEEE Simposium, Rostov-na-Donu, September 1995.- PP. 7-14.
297. Gorban A.N., Rossiev D.A., Gilev S.E. et al. “NeuroComp” group: neural-networks software and its application // Russian Academy of Sciences, Krasnoyarsk Computing Center, Preprint N 8.- Krasnoyarsk, 1995.- 38 p.
298. Gorban A.N., Rossiev D.A., Gilev S.E. et al. Medical and physiological applications of MultiNeuron neural simulator // Proceedings of World Congress on Neural Networks-1995 (WCNN’95).- Washington, 1995.- V.1, P.170-175.
299. Gorban A.N., Rossiev D.A., Gilev S.E., Dorrer M.A., Kochenov D.A., Mirkes Ye.M., Golovenkin S.E., Dogadin S.A., Nozdrachev K.G., Matyushin G.V., Shulman V.A., Savchenko A.A. Medical and physiological applications of MultiNeuron neural simulator // Proceedings of World Congress on Neural Networks - 1995 (WCNN'95).- PP. 170-175.
300. Gorban A.N., Waxman C. How many neurons are sufficient to elect the U.S.A. President?// AMSE Transaction, Scientific Siberian, A, 1993, Vol. 6. Neurocomputing, pp. 168-188.
301. Gorban A.N., Waxman C. How many Neurons are Sufficient to Elect the U.S.A. President? TWO! (Siberian neurocomputer forecasts results of U.S.A. Presidential elections) Krasnoyarsk, Institute of Biophysics, Russian Academy of Sciences Siberian Branch, 1992 - 29 pp. (preprint Russian Academy of Sciences Siberian Branch, Institute of Biophysics N 191 Б).
302. Gorban A.N., Waxman C. Neural networks for political forecast. Proceedings of the WCNN'95 (World Congress on Neural Networks'95, Washington DC, July 1995). PP. 179-184.
303. Gordienko P. Construction of efficient neural networks // Proceedings of the International Conference on Neural Information Processing (Oct. 17-20, 1994, Seoul, Korea) V.1. PP. 366-371.
304. Gordienko P. How to obtain a maximum of skills with minimum numbers of connections// AMSE Transaction, Scientific Siberian, A, 1993, Vol. 6. Neurocomputing, pp.204-208.
305. Gross G.W., Boone J.M., Greco-Hunt V. et al. Neural networks in radiologic diagnosis. II. Interpretation of neonatal chest radiographs // Invest. Radiol.- 1990.- V.25, N.9.- P.1017-1023.
306. Grossberg S. Nonlinear Neural Networks: Principles, Mechanism and Architectures// Neural Networks, 1988. V.1. N1. P. 17-62.
307. Guo Z., Durand L.G., Lee H.C. et al. Artificial neural networks in computer-assisted classification of heart sounds in patients with porcine bioprosthetic valves // Med. Biol. Eng. Comput.- 1994.- V.32, N.3.- P.311-316.
308. Hecht-Nielsen R. Neurocomputing: Picking the Human Brain/IEEE Spectrum, 1988. March. P. 36-41.
309. Heht-Nielsen R. Theory of the backpropagation neural network. - Neural Networks for Human and Mashine Perception. H.Wechsler (Ed.). Vol. 2. Boston, MA: Academic Press, 1992. PP. 65 - 93.
310. Hod H., Lew A.S., Keltai M. et al. Early atrial fibrilla tion during evolving myocardial infarction: a consequence of impaired left atrial perfusion // Circulation, 1987. V.75, N.1. PP. 146-150.
311. Hoher M., Kestler H.A., Palm G. et al. Neural network based QRS classification of the signal averaged electrocardiogram // Eur. Heart J.- 1994.- V.15.- Abstr. Supplement XII-th World Congress Cardiology (734).- P.114.
312. Hopfield J.J. Neural Networks and physical systems with emergent collective computational abilities//Proc. Nat. Sci. USA. 1982. V.79. P. 2554-2558.
313. Hornik K., Stinchcombe M., White H. Multilayer Feedforward Networks are Universal Approximators. - Neural Networks. 1989. Vol. 2,. PP. 359–366.
314. Jeffries C. Code recognition with neural network dynamical systems // SIAM Rev.- 1990.- 32, № 4.- PP. 636-651.
315. Kalman R.E. A theory for the identification of linear relations // Frontiers Pure and Appl. Math.: Collect. Pap. Dedicat. Jacques-Louis Lions Occas. His 60th Birthday: Sci. Meet., Paris, 6-10 June, 1988.- Amsterdam etc., 1991.- PP.
316. 117-132. Keller J.M., Yager R.R., Tahani H. Neural network implementation of fuzzy logic // Fuzzy Sets and Syst.1992.- 45, № 1. PP. 1-12.
317. Kirdin A.N., Rossiev D.A., Dorrer M.G. Neural Networks Simulator for Medical, Physiological and Psychological Applications. Труды третьей международной конференции "Математика, компьютер, образование". - Москва, 1996. с.360-367.
318. Kirdin A.N., Rossiev D.A.. Neural-networks simulator for medical and physiological applications.3-d International conference "Mathematics, computer, education", Dubna, Jan. 1996. Abstracts, p. 162.
319. Kochenov D.A., Rossiev D.A. Approximations of functions of C[A,B] class by neural-net predictors (architectures and results)// AMSE Transaction, Scientific Siberian, A, 1993, Vol. 6. Neurocomputing. PP. 189-203.
320. Koopmans T. Serial correlation and quadratic forms in normal variates // Ann. Math. Statist, 1942. V. 13. PP. 14-33.
321. Korver M., Lucas P.J. Converting a rule-based expert system into a belief network // Med. Inf. Lond.- 1993.- V.18, N.3.- P.219-241.
322. Kosko B. Bidirectional Associative Memories. - IEEE Transactions on Systems, Man, and Cybernetics, Jan. 1988. Vol. SMC-18. PP.49-60.
323. Le Cun Y., Denker J.S., Solla S.A. Optimal Brain Damage // Advances in Neural Information Processing Systems II (Denver 1989). San Mateo, Morgan Kaufman, pp. 598-605 (1990)
324. Lee H.-L., Suzuki S., Adachi Y. et al. Fuzzy Theory in Traditional Chinese Pulse Diagnosis // Proceedings of 1993 International Joint Conference on Neural Networks, Nagoya, Japan, October 25-29, 1993.- Nagoya, 1993.- V.1.- P.774-777.
325. Levine D.S., Parks R.W., Prueitt P.S. Methodological and theoretical issues in neural network models of frontal cognitive functions // Int. J. Neurosci.- 1993.- V.72, N.3-4.- P.209-233.
326. Lichtman A.J., Keilis-Borok V.I., Pattern Recognition as Applied to Presidential Elections in U.S.A., 1860-1980; Role of Integral Social, Economic and Political Traits, Contribution No. 3760. 1981, Division of Geological and Planetary Sciences, California Institute of Technology.
327. Maclin P.S., Dempsey J. Using an artificial neural network to diagnose hepatic masses // J. Med. Syst.- 1992.- V.16, N.5.- P.215-225.
328. Macukow B. Robot control with neural networks // Artif. Intell. and Inf.-Contr. Syst. Rob.-89: Proc. 5th Int. Conf., Strbske Pleso, 6-10 Nov., 1989.- Amsterdam etc., 1989.- PP. 373-376.
329. Mirkes E.M., Svitin A.P. The usage of adaptive neural networks for catalytic activity predictions // CHISA - 10th Int. Congr. of chem. eng., chem. equipment design and automation. Praha, 1990. Prepr. B3.80 [1418]. 7 pp.
330. Modai I., Stoler M., Inbar-Saban N. et al. Clinical decisions for psychiatric inpatients and their evaluation by a trained neural network // Methods Inf. Med.- 1993.- V.32, N.5.- P.396-399.
331. Modha D.S., Heht-Nielsen R. Multilayer Functionals. Mathematical Approaches to Neural Networks. J.G.Taylor (Ed.). Elsevier, 1993. PP. 235–260.
332. Nakajima H., Anbe J., Egoh Y. et al. Evaluation of neural network rate regulation system in dual activity sensor rate adaptive pacer // European Journal of Cardiac Pacing and Electrophysiology.- Abstracts of 9th International Congress, Nice Acropolis - French, Rivera, June 15-18, (228), 1994.- Rivera, 1994.- P.54.
333. Narendra K.S., Amnasway A.M. A stable Adaptive Systems. Prentice-Hall, 1988. 350 p.
334. Neural Computers/Ed. by R. Eckmiller, Ch. Malsburg. Springer, 1989. 556 p.
335. Okamoto Y., Nakano H., Yoshikawa M. et al. Study on decision support system for the interpretation of laboratory data by an artificial neural network // Rinsho. Byori.- 1994.- V.42, N.2.- P.195-199.
336. Pedrycz W. Neurocomputations in relational systems // IEEE Trans. Pattern Anal. and Mach. Intell.- 1991.- 13, № 3.- PP. 289-297.
337. Pham D.T., Liu X. Statespace identification of dynamic systems using neural networks // Eng. Appl. Artif. Intell.1990.- 3, № 3.- PP. 198-203.
338. Pineda F.J. Recurrent bakpropagation and the dynamical approach to adaptive neural computation. - Neural Comput., 1989. Vol. 1. PP.161–172.
339. Poli R., Cagnoni S., Livi R. et al. A Neural Network Expert System for Diagnosing and Treating Hypertension // Computer.- 1991.- N.3.- P.64-71.
340. Prechelt L. Comparing Adaptive and Non-Adaptive Connection Pruning With Pure Early Stopping // Progress in Neural Information Processing (Hong Kong, September 24-27, 1996), Springer, Vol. 1 pp. 46-52.
341. Real Brains, Artificial Minds/Ed. by J.L. Casti, A. Karlqvist. Norton-Holland, 1987. 226 p.
342. Reinbnerger G., Weiss G., Werner-Felmayer G. et al. Neural networks as a tool for utilizing laboratory information: comparison with linear discriminant analysis and with classification and regression trees // Proc. Natl. Acad. Sci., USA.- 1991.- V.88, N.24.- P.11426-11430.
343. Rinast E., Linder R., Weiss H.D. Neural network approach for computer-assisted interpretation of ultrasound images of the gallbladder // Eur. J. Radiol.- 1993.- V.17, N.3.- P.175-178.
344. Rossiev D.A., Golovenkin S.E., Shulman V.A., Matyushin G.V. Forecasting of myocardial infarction complications with the help of neural networks // Proceedings of the WCNN'95 (World Congress on Neural Networks'95, Washington DC, July 1995). PP. 185-188.
345. Rossiev D.A., Golovenkin S.E., Shulman V.A., Matyushin G.V. Neural networks for forecasting of myocardial infarction complications // Proceedings of the Second IEEE RNNS International Symposium on Neuroinformatics and Neurocomputers, September 20-23, 1995, Rostov-on-Don. - PP 292-298.
346. Rossiev D.A., Golovenkin S.E., Shulman V.A., Matyushin G.V. The employment of neural networks to model implantation of pacemaker in patients with arrhythmias and heart blocks // Modelling, Measurument & Control, C, 1995. Vol. 48, № 2. PP. 39-46.
347. Rossiev D.A., Golovenkin S.E., Shulman V.A., Matyushin G.V. The employment of neural networks to model implantation of pacemaker in patients with arrhythmias and heart blocks // Proceedings of International Conference on Neural Information Processing, Oct. 17-20, 1994, Seoul, Korea.V.1.- PP.537-542.
348. Rossiev D.A., Savchenko A.A., Borisov A.G., Kochenov D.A. The employment of neural-network classifier for diagnostics of different phases of immunodeficiency // Modelling, Measurement & Control.- 1994.- V.42.- N.2. P.55-63.
349. Rozenbojm J., Palladino E., Azevedo A.C. An expert clinical diagnosis system for the support of the primary consultation // Salud. Publica Mex.- 1993.- V.35, N.3.- P.321-325.
350. Rumelhart D.E., Hinton G.E., Williams R.J. Learning internal representations by error propagation. - Parallel Distributed Processing: Exploration in the Microstructure of Cognition, D.E.Rumelhart and J.L.McClelland (Eds.), vol. 1, Cambridge, MA: MIT Press, 1986. PP. 318–362.
351. Rummelhart D.E., Hinton G.E., Williams R.J. Learning representations by back-propagating errors // Nature, 1986. V. 323. P. 533-536.
352. Saaf L. A., Morris G. M. Filter synthesis using neural networks: [Pap.] Opt. Pattern Recogn. II: Proc. Meet., Paris, 26-27 Apr., 1989 // Proc. Soc. Photo-Opt. Instrum. Eng.- 1989.- 1134.- PP. 12-16.
353. Sandberg I.W. Approximation for Nonlinear Functionals. - IEEE Transactions on Circuits and Systems - 1: Fundamental Theory and Applications, Jan. 1992. Vol.39, No 1. PP.65 67.
354. Savchenko A.A., Zakharova L.B., Rossiev D.A. The employment of neural networks for investigation & diagnostics of Viliuisk encephalomyelitis // Modelling, Measurement & Control, C.- 1995.- V.48, N.4.- P.1-15.
355. Senashova M.Yu., Gorban A.N. and. Wunsch D.C. II. Back-propagation of accuracy // ICNN97 (The 1997 IEEE International Conference on Neural Networks), Houston, IEEE, 1997. PP. 1998-2001.
356. Senna A.L., Junior W.M., Carvallo M.L.B., Siqueira A.M. Neural Networks in Biological Taxonomy // Proceedings of 1993 International Joint Conference on Neural Networks, Nagoya, Japan, October 25-29, 1993.- Nagoya, 1993.- V.1.- P.33-36.
357. Stefanuk V.L. Expert systems and its applications // The lectures of Union's workshop on the main problems of artificial intillegence and intellectual systems. Part 2, Minsk, 1990.- P.36-55.
358. Sussman H.J. Uniqueness of the weigts for minimal feedforward nets wits a given input - output map. Neural Networks, 1992, No. 5. PP. 589–593.
359. Sweeney J.W.P., Musavi M.T., Guidi J.N. Probabilistic Neural Network as Chromosome Classifier // Proceedings of 1993 International Joint Conference on Neural Networks, Nagoya, Japan, October 25-29, 1993.- Nagoya, 1993.-V.1.- P.935-938.
360. Tabatabai A., Troudet T. P. A neural net based architecture for the segmentation of mixed gray-level and binary pictures // IEEE Trans. Circuits and Syst.- 1991. 31 38, № 1.- PP. 66-77.
361. Tao K.M., Morf M. A lattice filter type of neuron model for faster nonlinear processing // 23th Asilomar Conf. Signals, Syst. and Comput., Pasific Grove, Calif. Oct. 30-Nov. 1, 1989: Conf. Rec. Vol. 1.- San Jose (Calif.), 1989.- PP. 123-127.
362. The Adaptive Brain/ S. Grossberg (Ed.). North-Holland, 1987. V.1. Cognition, Learning, Reforcement, and Rhythm. 498 p. V.2. Vision, Speech, Language, and Motor Control. 514 p.
363. The Computer and the Brain. Perspectives of Human and Artificial Intelligence/Ed. by J.R. Brinc, C.R. Haden, C. Burava. North-Holland, 1989. 300 p.
364. Vakhrushev S.G., Rossiev D.A., Burenkov G.I., Toropova L.A. Neural network forecasting of optimal parameters of laserotherapy in patients after tonsillectomy // Proceedings of World Congress on Neural Networks - 1995 (WCNN'95).- P. 176-178.
365. Van Leeuwen J.L. Neural network simulations of the nervous system // Eur. J. Morphol.- 1990.- V.28, N.2-4.- P.139-147.
366. Varela F.J., Coutinho A., Dupire B. et al. Cognitive networks: immune, neural and otherwise // Teoretical immunology. Ed. by Perelson A.- Addison Wesley, 1988.- Part 2.- P.359-375.
367. Waxman C. Neurocomputers in the human sciences: program: predictions of US presidential elections// Modelling, Measurement & Control, D, Vol.5, No.1, 1992, pp.41-53
368. Weckert J. How expert can expert systems really be? // Libr. and Expert Syst.: Proc. Conf. and Workshop [Centre Inf. Stud.], Riverina, July, 1990.- London, 1991.- PP. 99-114.
369. Wiedermann J. On the computation efficiency of symmetric neural networks // Theor. Comput. Sci.- 1991.- 80, № 2.- PP. 337-345.
370. Wong K.Y.M., Kahn P.E., Sherrington D. A neural network model of working memory exhibiting primacy and recency // J. Phys. A.- 1991.- 24, № 5.- PP. 1119-1133.
371. Yang T.-F., Devine B., Macfarlane P.W. Combination of artificial neural networks and deterministic logic in the electrocardiogram diagnosis of inferior myocardial infarction // Eur. Heart J.- 1994.- V.15.- Abstr. Supplement XII-th World Congress Cardiology (2408).- P.449.
372. Hecht-Nielsen R. Neurocomputing. Addison-Wesley, 1990
373. Kock, G., Serbedzija, N.B.. Specification of Artificial Neural Networks based on the modified AXON Model, Proc. World Congress on Neural Networks Vol. I, Portland, 1993, P-433-436.
374. Kock, G., Serbedzija, N.B. (1993). Object-Oriented and Functional Concepts in Artificial Neural Network Modeling, Proc. Int. Joint Conf. on Neural Networks, Nagoya (Japan), 1993.
375. Kock, G., Serbedzija, N.B. Artificial Neural Networks: From Compact Descriptions to C++, in ICANN'94: Proc. of the Int. Conf. on Artificial Neural Networks, 1994
376. Миркес Е.М. Нейрокомпьютер. Проект стандарта. Новосибирск: Наука, Сибирская издательская фирма РАН, 1998, 337 С
377. Нейроинформатика / А.Н.Горбань, В.Л.Дунин-Барковский, А.Н.Кирдин, Е.М.Миркес, А.Ю.Новоходько, Д.А.Россиев, С.А.Терехов, М.Ю.Сенашова, В.Г.Царегородцев. Новосибирск: Наука, Сибирская издательская фирма РАН, 1998, 296 С.
378. Горбань А.Н., Миркес Е.М. Логически прозрачные нейронные сети // Изв. ВУЗов. Приборостроение, 1996, Т. 39, № 1, С. 64–67.
379. Горбань А.Н., Миркес Е.М. Оценки и интерпретаторы ответа для нейронных сетей двойственного функционирования // Изв. ВУЗов. Приборостроение, 1996, Т. 39, № 1, С. 5–14.

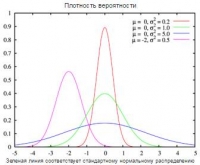




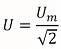
Комментарии к книге «Учебное пособие по курсу «Нейроинформатика»», Е. М. Миркес
Всего 0 комментариев