Н. Хомский СИНТАКСИЧЕСКИЕ СТРУКТУРЫ[1]
ПРЕДИСЛОВИЕ
Настоящее исследование посвящено синтаксической структуре как в широком смысле (т. е. синтаксису в противоположность семантике), так и в узком (т. е. синтаксису в противоположность фонологии и морфологии). Оно является частью попытки построить формализованную общую теорию лингвистической структуры и исследовать основания такой теории. Поиски строгих формулировок в лингвистике вызываются гораздо более серьезными мотивами, чем просто желанием соблюсти логические тонкости или упорядочить традиционные методы лингвистического анализа. Точно построенные модели лингвистической структуры могут играть важную роль (как отрицательную, так и положительную) в самом процессе исследования. Выводя неприемлемые следствия из точных, но неадекватных формулировок, мы часто можем с большой точностью установить причину этой неадекватности и, таким образом, получить более глубокое представление о лингвистических данных. Говоря позитивно, формализованная теория автоматически может дать решение многих проблем, помимо тех, на решение которых она была явным образом рассчитана. Туманные интуитивные понятия не могут привести ни к абсурдным выводам, ни к выводам новым и правильным; следовательно, они оказываются бесполезными в двух важных отношениях. Я думаю, что некоторые лингвисты, поставившие под сомнение ценность точного и «технического» развития лингвистической теории, по-видимому, не сумели оценить продуктивные возможности строгих методов изложения теории и их точного применения к лингвистическому материалу без попыток избежать неприемлемых выводов с помощью поправок ad hoc или расплывчатых формулировок. Результаты, излагаемые ниже, получены путем сознательной попытки систематически следовать именно такому курсу. Поскольку это обстоятельство может быть затемнено недостаточной формальностью изложения, важно подчеркнуть его здесь.
Конкретно мы изучим три модели лингвистической структуры и постараемся выяснить их возможности. Мы увидим, что некоторая, весьма простая теоретикокоммуникационная модель языка, а также более сильная модель, включающая значительную часть того, что общеизвестно как «анализ по непосредственно составляющим», не могут надлежащим образом служить целям грамматического описания. По изучении приложений этих моделей нам станут понятными некоторые стороны лингвистической структуры и мы обнаружим ряд пробелов в лингвистической теории; к ним следует отнести, в частности, невозможность объяснения таких отношений между предложениями, как активно-пассивные. Мы развиваем третью, трансформационную, модель лингвистической структуры, в некоторых важных отношениях модель более сильную, чем модель непосредственно составляющих, и естественным образом объясняющую эти отношения. Сформулировав теорию трансформации более тщательно и приложив ее без всякой предвзятости к английскому языку, мы увидим, что она позволяет глубоко проникнуть в сущность целого ряда явлений, помимо тех, для объяснения которых она непосредственно была построена. Короче, мы убеждаемся, что формализация действительно может играть ту отрицательную и положительную роли, о которых говорилось выше.
В период исследований мне посчастливилось иметь частые и продолжительные дискуссии с Зеллигом С. Хэррисом. Настоящая работа и сами исследования, на основе которых она написана, содержат так много его идей и положений, что я не буду пытаться отмечать их особыми ссылками. Исследования Хэрриса в области трансформационной структуры, ведущиеся с несколько иной, чем здесь, точки зрения, изложены в его работах, которые приводятся в библиографии к настоящей книге (см. №№ 15,16, 19, стр. 526—527). Менее очевидное, но сильное влияние на ход данного исследования оказали работы Н. Гудмэна и У. В. Куайна. Я обсуждал подолгу большую часть своих материалов с Морисом Халле, и мне много дали его замечания и предложения. Эрик Леннеберг, Израэль Шеффлер и Егошуа Бар-Хиллел прочли ранние варианты этой рукописи и высказали много ценных замечаний и соображений как по содержанию, так и по форме изложения.
Исследования по теории трансформации и трансформационной структуре английского языка, хотя и кратко изложенные ниже, однако служащие основой для многочисленных дискуссий, были выполнены в большей своей части в 1951—1955 гг., когда я состоял младшим членом Научного общества Гарвардского университета. Пользуюсь случаем, чтобы выразить свою признательность Научному обществу за предоставленную мне свободу для проведения исследований.
Настоящая работа финансировалась частично военными организациями США (Управлением войск связи, Управлением научных исследований ВВС Главным авиационным научно-исследовательским командованием ВВС, Научно-исследовательским управлением ВМС) и частично Национальным научным фондом, а также корпорацией «Истмэн Кодак».
Наум Хомский
Массачусетский технологический институт,
Отделение новых языков и Исследовательская лаборатория электроники Кембридж, штат Массачусетс 1 августа 1956 г.
1. ВВЕДЕНИЕ
Синтаксис — учение о принципах и способах построения предложений. Целью синтаксического исследования данного языка является построение грамматики, которую можно рассматривать как механизм некоторого рода, порождающий предложения этого языка. В более широком плане лингвисты стоят перед проблемой определения глубоких, фундаментальных свойств успешно действующих грамматик. Конечным результатом этих исследований должна явиться теория лингвистической структуры, в которой описательные механизмы конкретных грамматик представлялись бы и изучались абстрактно, без обращения к конкретным языкам. Одна из задач такой теории — выработать общий метод выбора грамматики для любого языка при наличии всей совокупности предложений данного языка.
Центральным в лингвистической теории является понятие «лингвистического уровня». Каждый лингвистический уровень (например, фонологический, морфологический, а также уровень непосредственно составляющих) есть, по существу, совокупность описательных механизмов, имеющихся в нашем распоряжении для построения грамматик; это — определенный способ представления высказываний. Мы можем оценить адекватность лингвистической теории, разработав строгим и точным об- базом тип грамматики, соответствующий набору уровней, которыми располагает эта теория, и исследовав затем возможность построения простых и наглядных грамматик этого типа для естественных языков. Мы изучим таким способом несколько различных концепций лингвистической структуры, рассматривая последовательности лингвистических уровней возрастающей сложности, которые соответствуют все более и более сильным типам грамматического описания, и сделаем попытку доказать, что лингвистическая теория должна содержать по меньшей мере данные уровни, если она, например, желает выработать удовлетворительную грамматику английского языка. Наконец, мы постараемся показать, что это чисто формальное изучение структуры языка можно применить к некоторым проблемам семантики[2].
2. НЕЗАВИСИМОСТЬ ГРАММАТИКИ
2.1.
Под языком мы будем понимать множество (конечное или бесконечное) предложений, каждое из которых имеет конечную длину и построено из конечного множества элементов. Все естественные языки в их письменной или устной форме являются языками в указанном смысле, поскольку каждый естественный язык имеет конечное число фонем (или букв алфавита) и каждое предложение может быть представлено в форме конечной последовательности этих фонем (или букв), хотя количество предложений бесконечно велико. Подобным же образом множество «предложений» некоторой формализованной математической теории может рассматриваться как язык. Основная проблема лингвистического анализа языка состоит в том, чтобы отделить грамматически правильные последовательности, которые являются предложениями языка L, от грамматически неправильных последовательностей, которые не являются предложениями языка L, и исследовать структуру грамматически правильных последовательностей. Грамматика языка L представляет собой, таким образом, своего рода механизм, порождающий все грамматически правильные последовательности L и не порождающий ни одной грамматически неправильной.
Один из методов проверки адекватности грамматики, предложенной для L, состоит в установлении того, являются ли порождаемые ею предложения действительно грамматически правильными, т. е. приемлемыми для природного носителя данного языка. Мы в состоянии сделать определенные шаги, чтобы сформулировать операционный критерий грамматической правильности для осуществления подобной проверки адекватности. Однако для целей настоящего рассмотрения мы можем допустить интуитивное знание грамматически правильных предложений английского языка и затем поставить вопрос: какого рода грамматика способна выполнять работу порождения этих предложений эффективным и ясным способом? Мы сталкиваемся, таким образом, с обычной задачей логического анализа некоторого интуитивного понятия, в данном случае — понятия «грамматической правильности в английском языке» и в более широком плане «грамматической правильности» вообще.
Заметим, что для содержательной постановки задач грамматики достаточно предположить лишь частичное знание предложений и непредложений. Это значит, что в рамках данного рассмотрения мы можем допустить, что некоторые последовательности фонем суть определенно предложения и что некоторые другие последовательности являются определенно непредложениями. Во многих промежуточных случаях мы должны быть готовы предоставить самой грамматике решать вопрос о грамматической правильности предложения, если грамматика построена простейшим образом так, что в нее включаются несомненные предложения и исключаются несомненные непредложения. Это — обычная черта логического анализа понятий[3]. Определенное число ясных случаев предоставляет нам, таким образом, критерий адекватности, пригодный для любой конкретной грамматики. Для одного языка, взятого в изоляции, этот критерий весьма слаб, поскольку ясные случаи могут быть удовлетворительно истолкованы разными грамматиками. Однако этот критерий может превратиться в весьма сильное условие, если мы будем настаивать на том, чтобы ясные случаи удовлетворительно истолковывались для любого языка посредством грамматик, каждая из которых построена по одному и тому же методу. Это значит, что каждая грамматика должна соотноситься с конечной совокупностью наблюденных предложений описываемого ею языка так, как это предусмотрено заранее данной лингвистической теорией. Таким путем мы получаем весьма сильный критерий адекватности для лингвистической теории, претендующей на общее объяснение понятия «грамматически правильного предложения» через понятие «наблюденного предложения», а также для множества грамматик, построенных в соответствии с этой теорией. Кроме того, указанное требование является разумным еще и потому, что нас интересуют не только конкретные языки, но и общая природа языка. По данному весьма важному вопросу можно было бы сказать еще очень многое, но это завело бы нас слишком далеко. Ср. § 6.
2.2.
Из чего исходим мы в действительности, когда намереваемся отделить грамматически правильные предложения от грамматически неправильных последовательностей? Не пытаясь дать исчерпывающий ответ на этот вопрос (ср. §§6, 7), я считаю, однако, нелишним указать на неправильность некоторых ответов, которые, по-видимому, приходят на ум сами собой. Во-первых, очевидно, что множество грамматически правильных предложений не может отождествляться с какой бы то ни было совокупностью высказываний, полученной тем или иным лингвистом в его полевой работе. Любая грамматика рассматриваемого языка проецирует конечную и в известной мере случайную совокупность наблюденных высказываний на множество (предположительно бесконечное) грамматически правильных высказываний. В этом отношении грамматика отражает поведение носителя языка, который на базе своего конечного и случайного языкового опыта в состоянии произвести и понять бесконечное число новых предложений. В действительности любой логический анализ понятия «грамматической правильности в языке L» (т. е. любая характеристика «грамматически правильного в L» через «наблюденное высказывание в L») может пониматься как объяснение этого фундаментального аспекта лингвистического поведения.
2.3.
Во-вторых, понятие «грамматически правильный» не может отождествляться с понятиями «осмысленный», «значимый» в каком бы то ни было семантическом смысле. Данные ниже предложения (1) и (2) равно бессмысленны, но любой носитель английского языка назовет грамматически правильным лишь первое.
(1) Colorless green ideas sleep furiously.
«Бесцветные зеленые мысли спят яростно».
(2) Furiously sleep ideas green colorless.
Точно так же нет никакого семантического основания предпочесть последовательность (3) последовательности (5) или (4) — (6), однако лишь (3) и (4) являются грамматически правильными предложениями английского языка.
(3) Have you a book on modern music?
«Есть ли у Вас книга по современной музыке?»
(4) The book seems interesting.
«Эта книга кажется интересной».
(5) Read you a book on modern music?
(6) The child seems sleeping.
Из этих примеров видно, что всякие поиски определения грамматической правильности, основанного на семантике, останутся тщетными. В действительности, как мы увидим в § 7, существуют основания структурного характера, позволяющие отличать (3) и (4) от (5) и (6); однако прежде чем мы сможем дать объяснение фактам подобного рода, нам придется развить теорию синтаксической структуры намного дальше ее обычных границ.
2.4.
В-третьих, понятие «грамматической правильности в английском языке» нельзя отождествлять ни в каком смысле с понятием «высокого порядка статистического приближения к английскому языку». С полной уверенностью можно предположить, что ни (1), ни (2) (и фактически никакая часть этих предложений) никогда не появлялись в английской речи. Следовательно, согласно любой статистической модели грамматической правильности оба эти предложения были бы отброшены как равно далекие от английского языка. И тем не менее первое, хотя и бессмысленное, грамматически правильно, а второе нет. Носитель английского языка, если его попросят прочесть эти предложения, первое прочтет с нормальной интонацией предложения, а второе — с интонацией, падающей на каждом слове, т. е. как всякую последовательность бессвязных слов, принимая каждое слово в ней за отдельное высказывание. Отсюда вытекает, что ему гораздо легче припомнить первое, чем второе, что он гораздо быстрей заучит первое и т. д. И все это несмотря на то, что ему никогда не приходилось видеть или слышать ни одной пары приведенных слов соединенными в реальной речи. Еще пример. В прошлом языковом опыте говорящего слова whale «кит» и of могут иметь одинаковую (т. е. нулевую) частотность появления в контексте (I saw a fragile — «Я видел хрупкого — »), и все же говорящий немедленно заявит, что лишь первая из этих подстановок приводит к грамматически правильному предложению. Мы не можем, разумеется, апеллировать к тому факту, что предложения, подобные (1), «могут» быть высказаны в некотором достаточно искусственном контексте, а тип (2) не может быть высказан ни при каких условиях, поскольку нам нужно выяснить именно причину такого различения между (1) и (2).
Ясно, таким образом, что способность производить и распознавать грамматически правильные предложения не основывается на таких понятиях, как, например, понятие статистической приближенности. Источником недоразумения служит здесь обычай считать грамматически правильными предложения, которые «могут встретиться», «возможны» и т. п. Естественно трактовать слово «возможный» как «имеющий большую вероятность» и предположить, что способность лингвиста четко различать грамматически правильное и грамматически неправильное[4] основана на убеждении, что, поскольку «реальность» языка слишком сложна для полного описания, необходимо удовлетвориться упрощенным вариантом описания, называющим «все невероятное и весьма маловероятное невозможным и все, имеющее большую вероятность, возможным»[5]. Мы видим, однако, что это представление совершенно неправильное и что структурный анализ нельзя понимать как упрощенную схему, полученную в результате четкой обрисовки размытых границ полностью статистической картины. Если расположить последовательности данной длины в порядке статистического приближения к английскому языку, мы обнаружим в списке разбросанными в беспорядке как грамматически правильные, так и грамматически неправильные предложения; нет, по-видимому, никакой специфической связи между порядком статистического приближения и грамматической правильностью. При всем несомненном интересе и важности статистического и семантического изучения языка изучение это представляется не имеющим прямого отношения к определению или характеристике понятия множества грамматических высказываний. Я думаю, мы принуждены сделать вывод, что грамматика автономна и независима от значения и что вероятностная модель не дает особого проникновения в сущность основных проблем синтаксической структуры[6].
3. ЭЛЕМЕНТАРНАЯ ЛИНГВИСТИЧЕСКАЯ ТЕОРИЯ
3.1.
Допустим, что нам дано множество грамматически правильных предложений английского языка. Спрашивается, «какого рода механизм может порождать это множество (другими словами, какого рода теория дает адекватное описание структуры этого множества высказываний). Мы можем представлять себе каждое предложение этого множества как последовательность фонем конечной длины. Язык — необычайно запутанная система, и совершенно очевидно, что любая попытка представить непосредственным образом множество грамматически правильных последовательностей фонем привела бы к грамматике столь сложной, что практически она стала бы бесполезной. По этой причине (существуют и другие причины) для лингвистического описания используется система «уровней представления». Вместо того чтобы устанавливать фонемную структуру предложений непосредственно, лингвист исходит из элементов «более высокого уровня»— морфем; затем он отдельно устанавливает морфемную структуру предложений и фонемную структуру морфем. Легко понять, что совокупное описание этих двух уровней значительно проще непосредственного описания фонемной структуры предложений.
Рассмотрим теперь различные способы описания морфемной структуры предложений. Какого рода грамматика необходима для порождения всех последовательностей морфем (или слов), представляющих собой грамматически правильные английские предложения, и только такие последовательности?
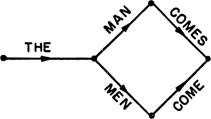
Одно из требований, предъявляемых грамматике, состоит в том, что она должна быть конечной. Отсюда следует, что грамматика не может быть просто списком всех последовательностей морфем или слов, поскольку число их бесконечно. Обычная теоретико-коммуникационная модель языка предоставляет нам один из способов, которым мы можем воспользоваться, чтобы обойти эту трудность. Предположим, мы имеем машину, способную принимать одно из конечного числа различных внутренних состояний, и пусть эта машина при переходе из одного состояния в другое вырабатывает определенный символ (скажем, английское слово). Одно из этих состояний является начальным, некоторое другое — конечным. Допустим, машина начинает свою работу с начального состояния, проходит ряд промежуточных состояний (выдавая некоторый символ при каждой смене состояний) и оканчивает работу конечным состоянием. Порожденную таким способом последовательность слов назовем «предложением». Каждая подобная машина, таким образом, определяет какой-то язык, а именно — множество предложений, создаваемых с ее помощью. Всякий язык, который может быть порожден машиной такого рода, мы назовем языком с конечным числом состояний; самую машину мы можем назвать грамматикой с конечным числом состояний. Грамматику с конечным числом состояний можно представить в виде «диаграммы состояний»[7]. Например, грамматика, порождающая равно два предложения — The man comes «Человек приходит» и The men come «Люди приходят»,— может быть представлена следующей диаграммой состояний:
(7)
Мы можем усовершенствовать эту грамматику, с тем чтобы она порождала бесконечное число предложений путем добавления к ней замкнутых петель. Так, грамматика части английского языка, содержащей, кроме упомянутых, еще предложения The old man comes «Старый человек приходит», The old old man comes «Старый-старый человек приходит», .., The old men come «Старые люди приходят», The old old men come «Старые-старые люди приходят», .., представляется диаграммой состояний (см. стр. 424).
Имея диаграмму состояний, мы порождаем предложение, совершая путь от начальной точки слева до конечной точки справа и каждый раз передвигаясь в направлении стрелок. По достижении некоторой точки диаграммы мы можем следовать по любому пути, исходящему из этой точки независимо от того, проходили ли мы по этому пути когда-либо прежде при построении данного предложения или нет. Каждый узел диаграммы, таким образом, соответствует некоторому состоянию машины. Мы можем допустить переход из состояния в состояние по нескольким путям и иметь некоторое число петель любой длины.
(8)
Машина, порождающая языки таким способом, известна в математике под именем «марковского процесса с конечным числом состояний». Для завершения этой элементарной теоретико-коммуникационной модели языка припишем некоторую вероятность каждому переходу из одного состояния в другое. Мы можем теперь вычислить «неопределенность», связанную с каждым состоянием, и определить количество информации в данном языке как взвешенное среднее неопределенностей, причем весовым коэффициентом для каждого состояния будет вероятность нахождения системы в этом состоянии. Поскольку мы изучаем здесь грамматическую, а не статистическую структуру языка, это обобщение не должно нас интересовать.
Данная концепция языка обладает очень большой силой и общностью. Приняв ее, мы можем рассматривать говорящего, по существу, как машину описанного типа. Производя предложение, говорящий начинает с начального состояния, произносит первое слово предложения и тем самым переключается во второе состояние, которое ограничивает выбор второго слова и т. д. Каждое состояние, через которое он проходит, соответствует грамматическим условиям, ограничивающим выбор следующего слова в этой точке высказывания[8].
Учитывая общий характер этой концепции языка и ее значимость для таких смежных дисциплин, как теория коммуникации, важно установить следствия приложения ее к синтаксическому изучению таких языков, как английский, или к формализованной системе математики. Всякая попытка построить грамматику с конечным числом состояний для английского языка с первых же шагов наталкивается на серьезные затруднения и сложности, которые читатель легко может себе представить. Однако нет необходимости иллюстрировать это примерами, поскольку существует следующее более общее утверждение, относящееся к английскому языку:
(9) Английский язык не является языком с конечным числом состояний. Это значит, что невозможно, а не только трудно построить механизм описанного выше типа (диаграмма вида (7) или (8)), который порождал бы все грамматически правильные предложения английского языка, и только их. Чтобы убедиться в справедливости утверждения (9), необходимо определить синтаксические свойства английского языка более точно. Ниже мы опишем некоторые синтаксические свойства английского языка, благодаря чему станет ясно, что при любых разумных ограничениях множества предложений языка утверждение (9) может считаться теоремой для английского языка. Возвращаясь к вопросу, поставленному в § 3.2[9], мы можем сказать, что утверждение (9) равносильно утверждению о невозможности установления морфемной структуры предложений непосредственно с помощью таких механизмов, как диаграмма состояний, и о неприемлемости, по крайней мере для целей грамматики, концепции языка, основанной на марковском процессе, описанном выше.
3.2.
Язык определяется путем задания его «алфавита» (т. е. конечного множества символов, из которых строятся его предложения) и его грамматически правильных предложений. Прежде чем приступить непосредственно к исследованию английского языка, рассмотрим несколько языков, алфавит которых содержит всего две буквы a и b и предложения которых определяются правилами (10 I—III):
(10) (I) ab, aabb, aaabbb и вообще все предложения, состоящие из n вхождений a, за которыми следуют n вхождений b, и только такие предложения;
(II) аа, bb, abba, baab, аааа, bbbb, aabbaa, abbbba,.. и вообще все предложения, состоящие из цепочки X, за которой следует «зеркальное отражение» X (т. е. Х в обратном порядке), и только такие предложения;
(III) аа, bb, abab, baba, аааа, bbbb, aabaab, abbabb,.. и вообще все предложения, состоящие из цепочки X (содержащей в некоторой комбинации буквы а и Ь), за которой следует точно такая же цепочка X, и только такие предложения.
Легко доказать, что каждый из этих трех языков не является языком с конечным числом состояний. Сходным образом и языки типа (10), в которых буквы а и b не следуют друг за другом, а включены в другие цепочки, также не являются языками с конечным числом состояний при весьма общих условиях[10].
Но ясно, что существуют части английского языка, имеющие структуру вида (10 I) и (10 II). Пусть S1, S2, S3,.. — повествовательные предложения английского языка. Тогда мы можем записать английские предложения так:
(11) (I) If S1, then S,.
„Если S1 то S2“.
(II) Either S3, or S4.
„Либо S,, либо S4“.
(III) The man who said that S5, is arriving today.
„Человек, который сказал, что S5, прибывает сегодня".
В (11 I) мы не можем поставить or вместо then, в (11 II) нельзя заменить or словом then, в (11 III) мы не можем поставить are на место is. В каждом из этих случаев существует некоторая зависимость между словами, стоящими по обе стороны запятой (т. е. if — then, either — or, man — is). Однако между взаимозависимыми словами мы можем вставить повествовательное предложение S1, S3, S5, и это повествовательное предложение может, разумеется, иметь вид одного из (11 I—III). Так, если принять, что в (11 I) S1 есть (11 II), a S3 есть (11 III), мы получим предложение:
(12) if, either (11 III), or S4 then S2
«если, либо (11 III), либо S4, тогда S2»,
a S5 в (11 III) может оказаться снова одним из предложений (11). Отсюда ясно, что в английском языке можно найти предложение a+S1+b, в котором существует зависимость между a и b, затем в качестве S1 выбрать другое предложение типа c+S2+d, в котором существует зависимость между с и d, а затем в качестве S2 выбрать еще одно из предложений такого типа и т. д. Множество предложений, образуемых таким способом (а мы видели из примера (11), что существует несколько возможных вариантов построения, причем (11) далеко не исчерпывает этих возможностей), обладает всеми зеркальными свойствами множества (10 II), исключающими его из совокупности языков с конечным числом состояний. Следовательно, в английском языке можно обнаружить различные модели, не отвечающие условиям конечного числа состояний. Все сказанное здесь является общим указанием на путь, следуя по которому можно представить строгое доказательство утверждения (9), если принять, что такие предложения, как (11) и (12), принадлежат английскому языку, а предложения, противоречащие указанным зависимостям (11) (например, either S1, then S2 «либо S1, то S2» и т. п.), не имеют места в этом языке. Заметим, что многие предложения типа (12) и т. п. выглядят весьма странно и необычно (их часто можно сделать менее странными, подставив вместо if «если» выражения whenever «всякий раз, когда», on the assumption that «в допущении, что», if it is the case that «если верно, что» и т. п. без изменения существа наших замечаний). Все это тем не менее грамматически правильные предложения, построенные по правилам настолько простым и элементарным, что самая примитивная грамматика английского языка непременно должна включать эти предложения. Их можно понять, и мы даже можем весьма просто определить условия, при которых они представляют собой истинные высказывания. Трудно представить себе сколько-нибудь основательные мотивы для исключения их из числа грамматически правильных предложений английского языка. Кажется, таким образом, весьма очевидным, что никакая теория лингвистической структуры, основанная исключительно на марковской и подобных ей моделях, не в состоянии объяснить способность говорящего по-английски производить и понимать новые предложения и вместе с тем отбрасывать некоторые новые последовательности как не принадлежащие языку.
3.3.
Предположим, что процессы построения английских предложений, подобные рассмотренным, могут осуществляться не более n-ного количества раз при некотором фиксированном n. Тем самым английский язык превратится, разумеется, в язык с конечным числом состояний (к тому же результату приведет, например, ограничение длины английского предложения миллионом слов). Такие произвольные ограничения не приносят, однако, никакой пользы. Важно то, что существуют процессы построения предложений, которые грамматики с конечным числом состояний в принципе не способны истолковать. Если эти процессы не имеют конечного предела, мы можем доказать буквальную неприложимость данной элементарной теории. Если процессы имеют предел, то построение грамматики с конечным числом состояний не является в буквальном смысле слова немыслимым, поскольку предложения можно перечислить, а список и есть по существу тривиальная грамматика с конечным числом состояний. Но такая грамматика окажется настолько сложной, что не будет представлять интереса и не принесет никакой пользы. Вообще допущение о бесконечности языка делается для упрощения его описания. Если грамматика не содержит рекурсивных механизмов (замкнутых петель, как в (8), для случая грамматики с конечным числом состояний), она оказывается недопустимо сложной. Если же в ней появляются некоторого рода рекурсивные механизмы, она порождает бесконечное число предложений.
Короче говоря, метод анализа выдвигаемого здесь понятия степени грамматической правильности в терминах марковского процесса с конечным числом состояний, порождающего предложения слева направо, заводит в тупик в той же мере, как и гипотезы, отклоненные выше (см. § 2). Если грамматика подобного типа порождает все английские предложения, она произведет на свет также много и непредложений. Если она порождает только английские предложения, то мы можем быть уверены, что найдется бесконечное число истинных предложений, ложных предложений, правильно поставленных вопросов и т. д., которые она просто не в состоянии породить.
Отклоненная только что концепция грамматики представляет собой простейшую лингвистическую теорию, заслуживающую серьезного рассмотрения. Грамматика с конечным числом состояний — это простейший тип грамматики, которая с конечным набором средств способна порождать бесконечное число предложений. Мы видели, что такая ограниченная лингвистическая теория не адекватна; мы вынуждены искать какой-то более сильный тип грамматики и какую-то более «абстрактную» форму лингвистической теории. Понятие «лингвистического уровня представления», введенное в начале настоящей главы, должно быть видоизменено и усовершенствовано. По крайней мере один уровень не может иметь такой простой структуры. Другими словами, на некотором уровне оказывается невозможным представлять каждое предложение просто как конечную последовательность элементов определенного рода, порождаемых слева направо некоторым простым механизмом. Если этого не сделать, то нельзя надеяться найти конечное множество уровней, упорядоченных сверху вниз, таких, чтобы можно было породить все высказывания путем задания допускаемых последовательностей элементов самого высокого уровня, разложения каждого элемента высшего уровня на элементы второго уровня и т. д. и, наконец, задания фонемного состава элементов предпоследнего уровня[11]
В Начале § 3 мЬі предложили для упрощения описания грамматически правильных последовательностей фонем устанавливать уровни таким способом. Если язык можно описать элементарным образом (через порождение слева направо) с помощью единственного уровня (т. е. если это язык с конечным числом состояний), то такое описание действительно можно упростить, построив более высокие уровни; но для порождения таких неконечных языков, как английский, необходимы коренным образом отличные методы и более общая концепция «лингвистического уровня».
4. МОДЕЛЬ НЕПОСРЕДСТВЕННО СОСТАВЛЯЮЩИХ[12]
4.1.
Обычно лингвистическое описание на синтаксическом уровне формулируется в терминах анализа по непосредственно составляющим. Спросим себя, какова та форма грамматики, из которой исходят при описании такого рода? Мы увидим, что эта новая форма грамматики является существенно более сильной, чем отброшенная выше модель с конечным числом состояний, и что отвечающая ей концепция «лингвистического уровня» коренным образом отлична от предыдущей концепции.
В качестве простого примера того вида грамматик, который связан с анализом по непосредственно составляющим, рассмотрим следующую систему:
(13) (1) Sentence—>NP+VP
(II) NP—>T+N
(III) VP—>Verb+NP
(IV) T—>the
(V) N—>man, ball и т. д.
(VI) Verb—>hit, took и т. д.
Пусть каждое правило вида X—>Y системы (13) означает предписание: «вместо X подставить К». Систему (14) мы можем назвать деривацией предложения The man hit the ball «Человек ударил мяч». Номер справа от Каждой строки деривации показывает, какое правило «грамматики» (13) используется для получения данной строки из предыдущей[13].
(14) Sentence
NP+VP (I)
T+N+VP (II)
T+N+Verb+NP (III)
the+N+Verb+NP (IV)
the+man+Verb+NP (V)
the+man+hit+NP (VI)
the+man+hit+T+N (II)
the+man+hit+the+N (IV)
the+man+hit+the+ball (V)
Таким образом, вторая строка (14) получается из первой подстановкой NP+VP вместо Sentence по правилу (1) системы (13); третья строка получается из второй подстановкой T+N вместо NP по правилу (II) и т. д. Мы можем наглядным образом представить деривацию (14) с помощью следующей схемы:
(15)
Схема (15) несет меньше информации, чем деривация
(14) , поскольку она не показывает, в каком порядке применяются правила. Имея (14), мы можем построить (15) только одним способом, но не обратно, так как можно построить деривацию, сводящуюся к (15), но имеющую иной порядок применения правил. Схема (15) содержит именно то, что есть существенного в (14) для определения структуры непосредственно составляющих предложения- деривата The man hit the ball «Человек ударил мяч». Некоторая последовательность слов в этом предложении есть составляющая типа Z, если на схеме (15) мы можем возвести эту последовательность к некоторой одной точке, и эта точка обозначена Z. Так, hit the ball «ударил мяч» можно возвести к VP в (15); следовательно, в предложении-деривате hit the ball есть VP. Но man hit нельзя возвести ни к какой одной точке на схеме (15); значит, man hit — вообще не составляющая.
Мы называем две деривации эквивалентными, если они сводятся к одной и той же схеме типа (15). В некоторых случаях грамматика позволяет построить неэквивалентные деривации заданного предложения. В таких условиях можно говорить о «конструкционной омонимии»[14]. Если наша грамматика правильна, данное предложение должно быть двусмысленным. Ниже мы вернемся к этому важному понятию конструкционной омонимии.
Очевидна необходимость следующего обобщения системы (13). Мы должны иметь возможность ограничивать применение некоторого правила определенным контекстом. Так, вместо Т можно подставить а, если следующее существительное стоит в единственном числе, но не во множественном; точно так же вместо Verb можно подставить hits, если ему предшествует существительное man, но нельзя — если ему предшествует men. Вообще, если мы хотим ограничить подстановку Y вместо X контекстом Z—>W, мы можем задать в грамматике правило
(16) Z+X+W—>Z+Y+W
Например, в том случае, когда рассматривается единственное и множественное число глаголов, мы должны вместо того, чтобы добавлять к (13) правило Verb—>hits, добавить правило
(17) NPsing+Verb —> Npsing+hits.
показывающее, что hits подставляется на место Verb только в контексте NPsing—. Соответственно, правило (13 II) должно быть сформулировано так, чтобы можно было учесть NPsing и NPpl[15]. Это прямое обобщение правила (13). Одна черта системы (13) должна быть сохранена, однако, как это имеет место в (17): при применении одного правила только один элемент может подвергаться подстановке; другими словами, в (16) X должен представлять собой один символ, например Т или Verb, а не последовательность символов, как, скажем, T+N. Если это условие не соблюдено, мы не можем надлежащим образом восстановить структуру непосредственно составляющих предложений-дериватов по соответствующим схемам вида (15) , как мы делали выше.
Теперь мы в состоянии дать более общее описание того типа грамматики, который связан с теорией лингвистической структуры, основанной на анализе по непосредственно составляющим. Всякая такая грамматика определяется конечным множеством Σ начальных цепочек и конечным множеством F «формул-команд» вида X—>Y, означающих: «подставить Y вместо X». Хотя X не обязательно должно быть одним символом, только один символ из состава X может быть заменен при образовании Y. В грамматике (13) множество Σ начальных цепочек состоит из единственного символа Sentence, a F состоит из правил (I) —(VI); но мы можем потребовать расширения множества Σ, с тем чтобы оно включало, например, Declarative Sentence, Interrogative Sentence в качестве дополнительных символов. Обладая грамматикой [Σ,F], мы определяем деривацию как конечную последовательность цепочек, начинающуюся с одной из начальных цепочек Σ, такую, что каждая цепочка в ней получается из предыдущей цепочки в результате применения одной из формул-команд множества F. Так, (14) есть деривация; пятичленная последовательность цепочек, состоящая из первых пяти строк (14),также есть деривация. Некоторые деривации являются завершенными в том смысле, что нет такого правила в F, с помощью которого можно было бы преобразовать их последнюю цепочку. Так, (14) — завершенная деривация, а последовательность первых пяти строк (14) — незавершенная. Если какая-то цепочка является последней цепочкой завершенной деривации, мы называем ее терминальной.Так, the+man+hit+the+ball есть терминальная цепочка грамматики (13). Некоторые грамматики типа [Σ,F] могут не иметь терминальных цепочек, но мы интересуемся только теми грамматиками, которые их имеют, то есть описывающими некоторые языки. Множество цепочек называется терминальным языком, если это множество является множеством терминальных цепочек некоторой грамматики [Σ,F]. Таким образом, каждая такая грамматика определяет некоторый терминальный язык (в частности, «пустой» язык, не содержащий ни одного предложения), и каждый терминальный язык порождается некоторой грамматикой типа [Σ,F], Имея терминальный язык и его грамматику, мы можем реконструировать структуру непосредственно составляющих каждого предложения этого языка (каждой терминальной цепочки грамматики), рассматривая соответствующие схемы типа (15), как мы делали это выше. Мы можем также определить грамматические отношения в этих языках формальным образом в терминах соответствующих схем.
4.2.
В § 3 мы рассмотрели языки, названные «языками с конечным числом состояний», которые порождаются посредством марковских процессов с конечным числом состояний. В настоящей главе мы рассматриваем терминальные языки, порождаемые системами вида [Σ,F]. Эти два типа языков связаны друг с другом следующим образом.
Теорема: Каждый язык с конечным числом состояний есть терминальный язык, но существуют терминальные языки, не являющиеся языками с конечным числом состояний[16]. Важно в этой теореме то, что описание в терминах модели непосредственно составляющих оказывается существенно более сильным, чем описание в терминах элементарной теории, рассмотренной выше в § 3. Примерами терминальных языков, не являющихся языками с конечным числом состояний, могут служить языки (10 I) и (10 II), рассмотренные в § 3. Так, язык (10 I), состоящий из всех цепочек вида ab, aabb, aaabbb,.. и только этого вида, может порождаться [Σ,F]-грамма- тикой (18):
(18) Σ: Z
F: Z—>ab
Z—>aZb
Эта грамматика имеет начальную цепочку Z [как,(13) имеет в качестве начальной цепочки символ Sentence] и два правила. Нетрудно заметить, что каждая завершенная деривация, построенная согласно (18), оканчивается цепочкой языка (10 I) и что этим способом порождаются все такие цепочки. Подобным образом языки вида (10 II) также могут порождаться [Σ,F]-грамматиками. Язык (10 III), однако, не может порождаться грамматикой этого типа.
В § 3 мы указали, что языки (10 I) и (10 II) соответствуют определенным частям английского языка и что поэтому модель марковского процесса с конечным числом состояний не адекватна английскому языку. Мы убедились теперь, что модель непосредственно составляющих не оказывается несостоятельной в таких случаях. Мы не доказали адекватности этой модели, но нам удалось показать, что значительные части английского языка, которые в буквальном смысле не могут быть описаны в терминах модели с конечным числом состояний, описываются в терминах модели непосредственно составляющих.
Можно сказать, что в случае (18) в цепочке aaabbb языка (10 I) ab, например, есть Z, aabb есть Z и aaabbb само есть Z[17]. Таким образом, эта конкретная цепочка содержит три группы, каждая из которых есть Z. Это, разумеется, весьма тривиальный язык. Важно отметить, что при описании данного языка мы ввели символ Z, который не содержится в предложениях указанного языка. Это существенная черта модели непосредственно составляющих, обусловливающая ее «абстрактный» характер.
Заметим также, что в случае (13) и (18) (как вообще в случае любой системы непосредственно составляющих) всякая терминальная цепочка имеет несколько представлений. Так, например, в случае (13) терминальная цепочка The man hit the ball «Человек ударил мяч» представляется цепочками Sentence, NP+VP, T+N+VP и вообще любой из строк системы (14), равно как и цепочками типа NP+Verb+NP, T+N+hit+NP, которые могут выступать в деривациях, эквивалентных (14) в определенном выше смысле. На уровне непосредственно составляющих, следовательно, каждое предложение определенного языка представляется множеством цепочек, а не одной цепочкой, как это имеет место на уровнях фонем, морфем или слов. Таким образом, структура непосредственно составляющих, рассматриваемая как лингвистический уровень, имеет радикально иной и нетривиальный характер, что, как мы видели в § 3.3, необходимо для некоторых лингвистических уровней. Мы не можем установить иерархию среди различных представлений предложения The man hit the ball «Человек ударил мяч»; мы не можем разбить систему непосредственно составляющих на конечное множество уровней, упорядоченных от верхнего до нижнего так, чтобы каждое предложение имело одно представление на каждом из этих подуровней. Например, нет способа установить очередность по вертикали для элементов NP и VP. В английском языке именная группа может содержаться в глагольной, а глагольная — в именной. Структура непосредственно составляющих должна рассматриваться как единый уровень с множеством представлений для каждого предложения языка. Существует взаимно однозначное соответствие между правильно выбранными множествами представлений и схемами типа (15).
4.3.
Допустим, что с помощью [Σ,F]-грамматики мы можем порождать все грамматически правильные последовательности морфем какого-то языка. Для завершения грамматики мы должны установить фонемную структуру этих морфем, с тем чтобы грамматика производила грамматически правильные последовательности фонем данного языка. Но и эта часть грамматики (которую мы назовем морфофонемикой языка) также может быть задана в виде набора правил типа «подставить Y вместо X», то есть, для английского языка, в виде системы
(19) (I) walk—>/wok/
(И) take+past—>/tuk/
(III) hit+past—>/hit/
(IV) /...D/+past—>/...D/+/id/ (где D=/t/ или /d/)
(V) /...Cunv/+past—>/...Cunv/+/t/ (где Cunv — глухая согласная)
(VI) past—>/d/
(VII) take—>/teyk/ и т. д.
или чего-либо в этом роде. Заметим, в частности, что между этими правилами должна быть установлена очередность. Так, правило (II) должно предшествовать правилу (V) или правилу (VII), иначе мы получим такие формы, как /teykt/ для прошедшего времени от глагола take «брать». Для этих морфофонемных правил уже не является обязательным требование, чтобы в результате применения каждого правила заменялся только один символ.
Теперь мы можем прибавить к деривациям модели непосредственно составляющих систему (19); в результате мы получим единый процесс порождения последовательностей фонем из начальной цепочки Sentence. Это может создать впечатление, что граница между уровнем непосредственно составляющих и более низкими уровнями произвольна. В действительности это не так. Во-первых, как мы видели, формальные свойства правил X—>Y, относящихся к модели непосредственно составляющих, отличаются от свойств правил морфофонемики, поскольку в первом случае мы должны требовать, чтобы заменялся только один символ. Во-вторых, элементы, фигурирующие в правилах (19), могут быть разбиты на конечное число уровней (например, фонемы и морфемы; или, может быть, фонемы, морфофонемы и морфемы), каждый из которых является элементарным в том смысле, что лишь единственная цепочка элементов этого уровня служит представлением для каждого предложения на данном уровне (если исключить случаи омонимии) и что каждая такая цепочка представляет лишь одно предложение. Элементы же, появляющиеся в правилах, относящихся к модели непосредственно составляющих, не могут быть разбиты на более высокие и более низкие уровни указанным способом.
Ниже мы увидим, что существует более глубокое основание для того, чтобы различать правила модели непосредственно составляющих, носящие характер более высокого уровня, и правила, носящие характер более низкого уровня, превращающие цепочки морфем в цепочки фонем.
Формальные свойства модели непосредственно составляющих представляют предмет интересного исследования, и легко доказать, что дальнейшая разработка этого типа грамматики необходима и возможна. Нетрудно обнаружить, что весьма выгодно расположить правила множества F так, чтобы некоторые из правил могли применяться только после того, как другие правила уже были применены. Например, определенно необходимо, чтобы правила типа (17) применялись раньше любого правила, позволяющего нам подставить NP+Preposition+NP вместо NP и т. п.; в противном случае грамматика будет порождать такие непредложения, как The men near the truck begins work at eight. Однако такая разработка связана с проблемами, уводящими нас за рамки этого исследования.
5. ОГРАНИЧЕННОСТЬ ОПИСАНИЯ ПО НЕПОСРЕДСТВЕННО СОСТАВЛЯЮЩИМ
5.1.
Мы рассмотрели две модели структуры языка: теоретико-коммуникационную модель, основанную на представлении о языке как о марковском процессе, являющуюся в некотором смысле минимальной лингвистической теорией, и модель, основанную на анализе по непосредственно составляющим. Мы убедились, что первая из них, безусловно, не адекватна задачам грамматики и что вторая является более сильной, чем первая, оставаясь пригодной в тех случаях, когда первая оказывается несостоятельной. Вместе с тем существуют, разумеется, языки, которые не могут быть описаны в терминах модели непосредственно составляющих ((10 III) — один из них). Я не знаю, является ли английский язык таким языком, который в буквальном смысле находится вне сферы компетенции анализа подобного рода. Я думаю, однако, что существуют другие основания для того, чтобы отклонить теорию анализа по непосредственно составляющим как не адекватную целям лингвистического описания.
Самое сильное из возможных доказательств неадекватности лингвистической теории состоит в том, чтобы показать, что она вообще не может быть применена к некоторому естественному языку. Более слабым, но вполне достаточным доказательством было бы показать, что эту теорию можно применить лишь громоздким, неизящным способом; другими словами — показать, что любая грамматика, которую можно построить на основе этой теории, будет чрезвычайно сложной, эмпиричной, ad hoc, и не «наглядной», что некоторые весьма простые способы описания грамматически правильных предложений не могут быть формализованы в терминах грамматики и что некоторые фундаментальные формальные свойства естественного языка нельзя использовать для упрощения грамматик. Мы в состоянии привести большое число свидетельств подобного рода в пользу того положения, что описанный выше тип грамматики, а также лежащая в его основе лингвистическая теория принципиально неадекватны.
Единственный способ проверить адекватность данного механизма — попытаться применить его непосредственно для описания английских предложений. Как только мы рассмотрим предложения, выходящие за пределы простейшего типа, и в особенности попытаемся установить какую-то очередность среди правил, порождающих эти предложения, мы натолкнемся на многочисленные сложности изатруднения. Обоснование этого утверждения потребовало бы много труда и места, и здесь я могу лишь заявить, что его можно подтвердить весьма убедительно[18]. Вместо того чтобы следовать здесь этому довольно трудному и рискованному курсу, я ограничусь кратким рассмотрением кескольких простых случаев, в которые оказывается возможным значительное упрощение описаний по сравнению с грамматиками типа [Σ,F]. В § 8 я предложу другой, независимый способ доказательства непригодности анализа по непосредственно составляющим для описания структуры английского предложения.
5.2.
Одним из наиболее продуктивных способов образования новых предложений является процесс сочинения. Если имеется два предложения Z+X+W и Z+Y+W, примем X и Y являются действительно составляющими этих предложений, мы можем в общем случае образовать новое предложение Z—X+and+Y—W. Например, из предложений (20a—b) можно получить новое предложение (21):
(20) (a) The scene —of the movie—was in Chicago
«Эта сцена—фильма—происходила в Чикаго»
(b) The scene—of the play—was in Chicago
«Эта сцена—пьесы— происходила в Чикаго»
(21) The scene—of the movie and of the play—was in Chicago.
«Эта сцена—фильма и пьесы—происходила в Чикаго».
Если же X и Y не являются составляющими, мы, вообще говоря, не сможем этого сделать[19] Например, нельзя получить (23) из (22 а—b).
(22) (a) The — liner sailed down the — river
«Этот — пароход спускался по — реке»
(b) The — tugboat chugged up the — river «Этот — буксир подымался по — реке»
(23) The — liner sailed down the and tugboat chugged up the — river
«Этот — пароход спускался по и буксир подымался по — реке».
Подобным же образом, если X и Y — оба суть составляющие, но разного рода (т. е. на схеме типа (15) каждая из них имеет одну исходную точку, но эти точки обозначены разными символами), то мы не можем в общем случае образовать новое предложение посредством сочинения. Например, нельзя образовать (25) из (24a—b).
(24) (a) The scene—-of the movie — was in Chicago
„Эта сцена — фильма — происходила в Чикаго"
(b) The scene — that I wrote — was in Chicago
„(Эта) сцена — которую я написал — происходила в Чикаго"
(25) The scene — of the movie and that I wrote — was in Chicago
„Эта сцена—фильма и которую я написал — происходила в Чикаго".
Фактически возможность сочинения представляет собой один из лучших критериев правильности первоначального определения структуры составляющих. Можно упростить описание сочинения, если дать такое определение составляющих, при котором выполнялось бы следующее правило:
(26) Если S1 и S2 — грамматически правильные предложения и S1 отличается от S2 только тем, что Y появляется в S2 на том месте, где X находится в Sl (т. е. S1= ...X... и S2=...Y...; причем X и Y — суть составляющие одного типа, соответственно в S1 и S2), то S3 есть поедложение; здесь S3 — результат подстановки X+and+Y вместо X в S1 (т. е. S3=...X+and+Y...).
Хотя это правило требует дополнительных уточнений, грамматика сильно упрощается, если определять составляющие так, чтобы (26) выполнялось, пусть даже приблизительно. Другими словами, легче установить дистрибуцию союза and путем уточнения этого правила, чем сделать это непосредственно, без помощи такого правила. Теперь, однако, перед нами возникает следующая трудность: мы не можем включить правило (26) или что-либо ему подобное в грамматику типа [Σ,F] в силу некоторых фундаментальных ограничений, наложенных на такие грамматики. Существенное свойство правила (26) состоит в том, что для примейения его к предложениям S1 и S2 с целью образования предложения S3 необходимо знать не только наличный вид Sl и S2, но и структуру их составляющих, т. е. нам должна быть известна не только окончательная форма этих предложений, но также их «деривационная история». Каждое же из правил X—>Y грамматики [Σ,F] применимо или не применимо к заданной цепочке только в зависимости от состояния этой цепочки. Каким образом цепочка постепенно получила данный вид— не существенно. Если цепочка содержит X в качестве элемента, правило X—>Y к ней применить можно; если нет, правило не применимо.
Изложим это несколько иначе. Грамматику [Σ,F] можно рассматривать как некоторый весьма элементарный процесс, порождающий предложения не «слева направо», а «сверху вниз». Пусть имеется следующая грамматика непосредственно составляющих:
(27) Σ: Sentence
F: X1—>Y1
…
Xn—>Yn
В таком случаемы можем представить эту грамматику как машину с конечным числом внутренних состояний, включая начальное и конечное состояния. Находясь в начальном состоянии, машина способна произвести только элемент Sentence, после чего она переходит в следующее состояние. В следующий момент она может произвести любую цепочку Yi такую, что Sentence—>Yi будет одним из правил F в (27) и окажется уже в следующем состоянии. Допустим, Yi есть цепочка ...Хj... Тогда машина может произвести цепочку ...Yj... посредством «применения» правила Xj—>Yj. Машина продолжает переходить таким образом от состояния к состоянию до тех пор, пока не произведет терминальной цепочки — это ее конечное состояние. Значит, машина осуществляет деривации, подобные описанным в § 4. Существенным здесь является то, что состояние машины полностью определяется цепочкой, которую она только что произвела (т. е. последней ступенью деривации); говоря конкретно, состояние определяется подмножеством «левых» элементов Хi правил F, содержащихся в последней произведенной цепочке. Но правило (26) требует более сильной машины, которая способна «оглядываться» на бо нее ранние цепочки в деривации, для того чтобы определить, каким способом выполнить следующий шаг деривации.
Правило (26) является принципиально новым также еще в одном отношении. В нем дается ссылка на два различных предложения S1 и S2, а в грамматике типа [Σ,F] нет способа предусмотреть подобную двойную ссылку. Тот факт, что правило (26) нельзя включить в грамматику непосредственно составляющих, свидетельствует о том, что, хотя эта форма грамматики в какой-то мере и применима к английскому языку, все же она не адекватна в том более слабом, но достаточном смысле, о котором шла речь выше. Это правило ведет к значительному упрощению грамматики, фактически оно представляет один из лучших критериев правильности определения составляющих. Мы увидим далее, что существует много других правил того же общего типа, что и (26), которые играют такую же двоякую роль.
5.3.
В грамматике (13) мы приводили лишь один способ разложения элемента Verb, а именно: Verb—>hit (ср. (13 VI)). Но даже при фиксированном глагольном корне (скажем, в виде take «брать») имеется много других форм, которые может принимать этот элемент, например: takes «берет», has+taken «взял», will+take «будет брать», has+been+taken «[уже] взял», is+being+taken «берется» и т. д. Исследование указанных «вспомогательных глаголов» — одна из узловых проблем при разработке английской грамматики. Мы увидим, что поведение этих глаголов вполне правильно и его легко описать, если стать на точку зрения, совершенно отличную от развиваемой выше, и, наоборот, оно окажется весьма сложным, если попытаться включить эти группы прямо в [Σ,F]-грамматику.
Рассмотрим сначала вспомогательные глаголы, выступающие как неакцентированные; например, has в John has read a book «Джон прочел книгу», но не does в John does read books «Джон действительно читает книги»[20]. Мы можем задать появление этих вспомогательных глаголов в повествовательных предложениях, добавив к грамматике (13) следующие правила:
(28) (I) Verb—>Aux+V
(II) V—>hit, take, walk, read и т. д.
(III) Aux—>C (M) (have+en) (be+ing) (be+en)
(IV) M—>will, can, may, shall, must
(29) (I)С—>{S в контексте NPsin— / 0 в контексте NPpl— / past}[21]
(II) Пусть Af есть любой из аффиксов past, S, 0, en, ing. Обозначим через v любой из элементов М, V, have, be (т. е. любой неаффикс в группе Verb). Тогда
Af+v—>v+Af#
где символ # означает границу слова[22].
(III) Подставить # вместо + во всех случаях, за исключением контекста v—Af. Вставить # в начале и в конце цепочки.
Символические выражения в (28 III) надо понимать следующим образом: мы должны выбрать элемент С и можем выбрать некоторые (в том числе и ни одного) из элементов, стоящих в скобках, сохраняя указанный порядок. В соответствии с (29 I) мы можем развернуть С в виде любой из трех морфем с соблюдением указанных контекстных ограничений. Для иллюстрации применения этих правил построим деривацию, подобную (14), опуская начальные шаги.
(30) the+man+Verb+the+book согласно (13 I—V)
the+man+Aux+V+the+book (28 I)
the+man+Aux+read+the+book (28 II)
the+man+С+have+en+be+ing+read+the+book (28 III)—мы выбираем элементы С, have+en и be+ing
the+man+S+have+en+be+ing+read+the+book (29 I)
the+man+have+S#be+en#read+ing#the+book (29 II)— 3 раза
#the#man#have+S#be+en#read+ing#the#book# (29 III)
Морфофонемные правила (19) и т. п. превращают последнюю строку этой деривации в
(31) The man has been reading the book
«Человек [начал и продолжает] читать книгу» в фонемной транскрипции. Подобным же образом может порождаться любая группа с вспомогательным глаголом. Позднее мы вернемся к вопросу о дальнейших ограничениях, которые необходимо наложить на эти правила, с тем чтобы порождались только грамматически правильные последовательности. Заметим, в частности, что система морфофонемных правил должна включать и такие правила, как will+S—>will,will+past—>would. Последние можно опустить, если мы изменим (28 III) таким образом, чтобы выбиралось С или М, но не оба вместе. Но в таком случае к (28 IV) необходимо добавить формы would, could, might, should, причем определенные правила «согласования времен» станут более сложными. Для наших дальнейших рассуждений несущественно, какой из этих путей принять. Возможны также и другие, более мелкие изменения.
Заметим, что для применения (29 I) в примере (30) мы должны были использовать тот факт, что the+man является именной группой в единственном числе, т. е. NPsing. Другими словами, мы должны были обратиться к некоторому более раннему этапу деривации для определения структуры составляющих цепочки the+man. (Иной порядок очередности (29 I) и правила, разворачивающего NPsing в the+man, при котором (29 I) следует раньше, невозможен в силу многих причин; некоторые из них выяснятся ниже.) Следовательно, правило (29 I), равно как и (26), выходит за пределы элементарного марковского характера грамматик непосредственно составляющих и не может быть включено в (Σ,F)-грамматику.
Правило (29 II) нарушает условия (Σ,F)-грамматик еще сильнее. Оно также требует обращения к структуре составляющих (т. е. к предыдущей истории деривации), и, кроме того, у нас нет способа выразить необходимую инверсию в терминах модели непосредственно составляющих. Заметим, что указанное правило используется в грамматике еще в ряде случаев, например там, где Af есть ing. Таким образом, морфемы to и ing играют весьма сходную роль в именной группе: они превращают глагольную группу в именную, давая, например:
(32) {to prove that theorem / proving that theorem} was difficult
{«доказать эту теорему» / «доказательство зтой теоремы»} «было трудно».
и т. п. Мы можем выразить эту параллель, добавив к грамматике (13) правило
(33) NP—>{ing / to}VP
Правило (29 II) переводит затем ing+prove+that+theorem в proving#that+theorem. Более детальный анализ VP показывает, что эта параллель заходит в действительности гораздо дальше.
Читателю легко убедиться в том, что получить такой же эффект, какой мы получаем с помощью (28 III) и (29), не выходя за рамки системы (Σ,F)-грамматики непосредственно составляющих, можно лишь посредством весьма сложного аппарата. Еще раз, как и в случае сочинения, мы убеждаемся, что возможно значительное упрощение грамматики, если допустить формулирование правил более сложного типа, чем те, которые соответствуют системе анализа по непосредственно составляющим. Допустив использование правила (29 II), мы получаем возможность установить состав группы с вспомогательным глаголом в (28 III), не обращаясь к взаимозависимостям элементов внутри нее (а мы ведь знаем, что всегда легче описать последовательность независимых элементов, чем последовательность взаимозависимых). Иначе говоря, группа с вспомогательным глаголом является в действительности разрывной, например в (30) мы находим элементы have... еn и be... ing. Но (Σ,F)-грамматики не могут иметь дело с разрывами[23]. В (28 III) мы трактовали эти элементы как неразрывные и ввели затем разрывность посредством весьма простого дополнительного правила (29 II). Мы увидим ниже, в § 7, что такое разложение элемента Verb служит основой для далеко идущего и чрезвычайно простого анализа некоторых важных особенностей английского синтаксиса.
5.4.
В качестве третьего примера недостаточности понятий, относящихся к уровню непосредственно составляющих, рассмотрим случай активно-пассивного отношения. Пассивные предложения образуются путем выбора элемента be+en в правиле (28 III). Но существуют сильные ограничения, налагаемые на этот элемент, которые выдвигают его на особое место среди элементов группы с вспомогательным глаголом. Во-первых, be+en можно выбрать только в том случае, если следующий V является переходным (например, was+eaten допустимо, a was+occurred —нет); другие же элементы группы с вспомогательным глаголом проявляют, за немногими исключениями, безразличие к выбору знаменательного глагола. Кроме того, be+en нельзя выбрать, если за V следует именная группа, как в (30) (например, у нас вообще не может быть выражения NP+is+V+en+NP, даже если V является переходным, т. е. у нас не должно получиться Lunch is eaten John «Завтрак съеден Джон»). Далее, если V является переходным и за ним следует предложная группа by+NP, мы обязаны выбрать be+en (тогда мы будем иметь Lunch is eaten by John «Завтрак съедается Джоном», но не John is eating by lunch «Джон съеден завтраком» и т. д.). Наконец, заметим, что при развертывании (13) в исчерпывающую грамматику мы должны наложить многие ограничения на выбор V для различения субъекта и объекта, с тем чтобы разрешенными были такие предложения, как: John admires sincerity «Джон восхищается искренностью»; Sincerity frightens John «Искренность пугает Джона»; John plays golf «Джон играет в гольф»; John drinks wine «Джон пьет вино», но не такие непредложения[24], как: Sincerity admires John «Искренность восхищается Джоном»; John frightens sincerity «Джон пугает искренность»; Golf plays John «Гольф играет в Джона»; Wine drinks John «Вино пьет Джона». Вся эта система ограничений совершенно теряет смысл, если мы выберем be+en в качестве части вспомогательного глагола. Фактически в таком случае сохраняются те же самые избирательные зависимости, но в обратном порядке. Это значит, что всякому предложению NP1—V—NP2 может соответствовать предложение NP2—is+Ven—by+NP1. Если попытаться включить пассивные предложения в грамматику (13) непосредственно, окажется необходимым заново сформулировать все ограничения, но в обратном порядке — для случая, когда в качестве части вспомогательного глагола выбирается be+en. Этого неизящного удвоения, равно как и специальных ограничений, включающих элемент be+en, можно избежать только тогда, когда мы произвольным образом исключим пассивные предложения из грамматики непосредственно составляющих и введем их снова посредством правила типа
(34) . Если S1 — грамматически правильное предложение вида
NP1—Aux—V—NP2, то соответствующая цепочка вида
NP2—Aux+be+en—V—by+NP1
является также грамматически правильным предложением.
Например, если John—С—admire—sincerity есть предложение, то Sincerity—C+be+en—admire—by+John (которая действием (29) и (19) превращается в Sincerity is admired by John «Искренность восхищает Джона») также является предложением.
Мы можем теперь опустить в (28 III) элемент be+en и все связанные с ним специальные ограничения. То, что элемент be+en требует переходного глагола, что он не может выступать перед V+NP, что он должен стоять перед V+by+NP (где V — переходный глагол), что он инвертирует окружающие именные группы, оказывается в каждом конкретном случае автоматическим следствием правила (34). Это правило, таким образом, ведет к значительному упрощению грамматики. Однако (34) далеко выходит за рамки (Σ,F)-грамматики. Подобно (29 II), оно требует обращения к структуре составляющих цепочки, к которой оно применяется, и осуществляет инверсию этой цепочки структурно определенным способом.
5.5.
Мы рассмотрели три правила ((26), (29), (34)), которые существенно упрощают описание английского языка, но не могут быть включены в (Σ,F)-грамматику. Существует немало иных правил этого типа; некоторые из них мы рассмотрим ниже. Исследуя далее недостатки грамматик непосредственно составляющих, мы можем показать вполне убедительно, что эти грамматики будут так безнадежно сложны, что окажутся совершенно неинтересными, если не включить в них такие правила.
Если же тщательно разобраться в предпосылках, из которых исходят эти правила, мы увидим, что они ведут к совершенно новой концепции лингвистической структуры. Назовем каждое подобное правило «грамматической трансформацией». Грамматическая трансформация Т, воздействуя на заданную цепочку (или, как в случае (26), на совокупность цепочек) с заданной структурой составляющих, преобразует ее в новую цепочку с новой производной структурой составляющих. Чтобы показать, как эта операция осуществляется, необходимо весьма обширное исследование, которое поведет нас далеко за рамки данной работы; тем не менее можно разработать некоторую, довольно сложную, но вполне разумную алгебру трансформаций, удовлетворяющую очевидным требованиям, предъявляемым к грамматическому описанию[25].
В приведенных примерах можно уже обнаружить некоторые из существенных черт трансформационной грамматики. Во-первых, ясно, что необходимо определить очередность применения имеющихся трансформаций. Пассивная трансформация (34), например, должна применяться перед (29). За ней должна следовать (29 I) уже потому, что глагольный элемент в полученном пассивном предложении должен иметь то же число, что и новое грамматическое подлежащее. Она должна предшествовать (29 II), для того чтобы последнее правило могло быть надлежащим образом применено к новому вставленному элементу be+en. (Обсуждая вопрос о возможности включить (29 I) в [Σ,F]-грамматику, мы упомянули о том, что нельзя требовать, чтобы данное правило применялось прежде правила, развертывающего NPsing в the+man, и т. п. Одно из оснований для этого теперь очевидно: (29 I) должно применяться после (34), (34) же должно применяться после развертывания NPsing, иначе мы не получим надлежащих отношений выбора между подлежащим и глаголом и между глаголом и «действующим лицом» пассивного предложения.)
Во-вторых, заметим, что некоторые трансформации являются обязательными, тогда как другие лишь факультативны. Например, (29) необходимо применять к любой деривации, так как без него мы предложения просто не получим[26]. Пассивная же трансформация (34) может применяться, а может и не применяться в зависимости от конкретных обстоятельств. И в том и в другом случае результатом будет предложение. Значит, (29) — обязательная трансформация, а (34) — факультативная.
Это различение между обязательными и факультативными трансформациями приводит к установлению фун: даментального различия между предложениями языка. Допустим, существует грамматика G с [Σ,F]-частью и трансформационной частью, и пусть трансформационная часть имеет некоторые обязательные трансформации и некоторые факультативные трансформации. Тогда мы можем определить ядро языка (в терминах грамматики G) как множество предложений, получаемых в результате применения обязательных трансформаций к терминальным цепочкам [Σ,F]-грамматики. Трансформационная часть грамматики задается таким образом, что трансформации могут применяться к ядерным предложениям (точнее — к формам, лежащим в основе ядерных предложений, т. е. к терминальным цепочкам [Σ,F]-части грамматики) или ранее полученным трансформам. Таким образом, всякое предложение языка либо принадлежит ядру, либо выводится из цепочек, лежащих в основе одного или более ядерных предложений, применением последовательности из одной или более трансформаций.
Эти рассуждения позволяют нам представить грамматику как систему, обладающую естественным трехчастным строением. В соответствии с уровнем непосредственно составляющих грамматика обладает последовательностью правил вида X—>Y, а в соответствии с более низкими уровнями — последовательностью морфофонемных правил того же основного вида. В качестве промежуточного звена между этими двумя последовательностями она имеет последовательность трансформационных правил. Таким образом, грамматика должна выглядеть так:
(35) Σ: Sentence:
X1—>Y1 … Xn—>Yn } Уровень непосредственно составляющих
T1 … Tn } Трансформационный уровень
Z1—>W1 … Zn—>Wn } Морфофонемный уровень
Для получения предложения с помощью такой грамматики мы строим расширенную деривацию, начиная с Sentence. Пробегая правила, мы строим терминальную цепочку, которая представляет собой последовательность морфем, расположенных не обязательно в правильном порядке. Затем мы пробегаем последовательность трансформаций Т,,...Ту, применяя все обязательные трансформации и, возможно, некоторые факультативные. Эти трансформации могут переупорядочивать цепочки, а также добавлять и опускать морфемы. В результате они выдают цепочку слов. Затем мы пробегаем морфофонемные правила, обращая цепочку слов в цепочку фонем. Отрезок грамматики непосредственно составляющих включает такие правила, как (13), (17) и (28). Трансформационная часть состоит из правил типа (26), (29) и (34), сформулированных надлежащим образом в терминах, которые должны быть разработаны в полной теории трансформаций. Морфофонемная часть включает такие правила, как (19). Эта схема процесса порождения предложений должна (и легко может) быть обобщена, с тем чтобы обеспечить надлежащее функционирование таких правил, как (26), воздействующих на несколько предложений. Она должна быть обобщена и для того, чтобы обеспечить возможность повторного применения трансформаций к трансформам с целью получения все более и более сложных предложений.
Если для порождения данного предложения применяются только обязательные трансформации, мы называем полученное предложение ядерным. Дальнейшее исследование покажет, что в части грамматики, относящейся к уровню непосредственно составляющих, и в морфофонемной части грамматики можно выделить также некоторый скелет обязательных правил, которые должны применяться всякий раз, как мы приходим к ним в процессе порождения предложений. В § 4 мы указывали, что правила модели непосредственно составляющих приводят к такой концепции лингвистической структуры и «уровня представления», которая принципиально отличается от концепции, связанной с морфофонемными правилами. На каждом из нижних уровней, отвечающих нижней трети грамматики, высказывание представлено, вообще говоря, единственной последовательностью элементов. Однако уровень непосредственно составляющих не может быть разбит на подуровни: на уровне непосредственно составляющих высказывание представляется в виде множества цепочек, которые нельзя разместить по более высоким или более низким уровням. Это множество цепочек эквивалентно схеме типа (15). На трансформационном уровне высказывание представляется еще более абстрактно, через последовательность трансформаций, посредством которых оно выводится в конечном счете из ядерных предложений (точнее, из цепочек, лежащих в основе ядерных предложений). Существует весьма естественное общее определение «лингвистического уровня», включающее все эти случаи[27], и, как мы увидим ниже, имеется полное основание считать, что каждая из этих структур является лингвистическим уровнем.
Когда правила трансформационного анализа надлежащим образом сформулированы, мы обнаруживаем, что он является значительно более сильным, чем описание в терминах модели непосредственно составляющих, подобно тому, как последнее является значительно более сильным, чем описание в терминах марковского процесса с конечным числом состояний, который порождает предложения слева направо. В частности, такие языки, как (10 III), лежащие вне границ описания по непосредственно составляющим, могут выводиться трансформационным путем[28]. Важно отметить, что грамматика существенно упрощается при добавлении трансформационного уровня, поскольку теперь необходимо обеспечить построение по непосредственно составляющим только для ядерных предложений — терминальные цепочки [Σ,F]-грамматики в точности те же самые, что и лежащие в основе ядерных предложений. Ядерные предложения выбираются так, чтобы терминальные цепочки, лежащие в основе ядра, легко производились средствами [Σ,F]-описания, а все прочие предложения могли выводиться из этих терминальных цепочек посредством просто формулируемых трансформаций. Мы видели и еще увидим ниже некоторые примеры упрощений, к которым приводит трансформационный анализ. Полное синтаксическое исследование английского языка представит нам еще немало подобных примеров.
Заслуживает упоминания еще один момент, связанный с грамматиками вида (35). Мы описали эти грамматики как механизмы для порождения предложений. Эта довольно обычная формулировка может, пожалуй, навести на мысль, что грамматическая теория в какой-то мере асимметрична в том смысле, что грамматика становится на точку зрения скорее говорящего, чем слушающего, что она имеет дело с процессом производства высказываний, а не с «обратным» процессом анализа и реконструкции структуры заданных высказываний. В действительности грамматики рассмотренного нами вида вполне нейтральны по отношению к говорящему и слушающему, по отношению к синтезу и анализу высказываний. Грамматика не говорит нам, как синтезировать конкретное высказывание; она не говорит и того, как анализировать то или иное заданное высказывание. Фактически задачи, которые должны решать говорящий и слушающий, тождественны в своем существе и выходят за пределы компетенции грамматик вида (35). Каждая такая грамматика есть просто описание некоторого множества высказываний, именно тех, которые она порождает. С помощью этой грамматики можно реконструировать формальные отношения, справедливые для высказываний в терминах модели непосредственно составляющих, трансформационной структуры и т. п. Может быть, данный вопрос станет более ясным, если прибегнуть к аналогии с отделом химии, трактующим о структурно возможных соединениях. Об этой теории можно сказать, что она порождает все физически возможные соединения точно так же, как грамматика порождает все грамматически «возможные» высказывания. Она может служить теоретической базой для качественного анализа и синтеза конкретных соединений, точно так же, как грамматика может служить базой при решении таких проблем, как анализ и синтез конкретных высказываний.
6. О ЗАДАЧАХ ЛИНГВИСТИЧЕСКОЙ ТЕОРИИ
6.1.
В §§ 3,4 описаны две модели лингвистической структуры: простая теоретико-коммуникационная модель и формализованный вариант анализа по непосредственно составляющим. Обеони оказались неадекватными, и в § 5 я предложил более сильную модель, сочетающую уровень непосредственно составляющих и грамматические трансформации, которая предназначена восполнить недостатки предыдущих моделей. Прежде чем переходить к изучению этой возможности, я хотел бы разъяснить некоторые исходные моменты, лежащие в основе метода данного исследования.
Главное в настоящем обсуждении лингвистической структуры — это проблема обоснования грамматик. Грамматика языка L есть в сущности теория языка L. Любая научная теория, основываясь на конечном числе наблюдений, стремится установить соотношения между наблюденными явлениями и предсказать новые явления, сформулировав общие законы в терминах гипотетических конструктов, таких, как (в физике, например) «масса» и «электрон». Подобным же образом грамматика английского языка основывается на конечном множестве высказываний (наблюдений) и содержит некоторые грамматические правила (законы), сформулированные в терминах конкретных фонем, групп и т. п, английского языка (гипотетические конструкты). Эти правила выражают структурные соотношения между наблюденными предложениями и бесконечным числом предложений, порождаемых грамматикой независимо от этих наблюденных предложений (предсказания). Наша задача состоит в выработке и уяснении критериев выбора правильной грамматики для каждого языка, то есть правильной теории этого языка.
В § 2.1 были упомянуты два типа таких критериев. Ясно, что каждая грамматика обязана удовлетворять определенным внешним условиям адекватности; так, например, порождаемые ею предложения должны быть приемлемы для природного носителя языка. В § 8 мы рассмотрим некоторые другие внешние условия этого рода. Кроме того, мы предъявляем к грамматикам требование общности; мы требуем, чтобы грамматика данного языка была построена в соответствии с определенной теорией лингвистической структуры, в которой такие понятия, как «фонема» и «группа», определяются вне зависимости от всякого конкретного языка[29]. Если опустить либо внешние условия, либо требование общности, у нас не будет оснований для выбора среди большого числа совершенно различных «грамматик», каждая из которых совместима с данной совокупностью наблюденных высказываний. Но, как мы заметили в § 2.1, эти требования в своей совокупности представляют весьма сильный критерий адекватности для общей теории лингвистической структуры, а также для множества грамматик, которые созданы на ее основе для конкретных языков. Заметим, что ни общая теория, ни конкретные грамматики не фиксированы с этой точки зрения раз навсегда. Прогресс и пересмотр могут осуществляться в силу открытия новых фактов, касающихся конкретных языков, или чисто теоретического проникновения в организацию языковых данных, т. е. построения новых моделей лингвистической структуры. В этой концепции, однако, нет круга. В любой момент времени мы можем попытаться сформулировать со всей возможной точностью как общую теорию, так и множество связанных с ней грамматик, которые обязаны удовлетворять эмпирическим, внешним условиям адекватности.
Мы не рассмотрели еще следующего весьма решающего вопроса: каково отношение между общей теорией и конкретными грамматиками, вытекающими из нее? Другими словами, какой смысл мы вкладываем в данном контексте в понятие «вытекать из»? Именно в этом пункте наш подход резко расходится со многими теориями лингвистической структуры.
Наиболее сильное требование, которое можно было бы предъявить к соотношению между теорией лингвистической структуры и конкретными грамматиками, состоит в том, чтобы теория, исходя из определенной совокупности высказываний, давала практичный и автоматический метод конструирования грамматики. Будем говорить, что такая теория предоставляет нам процедуру для открытия грамматик.
Более слабое требование заключается в том, чтобы теория давала практичный и автоматический метод для определения того, является ли грамматика, предлагаемая для данной совокупности высказываний, действительно наилучшей грамматикой для того языка, из которого взята данная совокупность. О такой теории, не затрагивающей вопроса о том, как строится грамматика, надо говорить как о теории, предоставляющей процедуру суждения о грамматике.
Еще более слабое требование сводится к тому, чтобы, имея совокупность высказываний и две предлагаемые грамматики G1 и G2, мы могли с их помощью решить, какая из грамматик лучше для языка, из которого выделена данная совокупность высказываний. В этом случае следует говорить, что теория дает нам процедуру выбора грамматик.
Все эти теории можно представить графически следующим образом:
(36).
На рис. (36 I) представлена теория, понимаемая как машина, получающая совокупность высказываний на входе и выдающая на выходе грамматику, т. е. теория, дающая процедуру открытия. На рис. (36 II) показан механизм с грамматикой и совокупностью высказываний в качестве входов и ответами «да» и «нет» в качестве выходов, означающими правильность или неправильность грамматики; следовательно, это теория, дающая процедуру суждения о грамматике. Рис. (36 III) представляет теорию с грамматиками G1 и G2, а также всей совокупностью высказываний на входе и решением о предпочтительности G1 или G2 на выходе, т. е. теорию, дающую процедуру выбора грамматик[30].
Из принятой здесь точки зрения вытекает, что неразумно требовать от лингвистической теории чего-либо большего, чем практичной процедуры выбора грамматик. Иначе говоря, мы принимаем последнюю из трех позиций, о которых говорилось выше. Насколько я понимаю, большинство наиболее тщательных программ в области разработки лингвистической теории[31] стремятся к удовлетворению самого сильного из этих трех требований. Это значит, что предпринимаются попытки сформулировать методы анализа, которые исследователь реально может использовать, если у него есть время, чтобы построить грамматику языка, исходя непосредственно из сырых данных. По-моему, весьма сомнительно, чтобы этой цели можно было достигнуть сколько-нибудь интересным путем, и я подозреваю, что всякая попытка достичь ее должна завести в лабиринт все более и более подробных и сложных аналитических процедур, которые, однако, не дают ответа на многие важные вопросы, касающиеся природы лингвистической структуры. Я полагаю, что, снизив наши запросы и поставив более скромную цель — разработать процедуры выбора грамматик,— мы сможем сосредоточить наше внимание на узловых проблемах лингвистической структуры и прийти к более удовлетворительному их решению. Справедливость этого мнения может быть проверена лишь путем фактической разработки и сравнения указанных теорий. Заметим, однако, что слабейшее из этих трех требований является все же достаточно сильным для того, чтобы обеспечить высокую содержательность теории, которая ему удовлетворяет. Нам известно немного таких областей науки, в которых можно было бы серьезно рассматривать возможность разработки общего, практичного, автоматического метода выбора между несколькими теориями, каждая из которых совместима с имеющимися данными.
Рассматривая каждую из указанных концепций лингвистической теории, мы охарактеризовали соответствующие типы процедуры словом «практичная». Эта неопределенная характеристика очень важна для эмпирической науки. Допустим, к примеру, что мы оцениваем грамматики в соответствии с таким простым их свойством, как длина. Тогда было бы правильным сказать, что мы имеем практичную процедуру выбора грамматик, поскольку мы можем сосчитать количество символов, которые каждая из них содержит; абсолютно верным было бы также утверждение, что мы имеем процедуру открытия, поскольку можно расположить все последовательности, состоящие из конечного числа символов, из которых построены грамматики, в порядке возрастания их длины. При этом мы могли бы проверить, является ли каждая из этих последовательностей грамматикой или нет, так, чтобы можно было быть уверенным, что по прошествии некоторого конечного отрезка времени найдется кратчайшая последовательность, которая удовлетворит необходимым требованиям. Однако данная процедура открытия не того типа, который желателен тем, кто пытается удовлетворить наиболее сильное из требований, рассмотренных выше.
Предположим, что мы пользуемся словом «простота» по отношению к совокупности формальных свойств грамматик, рассматриваемых с целью выбора между ними. Тогда перед лингвистической теорией предлагаемого нами типа встают три главные задачи. Во-первых, необходимо сформулировать точно (если возможно — с операционными, поведенческими испытаниями) внешние критерии адекватности грамматик. Во-вторых, мы должны охарактеризовать строение грамматик в общей и явной форме так, чтобы можно было реально предложить грамматики этого типа для конкретных языков. В-третьих, необходимо анализировать и определить понятие простоты, которым мы собираемся пользоваться при выборе между грамматиками, каждая из которых имеет требуемую форму. По выполнении последних двух задач мы в состоянии сформулировать общую теорию лингвистической структуры, в которой такие понятия, как «фонема в L», «группа в L», «трансформация в L», определяются для произвольного языка L в терминах физических и дистрибутивных свойств высказываний L и формальных свойств грамматик L[32]. Например, мы определим множество фонем L как множество элементов, имеющих известные физические и дистрибутивные свойства и выступающих в простейшей из грамматик, предложенных для L. Имея такую теорию, можно попытаться построить грамматики для реальных языков и решить затем, удовлетворяют ли простейшие из грамматик, предлагаемые нами (т. е. грамматики, которые мы обязаны выбрать согласно общей теории), внешним условиям адекватности. Мы должны продолжать пересматривать наши понятия простоты и характеристики форм грамматик до тех пор, пока грамматики, отобранные в соответствии с теорией, не будут удовлетворять внешним условиям[33]. Заметим, что эта теория не может подсказать нам, как реально приступить к построению грамматики данного языка, исходя из всей совокупности высказываний. Однако благодаря ей мы можем решить, как оценить такую грамматику; эта теория должна, таким образом, дать нам возможность выбрать между двумя предложенными грамматиками.
В предыдущих разделах настоящего исследования мы имели дело со второй из упомянутых трех задач. Мы предполагали, что множество грамматически правильных предложений английского языка задано и что существует некоторое понятие простоты, и старались решить, какого рода грамматика будет точно порождать грамматически правильные предложения некоторым простым способом. Формулируя это несколько иными словами, мы отметили выше, что одно из понятий, которое необходимо определить в общей лингвистической теории, есть «предложение в L». Исходными для определения должны быть такие понятия, как «наблюденное высказывание в L», «простота грамматики L» и т. п. В соответствии со сказанным общая теория имеет дело с разъяснением отношения между множеством грамматически правильных предложений и множеством наблюденных предложений. Наше изучение структуры первого множества — это подготовительное исследование, исходящее из допущения, что, прежде чем мы сможем ясно охарактеризовать указанное отношение, мы должны знать гораздо больше о формальных свойствах этих множеств.
Ниже, в § 7, мы продолжим рассмотрение сравнительной сложности различных способов описания структуры английского языка. В частности, мы коснемся вопроса о том, упростится ли грамматика в целом в том случае, если мы отнесем некоторый класс предложений к числу ядерных или если будем считать их полученными посредством трансформаций. Этим путем мы придем к определенным заключениям относительно структуры английского языка, В § 8 мы покажем, что существует независимое свидетельство в пользу нашего метода выбора, т. е. что более простые грамматики удовлетворяют определенным внешним условиям адекватности, тогда как более сложные грамматики, где иначе решен вопрос об отнесении предложений к ядру, таким условиям не удовлетворяют. Полученные результаты, однако, остаются всего лишь правдоподобными до тех пор, пока мы не дадим строгого определения используемого нами понятия простоты. Я думаю, что такое определение можно дать, но это не входит в задачу настоящей монографии. Тем не менее ясно, что при любом разумном определении «простоты грамматики» большинство суждений об относительной сложности, к которым мы придем ниже, останется в силе[34]
Заметим, что простота есть системный критерий; единственное окончательное мерило для оценки — это простота системы в целом. При рассмотрении частных случаев мы можем фиксировать лишь, насколько то или иное решение влияет на общую сложность. Такой критерий может быть только приблизительным, поскольку в результате упрощения одной части грамматики могут усложниться другие ее части. Другими словами, если выяснится, что упрощение одной части грамматики ведет к соответствующему упрощению других частей, мы вправе надеяться, что находимся на правильном пути. Ниже мы попытаемся показать, что как раз простейший трансформационный анализ одного класса предложений весьма часто прокладывает путь к более простому анализу других классов.
Короче говоря, никоим образом не следует останавливаться на способе получения грамматики, степень простоты которой определена, например, на том, как можно получить разложение глагольной группы, приведенное в § 5.3. Вопросы подобного рода не имеют отношения к программе исследования, изложенной выше. Можно прийти к грамматике с помощью интуиции, проб, всякого рода вспомогательных методологических средств, на основании предыдущего опыта и т. п. Без сомнения, можно дать систематическое описание многих полезных процедур анализа, но навряд ли удастся сформулировать их достаточно строго, исчерпывающе и просто, чтобы именовать все это практичной и автоматической процедурой открытия. Так или иначе данная проблема выходит за рамки настоящего исследования. Наша конечная цель — дать объективный и формальный метод выбора грамматики и сравнения ее с другими предложенными грамматиками. Нас интересует, таким образом, описание форм грамматик (или, что то же самое, природы лингвистической структуры) и изучение эмпирических последствий принятия определенной модели лингвистической структуры, а не указания, как в принципе можно прийти к грамматике того или иного языка.
6.2.
Как скоро мы отказываемся от всякого намерения найти практичную процедуру открытия грамматик, многие проблемы, которые были предметом горячей методологической дискуссии, попросту снимаются. Рассмотрим проблему независимости уровней. Справедливо указывалось, что если морфемы определяются через фонемы и одновременно фонемный анализ связан с морфологическими соображениями, то лингвистическая теория сходит на нет в силу логического круга. Однако эта взаимозависимость уровней не обязательно должна привести к кругу. В данном случае можно задать «предположительное множество фонем» и «предположительное множество морфем» и определить отношение совместимости, существующее между предположительными множествами фонем и пред- лоложительными множествами морфем. Тогда мы сможем определить пару, состоящую из множества фонем и множества морфем, для данного языка как совместимую пару, состоящую из предположительного множества фонем и предположительного множества морфем. Наше отношение совместимости будет частично базироваться на соображениях простоты, т. е. мы сможем определять фонемы и морфемы языка как предположительные фонемы и морфемы, которые, между прочим, в совокупности приведут к самой простой грамматике. Таким образом, мы получаем совершенно прямой путь определения взаимозависимых уровней, не впадая в ошибку круга. Разумеется, все это еще не дает ответа на вопрос, как найти фонемы и морфемы прямым, автоматическим путем. Но и никакая другая фонемная или морфологическая теория в действительности не ответит на этот прямой вопрос, и мало оснований полагать, что на него вообще можно ответить сколько-нибудь содержательным образом. Во всяком случае, если мы поставим себе более скромную цель к потребуем только разработки процедуры выбора грамматик, то останется мало оснований возражать против смешения уровней и нетрудно будет избежать круга при определении взаимозависимых уровней[35].
Многие проблемы морфемного анализа также получают совершенно простое решение, если мы примем общее направление, охарактеризованное выше. Пытаясь разработать процедуры открытия грамматик, мы естественным образом приходим к необходимости рассматривать морфемы как классы последовательностей фонем, т. е. как единицы, имеющие конкретный фонемный «состав» в некотором совершенно буквальном смысле. Это ведет к помехам в таких общеизвестных случаях, как английское took /tuk/, где трудно, не прибегая к искусственности, связать какую бы то ни было часть слова с морфемой прошедшего времени, присутствующей в виде jtl в walked /wokt/, а также в виде /d/ в framed /freymd/ и т. д. Можно избежать всех этих проблем, рассматривая морфологию и фонологию как два различных, но взаимозависимых уровня представления, связанных в грамматике посредством морфофонемных правил типа (19). Так, took представляется на морфологическом уровне в виде take+past, подобно тому как walked можно воспринимать в виде walk+past. Морфофонемные правила (19 II) и (19 V), соответственно, превращают эти цепочки морфем в /tuk/ и /wokt/. Единственная разница между этими двумя случаями состоит в том, что (19 V) является гораздо более общим правилом, чем (19 II)[36]. Если мы откажемся от мысли, что более высокие уровни в буквальном смысле слова построены из элементов более низких уровней (а я думаю, что мы должны это сделать), то станет куда более естественным рассматривать даже такие абстрактные системы представления, как трансформационная структура (где каждое высказывание представляется последовательностью трансформаций, посредством которых оно получается из терминальной цепочки грамматики непосредственно составляющих), в качестве лингвистического уровня.
В действительности, становясь на ту точку зрения, что уровни взаимозависимы, или принимая концепцию лингвистических уровней как абстрактных систем представления, связанных между собой только общими правилами мы вовсе не оказываемся вынужденными оставить всякую надежду найти практичные процедуры открытия грамматик. И все же, по-моему, не подлежит сомнению, что сопротивление смешению уровней, равно как и мысль, что каждый уровень в буквальном смысле слова строится из элементов более низкого уровня, имеют источником стремление разработать процедуры открытия грамматик. Если мы откажемся от этой цели и будем проводить ясное различие между справочником полезных эвристических процедур и теорией лингвистической структуры, то останется мало оснований отстаивать любую из этих довольно шатких позиций.
Многие общепринятые точки зрения окажутся несостоятельными, если мы сформулируем наши цели предложенным выше образом. Так, утверждают иногда, что работа в области синтаксической теории в настоящее время преждевременна, поскольку многие проблемы, возникающие на более низком уровне фонетики и морфологии, не решены. Совершенно справедливо, что высшие уровни лингвистического описания зависят от результатов, полученных на низших уровнях. Однако в определенном, вполне разумном смысле, верно также и обратное. Выше мы видели, например, что было бы абсурдным или даже безнадежным устанавливать принципы построения предложений в терминах фонем или морфем, однако только разработка таких высших уровней, как уровень непосредственно составляющих, показывает нам, что нет смысла предпринимать эту тщетную попытку на низших уровнях[37]. Подобным же образом мы утверждали, что описание структуры предложения через анализ по непосредственно составляющим теряет силу вне определенных границ. Однако только разработка еще более абстрактного уровня трансформаций может подготовить почву для разработки более простой и адекватной методики анализа по непосредственно составляющим в более узких границах.
Грамматика языка —это сложная система с многочисленными и разнообразными связями между ее частями. Для исчерпывающей разработки одной части зачастую полезно или даже необходимо иметь некоторую картину системы в целом. Итак, я думаю, что мнение, будто синтаксическая теория должна ожидать решения проблем фонологии и морфологии, совершенно несостоятельно и не зависит от того, занимаемся ли мы проблемой процедур открытия или нет. Однако я уверен, что это мнение питается ложной аналогией между порядком разработки лингвистической теории и предполагаемой очередностью операций при открытии грамматической структуры.
7. НЕКОТОРЫЕ ТРАНСФОРМАЦИИ В АНГЛИЙСКОМ ЯЗЫКЕ
7.1.
После некоторого отступления мы можем вернуться к изучению последствий принятия трансформационного подхода к описанию английского синтаксиса. Наша задача — так ограничить объем ядра, чтобы терминальные цепочки, лежащие в основе предложений, выводились с помощью простой модели непосредственно составляющих и могли явиться базой для образования всех предложений посредством простых трансформаций: обязательных трансформаций в случае ядерных предложений, обязательных и факультативных трансформаций в случае неядерных предложений.
Чтобы определить трансформацию точно, необходимо описать разложение цепочек, к которым она применяется, и те структурные изменения, которые вызывает трансформация в этих цепочках[38]. Так, пассивная трансформация применяется к цепочкам вида NP—Aux—V—NP и вызывает обмен местами двух именных групп, добавление by перед последней именной группой и прибавление be+en к Aux (ср. (34)). Рассмотрим теперь введение not или n't в группу с вспомогательным глаголом. Проще всего описать отрицание посредством трансформации, которая применяется раньше, чем (29 II), и вводит not или n't после второй морфемы группы, получаемой с помощью (28 III), если эта группа содержит по крайней мере две морфемы, или после первой морфемы, если группа содержит только одну. Следовательно, трансформация Тnot воздействует на цепочки, разлагающиеся на три сегмента, одним из следующих способов:
(37) (I) NP—С—V...
(II) NP—C+M—...
(III) NP—C+have—...
(IV) NP—C+be—…
где значения символов те же, что и в (28), (29), и безразлично, что стоит на месте точек. При наличии цепочки, разлагаемой на три сегмента одним из этих способов, трансформация Tnot добавляет not (или n’t) ко второму сегменту цепочки. Так, например, будучи применена к терминальной цепочке they—0+can—come (пример из (37 II)), трансформация Тnot дает they—0+сап+п’t—come (и, в конечном счете—They can’t come «Они не могут прийти»); примененная к they—0+have—en+come (пример из (37 III)), она дает they—0+have+n't—en+come (в конечном счете — They haven’t come «Они не пришли»); примененная к they—0+be—ing+come (пример(37 IV)), она дает they—0+be+n’t—ing+come (в конечном счете — They aren’t coming «Они не приходят»). Это правило, следовательно, справедливо, если взять три последних случая из (37).
Рассмотрим теперь пример (37 I) т. е. терминальную цепочку типа (38)
(38) John—S—come,
дающую в результате применения правила (29 II) ядерное предложение John comes «Джон приходит». Применение трансформации Тnot к (38) дает
(39) John—S+n’t—come.
Но мы установили, что Tnot применяется раньше правила (29 II), которое превращает Af+v в v+Af#. Далее мы обнаруживаем, что (29 II) вообще не применимо к (39), поскольку (39) уже не содержит последовательности Af+v. Дополним теперь грамматику следующим обязательным трансформационным правилом, применяющимся после (29):
(40) #Af—>#do+Af,
где do — тот же самый элемент, что и знаменательный глагол в John does his homework «Джон выполняет свое домашнее задание». (Ср. (29 III) относительно введения символа #). Правило (40) означает лишь, что do вводится в качестве носителя «холостого» аффикса. Применив к (39) правило (40), а также морфологические правила, мы получаем John doesn’t come «Джон не приходит». Правила (37) и (40) позволяют, таким образом, получить все и только грамматические формы отрицания в предложении.
Как таковая трансформационная трактовка отрицания несколько проще, чем всякая трактовка, основанная на модели непосредственно составляющих. Преимущества трансформационной трактовки (перед включением отрицательных предложений в ядро) стали бы гораздо очевидней, если бы нам удалось найти другие случаи, когда те же самые формулировки (т. е. (37) и (40)) оказались бы необходимыми, но уже по совершенно иным мотивам. И такие случаи в действительности имеются.
Рассмотрим класс предложений, выражающих «общий: вопрос (т. е. требующий ответа: «да» или «нет»), например» Have they arrived? «Прибыли ли они уже?», Can they arrive? «Могут ли они прибыть?», Did they arrive? «Прибыли ли они?» Можно породить все (и только) такие предложения с помощью трансформации Tq которая воздействует на цепочки с разложением (37) и меняет местами первый и второй сегменты этих цепочек, как они определены в (37). Потребуем, чтобы Tq применялось после (29 I) и раньше 29 II). Будучи применена к цепочкам
(41) (I) they—0—arrive
(II) they—0+can—arrive
(III) they—0+have—en+arrive
(IV) they—0+be—ing+arrive,
имеющим вид (37 I—IV). Tq вырабатывает цепочки
(42) (I) 0—they—arrive
(II) 0+can—they—arri ve
(III) 0-+have — they—en+arrive
(IV) 0+be — they —ing+arrive.
Применяя к последним обязательные правила (29 II, III) и (40), а затем морфофонемные правила, получаем
(43) (I) Do they arrive?
«Прибывают ли они?»
(II) Can they arrive?
«Могут ли они прибыть?»
(III) Have they arrived?
«Прибыли ли они уже?»
(IV) Are they arriving?
«Прибывают ли они [в настоящий момент]?».
в фонологической транскрипции. Применив обязательные правила непосредственно к (41), минуя Tq, мы могли бы получить предложения
(44) (I) They arrive
«Они прибывают»
(II) They can arrive «Они могут прибыть»
(III) They have arrived «Они уже прибыли»
(IV) They are arriving
«Они прибывают [в настоящий моменг]».
Таким образом, (43 I—IV) — вопросительные аналоги (44 I—IV).
В случае (42 I) do вводится правилом (40) в качестве носителя холостого аффикса 0. Если бы С было развернуто посредством правила (29 I) в S или в past, правило (40) ввело бы его как носителя этих элементов и мы получили бы предложения типа Does he arrive? «Прибывает ли он?», Did he arrive? «Прибыл ли он?» Заметим, что не требуется никаких новых морфофонемных правил для объяснения того, что do+0—>/duw/, do+S—>/daz/, do+past—>/did/; мы пользуемся этими правилами повсюду для объяснения форм знаменательного глагола do. Заметим также, что Tq должно применяться после (29 I), иначе не будет получено надлежащее грамматическое число.
Анализируя группу со вспомогательным глаголом по правилам (28), (29), мы считали S морфемой третьего лица единственного числа, а 0 морфемой, присоединяемой к глаголу для всех прочих форм подлежащего. Следовательно, глагол имеет S, если именное подлежащее имеет 0 (The boy arrives «Мальчик прибывает»), и глагол имеет 0, если подлежащее имеет S (The boys arrive «Мальчики прибывают»). Другая возможность, которой мы не рассматривали, состоит в том, чтобы отказаться от нулевой морфемы и просто указать, что никакого аффикса нет, если подлежащее не имеет формы третьего лица единственного числа. Мы видим теперь, что этот вариант неприемлем. Необходимо присутствие морфемы 0, иначе не будет аффикса в (42 I), носителем которого являлось бы do, и, следовательно, правило (40) окажется неприменимым к (42 I). Встречается немало других случаев, когда трансформационный анализ дает нам решающие доводы за или против введения нулевых морфем. В качестве отрицательного примера рассмотрим утверждение, что непереходные глаголы должны разлагаться на глагол и нулевой объект. В этом случае пассивная трансформация (34) обратила бы, например, John—slept—0 в непредложение 0—was slept—by John—>was slept by John[39]. Следовательно, от такого разложения непереходных глаголов нужно отказаться. В §7.6 мы обратимся к более общей проблеме, касающейся роли трансформаций в определении структуры составляющих.
Знаменательно, что для описания вопросительной трансформации Tq почти ничего не нужно добавлять к грамматике. Поскольку как анализ предложения, которого эта трансформация требует, так и правила появления do оказались независимо от этой трансформации необходимыми для целей отрицания, нам нужно описать лишь перестановку, вызываемую действием Тq для того чтобы распространить грамматику на случай «общих» вопросов. Говоря иначе, трансформационный анализ обнаруживает структурную близость отрицательных и вопросительных предложений и использует ее для упрощения описания английского синтаксиса.
При рассмотрении группы со вспомогательным глаголом мы оставили в стороне формы с акцентированным элементом do в таких, например, случаях, как John does come «Джон [именно] приходит» и т. п. Предположим, мы ввели морфему А контрастного подчеркивания, к которой применимо следующее морфофонемное правило:
(45) ...V...+A—>...V"... где " означает резкое подчеркивание.
Введем теперь трансформацию ТA, предполагающую такое же разложение цепочек, как и Тпоt (т. е. разложение (37)), и добавляющую к этим цепочкам А в том же месте, где Tnot добавляет not или n’t. Подобно тому как Тnot производит предложения типа
(46) (I) John doesn’t arrive (из John#S+n’t#arrive, применением (40))
«Джон не прибывает»
(II) John can’t arrive (из John#S+can+n’t#arrive)
«Джон не может прибыть»
(III) John hasn’t arrived (из John#S+have+n’t#en+arrive)
«Джон не прибыл»
Та производит аналогичные предложения:
(47) (I) John does arive (из John#S+A#arrive,,применением (40))
«Джон [именно] прибывает»
(II) John can arrive (из John#S+can+A#arrive)
«Джон может прибыть»
(III) John has arrived (из John#S+have+A#en+arrive)
«Джон [уже] прибыл».
Таким образом, ТA является трансформацией утверждения, которая создает утвердительные предложения John arrives «Джон прибывает», John can arrive «Джон может прибыть», John has arrived «Джон [уже] прибыл» и т. п., точно так же как Tnot создает отрицательные предложения. Это наиболее простое в формальном отношении решение представляется интуитивно наиболее правильным.
Имеются и другие примеры трансформаций, определяемые тем же самым фундаментальным синтаксическим разложением предложений, а именно (37). Рассмотрим трансформацию Тso обращающую пары цепочек (48) в соответствующие цепочки (49):
(48) (I) John—S—arrive; I—0—arrive
(II) John—S+can—arrive; I—0+can—arrive
(III) John—S+have—en+arrive; I—0+have—en+arrive
(49) (I) John—S—arrive—and—so—0—I
(II) John—S+can—arrive—and —so—0+can—I
(III) John—S+have—en+arrive—and—so—0+have—I.
Применяя правила (29 II, III), (40) и морфофонемные правила, в конечном счете получаем:
(50) (I) John arrives and so do I
«Джон прибывает и я тоже»
(II) John can arrive and so can I
«Джон может прибыть и я тоже»
(III) John has arrived and so have I
«Джон [уже] прибыл и я тоже».
Тso воздействует на второе предложение каждой пары в (48), заменяя третий сегмент этого предложения элементом so, а затем меняя местами первый и второй сегменты. (Элемент so является, следовательно, заместителем глагольной группы, аналогично тому как he является заместителем имени — местоимением.) Для получения (49) Tso сочетается с сочинительной трансформацией. Хотя мы не описываем последней подробно, мы понимаем, что разложение предложений (37), а также использование правила
(40) являются принципиально необходимыми и в данном случае. Таким образом, почти ничего нового не требуется добавлять к грамматике для описания таких предложений, как (50), которые формируются по тем же трансформационным образцам, что и отрицательные, общевопросительные и подчеркнуто утвердительные предложения.
Существует еще одно примечательное свидетельство фундаментального характера указанного разложения, заслуживающее упоминания здесь. Рассмотрим ядерные предложения:
(51) (I) John has a chance to live
«Джон имеет шанс выжить».
(II) John is my friend
«Джон—мой друг».
Терминальные цепочки, лежащие в основе (51), суть:
(52) (I) John+C+have+a+chance+to+live
(II) John+C+be+my+friend,
причем have в (52 I) и be в (52 II) — знаменательные, а не вспомогательные глаголы. Посмотрим теперь, как применяются к этим цепочкам трансформации Tnot, Tq и Тso. Tnot применяется к любой цепочке вида (37) при добавлении not или n’t между вторым и третьим сегментами цепочки. Но (52 I) фактически представляет собой и пример (37 I), и пример (37 III). Значит, Tnot приложенная к (52 I), даст (53 I) или (53 II):
(53) (I) John—С+n’t—have+a+chance+to+live
(—>John doesn’t have a chance to live)
(—>«Джон совершенно не имеет шанса выжить»)
(II) John—С+have+n’t—a+chance+to+live
(—>John hasn’t a chance to live)
(—>«Джон не имеет шанса выжить»).
Фактически обе формы примера (53) являются грамматически правильными. Более того, have — единственный переходный глагол, для которого такое неоднозначное отрицание возможно, и в то же время это единственный переходный глагол, допускающий неоднозначное разложение в смысле (37). Это значит, мы получаем John doesn’t read books «Джон совершенно не читает книг», но не John readsn’t books.
Подобным образом ТA примененная к (52 I), производит обе формы (54), а Тso— обе формы (55), поскольку эти трансформации также основаны на структурном разложении (37).
(54) (I) Does John have a chance to live?
«Имеет ли Джон [хоть какой-нибудь] шанс выжить?»
(II) Has John a chance to live?
«Имеет ли Джон шанс выжить?»
(55) (I) Bill has a chance to live and so does John.
«Билл имеет шанс выжить, Джон [точно] так же».
(II) Bill has a chance to live and so has John.
«Билл имеет шанс выжить, Джон также».
Но при всех других переходных глаголах такие формы, как (54 II), (55 II), невозможны. Мы не встречаем Reads John books? или Bill reads books and so reads John. Мы замечаем, однако, что такое, по-видимому, нерегулярное поведение глагола have оказывается в действительности автоматическим следствием наших правил. Тем самым решена поставленная в §2.3 проблема грамматической правильности (3) и грамматической неправильности (5).
Рассмотрим теперь (52 II). Хотя мы и не показали этого, но фактически верно, что в простейшей грамматике непосредственно составляющих английского языка отсутствуют какие бы то ни было основания для отнесения be к классу глаголов, т. е. из этой грамматики не следует, что be есть V. Точно так же, как одним из видов глагольной группы является V+NP, одним из видов ее является и be+Predicate. Следовательно, если даже be не будет вспомогательным глаголом в (52 II), тем не менее остается справедливым, что из разложений, допускаемых (37), только (37 IV) имеет силу в (52 II). Поэтому трансформации Тnot, Tq и Тso будучи приложены к (52 II), произведут соответственно (наряду с (29 I)),
(56) (I) John—S+be+n't—my+friend
(—>John isn’t my friend)
(—>«Джон не является моим другом»)
(II) S+be—John—my+friend
(—>Is John my friend?)
(—>«Является ли Джон моим другом?»)
(Ill) Bill—S+be—my+friend—and—so—S+-f- be—John
(—>Bill is my friend and so is John)
(—>«Билл мой друг, Джон также»).
И снова аналогичные формы (например, John readsn’t books и т. п.) оказываются невозможными при знаменательных глаголах. Подобным образом, ТA образует John is here «Джон [как раз] здесь» вместо John does be here, как было бы в случае знаменательных глаголов.
Если бы мы попытались описать весь английский синтаксис целиком в терминах модели непосредственно составляющих, то формы be и have выглядели бы как явные и недвусмысленные исключения. Но мы видели сейчас, что как раз эти, по-видимому неправильные, формы приходят автоматически из простейшей грамматики, построенной с расчетом на объяснение регулярных случаев. Таким образом, поведение be и have оказывается в действительности примером более глубокой и фундаментальной регулярности, если рассматривать структуру английского языка с точки зрения трансформационного анализа.
Заметим, что have в качестве вспомогательного глагола в таких терминальных цепочках, как John+С+have+en+arrive (эта цепочка лежит в основе ядерного предложения John has arrived «Джон [уже] прибыл»), не подвергается неоднозначному разложению. Эта терминальная цепочка — пример (37 III), но не (37 I), т. е. ее можно разложить в соответствии с (57 I), но не с (57 II).
(57) (I) John—С+have—en+ arrive (NP—C+have—…, т. e. (37 III))
(II) John—С—have+en+arrive (NP—С—V..., т. e. (37 I))
Эта цепочка не может быть примером (37 I), поскольку в данном случае have не является V, даже если в некоторых других случаях (например, (52 I)) have есть V. Структура непосредственно составляющих терминальной цепочки определяется по ее деривации, для чего нужно найти общую всем сегментам узловую точку, которая находится способом, описанным в §4.1. Но have в (57) невозможно возвести ни к какой узловой точке, обозначенной V в деривации этой цепочки. (52 I) тем не менее допускает неоднозначное разложение, поскольку в схеме, соответствующей деривации (52 I), have можно возвести к V, а, с другой стороны, его можно возвести, разумеется, и к have (т. е. к самому себе). То обстоятельство, что разложение (57 II) недопустимо, препятствует деривации таких непред- ложений, как John doesn’t have arrived; Does John have arrived и т. n.
Мы видели в настоящем разделе, что целый ряд, очевидно, различных явлений весьма просто находит свое место в системе, если исходить из трансформационного анализа, и что благодаря этому грамматика английского языка становится более простой и регулярной. Это основное требование, которому должна удовлетворять любая концепция лингвистической структуры (т. е. любая предлагаемая форма грамматик). Я думаю, что приведенные соображения вполне подтверждают высказанное выше мнение о том, что системы грамматик непосредственно составляющих принципиально неадекватны и что теория лингвистической структуры должна разрабатываться в направлении, указанном в ходе дискуссии о трансформационном анализе.
7.2.
Приведенный выше анализ общевопросительных предложений легко распространить на случай таких вопросительных предложений, как
(58) (I) What did John eat?
«Что ел Джон?»
(II) Who ate an apple?
«Кто ел яблоко?»,
которые не требуют ответа «да» или «нет». Проще всего включить этот класс в грамматику, введя новую факультативную трансформацию Tw, которая воздействует на любую цепочку вида
(59) X—NP—Y,
где X и Y — любые цепочки, в том числе, в частности, «нулевая» цепочка (т. е. первая или третья позиция может быть пустой). Тогда работа Tw составляется из двух шагов:
(60) (I) TW1 обращает цепочку вида X—NP—Y в соответствующую цепочку вида NP—X—Y, т. е. меняет местами первый и второй сегменты (59). Таким образом, она оказывает то же трансформационное воздействие, что и Tq (ср. (41) (42)).
(II) Tw2 обращает полученную цепочку NP—X—Y в who—X—Y, если NP одушевленное, и в what— X—Y, если NP неодушевленное[40].
Потребуем теперь, чтобы Tw могла применяться лишь к цепочкам, к которым уже применена Tq. Мы установили, что Tq должна применяться после (29 I) и перед (29II). Tw применяется после Tq и раньше (29 II) и является условной относительно Tq в том смысле, что она может применяться только к формам, полученным в результате применения Tq. Эта условная зависимость является обобщением различия между обязательными и факультативными трансформациями, которое легко «встроить» в грамматику и которое оказывается существенным. Терминальная цепочка, лежащая в основе как (58 I) , так и (58 II) ( а также (62), (64) ), имеет вид
(61 )John—С—eat+an+apple (NP—С—V...),
где тире указывает разложение, предполагаемое трансформацией Tq. Таким образом, (61) оказывается частным случаем (37 I). Задавшись условием применять к (61) только обязательные трансформации и выбирая элемент past при развертывании С, согласно (29 I), мы можем получить
(62) #John#eat+past#an#apple#
(—> John ate an apple «Джон ел яблоко»).
Если применить к (61) сначала (29 I), а затем Tq, то получится
(63) past—John—eat+an+apple,
где С развернуто в past. Если бы нам пришлось теперь применить к (63) трансформацию (40), вводящую do в качестве носителя past, мы получили бы простое вопросительное предложение
(64) Did John eat an apple? «Ел ли Джон яблоко?»
Если же применить к (63) трансформацию Tw, получится сначала (65) (применением Tw1), а затем (66) (применением Tw2).
(65) John—past—eat+an+apple
(66) Who—past—eat+an+apple.
После этого правило (29 II) и морфофонемные правила обращают (66) в (58 II). Таким образом, для получения (58 II) к терминальной цепочке (61), лежащей в основе ядерного предложения (62), мы применяем сначала Tq, а затем Tw. Заметим, что в данном случае TW1 просто уничтожает действие Tq чем и объясняется отсутствие инверсии в (58 II).
Применяя Tw к цепочке, мы сначала выбираем именную группу, а затем меняем местами эту группу с сегментом, который ей предшествует. Для получения (58 II) мы применяем Tw к (63), выбрав теперь группу John. Применим теперь Tw к (63), выбрав именную группу an+ apple. Следовательно, для целей этой трансформации мы представим (63) в виде
(67) past+John+eat—аn+apple,
т. е. как цепочку вида (59), где Y равняется нулю. Применяя Tw к (67), получим сначала (Tw1)
(68) an+apple—past+John+eat,
а затем (Tw2)
(69) what—past+John+eat.
(29 II) неприменимо к (69), а также к (39) и к (42 I) поскольку (69) не содержит подцепочки Af+v. Следова, тельно, к (69) применяется (40), вводящее do в качестве- носителя морфемы past. Применяя остальные правила, получаем в конечном счете (58 I).
Трансформация Tw определяемая правилами (59)—(60) , объясняет также все такие частновопросительные предложения, как What will he eat? «Что он будет есть?», What has he been eating? «Что он ел [в то время]?» Ее легко обобщить и на вопросительные предложения типа «What book did he read?» «Какую книгу он читал?»
Заметим, что трансформация TW1 определяемая правилом (60 I), осуществляет те же преобразования, что и Tq, т. е. меняет местами первые два сегмента цепочки, к которой она применяется. Теперь перейдем к рассмотрению воздействия трансформации на интонацию. Пусть существуют две основные интонации предложения: нисходящая, которую мы связываем с ядерным предложением, и восходящая, связанная с общевопросительными предложениями. Тогда действие Tq будет заключаться, в частности, в замене одного вида интонации другим, следовательно, в случае (64) — в замене нисходящей интонации на восходящую. Но мы видели, что Tw1 применяется только после Tq и что ее действие таково же, как и действие Tq. Значит, TW1 превращает восходящую интонацию обратно в нисходящую. Представляется разумным рассматривать это как объяснение того факта, что вопросительные предложения типа (58 I—II) имеют обычно нисходящую интонацию, подобно повествовательным предложениям. Такое распространение трансформационной концепции на явления интонации предложений поднимает много проблем, и хотя данное замечание слишком кратко, однако оно показывает, что такое распространение может быть плодотворным.
Итак, мы видим, что четыре предложения
(70) (I) John ate an apple (=(62))
«Джон ел яблоко».
(II) Did John eat an apple? (=(64))
«Ел ли Джон яблоко?»
(III) What did John eat? (=(581))
«Что ел Джон?»
(IV) Who ate an apple? (=(5811))
«Кто ел яблоко?»
подучаются из терминальной цепочки (61). (70 1) — ядерное предложение, поскольку в его «трансформационную историю» входят только обязательные трансформации. (70 II) получается из (61) применением Tq. (70 III) и (70 IV) еще далее отстоят от ядра, так как они получаются из (61) применением сначала Tq, а затем Tw.
7.3.
В §5.3 мы отмечали, что существуют именные группы типа to+VP, ing+NP (to prove that theorem «доказать эту теорему»; proving that theorem «доказательство этой теоремы»; ср. (32), (33)). В их числе мы имеем такие группы, как to be cheated «быть обманутым», being cheated «состояние обманутого», характерные для пассивных предложений. Но пассивные предложения не входят в ядро, следовательно, именные группы to+VP или ing+NP не могут вводиться в грамматику посредством таких правил, как (33). Поэтому они должны вводиться с помощью «номинализую- щей трансформации», превращающей предложение типа NP—VP в именную группу типа to+VP или ing+VP[41] Мы не станем вникать в структуру интересного и разветвленного множества номинализующих трансформаций, а ограничимся лишь кратким изложением решения трансформационной проблемы, поставленной в § 2.3.
Одной из номинализующих трансформаций является трансформация ТAdj, воздействующая на любую цепочку вида
(71) Т—N—is—Adj (т. е. артикль—существительное—есть—прилагательное)
и обращающая ее в соответствующую именную группу типа T+Adj+N. Так, она обращает The boy is tall «Мальчик высок» в the tall boy «высокий мальчик» и т. п. Ясно, что такая трансформация значительно упрощает грамматику и следует избрать именно этот, а не противоположный путь. При надлежащей формулировке данной трансформации мы обнаружим, что она позволяет изъять из ядра все комбинации прилагательного с существительным, с тем чтобы затем ввести их посредством ТAdj.
В грамматике непосредственно составляющих существует правило
(72) Adj—>old, tall..,
перечисляющее все элементы, которые могут выступать в ядерных предложениях типа (71). Однако слов типа sleeping «спящий» в этом списке не будет, хотя и существуют такие предложения, как
(73) The child is sleeping «Ребенок спит [в данный момент]».
Такое предложение можно построить, несмотря на отсутствие sleeping в (72), (73), с помощью трансформации (29 II), превращающей Af+v в v+Af# из терминальной цепочки
(74) the+child+C+be—ing—sleep,
где be+ing — часть вспомогательного глагола (ср. 28 III). Наряду с (73) мы располагаем также предложениями типа The child will sleep «Ребенок будет спать», The child sleeps «Ребенок спит», и т. д., получаемыми при различном выборе вспомогательного глагола.
Такие же слова, как interesting «интересный», придется ввести в (73)[42]. В предложениях типа
(75) The book is interesting «Книга интересна»
interesting есть Adj, а не часть Verb, что можно видеть из факта отсутствия высказываний The book will interest; The book interests и т. п.
Подтверждение такого анализа слов interesting и sleeping можно получить, рассматривая поведение слова very «очень», которое с одними прилагательными сочетается, а с другими — нет. Простейший способ обращения с very состоит в том, чтобы ввести в грамматику непосредственно составляющих правило
(76) Adj—>very+Adj.
Very может появляться в (75) и всюду вместе с interesting; но это слово не может встречаться в (73) и в других контекстах в сочетании со sleeping «спящий». Следовательно, чтобы сохранить простейший способ трактовки
Very, мы должны ввести в (72) в качестве Adj только interesting, но не sleeping.
Мы не рассматривали вопроса о том, как влияет трансформация на структуру составляющих, хотя и указали, что это необходимо сделать, в частности, для того, чтобы можно было сочетать трансформации друг с другом. Одно из условий для производной структуры составляющих предложения следующее.
(77) Если X есть Z в грамматике непосредственно составляющих, а цепочка Y, являющаяся результатом трансформации, имеет тот же структурный вид, что и X, то Y также есть Z[43]
В частности, даже при отсутствии в ядре пассивных предложений нам может понадобиться утверждение, что группа с by (например, в The food was eaten—by the man «Пища съедается человеком») есть предложная группа (РР) пассивного предложения. Утверждать это позволяет нам (77), поскольку из грамматики ядра известно, что by+NP есть PP. Условие (77) не сформулировано с достаточной точностью, но его можно разработать более тщательно в качестве одного из условий, предъявляемых к производной структуре составляющих.
Теперь еще раз рассмотрим (73). Слово sleeping получается в результате применения трансформации (29 II) и имеет ту же форму, что и слово interesting (т. е. V+ing), которое, как мы знаем из грамматики непосредственно составляющих, есть Adj. Следовательно, в силу (77) sleeping есть также Adj в трансформе (73). А это значит, что (73) может рассматриваться в качестве цепочки типа (71) и поэтому к нему применима трансформация Тadj, образующая именную группу:
(78) the sleeping child
«спящий ребенок».
Точно так же образуется и the interesting book «интересная книга» из (75). Таким образом, хотя sleeping исключено из G2), оно выступает в качестве прилагательного, определяющего существительное.
Подобный анализ Прилагательных (представляющий собой максимум того, что может потребоваться для фактически встречающихся предложений) не вводит, однако, слово sleeping во все адъективные позиции слов типа interesting, которые остаются в ядре. Он ни в коем случае не введет, например, sleeping в контекст very— . Поскольку very никогда не определяет глаголов, оно не выступит в (74) или (73), и все случаи появления sleeping как определения связаны с его появлением в качестве глагола в (74) и т. п.
Подобным же образом можно установить правила грамматики непосредственно составляющих, разлагающие глагольную группу на:
(79) Aux+seem+Adj,
точно так же, как другие правила представляют VP в виде Aux+V+NP, Aux+be+Adj и т. д. Но sleeping в коем случае не может быть введено в контекст seem — с помощью грамматики, которая является, по-видимому, наиболее простейшей из всех, какую можно построить для фактически встречающихся предложений.
Развивая наше краткое рассуждение более подробно, мы могли бы прийти к заключению, что простейшая трансформационная грамматика встречающихся предложений исключит (80), но породит (81).
(80) (I) The child seems sleeping
(II) The very sleeping child
(81) (I) The book seems interesting
«Книга кажется интересной»
(II) The very interesting book
«Очень интересная книга».
Мы видим теперь, что упомянутые в§ 2.3, по-видимому, произвольные различия между (3) (=Have you a book on modern music? «Есть ли у вас книга по современной музыке?») и (4) (=81 I), с одной стороны, и (5) (—Read you a book on modern music? «Читаете ли вы книгу по современной музыке?») и (6) (=(80 I)), с другой, имеют ясное структурное происхождение и являются в действительности примером регулярности более высокого уровня,ч поскольку они обусловлены простейшей трансформационной грамматикой. Другими словами, определенные случаи лингвистического поведения, которые представляются немотивированными и непонятными на уровне анализа по непосредственно составляющим, оказываются простыми и систематическими, как скоро мы встанем на трансформационную точку зрения. Пользуясь терминологией § 2.2, мы можем сказать, что, если бы говорящему надо было проецировать свой конечный лингвистический опыт, используя структуру непосредственно составляющих и трансформации простейшим возможным способом, совместимым с его опытом, он принял бы (3) и (4) как грамматически правильные, но отклонил бы (5) и (6).
7.4.
В (28) (см. § 5.3) мы разложили элемент Verb на Aux+V, а затем просто перечислили глагольные корни класса V. Существует, однако, большое число продуктивных подконструкций элемента V, заслуживающих упоминания, поскольку они проливают свет на некоторые принципиальные моменты. Рассмотрим прежде всего такие конструкции вида V+Prt (глагол+частица), как bring in «ввести», call up «вызвать», drive away «прогнать».
Можно получить такие формы, как (82), но не как (83).
(82) (I) The police brought in the criminal
«Полицейские ввели преступника»
(II) The police brought the criminal in
«Полицейские ввели преступника»
(III) The police brought him in
«Полицейские ввели его»
(83) The police brought in him.
Мы знаем, что разрывные элементы трудно истолковывать в рамках грамматики непосредственно составляющих. Значит, наиболее естественный способ объяснения
этих конструкций состоит в том, чтобы добавить к правилу (28 II) возможность
(84) V—>V1+Prt
наряду с совокупностью дополнительных правил, указывающих, какой V1 может выступать с какой Prt. Чтобы реализовать возможность (82 II), введем факультативную трансформацию Тopsep, воздействующую на цепочки со структурным разложением
(85) X—V1—Prt—NP
и меняющую местами третий и четвертый элементы цепочки. Тем самым эта трансформация превращает (82 I) в (82 II). Чтобы предусмотреть (82 III), но исключить (83), мы должны указать, что эта трансформация обязательна, если NP дополнения представлено местоимением (Pron). Равным образом мы можем ввести обязательную трансформацию Тopsep, имеющую тот же структурный результат, что и Тobsep. но применяемую к цепочкам с разложением
(86) X—V1—Prt—Pron.
Мы знаем, что пассивная трансформация воздействует на всякую цепочку типа NP—Verb—NP. Если установить, что пассивная трансформация применяется перед Тopsep или Тobsep, можно получить из (82 I) грамматически правильные предложения
(87) (I) The criminal was brought in by the police
«Преступник был введен полицейскими»
(II) Не was brought in by the police
«Он был введен полицейскими».
Дальнейшее изучение глагольной группы показывает, что существует обобщенная конструкция глагол+дополнение (V+Comp), которая ведет себя весьма сходно с только что рассмотренной конструкцией глагол+частица. Рассмотрим предложения:
(88) Everyone in the lab considers John incompetent «Каждый в этой лаборатории рассматривает Джона как несведущего»
(89) John is considered incompetent by everyone in the lab «Джон рассматривается как несведущий каждым в этой лаборатории».
Если мы хотим получить (89) из (88) посредством пассивной трансформации, следует разложить (88) на составляющие NP1—Verb— NP2, где NР1=everyone+in+the+lab, a NP2=John. Другими словами, мы должны применять трансформацию не к (88), а к лежащей в основе (88) терминальной цепочке (90):
(90) Everyone in the lab—considers incompetent—John
«Каждый в этой лаборатории—рассматривает как несведущего—Джона».
Мы можем теперь образовать (88) из (90) посредством трансформации, аналогичной Тobsep. Допустим, мы добавим к правилу (84) грамматики непосредственно составляющих правило
(91) V—>Va+Comp.
Обобщим теперь Тobsep так, чтобы она применялась и к цепочкам типа
(92) X—Va—Comp—NP,
а не только к (86), как выше.
Эта пересмотренная трансформация Тobsep обращает (90) в (88). Таким образом, конструкции глагол+дополнение и глагол+частица обрабатываются совершенно аналогично. Первая из них является чрезвычайно широко распространенной конструкцией английского языка[44].
7.5.
Мы лишь вкратце остановимся на обосновании конкретной формы каждой из рассмотренных трансфор* маций. Не менее важно установить, является ли система трансформаций единственно возможной. Я думаю, мы можем показать, что каждый из рассмотренных выше случаев, равно как и многие другие, обладает весьма ясными и легко обобщаемыми критериями простоты, позволяющими решить, какая именно совокупность предложений относится к ядру и какого рода трансформации необходимы для объяснения неядерных предложений. В качестве примера мы рассмотрим статус пассивной трансформации.
В § 5.4 мы показали, что грамматика оказывается гораздо более сложной, когда она содержит в ядре как активные, так и пассивные предложения, чем если последние исключены из ядра и вводятся посредством трансформации, меняющей местами подлежащее и прямое дополнение активного предложения и заменяющей глагол V цепочкой is+V+en+by. В связи с необходимостью выяснить, является ли данная система единственно возможной, возникают два вопроса. Во-первых, обязательно ли менять местами именные группы при образовании пассивного предложения? Во-вторых, не лучше ли было бы отнести пассивные предложения к ядру, а соответствующие активные выводить из них с помощью некой «активной» трансформации?
Рассмотрим сначала вопрос об инверсии подлежащего и прямого дополнения. Необходима ли такая перестановка или можно описать пассивную трансформацию как осуществляющую следующее воздействие:
(93) цепочка NP1—Aux—V—NP2
заменяется цепочкой NP1—Aux+be+en—V—by+NP2.
В частности, пассивной формой от John loves Mary «Джон любит Мери» будет John is loved by Mary «Джон любим Мери».
В § 5.4 мы отвергли (93) в пользу инверсии, основываясь на том факте, что существуют такие предложения, как (94), но не как (95).
(94) (I) John admires sincerity — Sincerity is admired by John
«Джон обожает искренность» — «Искренность обожаема Джоном»
(II) John plays golf — Golf is played by John
«Джон играет в гольф» — «Гольф играется Джоном»
(III) Sincerity frightens John — John is frightened by sincerity
«Искренность пугает Джона» — «Джон пугается искренности»
(95) (I) Sincerity admires John — John is admired by sincerity
«Искренность обожает Джона» — «Джон обожаем искренностью»
(II) Golf plays John—John is played by golf
«Гольф играет в Джона» — «Джон играется гольфом»
(III) John frightens sincerity — Sincerity is frightened by John
«Джона пугает искренность» — «Искренность пугается Джона».
Мы указывали, однако, что такой подход требует разработки понятия «степени грамматической правильности», которое было бы способно подкрепить это различение. Я полагаю, что данный подход верен, и утверждение о том, что предложения (94) более грамматически правильны, чем предложения (95), а последние в свою очередь более грамматически правильны, чем Sincerity admires eat и т. п., имеют достаточно ясный смысл. Всякая грамматика, различающая имена собственные и нарицательные, обладает достаточной «разрешающей силой» для описания разницы, например, между (94 I, III) и (95 I, III), и, разумеется, лингвистическая теория должна предоставлять средства для такого различения. Однако, поскольку в настоящем исследовании мы не касаемся вопроса о категориях, интересно показать, что существует также более сильный довод против (93). Действительно, любая грамматика, способная различать единственное и множественное число, в состоянии дать нам средства для доказательства того, что пассивная трансформация требует инверсии именных групп.
Чтобы убедиться в этом, рассмотрим конструкцию глагол+дополнение, упомянутую в § 7.4. Наряду с (88) и (89) мы имеем такие предложения, как
(96) All the people in the lab consider John a fool
«Все люди в лаборатории рассматривают Джона как дурака».
(97) John is considered a fool by all the people in the lab
«Джон рассматривается как дурак всеми людьми в лаборатории»,
В § 7.4 мы видели, что (96) образуется с помощью трансформации Тopsep из цепочки
(98) All the people in the lab—consider a fool—John (NP—Verb—NP),
где Verb «consider a fool»— пример (91). Мы видели также, что пассивная трансформация применяется непосредственно к (98). Если она меняет местами подлежащее и прямое дополнение, она правильно образует (97) из (98) в качестве пассива от (96). Если же, однако, принять (93) за определение пассивной трансформации, мы получим непредложение
(99) All the people in the lab are considered a fool by John
«Все люди в лаборатории рассматриваются как дураки Джоном»
в результате применения этой трансформации к (98).
Все дело в том, что мы нашли такой глагол, а именно consider a fool, который должен согласоваться в числе как с подлежащим, так и со своим прямым дополнением[45]. Существование таких глаголов — убедительное доказательство того, что пассивная трансформация должна основываться на инверсии подлежащего и прямого дополнения. Рассмотрим теперь вопрос о том, можно ли отнести к ядру пассивные предложения вместо активных. Нетрудно видеть, что этот вариант ведет к гораздо более сложной грамматике. При наличии активных предложений в ядре грамматика непосредственно составляющих включает (28), причем в (28 III) опущен случай be+en. Если же отнести к ядру пассивные предложения, be+en должно присутствовать в (28 III) наряду с другими формами вспомогательного глагола, и мы должны будем добавить специальные правила, указывающие, что, если V непереходный, он не может иметь вспомогательный глагол be+en (т. е. мы не можем получить lunch eats by John). При сравнении указанных двух вариантов не возникает никаких сомнений по поводу того, какой из них более сложен, и мы оказываемся вынужденными оставить в ядре активные предложения, а не пассивные.
Заметим, что, если бы в качестве ядерных были выбраны пассивные предложения, а не активные, мы столкнулись бы с трудностями совершенно иного рода. Ведь в таком случае «активная» трансформация применялась бы к цепочкам типа
(100) NP1—Aux+be+en—V—by+NP2,
обращая их в NP2— Aux—V—NР1. Так, например, она обращала бы
(101) The wine was drunk by the guests
«Вино было выпито гостями»
в The guests drank the wine «Гости выпивали вино», где drunk «выпивали» восходит к en+drink. Но существует также прилагательное drunk «пьяный» (72), наряду с old «старый», interesting «интересный» и т. п.; так, мы встречаем Не is very drunk «Он сильно пьян», Не seems drunk «Он кажется пьяным» и т. д. (ср. § 7.3); однако это прилагательное также восходит к en+drunk. Представляется, таким образом, что в простейшей системе непосредственно составляющих английского языка предложение
(102) John was drunk by midnight
«Джон был пьян к полночи»
также имеет в своей основе терминальную цепочку, которая допускает разложение в соответствии с (100). Другими словами, структурного способа для различения (101) и (102) не существует, если оба они считаются ядерными предложениями. Однако применение «активной» трансформации к (102) не дает грамматически правильного предложения.
Если мы действительно попытаемся построить для английского языка простейшую грамматику, содержащую правила уровня непосредственно составляющих и трансформационные правила, то окажется, что ядро состоит из простых повествовательных активных предложений (фактически, вероятно, из конечного числа таких предложений) и что все прочие предложения можно описать более просто как трансформы. Можно показать, что каждая из трансформаций, которые я исследовал, необратима в том смысле, что в одном направлении осуществить трансформацию гораздо легче, чем в другом; именно такой случай представляет рассмотренная выше пассивная трансформация. Этим можно объяснить традиционную практику грамматистов, которые обычно начинают грамматику английского языка, например, с изучения простых предложений типа «деятель—действие» и простых грамматических отношений вроде подлежащее—сказуемое и глагол—дополнение. Никто не станет всерьез начинать изучение структуры составляющих английского языка с таких предложений, как Whom have they nominated «Кого они уже назвали», пытаясь разложить их на две части и т. д.; и в то время, как в некоторых весьма подробных исследованиях структуры английского языка о вопросительных предложениях даже не упоминается, нет такого исследования, которое не рассматривало бы предложения повествовательные. Трансформационный анализ дает довольно простое объяснение этой асимметрии (которая иначе формально не мотивирована), исходя из допущения, что грамматисты действуют на основе правильных интуитивных представлений о языке[46]
7.6.
Еще один пункт заслуживает упоминания, прежде чем мы покончим с трансформациями английского языка. В конце § 5 мы заметили, что правило сочинения дает полезный критерий правильности разложения на составляющие в том смысле, что это правило значительно упрощается, если составляющие установлены определенным образом. Теперь мы истолковываем это правило как трансформацию. Отмечено немало и других случаев, когда поведение предложения при трансформациях дает нам ценные, даже решающие свидетельства в пользу той или иной структуры его составляющих.
Рассмотрим, например, пару предложений.
(103) (I) John knew the boy studying in the library.
«Джон знал мальчика, [в данный момент] занимающегося в библиотеке».
(II) John found the boy studying in the library.
«Джон нашел мальчика, [в данный момент] занимающимся в библиотеке»,
«Джон нашел, что мальчик [в данный момент] занимается в библиотеке»[47].
Интуитивно ясно, что приведенные предложения имеют- различную грамматическую структуру (это становится очевидным, например, если к (103) добавить not running around in the streets «а не гоняет по улице»). Однако, мне кажется, что на уровне непосредственно составляющих можно найти основания для того, чтобы по-разному разлагать на составляющие (103 I) и (103 II). Простейшее разложение в обоих случаях есть NP—Verb—NP—mg+VP. Рассмотрим, однако, поведение этих предложений в ходе пассивной трансформации. (104) — предложения, а (105) — нет[48].
(104) (I) The boy studying in the library was known (by John)
«Мальчик, занимающийся в библиотеке, были известен (Джону)»
(II) The boy studying in the library was found (by John)
«Мальчик, занимающийся в библиотеке, был найден (Джоном)»
(III) The boy was found studying in the library (by John)
«Джоном было найдено, что мальчик занимается в библиотеке».
(105) The boy was known studying in the library (by John).
Пассивная трансформация применима только к предложениям типа NP—Verb—NP. Следовательно, для получения (104 II) нужно разложить (103 II) так:
(106) John—found—the boy studying in the library «Джон—нашел—мальчика, занимающегося в библиотеке».
Здесь прямым дополнением является именная группа the boy studying in the library. (103 I) имеет такое разложение в связи с тем, что существует пассивное предложение (104 I).
Но предложению (103 II) соответствует пассивное предложение (104 III). Отсюда мы заключаем, что (103 II) является случаем конструкции глагол+дополнение, исследованной в § 7.4, т. е. что оно выводится посредством трансформации Тobsep из цепочки
(107) John—found studying in the library—the boy,
где found — глагол, a studying in the library — дополнение. Пассивная трансформация переводит (107) в (104 III) точно так же, как она переводит (90) в (89). (103 I), однако, не является трансформом цепочки John—knew studying in the library—the boy (та же форма, что и (107) ), поскольку (105) не есть грамматически правильное предложение.
Изучая грамматически правильные пассивные предложения, мы находим далее, что John found the boy studying in the library (=(103 II)) разлагается двояко: как NP— Verb—NP с дополнением The boy studying in the library и как NP—Aux+V—NP—Comp (трансформ цепочки (107) со сложным Verb: found studying in the library). John knew the boy studying in the library (=(1031)) допускает, однако, лишь первое из этих разложений. Такая трактовка (103) находится в полном согласии с интуицией.
В качестве другого примера такого же рода рассмотрим предложение
(108) John came home
«Джон пришел домой».
Хотя John и home суть NP, a came является глаголом (Verb), исследование воздействия трансформаций на (108)
Показывает, что последнее не может быть разложено на NP—Verb—NP. Мы не получаем грамматически правильных предложений ни в результате пассивной трансформации (Home was come by John), ни в результате вопросительной трансформации Tw (what did John come). Следовательно, мы должны разложить (108) каким-то иным образом (если не хотим чересчур усложнять определение этих трансформаций), по-видимому, на элементы NP—Verb—Adverb. Иначе я не вижу сколько-нибудь сильных доводов против разложения (108) на NP—Verb—NP с home в качестве дополнения к came.
Я думаю, будет правильным сказать, что значительное число основных критериев определения структуры составляющих является фактически трансформационным. Общий принцип таков: если налицо трансформация, упрощающая грамматику и ведущая от предложения к предложению (т. е. трансформация, весьма тесно охватывающая множество грамматически правильных предложений), то определять структуру составляющих предложения следует таким образом, чтобы эта трансформация всегда приводила к грамматически правильным предложениям, упрощая этим грамматику все больше и больше.
Читатель заметит, пожалуй, ошибку логического круга или даже явную непоследовательность в наших рассуждениях. Мы определяем такие трансформации как пассивные через конкретный анализ предложений по непосредственно составляющим, а затем рассматриваем поведение предложений в ходе этих трансформаций для того, чтобы решить, каким образом следует анализировать эти предложения.
В § 7.5 мы использовали тот факт, что John was drunk by midnight «Джон был пьян к полуночи» (=(102)) не имеет соответствующего «активного» предложения, в качестве довода против допущения пассивно-активной трансформации. В § 7.6 мы использовали факт, что John came home «Джон пришел домой» (=(108)) не имеет пассива, как довод против приписывания этому предложению разложения NP—Verb—NP. Однако если разобраться в рассуждениях тщательно, то в каждом случае станет ясно, что логический круг или непоследовательность отсутствуют. В каждом случае нашей единственной задачей было уменьшить сложность грамматики, и мы старались доказать, что предлагаемый анализ гораздо проще отбрасываемых вариантов. Иногда грамматика упрощается, если мы отказываемся от некоторых трансформаций; в других случаях лучше изменить разложение. Мы следовали, таким образом, курсу, намеченному в § 6. Используя модель непосредственно составляющих и трансформационную модель, мы старались построить грамматику английского языка, которая была бы проще любой другой предложенной, и не заботились о том, как в действительности можно прийти к этой грамматике автоматическим путем, исходя из всей совокупности наблюденных предложений английского языка независимо от объема последней. Поставив перед собой более скромную задачу выбора вместо задачи открытия, мы устраним всякую опасность порочного круга в рассмотренных выше случаях. Интуитивные соответствия и объяснение кажущейся нерегулярности дают, как мне представляется, важное свидетельство правильности разрабатываемого нами метода. Ср. § 8.
8. ОБЪЯСНИТЕЛЬНАЯ СИЛА ЛИНГВИСТИЧЕСКОЙ ТЕОРИИ
8.1.
До сих пор мы считали, что задачей лингвиста является создание своеобразного механизма (называемого грамматикой), предназначенного для порождения всех и только предложений некоторого языка, каким-то образом заданного заранее. Мы видели, что такое понимание деятельности лингвиста, естественно, приводит к описанию языков посредством уровней представления; некоторые из них являются абстрактными и нетривиальными. В частности, это ведет к необходимости определять структуру непосредственно составляющих и трансформационную структуру как различные уровни представления грамматически правильных предложений.
Теперь перейдем к изложению задач лингвиста в совершенно ином плане, что, однако, должно привести нас к сходным представлениям о лингвистической структуре. Существует немало фактов языка и лингвистического поведения, требующих объяснения независимо от того, является ли такая-то и такая-то цепочка (которую, может быть, никто никогда и не произведет) предложением или нет. Можно надеяться, что грамматики дадут объяснение некоторым из этих фактов. Так, например, последовательность фонем /eneym/ многими говорящими по-английски может пониматься двояко: как a name «некоторое имя» и как an aim «некоторая цель». Если бы наша грамматика была системой с одним уровнем, имеющей дело только с фонемами, мы не получили бы никакого объяснения этому факту. Но, разработав морфологический уровень, мы обнаруживаем, что по совершенно независимым причинам необходимо задать морфемы a, an, aim и name с фонетическим составом /a/, /an/,/eym/ и /neym/. Отсюда как автоматическое следствие попытки задать морфологию простейшим возможным способом вытекает, что последовательность фонем /eneym/ может быть представлена на морфологическом уровне двояким образом. Вообще мы называем конструкционной омонимией случаи, когда данная последовательность фонем разложима на каком-либо уровне более, чем одним способом. Это дает нам критерий адекватности грамматик. Можно проверить адекватность заданной грамматики, поставив вопрос, действительно ли каждому случаю конструкционной омонимии отвечает двусмысленность выражения и каждому случаю какого бы то ни было рода двусмысленности отвечает конструкционная омонимия[49]. Вообще, если известное представление о том, какую форму должна иметь грамматика, приводит к созданию грамматики, не выдерживающей проверки, то мы вправе сомневаться в адекватности этого представления и лингвистической теории, на которой оно основано. Таким образом, прекрасным доводом в пользу принятия морфологического уровня служит то обстоятельство, что на этом уровне естественным образом описывается иначе не объяснимая двусмысленность выражения /eneym/.
Когда некоторая последовательность фонем допускает неоднозначное представление, мы имеем случай конструкционной омонимии. Допустим, что на некотором уровне две различных последовательности фонем разлагаются сходным или тождественным образом. Можно ожидать, что эти последовательности должны «пониматься» в каком-то смысле одинаково, точно так же как случаи двойственного представления «понимаются» неодинаково. Например, предложения
(109) (I) John played tennis
«Джон играет в теннис»
(II) My friend likes music
«Мой друг любит музыку»
Совершенно различны на фонемном и морфемном уровнях. Но на уровне непосредственно составляющих оба они получают представление NP—Verb—NP; итак, в некотором смысле они понимаются одинаково. Этот факт нельзя объяснить в терминах грамматики, которая не выходила бы за рамки уровня морфем или слов, и, следовательно, такие случаи служат поводом для введения уровня непосредственно составляющих совершенно
независимо от положений, выдвинутых в § 3. Заметим, что соображения, касающиеся структурной омонимии, также могут служить причиной для введения уровня непосредственно составляющих. Такие выражения, как old men and women «старые мужчины и женщины» и they are flying planes «(они) летят [в данный момент] на самолетах» (т. е. those specks on the horizons are flying planes «те точки на горизонте — самолеты» или my friends are flying planes «мои друзья летят на самолетах»), явно двусмысленны, и, действительно, они двояко разлагаются на уровне непосредственно составляющих, но не на более низких уровнях. Вспомним, что анализ выражения на уровне непосредственно составляющих определяется не одной цепочкой, а схемой типа (15) или, что то же самое, некоторым множеством представляющих цепочек[50].
Мы утверждаем, что понятие «понимание предложения» должно определяться отчасти через понятие «лингвистического уровня». В таком случае, чтобы понять предложение, необходимо прежде всего разложить его на каждом из лингвистических уровней; тогда можно проверить адекватность данной совокупности абстрактных лингвистических уровней, поставив вопрос, позволяют ли грамматики, сформулированные в терминах этих уровней, получить удовлетворительное определение понятия «понимание». Случаи сходства на высших уровнях или различия на высших уровнях (конструкционная омонимия) — просто крайние случаи, которые, если принять нашу схему, доказывают существование высших уровней. Вообще нельзя полностью понять ни одного предложения, если мы не знаем, как оно разлагается на всех уровнях, включая такие высшие уровни, как уровень непосредственно составляющих и, как мы увидим далее, трансформационный уровень.
Мы смогли-показать неадекватность теории лингвистической структуры, не поднявшейся до уровня анализа по непосредственно составляющим, указав на необъяснимые на более низких уровнях случаи двусмысленного и сходного понимания. Однако оказывается, что остается еще большое число необъясненных случаев даже после того, как уровень непосредственно составляющих установлен и применен к английскому языку. При рассмотрении этих случаев выясняется необходимость установить еще более «высокий» уровень трансформационного анализа независимо от того, что сказано в § 5.7. Я приведу лишь несколько примеров.
8.2.
В § 7.6 мы рассмотрели предложение I found the boy studying in the library ==(103 II), двусмысленность которого нельзя обнаружить без привлечения трансформационных критериев. Мы нашли, что при одной интерпретации это предложение оказывается трансформом выражения I—found studying in the library—the boy, полученным применением Тobsep, а при другой — оно предстает в виде конструкции NP—Verb—NP c прямым дополнением The boy studying in the library. Дальнейший трансформационный анализ должен показать, что в обоих случаях это предложение является трансформом пары терминальных цепочек, которые лежат в основе простых ядерных предложений:
(110) (I) I found the boy
«Я нашел мальчика»
(II) The boy is studying in the library
«Мальчик [в данный момент] занимается в библиотеке».
Мы получаем, таким образом, интересный случай предложения, двусмысленность которого — результат двоякого трансформационного вывода из одних и тех же ядерных цепочек. Однако это весьма сложный пример, требующий довольно детального изучения того, каким образом трансформации определяют структуру составляющих; нетрудно найти более простые примеры двусмысленностей трансформационного происхождения.
Рассмотрим группу (111), которая может быть понята двояко: hunters «охотники» здесь может быть подлежащим, как в (112 I), и прямым дополнением, как в (112 II):
(111) the shooting of the hunters
«стрельба охотников»
(112) (I) the growling of lions
«рычание львов»
(II) the raising of flowers
«выращивание цветов».
На уровне непосредственно составляющих нет удовлетворительного способа объяснить эту двусмысленность; все группы представляются в виде the—V+ing—of+NP[51]. В трансформационных терминах, однако, можно дать ясное и автоматическое объяснение. Тщательный анализ английского языка показывает, что можно упростить грамматику, если изъять группы, подобные (111) и (112), из ядра и ввести их с помощью трансформаций. Для объяснения групп типа (112 I) введем трансформацию, переводящую любое предложение типа NP—С—V в соответствующую группу типа the—V+ing—of+NP; причем эта трансформация задумана так, что результатом является NP[52]. Для объяснения A12 II) введем трансформацию, переводящую любое предложение типа NP1—С — V — NP2 в соответствующую группу NP типа the—V+ing—of+NP2. Так, первая из этих трансформаций превращает lions growl «львы рычат» в the growling of lions «рычание львов», а вторая превращает John raises flowers «Джон выращивает цветы» в the raising of flowers «выращивание цветов». С другой стороны, The hunters shoot «Охотники стреляют» и They shoot the hunters «Они стреляют охотников» — ядерные предложения. Следовательно, группа (111) = The shooting of the hunters имеет двоякое происхождение, т. е. она является двусмысленной на трансформационном уровне. Двузначность грамматического отношения в (111) — следствие того, что отношение между shoot и hunters различно в двух исходных ядерных предложениях. В (112) такой двусмысленности нет, поскольку ни They growl lions, ни Flowers raise не являются грамматически правильными ядерными предложениями.
Подобным же образом рассмотрим пару предложений:
(113) (I) The picture was painted by a new technique
«Эта картина написана новым методом»
(II) The picture was painted by a real artist
«Эта картина написана настоящим художником».
Приведенные предложения понимаются по-разному, несмотря на то, что они имеют одно и то же разложение NP—was+Verb+en—by+NP на уровне непосредственно составляющих. Совершенно различны и их трансформационные истории. A13 II) — пассив от A real artist painted the picture «Настоящий художник написал картину», а A13 I) образовано, например, из John painted the picture by a new technique «Джон написал картину новым методом» посредством двойной трансформации: мы осуществляем сперва пассивную, а затем эллиптическую трансформацию (которая упомянута в прим. 48 на стр. 493), опускающую «действующее лицо» в пассивном предложении. Нетрудно отыскать абсолютный омоним, построенный согласно модели A13). Например, предложение
(114) John was frightened by the new methods
«Джон был испуган новым методом»
может означать либо, что Джон консервативен — новые методы пугают его, либо, что новые методы устрашения людей применяются для того, чтобы испугать Джона (эта интерпретация выглядела бы более естественно,если бы после was мы вставили being). На трансформационном уровне предложение (114) имеет как разложение (113 I), так и разложение (113 II), чем и объясняется двусмысленность этого предложения.
8.3.
Мы можем завершить наши рассуждения примером противоположного характера. Имеются в виду предложения, понимаемые сходным образом, хотя они совершенно различны на уровне анализа по непосредственно составляющим и на более низких уровнях представлений Приведем следующие предложения, рассмотренные в § 7.2
(115) (I) John ate an apple — повествовательное предложение
«Джон ел яблоко»
(II) Did John eat an apple — общевопросительное предложение
«Ел ли Джон яблоко»
(III) What did John eat — частновопросительное предложение
«Что ел Джон»
(IV) Who ate an apple — частновопросительное предложение
«Кто ел яблоко»
Интуитивно мы понимаем, что (115) содержит предложения двух типов — повествовательные (115 I) и вопросительные (115 II—IV). Кроме того, вопросительные предложения интуитивно можно подразделить на два типа: общевопросительные (115 II) и частновопросительные (115 III, IV). Однако трудно найти такие формальные основания для этой классификации, которые не были бы произвольными и эмпиричными. Если, скажем, делить предложения по признаку интонации, то (115 I), (115 III) и (115 IV), имеющие нормальную повествовательную нисходящую интонацию, окажутся противопоставленными (115 II), где интонация восходящая. Если разделить предложения по признаку порядка слов, то в одну группу попадут (115 I) и (1151V) с прямым порядком слов NP—Verb—NP, а в другую (115 II) и (115 III), имеющие инверсию подлежащего и вспомогательного глагола. Тем не менее любая грамматика английского языка классифицирует эти предложения так, как показано в (115), и каждый говорящий на английском языке понимает эти предложения в соответствии с данной моделью. Без сомнения, лингвистическая теория, которая не в состоянии обосновать такую классификацию, должна быть признана неадекватной.
Представление некоторой цепочки на уровне трансформаций определяется терминальной цепочкой (или цепочками), от которых она происходит, и последовательностью трансформаций, с помощью которых она выводится из исходных цепочек. В §§ 7. 1—2 мы пришли к следующим выводам относительно (115) ( = (70)). Каждое из предложений (115) происходит из терминальной цепочки
(116) John—С—eat+an+apple (=61),
которая устанавливается в рамках грамматики непосредственно составляющих. (115 I) получается из (116) применением только обязательных трансформаций; следовательно, это, по определению, ядерное предложение. (115 II) получается из (116) благодаря применению обязательных трансформаций и Tq, a (115 III) и (115 IV) получаются посредством применения обязательных трансформаций Tq и Tw. Они различаются только выбором именной группы, к которой применяется Tw. Допустим, тип предложения определяется в общем через его трансформационную историю, т. е. его представлением на трансформационном уровне. Тогда главное подразделение (115) пройдет между ядерным предложением (115 I), с одной стороны, и предложениями (115 II—IV) (каждое из которых имеет То в своем трансформационном представлении) —с другой. Таким образом, предложения (115 II—IV) являются вопросительными. (115 III—IV) составляют особый подкласс вопросительных предложений, поскольку в их образовании участвует дополнительно трансформация Tw. Таким образом, сформулировав простейшую трансформационную грамматику для (115), мы обнаруживаем, что полученные трансформационные представления дают классификацию предложений, которая интуитивно является правильной.
9. СИНТАКСИС И СЕМАНТИКА
9.1.
Итак, мы нашли случаи предложений, понимаемых по-разному и имеющих неоднозначное представление на уровне трансформаций (но не на других уровнях), и случаи предложений, понимаемых одинаково и одинаково представленных только на уровне трансформаций. Тем самым мы получили обоснование для описания языка в терминах трансформационной структуры и для введения трансформационного представления в качестве лингвистического уровня столь же фундаментального характера, как и другие уровни. Более того, теперь укрепилась наша уверенность в том, что процесс «понимания предложений» можно объяснить частично с помощью понятия лингвистического уровня.[Чтобы понять предложение, необходимо, в частности, знать, каковы ядерные предложения, из которых оно получено (точнее — терминальные цепочки, лежащие в основе ядерных предложений),и какова структура каждого из этих элементарных составляющих, а также трансформационная история получения данного предложения из этих ядерных предложений[53]. Общая проблема анализа процесса «понимания» сводится в известной мере к объяснению того, как понимаются ядерные предложения, рассматриваемые в качестве основных «содержательных» элементов, из которых посредством трансформаций образуются обычные более сложные предложения реальной речи.
Предполагая, что синтаксическая структура может пролить свет на проблему значения и понимания, мы вступаем на опасную почву. Не существует иного аспекта лингвистического исследования, вызывающего больше путаницы и недоразумений и более нуждающегося в ясной и тщательной формулировке, нежели проблема связи между синтаксисом и семантикой. Реальный вопрос, который можно задать, состоит в следующем: «Каким образом синтаксические механизмы, наличествующие в данном языке, «работают» при фактическом употреблении этого языка?» Однако вместо того, чтобы заниматься данной весьма важной проблемой, исследователи, изучающие связь между синтаксисом и семантикой, занимаются чаще всего посторонними проблемами и неправильно решают поставленные вопросы. Обсуждению подвергался, например, вопрос о том, нужна ли семантическая информация для открытия или выбора грамматики, и положительный ответ на этот вопрос неизменно вызывал новый вопрос: «Как можно построить грамматику, не обращаясь к значению!?»
Замечания о возможности использования семантических данных при синтаксических исследованиях, приведенные в § 8, не должны пониматься неправильно, т. е. они не должны подтверждать мнение о том, что грамматика основывается на значении. В действительности теория, изложенная в §§ 3—7, была полностью формальной и несемантической. В § 8 мы кратко указали несколько способов исследования того, как фактически используются наличные синтаксические средства. По-видимому, в эту проблему можно внести большую ясность путем чисто негативного рассмотрения возможностей отыскания семантических оснований для синтаксической теории.
9.2.1.
Много сил потрачено на то, чтобы ответить на вопрос: «Как построить грамматику, не обращаясь к значению?» Однако сам этот вопрос поставлен неправильно, поскольку подразумеваемый при этом тезис о том, что, обращаясь к значению, мы можем построить грамматику, совершенно не обоснован. С тем же правом можно спросить: «Как построить грамматику, не зная ничего о цвете волос говорящих»? На самом деле вопрос должен стоять только так: «Каким образом можно построить грамматику?» Мне не известно ни одного сколько-нибудь подробного опыта построения теории грамматической структуры в частично семантических терминах, ни какой-либо строгой и конкретной программы использования семантической информации при построении и выборе грамматик. Несомненно, «интуитивное чувство лингвистической формы» весьма полезно для исследователя лингвистических форм (т. е. грамматики). Совершенно ясно также, что главная задача лингвистической теории — заменить смутные интуитивные представления некоторым строгим и объективным подходом. Но имеется мало оснований считать, что" «интуитивное чувство значения» приносит вообще какую-нибудь пользу при реальном изучении лингвистических форм. Я думаю, что ошибочность утверждений об использовании значения при грамматическом анализе не очевидна лишь в силу их расплывчатости, а также вследствие печальной тенденции смешивать понятия «интуитивного чувства лингвистической формы» и «интуитивного чувства значения» (сами по себе смутные и нежелательные в лингвистической теории). Однако популярность таких утверждений делает небесполезным краткое рассмотрение некоторых из них, хотя, разумеется, доказывать их приходится именно тем лингвистам, которые заявляют о своей способности изложить грамматические понятия в терминах семантики.
9.2.2.
В числе наиболее обычных утверждений, выдвигаемых в пользу зависимости грамматики от семантики, встречаются следующие:
(117) (I) два высказывания фонетически различны в том и только в том случае, когда они различаются по значению;
(II) морфемы суть мельчайшие элементы, обладающие значением;
(III) грамматически правильные предложения— это предложения, обладающие семантической значимостью;
(IV) грамматическое отношение подлежащее — сказуемое (т. е. NP—VP как разложение для Sentence) соответствует общему «структурному значению» деятель — действие;
(V) грамматическое отношение глагол — дополнение (т. е. Verb—NP как разложение VP) соответствует структурному значению действие — цель и действие—объект действия;
(VI) активное предложение и соответствующее ему пассивное синонимичны.
9.2.3.
Многие лингвисты высказывали мнение, что фонетические различия должны определяться через дифференциальное значение (т. е., говоря проще, через синонимию) в соответствии с (117 I). Очевидно, однако, что утверждение (117 I) не может как таковое использоваться в качестве определения фонетических различий [54] Если мы не хотим совершить логическую ошибку petitio principii, то упомянутые высказывания должны быть индивидуальными знаками (tokens), а не знаками-типами (types). Дело в том, что существуют индивидуальные высказывания, фонематически различные, но тождественные по значению (синонимы), и существуют индивидуальные высказывания, фонематически тождественные, но разные по значению (омонимы). Таким образом, утверждение, входящее в состав (117 I), оказывается ложным, будем ли мы его проверять от основания к следствию или же, наоборот, от следствия к основанию. Если проверять его от следствия к основанию, то оно оказывается ложным в силу существования таких пар, как bachelor «баккалавр» и unmarried man «холостяк», или, говоря более точно, таких абсолютных синонимов, как /ekinamiks/ и /iyk+namiks/ economics «экономика»; adult «взрослый» и adult; /raesin/ и /reysin/ ration «рацион» и многих других, которые могут сосуществовать даже в одном стиле речи. Если проверять утверждение (117 I) от основания к следствию, то оно оказывается ложным в силу существования таких пар, как bank «берег» и bank «банк» [55], metal и medal (одинаково произносимых во многих диалектах) и др. Другими словами, если мы отнесем два индивидуальныхвысказывания к одному высказыванию-типу на основании (117 I), то получим неправильную классификацию в большом числе случаев.
К более слабому, чем (117 I), требованию можно прийти следующим образом. Допустим, мы имеем абсолютную фонетическую систему, данную нам до анализа какого бы то ни было языка, достаточно подробную, чтобы любые два фонемно различные высказывания любого языка транскрибировались различно. При этом может случиться, что некоторые различные знаки в этой фонетической транскрипции окажутся записанными одинаково. Предположим, мы определяем «неоднозначное значение» индивидуального высказывания как совокупность значений всех индивидуальных высказываний, записываемых одинаково с этим индивидуальным высказыванием. Тогда можно видоизменить (117 I), подставив «неоднозначное значение» : вместо «значение». Таким путем можно было бы подойти к проблеме омонимии, если бы мы могли наблюдать такое огромное количество высказываний, которое давало бы уверенность, что каждая фонетически отличная форма данного слова встречается в любом из значений, которые может иметь это слово. Допустим, окажется возможным распространить этот подход еще дальше на случаи синонимии. Тогда можно надеяться определить фонемные различия путем изучения значений элементов всей совокупности высказываний, записанных в фонетической транскрипции.Однако трудность точного и реалистического определения числа значений, которыми могут обладать несколько элементов совокупности, а также громоздкость задачи делают перспективу применения подобного метода весьма сомнительной.
9.2.4.
К счастью, мы не обязаны осуществлять такую искусственную и громоздкую программу, для того чтобы определить фонемные различия. На практике каждый лингвист пользуется гораздо более простыми и прямыми несемантическими средствами. Допустим, лингвист интересуется, являются ли metal и medal различными по своему фонемному составу в некотором диалекте английского языка. Он не станет изучать значений этих слов, поскольку такая информация не имеет отношения к его задаче. Он знает, что значения различаются, и желает выяснить, различны ли эти слова по своему фонемному составу. Добросовестный полевой исследователь использует, вероятно, парные тесты[56] с двумя информантами либо с одним информантом и магнитофоном. Он может, например, записать в случайной последовательности интересующие его высказывания и затем выяснить, в состоянии ли носитель языка распознать их надежным образом. При удовлетворительном распознавании лингвист может применить более cтрогий тест, попросив говорящего повторить каждое слово несколько раз и применить после этого новый парный тест. Если после повторения различие сохраняется, лингвист вправе утверждать, что metal и medal различны по своему фонемному составу. Парный тест с его вариантами и усовершенствованиями представляет нам ясный экспериментальный критерий фонемного различия, не связанный ни с какими семантическими категориями[57]. Несемантический подход к грамматике принято считать альтернативой по отношению к семантическому и критиковать его как слишком сложный, если вообще не невозможный. Мы находим, однако, что по крайней мере в случае фонематических различий справедливо как раз обратное. Существует вполне прямой и экспериментальный метод определения фонематических различий в виде акого несемантического способа, как парный тест. В принципе может оказаться возможной разработка некоторого семантического эквивалента парного теста и его модификаций, однако всякий подобный метод будет весьма сложным, требующим исчерпывающего анализа всей совокупности высказываний, и вовлечет лингвиста в довольно безнадежную попытку определить, сколько значений может иметь данная последовательность звуков.
9.2.5.
Существует еще одна принципиальная трудность, о которой необходимо упомянуть при рассмотрении всякого семантического подхода к фонематическим различиям. Можно поставить вопрос, какими являются значения, приписываемые различным (но тождественным по своему фонемному составу) индивидуальным знакам,— тождественными или только весьма сходными. Если верно последнее, то трудности определения фонемных различий усугубляются (и умножаются в силу неясности самого предмета) необходимостью определения тождества значения. Нам придется решать, когда два различных значения становятся достаточно близкими для того, чтобы считать их «одинаковыми». Если же мы останемся на той позиции, что приписанные значения всегда тождественны и что значение слова есть фиксированная и неизменная составляющая каждого его употребления, то нас с полным правом могут упрекнуть в логическом круге. Единственная возможность сохранить позицию состоит, по-видимому, в том, чтобы воспринимать значение индивидуального знака как «способ (или возможный способ) употребления индивидуальных знаков данного типа», как класс ситуаций, в которых они могут применяться, как тип ответа, который они обычно вызывают, или как что-нибудь еще в этом же роде. Однако трудно извлечь какую-нибудь пользу из такой концепции значения, не имея представления о типе высказывания. Таким образом, независимо от предыдущих возражений любая попытка объяснения фонематических различий в терминах семантики либо приводит к логическому кругу, либо основывается на различиях, устанавливаемых с гораздо большим трудом, чем те, которые мы пытаемся ими обосновать.
9.2.6.
Чем же объясняется в таком случае широкое распространение некоторых формулировок типа (117 I)? Я думаю, что причин две. Отчасти это следствие предположения, что семантический подход есть нечто непосредственно данное и что он слишком прост, чтобы его анализировать. Однако первая же попытка точного описания сразу же рассеивает эту иллюзию. Семантический подход к грамматическим понятиям требует такой же тщательной и детальной разработки, что и несемантический подход, причем он связан с весьма значительными трудностями.
Вторым источником таких формулировок, как (117, I), является, по-моему, смешение понятий «значение» и «ответ информанта». Так, можно встретить следующее толкование лингвистического метода: «При лингвистическом анализе мы определяем противопоставление форм экспериментально, с помощью разницы в ответах о значении»[58]. Мы видели в § 9. 2. 3, что при определении противопоставления с помощью ответов о значении сколько-нибудь прямым способом можно прийти к ложному выводу в очень многих случаях; если же попытаться избежать немедленно возникающих трудностей, то можно прийти к схеме столь сложной и требующей таких неоправданных допущений, что вряд ли кто-нибудь захочет ей следовать. Из § 9. 2. 5, кроме того, вытекает, что существуют, по-видимому, и еще более глубокие принципиальные трудности. Поэтому, понимая указанное утверждение буквально, мы обязаны отбросить его как неверное.
Если, однако, мы выбросим слово «значение» из данного утверждения, то получим вполне приемлемую ссылку на такие методы, как парный тест. Однако нет никаких оснований для того, чтобы считать получаемые при этом ответы семантическими в каком бы то ни было смысле[59] Можно было бы создать операционный тест для рифм, который бы показал, что bill и pill находятся друг с другом в иных отношениях, чем bill и ball. В этом тесте не было бы ничего семантического. Фонемное тождество есть, в сущности, совершенная рифма, и, таким образом, у нас нет больших оснований предполагать ненаблюдаемую семантическую реакцию в случае с bill—ball, а не в случае с bill—pill.
Странно, что те, кто возражает против того, чтобы лингвистическая теория базировалась на формулировках типа (117 I),. обвиняются в недооценке значения. На мой взгляд, наоборот, тот, кто предлагает какие-либо варианты (117 I), должен понимать «значение» так широко, чтобы любую реакцию на язык можно было называть «значением». Но принять подобную точку зрения — значит лишить понятие «значение» всякого интереса и значимости. Я думаю, что всякий, кто хочет сохранить выражение «изучение значения» как указание на важный аспект лингвистического исследования, должен отказаться от отождествления понятий «значение» и «реакция на язык», а вместе с этим и от таких формулировок, как (117 I).
9.2.7.
Невозможно, разумеется, доказать, что семантические понятия бесполезны в грамматике, точно так же как невозможно доказать непригодность любой другой системы понятий. Однако изучение таких предложений неизменно ведет к заключению, что, по-видимому, только на чисто формальной основе можно получить твердую базу для создания грамматической теории. Детальное рассмотрение каждой семантически направленной теории выходит за рамки данного исследования и не представляет интереса, однако мы можем коснуться некоторых очевидных примеров, противоречащих таким известным утверждениям, как (17).
О морфемах типа «to» в I want to go «Я хочу идти» или «пустом» слове «do» в Did he come? «Пришел ли он?» (ср. §7. 1) вряд ли можно сказать, что они имеют значение в каком бы то ни было независимом смысле, и представляется разумным допустить, что, исходя из независимой концепции значения, можно приписать значение некоторого рода таким неморфемам, как gl- в gleam, glimmer, glow[60]. Приведенные примеры противоречат утверждению (117 II), гласящему, что морфемы должны определяться как минимальные элементы, несущие значение. В § 2 мы изложили основания, вынуждающие нас отказаться от «семантической значимости» в качестве общего критерия грамматической правильности, что предлагается утверждением (117 III). Такие предложения, как John received a letter «Джон получил письмо» или The fighting stopped «Бой кончился», с очевидностью показывают несостоятельность утверждения (117 IV), гласящего, что грамматическое отношение подлежащее — сказуемое имеет «структурное значение» деятель — действие," если значение понимать как понятие, не зависимое от грамматики. Точно так же попытке A17 V) приписать какое-либо структурное значение вроде действие — цель отношению сказуемое — дополнение как таковому, противоречат такие предложения, как I will disregard his incompetence «Я пренебрегу его неосведомленностью» или I missed the train «Я опоздал на поезд». В противоположность A17 VI) мы можем описать условия, при которых «разделительное» предложение вида Everyone in the room knows at least two languages «Каждый в этой комнате знает по крайней мере два языка» может быть истинным, в то время как соответствующее пассивное At least two languages are known by everyone in the room «По крайней мере два языка известны каждому в этой комнате» ложно при обычном понимании этих предложений, например, если одно лицо в комнате знает только французский и немецкий языки, а другое — только испанский и итальянский. Это показывает, что даже более слабое семантическое отношение (фактическая эквивалентность) не сохраняется между активным и пассивным предложениями.
9.3.
Данные противоречащие примеры не должны, однако, заслонять от нас того факта, что существует поразительное соответствие между структурами и элементами, раскрываемыми с помощью формального грамматического анализа, с одной стороны, и специфических семантических функций — с другой. Ни одно из утверждений (117) не является вполне ложным; некоторые из них весьма близки к истине. Таким образом, ясно, что между формальными и семантическими моментами языка наблюдаются несомненные, хотя и неполные соответствия. Такая неполнота соответствий не дает нам возможности привлекать значение в качестве базы для грамматического описания[61]. Тщательный разбор каждой гипотезы, предлагающей исходить из значения, подтверждает это мнение и доказывает, что важные соображения и обобщения, связанные с лингвистической структурой, могут оказаться упущенными, если слишком строго следовать шатким семантическим ориентирам. Так, мы наблюдали, что отношение актив — пассив является как раз примером одного весьма общего и фундаментального аспекта лингвистической структуры. Сходство актива — пассива, утверждения — отрицания, утверждения — вопроса и других трансформационных отношений не выявилось бы с очевидностью, если бы отношение актив — пассив изучалось только посредством понятий синонимии.
Нельзя игнорировать, однако, существования соответствий между формальной и семантической сторонами. Эти соответствия должны изучаться в более общей теории языка, включающей в качестве составных частей теорию лингвистических форм и теорию использования языка. Из § 8 мы узнали, что существуют, по-видимому, весьма общие соотношения между этими двумя областями, заслуживающие интенсивного изучения. Определив синтаксическую структуру языка, мы можем исследовать, каким образом эта синтаксическая структура используется при реальном функционировании языка. Изучение семантических функций структуры уровней, кратко намеченное в § 8, может явиться разумным шагом к теории взаимоотношений между синтаксисом и семантикой. Фактически мы указали в § 8, что соотношение между формой и использованием языка может дать нам некоторые весьма общие критерии адекватности лингвистической теории и основанных на ней грамматик. Мы можем судить о достоинствах формальных теорий по их способностям объяснять и делать очевидными разнообразные факты, связанные с пониманием и использованием предложений. Другими словами, нам хотелось бы, чтобы синтаксический каркас языка, обнаруживаемый грамматикой, был способен поддержать семантическое описание, и мы, естественно, высоко оценим такую теорию формальной структуры, которая приведет нас к грамматикам, более полно удовлетворяющим этому требованию.
Структура непосредственно составляющих и трансформационная структура являются, очевидно, главными синтаксическими механизмами языка, предназначенными для организации и выражения содержания. Грамматика данного языка должна показать, как эти абстрактные структуры реализуются в данном языке, а лингвистическая теория должна попытаться объяснить их, а также методы оценки и выбора между предлагаемыми грамматиками.
Важно понять, что включение положений, подобных приведенным в § 8, в метатеорию, рассматривающую грамматику и семантику и точки их соприкосновения, не меняет чисто формального характера самой теории грамматической структуры. В § 3—7 мы очертили развитие некоторых фундаментальных лингвистических концепций в чисто формальных понятиях. Мы рассматривали проблему синтаксического исследования как проблему построения механизма, производящего заданную совокупность грамматически правильных предложений, и изучения грамматик, эффективно решающих эту задачу. Семантические понятия, такие, как референция (отношения), значимость и синонимия, не играли никакой роли в наших рассуждениях. Изложенная теория имеет, разумеется, серьезные пробелы. В частности, допущение, что множество грамматически правильных предложений задано в самом начале, является, очевидно, слишком сильным, а понятие «простоты», на которое мы ссылались в явной или скрытой форме, остается неразработанным. Однако ни упомянутые, ни иные недостатки развиваемой грамматической теории не могут, как я полагаю, быть преодолены или уменьшены путем построения теории на частично семантических основаниях.
Далее, в § 3—7 мы рассматривали язык в качестве орудия или средства, пытаясь описать его структуру и не ссылаясь на способы его применения. Это самоограничение требованием строгой формальности объясняется просто: никакой иной базы для развития строгой, эффективной и «наглядной» теории лингвистической структуры, видимому, не существует. Требование придать этой теории формальный характер вполне совместимо с желанием сформулировать ее таким образом, чтобы иметь определенные и значимые точки соприкосновения с параллельной семантической теорией. В § 8 мы указывали как раз на то, что формальное изучение структуры языка как орудия может, по нашему предположению, помочь нам понять фактическое употребление языка, т. е. процесс понимания предложений.
9.4.
Чтобы понять предложение, мы должны знать весьма многое, помимо разложения этого предложения на каждом из лингвистических уровней. Мы должны знать также референцию (отношения) и значение[62] морфем или слов, из которых предложение построено; естествен-
естественно, нельзя ожидать от грамматики большой помощи в этом деле. Указанные понятия составляют предмет семантики. При описании значения слова часто бывает выгодным или даже необходимым обращаться к синтаксическим аспектам, в которых это слово обычно выступает; например, при описании значения слова hit «ударить» мы, несомненно, должны описывать деятеля и объект действия в терминах «подлежащее» и «дополнение», которые, очевидно, лучше всего анализируются как чисто формальные понятия, относящиеся к теории грамматики[63].
Естественно, мы обнаруживаем, что очень многие слова и морфемы единой грамматической категории описываются семантически посредством частично сходных понятий, например глагол — посредством понятий подлежащего и дополнения и т. д. В этом нет ничего удивительного. Это означает, что синтаксические механизмы языка применяются в высокой степени систематически. Мы видели, однако, что выводить какие-то обобщения из такого систематического применения и приписывать «структурное значение» грамматическим категориям и конструкциям, подобно тому как приписываются «лексические значения» словам и морфемам, — шаг весьма шаткий.
Другое общеупотребительное, но сомнительное применение понятия «структурного значения» связано со значением так называемых «грамматически функционирующих» морфем типа ing, ly, предлогов и т. п. В подтверждение того положения, что значения указанных морфем коренным образом отличаются от значений существительных, глаголов, прилагательных и, вероятно, других больших классов, часто ссылаются на тот факт, что эти морфемы можно расставить в последовательности пробелов или бессмысленных слогов таким образом, чтобы получилась полная видимость предложения, т. е. фактически чтобы определились грамматические категории бессмысленных элементов. Например, в последовательности Pirots karulize elatically мы узнаем в первом, втором и третьем слове существительное, глагол и наречие по суффиксам s, ize и 1у соответственно. Однако это свойство не позволяет четко отграничить «грамматические» морфемы от иных, поскольку в таких последовательностях, как the Pirots karul — yesterday или give him — water, пробелы в первом случае также определяются как вариант прошедшего времени, а во втором — как the, some и т. п., но не а. Тот факт, что в этих случаях мы принуждены дать пробелы, а не бессмысленные слова, объясняется продуктивностью или «незамкнутостью» категорий существительного, прилагательного и т. п. в противоположность категориям артикля, глагольного аффикса и т. д. Вообще, расставляя последовательность морфем в последовательности пробелов, мы ограничиваем выбор элементов, которые можно поместить на пустых местах, с тем чтобы получилось грамматически правильное предложение. Какие бы различия относительно этого свойства ни существовали между морфемами, они, очевидно, лучше объясняются посредством таких грамматических понятий, как продуктивность, свобода сочетания или объем субституционных классов, чем с помощью каких-либо предполагаемых особенностей значений.
10. ИТОГИ
В наших рассуждениях мы стремились подчеркнуть следующие моменты. Самое большее, чего можно требовать от лингвистической теории, это чтобы она давала метод выбора грамматик. Теорию лингвистической структуры следует четко отличать от руководства, содержащего полезные эвристические процедуры для открытия грамматик, хотя подобное руководство, несомненно, основывается на результатах лингвистической теории, и попытки составить такое руководство окажутся, вероятно (как это случалось и в прошлом), существенным вкладом в развитие лингвистической теории. Если принять данную точку зрения, то у нас не будет оснований возражать против смешения уровней, считать элементы высшего уровня построенными буквальным образом из элементов низшего и полагать, что синтаксическое исследование преждевременно, пока не решены все проблемы фонологии и морфологии.
Грамматику лучше всего определять как самостоятельное исследование, не зависящее от семантики. В частности, понятие грамматической правильности нельзя отождествлять с осмысленностью (а также ставить в какую бы то ни было определенную, пусть даже приблизительную связь с понятием порядка статистической аппроксимации). В ходе такого независимого и формального исследования мы обнаруживаем, что простая модель языка, представляющая его в виде марковского процесса с конечным числом состояний, при котором предложения порождаются слева направо, неприемлема и что для описания естественных языков необходимы такие весьма абстрактные лингвистические уровни, как уровень анализа по непосредственно составляющим и трансформационный уровень.
Мы можем сильно упростить описание английского языка и сделать новый и важный шаг к проникновению в его формальную структуру, если ограничим область прямого описания (в терминах анализа по непосредственно составляющим) ядром основных предложений (простых, повествовательных, активных предложений без сложных глагольных или именных групп) и будем выводить все остальные предложения из предложений ядра (точнее, из цепочек, лежащих в их основе) посредством трансформаций, возможно, повторных. Обратно, получив систему трансформаций, переводящих грамматически правильные предложения в грамматически правильные предложения, мы можем определить структуру составляющих отдельных предложений, исследуя их поведение при этих трансформациях в случае иного разложения на непосредственно составляющие.
Мы рассматриваем, таким образом, грамматику как систему, имеющую трехчастное строение. Грамматика включает ряд правил, с помощью которых можно воссоздать структуру " непосредственно " составляющих, и ряд морфофонемных правил, обращающих цепочки морфем в цепочки фонем. В качестве связующего звена имеется ряд трансформационных правил, переводящих цепочки структуры непосредственно составляющих в цепочки, к которым приложимы морфофонемные правила. В некотором определенном смысле правила структуры непосредственно составляющих и морфофонемные правила являются элементарными, а трансформационные — нет. Для применения трансформации к цепочке необходимо знать нечто об истории ее деривации; в случае же нетрансформационных правил достаточно знать лишь форму цепочки, к которой они применяются.
По-видимому, нерегулярное поведение некоторых слов (например, have, be, seem) в действительности представляет собой случай регулярности более высокого уровня. Этот факт явился автоматическим следствием из попытки построить простейшую грамматику английского языка с помощью абстрактных уровней, выработанных лингвистической теорией. Мы обнаружили также, что многие предложения имеют двоякие представления на определенном уровне и многие пары предложений имеют сходные или тождественные представления на определенном уровне. В значительном числе случаев двоякое представление (конструкционная омонимия) соответствует двусмысленности представляемого предложения, а сходное или тождественное представление имеет место в случаях интуитивно воспринимаемого сходства высказываний.
Вообще, по нашему мнению, понятие «понимание предложения» можно частично анализировать с помощью грамматических понятий. Чтобы понять предложение, необходимо (хотя, разумеется, недостаточно) воссоздать его представление на каждом из уровней, включая трансформационный уровень, где предложения ядра, лежащие в основе данного предложения, могут восприниматься в некотором смысле в качестве «элементарных элементов содержания», из которых предложение построено. Другими словами, один из результатов формального изучения грамматической структуры состоит в том, что выявляется синтаксический каркас, способный подкрепить семантический анализ. При описании значения можно с успехом обращаться к этому глубинному синтаксическому каркасу, хотя систематические семантические соображения, по-видимому, бесполезны для его первоначального определения. Однако понятие «структурного значения» в противоположность «лексическому значению» представляется весьма подозрительным, и сомнительно, чтобы грамматические механизмы, действующие в языке, использовались с достаточной последовательностью так, чтобы им можно было непосредственно приписать значение. Тем не менее мы находим, разумеется, многие важные соотношения между синтаксической структурой и значением; другими словами, мы обнаруживаем, что грамматические механизмы используются весьма систематично. Эти соотношения могут стать частью предмета более общей теории языка, рассматривающей синтаксис и семантику и точки их соприкосновения.
11. Приложение I ОБОЗНАЧЕНИЯ И ТЕРМИНОЛОГИЯ
В этом приложении мы кратко перечислим все новые или малоизвестные обозначения и термины, которыми мы пользовались.
Лингвистический уровень есть метод представления высказываний. Он имеет конечный словарь символов (на фонемном уровне мы называем этот словарь алфавитом языка), которые могут располагаться в линейной последовательности, образуя цепочки символов посредством операции, называемой сцеплением и обозначаемой +. Так, в английском языке на уровне морфем мы имеем элементы словаря the, boy, S, past, come и т. д. и можем образовать цепочку the+boy+S+come+past (которая посредством морфофонемных правил будет превращена в цепочку /diboyz#keym/), представляющую высказывание The boys came. На всех уровнях, кроме фонемного, мы пользовались курсивом для выделения символов словаря и цепочек представляющих символов. На уровне фонем мы опускаем символ сцепления и используем обычные косые скобки, как в приведенном примере. Буквы X, Y, Z, W обозначают переменные в цепочках.
В некоторых случаях для обозначения сцепления мы применяем тире вместо знака плюс. Это делается, чтобы привлечь особое внимание к тому подразделению высказывания, которым мы конкретно занимаемся в данный момент. Ни один из этих приемов обозначения не употребляется систематически; они вводятся лишь для ясности изложения. При рассмотрении трансформаций знаки тире указывают на подразделение цепочки, предполагаемое определенной трансформацией. Так, если мы утверждаем, что вопросительная трансформация Tq применима, в частности, к цепочке типа
(118) NP—have—en+V (cp, (37 III)),
в которой благодаря ей два первых сегмента меняют места, то имеется в виду, что она применима, например, к
(119) They—have—en+arrive,
поскольку в этой цепочке they есть NP, a arrive есть V.
Трансформом в таком случае будет:
(120) Have—they—en+arrive,
или окончательно,Have they arrived?
Правило X—>Y должно пониматься как команда «подставить Y вместо X», где X и Y — цепочки. Круглые скобки мы используем для того, чтобы показать, что элемент может появиться, а может и не появиться, а фигурные скобки (или перечисление) — для .указания на выбор между элементами.
Так, правила (121 I) и (121 II)
(121) (I) a—>b(с)
(II) a—>{b+c / b}
являются каждое сокращением двоякой возможности: a—>b+c, a—>b.
В нижеследующем списке указаны страницы, на которых первый раз появляются еще некоторые специальные символы, кроме упомянутых выше.
(122) NP стр. 431
VP стр. 431
Т стр. 431
N стр. 431
NPsing стр. 433
NPpl стр. 433
[Σ,F] стр. 434
Aux стр. 445
V стр. 445
С стр. 445
М стр. 445
en стр. 445
S стр. 445
0 стр. 445
past стр. 445
Af стр. 445
# стр. 445
А стр. 472
wh стр. 478,прим.40
Adj стр. 481
РР стр. 483
Prt стр. 485
Comp стр. 487
12. Приложение II ПРИМЕРЫ ПРАВИЛ МОДЕЛИ НЕПОСРЕДСТВЕННО СОСТАВЛЯЮЩИХ И ТРАНСФОРМАЦИОННОЙ МОДЕЛИ ДЛЯ АНГЛИЙСКОГО ЯЗЫКА
Для облегчения ссылок мы сводим здесь примеры правил английской грамматики, играющих важную роль в наших рассуждениях. Цифры слева показывают надлежащий порядок этих правил при предположении, что настоящая схема является наброском грамматики вида (35). В скобках справа от каждого правила стоят их порядковые номера в тексте. Некоторые правила, видоизменены по сравнению с их формой в тексте в свете последующего рассмотрения, а также для придания схеме большей систематичности.
Модель непосредственно составляющих
Σ: #Sentence#
F: 1. Sentence—>NP+VP (13 I)
2. VP—>Verb+NP (13 III)
3. NP—>{NPsing / NPpl} (стр- 433) прим. 15)
4. NPsing—>T+N+0 (стр. 433, прим. 15)
5. NPpl—>T+N+S (стр. 433, прим. 15)
6. T—>the (13 IV)
7. N—>man, ball и т.д. (13 V)
8. Verb—>Aux+V (28 I)
9. V—>hit, take, walk, read и т. д. (28 II)
10. Aux—>C{M) (have+en), (be+ing) (28 III)
11. M—>will, can, may, shall, must (28 IV)
Трансформационная модель
Трансформация определяется структурным разложением цепочек, к которым она применима, и структурными изменениями, которые она производит в этих цепочках.
12. Пассивная (возможная)
Структурное разложение: NP—Aux—V—NP
Структурное изменение: Х1—Х2—X3—Х4—>Х4—Х2+be+en—X3—by+Х1
13. Тobsep (обязательная)
Структурное разложение: {X—V1—Prt—Pronoun (86) / X—V2—Comp—NP (92)}
Структурное изменение: Х1—Х2—X3—Х4—> Х1—Х2—X4—Х3
14. Тopsep (возможная)
Структурное разложение: X—V1—Prt—NP (85)
Структурное изменение; то же, что и 13
15. Число (обязательная)
Структурное разложение: X—С—Y
Структурное изменение: {S в контексте NPsing— / 0 в иных контекстах / past в любом контексте} (29 I)
16. Tnot (возможная)
Структурное разложение: {NP—C—V… / NP—С+М—… / NP—С+have—… / NP—С+be—…} (37)
Структурное изменение: Х1—Х2—X3—>Х1—Х2+n't—X3
1 7. ТA (возможная)
Структурное разложение: то же, что и 16 (ср. (45)-(47))
Структурное изменение: Х1—Х2—X3—>Х1—Х2+A—X3
18. Tq (возможная)
Структурное разложение: то же, что и 16 (ср. (41)-(43))
Структурное изменение: X1—Х2—Х3—>Х2—X1—Х3
19. Tw (возможная и условная по отношению к Tq)
TW1: Структурное разложение: X—NP—Y (X или Y может быть нулем)
Структурное изменение: то же, что и 18 (60 I)
TW2: Структурное разложение: NP—X (60 II)
Структурное изменение: X1—Х2—>wh+X1—Х2,
где wh+одушевл. сущ.—>who (ср. стр. 478,прим. 40)
wh+неодушевл. сущ.—>what
20. Aux (обязательная)
Структурное разложение: X—Af—v—Y
(где Af есть любое С либо en или ing; v — любое М либо V или have либо be) (29 II)
Структурное изменение: Х1—Х2—X3—Х4—>Х1—Х3—X2#—Х4
21. Граница слова (обязательная)
Структурное разложение: X—Y (где Х=/=v или Y=/=Af) (29 III)
Структурное изменение: Х1—Х2—>Х1—#Х2
22. do (обязательная)
Структурное разложение: #—Af (40)
Структурное изменение: Х1—Х2—>Х1—do+Х2
Обобщенные трансформации
23. Сочинение (26) Структурное разложение: S1 : Z—X—W
S2 : Z—X—W,
где X — минимальный элемент (например, NP, VP и т.п.), a Z и W — сегменты терминальных цепочек.
Структурное изменение: (Х1—Х2—Х3;Х4—X5—Х6)—>Х1—X2+and+Х5—X3
24. Тso (48)—(50)
Структурное разложение:S1: как 16; S2 : как 16
Структурное изменение: (Х1—Х2—Х3;Х4—X5—Х6)—>Х1—X2—X3+and+so+Х5—X4
Tso фактически соединена с трансформацией сочинения.
25. Номинализация — Tto (стр. 481, прим. 41)
Структурное разложение: S1: NP—VP; S2: X—NP—Y (X или Y может быть нулем)
Структурное изменение: (Х1—Х2;Х3—Х4—X5)—>X3—to+Х2—X5
26. Номинализация Ting (стр. 481, прим. 41)
То же, что и 24, с заменой to на ing.
27. Номинализация — ТAdj (71)
Структурное разложение: S1: Т—N—is—А; S2 так же, как 24
Структурное изменение: (Х1—Х2—Х3—Х4;X5—Х6—Х7)—>Х5—X1+X4+X2—X1
Морфофонемная структура
Правила (19); (45); стр. 466, прим. 36; стр. 478, прим. 40, и т. д.
Мы имеем, таким образом, согласно (35), три набора правил: правила модели непосредственно составляющих, трансформационные правила (включая простые и обобщенные трансформации) и морфофонемные правила. Порядок применения правил является существенным, и в надлежащим образом сформулированной грамматике он должен быть указан во всех трех разделах наряду с различением обязательных и возможных правил, а также (по крайней мере в трансформационной части) с установлением условных зависимостей между правилами. Результат применений всех этих правил представляет собой расширенную деривацию (типа (13)—(30)—(31)), оканчивающуюся цепочкой фонем анализируемого языка, т. е. грамматически правильным высказыванием. Мы смотрим на такую формулировку трансформационных правил не более как на повод к размышлению. Нами не разработан аппарат для представления всех этих правил в подходящей и единообразной форме. Более подробную разработку и данные о применении трансформационного анализа можно найти в литературе, указанной на стр. 451 в примечании 25.
Примечания
1
См. Noam Chomsky, Syntactic Structures, s’-Gravenhage 1957.
(обратно)2
Обоснование такого характера нашего исследования будет
изложено ниже, в § 6.
(обратно)3
Ср., например, N. Goodman, The structure of appearance, Cambridge, 1951, p. 5—6.
Заметим, что для достижения целей грамматики при наличии лингвистической теории достаточно частичного знания предложений (т. е. знания только наблюденных предложений) языка, поскольку лингвистическая теория устанавливает соотношение между множеством наблюденных предложений и множеством грамматически правильных предложений; другими словами, она определяет «грамматически правильное предложение» через понятие «наблюденное предложение», а также через некоторые свойства наблюденных предложений и некоторые свойства грамматик. Согласно формулировке Куайна, лингвистическая теория дает общее объяснение тому, что «должно» быть в языке на базе «того, что есть плюс простота законов, посредством которых мы описываем и экстраполируем то, что есть». (W. V. Q u i n e, From a logical point oi view, Cambridge, 1953, p. 54; cp. §6.1.)
(обратно)4
4 Ниже мы покажем, что это четкое различение можно уточнить с помощью понятия уровня грамматической правильности. Однако это не влияет на сказанное здесь. Так, A) и B) оказываются на разных уровнях грамматической правильности, даже если приписать A) меньшую степень грамматической правильности, чем, скажем, C) и D), но они находятся на одинаковом уровне статистической удаленности от английского языка. То же справедливо и в отношении бесконечного числа подобных пар.
(обратно)5
5 С. F. Hockett, A manual of phonology, Baltimore, 1955, p. 10.
(обратно)6
Мы вернемся к вопросу о связи между семантикой и синтаксисом в §§ 8, 9, где будем утверждать, что эту связь можно исследовать после того, как на независимых основаниях будет установлена синтаксическая структура. Я думаю, что то же самое верно и в отношении связи между синтаксисом и статистическим изучением языка. Зная грамматику языка, можно статистически исследовать использование языка различными способами; при этом разработка вероятностных моделей использования языка (отличных от моделей синтаксической структуры языка^ может дать весьма ценные результаты. Ср. В. Mandelbrot, Structure formelle des textes et communication: deux etudes, «Word», 10, 1954, p. 1—27; H. A. S i mon, On a class of skew distribution functions, «Biometrica», 42, 1955, p. 425—440.
Можно попытаться разработать более тонкую систему отношений между статистической и синтаксической структурой, чем отклоненная нами простая модель порядка статистического приближения. В мои намерения определенно не входит утверждать, что всякая такая система немыслима, но мне не известна ни одна гипотеза подобного рода, которая не стоадала бы очевидными изъянами. Заметим, в частности, что для любого п можно найти цепочку, первые п слов которой могут встретиться в качестве начала грамматически правильного предложения S,, а последние п — в качестве конца некоторого грамматически правильного предложения S,, но при stomS, отлично от S2. Для примера рассмотрим последовательность типа the man who... iff here «человек, который... находится здесь», где «...» может быть глагольной группой произвольной длины. Заметим также, что мы можем оперировать новыми, но вполне грамматически правильными последовательностями классов слов, например последовательностью прилагательных более длинной, чем любая до сих пор встречавшаяся в контексте: I saw а house «Я-видел дом». Разные попытки объяснить различия грамматически правильного и грамматически неправильного, как в случае с A), B), на базе частотности типов предложений, порядка приближения последовательностей классов слов и т. п. должны натолкнуться на многочисленные, подобные приведенным здесь факты.
(обратно)7
С. Е. Shannon and W. Weaver, The mathematical theory of communication, Urbana, 1949, p. 15f.
(обратно)8
Это, по существу, модель языка, развиваемая Хоккетом в «A Manual of phonology», Baltimore, 1955, 02.
(обратно)9
По-видимому, ошибка оригинала. Должно быть: «.., поставленному в начале настоящей главы».— Прим. перев.
(обратно)10
См. мою работу «Three models for the description of language», «I. R. E. Transactions on Information Theory», vol. IT-2 (Proceedings of the symposium on information theory, Sept., 1956), где устанавливаются такие условия и дается доказательство утверждения (9). Заметим, в частности, что множество правильно построенных формул любой формализованной теории математики или логики не представляет собой языка с конечным числом состояний в силу наличия парных скобок и других подобного рода ограничений.
(обратно)11
Третья возможность — сохранить понятие лингвистического уровня в качестве простого линейного метода представления, но при этом допустить, что хотя бы один такой уровень порождается слева направо посредством механизма более мощного, чем марковский процесс с конечным числом состояний. Концепция лингвистического уровня, основанная на порождении слева направо, настолько трудна как по сложности описания, так и ввиду недостатка объяснительной силы (ср. §8), что ее дальнейшее развитие представляется бесполезным. Грамматики, рассматриваемые нами ниже и не базирующиеся на порождении слева направо, также отвечают про-цессам менее элементарным, чем марковский процесс с конечным числом состояний. Однако они, по-видимому, менее сильны, чем тот тип механизма, который требуется для прямого порождения английского языка слева направо. Ср. мою работу «Three models for the description of language», где этот вопрос рассматривается более подробно.
(обратно)12
В подлиннике — «Phrase structure».— Прим. ред.
(обратно)13
Упорядоченный надлежащим образом список правил английской грамматики, на который мы будем постоянно ссылаться в дальнейшем, приведен в § 12; см. приложение 11. Список условных обозначений, используемых на протяжении всей книги, дан в § 11; см. приложение 1.
В своей работе «Axiomatic syntax: the construction and evaluation of a syntactic calculus», «Language», 31, 1955, p. 409—414 Харвуд описывает систему анализа классов слов, сходную по форме с системой, развиваемой ниже для модели непосредственно составляющих. Его система имеет дело только с соотношением между Т+N+Verb+T+N и the+man+hit+the+ ball (если взять пример, приведенный в (13)—(15)); это значит, что грамматика содержит «начальную цепочку» Т+N+Verb+T+N и правила вида (13 IV—VI). Она является, следовательно, более слабой, чем элементарная теория, рассмотренная в § 3, поскольку она не в состоянии порождать бесконечный язык с помощью конечной грамматики. В то время как формальный подход Харвуда (см. стр. 409—411) относится лишь к анализу классов слов, его лингвистическое приложение (см. стр. 412) является случаем анализа по непосредственно составляющим, где классы Ci...m являются предположительно классами последовательностей слов. Это расширенное толкование, однако, не вполне совместимо с указанным формальным подходом. так, например, при таком измененном толковании ни одна из предложенных мер адекватности не остается справедливой без пересмотра.
(обратно)14
См. § 8.1, где приводятся некоторые примеры конструкциноной омонимии. См. также мои работы «Fhe logical structure of linguistic theory» (мимеографическое издание); «three models for the description of language» (см. выше, стр. 426, прим. 10); С. F. Носkett, Two models of grammatical description, «Linguistics Today»=«Word», 10,1954, p. 210—233; R. S. Wells, Immediate constituents, «Language», 23, 1947, p. 81 —117, где приводятся подробности.
(обратно)15
Так, в более полной грамматике правила (13 II) можно заменить следующей совокупностью правил:
NP—>{NРsing / NPpl}
NРsing—>Т+N+0 (+ Prepositional Phrase „Предложная группа")
NPpl—>T+N+S (+Prepositional Phrase „Предложная группа"),
где S — морфема, выражающая единственное число для глаголов и множественное число для существительных (comes «приходит», boys «мальчики»), а 0 — морфема, выражающая единственное число для существительных и множественное для глаголов (boy «мальчик», come «приходят»). В данной работе мы повсюду опускаем упоминания о первом и втором лице. Отождествление аффикса числа существительного и глагола представляет сомнительную ценность.
(обратно)16
См. мою работу «Three models for the description of language» (см. выше, стр. 426, прим. 10), где приводится доказательство этой и других теорем, касающихся сравнительной силы грамматик.
(обратно)17
Здесь выражение «есть» представляет отношения, которые определяются схемой типа A5); см. § 4.1.
(обратно)18
См. мою работу «The logical structure of linguistic theory», где приводится детальный анализ этой проблемы.
(обратно)19
(21) и (23) — крайние случаи, в которых возможность или невозможность сочинения не подлежит сомнению. Есть много менее ясных случаев. Очевидно, например, что John enjoyed the book and liked the play «Джон ценил книгу и любил игру» (цепочка вида NP—VP+and+VP) — вполне правильное предложение, однако многие усомнятся в грамматической правильности, например, такого предложения, как John enjoyed and my friend liked the play «Джон ценил, а мой друг любил игру» (цепочка вида NP+Verb+and+NP+Verb—NP). Последнее предложение, в котором сочинение простирается за границы составляющих, гораздо менее естественно, чем John enjoyed the play and my friend liked it «Джон ценил игру, а мой друг любил ее»; но нет необходимости предпочесть какое-либо другое предложение первому. Подобные предложения с сочинением, пересекающим границы составляющих, вообще говоря, отмечаются также характерными фонетическими признаками вроде особенно длинных пауз (в нашем примере — между liked и the), подчеркивающей интонации, отсутствия редукции гласных и выпадения согласных в беглой речи и т. п. Такие явления наблюдаются при чтении грамматически неправильных последовательностей. Наиболее рациональный способ описания таких ситуаций, по-видимому, следующий: чтобы образовать вполне грамматически правильное предложение посредством сочинения, нужно сочинять отдельные составляющие; при сочинении пар составляющих, образующих составляющие более высокого ранга (т. е. «следующую инстанцию» в схеме (15)), получаются грамматические полуправильные предложения; чем больше мы нарушаем структуру составляющих при сочинении, тем менее грамматически правильные предложения мы получаем. Это заключение требует обобщения понятия грамматической правильности (которое до сих пор предполагало лишь две возможности: да — нет) путем введения понятия степени грамматической правильности. Для нашего рассмотрения несущественно, однако, решим ли мы исключить такие предложения, как John enjoyed and my friend liked the play из числа грамматически правильных или включим их в число грамматически полуправильных, либо в число вполне грамматически правильных, но со специальными фонетическими признаками. В любом случае они составляют класс высказываний, отличных от John enjoyed the play and liked the book «Джон ценил игру и любил книгу» и т. п., где структура составляющих полностью сохранена, и, следовательно, наш вывод о необходимости обращения к структуре составляющих в правиле сочинения остается в силе, поскольку это различие должно быть отражено в грамматике.
(обратно)20
Мы вернемся к акцентированному вспомогательному глаголу do ниже, в §7.1 (45)—(47).
(обратно)21
Здесь предполагается, что A3 II) обобщено в духе прим. 15 на стр. 433 или чего-то подобного.
(обратно)22
При более тщательной формулировке теории грамматики знак # мы интерпретировали бы как оператор сцепления на уровне слов, в то время как знак + обозначает оператор сцепления на уровне непосредственно составляющих. Тогда B9) стало бы частью определения механизма, переводящего определенные объекты уровня непосредственно составляющих (по существу — схемы вида (15)) в цепочки слов. См. мою работу «The logical structure of linguistic theory», где дается более точная формулировка.
(обратно)23
Можно попытаться обобщить понятия, относящиеся к уровню непосредственно составляющих, с тем, чтобы объяснить разрывы. Неоднократно указывалось, однако, что при всякой снстематической попытке следовать этому курсу возникают весьма серьезные трудности. Ср. мою работу «System of syntactic analysis» в «Journal of Symbolic Logic», 18, 1953, p. 242—256; С F.Hосkett, A formal statement of morphemic analysis, «Studies in Linguistics», j10, 1952, p. 27—39; его же, «Two models of grammatical description», «Linguistics Today», «Word», 10, 1954, p. 210—233. Подобным образом можно попытаться восполнить некоторые другие недостатки (Σ,F)-грамматик путем более сложного описания структуры непосредственно составляющих. Я думаю, однако, что этот путь порочен и может привести лишь к эмпиричным и бесплодным осложнениям. По-видимому, понятия грамматики непосредственно составляющих вполне адекватны лишь небольшой части языка и что все прочее в языке можно вывести путем повторного применения довольно простой совокупности трансформаций к цепочкам, полученным как продукт грамматики непосредственно составляющих. Если бы мы попытались обобщить последнюю так, чтобы она непосредственно покрывала весь язык, мы потеряли бы простоту, присущую соединению ограниченной грамматики непосредственно составляющих с ее трансформационным развитием. В этом подходе отсутствовала бы главная черта построений, основанных на понятии уровня (ср. начало §3.1) и состоящая в том, чтобы более изящно и систематически реконструировать реальный язык во всей его сложности, определяя взаимодействие уровнен, которые сами по себе являются простыми.
(обратно)24
И здесь мы могли бы использовать понятие степени грамматической правильности, введенного в прим. 19 на стр. 440—441. Например, предложение Sincerity admires John «Искренность восхищается Джоном», хотя и явно менее грамматически правильное, чем John admires sincerity «Джон восхищается искренностью», все же несомненно более грамматически правильное, чем of admires John. Я полагаю, что пригодное для работы понятие степени грамматической правильности можно выработать на чисто формальной основе (ср. мою работу «The logical structure of linguistic theory»), однако это выходит за рамки данной работы. См. § 7.5, где показано более четко, что инверсия необходима в пассиве.
(обратно)25
См. мою работу «Three models for the description of language» (см. выше, стр. 426, прим. 10), в которой приводится краткое изложение трансформаций, а также «The logical structure of linguistic theory» и «Transformational analysis», где дана детальная разработка трансформационной алгебры и трансформационных грамматик. Ср. Z. S. Harris, Transformations in linguistic analysis, где мы встречаем несколько иной подход к трансформационному анализу.
(обратно)26
Правда, из трех частей (29 I) обязательна лишь третья. Это означает, что past может выступать как после NPsing, так и после NPpl. Всякий раз, когда мы имеем элемент типа С в (29 I), который должен быть развернут, что можно сделать несколькими различными способами, мы можем установить очередность и сделать все случаи, кроме последнего, факультативными, последний же — обязательным.
(обратно)27
Ср. «The logical structure of linguistic theory» и «Transformational analysis».
(обратно)28
Пусть G есть [Σ,F]-грамматика с начальной цепочкой Sentence и множеством всех конечных иепочек из букв а и b в качестве терминального выхода. Такая грамматика существует. Если G' есть грамматика, включающая G как одну из своих частей на уровне непосредственно составляющих, и если она дополняется трансформацией Т, применяемой к любой цепочке K, служащей предложением,, превращая ее в К+К, то на выходе G' мы будем иметь (10 III).
(обратно)29
Предполагается, что эти два условия соответствуют тому, что имел в виду Ельмслев, говоря о пригодности и произвольности лингвистической теории. Ср. L. Hjelmslev, Prolegomena to a theory of language (Memoir 7, Indiana University Publications in Anthropology and Linguistics), Baltimore, 1953, p. 8 [в переводе на русский см. «Новое в лингвистике», вып. 1, Изд-во иностранной лит-ры, М., 1960, стр. 275. —Прим. ред.]; в этой связи см. также рассужление Хоккета о «метакритериях» в лингвистике («Two models of grammatical description», «Linguistics Today» = «Word», 10,p. 232—233).
(обратно)30
Основная проблема не изменится, если мы захотим взять небольшое множество правильных грамматик вместо одной.
(обратно)31
См., например, В. Вlосh, A set of postulates for phonemic analysis, «Language», 24, 1948, p. 3—46; N. Chomsky, Systems of syntactic analysis, «Journal of Symbolic Logic», 18, 1953, p. 242—256; Z. S. Harris, From phoneme to morpheme, «Language», 31, 1955, p. 190—222; e г о ж е, Methods in structural linguistics, Chicago, 1951; C. F, Hockett, A formal statement of morphemic analysis, «Studies in Linguistics», 10, 1952, p. 27—39; его же, Problems of morphemic analysis, «Language», 23, 1947, p. 321—343; R..S. Wells, Immediate constituents, «Language», 23, 1947, p. 81 — 117, и многие другие работы. Хотя явной целью этих, работ являются процедуры открытия, мы часто обнаруживаем при тщательном рассмотрении, что теория, которая в действительности построена, дает всего лишь процедуру выбора грамматик. Так, например, Хоккет считает своей задачей в «A formal statement of morphemic analysis» разработку «формальных процедур, с помощью которых можно идти от стартовой черты до полного описания системы языка» (стр. 27); но реально он лишь описывает некоторые из формальных свойств морфологического анализа, а затем предлагает «критерий, с помощью которого можно определить относительную эффективность возможных морфологических решений; пользуясь им, можно выбрать максимально эффективный вариант либо несколько вариантов, равно эффективных, но более эффективных, чем все прочие» (стр. 29).
(обратно)32
Лингвистическая теория формулируется, таким образом, на языке, который является метаязыком по отношению к языку, на котором написаны грамматики, и на метаметаязыке по отношению к языку, для которого построена грамматика.
(обратно)33
В действительности в ходе исследования мы можем пересмотреть также критерии адекватности. Это значит, мы можем решить, что некоторые из соответствующих испытаний не применимы к грамматическим явлениям. Предмет теории не вполне определен в начале исследования. Он определяется частично в меру возможности дать организованное и систематическое описание некоторой области явлений.
(обратно)34
См. мою работу «The logical structure of linguistic theory», где рассматриваются методы оценки грамматик в терминах формальных свойств простоты. Мы не отрицаем в данном конкретном случае полезности даже частично адекватных процедур построения. Они могут дать лингвисту-практику ценное вспомогательное средство, а также привести к небольшому набору грамматик, среди которых затем можно выбрать лучшие. Существо нашей позиции заключается в том, что лингвистическая теория не должна отождествляться со справочником полезных процедур и не следует ожидать от нее, что она предоставит нам автоматические процедуры открытия грамматик.
(обратно)35
См. Z. S. Наггis, Methods in structural linguistics, Chicago, 1951 (напр., Приложение к 7.4, Приложение к 8.2, гл. 9, 12), где приводятся примеры процедур, ведущих к взаимозависимым уровням. Я думаю, что возражение Фаулера против морфологических процедур Хэрриса (ср. «Language», 28, 1952, р. 504—509) можно без труда опровергнуть, если сформулировать, не впадая в круг, предложенную здесь процедуру. Ср. С. F. Носkett, A manual of phonology (Memoir 11, Indiana University Publications в «Anthropology an Linguistics»), Baltimore, 1955; eго же, Two fundamental problems in phonemics, «Studies in Linguistics», 7, 1949, p. 33; R. Jаkоbsоn, The phonemic and grammatical aspects of language and their interrelation (Proceedings of the Sixth International congress of linguists, 5—18, Paris, 1948); K. L. Pike, Grammatical prerequisites to phonemic analysis, «Word», 3, 1947, p. 155—172; его ж е, More on grammatical prerequisites, «Word», 8, 1952, p. 106—121, где обсуждается проблема взаимозависимости уровней. См. также N.Chomsky, М. Нalle, F. Lukoff, On accent and juncture in English («For Roman Jakobson», 's-Gravenhage, 1956, p. 65—80).
Бар-Хиллел утверждает в «Logical syntax and semantics» (см. «Language», 30, 1954, p. 230—237), что предложения Пайка можно формализовать с помощью рекурсивных определений. Он не обосновывает этого утверждения подробно; что до меня, то я считаю, что этот путь вряд ли приведет к успеху. Кроме того, если удовлетвориться процедурой выбора грамматик, то можно построить взаимозависимые уровни, пользуясь только прямыми определениями, как мы только что видели.
Проблему взаимозависимости фонемного и морфемного уровней не следует смешивать с вопросом о том, необходима ли морфологическая информация для того, чтобы читать фонемную транскрипцию. Даже если считать морфологические соображения имеющими отношение к определению фонем языка, может тем не менее оказаться, что фонемная транскрипция дает полный набор «правил чтения» вне зависимости от других уровней. Ср. N. Сhоmskу, М. Halle, F. Lukоff , On accent and juncture in English («For Roman Jakobson», 's-Gravenhage, 1956, p. 65—80), где рассматривается этот вопрос и приводятся примеры.
(обратно)36
Хоккет дает весьма ясное изложение этого подхода к уровням в «A manual of phonology», 1955, p. 15. В «Two models of grammatical description» (см. «Linguistics 1 odayx=«'Word», 10, 1954,p. 210—233) Хоккет отбрасывает решение, весьма сходное с тем, которое только что было предложено, на том основании, что «took и take частично сходны по фонемному виду, точно так же как baked и bake; они сходны также по значению; этого факта нельзя упускать из виду» (стр. 224). Но сходство значений не упускается из виду при нашей формулировке, поскольку морфема past налицо в морфемном представлении как слова took «взял», так и слова baked «пек». Сходство фонемного вида также может быть обнаружено при данной формулировке морфсфонемного правила, которое превращает take+past в /tuk/. Без сомнения, в реальной морфемной системе мы сформулируем это правило в виде:
ey —> u в контексте t—k+past.
Это позволит нам упростить грамматику посредством обобщения, которое обнаружит параллели между take «взять» — took «взял», shake «трясти» — shook «тряс», forsake «покинуть» — forsoo к «покинул» и в более общем случае между stand «стоять» — stood «СТОЯЛ» и т. п.
(обратно)37
См. N. Сhоmskу, М. Halle, F. Luкоff, On accent and juncture in English («For Roman Jakobson», 's-Gravenhage, 1956, p. 65—80), где рассматриваются явления на всех высших уровнях (включая ' морфологию, непосредственно составляющие и трансформации), связанные с выбором того или иного фонемного анализа.
(обратно)38
88 См. литературу, указанную в прим. 25, где более детально рассматриваются общие вопросы определения трансформаций и определяются некоторые конкретные трансформации.
(обратно)39
Примеры, представляющие собой грамматически неправильные выражения, переводу не поддаются.— Прим. перев.
(обратно)40
Проще говоря, можно ограничить применение Tw к цепочкам X—NP—Y, где NP есть he, him или it, и определить TW2 как трансформацию, обращающую любую цепочку Z в wh+Z, где wh есть некоторая морфема. Соответственно, в морфофонемике английского языка необходимы правила: wh+he—>/huw/, wh+him—>/huwm/, wh+it—>7wat/.
(обратно)41
Эта номивализующая трансформация может быть представлена в виде обобщенной трансформации типа B6). Она воздействует на пару предложений, одно из которых она превращает из NP—VP в to+ VP (или ing+VP), куда затем подставляется NP второго предложения. См. мои работы «The logical structure of linguistic theory» и «Transformational analysis», где дается подробное изложение данного вопроса.
(обратно)42
В оригинале ошибочно сказано G3).— Прим. перев.
(обратно)43
Т. е. две цепочки (одна из которых входит в грамматику непосредственно составляющих, а другая — результат некоторой трансформации), имеющие одинаковую модель непосредственно составляющих, рассматриваются как тождественные по отношению к следующей возможной трансформации.— Прим. перев.
(обратно)44
Дальнейшее исследование показывает, что все формы сочетания глагол + дополнение, вводимые правилом (91), сами могут быть исключены из ядра и выведены трансформационным способом из John is incompetent «Джон несведущ» и т. п. Но это сложный вопрос, требующий гораздо более детальной разработки трансформационной теории, чем та, которую мы можем осуществить здесь. Ср. мои работы «The logical structure of linguistic theory» и «Transformational analysis». Наблюдаются также и другие особенности этих конструкций (мы коснулись их лишь мимоходом). Вовсе не очевидно, например, что здесь налицо обязательная трансформация. В случае длинных и сложных дополнений мы можем получить предложение типа They consider incompetent anyone who is unable to... «Они рассматривают как несведущего всякого, кто неспособен...». Следовательно, для учета такого случая можно обобщить не Тopsep, а Тobsep. Интересно исследовать те особенности грамматического дополнения, которые делают эту трансформацию необходимой или невозможной. Длина здесь отнюдь не самое важное. Существуют также и другие возможности для пассивной трансформации, которые мы не можем рассмотреть здесь за недостатком места, хотя они и дают повод для интересного исследования.
(обратно)45
45 Согласование между a fool и John в (98) является, несомненно, подтверждением дальнейшего трансформационного разложения конструкции глагол -[-дополнение-{-именная группа, упомянутой, в прим. 44.
(обратно)46
При решении вопроса о том, какая из двух соотносимых форм является более центральной, мы придерживаемся рассуждения, изложенного Блумфилдом применительно к морфологии: «... если некоторые формы в чем-то подобны, может встать вопрос, какую из них выгоднее принять за исходную... сама структура языка может решить за нас этот вопрос, поскольку, приняв один из вариантов, мы получаем недопустимо сложное описание, а приняв другой — сравнительно простое». (См. «Language», New York, 1933, p. 218.) Блумфилд указывает далее, что «то же самое соображение часто заставляет нас задавать искусственную исходную форму». Мы также считаем это соображение применимым для трансформационного анализа, например в том случае, когда мы задаем терминальную цепочку John—С—have+en—be+ing—read, лежащую в огнове ядерного предложения John has been reading «Джон читал [и читает сейчас]».
(обратно)47
Здесь и ниже для двусмысленных выражений дается два перевода.— Прим. перев.
(обратно)48
Предложения примера (104) без выражений, заключенных в скобки,— результат применения второй, «эллиптической» трансформации, обращающей, например, The boy was seen by John «Этот мальчик был замечен Джоном» в The boy was seen «Этот мальчик был замечен:».
(обратно)49
Очевидно, не все виды двусмысленности поддаются анализу в пределах синтаксиса. Так, например, мы не должны ожидать от грамматики объяснения такой референциоиной двусмысленности, как son «сын» — sun «солнце», light (в значении цвета, веса) и т. п. В своей работе «Two models of grammatical description» «Linguistics Today»= «Word», 10, 1954, p. 210—233 Хоккет пользуется понятием структурной двусмысленности, чтобы показать независимость различных лингвистических понятий посредством метода, весьма близкого тому, который приводится здесь.
(обратно)50
Т.е. тем, что называется «конституентным показателем» в моих работах «The logical structure of linguistic theory» и «Three models for the descripition of language» (см. выше, стр. 426, прим. 20). Во второй из этих работ рассматривается конструкционная омонимия выражений they are flying planes в рамках грамматики непосредственно составляющих. Если присоединить к последней трансфомационную грамматику, то это выражение явится прмером трансфомационной двусмысленности а не конструкционной омонимии в пределах структуры непосредственно составляющих. В действительности не ясно, останется ли хотя бы один случай чистой конструкционной омонимии в пределах структуры непосредственно составляющих, если будет разработана трансфомационная грамматика.
(обратно)51
Справедливо, что (111) можно разложить двояко с употреблением shoot «стрелять» либо в качестве переходного, либо в качестве непереходного глагола, но существенным здесь является лишь то, что грамматическое отношение в (111) неоднозначно (т. е. hunters «охотники» может быть подлежащим или прямым дополнением). Грамматические отношения в рамках структуры непосредственно составляющих можно определять через форму схем типа (15) и т. п. Однако в этом плане нет оснований для утверждения, что в (111) следует искать либо отношение подлежащее — глагол, либо отношение глэгол — прямое дополнение. Если распределить глаголы по трем классам — переходные, непереходные и глаголы, могущие быть то теми, то другими,— то даже это (само по себе недостаточное) различие исчезает.
(обратно)52
Ср. прим. 41 на стр. 481.
(обратно)53
63 При более точном определении трасформационного анализа оказывается, что знания трансформационного анализа предложения (включая структуру непосредственно составляющих цепочек ядра, нз которых получено предложение) достаточно для определения производной структуры непосредственно составляющих трансформа.
(обратно)54
64 См. мою работу «Semantic considerations in grammar», «Monograph», No 8, 1955, p. 141 —153, где A17 I) рассматривается более подробно.
(обратно)55
Заметим, что нельзя утверждать, что bank в the river bank «берег реки» и bank в the savings bank «сберегательная касса»— два появления одного и того же слова, поскольку как раз этой требуется доказать. Заявлять, что два индивидуальных слова — суть появления одного и того же слова,— то же самое, что сказать, будто они не являются фонетически различными, и именно с этим, по-видимому, должен считаться критерий синонимии (117 I).
(обратно)56
Ср. мою работу «Semantic considerations of grammar»)B «Monograph», No 8, 1955, p. 141 — 154; M. Halle, The strategy of phonemics, «Linguistics Today»=«Word», 10, 1954, p. 197—209; Z. S. Harris, Methods in structural linguistics, Chicago, 1951, p. 32 f.; C.F. Hockett, A manual of phonology (Memoir 11, Indiana UniverUniversity Publications in Anthropology and Linguistics), Baltimore, 1955, p. 146).
(обратно)57
Лаунсбери в своем «A semantic analysis of the Pawnee kinship usage» в «Language», 32, 1956, p. 153—194 (особенно 190) утверждает, что апелляция к синонимии необходима для того, чтобы отличить свободные варианты от противопоставлений: «Если лингвист, не знающий английского языка, записывает с моего произнесения слово cat сначала с придыхательным смычным в исходе, а затем с непридыхательным имплозивным смычным в той же позиции, то он располагает недостаточными фонетическими данными, чтобы решить, противопоставляются ли эти формы. И только если он спросит меня, своего информанта, отличается ли значение первой формы от значения второй, и я отвечу, что не отличается, он сможет продолжать свой фонематический анализ». Как общий метод этот подход не выдерживает критики. Допустим, лингвист записывает /ekinamiks/ и /iykinamiks/, /vikstn/ и /fimeyl # faks/ и т. д. и спрашивает, различаются ли они по значению. Получив отрицательный ответ, он ошибочно приписывает им одинаковый фонемный состав, если придерживается этой позиции буквально. С другой стороны, имеется много носителей языка, не различающих в произношении metal и medal, хотя, если их спросить, они с уверенностью скажут, что делают это. Ответы таких информантов на прямые вопросы Лаунсбери относительно значения только запутают дело.
Можно сделать позицию Лаунсбери более приемлемой, заменив вопрос: «Имеют ли они одно и то же значение?» вопросом: «Являются ли они одним и тем же словом?» Таким образом, мы избежим ловушек, связанных с не относящимися к существу дела вопросами семантики. Однако вопрос в такой форме вряд ли приемлем, поскольку он сводится к тому, что информант должен решать за лингвиста; он подменяет операционный тест относительно поведения информанта (вроде парного теста) суждением информанта о своем поведении. Операционные тесты относительно лингвистических представлений могут требовать ответа информанта, но отнюдь не выражения им мнения о своем поведении, его суждения о синонимии, о фонематических различиях и т. п. Мнения информанта могут основываться на всякого рода посторонних факторах. Это важное различение следует тщательно соблюдать, если мы не хотим упрощенного понимания экспериментальной основы грамматики.
(обратно)58
F. Lounsbury, A semantic analysis of the Pawnee kinship usage, «Language», 32, 1956, p. 158—194 (особенно 191).
(обратно)59
Нас не должен вводить в заблуждение тот факт, что субъекта при парном тесте можно попросить распознать индивидуальные высказывания по значению. С тем же успехом его можно просить распознать их с помощью произвольно выбранных чисел, с помощью знаков зодиака и т. п. Ту или иную частную формулировку парного теста мы можем использовать как аргумент в пользу зависимости грамматики от значения не с большим правом, чем в пользу утверждения, что лингвистика основана на арифметике или астрологии.
(обратно)60
См. L. Вlооmfie1d, Language, New York, 1933, p. 156; Z. S. Harris, Methods in structural linguistics, Chicago, 1951, p. 177; 0. Sespersen, Language, New York, 1922, chap. XX, где приводится много других примеров.
(обратно)61
61 Другим основанием для мнения, что нельзя эффективным образом развить грамматику на семантической основе, является частный случай фонемных различий, изложенный в § 9.2.5. Вообще изучение значения наталкивается на многочисленные трудности даже после того, как определены.лингвистические элементы, несущие значение, и их взаимоотношения, и ни о какой попытке исследовать значение независимо от этих определений не может идти речи. Другими словами, при наличии языка-орудия и его формальных механизмов можно и должно исследовать их семантические функции (см., например, R. Jakobson, Beitrag zur allgemeinen Kasuslehre, «Travaux du Cercle Linguistique de Prague», 6, 1936, p. 240—288), но нельзя, по-видимому, найти семантического абсолюта, априорного по отношению к грамматике, который бы мог каким бы то ни было образом использоваться для определения объектов грамматики,
(обратно)62
Гудмэн утверждает — по-моему, вполне убедительно,— что понятие значения слов в конечном счете можно частично свести к понятию референции выражений, содержащих эти слова. (См. N. Goodman, On likeness of meaning, «Analysis», vol. 10, No 1, 1949; его ж е, On some differences about meaning, «Analysis», vol. !3, No 4, 1953). Подход Гудмэна равнозначен переформулированию части теории значения в более ясных терминах теории референции, точно так же, как многое в наших рассуждениях можно понимать как требование сформулировать заново части теории значения, относящееся к так называемому «структурному значению» в терминах совершенно несемантической теории грамматической структуры. Трудность теории значения состоит, в частности, в том, что «значение» имеет тенденцию применяться как всеохватывающий термин, включающий любой аспект языка, о котором мы знаем очень мало. В той мере, в какой это справедливо, мы можем ожидать, что к различным аспектам данной теории будут предъявляться законные претензии со стороны дисциплин, изучающих язык с иных точек зрения, по мере развития этих дисциплин.
(обратно)63
Подобное описание значения слова hit объясняет автоматически применение hit в таких трансформах, как Bill was hit by John «Билл был ударен Джоном»; Hitting Bill was wrong «Билл был ударен зря» и т. п,, если мы сумеем показать достаточно подробно и общо, что трансформы «понимаются» в терминах предложений ядра, лежащих в основе предложений,
(обратно)


Комментарии к книге «Синтаксические структуры», Ноам Хомский
Всего 0 комментариев