
Дэвид Андерсон Канбан. Альтернативный путь в Agile
David J. Anderson
KANBAN
Successful Evolutionary Change for Your Technology Business
Издано с разрешения Lean Kanban Inc.
Благодарим за помощь в подготовке издания сообщество Lean Kanban Community Russia в лице Пименова Алексея, Вячеслава Цырульника, Антона Манина, Сергея Баранова и Игоря Филипьева
Все права защищены.
Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
© David J. Anderson, 2010
© Перевод на русский язык, издание на русском языке, оформление. ООО «Манн, Иванов и Фербер», 2017
* * *
Посвящается Николе и Натали
Предисловие
Я всегда обращаю внимание на работы Дэвида Андерсона. Познакомился я с ним в октябре 2003 года, когда он прислал мне экземпляр своей книги Agile Management for Software Engineering: Applying Theory of Constraints for Business Results («Гибкое управление в разработке программ: применение теории ограничения систем для результатов в бизнесе»). Как можно предположить из названия, на книгу большое влияние оказала теория ограничений (ТОС) Элияху Голдратта[1]. Позднее, в марте 2005 года, я посетил Дэвида в Microsoft, к тому времени он плотно работал с кумулятивными диаграммами потока. Еще позже, в апреле 2007 года, мне довелось наблюдать, как действует прорывная канбан-система, внедренная им в Corbis.
Всю эту хронологию я привожу для того, чтобы вы почувствовали, в каком неудержимом темпе продвигается управленческое мышление Дэвида. Он не держится за единственную идею, пытаясь подогнать под нее весь мир. Напротив, он старается рассматривать проблему в целом, открыт для различных вариантов решений, пробует их на практике и оценивает принципы работы. Результаты подобного подхода вы увидите в этой книге.
Конечно, скорость хороша, если направлена в нужную сторону, и я уверен, что Дэвид двигается в верном направлении. Особенно меня восхищает последняя работа с канбан-системами. Я всегда считал, что принципы бережливого производства можно напрямую применить в разработке продукта, в отличие от идей ТОС. Более того, еще в октябре 2003 года я написал Дэвиду следующее: «Одна из главных слабостей ТОС – недооценка важности размера партии. Если ваш основной приоритет состоит в том, чтобы найти и устранить ограничение, то это часто значит, что вы просто решаете не ту проблему». Я до сих пор считаю это утверждение верным.
На нашей встрече в 2005 году я снова предлагал Дэвиду смотреть дальше, чем простая фокусировка на узких местах в ТОС. Я объяснял ему, что шумный успех производственной системы Toyota (ПСТ) не имеет ничего общего с поиском и устранением узких мест. Выигрыша в производительности Toyota достигает благодаря снижению объемов партии и уменьшению вариативности, благодаря чему сокращается количество необходимых производственных запасов. Именно сокращение таких запасов привело к достижению экономических преимуществ, и это стало возможным благодаря таким системам сокращения незавершенного производства, как канбан.
В 2007 году я посетил Corbis. Результат внедрения канбан-системы выглядел впечатляющим. Я указал Дэвиду, что он значительно улучшил канбан-подход, используемый в Toyota. Почему я так считал? Производственная система Toyota оптимизирована для работы с повторяющимися и предсказуемыми задачами с одинаковой длительностью и однородной стоимостью задержки. В этих условиях вполне корректно использовать такие подходы, как FIFO-приоритизация («первым пришел – первым ушел»). Также вполне корректно блокировать поступление работы, если достигнут предел незавершенных задач. Однако если мы имеем дело с неповторяющейся, непредсказуемой деятельностью с разной продолжительностью и различными стоимостями задержки, эти подходы нельзя признать оптимальными – а именно так и обстоят дела с разработкой ПО. Нам нужны более продвинутые системы, и это первая книга, которая описывает их с практическими подробностями.
Я хотел бы предупредить читателей о некоторых вещах. Во-первых, если вы думаете, что знаете, как работают канбан-системы, то вы, вероятно, имеете в виду те, что используются в бережливом производстве. Идеи, описанные в этой книге, намного прогрессивнее тех простых систем, в которых используются статические WIP-лимиты[2], FIFO-планирование и единый класс обслуживания. Пожалуйста, обратите внимание на эти различия.
Во-вторых, не думайте, что этот подход является системой визуального контроля. Визуализация незавершенных задач, достигаемая при помощи канбан-досок, очень полезна, но это лишь небольшой аспект данного подхода. Если вы тщательно прочитаете эту книгу, то найдете в ней много интересного. Наиболее ценная информация скрывается, например, в таких аспектах, как структуры процессов поступления и отправки задач, управления незаменимыми ресурсами и использования классов обслуживания. Не отвлекайтесь на визуальную часть, иначе пропустите самые увлекательные моменты.
В-третьих, не сбрасывайте эти методы со счетов только потому, что они кажутся слишком простыми в применении. Простота в применении – это результат идей Дэвида по поводу того, как получить максимальную выгоду с минимальными результатами. Он хорошо знает потребности практиков и уделил серьезное внимание тому, что действительно работает. Простые методы показывают высокую стабильность и почти всегда приводят к наилучшим долгосрочным результатам.
Это увлекательная и нужная книга, она заслуживает тщательного изучения. Уровень пользы, которую вы извлечете из нее, зависит от того, насколько серьезно вы отнесетесь к чтению. Ни одна другая книга не познакомит вас с этими передовыми идеями лучше. Надеюсь, она понравится вам так же, как и мне.
Дон Рейнертсен,автор книги The Principles of Product Development FlowЧасть I Основы
Глава 1 Решение дилеммы agile-менеджера
В 2002 году я был менеджером по разработке в удаленном офисе подразделения мобильных телефонов Motorola в Сиэтле (оно называлось PCS) и оказался в сложной ситуации. Мой отдел был частью стартапа, который Motorola приобрела годом ранее. Мы разрабатывали сетевое ПО для беспроводной передачи данных, например беспроводного скачивания и управления приборами. Эти серверные приложения входили в интегрированные системы, которые были тесно связаны с клиентским кодом мобильных телефонов, а также с другими элементами в телекоммуникационных сетях и операционной инфраструктуре, например с биллингом. Дедлайны назначались менеджерами, которые не обращали внимания на инженерную сложность проекта, его риски или масштаб. Основа кода развивалась из стартапа, при этом разработка многих первоначально запланированных возможностей была отложен на потом. Один старший разработчик настаивал на том, чтобы наши продукты назывались «прототипами». Нам было отчаянно необходимо повысить производительность и качество продукции, чтобы соответствовать требованиям бизнеса.
В своей повседневной деятельности в 2002 году и в процессе работы над предыдущей книгой{1} я был обеспокоен в основном двумя проблемами. Во-первых, как защитить команду от постоянно растущих требований бизнеса и достичь того, что сейчас в agile-сообществе принято называть «оптимальным темпом». И во-вторых, как я могу успешно внедрить agile-подход в масштабах всей организации, преодолев неизбежное сопротивление переменам?
В поисках оптимального темпа
В 2002 году agile-сообщество воспринимало оптимальный темп просто как «40-часовую рабочую неделю»{2}. Принципы Agile-манифеста{3} гласили, что «agile-процессы способствуют оптимальному развитию. Спонсоры, разработчики и пользователи должны быть готовы поддерживать постоянный темп в течение бесконечного времени». За два года до этого моя команда в Sprint PCS постоянно слышала от меня, что «масштабная разработка ПО – это марафон, а не спринт». Если членам команды предстояло поддерживать неизменный темп в процессе работы над полуторагодичным проектом, то нельзя было позволить им сгореть за месяц-другой. Проект нужно было распланировать, вставить в бюджет, расписать по времени и подвергнуть оценке, чтобы члены команды ежедневно тратили на работу разумное количество времени и не слишком уставали. Передо мной как менеджером стояла задача достичь этой цели и удовлетворить все требования бизнеса.
Когда я работал на первой менеджерской должности (это было в 1991 году, в стартапе, который делал платы захвата видео для персональных и более мелких компьютеров), CEO[3] сообщил, что у руководства сложилось обо мне «крайне отрицательное мнение». Я всегда отвечал «нет», когда наши возможности как разработчиков уже были исчерпаны, а от нас требовали все больше продуктов или функций. К 2002 году это вошло у меня в привычку: я провел еще десять лет, отказываясь выполнять капризы владельцев бизнеса.
Команды разработчиков и IT-отделы компаний сильно зависят от других групп, которые постоянно торгуются, упрашивают, угрожают и переделывают даже самые очевидные и объективно разработанные планы. В число уязвимых попадают и планы, основанные на тщательном анализе и историческом опыте. Большинство же команд, не имевших тщательных методов анализа и исторического опыта, не могли совладать с теми, кто подталкивал их брать на себя непонятные, а нередко и неосуществимые обязательства.
Тем временем сотрудники смирились с безумной загрузкой, и непомерные объемы работы стали нормой. Кажется, никто не задумывался над тем, что у инженеров-программистов тоже может быть общественная или семейная жизнь. Звучит грубо, но это правда! Я знаю слишком много примеров, когда излишняя производственная нагрузка навсегда разрушила семейные отношения. Трудно сочувствовать типичному гику-разработчику. В моем родном штате Вашингтон доход инженера-программиста уступает только заработку стоматолога. Как и во времена Форда, то есть в 1920-е годы, когда люди на его заводах зарабатывали в пять раз больше, чем в среднем по стране, никому и в голову не приходит подумать о монотонности работы или о благополучии специалистов: им столько платят! Трудно представить себе наличие профсоюзов в таких интеллектуальных отраслях, как разработка ПО, потому что никто не станет всерьез изучать причины физических и психологических недугов, которые испытывают разработчики. Более ответственные работодатели предлагают, например, такие меры, как массаж или психотерапия. Или проводят дни психического здоровья – и это вместо того, чтобы уделить внимание изучению основных причин проблемы. Технический писатель, сотрудник известной фирмы – разработчика ПО, однажды сказал мне: «Нет ничего страшного в том, что я употребляю антидепрессанты, ведь так поступают все!» Программисты обычно соглашаются со всеми требованиями, получают неплохую зарплату и страдают от последствий. Я хотел изменить такое положение дел, найти взаимовыгодный подход, который позволял бы мне говорить «да» и при этом все же защищать свою команду, обеспечивая достижение оптимального темпа. Я хотел вернуть членов своей команды в общество и семью и улучшить условия, которые вызывали у разработчиков, не достигших и тридцати лет, стресс и проблемы со здоровьем. Поэтому я решил начать бороться с этими проблемами.
В поисках успешного управления изменениями
Вторая проблема, которая занимала мои мысли, – это управление изменениями в крупных организациях. Я был менеджером по разработке в Sprint PCS и затем в Motorola. В обеих компаниях существовала серьезная потребность в переходе на более гибкие методы работы. Но в обоих случаях у меня возникали трудности при внедрении agile-методов более чем в одной-двух командах.
Оба раза у меня не было достаточно полномочий, чтобы просто приказать внести изменения в работу множества команд. Я старался внедрить изменения по просьбе высшего руководства, но не обладал должной властью. Меня просили повлиять на коллег, чтобы те внедрили в своих командах такие же изменения, как я – в своей. Но они не торопились брать на вооружение методы, которые, казалось бы, зарекомендовали себя в моей команде наилучшим образом. У этого сопротивления, вероятно, было несколько причин. Чаще всего я слышал, что у каждой команды своя ситуация и мои методы нужно будет подгонять под конкретные нужды других. К середине 2002 года я понял, что жестко предписывать какой-либо процесс разработки ПО бесполезно – это просто не будет работать.
Процесс нужно было адаптировать для каждой конкретной ситуации, поэтому требовалось активное руководство каждой командой. А этого нередко не хватало. Даже при должном руководстве нет полной уверенности в том, что существенные изменения могут произойти без наличия установленной структуры и советов по поводу того, как подогнать процессы под иные ситуации. Если у руководителя, коуча или ответственного инженера нет четкого представления о том, что делать, то любая адаптация, скорее всего, пройдет субъективно. При этом велика вероятность ошибок – например, внедрения неподходящего шаблона процесса.
Я попытался осветить эту проблему в книге Agile Management for Software Engineering, которую писал в то время. Я задавался вопросом: «Почему гибкая разработка дает лучшие экономические результаты, чем традиционные подходы?» Я хотел применить с этой целью структуру теории ограничений{4}.
В процессе исследований и написания упомянутой книги я понял, что уникальна каждая ситуация. Да и разве может сдерживающий фактор или узкое место оказаться одинаковым для любой команды и проекта в любое время? Каждая команда уникальна: иные навыки, возможности, опыт. Каждый проект отличается от других бюджетом, расписанием, объемом и рисками. Непохожи друг на друга и организации: у них разные цепочки создания ценности, они работают на различных рынках (рис. 1.1). Мне показалось, что это может дать ключ к пониманию сопротивления изменениям. Если предлагаемые перемены в методах работы и моделях поведения не дают, по мнению сотрудника, очевидного преимущества, то он не примет их. Если эти изменения не влияют на то, что воспринимается командой как ограничитель или сдерживающий фактор, то команда будет сопротивляться. Иными словами, перемены, предложенные без учета контекста, будут отвергнуты сотрудниками, которые прекрасно знают контекст работы.
Рис. 1.1. Почему универсальные методологии разработки неверны
Казалось бы, будет лучше, если новый процесс начнет развиваться, устраняя одно ограничение за другим. Это основное положение теории ограничений Голдратта. Понимая, что мне еще многому предстоит научиться, я осознавал ценность материала и устремился вперед в работе над рукописью. Мне было ясно, что книга не давала советов, как внедрить идеи в более широком масштабе, а также почти не помогала найти способы управления изменениями.
Подход Голдратта, изложенный в главе 16, направлен на поиск ограничений, а затем и способов их устранения, чтобы они перестали препятствовать производительности. После этого возникает новое ограничение, и цикл повторяется. Это итеративный подход, предполагающий систематическое улучшение производительности посредством выявления и устранения препятствий.
Я понял, что можно сочетать этот подход с некоторыми приемами из области бережливого производства. Смоделировав рабочий процесс жизненного цикла разработки ПО как потока создания ценности и создав систему отслеживания и визуализации для фиксации изменений состояния возникающей работы, «протекающей» по системе, я мог определить ограничители. Способность выявить ограничение – это первый шаг к модели, лежащей в основе ТОС. Голдратт уже разработал применение этой теории для проблем рабочего процесса, носящее неуклюжее название «барабан-буфер-канат». Однако я понял, что упрощенный вариант этой системы можно внедрить в область разработки ПО.
С точки зрения происхождения «барабан-буфер-канат» – это пример класса решений, известных как вытягивающие системы. Как мы увидим в главе 2, канбан тоже один из примеров такого рода систем. Побочный эффект вытягивающих систем состоит в том, что они ограничивают объем незавершенной работы до установленного заранее количества, препятствуя перегрузке сотрудников. К тому же полностью загруженными остаются только работники, напрямую сталкивающиеся с ограничением; у всех остальных должно оставаться свободное время. Я понял, что вытягивающие системы способны решить обе волновавшие меня проблемы. Вытягивающая система позволит мне внедрять пошаговые изменения, что (как я надеялся) существенно уменьшит сопротивление им, а также облегчит достижение оптимального темпа. Я принял решение перейти на систему «барабан-буфер-канат» при первой возможности. Мне хотелось поэкспериментировать с пошаговой эволюцией процесса и посмотреть, насколько она обеспечивает оптимальный темп и снижает сопротивление изменениям.
Такая возможность появилась осенью 2004 года в Microsoft, что подробно описано в главе 4 этой книги в анализе примера.
От системы «барабан-буфер-канат» к канбану
Применение решения «барабан-буфер-канат» в Microsoft дало свои результаты. Сопротивление было слабым, производительность выросла более чем втрое, время опережения сократилось на 90 %, а предсказуемость повысилась на 98 %. Осенью 2005 года я сообщил о достигнутых результатах на конференции в Барселоне{5}, а зимой 2006 года сделал еще один доклад. Моя работа привлекла внимание Дональда Рейнертсена, который специально приехал ко мне в офис в Редмонде. Он хотел убедить меня, что все готово к полному переходу на канбан.
Кан-бан – японское слово, которое дословно переводится как «сигнальная доска». В производстве такая доска используется для визуализации нарастающего темпа производства, что позволяет давать больше продукции. Сотрудники на каждом этапе процесса не могут перейти к следующей фазе работы, пока посредством канбан-доски не будет дан соответствующий сигнал. Хотя я знал о существовании этого механизма, я не был убежден, что он полезен или даже жизнеспособен применительно к интеллектуальной работе, особенно к разработке ПО. Я понимал, что канбан обеспечивает оптимальный темп, но не знал о его хорошей репутации в качестве метода стимулирования пошагового улучшения процессов. Я не знал, что Тайити Оно, один из создателей производственной системы Toyota, говорил: «Два основных принципа системы производства Toyota – это “точно-в-срок” и автоматизация с участием человека, или автономизация. Для управления системой используется инструмент – это и есть канбан». Иными словами, канбан жизненно важен для процесса кайдзен («непрерывное улучшение»), применяемого в Toyota. Это механизм, который заставляет систему работать. Сейчас, имея за плечами пятилетний опыт, я принимаю это как абсолютную истину.
К счастью, Дон привел убедительный аргумент в пользу перехода с системы «барабан-буфер-канат» на канбан. Он звучал довольно эзотерически: система канбан обеспечивает более гладкий переход с простоя в узком месте, чем «барабан-буфер-канат». Однако понимание подобной отличительной особенности не так уж обязательно, чтобы читать и понимать эту книгу.
Вновь изучив реализованное в Microsoft решение, я понял, что если бы мы сразу воспринимали его как результат системы канбан, то итог был бы таким же. Мне показалось интересным, что два разных подхода ведут к одному и тому же результату. Итак, поскольку получался один и тот же процесс, я не чувствовал себя обязанным воспринимать его исключительно как результат внедрения системы «барабан-буфер-канат».
Я стал предпочитать этому сложному словосочетанию термин «канбан». Он используется в бережливом производстве (то же, что производственная система Toyota). Эта совокупность знаний получила гораздо большее распространение и признание, чем теория ограничений. Канбан, несмотря на свое японское происхождение, менее метафоричен, чем барабан, буфер и канат, вместе взятые. Это слово легче произносить, объяснять и, как оказалось впоследствии, преподавать и внедрять. Вот оно и закрепилось.
Возникновение канбан-метода
В сентябре 2006 года я ушел из Microsoft и возглавил отдел разработки ПО в Corbis – расположенной в центре Сиэтла частной компании по хранению базы фотографий и защите интеллектуальной собственности. Вдохновившись достигнутым в Microsoft, я решил внедрить вытягивающую систему канбан в Corbis. И здесь результаты были весьма успешными, они привели к развитию большинства концепций, представленных в этой книге. Это расширенный набор тех концепций – визуализация рабочего процесса, типы элемента потока операций, каденции, классы обслуживания, особая отчетность руководства и анализ операций, – которые определяют Канбан-метод.
В этой книге я описываю Канбан (с большой буквы) как метод эволюционных изменений, использующий вытягивающую систему канбан (с маленькой буквы), визуализацию и другие инструменты для катализации введения идей бережливого производства в технологические разработки и IT-операции. Это эволюционный и пошаговый процесс. Канбан позволяет достичь оптимизации процесса, связанной с контекстом, с минимальным сопротивлением изменениям и при этом сохранить оптимальный темп для всех вовлеченных в работу сотрудников.
Принятие канбана в сообществе
В мае 2007 года Рик Гарбер и я представили первые результаты работы в Corbis на конференции по бережливой разработке новых продуктов в Чикаго. Доклад слушали примерно 55 человек. Летом того же года на конференции Agile 2007 в Вашингтоне я предложил провести круглый стол по обсуждению системы канбан – на него пришло человек двадцать пять. Через два дня один из присутствовавших, Арло Бельши, произнес краткую речь, в которой рассказывал о своем методе «обнаженного планирования»{6}. Оказалось, что и другие компании внедряют у себя вытягивающие системы. Так, в Yahoo! была создана дискуссионная группа, которая быстро набрала сотню членов. А сейчас в нее входит уже более 1000 человек. Некоторые из участников моего круглого стола решили попробовать Канбан на своем рабочем месте – нередко с командами, которые безуспешно боролись со Scrum. Самые известные из моих ранних последователей – Карл Скотланд, Аарон Сандерс и Джо Арнольд, все из Yahoo!. Эта компания быстро внедрила Канбан в более чем десяток команд на трех континентах. Еще один заметный участник круглого стола, Кендзи Хиранабе, разрабатывал канбан-решения в Японии. Вскоре после конференции он написал на эту тему две статьи для InfoQ{7},{8}, которые вызвали большой интерес. Осенью 2007 года Санджив Огастайн, автор Managing Agile Projects{9} и основатель Организации руководителей гибких проектов (Agile Project Leadership Network, APLN), посетил Corbis в Сиэтле и описал наши канбан-системы как «первый новый agile-метод, который я увидел за пять лет».
На следующий год на конференции Agile 2008 в Торонто состоялось шесть презентаций решений канбан разного формата. Одна из них была проведена Джошуа Кериевски из Industrial Logic – компании по обучению и консалтингу в области экстремального программирования. В ней он продемонстрировал, как пришел к похожим идеям по взятию на вооружение принципов экстремального программирования и их улучшению в контексте его бизнеса. В тот год Agile Alliance вручил приз Гордона Паска Арло Бельши и Кендзи Хиранабе за их вклад в agile-сообщество. Как я понял, он состоял в одном случае во внедрении Канбана, а в другом – в разработке и пропаганде на удивление схожих идей.
Ценность канбана неочевидна
Во многих отношениях интеллектуальная деятельность противоположна идее массового производства. И уж совершенно точно разработка ПО не похожа на промышленное производство. У этих отраслей промышленности совершенно разные свойства. Для производства характерна низкая вариативность, а разработка ПО в основном вариативна. Более того – она стремится использовать эту вариативность, чтобы благодаря новинкам дизайна получить больше доходов. Неслучайно в английском названии программного обеспечения – software – есть элемент soft («мягкий»): ПО можно легко и безболезненно трансформировать, а производство концентрируется на «жестких» вещах, менять которые тяжело. Вполне естественно поэтому выглядит скептицизм по поводу ценности канбан-систем в разработке ПО и других IT-сферах. Большая часть из того, что наше сообщество за последние несколько лет усвоило о Канбане, противоречит интуиции. Никто не мог предсказать того эффекта, который Канбан оказал на корпоративную культуру и на улучшение межфункционального сотрудничества в Corbis (см. главу 5). Я надеюсь доказать вам, что Канбан способен на многое. Хочу убедить вас, что, внедрив простые правила Канбана, вы сможете повысить производительность, предсказуемость и удовлетворенность пользователей, а также сократить срок работы. Благодаря этому изменится культура вашей организации, поскольку рост объемов совместной работы позволит установить лучшие, более функциональные отношения.
Выводы
• Канбан-системы принадлежат к семейству подходов, известных как вытягивающие системы.
• Применение Элияху Голдраттом теории ограничений, известной как «барабан-буфер-канат», является альтернативным способом внедрения вытягивающей системы.
• Мотивация к переходу на вытягивающие системы имелась у обеих сторон: нужно было найти системный путь достижения оптимального темпа работы и такой подход к введению процессуальных изменений, который встретил бы минимальное сопротивление.
• Канбан – это механизм, лежащий в основе производственной системы Toyota и ее метода постоянного улучшения – кайдзен.
• Первая виртуальная канбан-система для программирования внедрялась в Microsoft с 2004 года.
• Результаты первых опытов внедрения Канбана впечатляли, так как удалось достичь оптимального темпа, минимизировать сопротивление переменам благодаря пошаговому эволюционному подходу и получить существенные экономические выгоды.
• Канбан-метод как подход к управлению изменениями стал зарождаться в сообществе после конференции Agile 2007, прошедшей в августе 2007 года в Вашингтоне.
• В этой книге термин «канбан» (с маленькой буквы) относится к сигнальным доскам, а «канбан-система» (с маленькой буквы) – к вытягивающей системе, использующей (виртуальные) сигнальные доски.
• Слово «Канбан» (с большой буквы) относится к методологии эволюционного пошагового улучшения процесса, которая зародилась в Corbis в 2006–2008 годах и продолжала развиваться в более широком сообществе разработчиков, связанных с бережливым программированием.
Глава 2 Что такое канбан-метод
Весной 2005 года мне посчастливилось провести отпуск в Японии, в Токио. Дело было в начале апреля, когда цветут вишни. Чтобы насладиться этим зрелищем, я во второй раз в жизни приехал в Восточные сады в Императорском дворце в Токио. Именно здесь меня осенило: канбан – это не только производство.
В субботу, 9 апреля 2005 года, я вошел в парк с северного входа, перейдя мост через ров неподалеку от станции метро «Такэбаси». Многие токийцы решили этим солнечным воскресным утром выбраться в парк и насладиться его спокойствием и цветением японской вишни – сакуры.
Обычай устраивать пикник под вишневыми деревьями, когда опадают их цветы, называется «ханами» (цветочный праздник). Это древняя японская традиция – возможность подумать о красоте, хрупкости и кратковременности жизни. Короткий период цветения сакуры – это метафора нашей собственной жизни, нашего краткого, прекрасного и хрупкого существования посреди огромной Вселенной.
Цветущая вишня резко контрастировала с серыми зданиями делового Токио, его шумом и суетой, огромными толпами занятых людей и шумом транспорта. Сады были оазисом в сердце бетонных джунглей. Когда мы с семьей шли по мосту, к нам подошел пожилой японец с сумкой через плечо. Он полез в сумку и вынул пачку пластиковых карточек. Он предложил каждому из нас по одной, правда, задумался, нужна ли карточка моей трехмесячной дочери, сидевшей в слинге. Но в итоге вручил мне карточку и для нее. Он ничего не сказал, и я, плохо зная японский, тоже промолчал. Мы пошли дальше в сады подыскивать местечко для семейного пикника.
Проведя прекрасное утро на солнышке, мы через два часа собрали принадлежности для пикника и направились к Восточным воротам, чтобы пройти к станции «Отэмати». Возле выхода стояла очередь к небольшому киоску. Когда она немного продвинулась вперед, я понял, что это люди возвращают пластиковые карточки, которые были входными билетами. Я залез в карман и вынул наши карточки. В киоске находилась японка в униформе. Между нами была стеклянная перегородка с полукруглым вырезом у стойки, как в кассе кинотеатра или парка развлечений. Я передал через это отверстие наши карточки. Дама взяла их руками в белых перчатках и положила в стопку к другим. Она едва кивнула головой и поблагодарила меня улыбкой. Никаких денег не требовалось. Никакого объяснения, зачем я два часа с момента входа в парк носил с собой белые пластиковые карточки, дано не было.
Что же это за входные билеты? Зачем их выдавать, если они бесплатные? Сначала я предположил, что это связано с безопасностью. Подсчитав все возвращенные карточки, администрация могла убедиться, что внутри не осталось никого постороннего после закрытия парка на ночь. Однако затем я понял, что если речь идет о безопасности, то это какая-то очень сомнительная схема. Как они могут знать, что мне дали не одну карточку, а две? Моя трехмесячная дочь – это посетитель или багаж? Система казалась слишком вариативной. Чересчур много возможностей для ошибки! Если бы это действительно была схема безопасности, то она была обречена на провал и ежедневно давала бы ошибки первого рода[4]. (Кстати, отмечу, что подобная система не может выдавать ошибки второго рода, поскольку это потребовало бы печати дополнительных входных билетов. Это общее полезное свойство систем канбан.)
Тем временем охрана ежевечерне рыскала бы по парку в поисках заблудившихся туристов. Нет, дело в чем-то другом. И я понял, что в садах Императорского дворца реализуется канбан-система! Это озарение позволило мне понять, что канбан-системы полезны не только в производстве. Похоже, канбан-жетоны разного вида помогают во всех типах управленческих ситуаций.
Что такое канбан-система?
Некоторое количество канбан-жетонов (в нашем случае – карточек), равное (оговоренной) емкости системы, запускается в обращение. Одна карточка соответствует одному элементу работы. Каждая карточка – это сигнальный механизм. Новый элемент работы может начаться, только если для него доступна карточка. Эта доступная карточка прикрепляется к элементу работы на время его прохода через всю систему. Когда карточек больше не остается, новую работу начинать нельзя. Любая новая работа должна оставаться в очереди, пока карточка не освободится. Когда какое-то количество работы окончено, карточка освобождается и снова запускается в обращение. Теперь можно начинать работу над новым элементом в очереди.
Этот механизм известен как вытягивающая система, поскольку новая работа втягивается системой, когда она обладает достаточной емкостью для этого, а не вталкивается в нее по требованию. Вытягивающая система не может оказаться перегруженной, если емкость, определяемая количеством находящихся в обращении карточек, определена верно.
В садах Императорского дворца система – сами сады, посетители – это неоконченная работа, а емкость определяется количеством находящихся в обращении карточек. Вновь прибывающие посетители получают доступ, только если в наличии есть билеты для них. В обычное время проблем не возникает. Однако в пиковые дни, например в выходные во время цветения сакуры, парк пользуется большой популярностью. Когда все входные билеты выданы, новые посетители должны ждать в очереди перед мостом, пока предыдущие туристы не уйдут, сдав свои карточки. Канбан-система дает простой, дешевый и легко внедряемый метод контроля количества посетителей и его ограничения. Это позволяет работникам парка поддерживать сады в хорошем состоянии и избегать ущерба, вызванного чрезмерным количеством людей.
Применение канбана в разработке ПО
В разработке ПО мы используем виртуальную канбан-систему, чтобы ограничить количество неоконченных задач. Хотя слово «канбан» переводится как «сигнальная карточка», а в большинстве вариантов Канбан для разработки ПО действительно используются карточки, их нельзя считать сигналами для получения новых задач. Они символизируют элементы работы. Отсюда термин «виртуальный», поскольку это не материальные сигнальные карточки. Сигнал для вытягивания новой работы вытекает из визуального количества неоконченных задач, вычисленных из некоего индикатора предела (или емкости). В ряде случаев внедряются физические методы использования канбана – например, клейкие стикеры или магниты на доске. Однако чаще сигнал порождается программой для управления задачами. В главе 6 приводятся примеры принципов действия систем канбан в их применении к IT.
Стены карточек стали популярным механизмом визуального контроля в гибкой разработке ПО, что показано на рис. 2.1. Обычно используют пробковую доску с прикрепленными к ней карточками или белую доску с клейкими стикерами для визуализации незавершенных задач. Стоит заметить, что эти стены карточек сами по себе не являются канбан-системами, хотя некоторые и утверждают обратное. Это просто системы визуального контроля. Они позволяют командам следить за незаконченными задачами и самоорганизовываться, назначать собственные задачи и переносить работу из бэклога без подсказок менеджера проекта или непосредственного руководителя. Однако если отсутствует четко определенный предел и сигнал для проведения новой работы по системе, это не канбан. Подробнее об этом говорится в главе 7.
Рис. 2.1. Стена карточек канбан (с разрешения SEP)
Зачем использовать канбан-систему
Из последующих глав станет понятно: мы используем канбан-систему для того, чтобы довести число незавершенных задач команды до заданной емкости и достичь баланса между нагрузкой на команду и ее пропускной способностью. Тем самым мы можем добиться оптимального темпа разработки, поэтому все сотрудники смогут заниматься и работой, и личной жизнью. Как вы увидите, Канбан быстро выявляет проблемы, которые сказываются на производительности, и заставляет команду сосредоточиться на их разрешении, чтобы сохранять постоянный поток работы. Делая наглядными проблемы качества и процесса, канбан дает возможность оценить влияние дефектов, ограничений, вариативности, затрат на обслуживание производственного потока и пропускную способность сотрудников.
Простое ограничение незавершенных задач посредством канбана приводит к повышению качества работы и ее производительности. Сочетание оптимизации потока работ и повышения качества помогает сократить время выполнения работ и повышает предсказуемость и вероятность выполнения задачи в срок. Установив регулярные каденции релиза и постоянное следование расписанию, Канбан помогает создать доверительные отношения с клиентами и другими участниками цепочки создания ценности – другими отделами, с поставщиками и зависящими от вас партнерами.
Благодаря всему этому Канбан вносит вклад в культурную эволюцию организаций. Обнажая проблемы и сосредоточивая организационные усилия на их решении, устраняя их эффекты в будущем, Канбан облегчает создание тесно сотрудничающей, доверяющей друг другу, наделенной бoльшими полномочиями и постоянно совершенствующейся команды.
Доказано, что Канбан повышает удовлетворенность пользователя благодаря регулярным, надежным и высококачественным релизам ценного функционала. Также доказано, что он улучшает производительность, качество и сокращает время выработки. К тому же есть свидетельства того, что канбан может стать катализатором для возникновения более гибкой организации благодаря эволюционным культурным изменениям.
Дальнейшая цель этой книги – помочь понять, как использовать канбан-системы в разработке ПО, и научить вас внедрять такие системы, чтобы достичь обещанных выгод вместе с вашей командой.
Канбан как комплексная адаптивная система для бережливого производства
Канбан-метод предлагает комплексную адаптивную систему, которая направлена на катализацию перехода организации к бережливому производству. Комплексные адаптивные системы обладают начальными условиями и простыми правилами, которые требуются для перехода к комплексному адаптивному интеграционному поведению. Чтобы создать навыки бережливого производства в организации, Канбан использует пять ключевых свойств. Эти свойства присутствуют во всех успешных вариантах внедрения Канбана, в том числе и в том, который использовался в Microsoft и будет описан в главе 4. Вот эти пять свойств.
1. Визуализация рабочего потока.
2. Ограничение количества незавершенных задач.
3. Измерения и управление потоком.
4. Формальные политики процессов.
5. Использование моделей[5] для оценки возможностей совершенствования.
Ситуационное поведение и канбан
В реализациях Канбана мы ожидаем увидеть появление новых привычек и осознания некоторых правил, список которых постоянно растет. Некоторые из них (или даже все) есть в большинстве последних реализаций. Так, все они присутствовали в Corbis за 2007 год. Мы полагаем, что этот список будет расти, когда мы больше узнаем о влиянии Канбана на организации.
• Процессы уникальны для каждого проекта или потока создания ценности.
• Разделенные каденции (или разработка, не привязанная к единому итерационному циклу).
• Рабочее расписание определяется стоимостью задержки.
• Оптимизация поставки ценности с помощью классов обслуживания.
• Управление рисками основывается на емкости производственной системы.
• Терпимость к экспериментам в процессе.
• Управление на основании количественных показателей
• Вирусное распространение (Канбана) по организации.
• Слияние небольших команд для создания единых трудовых центров.
Канбан как разрешение действовать
Канбан – это не методология жизненного цикла разработки ПО и не подход к управлению проектами. Он требует наличия каких-то процессов, чтобы можно было применить Канбан для их постепенного изменения.
Этот эволюционный подход, поддерживающий постепенные изменения, до сих пор оспаривается в сообществе специалистов по гибкой разработке ПО. Дело в том, что в его рамках команды не должны брать на вооружение определенный метод или шаблон процесса. Индустрия сервисов и инструментов разработала несколько методик, определенных в двух популярных методах гибкой разработки. В рамках же Канбана сотрудники и их команды могут создавать собственные производственные процессы, способные покрывать ожидания заказчика от этих самых процессов и требующие выработки нового набора инструментов. И действительно, Канбан породил целую волну возникновения революционных инструментов, готовых сместить уже используемые в гибком управлении проектами и заменить их более наглядными и программируемыми, легко подгоняемыми под конкретные рабочие задачи.
В ранние годы гибкой разработки ПО лидеры сообщества нередко не понимали, почему их методы работали. Мы говорили об «экосистемах»{10} и советовали новичкам внедрять все практики – иначе решение не сработает. Некоторые компании опубликовали модели agile-зрелости, где делались попытки оценки усвоения практик. В Scrum-сообществе существует опробованный на практике тест, который часто называют «тестом Nokia»{11}.
Эти основанные на практике оценки направлены на унификацию и отрицают необходимость в адаптации в соответствии с контекстом. Канбан дает рынку разрешение игнорировать эти практические схемы. Он активно поощряет разнообразие.
В 2007 году несколько человек побывали в моем офисе в Corbis, чтобы посмотреть на Канбан в действии. Обычно все посетители, связанные с agile-сообществом разработки ПО, спрашивали об одном и том же: «Дэвид, мы увидели в офисе семь канбан-досок. Они все разные! Каждая команда работает по своему процессу! Как можно справиться с таким разнообразием?» На этот вопрос я обычно отвечал так: «Конечно! Все ситуации разные. Они развивают свой процесс в соответствии с контекстом». Но я знал, что все процессы ведут начало от одних и тех же принципов и что члены команд, осознавая эти базовые принципы, могут адаптировать их под собственные нужды.
Когда с Канбаном познакомилось больше людей, они поняли, что эта система помогает решать проблемы управления изменениями, с которыми они столкнулись в своих организациях. Канбан придает гибкости команде, проекту или компании. Мы пришли к выводу, что Канбан разрешает создать на рынке собственный процесс, оптимизированный для конкретного контекста. Канбан дает разрешение людям думать самостоятельно. Он позволяет быть разными: отличаться от команды, расположившейся в соседнем кабинете, на другом этаже, в другом здании или в конкурирующей фирме. Он дает разрешение отклониться от учебника. Более того, Канбан дает инструменты, которые позволяют объяснить (и оправдать), почему разнообразие – это хорошо и выбрать его – значит поступить правильно.
Чтобы подчеркнуть этот выбор, я разработал дизайн футболки для Общества ограничения незавершенных задач. Я вдохновился постером Шепарда Фэйри для предвыборной кампании Обамы, на который поместил портрет Тайити Оно, создателя канбан-системы в Toyota. Слоган «Да, мы за канбан» призван подчеркнуть, что у вас есть возможность. Вам разрешается попробовать Канбан, модифицировать свои процессы, быть другими. Ваша ситуация уникальна, и вы можете разработать собственное решение для своего процесса, оптимизированное для вашей сферы деятельности и потока создания ценности, рисков, с которыми вы сталкиваетесь, навыков вашей команды и требований ваших клиентов.
Выводы
• Канбан-системы могут быть использованы в любой ситуации через ограничение наличия элементов работы внутри системы.
• Сады Императорского дворца в Токио используют канбан-систему, чтобы контролировать число посетителей в парке.
• Количество сигнальных карточек «канбан», находящихся в обращении, ограничивает объем незавершенных задач.
• Новая работа втягивается в процесс после возвращения в оборот сигнальной карточки, когда предыдущее задание выполнено.
• В IT-сфере мы, как правило, используем виртуальную канбан-систему, поскольку для ограничения количества незавершенных задач не передаются какие-либо физически существующие карточки.
• Доски со стикерами, часто встречающиеся в гибкой разработке ПО, не являются канбан-системами.
• Канбан-системы создают на рабочем месте положительную напряженность, которая вызывает обсуждение проблем.
• Канбан-метод (или Канбан с большой буквы) использует канбан-систему как катализатор изменений.
• Канбан требует формальных политик процессов.
• Канбан использует инструменты разных областей знаний для анализа проблем и поиска решений.
• Канбан предполагает пошаговое улучшение процессов благодаря постоянному выявлению проблем, влияющих на производительность.
• Современное определение Канбан-метода можно найти в сети на сайте Общества ограничения незавершенных задач (Limited WIP Society, /).
• Канбан дает разрешение на отклонения в разработке ПО, поощряет поиск специфических решений в зависимости от контекста вместо догматического следования определению процесса жизненного цикла разработки ПО или шаблону.
Часть II Преимущества канбана
Глава 3 Рецепт успеха
Последние десять лет я пытался ответить на вопрос, какие действия вам как менеджеру следует предпринять, если вы унаследовали команду, особенно работающую не в соответствии с agile-практиками, которая обладает широким набором способностей и, возможно, совершенно неэффективна. Обычно меня делали агентом организационных изменений. Таким образом, я должен был обеспечить переход к позитивным изменениям и быстрый прогресс, желательно в течение двух-трех месяцев.
Как у менеджера у меня никогда не было возможности в крупных организациях нанять собственную команду. Меня просили приспособить существующий коллектив, причем с минимальными кадровыми изменениями, для проведения революции в производительности организации. Я думаю, что такая ситуация встречается гораздо чаще, чем возможность набрать новую команду.
Постепенно я выработал подход к управлению такими изменениями. Он основан на опыте, в котором учтены все прошлые ошибки. Они связаны, как правило, с попытками использовать административный ресурс для навязывания рабочих процессов. Приказы руководства обычно не приводят ни к чему хорошему. Когда я просил команды изменить свое поведение и перейти на какой-нибудь agile-метод, например Feature Driven Development, я встречал сопротивление. Мои возражения, что бояться нечего, я проведу необходимое обучение и выступлю в роли наставника, почти не давали результата. В лучшем случае люди соглашались с большой неохотой – об истинной и глубокой институциализации перемен не могло быть и речи. Когда вы просите людей измениться, это порождает страх и снижает их самооценку, поскольку тем самым вы даете понять, что их навыки более не нужны.
Для борьбы с подобными проблемами я разработал так называемый рецепт успеха. Он содержит руководство для нового менеджера, адаптирующего существующую команду к новым реалиям. Действуя согласно этому рецепту, можно добиться быстрого улучшения и почти не вызвать сопротивления команды. Здесь я хотел бы упомянуть о влиянии Дональда Рейнертсена, благодаря которому я освоил два первых и последний, шестой, этап этого рецепта. Работы Элияху Голдратта по теории ограничений и его пять направляющих шагов также оказали серьезное воздействие на четвертый и пятый этапы.
Вот эти этапы:
• концентрация на качестве;
• снижение количества незавершенных задач;
• частые релизы;
• баланс требований и пропускной способности;
• приоритизация;
• борьба с источниками вариативности для улучшения предсказуемости.
Внедрение рецепта
Этот рецепт применяется в форме его выполнения техническим или функциональным менеджером. На первом месте – концентрация на качестве, и она находится под контролем менеджера по разработке или тестированию либо его непосредственного руководителя – например, технического директора. Двигаясь вниз по списку, мы видим, что постепенно требования контроля ослабевают и начинают уступать место сотрудничеству с сопредельными группами – вплоть до этапа «приоритизация». Приоритизация – это работа бизнес-отдела, а не технологической организации, поэтому менеджер технического отдела не должен этим заниматься. К сожалению, руководители бизнес-подразделений нередко уклоняются от ответственности и поручают провести расстановку приоритетов именно техническому менеджеру. А затем распекают его за неправильный выбор. Борьба с источниками вариативности для улучшения предсказуемости идет в списке последней, потому что для искоренения некоторых типов вариативности требуются изменения в поведении. А просить людей об этом – сложная задача! Поэтому борьбу с вариативностью лучше отложить до того момента, когда благодаря успехам, достигнутым на более ранних стадиях, в организации произойдет смена климата. Как мы увидим в главе 4, иногда важно бороться с источниками вариативности на ранних стадиях, чтобы стала возможной реализация первых этапов. Здесь главное – выбирать такие источники вариативности, которые не требуют серьезных изменений в поведении, чтобы сотрудники с готовностью приняли ваши предложения.
Концентрация на качестве – самый простой этап, потому что это техническая дисциплина, которой может руководить функциональный менеджер. Остальные этапы сложнее, поскольку во многом зависят от согласия и сотрудничества с другими командами. Они требуют навыков постановки целей, переговоров, знания психологии, социологии и эмоционального интеллекта. Создание консенсуса на этапе баланса требований и пропускной способности жизненно важно. Чтобы сгладить дисбаланс между ролями и обязанностями членов команды, требуются серьезные дипломатические способности и навыки переговорщика. Таким образом, имеет смысл сосредоточиться на тех вещах, которые находятся под вашим контролем и способны положительно сказаться на производительности вашей команды и бизнеса в целом.
Укрепление доверительных отношений с другими командами поможет выполнить более сложные элементы. Создание и демонстрация высококачественного кода, содержащего мало ошибок, закрепляет доверие. А еще сильнее повышает его регулярный выпуск высококачественного кода. С ростом уровня доверия менеджер получает больше политического капитала. Это позволяет двигаться к следующему этапу рецепта. В итоге ваша команда завоюет достаточно уважения, чтобы вы могли воздействовать на владельцев продукта, команду по маркетингу и бизнес-спонсоров, изменить их поведение и начать сотрудничество для расстановки приоритетов и выявления наиболее ценных элементов для разработки.
Борьба с источниками вариативности для улучшения предсказуемости – непростое дело. Ее нельзя начинать, пока команда не будет работать на более зрелом и существенно более высоком уровне. Первые четыре этапа рецепта имеют при этом серьезное значение. Они могут принести успех новому менеджеру. Однако чтобы действительно создать культуру инноваций и постоянного совершенствования, необходимо атаковать источники вариативности процесса. Поэтому последний этап рецепта требует дополнительного доверия: он отделяет действительно великих технических лидеров от обычных компетентных менеджеров.
Концентрация на качестве
В «Манифесте гибкой разработки ПО» ничего не говорится о качестве, хотя в «Принципах манифеста»{12} ведется речь о мастерстве, что подразумевает концентрацию на качестве. Но если качество не фигурирует в «Манифесте», почему оно стоит на первом месте в моем рецепте успеха? Суть в том, что большое количество ошибок приводит к основным потерям времени в разработке ПО. Эти цифры просто невероятны, а их амплитуда может колебаться на несколько порядков.
Кейперс Джонс{13} сообщает, что в 2000 году во время пузыря доткомов он оценивал качество программ для североамериканских команд, и оно колебалось от шести ошибок на одну функциональную точку до менее чем трех ошибок на 100 функциональных точек – 200 к одному. Серединой будет примерно одна ошибка на 0,6–1,0 функциональной точки. Таким образом, для команд вполне типично тратить более 90 % своих усилий на устранение ошибок. Есть и прямое тому свидетельство: в конце 2007 года Аарон Сандерс, один из первых последователей Канбана, написал на листе рассылки Kanbandev, что команда, с которой он работал, тратила 90 % доступной производительности на исправление ошибок.
Стремление к изначально высокому качеству окажет серьезное влияние на производительность и пропускную способность команд, имеющих большую долю ошибок. Можно ожидать увеличения пропускной способности в два – четыре раза. Если команда изначально отстающая, то концентрация на качестве позволяет увеличить этот показатель вдесятеро.
Улучшение качества программ – это всем хорошо понятная проблема.
И гибкая разработка, и традиционные подходы к качеству имеют свои достоинства. Их нужно сочетать. Тестированием должны заниматься профессиональные тестировщики. Они находят дефекты и предотвращают их попадание в готовый продукт. Если вы будете просить разработчиков писать модульные тесты и автоматизировать их для автоматизированного регрессионного тестирования, то это возымеет серьезный эффект. Казалось бы, если просить разработчиков сначала писать тесты, то это дает психологическое преимущество. Так называемая разработка через тестирование (Test Driven Development, TDD) действительно, судя по всему, помогает: тестовое покрытие выглядит более полным. Стоит сказать, что дисциплинированные команды, которые я возглавлял, писали тесты уже после функционального кодирования и демонстрировали качество на уровне лучших показателей индустрии. Однако очевидно, что у средней команды качество повысится, если тесты будут написаны до функционального кода.
Рецензирование кода повышает качество. Рецензирование кода работает и в случае парного программирования, и при экспертной оценке, анализе кода или полной инспекции по Фагану. Оно помогает повысить как внутреннее, так и внешнее качество кода. Рецензирование кода лучше всего проводить часто и небольшими порциями. Я предлагаю командам ежедневно рецензировать код друг друга как минимум по 30 минут.
Совместный анализ и проектирование улучшают качество. Когда команды просят работать вместе над анализом проблем и проектированием решений, качество обычно выше. Я предлагаю командам проводить сессии совместного командного анализа и проектирования. Проектирование должно проводиться ежедневно малыми порциями. Скотт Амблер называет это agile-моделированием{14}.
Использование шаблонов проектирования повышает качество. Шаблоны проектирования заключают в себе известные решения известных проблем. Благодаря им на ранних этапах жизненного цикла становится доступно больше информации, а ошибки проектирования устраняются.
Использование современных инструментов разработки повышает качество. Многие современные инструменты содержат функции проведения статического и динамического анализа кода. Их нужно включать и настраивать для каждого проекта. Эти средства анализа могут помочь программистам избежать элементарных ошибок – например, внесения таких широко известных проблем, как пробелы в защите.
Более экзотические современные инструменты разработки, такие как производственные линии программных продуктов (или фабрики программного обеспечения) и предметно-ориентированные языки, устраняют ошибки. Фабрики программного обеспечения можно использовать для инкапсуляции шаблонов проектирования как фрагментов кода. Тем самым сокращается вероятность внесения ошибок в код. Можно использовать этот инструмент и для автоматического переиспользования функционала в коде, что также сокращает вероятность внесения ошибок. Использование программного обеспечения также сокращает необходимость проверок кода, поскольку фабричный код не нужно проверять заново. Его качество доказано.
Некоторые из последних предложений на самом деле относятся к области сокращения вариативности процесса. Использование фабрик программного обеспечения, а возможно, даже и шаблонов проектирования – это просьба к разработчикам изменить их образ действий. Большим прорывом может стать использование профессиональных тестировщиков, написание тестов до описания функционала, автоматическое регрессивное тестирование, рецензирование кода. И еще одно…
Сокращение объема незаконченного проектирования существенно повышает качество программ.
Снижайте количество незавершенных задач и делайте частые релизы
В 2004 году я работал с двумя командами в Motorola. Обе они разрабатывали сетевую часть бэкэнд-приложения для мобильных телефонов. Одна команда работала над сервером для «скачивания по воздуху» (over-the-air, OTA) рингтонов, игр и других приложений и данных. Вторая разрабатывала сервер для управления устройствами «по воздуху» (OTA DM). Обе команды руководствовались методологией Feature Driven Development (FDD). Обе были примерно одного размера – человек восемь разработчиков, один архитектор, до пяти тестировщиков и менеджер проекта. Работая совместно с маркетологами, команды сами проводили анализ и проектирование. Обеим командам помогали отдельные команды проектирования пользовательского взаимодействия (UX) и разработки пользовательской документации (технические писатели).
Незавершенные задания (WIP), время выполнения и ошибки
На рис. 3.1 демонстрируется кумулятивная диаграмма потока для команды, занимавшейся закачкой ОТА. Кумулятивная диаграмма потока – это зонированный график, который отражает объем работы в определенном состоянии. Состояния, показанные на диаграмме, – это бэклог, то есть объем работы, который заведен в учетную систему, но очередь до него еще не дошла. «Начатое» – это когда требования к функционалу обсуждались с разработчиками; «спроектированное» – то есть для функции разработана ML-диаграмма последовательности; «разработанное» – то есть функционал разработан в соответствии с диаграммой последовательности; «завершенное» – то есть все модульные тестирования пройдены, код прошел рецензирование и был принят ведущими разработчиками и передан на тестирование.
.
Рис. 3.1. Кумулятивная диаграмма потока (КДП) команды закачек OTA (осень 2003 – зима 2004 гг.)
Первая линия на диаграмме показывает количество функций в масштабе проекта. Этот объем был разделен владельцами бизнеса на две части. Вторая линия показывает количество начатых функций. Третья линия – число спроектированных, четвертая – разработанных, а пятая – количество завершенных и готовых к тестированию функций.
Вертикальная разница между второй и пятой линиями в любой выбранный день показывает количество незавершенных задач, а горизонтальная дистанция между второй и пятой линиями показывает среднее время выполнения с момента начала работы над функцией до дня ее сдачи. Важно заметить, что горизонтальное расстояние – это среднее, а не конкретное время выполнения для конкретной функции. Кумулятивная диаграмма потока не показывает конкретных функций. Пятьдесят пятая начатая функция может быть тридцатой законченной. Никакой связи между линией на оси у и конкретной функцией из бэклога нет.
Команде сервера закачек ОТА не хватало либо дисциплины, либо мотивации для использования метода FDD. Они не работали совместно, как требует FDD, а выдавали большие порции функций на откуп индивидуальным разработчикам. Обычно на одного разработчика у них в любое время приходилось до десяти функций. А команда по разработке OTA DM следовала методам, изложенным в учебнике. Они хорошо работали в сотрудничестве и разрабатывали модульные тесты для 100 % своих функций. И самое важное – они трудились над небольшим количеством функций одновременно, обычно это было 5–10 функций в работе для всей команды в любой момент.
Целевым ориентиром для функции в FDD является 1,6–2,0 функционального очка кода.
У команды по разработке сервера закачек OTA, находившейся в Сиэтле, среднее время выполнения составляло примерно три месяца на функцию от начала работы до сдачи ее для интеграционного теста команде из Шампейна (рис. 3.1).
У команды по разработке OTA DM среднее время выполнения колебалось от 5 до 10 дней, что показано на рис. 3.2. Разница в исходном качестве, измеряемом в количестве ошибок в системном или интеграционном тесте, превысила 30 раз. Команда по разработке OTA DM продемонстрировала изначальное качество на уровне лидеров индустрии – две или три ошибки на 100 функций, а команда по разработке сервера закачек OTA продемонстрировала средний по индустрии результат – около двух ошибок на функцию.
Рис. 3.2. Кумулятивная диаграмма потока (КДП) команды управления устройствами OTA (зима 2004 года)
Из этих диаграмм можно сделать вывод, что количество незавершенных задач непосредственно связано с временем выполнения. Рис. 3.2 явно демонстрирует, что с сокращением числа незавершенных задач уменьшается и время выполнения. На пике среднее время выполнения составляет 12 дней. Позднее в проекте, когда незавершенных задач становится меньше, среднее время выполнения сокращается до четырех дней.
Существует причинно-следственная связь между количеством незавершенных задач и средним временем выполнения, и эта зависимость линейна. В производстве эти отношения известны как закон Литтла. Пример двух команд из Motorola предполагает наличие корреляции между увеличением времени выполнения и снижением качества. Похоже, что увеличение времени выполнения оборачивается существенно худшим качеством. В нашем случае увеличение среднего времени выполнения в 6,5 раза повлекло за собой более чем тридцатикратное увеличение первичных ошибок. Более долгое время выполнения связано с увеличением количества незавершенных задач. После выявления этого примера я стал использовать незавершенные задания как средство контроля качества и убедился в наличии взаимосвязи между их количеством и исходным качеством кода. Однако на момент написания этой книги не существует научных подтверждений этого эмпирически полученного результата.
Снижение количества незавершенных задач, или сокращение продолжительности итерации, оказывает серьезное влияние на исходное качество. Судя по всему, отношение между количеством незавершенных задач и исходным качеством нелинейно, то есть ошибки растут непропорционально увеличению количества незавершенных задач. Таким образом, видимо, двухнедельные итерации лучше четырехнедельных, а недельные еще лучше. Более короткие итерации повышают качество.
Логика представленных свидетельств подсказывает, что имеет смысл ограничить число незавершенных задач при помощи канбан-системы. Если мы знаем, что управление незавершенными задачами пойдет на пользу качеству, то почему бы не прописать формальные правила ограничения их количества, тем самым высвободив менеджеров для другой деятельности?
Из тесной взаимосвязи между незавершенными задачами и качеством следует, что этап 2 нашего рецепта должен внедряться параллельно с этапом 1 или сразу после него.
Кто лучше?
Я вмешался в деятельность команды разработки сервера закачек OTA в рождественскую неделю 2003 года и сообщил ведущему программисту, что незавершенных задач слишком много, время разработки велико, а завершено на самом деле не так много. Я посетовал, что все это приведет к потерям в качестве. Мои опасения были услышаны, и в январе 2004 года в работе команды появились некоторые изменения. В итоге в 2004 году сократились и незавершенные задачи, и время выполнения. Однако эти перемены произошли слишком поздно: команда уже успела наделать много ошибок.
Согласно диаграмме, проект был завершен примерно в середине марта 2004 года, но на самом деле команда продолжала работу над программами до середины июля. Половина команды разработчиков OTA DM были отозваны со своего проекта, чтобы помочь в работе над ошибками. В июле 2004 года руководитель бизнес-подразделения объявил продукт готовым, несмотря на то что не был уверен в его качестве. Продукт перешел к команде поддержки. За это время 50 % клиентов отменили заказы, усомнившись в качестве продукта. Хотя члены команды поддержки сохраняли хорошие личные отношения с разработчиками продукта, они разуверились в их профессионализме. По их мнению, продукт был плох, а разработчики оказались ни на что не способны.
Как ни странно, если бы в то время кто-то из посторонних спросил разработчиков: «Кто здесь самый умный?» – они указали бы на одного из членов той самой злополучной команды. Такую же реакцию вызвал бы вопрос «У кого здесь больше всего опыта?». Проанализировав резюме, вы убедились бы, что средний опыт команды разработчиков сервера закачек превосходил опыт команды, отвечавшей за управление устройствами, на три года. По бумагам выходило, что команда сервера закачек лучше. И некоторые из ее членов до сих пор в этом уверены, несмотря на множество свидетельств обратного.
Как опытный менеджер и наставник я могу сказать, что некоторые члены команды по управлению устройствами имели низкую профессиональную самооценку и сожалели, что не обладают одаренностью ребят из другой команды. Однако в реальности их производительность оказалась в пять с половиной раз выше, а исходное качество превосходило качество работы команды сервера закачек более чем в тридцать раз. Правильные процедуры, отличная дисциплина, сильный менеджмент и лидерство сделали свое дело. Этот пример подтверждает: необязательно обладать лучшими сотрудниками, чтобы выдавать результат мирового класса. Некоторые участники agile-сообщества уверены (хотя я считаю такой подход «снобизмом мастеров»): для успеха в гибкой разработке нужна лишь небольшая команда настоящих профессионалов. Однако в моем случае команда людей совершенно разного уровня смогла достичь великолепного результата.
Частые релизы порождают доверие
Сокращение незавершенных задач снижает время выполнения. Уменьшение времени выполнения делает возможными более частые релизы работающего кода. Частые релизы порождают доверие со стороны внешних команд, особенно отдела маркетинга и спонсоров. Определить доверие довольно трудно. Социологи называют его социальным капиталом. Они выяснили, что доверие зависит от текущих событий и что небольшие, но часто происходящие действия укрепляют доверие сильнее, чем крупные поступки, которые совершаются от случая к случаю.
Когда я рассказываю об этом в аудитории, я всегда спрашиваю девушек, о чем они думают после первого свидания. Предлагаю такую ситуацию: свидание понравилось, но парень не звонит уже две недели. После этого он появляется на пороге с букетом цветов и извинениями. Я прошу сравнить его поведение с поступком человека, который уже по дороге домой посылает первое СМС: «Отлично провел вечер, очень хотел бы встретиться снова. Позвоню завтра?» – а затем действительно звонит. Кого выберет девушка? Часто казалось бы малозначительные поступки вызывают больше доверия к человеку, чем яркие, но совершаемые от случая к случаю.
Так обстоит дело и с разработкой ПО. Небольшие, но частые и высококачественные релизы создают больше доверия у команд партнеров, чем пространные, но более редкие.
Мелкие релизы показывают, что команда разработчиков способна получать результат и создавать ценности. Они вызывают доверие у команды маркетологов и спонсоров. Высокое качество разработанного кода успокаивает также и партнеров по дальнейшей работе – операционный отдел, техподдержку, интеграторов и подразделение продаж.
Неявное знание
Довольно легко понять, почему маленькие порции кода идут на пользу качеству. Сложность задач, связанных с познанием, экспоненциально возрастает с увеличением незавершенных задач. А наш мозг усиленно пытается справиться с этой сложностью. В области разработки ПО большое количество знаний и информации передается неявно – это происходит во время совместной работы. Информация является вербальной и визуальной, но поставляется в своеобразном формате – например, в виде рисунка на доске. У нашего мозга ограниченны возможности хранения этих неявных знаний, и они начинают забываться. Мы не можем припомнить точных деталей и делаем ошибки. Если все члены команды доступны друг для друга, то такие ошибки памяти можно исправить, запрашивая уточнения или обращаясь к коллективной памяти группы. Поэтому гибкие команды, работающие в одном и том же месте, имеют больше шансов сохранять неявные знания. Однако ценность таких знаний со временем уменьшается, поэтому для связанных с ними процессов необходимо сокращать время выполнения. Мы знаем, что уменьшение незавершенных задач напрямую связано с сокращением времени выполнения. Поэтому можно предположить, что неявные знания будут обесцениваться медленнее при уменьшении количества незавершенных задач, что приведет и к более высокому качеству.
Нужно отметить, что сокращение незавершенных задач повышает качество и дает возможность более часто выпускать релизы. Более частые релизы высококачественного кода, в свою очередь, укрепляют доверие со стороны внешних команд.
Баланс между нагрузкой и пропускной способностью
Сохранение баланса между нагрузкой и пропускной способностью подразумевает, что мы сами задаем темп приема новых задач в разработку, который должен соответствовать скорости выдачи рабочего кода. Тем самым мы эффективно доводим количество незавершенных задач до необходимого показателя. Когда работа завершается, мы вытягиваем новую работу (или требования) от тех, кто формирует нагрузку. Поэтому любое обсуждение приоритетов и принятия обязательств по новым задачам может происходить лишь в контексте завершения выполнения какого-либо существующего объема текущей работы.
Эти изменения дают глубокий эффект. Пропускная способность этапов процесса будет ограничена уязвимыми местами. Вы вряд ли сразу же выявите их. Более того, если вы поговорите со всеми участниками цепочки создания ценности, то они, вероятнее всего, заявят о сильной перегруженности работой. Однако как только удастся сбалансировать нагрузку и пропускную способность и ограничить число незавершенных задач в своей цепочке ценностей, произойдет чудо. Полностью загруженными окажутся лишь уязвимые места – так называемые бутылочные горлышки. Остальные участники цепочки создания ценности вскоре почувствуют, что у них появились свободное время и силы. И даже те, кто работает на уязвимых участках, почувствуют, что работать стало легче. Возможно, впервые за долгие годы ваша команда перестанет чувствовать изнеможение и у многих сотрудников появится наконец давно забытое ощущение свободного времени.
Создание резерва времени
Благодаря резерву времени на организацию приходится меньше стресса, и сотрудники могут сосредоточиться на качестве выполнения работ. Теперь они смогут гордиться своей работой и еще сильнее наслаждаться этими ощущениями. Обладатели свободного времени начнут тратить его на совершенствование – пойдут на курсы или просто сделают уборку на своем рабочем месте. Нередко в этом случае люди стараются заниматься совершенствованием своих навыков, рабочих инструментов, отношений с коллегами, находящимися вниз и вверх по цепочке ценностей. Со временем одно небольшое улучшение будет следовать за другим, и команда начнет производить впечатление постоянно совершенствующейся. Изменится ее культура. Резерв времени, созданный благодаря ограничению количества незавершенных задач и согласию на новую работу только при наличии соответствующих возможностей, радикально улучшит ситуацию в команде.
Чтобы обеспечить постоянное совершенствование, необходимы резервы. Для их создания нужно сохранить баланс требований и пропускной способности и ограничить количество незавершенных задач.
Люди интуитивно стремятся заполнить свободное время. Поэтому после ограничения количества незавершенных задач и установления баланса между требованиями и пропускной способностью появится тенденция «поддержания равновесия» за счет перераспределения ресурсов, когда все сотрудники на равных заняты в рабочем процессе. Хотя это выглядит очень эффективным решением, удовлетворяющим представлениям об управлении в XXI веке, на самом деле оно замедляет создание культуры совершенствования. Для нее необходимо свободное время. Чтобы оно появлялось, цепочка создания ценности должна быть несбалансированной и содержать бутылочные горлышки. Оптимизация ради использования всех ресурсов нежелательна.
Расстановка приоритетов
Если первые три пункта рецепта внедрены, то дальше все пойдет без сучка без задоринки. Высококачественный код должен выдаваться часто, время выполнения разработки стать относительно коротким, а число незавершенных задач – ограниченным. Новые задания должны поступать в разработку только после того, как сдаются предыдущие и освобождается место. В это время внимание руководства переключается на оптимизацию создаваемых ценностей, а не только на объемы создаваемого кода. Нет смысла сосредоточиваться на расстановке приоритетов, пока выработка непредсказуема. Зачем тратить силы на приоритеты поступления, если это не скажется на конечном результате? Пока эта проблема не решена, лучше использовать драгоценное время на достижение предсказуемости и качества выполнения работ. Уделить внимание расстановке приоритетов задач стоит лишь тогда, когда вы убедитесь, что действительно можете выполнять задачи примерно в том же порядке, в котором они поступают.
Влияние
Расстановкой приоритетов не должна заниматься техническая организация: этот процесс находится вне зоны влияния технического руководства. Чтобы улучшить расстановку приоритетов, владельцу продукта, спонсору или отделу маркетинга следует изменить свое поведение. Технические управленцы могут искать рычаги влияния только после того, как все приоритеты уже установлены.
Чтобы появился достаточный политический и социальный капитал для воздействия на изменения, необходим определенный уровень доверия. Если ваша команда неспособна постоянно выдавать высококачественный код, то ни о каком доверии не может быть и речи. Такая команда имеет мало шансов повлиять на расстановку приоритетов и тем самым оптимизировать ценности, создаваемые в процессе разработки.
В последнее время в agile-сообществе модно говорить об оптимизации бизнес-ценности и о том, что объем выпуска рабочего кода (так называемая скорость разработки ПО) – не такой уж важный показатель. Это потому, что истинное мерило успеха – объем поставленной бизнес-ценности. В конечном счете так и есть, но важно не забывать, что команда должна растить свою зрелость. Большинство организаций неспособны измерить созданную бизнес-ценность и отчитаться по ней. Сначала им следует овладеть базовыми навыками, а уже потом браться за более серьезные вызовы.
Рост зрелости
Я считаю, что команда должна расти таким образом. Сначала следует научиться создавать высококачественный код. Затем сокращается количество незавершенных задач и, соответственно, время выполнения, более частыми становятся релизы. После этого поддерживается баланс нагрузки и пропускной способности, ограничиваются незавершенные задачи, создается резерв времени, что ведет к совершенствованию. Когда процесс разработки программ начинает идти гладко и со временем оптимизируется, улучшается и процесс расстановки приоритетов, что приводит к оптимизации создания ценности. Надежды на оптимизацию бизнес-ценности – это только мечты. Прежде всего примите меры для постепенного взросления коллектива, следуя рецепту успеха.
Атака на источники вариативности для улучшения предсказуемости
Как последствия вариативности, так и борьба с ней в процессе работы – это сложные понятия. Сокращение вариативности в разработке ПО требует от сотрудников изменений в их рабочем процессе – они должны освоить новые техники и изменить личное поведение. Все это непросто, а потому не подходит для новичков и незрелых организаций.
Вариативность приводит к большому количеству незавершенных задач и увеличению времени выполнения. Подробнее об этом читайте в главе 19. Вариативность порождает необходимость в резервах времени вне бутылочных горлышек, чтобы справиться с неустойчивым объемом работы: вариативность воздействует на объем работы, идущий через цепочку создания ценности. Чтобы глубже разобраться в том, почему так происходит, нужно обладать определенными познаниями в системе статистического контроля процессов и теории массового обслуживания, что выходит за рамки этой книги. Мне, например, нравится работа Дональда Уилера и Дональда Рейнертсена о вариативности и массовом обслуживании, так что, если вы хотите узнать об этом больше, начните с нее.
Пока же примите на веру положение о том, что вариативность в размерах задач, требующих усилий на анализ, дизайн, программирование, тестирование, сборку и выдачу релиза, отрицательно влияет на пропускную способность процесса и накладных расходов цепочки создания ценности в разработке ПО.
Однако ряд источников вариативности непосредственно вшит в производственный процесс вследствие неудачного выбора правил работы. Пример в главе 4 рассказывает о некоторых из них: это ежемесячное перепланирование, соглашение о предоставлении услуг, основанное на оценках, приоритет текстовых, то есть не требующих пересборки продукта, изменений в производстве. Все три приведенных примера – это результат работы по правилам, которые нужно изменить. Простое изменение существующих правил может значительно сократить число источников вариативности, влияющих на предсказуемость.
Рецепт успеха и канбан
Канбан делает возможными все шесть этапов рецепта успеха и обеспечивает его реализацию, а рецепт успеха создает доверие к внедряющему его менеджеру. В свою очередь, рецепт успеха иллюстрирует ценность Канбана.
Выводы
• Канбан делает возможным реализацию всех составляющих рецепта успеха.
• Рецепт успеха объясняет ценность Канбана.
• Плохое качество – это главный источник потерь в разработке ПО.
• Снижение количества незавершенных задач повышает качество продукта.
• Повышение качества порождает доверие у сотрудников ниже по цепочке создания ценности – например, операционных инженеров.
• Частый выход релизов порождает доверие со стороны сотрудников выше по цепочке создания ценности – например, отдела маркетинга.
• Вытягивающая система может сбалансировать нагрузку и пропускную способность.
• Вытягивающие системы выявляют бутылочные горлышки и создают резервы времени и усилий в остальных местах.
• Качественная расстановка приоритетов максимизирует производительность цепочки создания ценности в разработке ПО.
• Расстановка приоритетов сама по себе мало значит без хорошего изначального качества и предсказуемости производственной системы.
• Чтобы внести изменения для сокращения вариативности, требуются резервы.
• Сокращение вариативности снижает потребность в резервах.
• Сокращение вариативности позволяет сбалансировать ресурсы (а в дальнейшем, возможно, и сократить численный состав команды).
• Сокращение вариативности снижает требования к ресурсам.
• Сокращение вариативности позволяет уменьшить количество канбан-жетонов, незавершенных задач и приводит к снижению среднего времени выполнения.
• Появление резервов создает возможности для улучшения.
• Усовершенствование процесса ведет к повышению производительности и предсказуемости.
Глава 4 От худшего к лучшему за пять кварталов
В октябре 2004 года Драгош Думитриу был менеджером программ в Microsoft. Он только что возглавил отдел, который имел репутацию худшего IT-подразделения компании.
Должность «менеджер программ» в Microsoft примерно соответствует тому, что в других местах называют менеджером проектов, но обычно включает также некоторую ответственность за анализ и архитектуру. Менеджер программ назначается на инициативу, проект или продукт и отвечает за часть функционала. Чтобы выполнить работу, он привлекает ресурсы из функциональных областей, например разработки и тестирования. Драгош отвечал за техническое обеспечение ПО для бизнес-подразделения XIT. Эта команда (рис. 4.1), зрелость процессов которой оценивалась как CMMI Model Level 5, располагалась в Индии и состояла из трех разработчиков, трех тестировщиков и менеджеров, занимавшихся разработкой небольших обновлений и устранением ошибок примерно в 80 кроссфункциональных IT-приложениях, используемых сотрудниками Microsoft по всему миру. Сам Драгош находился в кампусе в Редмонде. В то же самое время там работал и я.
Рис. 4.1. Команда в Хайдарабаде (Индия). Драгош – четвертый слева
Проблема
Драгош сам вызвался возглавить команду, которая имела худшую репутацию в Microsoft с точки зрения клиентского обслуживания. В круг его обязанностей как агента изменений входило решение проблем длительного времени выполнения задач и плохо сформулированных, из-за сложившейся в компании конъюнктуры, ожиданий заказчиков. Некоторые из его предшественников на этой должности продолжали работать в компании с другими проектами того же подразделения. Они опасались, что если ему удастся улучшить производительность команды, то они будут выглядеть неудачниками.
Программисты и тестировщики этой организации следовали методологии PSP/TSP (Personal Software Process / Team Software Process). Такие требования компании Microsoft были записаны в контракте. Джон Де Ваан в то время – непосредственный подчиненный Билла Гейтса и большой поклонник Уоттса Хамфри из Института программной инженерии. Как глава Engineering Excellence в Microsoft, он мог требовать от IT-отдела и его поставщиков соблюдения определенных процедур. Поэтому изменение метода жизненного цикла разработки ПО было невозможным.
Драгош понял, что основная причина их проблем не в методе PSP/TSP и не в рейтинге зрелости организации. Более того, команда производила почти все, что от нее требовалось, с высоким качеством. Однако время выполнения запросов на изменения доходило до пяти месяцев и вместе с объемом бэклога продолжало бесконтрольно увеличиваться. Создавалось ощущение плохо организованной и почти неуправляемой команды. Высшее руководство не спешило выделять дополнительные средства на решение этой проблемы. Итак, сдерживающие факторы для изменений были связаны с политикой, финансами и правилами компании. Он обратился ко мне за помощью.
Визуализация рабочего процесса
Я попросил Драгоша сделать изображение рабочего процесса. Он набросал схему, в которой описывался жизненный цикл для запроса изменений, после чего мы обсудили проблему. Рис. 4.2 – это факсимиле того, что он сделал. Фигурка PM (менеджера программ) изображает Драгоша.
Рис. 4.2. Изначальный рабочий процесс технического обеспечения в XIT с указанием времени выполнения Initial
Поступление запросов было бесконтрольным. Четыре менеджера продукта представляли и контролировали бюджеты для ряда клиентов, которые владели приложениями, обслуживаемыми XIT. Они добавляли новые запросы и дефекты, выявленные в процессе промышленной эксплуатации.
Эти ошибки были внесены не командой техподдержки, а проектными командами разработки приложений. Такие команды обычно прекращают свое существование через месяц после выхода новой системы, а исходный код переходит к команде техподдержки.
Факторы, влияющие на производительность
Когда поступал запрос, Драгош отправлял его на оценку в Индию. Согласно регламенту, оценку нужно было произвести и представить владельцам бизнеса в течение 48 часов. Так было легче вычислить ROI (прибыли на инвестицию) и принять решения по запросу. Раз в месяц Драгош встречался с менеджерами продукта и другими заинтересованными лицами: проводилась новая расстановка приоритетов в бэклоге и составлялся план проекта по запросам.
В то время в месяц обрабатывалось около семи запросов. В бэклоге было более 80 записей, и его объем продолжал увеличиваться. Таким образом, ежемесячно подвергались переоценке более 70 запросов, а обработка запроса занимала в среднем четыре месяца. В этом и крылась основная причина неудовлетворительной работы. Сами запросы были небольшими, но постоянное изменение приоритетов означало стабильную неудовлетворенность клиентов.
Запросы фиксировались при помощи инструмента под названием Product Studio. Обновленная версия этой программы была впоследствии выпущена под названием Team Foundation Server Work Item Tracking. Команда техподдержки XIT представляла собой хорошо мне знакомый тип организации, в которой имеется множество данных, но они не используются. Драгош начал анализировать данные и обнаружил, что средний запрос занимал 11 рабочих дней.
Время выполнения при этом составляло от 125 до 155 дней, более 90 % времени тратилось впустую, в том числе на ожидание в очереди.
Оценки поступающей работы отнимали много ресурсов. Мы решили проанализировать процесс оценки, сделав ряд предположений. Хотя аббревиатура ROM расшифровывается как rough order of magnitude (приблизительный порядок величины), клиенты ожидали, что оценка будет очень точной, и члены команды проводили ее с особой тщательностью. У каждого разработчика и тестера одна оценка занимала примерно рабочий день. Мы подсчитали, что на это уходило около 33 % ресурсов команды, а в неудачный месяц – и 40 % рабочего времени, то есть больше, чем на разработку и тестирование. К тому же оценка новых запросов нередко вносила путаницу в планы, составленные на текущий месяц.
Помимо запросов на изменения у команды имелся и второй вид работ – так называемые текстовые изменения на продуктивной среде (Production text changes, PTC), касающиеся интерфейса, редакционных исправлений, изменения данных таблиц или xml-сообщений. Эти изменения не требовали участия разработчиков и часто вносились владельцами бизнеса, менеджерами продукта или программ. Но поскольку они подвергались формальной тестовой приемке, участие тестировщиков было все же необходимо.
PTC традиционно выполнялись прежде всей остальной работы или оценок. PTC поступали неравномерными порциями и тоже нарушали планы на месяц (рис. 4.3).
Рис. 4.3. Рабочий процесс, демонстрирующий оценки ROM и внесение PTC
Установление явных процедурных правил
Команда следовала предписанным процедурам, которые, к сожалению, содержали и неудачные решения, принятые менеджерами на различных уровнях. Важно помнить, что процесс – это набор правил, управляющих поведением, которые находятся под контролем руководства. Например, решение использовать PSP/TSP приняли на уровне вице-президента, то есть всего рангом ниже Билла Гейтса. Такое правило отменить тяжело или невозможно. Но другие правила, например приоритет оценок перед написанием кода и тестированием, были разработаны непосредственными руководителями на местах. Возможно, эти правила имели смысл, когда их внедряли. Но обстоятельства изменились, однако никто не попытался пересмотреть и обновить правила, по которым работала команда.
Оценка была пустой тратой времени
Побеседовав с коллегами и менеджером, Драгош решил внедрить в управление два важных изменения. Во-первых, команда перестала производить оценку. А те усилия, которые прежде тратились на нее, нужно было направить на разработку и тестирование ПО. Исключив этот фактор, вносивший к тому же хаос в рабочее расписание, Драгош надеялся повысить предсказуемость и, как следствие, – удовлетворенность клиентов.
Однако отказ от оценок вызвал целый ряд проблем. Он влиял на подсчет ROI, кроме того, клиенты могли заподозрить возможность неправильной расстановки приоритетов. К тому же оценки облегчали учет затрат и перераспределение бюджета между отделами, использовались для внедрения общих организационных принципов. В команду техподдержки поступали только небольшие запросы. Крупные, разработка или тестирование которых превышали 15 дней, должны были стать частью большого проекта и пройти все формальные процедуры управления портфелем проектного офиса (PMO). Вскоре мы вернемся к этому вопросу.
Ограничение задач в работе (WIP)
Еще одно изменение, задуманное Драгошем, – это ограничение числа задач в работе и вытягивание новых задач из очереди только после завершения старых. Он решил ограничить разработку одним запросом на разработчика, такой же норматив был установлен для тестировщиков.
Добавив очередь для получения PTC, он обеспечил равномерный поток работы между разработкой и тестированием, что показано на рис. 4.4. Этот подход – использование буфера для снижения вариативности размеров и усилий – обсуждается в главе 19.
Примечание. Это установленное правило: одна задача на одного разработчика в любое время. Позже правило может быть изменено. Представление процесса как набора правил – ключевой элемент Канбан-метода.
.
Рис. 4.4. Модель состояний, показывающая желаемый поток работ с ограничением незавершенной работы
Установление каденции пополнения
Примечание. Каденция – это понятие Канбан-метода, которое определяет ритм событий определенного типа. Расстановка приоритетов, поставка, ретроспективы и все повторяющиеся события могут иметь собственную каденцию.
Чтобы облегчить принятие решения об ограничении задач в работе и переходе на вытягивающую систему, Драгош должен был подумать о каденции взаимодействий с менеджерами продукта. Он посчитал, что еженедельное совещание – оптимальный вариант, поскольку его тема – пополнение входящей очереди производственной системы из бэклога. Обычно в течение недели освобождались три места в очереди, поэтому следовало обсуждать вопрос «Какие три элемента бэклога вы бы предпочли отправить сейчас в разработку?». Каденция моделируется на рис. 4.5.
Рис. 4.5. Рабочий процесс с Канбаном: ограничение задач в работе и очереди
Он хотел предложить «гарантированное» время выполнения – 25 дней с момента попадания задачи во входящую очередь. Конечно, 25 больше, чем 11. А на некоторые задачи требовалось до 30 дней. Но Драгош решил, что таких заданий не должно быть много. И, кроме того, 25 – это гораздо меньше, чем 140, а именно столько дней составлял текущий срок выполнения работ. Он рассчитывал добиться цели благодаря регулярности поставок, построению доверительных отношений с менеджерами продукта и их клиентами.
Достижение нового соглашения
Драгош сделал менеджерам продукта предложение – попросил примириться с тем, что они будут встречаться раз в неделю и обсуждать приоритеты, он ограничит количество незавершенной работы, а его команда перестанет заниматься оценкой. В обмен на это он сократит время выполнения до 25 дней и будет в дальнейшем ориентироваться на этот дедлайн.
Клиентам предложили отказаться от вычисления ROI и переводов бюджета между отделами на основе оценки планируемых трудозатрат. В обмен на это им пообещали беспрецедентно короткие сроки выполнения и надежность. Для удобства расчетов время обработки запроса – примерно 11 дней – устанавливалось на основании исторических данных, о чем говорилось выше, в разделе «Факторы, влияющие на производительность». Также их попросили считать затраты фиксированными и игнорировать ту калькуляционную парадигму, на которой ранее основывались переводы бюджета между отделами.
Драгош обосновывал эти перемены так: у организации-поставщика есть годичный контракт, по которому она ежемесячно выставляет счет. В соответствии с контрактом поставщик привлекает людей, получающих зарплату независимо от того, работают они в данный момент или нет. Бюджет, поступающий от четырех менеджеров продукта, – это фиксированная сумма, распределяемая пропорционально. Драгош гарантировал, что каждому менеджеру продукта достанется справедливая доля. Это освободит их от необходимости отслеживать каждый запрос. Если они смогут принять тот факт, что доллары приносят им гарантированный результат, то, возможно, откажутся от предубеждения против приблизительной оценки трудозатрат и переводов бюджета. Чтобы определить, чья очередь подходит, разработали несколько простых правил, поэтому распределение осуществлялось справедливо. Достаточно было простой круговой схемы с весовыми коэффициентами.
Внедрение изменений
Хотя менеджеры продукта и многие коллеги Драгоша по XIT оставались скептиками, они решили дать ему возможность попробовать. В конце концов, дела шли хуже некуда. Нужно было что-то предпринять, и Драгошу поручили внести изменения.
Итак, изменения начались.
И все наладилось! Запросы обрабатывались и выводились в новых релизах. Время выполнения по новым обязательствам укладывалось в обещанный 25-дневный срок. Ежедневные совещания работали как часы, пополнение производственной системы задачами тоже происходило каждую неделю. Менеджеры продукта стали проникаться доверием к команде.
Адаптация правил
Примечание. Это распространенная тема в канбан-методе. Сочетание четких правил, прозрачности и визуализации дает членам команды возможность принимать собственные решения и самостоятельно оценивать риски. Руководство в итоге начинает доверять системе, поскольку понимает, что процесс – это набор правил, которые предназначены для управления рисками и удовлетворения пользовательских ожиданий. Эти правила прописаны, работа открыто визуализируется, а все члены команды понимают правила и принципы их применения.
Но каким образом достигалась расстановка приоритетов, если подсчет ROI больше не проводился? Оказалось, что он и не нужен. Если элемент важен и ценен, то его выбирали из очереди в бэклоге, а если нет, то отодвигали дальше. Позже Драгош понял, что необходимо еще одно правило – безжалостно удалять из бэклога любой элемент более чем шестимесячной давности. Если за полгода о нем ни разу не вспомнили, то наверняка он не имеет никакого значения. А если выяснится, что данный элемент все же важен, то его можно включить заново.
А как насчет правила, согласно которому крупные запросы не поступали в техподдержку, а становились частью большого проекта? В итоге решили, что некоторые из них все же могут туда направляться. Опыт показывал, что таких запросов обычно менее 2 %. Разработчиков просили быть внимательными и, если новый запрос, по их оценкам, требовал на обработку более 15 дней, предупреждать своего менеджера. Риски и затраты в данном случае составляли менее 1 % доступной мощности. Это прекрасно окупалось: отказавшись от оценок, команда обрела более 33 % мощности за счет затрат менее 1 % той же мощности. Это новое правило позволило разработчикам управлять рисками и при необходимости высказывать свое мнение!
На первые два изменения отвели шесть месяцев. В течение этого периода внесли еще кое-какие незначительные улучшения. Как уже упоминалось, появилось правило очищения бэклога, а еженедельное совещание с владельцами продукта исчезло. Процесс протекал так гладко, что Драгош автоматизировал инструмент Product Studio: теперь он получал электронное сообщение каждый раз, когда образовывалось свободное место для нового задания. После этого Драгош предупреждал по электронной почте владельцев продукта, что им необходимо решить, за какое задание браться прежде всего. Производился выбор, и запрос из бэклога работы переводился в очередь через два часа после того, как появлялось свободное место.
Поиск дальнейших улучшений
Драгош начал искать способы для дальнейших улучшений. Изучив данные о продуктивности тестировщиков его команды и сравнив их с показателями других команд XIT от того же подрядчика, он заподозрил, что тестировщики располагают существенными резервами. Между тем звено разработчиков можно было назвать настоящим узким местом. Драгош решил навестить команду в Индии и, возвратившись, посоветовал подрядчику перераспределить ресурсы. Число тестировщиков сократили с трех до двух, но добавили дополнительного разработчика (рис. 4.6). Это привело к практически линейному увеличению производительности: пропускная способность за квартал повысилась с 45 до 56.
Рис. 4.6. Перераспределение ресурсов
Финансовый год Microsoft подходил к концу. Высшее руководство заметило значительный рост производительности и стабильности результатов команды техподдержки XIT.
Руководители наконец-то поверили в Драгоша и его методы. Отделу были выделены средства, чтобы нанять еще двух сотрудников. В июле 2005 года в команде появились новый разработчик и тестировщик. Результаты оказались существенными.
Рис. 4.7. Добавление ресурсов
Результаты
Дополнительная мощность позволила пропускной способности превысить требования. В результате бэклог 22 ноября 2005 года оказался полностью исполнен. К тому времени команда сократила срок выполнения в среднем до 14 дней при сохранении 11-дневного периода разработки. Выполнение 25-дневного дедлайна составляло 98 %. Пропускная способность увеличилась более чем втрое, время выполнения сократилось на 90 % и выше, а надежность программ примерно на столько же выросла. В процессы разработки ПО и тестирования не было внесено никаких изменений. Метод PSP/TSP остался неизменным, все корпоративные нормы, процедуры и контрактные обязательства строго соблюдались. Во второй половине 2005 года команда стала лучшей среди всех инженерных коллективов корпорации. Драгош получил дополнительные полномочия, а текущее руководство команды перешло к региональному менеджеру в Индии, который, впрочем, перебрался в Вашингтон.
Рис. 4.8. Квартальная пропускная способность на единицу производства
Эти улучшения отчасти стали возможны благодаря невероятным управленческим способностям Драгоша Думитриу, но главной причиной успеха послужили типовые элементы – формирование цепочки создания ценности, анализ потока, задание лимита задач в работе и внедрение вытягивающей системы. Без парадигмы потока и канбан-подхода к ограничению задач в работе выигрыш в производительности был бы невозможен. Благодаря Канбану произошли постепенные изменения, притом с низким политическим риском и уровнем сопротивления изменениям.
Пример XIT показывает, как вытягивающую систему с ограничением незавершенной работы можно применить к распределенному проекту с удаленной командой и как в этом помогает электронная система управления задачами.
Никакой визуализации еще не было, и многие более сложные приемы Канбан-метода, описанные в этой книге, в то время не существовали.
Рис. 4.9. Время выполнения командой техподдержки XIT по финансовым годам Microsoft
Но какой менеджер проигнорирует возможность увеличить производительность более чем на 200 %, сократить время выполнения на 90 % и существенно повысить предсказуемость при минимальных политических рисках и сопротивлении изменениям?
Выводы
• Первая канбан-система была внедрена в команде техподдержки XIT в Microsoft в 2004 году.
• Первая канбан-система использовала ПО для отслеживания работы.
• Первая канбан-система была внедрена в удаленной команде подрядчика в Хайдарабаде, которая стояла на пятом уровне в модели зрелости CMMI.
• Рабочий поток требуется описать и визуализировать.
• Процесс следует описывать как явно заданный набор правил.
• Канбан способствует постепенным изменениям.
• Канбан минимизирует политические риски при внесении изменений.
• Канбан минимизирует сопротивление изменениям.
• Канбан предоставляет возможности совершенствования, которые не предполагают сложных изменений в инженерных методах.
• Первая канбан-система показала более чем 200 %-ное увеличение производительности, 90 %-ное снижение времени выполнения и примерно такое же увеличение предсказуемости поставки.
• Значительные изменения становятся возможными благодаря управлению узкими местами, исключению потерь времени и снижению вариативности, которая негативно влияет на ожидания и удовлетворенность клиента.
• Чтобы изменения привели к результату, нужно время. В данном случае понадобилось 15 месяцев.
Глава 5 Культура постоянного совершенствования
В японском языке слово «кайдзен» дословно значит «постоянное совершенствование». Корпоративная культура, в которой все сотрудники сосредоточены на непрерывном повышении качества, производительности и удовлетворенности клиентов, известна как культура кайдзен. На самом деле подобной культуры удалось добиться очень немногим корпорациям. Такие компании, как Toyota, в которых доля участия сотрудников в программе совершенствования приближается к 100 % и где один сотрудник вносит в среднем одно внедряемое предложение по улучшению в год, очень редки.
В мире разработки ПО Институт технологий разработки ПО (SEI) Университета Карнеги – Меллон определяет высший уровень своей интегрированной модели зрелости процессов ПО (CMMI) как оптимизирование. Оптимизирование предполагает, что качество работы и производительность организации подвергаются постоянному совершенствованию. Хотя CMMI мало уделяет внимание корпоративной культуре и ничего об этом не говорит, достижение оптимизирующего поведения в организации более всего возможно в культуре кайдзен.
Культура кайдзен
Чтобы понять, почему так сложно добиться установления кайдзен, нужно разобраться, что это за культура и как она проявляется. Только после этого можно решить, нужна ли она нам и в чем ее преимущества.
В культуре кайдзен каждый сотрудник наделен полномочиями. Люди могут действовать свободно, по своему усмотрению. Они свободно дискутируют о проблемах, вариантах решения, внедряют поправки и улучшения. В культуре кайдзен сотрудники ничего не боятся. Нормой считается толерантность руководства к неудачам, если эксперименты и инновации проводятся во имя совершенствования процессов и общей производительности. В культуре кайдзен сотрудники свободно (с некоторыми ограничениями) самоорганизовываются для решения порученных задач и выполняют их так, как считают нужным. Визуальный контроль и сигналы присутствуют в явном виде, а рабочие задания обычно раздаются желающим, а не по усмотрению руководителя. Культура кайдзен предполагает высокий уровень сотрудничества и атмосферу коллегиальности, когда каждый работник ставит производительность команды и компании в целом выше собственных результатов. Культура кайдзен сосредоточена на системном мышлении даже при внедрении незначительных локальных улучшений, поскольку они повышают общую производительность.
Кайдзен обладает высоким уровнем социального капитала. Это культура высокого доверия, поскольку сотрудники независимо от своего служебного положения уважают друг друга и ценят вклад любого работника. При высокой степени доверия структура обычно менее вертикальная, чем при его низком уровне. А ведь именно уровень наделения полномочиями позволяет горизонтальным структурам работать эффективно. Таким образом, достижение культуры кайдзен может привести к исключению бессмысленных стадий руководства, что в итоге снизит координационные издержки.
Многие аспекты культуры кайдзен противоречат общепринятым нормам в современной западной культуре, где нас готовят к конкурентной борьбе. Наша система образования поощряет соперничество и в академической успеваемости, и в спорте. Даже в командных видах спорта часто находят героев, и команды строятся вокруг одного-двух исключительных талантов. Общественная норма сосредоточивается в первую очередь вокруг личности, которая призвана приносить победу или спасать нас от опасности. Неудивительно, что на рабочем месте мы испытываем большие трудности с внедрением корпоративного поведения или системного мышления и сотрудничества.
Канбан повышает зрелость и возможности организации
Канбан-метод призван свести к минимуму первичное влияние перемен и снизить сопротивление им. Переход на Канбан должен изменить культуру компании и помочь ей повзрослеть. Если переход проводится правильно, то организация будет охотно принимать и внедрять изменения, что приведет к совершенствованию процессов. SEI в рамках модели CMMI называет эту способность инновациями и перегруппировкой организации (OID){15}. Доказано{16}, что организации, достигшие столь высокого уровня в управлении переменами, могут перейти на agile-методы, например Scrum, быстрее и легче, чем менее зрелые компании.
При первом внедрении Канбана вы ищете способы оптимизировать существующие процессы и изменить культуру организации, не собираясь полностью переключаться на другие процессы, которые способны принести существенные экономические выгоды. Это дает повод для критики{17}: некоторые утверждают, что Канбан занимается оптимизацией того, что нужно попросту изменить. Однако существуют серьезные эмпирические доказательства{18} того, что Канбан ускоряет достижение высокого уровня зрелости и компетентности в отраслях, рассчитанных на зрелые организации, – таких как причинный анализ (CAR), а также инновации и перегруппировка организации.
Если вы хотите использовать Канбан для внесения изменений в вашу компанию, то тем самым подписываетесь под утверждением, будто лучше оптимизировать что-то уже существующее, поскольку это проще, быстрее и не встретит серьезного сопротивления в отличие от инициативы сверху, ведущей к радикальным переменам. Такие перемены гораздо сложнее, чем постепенное улучшение существующей системы. Нужно также учитывать, что Канбан основан на сотрудничестве, а это приведет к существенному сдвигу в сторону зрелости организации. Этот сдвиг станет отправной точкой для более серьезных перемен, которые встретят гораздо меньшее сопротивление, чем при немедленном внедрении. Переход на Канбан – это долгосрочные инвестиции в компетентность, зрелость и культуру организации. Канбан не является средством сиюминутного решения проблем.
КЕЙС: РАЗРАБОТКА ПРИЛОЖЕНИЙ CORBIS
Когда я вводил в 2006 году канбан-систему в Corbis, я имел в виду множество механических выгод, которые были продемонстрированы в Microsoft XIT в 2004 году (описано в главе 4). Изначально применение предполагалось таким же – техподдержка IT-приложений. Я не рассчитывал на значительные культурные изменения или сдвиг в организационной зрелости. И уж тем более я не ожидал, что итогом этой работы станет то, что мы теперь называем Канбан-метод.
В 2010 году, когда я пишу эту книгу, общепринято, что Канбан создан для техподдержки IT. Но в 2006-м мало кто это осознавал, хотя казалось, что канбан-система способна справиться с функциональными проблемами техподдержки. Я пришел в Corbis не для того, чтобы обязательно «вводить Канбан». Моей задачей было повысить удовлетворенность клиентов командой разработки ПО. Так сложилось, что первой проблемой оказалась недостаточная предсказуемость работы техподдержки IT-программ.
История и культура
В 2006 году Corbis была частной компанией и насчитывала 1300 сотрудников по всему миру. Corbis контролировала цифровые права на многие потрясающие произведения искусства, а также представляла интересы примерно 3000 профессиональных фотографов, выдавая лицензии на их работы для использования в издательском деле и рекламе. Это был второй по величине фотобанк в мире. В бизнесе были и другие направления, например отдел авторских прав, который от имени семей, предприятий и управляющих фирм контролировал права на изображения и имена знаменитостей. IT-отдел насчитывал примерно 110 человек, часть из них занималась разработкой, а другие – техподдержкой сетевых операций и систем. Для участия в крупных проектах подписывались контракты с дополнительными сотрудниками. В 2007 году в отделе числилось 105 человек, 35 штатных сотрудников находились в Сиэтле, а еще 30 – у индийского поставщика в Ченнаи, где в основном и проводилось тестирование. Подход к управлению проектами оставался традиционным. Все планировалось в соответствии с деревом зависимости задач и утверждалось в офисе руководства программами. Эта компания с консервативной культурой действовала в сравнительно консервативной и медленно продвигающейся вперед отрасли. Она использовала традиционные подходы к управлению проектами и жизненному циклу разработки ПО.
IT-отдел оказывал поддержку примерно 30 разнообразным системам. Некоторые из них представляли собой типичные системы учета и управления персоналом, другие же выглядели как экзотические, а порой даже эзотерические приложения для индустрии управления цифровыми правами. Поддерживалось множество технологий, программных платформ и языков. Работники сохраняли завидную лояльность: многие сотрудники IT-отдела трудились в нем от 8 до 15 лет. Неплохо для компании, существовавшей около 17 лет. Отдел придерживался традиционного, применявшегося многие годы водопадного жизненного цикла разработки ПО (SDLC). В компании существовали отделы бизнес-анализа, системного анализа, разработки и офшорного тестирования. В них сидели узкие специалисты – например, аналитики, ранее занимавшиеся бухгалтерией, а теперь – финансами. Некоторые разработчики также были узкими специалистами – в частности, программисты систем J.D. Edwards, которые поддерживали бухгалтерские программы J.D. Edwards.
Все это было далеко от идеала, но шло своим чередом. Когда я появился в компании, люди ждали, что я начну внедрять agile-методы и заставлю сотрудников менять поведение. Хотя такой подход казался перспективным, он предполагал определенную долю жестокости, и итог мог получиться не слишком удачным. Я опасался, что все проекты остановятся, пока работники будут обучаться новым методам и адаптироваться к непривычным принципам работы. Не хотелось также терять ключевых специалистов компании, многие из которых оказались очень уязвимыми из-за чрезмерно развитой специализации. Я предпочел ввести канбан-систему, вернуть работы по поддержке систем в первоначальное состояние и посмотреть, что из этого получится.
Необходимость функции сопровождения ПО
Команда сопровождения ПО (или RRT, то есть Rapid Response Team – группа быстрого реагирования, как мы их называли) была учреждена советом директоров на дополнительные 10 % бюджета, выделенные для отдела разработки. В 2006 году на эти деньги наняли еще пять человек. Они пришли незадолго до меня. Из-за разнообразия систем, которые требовалось поддерживать, и высокого уровня специализации было решено, что создавать отдельную команду из пяти человек исключительно для сопровождения нецелесообразно. Эту пятерку добавили к общему пулу сотрудников. Среди них были менеджер проектов, аналитик, разработчик, а также два тестировщика. Появились дополнительные сложности: необходимо было доказать руководству, что эти пятеро действительно занимаются сопровождением, а не просто влились в портфель крупного проекта. Однако в тот или иной день этими пятерыми могли оказаться кто угодно из 55 членов команды.
Одно из возможных решений выглядело так: обязать всех сотрудников заполнять сложные табели учета рабочего времени. Это наложило бы дополнительное административное бремя, но продемонстрировало бы, что 10 % деятельности команды действительно приходится на сопровождение ПО. Довольно неприятная, но типичная реакция менеджеров среднего звена на подобные проблемы. Другой вариант – это введение канбан-системы.
Ожидалось, что команда сопровождения позволит Corbis проводить пошаговые релизы в IT-системах каждые две недели. Крупные проекты обычно связаны с серьезными обновлениями системы, поэтому новые релизы выходили в них только каждые три месяца. Но по мере взросления бизнеса системы становились все сложнее и каденция ежеквартальных крупных релизов оказалась недостаточной. К тому же некоторые из существующих систем исчерпали свой ресурс и требовали полной замены. Замена системы прежнего поколения – серьезный вызов. Обычно она реализуется в долгосрочных проектах с большим количеством участников, пока не будет достигнута соответствующая функциональность, при которой можно свернуть прежнюю систему и заменить ее новой. (Этот подход вовсе не оптимален, зато типичен.)
Итак, релизы сопровождения ПО были единственной отраслью в IT-подразделении Corbis, где канбан мог обеспечить некоторую степень бизнес-гибкости.
Небольшие проекты сопровождения ПО неэффективны
Существовавшая система выдачи релизов сопровождения, которая работала неэффективно, предполагала планирование серии краткосрочных проектов на две недели каждый. Казалось бы, это напоминает двухнедельные итерации в гибкой разработке ПО, но это не так. Когда я пришел в компанию, переговоры по объему двухнедельного цикла релиза занимали примерно три недели. В результате непосредственные операционные издержки по релизу превышали работы по приросту стоимости. В итоге на двухнедельный релиз уходило до шести недель.
Внедрение изменений
Было понятно, что текущее положение дел неприемлемо. Используемая система не давала нужного уровня деловой гибкости. Сопровождение систем оказалось идеальным плацдармом для внесения изменений. Сопровождение – не самый критичный процесс, однако его результаты всегда на виду, поскольку бизнес непосредственно влиял на расстановку приоритетов, которая проводилась из тактических соображений и в расчете на краткосрочные цели. О сопровождении систем беспокоились все. Каждому хотелось, чтобы оно работало эффективно. Наконец, была еще одна убедительная причина для внесения изменений: никому не нравилась существующая система. Разработчиков, тестировщиков и аналитиков возмущало, что большая часть времени уходит на обсуждение масштаба работы, а представители бизнеса были крайне разочарованы результатами.
Мы разработали канбан-систему, в которой каждые две недели по средам в час дня были запланированы релизы, а каждый понедельник в 10 утра – совещания по расстановке приоритетов с бизнес-отделом. То есть каденция расстановки приоритетов была недельной, а каденция релизов – двухнедельной. Выбор такой каденции определился в ходе обсуждений с партнерами выше и ниже по цепочке создания ценности с учетом операционных и координационных издержек. Произошел и ряд других изменений. Мы установили очередь на выполнение с лимитом незавершенных задач, равным 5, добавили лимиты по всему жизненному циклу – на анализ, разработку, конфигурацию и системный тест. Тестовая приемка, обкатка и подготовка к запуску в производство остались без ограничений, поскольку мы считали, что они не служат ограничителями общей мощности и при этом находятся вне зоны нашего непосредственного контроля.
Первичные результаты изменений
Эффекты введения канбан-системы были, с одной стороны, неудивительными, а с другой – довольно примечательными. Мы начали выпускать релизы каждые две недели. После примерно трех итераций все пошло гладко, без инцидентов. Качество было хорошим, почти не возникало необходимости вносить срочные правки после выхода нового кода. Затраты на планирование релизов существенно сократились, а недопонимание между командой разработчиков и менеджерами программ практически исчезло. Итак, канбан сдержал свое основное обещание. Мы регулярно выпускали высококачественные релизы с минимальным вмешательством руководства. Операционные и координационные издержки существенно сократились. Команда стала выполнять больше работы, и клиент начал получать ее результаты значительно чаще.
Но еще примечательнее оказались вторичные эффекты.
Непредвиденные эффекты перехода на канбан
В команде разработки в январе 2007 года мы использовали реальные канбан-карточки – клеили стикеры к доске. Каждое утро в 9:30 мы собирались возле этой доски, чтобы провести 15-минутное совещание. С точки зрения психологии реальная доска имела значительно больший эффект, чем все использовавшиеся нами электронные системы управления задачами, применявшиеся в Microsoft. На наших совещаниях сотрудники словно видели замедленную съемку рабочего потока, представленную на доске. Заблокированные рабочие элементы отмечались розовыми стикерами, и команда активнее фокусировалась на разрешении проблем и сопровождении рабочего потока. Производительность существенно выросла.
Теперь, когда поток работы можно было отслеживать на доске, я сосредоточился на самом процессе работы. И отразил на той же доске некоторые изменения. Моя команда менеджеров уяснила мои принципы и к марту сама стала внедрять изменения. В свою очередь, члены их команд – индивидуальные разработчики, тестировщики и аналитики – воочию увидели процесс и поняли, как все работает. В начале лета все почувствовали, что обладают достаточными полномочиями, чтобы предлагать изменения, и мы увидели процесс спонтанного образования групп (состоящих из представителей разных отделов), обсуждавших проблемы и вызовы и вносивших необходимые улучшения. Обычно руководство узнавало обо всем постфактум. Примерно через шесть месяцев в команде разработки возникла настоящая культура кайдзен. Члены команды чувствовали себя уверенно. Страх исчез. Они гордились своим профессионализмом и достижениями, но надеялись, что смогут работать еще лучше.
Социологические изменения
После опыта с Corbis поступали другие аналогичные отчеты из той же отрасли. Роб Хэтэуэй из Indigo Blue первым воспроизвел эти результаты в IT-группе IPC Media в Лондоне. То, что социологический эффект, достигнутый в Corbis, оказался воспроизводимым, убеждает меня, что причина не во мне и не в простом совпадении, а именно в Канбане.
Я много думал о том, чем объясняются эти социологические изменения. Уже лет десять agile-методы предлагают прозрачность применительно к незавершенным задачам, но команды, применяющие Канбан-метод, судя по всему, достигают культуры кайдзен быстрее и эффективнее, чем типичные команды гибкой разработки. Часто команды, добавляющие Канбан к уже взятым на вооружение agile-методологиям, обнаруживают существенное увеличение социального капитала у своих членов. Чем это объяснить?
По-моему, дело в том, что Канбан обеспечивает прозрачность не только самой работы, но и процесса (или потока). Он дает наглядное представление о том, как работа передается от одной группы к другой. Показывает всем заинтересованным лицам, к какому результату приведет их действие или бездействие. Если элемент заблокирован и кто-то способен его разблокировать, это будет видно благодаря Канбану. Допустим, некое требование можно толковать двояко. Обычно в подобных случаях эксперт, способный разрешить противоречие, ждет электронного письма с просьбой о встрече. Наконец, после серии звонков назначается встреча, которая должна быть запланирована в календаре, – это может произойти и через три недели. Но Канбан и наглядность, присущая этому методу, сразу покажут эксперту эффект от его бездействия. Это может заставить его пересмотреть свои планы, чтобы провести встречу в течение ближайшей недели.
Помимо наглядности потока работы, лимиты на число незавершенных задач тоже стимулируют более быстрые и частые взаимодействия по проблеме. Не так-то легко игнорировать заблокированный элемент и продолжить работу над чем-то другим. Этот аспект Канбана, судя по всему, поощряет образование групп по всей цепочке создания ценности. Когда представители разных отраслей, занимающие различные должности, начинают вместе работать над решением проблемы, поддерживая тем самым рабочий поток и улучшая производительность на системном уровне, увеличивается уровень социального капитала и взаимного доверия в команде. Как только в организации благодаря сотрудничеству появляется высокий уровень доверия, страх сделать что-то не так исчезает.
Ограничение на число незавершенных задач наряду с введением классов обслуживания (о них говорится в главе 11) также позволяет сотрудникам принимать собственные решения по планированию, без указаний или надзора руководства. Наделение полномочиями повышает уровень социального капитала, поскольку демонстрирует, что руководители доверяют подчиненным самостоятельно принимать квалифицированные решения. Менеджеры освобождаются от функции контроля работников и могут сосредоточиться на других вещах – например, производственных показателях, управлении рисками, развитии персонала и повышении удовлетворенности клиентов и сотрудников.
Канбан серьезно повышает уровень социального капитала внутри команды. Рост доверия и исключение фактора страха поощряет совместные инновации и решение проблем. В итоге быстро развивается культура кайдзен.
Вирусное распространение сотрудничества
Канбан определенно улучшил атмосферу в отделе разработки Corbis, но наиболее примечательными были результаты его внедрения, проявившиеся за пределами инженерного подразделения. То, как вирусное распространение Канбана пошло на пользу сотрудничеству в масштабах всей компании, достойно отдельного разговора и анализа.
КЕЙС: РАЗРАБОТКА ПРИЛОЖЕНИЙ CORBIS, ПРОДОЛЖЕНИЕ
Каждый понедельник в 10 утра Диана Коломиец, менеджер проекта, отвечающая за координирование релизов сопровождения ПО IT-систем, проводила совещание группы быстрого реагирования по приоритетам. От бизнес-отдела обычно присутствовали вице-президенты. Они управляли бизнес-подразделением и непосредственно подчинялись либо старшему вице-президенту, либо иному руководителю высшего звена компании. Иными словами, вице-президент подчинялся члену совета директоров. Corbis была все еще достаточно маленькой компанией, поэтому руководителям столь высокого уровня имело смысл присутствовать на еженедельных совещаниях. Можно сказать и по-другому: тактический выбор, который предстояло сделать на этом собрании, был настолько важен, что требовалось присутствие вице-президента и его мнение. Обычно каждый участник совещания в пятницу получал электронное письмо примерно с таким текстом: «Мы предполагаем, что на следующей неделе освободятся два места для новых задач. Пожалуйста, изучите элементы вашего бэклога и выберите варианты для обсуждения на понедельничном совещании».
Торговля
В первые недели после трансформации процесса некоторые участники приходили с намерением поторговаться. Например, кто-то из них мог сказать: «Я знаю, что свободно только одно место, но у меня два маленьких задания, нельзя ли сделать оба?» Такая постановка вопроса редко приводила к успеху. Другие члены совета по приоритетам следили, чтобы правила были одинаковыми для всех. Они отвечали приблизительно так: «Откуда нам знать, действительно ли они маленькие? Поверить тебе на слово?» Или возражали: «У меня тоже два маленьких задания. Почему бы не сделать выбор в их пользу?» Я называл это периодом торговли, потому что именно так проходили переговоры на первых совещаниях по приоритетам.
Демократия
Прошло примерно шесть недель. По стечению обстоятельств примерно в то же время, когда команда разработки начала использовать доску, совет по приоритетам ввел демократическую систему голосования. Это произошло спонтанно, потому что всем надоели постоянные пререкания. Они отнимали много времени. Чтобы усовершенствовать систему голосования, потребовалось несколько итераций, но в итоге установилось положение, при котором у любого участника был один голос на каждое свободное место в очереди на текущей неделе. В начале совещания каждый участник предлагал небольшое количество кандидатов на выбор. Со временем предложение запросов стало оформляться разнообразнее: одни приходили с презентациями в PowerPoint, другие – с таблицами, иллюстрирующими кейсы. Потом мы узнали, что некоторые участники занимались лоббированием, приглашая коллег на ужин. Заключались сделки: «Если я на этой неделе проголосую за твой вариант, то ты поддержишь на следующей неделе мой». Демократической системе расстановки приоритетов способствовал рост сотрудничества между вице-президентами подразделений. Хотя в то время мы этого еще не понимали, рос социальный капитал в масштабах всей компании. Когда руководители подразделений начинают сотрудничать, их примеру, видимо, следуют подчиненные. Ведь все начинается с лидеров! Атмосфера сотрудничества наряду с наглядностью и прозрачностью порождает более тесное сотрудничество: этот период работы я называю периодом демократии.
Конец демократии
Демократия – это прекрасно, но через четыре месяца выяснилось, что она не способствует избранию лучшего кандидата. Были потрачены значительные усилия на реализацию функции для электронной коммерции с адаптацией к восточноевропейскому рынку. Кейс казался великолепным, но его жизнеспособность с самого начала вызывала подозрения, под сомнение было поставлено и качество данных. Далеко не с первой попытки, но функция была выбрана и внедрена. Это крупная функция, которая проходила через группу быстрого реагирования, в ее реализации приняли участие многие, так что она не осталась незамеченной. Через два месяца после запуска директор по интеллектуальному анализу данных обработал данные о выручке. Это была лишь небольшая часть того, что сулил исходный кейс: оказалось, что затраченные усилия окупятся примерно через 19 лет. Благодаря прозрачности, которую предлагает Канбан, результат стал известен многим заинтересованным лицам. Возникла дискуссия о том, для чего на этот вариант затрачивалось столько драгоценных ресурсов, хотя можно было сделать гораздо лучший выбор. Так окончился период демократии.
Сотрудничество
Примечательно то, что пришло на смену. Нужно помнить, что в совет по приоритетам входили в основном сотрудники уровня вице-президента компании. Они хорошо знали такие аспекты бизнеса, о которых многие из нас даже не подозревали. Поэтому в начале совещания они стали спрашивать: «Диана, какое сейчас среднее время выполнения?» Она отвечала, например: «В среднем это сорок четыре дня до релиза». Тогда они задались вопросом: «Какая тактическая деловая инициатива будет самой важной для компании через сорок четыре дня?» Возможно, последовало короткое обсуждение, но в целом соглашение было достигнуто сразу: «О, так это же наша европейская маркетинговая кампания, которую мы запускаем на конференции в Каннах». – «Отлично! Какие элементы бэклога призваны поддержать этот запуск в Каннах?» После быстрого поиска было выявлено шесть элементов. «Итак, сегодня у нас свободно три места. Давайте выберем три из шести, а остальные включим на следующей неделе». Почти никто не спорил, не было никакой торговли. Совещание продолжалось двадцать минут. Этот этап я называю периодом сотрудничества. Он отражает наивысший уровень социального капитала и доверия между подразделениями, который был достигнут, когда я работал старшим директором по разработке в Corbis.
Культурные перемены – едва ли не главное преимущество канбана
Было интересно наблюдать за возникновением культурных изменений и за тем, как они все шире распространяются в компании, после того как сотрудники последовали примеру своих вице-президентов и стали активнее сотрудничать с коллегами из других подразделений. Эти перемены оказались настолько глубокими, что недавно назначенный CEO Гэри Шенк вызвал меня в свой кабинет и спросил, как я это объясняю. Он отметил, что видит новый уровень сотрудничества и командного духа в высшем руководстве компании, и, по его мнению, бизнес-подразделения, между которыми прежде царила конкуренция, теперь работают гораздо лучше. Шенк считал, что все дело в организации группы быстрого реагирования, но хотел услышать и мое мнение. Я постарался убедить его, что именно наша канбан-система существенно повысила уровень сотрудничества и социального капитала у всех, кто имел к ней отношение.
Культурные изменения, опосредованно связанные с тем, что мы сейчас называем Канбаном (с большой буквы), оказались совершенно неожиданными и во многих отношениях противоречили здравому смыслу. Он спросил: «Почему же тогда мы не используем это во всех крупных проектах?» И мы решили внедрить в портфель крупных проектов Канбан, мотивируя это тем, что он создал культуру кайдзен. Эти культурные изменения оказались настолько желательными, что издержки на трансформацию механизмов расстановки приоритетов, планирования, форм отчетности и выполнения, которых требовало внедрение Канбана, не выглядели чрезмерными.
Выводы
• Кайдзен переводится как «непрерывное совершенствование».
• В культуре кайдзен люди чувствуют свои полномочия, действуют без страха, произвольно объединяются в группы, сотрудничают и вводят инновации.
• Для культуры кайдзен характерен высокий уровень социального капитала и доверия между людьми независимо от их места в корпоративной иерархии.
• Канбан обеспечивает прозрачность как самой работы, так и рабочего процесса.
• Прозрачность рабочего процесса позволяет всем заинтересованным лицам видеть результаты своей деятельности или бездействия.
• Люди с большей готовностью инвестируют свое время и выражают готовность к сотрудничеству, если они видят результаты своей деятельности.
• Ограничения на число незавершенных задач в Канбане стимулируют принятие ответственности на себя.
• Ограничения на число незавершенных задач в Канбане стимулируют произвольное образование групп для решения проблем.
• Повышение степени сотрудничества в результате формирования групп для решения проблем и взаимодействия с внешними заинтересованными лицами выводит на новый уровень социальный капитал внутри команды и доверие членов команды друг к другу.
• Ограничения на число незавершенных задач в Канбане и введение классов обслуживания позволяют сотрудникам брать работу и принимать решения по расстановке приоритетов и планированию без надзора или руководства вышестоящих лиц.
• Повышенный уровень полномочий увеличивает социальный капитал и доверие между сотрудниками и менеджерами.
• Коллективистское поведение распространяется вирусным образом.
• Сотрудники могут следовать примеру старших руководителей. Их коллегиальное поведение влияет на поведение всех работников организации.
Часть III Внедрение канбана
Глава 6 Визуализация цепочки создания ценности
Канбан – это подход, который благоприятствует изменениям, оптимизируя ваши процессы. Главное в начале использования Канбана – внесение минимальных изменений в рабочий процесс. Нужно противостоять искушению полностью перестроить рабочий поток, пересмотреть штатное расписание, роли, ответственность и конкретные рабочие методы. Все, что влияет на самооценку, профессиональную гордость и эго членов команды, сотрудников компании и заинтересованных лиц, должно остаться неизменным. Изменения должны быть направлены на количество незавершенных задач и точки взаимодействия с соседями выше и ниже по цепочке создания ценности. Поэтому вам нужно вместе с командой создать схему существующей цепочки создания ценности. Старайтесь ничего не менять и не изобретать в поисках улучшений.
В некоторых ситуациях официальная процедура не выполняется. При попытке составить схему цепочки создания ценности команда будет настаивать на фиксировании официальной процедуры, а не той, что используется фактически. Вы должны противостоять этому, чтобы описать реальную схему работающего процесса. Без этого невозможно использовать стену карточек как средство визуализации процесса, поскольку члены команды могут полагаться на нее, только если она отражает действительность.
Определение стартовой и финишной контрольных точек
Необходимо определиться со стартовой и финишной точками визуализации процесса, а также с точками взаимодействия с вышестоящими и нижестоящими соседями по цепочке создания ценности. Важно ответственно отнестись к этой начальной стадии внедрения Канбана, поскольку неверный выбор может привести вас к провалу. Успешные команды обычно начинают с перехода на визуализацию при помощи карточек и ограничения числа незавершенных задач в пределах своей сферы контроля и переговоров по поводу новых способов взаимодействия с непосредственными партнерами по цепочке создания ценности. Например, если вы контролируете отдел проектирования или разработки и обладаете контролем (влиянием) над анализом, дизайном, тестированием и написанием кода, то составьте схему этой цепочки создания ценности и начните переговоры по поводу нового стиля взаимодействия с вышестоящими деловыми партнерами, от которых зависят требования, расстановка приоритетов и управление портфелем, а также нижестоящими, занимающимися системными операциями и поддержкой продукта. Очертив тем самым границы, вы предлагаете перейти на ограничение числа незавершенных задач только своей команде. Другие не обязаны менять методы работы, ограничивать число незавершенных задач и внедрять вытягивающую систему. Однако вы просите их по-иному взаимодействовать с вами, чтобы это было совместимо с вытягивающей системой, которую вы внедряете у себя.
Типы работ
Выбрав стартовую точку для рабочего процесса или цепочки создания ценности, определите, какие типы работы относятся к этой точке, а какие существуют в рабочем процессе и должны подвергнуться ограничениям. Например, исправление ошибок, скорее всего, относится к типам работ, существующим в рабочем процессе. Возможно, вы выявите и иные типы деятельности, связанные с разработкой: рефакторинг, поддержку систем, обновление инфраструктуры и другие переделки. Для входящей работы это такие типы, как пользовательские истории, прецеденты, функциональные требования или функции. В некоторых случаях входящие типы работы могут быть иерархическими – например, эпики[6] (собрания пользовательских историй).
Вот основные типы работы в командах, использующих Канбан (это неполный список):
• требование;
• функция;
• пользовательская история;
• пользовательский сценарий;
• запрос изменений;
• дефект продукта;
• поддержка;
• рефакторинг из-за ошибки;
• предложение улучшения;
• блокирующая проблема.
Полезно именовать типы работы по источнику, например: регуляторное требование, запрос продаж на местах, требование стратегического планирования и т. д. Если по оглавлению задачи сразу понятен источник, это создает дополнительный контекст и позволяет системе развиваться в сторону обслуживания нескольких клиентов сразу.
Типы работы обычно определяются их источником, рабочим потоком или размером работы. Например, у производственных текстовых изменений (РТС) в примере с Microsoft из главы 4 рабочий поток иной, хотя источник тот же, что и у запроса изменений. Иметь отдельные канбан-системы для обоих типов бессмысленно: работу выполняет одна и та же команда и несложно визуализировать типы, используя различные цвета карточек или разные ряды («плавательные дорожки») на стене карточек. Порядок величины карточек обычно таков: маленькие (несколько дней), средние (от недели до двух) и большие (месяц и более). Каждый порядок должен соответствовать своему типу.
Создание стены карточек
Стена карточек обычно создается скорее для иллюстрации видов действий, чем для отражения конкретных функций или описаний работы. Часто функция и действие существенно перекрываются: например, аналитики проводят анализы. Однако в программных проектах, выполняемых при помощи Канбана, в последние несколько лет принято моделировать работу, а не работников, функции или передачи функций.
Перед созданием стены карточек для визуализации рабочего потока иногда полезно схематично набросать или смоделировать ее. Рис. 4.4 демонстрирует очень формальную модель желаемого рабочего потока, представленную при помощи диаграммы состояний. В ней добавляются очереди на запросы изменений и производственные текстовые изменения, обрабатываемые командой технической поддержки XIT в Microsoft. Вполне вероятен и менее формальный подход. Рисунка с человечками вроде тех, что фигурировали в главе 4, или схемы-алгоритма либо ее аналога может оказаться достаточно.
Когда вы лучше поняли рабочий поток, схематично набросав или смоделировав его, начните работу над стеной карточек, разграфив ее на столбцы, которые соответствуют выполняемым действиям в порядке их реализации, как показано на рис. 6.1.
Рис. 6.1. Черновик рабочего потока на стене карточек (поток движется справа налево)
Рисовать столбцы лучше маркером. Однако в процессе использования линии все равно сотрутся. За первые несколько недель вы, скорее всего, захотите внести в рабочий поток ряд изменений, так что продолжайте пользоваться маркером. Но со временем понадобится что-то более стойкое, например очень узкие рулоны виниловой самоклеящейся пленки, которые продаются в магазинах канцтоваров и специально разработаны для магнитных досок (рис. 6.2). В Corbis мы обычно разлиновывали столбцы и строки на стене карточек, используя именно такую пленку. Сейчас это обычная практика, и команды применяют для разметки пленку различного вида и ширины.
Рис. 6.2. Специальная пленка для магнитной доски (rolls = рулоны)
Заметьте, что для этапов деятельности необходимо моделировать как незавершенную, так и оконченную работу; обычно для этого столбец просто делят пополам.
После этого добавьте входящую очередь и любые действия нижестоящих партнеров, которые вы хотите визуализировать, как показано на рис. 6.3.
Рис. 6.3. Рабочий поток с буферами и очередями
Наконец, добавьте буферы или очереди, которые считаете необходимыми. По этому поводу мнения расходятся, и тема действительно сложная. Все пункты дискуссии о том, куда ставить буферы и как их масштабировать, лежат за пределами этой книги, так что достаточно описать два наиболее популярных подхода.
• Первая концепция состоит в том, чтобы не пытаться предугадывать место возникновения узкого места или источника вариативности, которым потребуется буфер. Просто внедрите систему и ждите, пока бутылочное горлышко не проявится само, а затем внесите изменения, введя буфер. Вариант того же подхода предлагает изначально произвольно установить ограничения числа незавершенных задач, чтобы вариативность, расход времени и узкое место не оказывали существенного влияния на вытягивающую систему при ее первом внедрении. Подробнее это будет описано в главе 10, а также в главе 17 и главе 19.
• Другая концепция предполагает иной подход: считается, что вместо внедрения свободных ограничений числа незавершенных задач для упрощения введения системы каждая стадия работы должна подвергнуться буферизации, а у этапов деятельной работы рамки должны быть довольно узкими. Узкие места и вариативность проявят себя в том, насколько сильно наполнятся буферы. После этого можно внести небольшие изменения в сторону уменьшения размеров буфера, а со временем ненужные буферы исключить.
На момент написания этой книги нет достаточного объема данных, чтобы решить, какой подход лучше.
Рис. 6.4. Стена карточек, иллюстрирующая использование ромбовидных карточек в верхней части очереди и буферных столбцов (публикуется с разрешения Liquidnet Holdings)
Некоторые команды договорились показывать буферные и очередные столбцы при помощи карточки, повернутой на 45 градусов. Это действительно сильный визуальный индикатор того, сколько рабочих элементов выполняется, а не находится в очереди в каждый заданный момент времени. Таким образом, команда и другие заинтересованные лица в буквальном смысле «видят» размер оптимальных (или не очень) издержек системы.
Анализ нагрузки
Анализ нагрузки необходимо проводить для каждого определенного типа работы. Если у вас накопились данные, проведите на их основе количественный анализ. Если их нет, то подойдет и анализ на основе личного опыта. Например, в примере с Microsoft XIT из главы 4 существовало два типа работы – запросы изменений и производственные текстовые изменения (PTC). Возможно, запросы изменений следовало тоже разбить на два типа – дефекты производства и собственно запросы изменений (для новой функциональности). Будь я сейчас наставником этой команды, я бы рекомендовал им различать четыре типа работ: запросы изменений, производственные дефекты, производственные текстовые изменения и ошибки (или неэкранированные дефекты).
Изучим нагрузку для каждого из этих типов. Нагрузка PTC носит пакетный характер: на протяжении шести недель их может не быть вовсе, а затем пройдет десяток за неделю, причем почти одновременно. PTC были небольшими и быстро внедрялись. Поэтому воздействие их не было критичным. Создание системы, способной справляться с такой прерывистой нагрузкой, – это сложная задача. Если PTC требовали серьезных усилий, то системе нужен был существенный встроенный резерв, чтобы справляться с PTC и при этом не снижать предсказуемость запросов изменений.
Запросы изменений, в свою очередь, прибывали гораздо равномернее. Хотя их появление было стохастично, нагрузка оставалась относительно устойчивой: примерно пять – семь новых запросов в неделю. Можно было бы указать скорость появления PTC на графике и отметить нагрузку, чтобы понять среднюю скорость появления и распределение по времени выполнения. После этого можно создавать канбан-систему и с ее помощью справляться с нагрузкой.
Нагрузка по некоторым типам работ, например регуляторным требованиям, носит сезонный характер. Новое налоговое законодательство также сезонно затрагивает финансовую систему и систему начисления заработной платы. Мне известен такой случай: IT-отдел автогоночной компании получал регуляторные изменения от контролирующей спортивной организации в начале каждого гоночного сезона. Их могли присылать и во время сезона, но в межсезонье объем был существенно больше, поскольку регуляторные требования менялись от сезона к сезону. Важно понимать принципы такой нагрузки, чтобы менять дизайн канбан-системы и лучше справляться с разными типами работы.
Распределение мощности в соответствии с нагрузкой
Поняв нагрузку, вы можете определить, какую мощность системы выделить на ее удовлетворение. В примере на рис. 6.5 приведены три «плавательные дорожки», по одной для каждого типа работы, а именно для запросов изменений, внутренней эксплуатационной деятельности (например, рефакторинга кода) и производственных текстовых изменений. В итоге выделено 60 % на запросы изменений, 10 % на работу по рефакторингу кода и 30 % на производственные текстовые изменения. Учитывая анализ нагрузки, который показывает, что производственные текстовые изменения прибывают порциями, такое распределение мощности демонстрирует, что значительный резерв выделяется на срочную обработку производственных текстовых изменений сразу после их прибытия без ущерба для дедлайнов по другим работам. Распределение мощности должно учитывать профиль риска. Если, например, допустима просрочка выполнения заданий для производственных текстовых изменений, а время выполнения по запросам изменений может быть более длительным и менее предсказуемым, то распределение будет иным: например, 85 % на запросы изменений, 10 % на обслуживание и 5 % на производственные текстовые изменения. Еще один вариант – оставить «плавательную дорожку» для производственных текстовых изменений, но не выделять для них никакой мощности, а просто превысить ограничение числа незавершенных задач, если поступает пакет производственных текстовых изменений. Тем самым вы отказываетесь от ненужного резерва и выдаете оптимальный экономический результат при обычной работе. Однако когда пакет производственных текстовых изменений действительно прибывает, это может повлечь за собой серьезные последствия для всех других задач с точки зрения времени выполнения и предсказуемости.
Такой выбор сделан в реальном примере (глава 4), когда было решено не резервировать отдельные силы для работы с производственными текстовыми изменениями.
.
Рис. 6.5. Канбан-доска с типичными «плавательными дорожками», включая распределение мощности
Когда мы начнем обсуждать ограничение числа незавершенных задач, нам понадобится информация о распределении, чтобы задать конкретные ограничения для очередей в каждой «плавательной дорожке».
Анатомия карточки
Каждая карточка, представляющая конкретный элемент работы, создающей ценности для клиента, содержит информацию по ряду пунктов. Важен дизайн карточек. Информация на них должна способствовать работе вытягивающей системы и помогать людям принимать индивидуальные решения об очередности новых задач. Информация на карточке группируется по типу работы или по классу обслуживания (об этом речь пойдет в главе 11). В примере на рис. 6.6 число в левом верхнем углу – это индивидуальный электронный номер, четко идентифицирующий задачу и связывающий ее с электронной версией системы управления задачами. Название задачи написано в середине. Дата поступления карточки в систему – слева внизу. Это служит двум целям: позволяет установить порядок очереди для стандартных классов обслуживания и дает возможность членам команды видеть, сколько времени прошло с момента соглашения об уровне обслуживания (описано в главе 11). Для элементов класса обслуживания с фиксированной датой поставки в правом нижнем углу карточки указывается требуемая дата выполнения.
.
Рис. 6.6. Увеличение участка стены карточек, демонстрирующее анатомию карточки
В примере на рис. 6.6 помимо текста на карточках приводится и другая информация. Звездочка обозначает, что данная задача завершена позже времени выполнения, указанного в соглашении об уровне обслуживания. Недавно я видел, как это же обстоятельство отмечалось стикером, прикрепленным к верхнему правому углу карточки. Имя назначенного специалиста тоже пишется над карточкой. Поскольку при перемещении карточки по доске назначенные специалисты меняются, писать имя на карточке нежелательно. Однако в последних вариантах применяются небольшие ярлычки, прикрепляемые к карточке, а иногда используются магниты (если доска магнитная), на которых помещаются аватары членов команды. Популярный источник аватаров – мультсериал «Южный парк». Подойдет любой механизм, который позволит членам команды и их руководителям сразу понять, кто над чем работает.
Карточка, которая используется для отображения конкретного элемента работы, должна содержать всю информацию, необходимую для облегчения решений по управлению проектом (например, какой элемент вытягивать следующим) без вмешательства или указания менеджера. Цель состоит в том, чтобы предоставить членам команды достаточно полномочий, обеспечив прозрачность процессов, целей и задач проекта и данных о рисках. Когда вы узнаете больше о классах обслуживания и соглашениях об уровне обслуживания, вы увидите, что благодаря Канбану создается мощный самоорганизующийся механизм управления рисками. Кроме того, Канбан, предоставляя членам команды возможность самостоятельно принимать решения о расписании работы и приоритетах, демонстрирует уважение к сотрудникам и доверие к системе (или разработке процесса). Хорошо продуманная карточка единицы работы – ключевой фактор для порождения культуры доверия и создания бережливой организации.
Системы управления задачами
Системы управления задачами для канбан-систем применяются в разработке ПО с момента их первого внедрения в 2004 году. Но использование таких систем не обязательно. Правда, для географически распределенных команд или для коллективов, члены которых могут один либо несколько дней в неделю работать дома, система управления задачами необходима. Фиксировать задачи в электронном виде можно при помощи самых простых систем учета – например, Jira, Microsoft Team Foundation Server, Fog Bugz и HP Quality Center. Однако более мощная система позволяет визуализировать поток задач, как будто бы он находится на доске с карточками.
В настоящий момент на рынке появляются веб-сервисы и приложения для электронной визуализации. Они используют визуальные панели, которые симулируют стены карточек с их столбцами, ограничениями числа рабочих задач и другими сущностными характеристиками Канбана. Среди них есть (список, конечно, неполон) Lean Kit Kanban, Agile Zen, Target Process, Silver Catalyst, RadTrack, Kanbanery, VersionOne, Greenhopper for Jira, Flow.io и некоторые другие надстройки с открытым кодом, которые добавляют интерфейс Канбана к таким инструментам, как Team Foundation Server и FogBugz. Рис. 6.7 демонстрирует пример из AgileZen.
Рис. 6.7. Скриншот AgileZen, система управления задачами
Электронная фиксация задач необходима для команд, которые стремятся к большей организационной зрелости. Если вы чувствуете необходимость в количественном менеджменте, сопоставлении организационных процессов (сравнение производительности по канбан-системам, командам или проектам), то лучше с самого начала внедрить систему управления задачами.
Определение границ входа и выхода
Дизайн канбан-системы и стены карточек должен сочетаться с принятым ранее решением по ограничению пределов контроля незавершенных задач. Вполне вероятно, что выше– и нижестоящие партнеры впоследствии попросят поместить визуализацию их деятельности на вашу стену карточек. Однако лучше сначала обеспечить прозрачность собственной работы и подождать, пока партнеры сами не изъявят желание присоединиться к вашей Канбан-инициативе.
В примере на рис. 6.8 очередь на вход отмечена буквами E.R., то есть «готово к проектированию». Следовало задать точку входа на этом этапе жизненного цикла, потому что вышестоящий по потоку отдел бизнес-аналитики подчинялся другой части организационной структуры. Руководителям обеих групп недоставало доверия и стремления к сотрудничеству. Поэтому очередь задач пополнялась из журнала требований, составляемого отделом бизнес-аналитики. В этом примере нижестоящие по потоку отделы передают работу в отдел производства. Как только ПО создано и передано в отдел системных и сетевых операций для поддержки и повседневного обслуживания, работа с ним считается законченной.
Рис. 6.8. Пример очереди на вход «Готово к проектированию» (E.R.)
Работа с параллельными процессами
При разработке стены карточек для канбан-системы часто встречаются процессы, в которых два и более видов деятельности могут происходить одновременно, например разработка ПО и тестов.
Есть два основных способа работы в такой ситуации. Один – не моделировать ее вовсе, а просто оставить одну колонку, в которой оба вида работы могут происходить одновременно (рис. 6.9). Это легко, но не нравится многим командам. Некоторые команды адаптировали эту модель и используют для разных видов деятельности различные цвета или формы карточек. Другой вариант – вертикально разделить доску на две (или более) секции (рис. 6.10).
Рис. 6.9. Открытый столбец для параллельных видов деятельности
Рис. 6.10. Разделенный столбец для параллельных видов деятельности
В этом примере необходим механизм именования, связывающий элементы в верхней и нижней частях доски. Например, поместите в верхнем правом углу карточки ссылку на связанный элемент. В хорошей системе управления задачами можно расставить ссылки на связанные задачи, такие как разработка ПО и тестов.
Обработка неупорядоченной деятельности
При экспериментальной работе, полной инноваций, определенные виды деятельности необходимы, чтобы создавать ценность для клиентов, но при этом они необязательно следуют в определенном порядке. Важно понимать, что Канбан не должен навязывать строгую очередность при совершении действий.
При моделировании канбан-систем важно помнить, что они должны отражать реальное выполнение работы.
Для работы с многочисленными неупорядоченными видами деятельности существуют две основные стратегии. Первая похожа на стратегию работы с параллельными заданиями: оставьте единый столбец для записи всех видов деятельности и не указывайте на доске, какой из них завершен.
Второй, потенциально более эффективный вариант, – моделировать виды деятельности так же, как и параллельные. В этом случае, как показано на рис. 6.11, карточки будут вертикально двигаться вверх и вниз по столбцу, как только их втягивают в соответствующие виды деятельности. Визуализация того, что делается с каждой задачей, достигается посредством модификации внешнего вида карточки: для каждого вида деятельности указывается свое поле, и, когда он завершается, это поле заполняется, сигнализируя о том, что эта задача готова для перехода к следующему виду деятельности из того же столбца. Если заполнены все поля, то карточка может переместиться в следующий столбец на доске или отправиться в столбец «Готово» (рис. 6.12).
Рис. 6.11. Открытый столбец для множества неупорядоченных видов деятельности
Рис. 6.12. Разделенный столбец для множества неупорядоченных видов деятельности
Выводы
• Определите внешние границы канбан-системы. Разумнее всего ограничить ее пределами вашего непосредственного контроля. Не заставляйте переходить на визуализацию, прозрачность и ограничение числа незавершенных задач отделы, которые не горят желанием сотрудничать.
• Смоделируйте стену карточек в соответствии с решениями о границе системы, лимитирующей число незавершенных задач и визуализирующей работу.
• Определите типы работы и смоделируйте рабочий поток для них. Для некоторых типов все этапы потока необязательны.
• Разработайте шаблоны карточек для каждого типа работы: они должны содержать достаточно информации для облегчения самоорганизации при вытягивании и принятия членами команды качественных решений, учитывающих риски и основанных на типе работы, соглашениях об уровнях обслуживания и классах обслуживания.
• Используйте электронную систему управления задачами, если ваша команда территориально разбросана или ее члены нередко работают из дома либо вы рассчитываете достичь более высокого уровня зрелости, который требует количественной информации, доступной в такой системе.
• При необходимости обсудите методы работы с параллельными заданиями и выберите способ их моделирования и визуализации.
• Обсудите также методы работы с видами деятельности, которые не должны выполняться в четко определенном порядке, и выберите способ их моделирования и визуализации.
Глава 7 Координация в канбан-системах
Визуальный контроль и вытягивание
Если говорить о Канбане, то самая популярная форма координации в нем – стена карточек. Обычно пределы числа незавершенных задач фиксируются на доске сверху каждого столбца или в интервалах между ними. Необходимость вытягивания возникает, когда количество карточек в столбце меньше заданного предела. На рис. 7.1 видно, что вверху столбца «Анализ» записан предел – четыре элемента. Карточек же в столбце всего три. Поскольку 4 – 3 = 1, это говорит о том, что мы можем добавить один элемент в столбец «Анализ» (функция системного анализа) из входящей очереди, «Готово к проектированию» (отмеченной на рис. 7.1 как E.R.). Входящая очередь имеет максимальный размер элементов, но в ней на данный момент осталось только два. После перевода одного из элементов в «Анализ» в очереди остается еще один (5 – 1 = 4). Это означает, что на следующем совещании по расстановке приоритетов можно будет добавить во входящую очередь четыре новых элемента.
Рис. 7.1. Представление пределов канбана на стене карточек
Когда команда решает, какой элемент вытянуть, выбор делается на основании доступной визуальной информации, такой как тип единицы работы, класс обслуживания, дедлайн (если он есть) и возраст рабочей единицы. Правила вытягивания, связанные с классом обслуживания, обсуждаются в главе 11.
На рис. 7.2 в увеличенном виде показаны стикеры, которые соответствуют рабочим единицам на стене карточек. Чтобы передать сочетание типа единицы работы и класса обслуживания, используется цвет.
Рис. 7.2. Крупный план стены карточек с карточкой проблемы, прикрепленной к блокированной единице
В верхней части карточки написано имя владельца или ответственного члена команды. Некоторые команды предпочитают использовать дополнительные, более мелкие стикеры с именами или аватарками, которые прикрепляются к карточке единицы работы и показывают, кто над ней трудится. Это дает возможность всем членам команды видеть, кто за что отвечает.
На рис. 6.6 электронный номер виден в верхнем левом углу стикера. Дата поступления единицы во входящую очередь проставляется в левом нижнем углу и служит основой для определения возраста элемента. Если элемент относится к классу обслуживания, имеющему гарантированную дату выполнения, это отмечается справа внизу. Об опоздании элемента свидетельствует красная звездочка в правом верхнем углу карточки. Если работа над элементом блокирована, то к его карточке прикрепляется дополнительная розовая карточка, обозначающая наличие проблемы. В примере на рис. 7.2 сложности возникли с рабочей единицей первого класса обслуживания, которая имеет собственный электронный номер, дату поступления в систему и содержит имя ответственного за нее сотрудника.
Эта схема характерна для первого внедрения канбан-системы в Corbis. Ваша реализация почти наверняка отличается. Однако вам, по всей вероятности, понадобится визуальное представление ответственного сотрудника, исходной даты, электронного номера, типа работы, класса обслуживания и информации о статусе – например, не опаздывает ли эта единица. Цель состоит в передаче информации, помогающей системе стать самоорганизующейся и самообслуживающейся на уровне команды. Благодаря такому средству визуального контроля, как канбан-доска, члены команды смогут вытягивать новые единицы работы без указаний менеджера.
Системы управления задачами
Альтернативой или дополнением к стене карточек в канбан-системе служит электронная система управления задачами. Некоторые доступные для этого инструменты перечислены в главе 6. Более актуальный список есть на сайте Limited WIP Society: .
Мы с командой разработали собственное приложение – Digital Whiteboard (рис. 7.3), надстройку к Team Foundation Server. В кейсе из главы 4 электронное ведение задач проводилось при помощи внутреннего инструмента Microsoft под названием Product Studio. Это предшественник Team Foundation Server, и с 2005 года Microsoft пользуется Team Foundation Server для собственных внутренних проектов разработки.
Рис. 7.3. Приложение Digital Whiteboard, использовавшееся в Corbis
Приложение на рис. 7.3 показывает канбан-лимиты, сгруппированные поверх столбцов. Оно способно визуально демонстрировать превышение канбан-лимита. Также оно отображает ряд статусных элементов для каждой рабочей единицы, в том числе различные значки, показывающие, что единица запаздывает или блокирована из-за возникшей проблемы.
Система управления задачами имеет большое значение для канбан-систем, поскольку в ней возможно то, что недоступно при использовании обычной доски с карточками. Система управления задачами позволяет собирать данные, полезные для создания отчетов и систем количественных показателей как для непосредственного руководства, так и для использования в дальнейшем – например, на ежемесячном совещании по анализу производственного процесса.
Ежедневные стендапы
Совещания в формате стендапов – широко распространенный элемент процесса agile-разработки. Обычно они проходят до начала работы в заранее утвержденном формате. Типичное стендап-совещание проводится для одной команды, состоящей максимум из двенадцати человек (чаще из шести). Формат предполагает обсуждение трех вопросов: чего вы добились вчера? Что вы будете делать сегодня? Что вам мешает, нужна ли помощь? Каждый член команды отвечает на эти вопросы, после чего группа координирует свою работу на текущий день.
После внедрения Канбана стендапы стали проходить иначе. С появлением стены карточек отпала необходимость ходить по комнате и задавать эти три вопроса. На стене есть вся информация о том, кто и над чем работает. Постоянно присутствующие на совещаниях сотрудники сами видят, что изменилось со вчерашнего дня, например, не блокирован ли рабочий элемент. Таким образом, совещания с канбан-системой обретают иной формат. Они сосредоточены на рабочем потоке. Ведущий, обычно менеджер проекта или непосредственный руководитель, «движется по доске». Как правило, с карточками на доске начинают работать в обратном направлении – справа налево (в направлении вытягивания). Ведущий может запросить обновление статуса на карточке или поинтересоваться, нет ли дополнительной информации, которая отсутствует на доске и поэтому неизвестна команде.
Особое внимание уделяется блокированным (с прикрепленной розовой карточкой) и отложенным из-за ошибок (с прикрепленными голубыми карточками) элементам. Могут быть заданы вопросы и по единицам работы, которые почему-либо не продвигаются вперед уже несколько дней. Некоторые команды придумали способы их визуализации. Например, в итальянской автогоночной компании, которая также производит спорткары, принято ежедневно ставить точку рядом с карточкой, которая надолго застывает в одном и том же месте. Это позволяет команде задуматься, не пометить ли такой элемент как заблокированный, не участвующий в рабочем потоке. Таким образом улучшаются возможности организации по решению проблем (которые будут подробнее описаны в главе 20). Команда кратко обсуждает вопрос, кто работает над проблемой и когда она будет решена. Рассматривается также наличие других блокирующих проблем, которые не отражены на доске; желающим предлагается выступить. Наиболее зрелые команды со временем поймут, что совершенно необязательно анализировать все карточки. Достаточно проанализировать заблокированные или содержащие ошибки элементы. Этот механизм позволяет принять участие в таких совещаниях гораздо большему числу сотрудников: например, в 2007 году Дэниэл Ваканти проводил успешные стендапы для более чем 50 участников проекта в Corbis. Несмотря на огромный размер команды, эти утренние совещания длились не дольше десяти минут.
Постсовещание
Постсовещание – это несколько небольших обсуждений в группах по два-три человека. Оно возникло спонтанно, поскольку после стендапов членам команды хотелось еще что-то обсудить: блокирующую проблему, технический дизайн или архитектуру, но чаще всего – вопросы процессуального характера. Постсовещание – это критический элемент культурной трансформации, которая происходит после перехода на Канбан. Постсовещание порождает идеи по улучшению и приводит к адаптации процесса к команде и инновациям.
В более крупных проектах постсовещания могут выливаться в митинги Scrum-типа. Команды численностью до шести человек, совместно работающие над функцией, историей или требованием, проводят краткое собрание, чтобы скоординировать свои усилия на текущий рабочий день. Интересно различие, которое наблюдается между этим зарождающимся поведением в Канбане и Scrum. В Scrum сначала встречаются небольшие команды, а затем каждая из них посылает делегата на скрам-над-скрамом, чтобы скоординировать программу или большой проект. В Канбане все происходит наоборот: сначала – крупное совещание программного уровня.
Собрания по пополнению очереди
Собрания по пополнению очереди в Канбане призваны расставить приоритеты. Этот этап обычно откладывается на последний момент в связи с природой механизма пополнения очереди и каденции совещаний. Собрания по пополнению очереди проводятся с привлечением группы бизнес-представителей или владельцев продукта (если использовать терминологию agile-разработки). Рекомендуется проводить такие собрания с регулярными интервалами. Равномерный темп снижает координационные затраты и придает надежность отношениям между бизнесом и командой разработки ПО.
Цель подобного собрания – встроить входящую очередь канбан-системы в цепочку ценности, систему или проект. Заинтересованные в конечном продукте команды лица, имеющие свои элементы в бэклоге, должны посетить это собрание. Причем представители бизнеса на нем занимают максимально высокое положение в своих организациях: чем значительнее должность такого сотрудника, тем больше решений он может принять. К тому же нередко он обладает большей ситуативной информацией, что повышает качество принятия решений и оптимизирует процесс выбора элементов, пополняющих очередь.
В идеале в собрании по расстановке приоритетов должны участвовать несколько владельцев продукта или представителей бизнеса из потенциально конкурирующих групп внутри компании. Порождаемое этим напряжение полезно при принятии решений и стимулирует создание более здоровой среды взаимного сотрудничества с командой разработчиков. Если присутствует только один владелец продукта, потенциалу взаимодействия это не поможет.
На собрании присутствуют и другие заинтересованные лица. Желательно, чтобы среди них были ответственный за выполнение (например, менеджер проекта), как минимум один менеджер, отвечающий за техническую функциональность (например, менеджер по разработке или тестированию либо более высокопоставленный менеджер из той же области), человек, способный оценить технические риски (например, технический архитектор системы или архитектор данных), профессионал в области эргономики, специалист по операциям и системам, бизнес-аналитик. В 2007 году в моей команде на собраниях бывали менеджер по разработке и менеджер команды аналитиков, а иногда также корпоративный архитектор или архитектор данных. Менеджеры по разработке посещают собрания поочередно в соответствии с графиком.
Каденция собраний по расстановке приоритетов влияет на размер очереди в канбан-системе, а следовательно, и на общее время выполнения в системе в целом. Чтобы добиться максимальной гибкости команды, рекомендуется проводить такие собрания как можно чаще, желательно еженедельно.
Некоторые команды в итоге пришли к расстановке приоритетов в соответствии с нагрузкой, отказавшись от регулярных собраний. Это могут себе позволить только самые зрелые организации, в которых все заинтересованные лица могут сразу же посетить собрание. В кейсе Microsoft из главы 4 менеджер проекта разработал триггеры базы данных, которые предупреждали его об освобождении места во входящей очереди. После этого он обсуждал приоритеты с четырьмя владельцами продукта по электронной почте, сообщая им, что освободилось место, и предлагая выставить кандидатов. Следовала переписка, и в итоге выбирали новый элемент бэклога. Процесс обычно занимал около двух часов. Внедрение такой работающей по запросу системы позволяет сократить по сравнению с еженедельными собраниями размер входящей очереди, что приводит к сокращению времени выполнения во всей системе.
Совещания по планированию поставок
Совещания по планированию поставок проводятся для составления плана дальнейшей работы. Если релизы выходят систематически, например раз в две недели, то нужно назначить и регулярные совещания по их планированию. Это снижает координационные издержки и обеспечивает присутствие всех необходимых участников, которые могут заранее скорректировать свой график.
Человек, ответственный за координацию выполнения (обычно это менеджер проекта), как правило, ведет и совещания по планированию поставки. Следует пригласить и все остальные заинтересованные стороны – специалистов по управлению конфигурацией системы, специалистов по эксплуатации системы и сети, разработчиков, тестировщиков, бизнес-аналитиков и т. д., а также непосредственных руководителей перечисленных сотрудников, которые присутствуют благодаря своим техническим познаниям и умению оценивать риски. Менеджеры участвуют в совещании, чтобы можно было немедленно принять решения.
У зрелой компании обычно готова технологическая карта или структура релиза, что облегчает планирование. Вот некоторые вопросы, которые нужно принимать во внимание:
• Какие элементы системы готовы (или будут готовы) для релиза?
• Что требуется, чтобы действительно подготовить релиз всех элементов?
• Какое тестирование потребуется после релиза, чтобы проверить жизнеспособность систем продукта?
• С какими рисками это сопряжено?
• Как эти риски минимизировать?
• Какие планы экстренных мероприятий потребуются?
• Кто будет участвовать в релизе до момента его запуска в производство или другого механизма выполнения?
• Сколько времени займет релиз?
• Что еще для него необходимо?
В результате должен получиться заполненный шаблон, представляющий собой план релиза. Иногда я встречал даже запись релиза, представляющую собой своего рода оркестровку процедур, которые должны быть выполнены в заданном порядке.
На больших совещаниях заполнение плана релиза не всегда возможно, так что требуется последующая дополнительная независимая работа менеджеров проекта.
Триаж
Триаж – это медицинский термин, который обозначает оценку и классификацию срочно поступивших больных по степени неотложности врачебной помощи. Сначала эта система применялась в военно-полевых условиях, где пациентов делили на три категории: умирающие, кому оказать помощь уже нельзя; те, кто может выжить только при неотложной помощи; и те, кто, скорее всего, останется в живых и без срочной помощи. И сейчас в приемных покоях больниц существует подобная система классификации пациентов.
Триаж был усвоен разработчиками ПО для систематизации дефектов во время стабилизационной фазы традиционного программного проекта. Триаж использовался для отделения ошибок, которые должны быть устранены (и очередности их устранения), от тех, что останутся и могут пойти в производство при выходе продукта. Обычно триаж ошибок проводили ведущий тестировщик и ведущий разработчик, руководители группы тестирования и разработки, а также владелец продукта.
В Канбане тоже имеет смысл проводить триаж ошибок. Однако еще полезнее применять его к элементам бэклога, ожидающим поступления в систему.
Триаж бэклога нужно проводить сравнительно нечасто. (Заметим, что в некоторых методах гибкой разработки ПО он называется «грумингом».) Разные команды предпочитают различную периодичность – ежемесячно, ежеквартально, дважды в год. При триаже бэклога обычно присутствуют те же владельцы продукта и представители бизнеса, которые ходят на собрания по пополнению очереди, а также менеджер проекта. Технических сотрудников немного – нередко они представлены одним менеджером среднего звена.
Цель триажа бэклога – проанализировать все эти элементы и решить, оставить их или удалить. При этом не назначаются никакие ранги и не расставляются приоритеты: выбор стоит единственный – оставить или удалить.
Некоторые команды смогли отказаться от триажа благодаря автоматизации и внутренним правилам. Так, команда Microsoft XIT из кейса в главе 4 ежемесячно удаляла из бэклога все элементы старше шести месяцев. Считалось, что если элемент за полгода так и не перевели во входящую очередь, то он вряд ли обладает существенной ценностью и, возможно, его вообще никогда не выберут. Но при изменении ситуации его всегда можно затребовать обратно, так что удаление из бэклога ничего не испортит.
Цель проведения триажа бэклога – сокращение его размеров. Преимущество меньшего размера бэклога – в облегчении процедуры обсуждения приоритетов. Выбирать из 200 элементов гораздо проще, чем из 2000.
Неплох также метод, при котором бэклог подвергается значительному сокращению, если работа по нему превышает три месяца пропускной способности и все элементы за это время не могут попасть в систему. У разных рынков и отраслей свои оптимальные размеры бэклога. Отраслям с высокой изменчивостью подойдет бэклог на месяц работы. Если же изменчивость низкая, то бэклог может содержать элементы даже на год вперед.
Таким образом, существует взаимосвязь между бэклогом, изменчивостью в отрасли, в условиях которой работает конкретная канбан-система, и скоростью выполнения, или пропускной способностью команды. Если команда выполняет 20 пользовательских историй в месяц, а отрасль обладает определенной, но не слишком большой изменчивостью, то предпочтителен бэклог на три месяца работы, то есть он должен содержать примерно 60 элементов.
Анализ журнала проблем и эскалация наверх
Когда рабочие единицы в системе Канбана замедляются, они получают соответствующую отметку и создается запись о рабочей проблеме. Эта проблема остается открытой, пока затруднения не будут решены, так что исходная рабочая единица продолжает движение по системе. Анализ открытых проблем, таким образом, необходим для ускорения хода работы.
Анализ журнала проблем должен проводиться часто и регулярно. Регулярность снижает координационные издержки и обеспечивает присутствие всех заинтересованных лиц, которые могут заранее выкроить для этого время. Очень зрелым организациям хватает регулярных совещаний, к которым добавляются срочные встречи. Этого достаточно, если количество проблем невелико, а повышенные координационные издержки на срочные совещания обходятся дешевле, чем стоимость проведения регулярных.
В анализе журнала проблем должны принимать участие менеджер проекта и члены команды, которые отметили элементы как блокированные. При этом следует ответить на вопросы «Кто отвечает за проблему и работает над ней?» и «Когда ожидается ее разрешение?». Проблемы, в решении которых нет прогресса и работа над которыми блокирована, должны быть переданы высшему руководству.
Представителям высшего руководства необязательно присутствовать на анализе журнала проблем, но важно установить четкий регламент передачи проблем наверх. Когда решение проблемы блокировано, менеджер проекта должен взять на себя ответственность и передать этот вопрос на рассмотрение руководителей.
Обычно работа с проблемами и передача их наверх – узкое место даже в организациях, принявших agile-методы разработки. Быстрое решение проблем, особенно тех, которые не зависят от команды разработки – доступность среды, не вполне понятные требования, недостаток оборудования для тестирования, – ускоряет рабочий поток и значительно увеличивает как производительность команды, так и создаваемую ценность. Устранение проблем и передача их наверх – очень важные элементы работы, которые окупаются сторицей. Улучшения в них должны стать приоритетом даже для незрелых команд. Подробнее об этом – в главе 20.
Стикерные представители
Идея стикерных представителей была предложена в Corbis для решения проблемы координации. Правила компании предусматривали возможность работать дома как минимум раз в неделю, особенно для тех сотрудников, которые жили далеко от офиса. Эти правила восходили еще ко времени переезда из Бельвю в Сиэтл, который состоялся за несколько лет до того. Удаленно работавшие сотрудники имели доступ к электронной системе управления задачами, контролю версий, среде разработки и другим системам через VPN. Поэтому они могли видеть, на какую работу назначены, заниматься ею, завершать ее и тестировать, а также обновлять ее электронный статус, помечать как законченную и готовую двигаться дальше по рабочему потоку. Однако поскольку они не присутствовали в офисе, они не могли передвинуть стикер на стене карточек.
Решили договариваться с кем-то из находящихся в офисе коллег: любой сотрудник мог стать представителем удаленного работника. Когда последний завершал работу над элементом и изменял его электронный статус, он связывался со своим стикерным представителем по электронной почте, сервису мгновенных сообщений или по телефону и просил обновить информацию на доске.
Стикерные представители помогают и при разработке, распределенной по нескольким географическим зонам. Особенно важно это было для Corbis, когда команда тестировщиков работала в Ченнаи (Индия), а некоторые специализированные разработчики финансовых систем находились в Южной Калифорнии.
Синхронизация по географическим зонам
Вопрос синхронизации команд при использовании канбан-систем в разных географических зонах постоянно поднимается теми, кто задумывается о переходе на канбан-систему. Часто эти люди полагают, что ранние варианты Канбана относились к единой географической зоне и что я (и другие защитники Канбана) не учел трудности координации географически распределенных команд.
На самом деле все наоборот. Первая команда в Microsoft (из главы 4) находилась в индийском Хайдарабаде, в то время как руководство и владельцы продукта размещались в американском Редмонде. У компании Corbis, описанной в главе 5, тоже были команды и в Индии, и в других местах за пределами Сиэтла – например, в Лос-Анджелесе и Нью-Йорке, и это не считая людей, периодически работавших дома.
Решить вопрос координации между разными местами можно при помощи электронной системы. Одной стены карточек недостаточно.
Помимо электронного ведения задач понадобится ежедневно синхронизировать физические стены карточек. Важно, чтобы за этим в каждом офисе следил специально назначенный человек. Одна команда, с которой мы работали в 2008 году, базировалась в Нью-Йорке и Лос-Анджелесе. У них были (почти) идентичные стены карточек в каждом офисе, и за их синхронизацию в обоих случаях отвечал определенный сотрудник.
Некоторые команды координируют и стендап-совещания – по телефону или через системы видеоконференции. Однако перед любым совещанием, видеоконференцией или телефонным звонком ответственный сотрудник должен убедиться, что канбан-доска синхронизирована с электронной системой.
Выводы
• Лучше всего использовать и физическую стену карточек, и электронную систему управления задачами.
• Канбан может использоваться в разных географических зонах, если у команд на вооружении есть электронная система управления задачами.
• Электронные системы, симулирующие функциональность физических стен карточек, предлагаются многими поставщиками.
• Проведение регулярных совещаний снижает координационные издержки на них и идет на пользу посещаемости.
• Расстановка приоритетов и планирование релиза должны проводиться независимо друг от друга и иметь свой собственный ритм.
• На ежедневных совещаниях на ходу необходимо обсуждать проблемы, издержки и рабочий процесс. Обычно они не следуют установившимся образцам других методов agile-разработки.
• Ежедневные стендап-совещания – неотъемлемая часть пути к культуре постоянного совершенствования. Поскольку они каждый день собирают команду в полном составе, все заинтересованные лица получают возможность предлагать и обсуждать возможности для улучшения. После совещания часто возникают неформальные беседы об оптимизации процессов.
• Регулярный триаж бэклога в целях его сокращения положительно влияет на скорость и эффективность совещаний по расстановке приоритетов.
• Работа с проблемами, передача их наверх и решение имеют большое значение для повышения производительности команды, поэтому на них нужно обратить внимание на самых первых этапах работы команды.
• Способы и методы передачи проблем высшему руководству должны быть четко определены.
Глава 8 Формирование каденции поставки
Раздел 3 (главы 6–15) описывает механизмы внедрения канбан-системы, заканчиваясь главой 15, где говорится о том, как выступить с инициативой перехода на Канбан. Инициация перехода требует договоренности с различными внешними заинтересованными лицами, а не только с клиентами, типичными для компаний по разработке и их партнеров. Например, эта новая договоренность предполагает обязательство по регулярной выдаче работающего продукта.
Термин «каденция поставки» предполагает установление паттерна выдачи релизов работающего продукта с регулярными интервалами. Например, если мы договорились выдавать продукт каждые две недели, то каденция поставки будет составлять раз в две недели, или 26 раз в год. Возможно, появится даже решение по конкретному дню поставки. Например, каждую вторую среду, как это было с корректировочными версиями IT-приложений в Corbis.
В кругах, близких к гибкой разработке ПО, устоялось мнение о важности регулярной каденции. В agile-методах разработки она достигается благодаря сгруппированным по времени итерациям длиной от одной до четырех недель. Необходимость таймбоксинга (ограничения по времени) основана на том, что для проекта очень важен устойчивый ритм, а для этого нужно применять строго ограниченные по времени итерации. В начале каждой итерации определяется объем работ (бэклог итерации) и обязательства по их выполнению. Все приходит в действие! Проводятся анализ, планирование тестов, проектирование, разработка, тестирование и рефакторинг. Если все идет по плану, то запланированная работа делается в полном объеме. Итерация заканчивается предоставлением работающего продукта и ретроспективным собранием, на котором обсуждаются возможности будущих усовершенствований и модификаций процесса. Затем цикл повторяется с четко заранее оговоренной частотой – еженедельно, раз в две недели, ежемесячно и т. д.
Канбан избавляется от ограниченных во времени итераций и вместо этого рассинхронизирует деятельность по расстановке приоритетов, разработке и поставке. Каденция для каждой из них устанавливается и корректируется естественным образом. Однако Канбан не отказывается от понятия «регулярная каденция». Канбан-команды по-прежнему с заданной частотой выдают версии продукта, предпочитая короткие интервалы. Метод тоже работает в соответствии с «Принципами манифеста гибкой разработки»{19}. Однако Канбан старается избегать любых крайностей, связанных с искусственной установкой временных рамок для задач.
За последние десять лет команды, использующие agile-методы, пришли к выводу, что лучше меньше незавершенных задач, чем больше, и что поставка функционала небольшими порциями предпочтительнее всего. Поэтому в середине последнего десятилетия произошел переход на более короткие итерации. Так, типичные команды Scrum перешли с четырехнедельных циклов на двухнедельные, а команды, практикующие экстремальное программирование, – с двухнедельных на недельные. В результате возникла проблема с делением работы на малые порции – порой бывает трудно сделать их достаточно малыми, чтобы их выполнение укладывалось в доступное временное окно. Рынок ответил на это, создав более изощренные методы анализа и написания пользовательских историй. Цель – сократить размер историй, сделать их детализированнее и снизить вариативность размера, чтобы уложить их в более короткие итерации. Хотя такой подход кажется вполне здравым, достичь этого трудно. Он относится к шестому элементу рецепта успеха: атака на источники вариативности для улучшения предсказуемости. Как уже говорилось в главе 3, сокращение вариативности часто требует от людей изменить свое поведение и обрести новые навыки. А это очень непросто.
Поэтому у команд возникают сложности при написании коротких пользовательских историй, которые можно уложить в небольшие, ограниченные по времени итерации. Это привело к ряду функциональных нарушений. Первое из них – отказ от сокращения итераций и возвращение к более долгим. Альтернатива – написание таких пользовательских историй, которые сосредоточены на элементах архитектуры или какой-то технической декомпозиции требований. Так появляются, например, отдельные истории для пользовательского интерфейса, уровня хранения данных и т. д. Еще одна альтернатива – разбить историю по трем итерациям на фазы, когда первая итерация предполагает анализ и, возможно, планирование тестов, вторая – разработку кода, а третья связана с системным тестированием и отладкой. Встречаются либо одна из этих альтернатив, либо сразу обе. При этом они не имеют ничего общего с ограниченными по времени итерациями и лишь маскируют тот факт, что работа продолжается, хотя о ней уже отчитались как о законченной.
Канбан отделяет время реализации пользовательских историй от темпов их поставки. Когда какая-то часть работы завершена и готова к сдаче, над другими элементами еще нужно работать. Отделив время разработки от каденции поставки, мы можем спросить и о том, как часто должна проходить расстановка приоритетов (а также планирование и оценка). Трудно поверить, что обсуждения планирования, оценки и расстановки приоритетов должны проводиться с той же частотой, что и разработка и сдача программ. Это совершенно непохожие функции, часто требующие внимания разных групп людей. Координационная деятельность по сдаче работы определенно отличается от координационной деятельности по расстановке приоритетов для новой работы. Канбан позволяет распараллелить эти виды деятельности.
Канбан также отделяет каденцию расстановки приоритетов от общего времени выполнения по всей системе и от каденции сдачи работы. В этой главе говорится об элементах, связанных с договоренностью о подходящей каденции поставки, и о том, когда поставка может происходить согласно запросу или сложившейся ситуации, а не регулярному расписанию (если оно вообще возможно). В соответствии с теми же принципами глава 9 рассказывает о том, как установить каденцию расстановки приоритетов и когда она может происходить по запросу или по ситуации, а не на специальном регулярном совещании. В главе 11 говорится о том, как задать ожидания времени выполнения и как определить содержание релиза.
Координационные затраты на релиз
Координация любого программного релиза связана с затратами. Необходимо собрать людей для обсуждения выпуска, производства, упаковки, маркетинга, работы с потенциальными клиентами, документации, подготовки конечных пользователей, дилеров, отдела справок и службы технической поддержки, документации и процедур по установке, дежурных сотрудников, расписания выпуска и т. д. Планирование поставки элемента работающей программы бывает невероятно сложным – все зависит от отрасли бизнеса и типа программы. Обновление сайта, например, может оказаться тривиальной задачей по сравнению с обновлением прошивки военного оборудования, используемого по всему миру, спутников на орбите, боевого самолета или узлов телефонной сети. В 2002 году, когда мы планировали релиз обновления PCS Vision для американской сети сотовых телефонов Sprint PCS, требовалось обучить десятки тысяч людей. Нужно было объяснить 17 тысячам продавцов по всей стране, как работают около 15 новых телефонов, выводимых на рынок. Примерно такому же количеству человек предстояло объяснить, как отвечать на неизбежные звонки в службу техподдержки, которые обязательно последуют, когда неопытные клиенты приобретут свои новые устройства. Одно только планирование обучения 30 тысяч человек обходится недешево.
Поэтому важно понимать координационные издержки, связанные с релизом. Например, если разработчикам нужно посещать совещания по координации релиза, то не отрывает ли это их от работы над программами? Ниже представлен список вопросов, которые нужно задать себе в первую очередь.
• Сколько совещаний?
• Сколько людей?
• Сколько времени это займет?
• Каков будет ущерб в результате отрыва людей от их основной работы?
Операционные расходы релиза
В случае с физически существующими товарами легко представить себе операционные расходы. Первый из них – платеж. Клиент платит поставщику, используя некое платежное средство, например кредитную карточку. За удовольствие получить платеж по кредитной карте ведущие компании в этой сфере, например MasterCard и Visa, взимают с продавца операционные расходы, обычно составляющие 2–4 % от стоимости сделки.
Помимо затрат на финансовые расчеты между продавцом и покупателем нужно учесть и возможные расходы на доставку – а это не только деньги, но и время и рабочая сила. Могут быть также и монтажные расходы. Например, вы покупаете в Sears стиральную машину и заказываете доставку на определенный день. Тем временем происходит планирование и уточнение, чтобы водитель доставил выбранную модель в нужный дом в правильное время и в срок. Все это – координационные расходы на доставку. Водитель забирает стиральную машину на складе, везет ее к вам домой и распаковывает там – это операционные расходы. Он же или вызванный специалист устанавливает ее. Специалисту нужно время, чтобы добраться до вашего дома, а затем установить купленное устройство. Все это – время, усилия на доставку и монтаж – составные части операционных расходов на покупку стиральной машины.
С экономической точки зрения розничный оператор абсорбирует операционные расходы на использование кредитных карт. Но операционные расходы на доставку и монтаж часто оплачивает покупатель. При этом не все они «видны» или «ощутимы» участниками цепочки создания ценности, но влияют на экономическую производительность системы в целом. Результат всех этих издержек состоит в повышении конечной стоимости, которую выплачивает покупатель, но при этом поставляемая ценность не увеличивается.
Действительно, от стиральной машины без доставки и установки мало толку, но ее ценность состоит в том, что она стирает одежду. Доставка и установка не создают ценности, так что должны быть отнесены к операционным расходам.
В разработке ПО операционные расходы на поставку программ тоже могут быть по своей природе физическими.
Так, некоторые фирмы, например Microsoft, продолжают производить «окончательные версии для промышленной эксплуатации» (RTM) и выпускают физические носители – DVD, упаковывают их и рассылают распространителям, розничным операторам и другим партнерам. Если ПО – часть встроенной системы, то необходимой может оказаться поставка чипов или, по крайней мере, запись программного кода в прошивку при помощи таких технологий, как EE-PROM. Чипы после этого, вероятнее всего, придется вмонтировать в оборудование, которое они призваны контролировать.
В иных случаях достаточно электронного распространения. Например, прошивку и настройки сотовых телефонов сейчас обновляют посредством так называемого управления устройством «по воздуху». Так же можно поступить с прошивкой многих спутников и автоматических межпланетных станций, поэтому космические аппараты сейчас стали намного более гибкими, чем ранее. Их работу можно изменить, загрузив новое оборудование. Ошибки тоже можно исправлять на местах. Некоторые печально известные дефекты, например фокусировка телескопа «Хаббл», были (частично) исправлены за счет изменения программного кода. Это трансформировало экономику эксплуатации.
Многие из тех, кто читает эти строки, возможно, занимаются веб-разработкой или разработкой внутренних приложений. Для них поставка – это просто копирование файлов на диски на других машинах. Это может показаться элементарным делом, но на самом деле не все так просто. Нередко необходимо планировать сложную процедуру плавного отключения баз данных, серверов приложений и других систем, их обновления и последующего возвращения в эксплуатацию. Одна из самых сложных задач – перенос данных с одного поколения схемы базы данных на другое. Базы данных бывают очень большими. Процесс сериализации данных в файл, их парсинга, распаковки, возможного дополнения другими данными, нового парсинга и распаковки в новую схему может занять несколько часов или дней.
В некоторых средах поставка ПО длится часы и даже дни. Часто это связано не с качеством программ или ошибками в их архитектуре, а с природой отрасли, в которой они должны функционировать. Все виды деятельности, связанные с успешной поставкой ПО (происходит ли она в форме запакованных приложений, встроенной прошивки или IT-приложений, работающих на внутренних серверах), должны быть просчитаны, распланированы, для них составляется расписание, изыскиваются ресурсы – и только затем происходит поставка. Все эти виды деятельности создают операционные расходы по релизу.
Эффективность поставки
Уравнение, оценивающее эффективность поставки, можно вывести двумя способами. Наиболее простой из них – рассмотреть финансовые и трудовые затраты. Другой метод связан с анализом создаваемой ценности.
Итак, первый вариант – модель на основе затрат. Мы должны учесть общие расходы между релизами. Часто их величина известна – это среднемесячные затраты организации. Если мы выпускаем релиз каждый месяц и ежемесячные затраты составляют 1,3 миллиона долларов, то наши расходы равняются минимум 1,3 миллиона долларов на релиз. В координационные издержки могут быть также включены расходы на физическое производство, печать, рекламу и накладные. Все это легко подсчитать. Предположим, они равняются 200 тысячам долларов. Итак, общая стоимость релиза составляет полтора миллиона.
Мы знаем, что дополнительные накладные расходы на релиз равны 200 тысячам, но какая часть из 1,3 миллиона потрачена на планирование, координацию и поставку продукта? Если у нас есть подходящие данные по учету рабочего времени, то можно посчитать и это. Но даже если их нет, мы все-таки способны сделать близкое к истине предположение. Сколько совещаний, людей? Как долго длились совещания? Включите сюда и число человеко-часов, потраченных на сдачу продукта. Умножьте на часовую ставку. Если результат составил около 300 тысяч долларов, то мы получили величину операционных и координационных издержек релиза на полмиллиона.
Эффективность релиза в процентах = 100 % × (общие затраты – (координационные затраты + операционные затраты)) / общая стоимость программного релиза.
В нашем примере эффективность равна
100 % × (1 500 000 – 500 000) / 1 500 000 = 66,7 %.
Чтобы быть эффективнее, нужно либо увеличить интервал между релизами, либо снизить координационные и операционные издержки. Первый вариант – это стандартный выбор западного бизнеса ХХ века и связан с «эффектом масштаба»: нужно производить большие партии, чтобы амортизировать издержки в долгосрочной перспективе. Второй вариант типичен для японского бизнеса конца ХХ века и компаний, стремящихся к бережливому мышлению. Он борется посредством снижения координационных и операционных расходов за то, чтобы размер партии был эффективен (в нашем случае речь идет об эффективности времени между релизами).
Какая эффективность считается достаточной?
Этот вопрос остается открытым. У всех компаний свои взгляды на достаточные показатели эффективности, и многое зависит от создаваемой ценности.
Формирование каденции поставки
Когда мы осознали, какую ценность будет приносить данная поставка, можно принять оптимальное решение относительно темпов. Если ежемесячный программный релиз будет давать выручку в два миллиона при затратах в полтора, то несложно подсчитать, что наша прибыль составит полмиллиона. Можем переписать уравнение эффективности так:
Эффективность релиза в процентах = 100 % × (1 – ((операционные затраты + координационные затраты) / (прибыль + операционные затраты + координационные затраты))).
В нашем примере показатель эффективности составит
100 % × (1 (500 000 / (500 000 + 500 000))) = 50 %.
А теперь все становится еще сложнее, поскольку подсчет истинной ценности релиза может оказаться почти невозможным. У нас может не появиться заказов по твердым ценам. Мы можем спекулировать на потреблении рынка, изменяя тем самым стоимость товара и прибыль. Мы можем выпускать релизы, которые скажутся на неосязаемых активах – например, изменении идентичности бренда, маркетинговых материалах или пакете устранения ошибок и улучшении потребительских свойств продукта или сайта.
Не легче вычислить, стоит ли во имя эффективности снизить темп и выпускать релизы пореже. Увеличение времени выхода на рынок может негативно сказаться на рыночной доле, цене и прибыли. Идея эффективности релиза не является знанием в области точных наук. Важнее всего то, что вы, команда и организация в целом имеете представление о расходах на релиз – затратах времени и денег – и способны провести рациональную оценку, которая приведет к расчету приемлемой частоты релизов.
Если команде из пятидесяти человек требуется три дня и десять сотрудников для успешной выдачи кода, то стоит ли выпускать релиз каждые десять рабочих дней (то есть две календарные недели)? Ответ, вероятно, отрицательный. Лучше установить месячную каденцию (то есть двадцать рабочих дней). Но в то же время не стоит забывать об особенностях рынка, где гибкость и время выхода на рынок имеют большое значение, а риски в основном гасятся более частыми релизами. Так что игра стоит свеч. Вы должны все взвесить и принять самостоятельное решение.
Увеличение эффективности для ускорения каденции поставок
Вернемся к нашему примеру. Мы пришли к выводу, что десять человек выпускают код за три дня. Из этого мы заключили, что приемлемыми будут ежемесячные релизы. Однако некоторые сотрудники считают, что при улучшении качества кода, управления конфигурациями, инструментов для управления, переноса данных и регулярных репетиций процедур распространения продукта удастся сократить трехдневный срок работы до восьми часов, и тогда внезапно оказывается, что вполне возможна двухнедельная и даже еженедельная каденция. Что вы будете делать?
Я бы предложил начать с консервативного подхода. Согласитесь на ежемесячный релиз. Пусть организация докажет, что может добиться такого уровня надежности. Через несколько месяцев оцените качество кода и учредите программу улучшения управления конфигурациями. Если существуют резервные ресурсы, то привлеките их для создания новых инструментов улучшения переноса данных по схемам в ходе релиза. Наконец, предложите команде репетировать релизы в условиях среды для переноса данных. Возможно, такую среду потребуется приобрести, установить и ввести в эксплуатацию. Все это займет время.
Поставьте перед командой и функциональными менеджерами, отвечающими за выход релизов, задачу сократить операционные и координационные издержки. Если это удается, то рассмотрите ход работы на совещании по анализу операций и согласуйте взаимодействие с другими заинтересованными лицами. Когда вы почувствуете, что ускорение каденции релизов, например до двухнедельной, возможно, – переходите на нее!
Снижение координационных и операционных издержек – это суть бережливого программирования. Здесь устранение неоправданных потерь проявляется наиболее ярко. Благодаря ему мелкие партии становятся эффективными, развивается деловая гибкость. Снижение координационных и операционных издержек меняет правила игры. Однако не стоит сосредоточиваться на них как на самоцели. Не забывайте, что ваша цель – чаще выпускать работающие программы, а следовательно, чаще создавать ценность для клиентов.
Релизы по запросу и по ситуации
У регулярных релизов есть свои преимущества. Приняв обязательства сдавать работу в определенные сроки, например каждую вторую среду, вы даете возможность выстраивать вокруг них рабочее расписание. Это рождает уверенность и может привести к сокращению координационных издержек, поскольку не возникает недопонимания относительно того, когда выпускать релиз и кто должен в этом участвовать. Все это установлено раз и навсегда.
Регулярные релизы также помогают создать доверие. А недостаток предсказуемости его разрушает. Отсутствие релиза в назначенную дату привлекает гораздо больше внимания, чем конкретное содержание этого релиза.
При всех очевидных достоинствах регулярной каденции релиза необходимо отметить, что иногда релизы выпускаются по запросу или по ситуации. При каких обстоятельствах это происходит?
Во-первых, релиз по запросу или по ситуации выпускают, если координационные издержки на него сравнительно невелики. Когда координационные затраты и так небольшие, выгоды от постоянных мероприятий по координации практически нет. Во-вторых, такой релиз оправдан при небольших операционных издержках – например, если распространение кода во многом автоматизировано, а качество обеспечено сразу, еще до поставки. Наконец, это имеет смысл в тех ситуациях, когда релизы выпускаются настолько часто, что не нужно разрабатывать для них специальный шаблон. Новые программы появляются практически друг за другом, и большинству наблюдателей и внешних заинтересованных лиц их поток кажется постоянным – они даже не задумываются над датой выхода следующего релиза. А когда нет ожиданий, нет и разочарований.
Такая почти непрерывная выдача кода полезна для некоторых отраслей. Примеры, известные мне от ранних последователей Канбана, в основном связаны с медиаиндустрией: это, в частности, IPC Media в Лондоне, где используются многочисленные канбан-системы для планирования разработок онлайн-медиа, например mousebreaker.com, невероятно популярной онлайн-игры.
Снижение координационных и операционных затрат – признак высокой зрелости организаций. Это относится и к ранним последователям Канбана. Так, XIT-отдел Microsoft сотрудничал с поставщиком из Индии, обладающим пятым уровнем по шкале зрелости организаций, и Microsoft IT из Редмонда, находившимся примерно на третьем уровне. В зрелых организациях высок уровень доверия между членами цепочки создания ценности и внешними заинтересованными лицами, в том числе высшим руководством, поэтому для создания такого доверия не требуется разработки регулярной каденции релизов.
Одним словом, можно смело рекомендовать регулярную каденцию релизов, за исключением тех случаев, когда доверие, высокий уровень мощности и зрелости организации уже существуют, а сфера действий компании предполагает практически непрерывные релизы.
Есть и еще одно обстоятельство, при котором приемлемы релизы по запросу, – когда запрос классифицируется как срочный и обрабатывается как особый случай. Идея ускоренного класса обслуживания подробно рассмотрена в главе 11. Мы можем принять решение об ускорении процесса по ряду причин, главная из которых – наличие критичной ошибки в продукте. Когда следует устранить проблему любой ценой, выпускайте релиз вне цикла.
Есть и другие случаи, в которых возможны релизы вне цикла. Например, команда отдела продаж получает заказ от крупного клиента, который хочет получить персонализированную версию программы, но из-за бюджетных ограничений или финансового цикла нужно успеть с релизом до конца месяца (квартала). Тогда оперативная группа поручает отделу разработки бросить все и заняться этим заказом, поскольку он сулит большую выручку.
В подобных случаях стоит запланировать особый релиз вне цикла. Он должен считаться исключительным, и после него следует как можно быстрее восстановить обычную каденцию. Впрочем, не забывайте о здравом смысле. Если, например, регулярный релиз запланирован на среду, а внеочередной – на пятницу той же недели, то лучше отложить релиз, назначенный на среду, до пятницы. Решив поступить именно так, важно как можно быстрее сообщить об этом всем участникам, чтобы изменить их ожидания. Нельзя допустить потери доверия со стороны партнеров по цепочке ценности как побочного эффекта от вашего старания быть покладистым и помочь.
Выводы
• Каденция поставки – это оговоренный заранее регулярный интервал между поставками работающего оборудования.
• Канбан отделяет каденцию поставки как от времени выполнения, так и от каденции пополнения.
• Короткие, ограниченные во времени итерации привели некоторые команды, желающие усвоить agile-методы, к печальным результатам.
• Любая поставка программного обеспечения требует координации многих людей, выполняющих различные функции. Все расходы на такую координацию могут быть подсчитаны.
• Выпуск программ влечет за собой операционные затраты как времени, так и денег. Эти затраты можно определить и отследить.
• Эффективность поставки можно подсчитать, сравнив сумму операционных и координационных издержек на релиз с общей стоимостью (или ежемесячными затратами) на создание программ для этого релиза.
• Каденцию поставки можно установить, сравнив стоимость поставки с общей суммой выручки от него.
• Эффективность и каденцию можно увеличить, сосредоточившись на сокращении операционных и координационных расходов.
• Регулярные поставки порождают доверие.
• Задавая ожидания регулярных поставок и постоянно их оправдывая, вы формируете привычку.
• Планирование регулярных поставок снижает координационные издержки.
• Поставки по запросу или по ситуации имеют смысл для очень зрелых организаций, обладающих высоким и давно установившимся уровнем доверия и низкими операционными и координационными затратами на релиз.
• Правомерные запросы на ускоренное выполнение работ могут стать причиной и для внеочередной поставки. Регулярные поставки нужно возобновить как можно раньше после подобной, особенной поставки.
Глава 9 Формирование каденции пополнения
В этой главе рассказывается об элементах, участвующих в согласовании каденции определения приоритетов, и о том, когда допустима расстановка приоритетов по запросу или по ситуации, а не на регулярной встрече.
Координационные расходы на расстановку приоритетов
Внедряя в 2006 году Канбан в Corbis, мы решили начать с поддержки работ, связанных с незначительными запросами на обновление и устранением ошибок во всех IT-приложениях, включая функциональные (финансовые и кадровые) и более специфические бизнес-системы, такие как управление цифровыми активами и сайт электронной коммерции. Эти системы обслуживали как минимум шесть подразделений – продажи, маркетинг, планирование, финансы и функциональные отделы, – которые управляли поставками цифровых фотографий, метаданных, каталогизированием и наполнением – то есть всей цепочкой поставок бизнеса.
Шесть подразделений конкурировали за общие ресурсы, необходимые для внесения небольших изменений и обновлений. При первом представлении канбан-системы был рассмотрен кейс, направленный на возможность поставки частых, «тактических» релизов командой поддержки. Эта команда обеспечивала ограниченную деловую гибкость путем выпуска небольших, инкрементальных релизов, тогда как новые IT-проекты создавались в соответствии с традиционным процессом управления отдела руководства программой (PMO). Обоснование и авторизация каждого проекта в портфеле проходили в индивидуальном порядке. Команда поддержки была одобрена исполнительным комитетом, на нее выделили 10 % бюджета, что позволило взять еще пятерых сотрудников. Отдел получил название «команда быстрого реагирования» (КБР). Но оно оказалось неудачным, потому что реакция не была быстрой, а иногда вовсе отсутствовала, да и команды как таковой не было.
Создать новый отдел технического обслуживания из этих пяти человек не удалось. IT-системы Corbis были очень разными, многие из них требовали специализированных навыков. Функции аналитиков, разрабатывающих и уточняющих системные требования, давались специалистам особенно тяжело. Пять новых сотрудников примерно на равных выполняли все задачи команды поддержки, включая управление проектами, системный анализ, разработку, тестирование, управление конфигурациями и сборками. То есть никакой команды не существовало. Буква «К» в аббревиатуре КБР ничего не значила. А ведь это считалось отдельной задачей менеджмента – показать, что дополнительные 10 % ресурсов потрачены на работу по обслуживанию и поддержке, а не просто поглощены общими крупными проектами.
Решили ввести в команду поддержки менеджера проекта, которая не занималась исключительно проектом, но стала единой точкой входа для коммуникации и координировала действия. Считалось, что менеджер – это половина штатной единицы из пяти выделенных на инициативу. Также был выделен билд-инженер из команды по управлению конфигурациями. Его задача – поддерживать предпродуктивные среды, необходимые для тестирования и вывода в промышленную эксплуатацию, осуществлять сборку и установку на тестовые среды.
Чтобы сохранить целостность общей среды тестирования, которая использовалась при работе над всеми проектами, Corbis ввела правило, согласно которому только билд-инженеры могли переносить код из среды разработки в среду тестирования. Позднее оно изменилось, но в сентябре 2006 года для передачи кода в тестирование был необходим билд-инженер.
До введения Канбана расходы на координацию – согласование требований для релиза техподдержки – были чрезмерными. Менеджеру проекта Дайане Коломиец, а часто и ее руководителю, менеджеру группы проектов, нужно было собрать встречу с участием всех заинтересованных сторон – бизнес-аналитиков, представителей бизнеса, системных аналитиков, руководителей разработки, руководителей групп тестирования и билд-инженера, а иногда также менеджера по управлению конфигурациями, представителей служб поддержки и сопровождения. Такие совещания порой длились несколько часов и заканчивались безрезультатно: членам разных команд поручалось провести оценки и назначалась следующая встреча. Она нередко переходила в дискуссию о приоритетах и тоже завершалась ничем. В сентябре 2006 года, чтобы договориться об объеме релиза, выпуск и поставка которого занимали две недели, приходилось затрачивать те же две недели на бесконечные совещания. Из-за двухнедельных итераций в релиз включались только очень небольшие задачи, а многие потенциально прибыльные запросы игнорировались. Эти запросы перенаправлялись в основной проект, поэтому период внедрения составлял месяцы, а порой и годы. Система, использовавшаяся до канбан-системы, не предполагала ни быстроты, ни реагирования. Буквы «БР» в аббревиатуре КБР не имели смысла.
Канбан освободил команду от лишних обязанностей, и она сумела стать реальной группой быстрого реагирования.
При внедрении канбан-системы руководителям бизнес-подразделений рассказали о рабочем потоке, входящей очереди и механизме вытягивания. Они узнали, что им нужно будет просто заполнять освободившиеся места в очереди, а расстановкой приоритетов в бэклоге заниматься необязательно. Если в очереди свободны два места, то основной вопрос – «Какие два новых элемента вы хотели бы передать в работу?». С учетом того, что у нас есть данные по среднему времени выполнения и срокам сдачи работы, а также целевому времени выполнения в соглашении об уровне обслуживания, вопрос может звучать еще конкретнее: «Какие два элемента вы хотели бы получить через тридцать дней?» Основная проблема заключалась в том, что шесть конкурирующих руководителей должны были выбрать только две задачи из всех возможных.
Тем не менее вопрос выглядел простым и предполагалось, что ответить на него можно в течение часа. Все согласились с тем, что час – это достаточный срок, и руководителей бизнес-подразделений спросили, готовы ли они потратить шестьдесят минут в неделю на еженедельные совещания по расстановке приоритетов, где будет пополняться входящая очередь заданий для команды инженерного обеспечения.
Формирование каденции расстановки приоритетов
Совещания отныне проводились по понедельникам в 10 утра. На них обычно приходили те же представители высшего руководства, которые раньше посещали совещания по установлению объемов релиза, – как правило, это были вице-президенты функциональных групп. Помимо них присутствовали менеджер проекта, CEO по разработке, CEO по IT-сервисам (в сферу компетенции которого входило управление проектом), минимум один менеджер по разработке, менеджер по тестированию, менеджер аналитической группы и некоторые другие сотрудники.
Соглашение о регулярной каденции обеспечило предсказуемость: все участники заранее планировали выделить час времени по понедельникам, так что в основном посещаемость была высокой.
Еженедельные совещания – хороший вариант для установления каденции расстановки приоритетов. Они позволяют часто общаться с руководителями бизнес-подразделений. Благодаря взаимодействию создаются доверительные отношения. В кооперативной игре по разработке программного обеспечения такие совещания дают возможность участникам передвигать фишки раз в неделю. Еженедельные совещания востребованы благодаря простоте вопроса, на который надо ответить, и уверенности, что все закончится в течение часа. Когда сотрудники бизнес-подразделений тратят время не на развитие бизнеса, им нужны гарантии, что от этого будет польза.
Многие аспекты канбана способствуют тому, что еженедельная встреча по расстановке приоритетов становится приятной: это опыт совместной деятельности, работа и рабочий процесс прозрачны, о прогрессе можно отчитываться еженедельно, все чувствуют причастность к чему-то важному и ценному. Некоторые вице-президенты Corbis в итоге убедились, что деятельность ГБР очень важна. Они почувствовали еще больше уважения к IT-отделу и научились сотрудничать с коллегами из других подразделений, что было нехарактерно для Corbis.
Эффективность расстановки приоритетов
Еженедельные координационные встречи могут и не подойти для вашей организации. Не исключено, что ваши координационные сложности менее или более серьезны, чем в Corbis. Например, некоторые команды и так работают в одном помещении, поэтому в дополнительных встречах нет нужды и координация приоритетов сводится к обсуждению через стол. А в других командах могут объединяться сотрудники из разных часовых поясов, рассеянные по континентам, так что еженедельные встречи непросто внести в расписание. Возможно, вопрос, на который нужно найти ответ, будет сложнее, чем в Corbis, так что встречи продлятся дольше. Трудно также представить ситуацию, в которой за общие ресурсы конкурирует более шести групп, но и такое случается. Чем больше групп вовлечено в процесс, тем дольше длятся встречи. А чем они длиннее, тем реже нужно их проводить.
Стоит отдать предпочтение более частой расстановке приоритетов. Это позволяет иметь небольшую входящую очередь и, следовательно, тратить меньше времени впустую. Сокращается число незавершенных заданий, а вслед за ним и сроки выполнения. Более частые встречи по расстановке приоритетов дают возможность участникам регулярно трудиться вместе. Опыт совместной работы порождает доверие и повышает корпоративную культуру. Постарайтесь найти наименее громоздкую и наиболее эффективную схему координации и проводить совещания по расстановке приоритетов согласно необходимости.
Операционные расходы на расстановку приоритетов
Чтобы обеспечить эффективность утренних совещаний, Дайана Коломиец в четверг или в пятницу направляла всем участникам электронные письма с информацией о том, сколько свободных мест в очереди ожидается в понедельник. Она просила их просмотреть бэклоги и выдвинуть кандидатов на эти освободившиеся места. Такая «домашняя работа» часто помогала подготовить аргументы в защиту своих задач. Работать с документами, обосновывающими выбор, мы начинали на понедельничном совещании. Чтобы поддержать свое предложение, кто-то готовил бизнес-кейс, а кто-то – презентацию. Другие начинали вербовать сторонников, которые бы выступили за их задачи. Вполне возможно, что одни члены совета по приоритетам приглашали других на обед, где договаривались о взаимной поддержке на предстоящем совещании. Появились закулисные переговоры: один участник соглашался поддержать предложение другого на этой неделе в обмен на то, что тот пролоббирует его интересы на следующей. Новые правила игры, в которой несколько организаций соперничали за общие ресурсы ГБР, привели к совершенно новому уровню сотрудничества.
Иногда представителей бизнеса беспокоило то, что запрос требовал слишком больших капиталовложений при внедрении, особенно в сравнении со своей ценностью, так что они просили команду аналитиков произвести оценку. Впоследствии сформулировали правила о классах сервиса: они помогали определить, стоит ли затевать оценку той или иной задачи. Подробнее об этом – в главе 11.
Все, включая оценку, подготовку бизнес-плана и выбор кандидата из бэклога, служит подготовительным этапом к расстановке приоритетов. С экономической точки зрения это операционные расходы на расстановку приоритетов. Поэтому желательно, чтобы они были минимизированы. Если операционные расходы начнут превышать разумные пределы, то вне зависимости от размера координационных расходов команда вряд ли захочет проводить регулярные совещания. Тщательно избегая детальных оценок при любой возможности, вы уменьшаете операционные издержки, что позволяет проводить совещания по приоритетам значительно чаще.
Увеличение эффективности для сокращения каденции расстановки приоритетов
В большинстве случаев команда менеджеров должна знать объем операционных и координационных расходов, понесенных всеми участниками, а не только разработчиками процесса расстановки приоритетов и выбора новых задач для входящей очереди на разработку и поставку.
Во многих agile-организациях для расстановки приоритетов используется прием под названием «покерное планирование», который применяет технику «мудрость толпы»: каждый член команды голосует карточкой c оценкой задачи. Подсчитывается среднее всех голосов, иногда ищут консенсус с теми, чье мнение особенно резко отличается от общего, затем проходит новый тур голосования – и так до тех пор, пока все члены команды не придут к единому мнению. На карточках часто используется нелинейная порядковая шкала, например ряд Фибоначчи, чтобы сделать более очевидной идею оценки.
Некоторые считают этот метод планирования (представляющий собой к тому же форму корпоративной игры) крайне эффективным, поскольку он позволяет быстро получить довольно точную оценку. Есть случаи, порой анекдотичные, опровергающие это, хотя существуют и примеры, доказывающие, что групповое мышление работает. Например, я слышал отчет команды (речь идет об одном стартапе в Сан-Франциско), оценка которой постоянно оказывалась ниже фактической, несмотря на проведение столь прозрачной корпоративной игры, как покерное планирование. От руководителей известного веб-сервиса по бронированию отелей и билетов я знаю, что их команды постоянно переоценивали задачи, хотя тоже использовали покерное планирование. Верить или не верить в эффективность планирующих игр – вопрос, который заслуживает более серьезного рассмотрения.
Планирующие игры с вовлечением всей команды позволяют быстро получить оценку отдельной задачи – например пользовательской истории. Но это упражнение требует участия всей команды, а значит, связано с существенными координационными издержками. Оно эффективно для небольших команд, сосредоточенных на работе над единственным продуктом. Однако если экстраполировать этот метод на такую организацию, как Corbis, где 55 человек, многие из которых – узкие специалисты в какой-то одной отрасли, сфере, системе или технологии, обслуживают 27 IT-систем, то почти всем им придется прервать работу, чтобы провести качественную оценку и добиться проявления «мудрости толпы». Операционные расходы на планирование и оценку в этом случае будут действительно невелики, но координационные издержки окажутся огромными.
Именно из-за координационных расходов такие agile-методы планирования эффективны только для небольших команд, сосредоточенных на единственной системе или линейке продуктов.
Отказавшись от проведения оценки для большинства классов обслуживания, вы снижаете и операционные, и координационные издержки на расстановку приоритетов. Это позволяет проводить совещания по приоритетам гораздо чаще, поскольку они остаются эффективными. Поэтому канбан-команды могут осуществлять расстановку приоритетов по запросу или по ситуации.
Расстановка приоритетов по мере необходимости или по запросу
Как уже говорилось в главе 4, в 2004 году Драгош Думитриу внедрил канбан-систему в своей команде инженерного обеспечения XIT в Microsoft. Соседями сверху по цепочке были четыре менеджера продукта, представлявшие несколько подразделений. Они собирали и расставляли в приоритетном порядке запросы на изменения примерно для 80 IT-систем, поддерживаемых XIT.
Когда мы с Драгошем разрабатывали канбан-систему для внедрения в XIT, мы спроектировали входящую очередь так, чтобы в нее помещалась по крайней мере неделя работы. Хотя все четыре бизнес-представителя и Драгош работали в Редмонде, в кампусе Microsoft, встречи по расстановке приоритетов проводились по телефону. Дело в том, что кампус Microsoft огромен, и номера заданий перевалили за сотню, хотя на самом деле зданий всего около сорока. Площадь кампуса – несколько квадратных километров, и между зданиями перемещаются на микроавтобусах или на Toyota Prius. Поэтому многие предпочитают проводить координационные совещания при помощи телефонных конференций, а не лично. Это отрицательно сказывается на уровне доверия и социального капитала среди сотрудников, но положительно – на эффективности.
Итак, Драгош организовал еженедельные телефонные совещания по расстановке приоритетов среди новых запросов на изменения в бэклоге. Четыре менеджера продукта представляли подразделения, которые спонсировали работу команды Драгоша. Основываясь на объеме поддержки, можно было предположить, как часто представитель того или иного подразделения сможет добавлять свою задачу в очередь. Так, менеджер продукта, который поставлял 60 % финансирования, имел право добавить в очередь свою задачу в трех случаях из пяти. Дискуссии между остальными также разрешались на основании сравнительного объема финансирования. Менеджер продукта, финансировавший работу команды меньше всех, мог добавить нужную ему задачу лишь в одном случае из одиннадцати. Таким образом, возник взвешенный циклический алгоритм выбора.
Итак, правила корпоративной игры, по методу которой осуществлялась расстановка приоритетов в XIT, были простыми. Каждую неделю менеджеры продукта заполняли освободившиеся места во входящей очереди – обычно их было три. Каждый из них получал право выбора в соответствии с алгоритмом. Время выполнения в соответствии с соглашением об уровне обслуживания составляло 25 дней. Поэтому, получая возможность выбрать запрос изменения для дальнейшей разработки, они должны были спросить себя: «Какие из элементов своего бэклога я больше всего хотел бы видеть реализованными через 25 дней?» Установился простой и четкий порядок, в котором они получали право на выбор, – он зависел от уровня финансирования ими отдела.
Поскольку правила были действительно несложными, совещания заканчивались очень быстро. Вскоре стало ясно, что даже координационный конференц-звонок был не так уж необходим. Драгош сделал так, что база данных Microsoft Product Studio (предшественник Visual Studio Team System, Team Foundation Server) автоматически посылала ему электронное письмо при освобождении места в очереди. Он пересылал это письмо менеджерам продукта. Они быстро выясняли, чья сейчас очередь, и этот человек делал свой выбор. Обычно освободившееся место заполнялось в течение двух часов. Исключительно низкие координационные издержки наряду с небольшими операционными издержками, связанными с решением не производить оценку запросов изменений, а также довольно высокая зрелость рабочей команды позволили Microsoft XIT отказаться от регулярного проведения совещаний по расстановке приоритетов.
Стоит заметить, что редмондский офис Microsoft имел примерно третий уровень зрелости, а поставщиком для разработки и тестирования XIT была команда пятого уровня зрелости, расположенная в Хайдарабаде. Таким образом, эта команда могла пользоваться преимуществами как низких координационных и операционных расходов, так и исключительно высокого уровня организационной зрелости. Вместе эти факторы означали, что расстановка приоритетов по запросу была для этой команды более эффективной.
Выбирайте расстановку приоритетов по запросу или по ситуации, если ваша организация имеет достаточно высокий уровень зрелости, а операционные и координационные расходы на расстановку приоритетов сравнительно низкие. В противном случае лучше вернуться к регулярным запланированным совещаниям и установить каденцию выбора задач, поступающих во входящую очередь.
Выводы
• Каденция расстановки приоритетов – это заранее оговоренный интервал между регулярными совещаниями по расстановке приоритетов в отношении новых заданий, поступающих во входящую очередь на разработку.
• Канбан устраняет потенциальные проблемы в координации планирования итераций, возможные при agile-методах, поскольку отделяет каденцию по расстановке приоритетов от времени выполнения разработки и поставки.
• Расстановка приоритетов среди новых запросов, таких как пользовательские истории, требует координации многих людей, выполняющих различные функции. Все расходы на такую координацию можно подсчитать.
• Проведение оценки, позволяющей облегчить расстановку приоритетов, влечет за собой операционные расходы – как времени, так и денег. Эти расходы могут быть определены и записаны.
• Правила, связанные с расстановкой приоритетов и информацией для принятия решений, в Канбане применительно к разработке ПО представляют собой правила корпоративной игры.
• Игры для планирования, использующиеся в agile-методах, нельзя подвергнуть безболезненному масштабированию, и они могут повлечь за собой существенные координационные расходы для крупных команд, работающих более чем с одной линейкой продуктов.
• Каденцию расстановки приоритетов можно установить, предложив всем заинтересованным лицам встречаться настолько часто, насколько потребуется с учетом соответствующих операционных и координационных расходов.
• Можно увеличить эффективность расстановки приоритетов и ее каденцию, сосредоточившись на снижении операционных и координационных расходов.
• Частые совещания по расстановке приоритетов укрепляют доверие.
• Регулярные встречи по расстановке приоритетов снижают координационные расходы и особенно полезны в организациях с низкой степенью зрелости.
• Расстановка приоритетов по мере необходимости или по запросу подходит для очень зрелых организаций с высоким уровнем доверия и низкими расходами на расстановку приоритетов.
Глава 10 Задание WIP-лимитов
Как уже говорилось в главе 2, одна из пяти ключевых практик Канбан-метода состоит в ограничении числа незавершенных задач (WIP). Поэтому не будет преувеличением сказать, что при переходе на Канбан одно из самых важных решений – выбор лимитов для незавершенных задач в ходе рабочего процесса.
В главе 15 предлагается обсудить WIP-лимиты с заинтересованными лицами выше и ниже по цепочке, а также со старшим руководством. Конечно, лимиты можно задать и в одностороннем порядке, однако обретение консенсуса и получение обязательств от внешних заинтересованных лиц имеет свои преимущества. Когда команда и рабочий процесс находятся под угрозой, вы можете вернуться к консенсусу, достигнутому в соглашении по сотрудничеству. Можно также перевести дискуссию в область переопределения процесса, а не делать исключения, закрывая глаза на нарушения, не пренебрегать правилами или как-то иначе обманывать уже спроектированную и внедренную систему. Достижение консенсуса – это способ поддерживать дисциплину в области WIP-лимитов, не отказываться от лимита и не игнорировать его.
Лимиты на рабочие задания
Драгош Думитриу в команде XIT в Microsoft решил, что разработчики и тестировщики не должны работать одновременно более чем над одним заданием. Никакой многозадачности. Объявление было сделано в одностороннем порядке, но, к счастью, не привело к проблемам с другими заинтересованными лицами. Это соответствовало текущим методам работы и индивидуальному процессу разработки ПО (PSP), принятому в то время в команде. Организация обладала достаточной степенью зрелости, чтобы поддерживать дисциплину и следовать заранее установленным процедурам. Как уже упоминалось, осенью 2004 года в команде было три разработчика и три тестировщика. Таким образом, WIP-лимит на разработку и тестирование равнялся трем.
В 2006 году в Corbis, выступив с инициативой в области инженерного обеспечения, мы приняли такое же решение: аналитики, разработчики и тестировщики должны работать над одной задачей одновременно. Для новых крупных проектов мы принимали другие решения. Работа над ними предусматривала увеличение численности команды. Нередко над одной задачей трудились небольшие команды из двух-трех человек. Поскольку эти задачи могли блокироваться или откладываться, мы решили использовать переключение между задачами и дополнительную параллельность в работе, поэтому WIP-лимит был задан с таким расчетом, чтобы над единицей работали два-три человека, но допускалось некоторое перекрытие задач. Например, если у нас было десять человек и расчет «два человека на задачу», то WIP-лимит составил бы пять плюс еще немного, чтобы нивелировать возможный эффект от блокировки. В таких обстоятельствах подходящее значение лимита – 8 (5 + 3).
Некоторых авторов исследования и эмпирические наблюдения привели к мысли, что две задачи в работе на одного квалифицированного специалиста – это оптимальный вариант. Часто этот вывод приводят в качестве оправдания многозадачности. Однако я считаю, что эти наблюдения отражают только состояние в изучаемых организациях, где существует множество задержек и причин для откладывания работы. В исследованиях не отражена организационная зрелость компаний, к тому же они не соотносятся с данными внешних источников (варианты систематических погрешностей, о которых пойдет речь в главе 19). Таким образом, результат может отражать только изучаемые условия и не подходить для иных ситуаций. Тем не менее нужно быть готовым к тому, что решение брать не более одной задачи в работу на одного-двух сотрудников или на небольшую команду встретит сопротивление как слишком жесткий вариант. В таком случае разумно сделать WIP-лимит для одного-двух сотрудников или на команду. Порой приемлем и лимит в три задачи.
Никакой общей формулы успеха здесь не существует. Важно помнить, что значение WIP-лимита меняется на основе эмпирических данных. Вы можете выбрать значение и затем решить, насколько оно удачно. Если нет, увеличьте его или сократите.
Лимиты на очереди
Когда работа закончена и элемент дожидается, пока его вытянут на следующую стадию, говорят, что он находится в очереди. Какой должна быть эта очередь? В идеале как можно короче. WIP-лимит для очереди часто объединяется с предыдущим этапом работы.
Например, очереди «Разработка» и «Готово к разработке» объединены, как показано на рис. 10.1. Если установлены действительно жесткие правила по WIP-лимитам, например строго один элемент на одного-двух человек или на небольшую команду, то необходимо организовать очередь, чтобы поддерживать рабочие задания и амортизировать вариативность. Когда ваша канбан-система на практике страдает от политики «остановка-запуск», которая вынуждает сотрудников к простою из-за того, что на выполнение заданий требуется разное время, стоит подумать об увеличении размеров очереди. Однако если вы сделали выбор в пользу, например, двух задач на одного-двух человек или на команду, то буфер для амортизации вариативности уже организован, так что размер очереди часто будет равен нулю. Просто объедините столбец рабочих задач с очередью.
Рис. 10.1. Стена карточек, демонстрирующая различные типы очередей и буфер
Буфер для бутылочного горлышка
Бутылочное горлышко в рабочем потоке может потребовать буфера перед ним, как показано на рис. 10.1. Это типичный механизм амортизации бутылочных горлышек, о чем будет рассказано в главе 16. Важен масштаб буфера – желательно, чтобы он был как можно меньше. Буферы и очереди вносят в систему незавершенные задачи, что увеличивает время выполнения. Однако буферы и очереди делают рабочий поток более равномерным, что улучшает предсказуемость времени выполнения. Тем самым они увеличивают пропускную способность, и канбан-система может обработать больше задач. Буферы также сохраняют более равномерную занятость людей. Необходим баланс, который и помогают поддерживать буферы. Во многих случаях приходится стремиться к деловой гибкости и более короткому времени выполнения, а также повышению качества, связанному с меньшим количеством незавершенных задач. Однако в погоне за гибкостью или качеством не стоит жертвовать предсказуемостью. Если размеры очереди и буфера слишком малы, так что ваша система страдает от политики «остановка-запуск», вызванной вариативностью, то время выполнения окажется непредсказуемым, а вариативность – огромной. Выбирая WIP-лимит для буфера, нужно иметь в виду, что он должен быть достаточно большим, чтобы обеспечить равномерный ход работы по системе и исключить простой перед бутылочными горлышками. Подробнее о масштабах буфера и о том, как создать буферы для бутылочных горлышек с ограниченной пропускной способностью и задержкой доступа элементов, мы расскажем в главе 16.
Размер входящей очереди
Размер входящей очереди можно установить исходя из каденции расстановки приоритетов и пропускной способности, или темпа производства системы. Например, если команда выпускает в среднем пять законченных элементов в неделю (обычно – от четырех до семи в неделю) при установленной еженедельной каденции пополнения очереди, то наиболее вероятный размер очереди – семь. Впрочем, возможны эмпирические поправки. Если система в ходу уже на протяжении несколько месяцев и очередь за это время ни разу полностью не истощилась перед совещаниями по расстановке приоритетов, то, вероятно, ее размер слишком велик, нужно уменьшить ее на одну позицию и посмотреть на результаты. Повторяйте до тех пор, пока на одном из совещаний по приоритетам вы не предложите представителям отделов заполнить все места в очереди.
Если же совещания по расстановке приоритетов проводятся по понедельникам, а очередь исчерпалась уже к середине четверга, после чего некоторым сотрудникам было нечем себя занять, то, значит, она слишком мала. Увеличьте размер очереди на единицу и последите за результатами в течение нескольких недель.
Размеры очереди и буфера должны подвергаться поправкам на основании опыта. Поэтому не стоит слишком долго раздумывать над установлением WIP-лимита. Не задерживайте ход канбан-системы из-за того, что никак не можете договориться об идеальном WIP-лимите. Сделайте выбор! Лучше начать работу, не имея полной информации, чтобы затем на основании наблюдений внести поправки. Канбан – это эмпирический процесс.
Какой должна быть входящая очередь, если вы используете расстановку приоритетов по запросу? Как уже упоминалось в главе 4, входящая очередь команды XIT состояла из пяти элементов. Она создавалась в расчете на то, что будет достаточно велика для амортизации недельной пропускной способности, исходя из того предположения, что совещания по приоритетам будут еженедельными. Однако вскоре менеджеры продукта пришли к выводу, что совещания не очень нужны, а решения можно принимать по ситуации, как только освобождается место в очереди. Когда это случилось, мне следовало посоветовать Драгошу сократить входящую очередь с пяти позиций до одной. Я этого не сделал по неопытности. Система изменилась. Основания, на которых она выстраивалась, – тоже. Правила о размерах входящей очереди были основаны именно на прежней системе, поэтому их нужно было пересмотреть. Если бы мы так и поступили, то сокращение времени выполнения оказалось бы еще более впечатляющим.
Когда в XIT переключились на расстановку приоритетов по запросу, пополнение очереди обычно занимало около двух часов на один элемент. Можно с уверенностью сказать, что на пополнение очереди никогда не уходило более четырех часов. Однако разработчики находились далеко от менеджеров продукта. Люди, принимавшие решения по приоритетам, сидели в Редмонде, а разработчики – в Хайдарабаде. Все они официально трудились по восемь часов в день, причем время работы у них чаще всего не совпадало. Поэтому нередкими были ситуации, когда сотрудники, жившие в Индии, утром приходили на работу, завершали задачи и ждали пополнения очереди, в то время как у менеджеров продукта в США продолжался сладкий ночной сон. Следовательно, нужно было учесть возможность 16-часового ожидания пополнения элемента очереди в критических обстоятельствах. Помните, что в этом рабочем процессе бутылочным горлышком были разработчики, и, чтобы максимально увеличить пропускную способность, мы совершенно не хотели их простоя. Поэтому нужно иметь запас прочности: 16 часов – это консервативное решение, учитывая, что в среднем решение по пополнению очереди занимает всего два часа. Итак, какова будет пропускная способность за эти 16 часов? На пике производительности команда реализовывала 56 элементов за квартал, то есть менее пяти в неделю. Так что маловероятно, чтобы за 16 часов они закончили бы хоть один элемент. Таким образом, очередь из одного элемента была вполне приемлемой. А вот отсутствие очереди неприемлемо. При этом сохранялась вероятность, что команда будет простаивать, когда они закончат работу за те 16 часов, пока менеджеры продукта будут недоступны для пополнения очереди.
Неограниченные разделы рабочего потока
В вытягивающей системе, связанной с теорией ограничений и известной как «барабан-буфер-канат», WIP-лимит всех рабочих станций после бутылочных горлышек не установлен. Это основано на предположении, что пропускная способность этих рабочих узлов выше, чем у бутылочных горлышек, так что они обладают резервной мощностью, что приводит к простою. Поэтому устанавливать WIP-лимит нет необходимости. Это отражено на рис. 10.2а, который основывается на метафоре, использованной в книге Элияху Голдратта и Джеффа Кокса «Цель: процесс непрерывного улучшения»[7] и показывает скаутский патруль, идущий змейкой. Между ведущим и самым медленным скаутом (четвертый в змейке) натянут канат. Самый медленный в змейке – это и есть бутылочное горлышко в пропускной способности (то есть в темпе хода скаутов). Необходим только один канат, поскольку скауты, идущие вслед за самым медленным из них, никогда от него не отстают, так как могут идти быстрее, чем четвертый в змейке, который снижает темп перемещения всего патруля.
Рис. 10.2. Человечки, иллюстрирующие четыре различных варианта WIP-лимитов в разных вытягивающих системах
В канбан-системе WIP-лимиты предусмотрены для большинства или даже всех рабочих узлов потока. Это является потенциальным преимуществом, поскольку препятствия, возникающие в связи с непредсказуемой вариативностью, могут сделать бутылочным горлышком любой предыдущий этап. Установление WIP-лимита вместе с канбан-системой быстро остановит очередь, так что система не подвергнется засорению и перегрузке. Когда препятствие устранено, система без помех перезапустится. Установление WIP-лимитов по канбану показано на рис. 10.2 г, где канаты связывают цепочку скаутов в соответствии с принципами канбана. В этом случае каждый человечек связан со следующим в цепочке. Чтобы контролировать темп перемещения всего скаутского патруля, требуется пять канатов.
В некоторых случаях в канбан-системе приемлемо отсутствие лимита на следующие этапы процесса. В примере Microsoft XIT было высказано предположение, что пользовательская база, доступная для проведения приемочного тестирования, практически бесконечна и доступна сразу же, поэтому для приемочного тестирования не нужны WIP-лимиты. В Corbis ограничения не касались очереди на подготовку к релизу. Это основывалось на предположении, что очередь на подготовку к релизу никогда не превысит пропускную способность при установленной двухнедельной каденции релиза. А если все же скапливался излишний материал для подготовки релиза, это повышало его сложность, так что координационные и операционные издержки на релиз слишком возрастали и пришлось бы установить WIP-лимиты и на этом этапе. Однако в Corbis такого не случалось, поэтому ограничения для данной фазы не устанавливались.
Не подвергайте организацию стрессу
Излишне жесткие WIP-лимиты могут подвергнуть вашу организацию сильному стрессу. У компаний с низкой степенью зрелости и невысокой производительностью изначально проблем будет больше. Для таких организаций внедрение канбан-системы может протекать болезненно при наличии слишком жестких WIP-лимитов. Если выявляется большое количество препятствий, отмеченных на стене розовыми карточками, то слишком жесткие WIP-лимиты могут привести к полной остановке работы, так что жертвами простоя окажутся все сотрудники. Конечно, простой можно использовать для концентрации внимания и накопления сил с целью решить проблемы и устранить препятствия, но он может слишком дорого обойтись недостаточно зрелой организации. Руководители начнут испытывать раздражение при виде праздношатающихся людей, которые продолжают получать зарплату.
Внося изменения, необходимо помнить о так называемом эффекте J-кривой. Обычно при каждом изменении WIP-лимитов на графике производительности появляется фигура, похожая на букву J: когда изменения незначительны, размер J невелик. Если установить слишком жесткие WIP-лимиты, то эффект J-кривой окажется слишком глубоким и длительным, что способно привести к нежелательным последствиям. Канбан обнажает все проблемы организации, но в итоге метод могут обвинить в том, что из-за него все стало только хуже. Канбан начнут воспринимать как часть проблемы, а не как ее решение. Поэтому действуйте осторожно. Если организация обладает большей мощностью и зрелостью и реже страдает от неожиданных проблем (вариативностей систематической погрешности), то можно проводить более агрессивную политику WIP-лимитов. Если организация менее слаженна, то изначально стоит ввести более свободные ограничения, с тем чтобы снизить WIP-лимиты позже.
Не устанавливать WIP-лимит – это ошибка
Хотя я советую быть сдержаннее при установлении изначальных WIP-лимитов, вовсе не устанавливать их – это ошибка.
Некоторые ранние последователи Канбана, например Yahoo! решили отказаться от WIP-лимитов, поскольку считали, что их команды недостаточно слаженны, чтобы справиться с негативными ощущениями, которые лимиты вызовут в компании. Предполагалось, что организации превратятся в более зрелые благодаря средствам визуального контроля Канбана, а WIP-лимиты можно будет внедрить позже. Однако это оказалось непросто, и несколько команд отказались от Канбана, а остальные захлестнула волна реорганизаций и отмен проектов, так что дальнейший сбор данных был затруднен. В Corbis некоторые команды на крупных проектах продолжали работать в рамках Канбана с очень свободными WIP-лимитами над высокоуровневой функциональностью. Результаты вызвали смешанные впечатления.
Я убедился, что напряжение, которое создается при наложении WIP-лимитов на цепочку создания ценности, – это позитивный фактор. Позитивное напряжение вызывает обсуждение организационных проблем и дисфункций. Дисфункции создают помехи рабочему потоку, в результате время выполнения и качество окажутся неоптимальными. Дискуссии и совместная работа, вызванные позитивным напряжением, созданным WIP-лимитом, идут организации на пользу. Это механизм, который порождает культуру непрерывного совершенствования. Без WIP-лимитов улучшение процессов идет очень медленно. Команды, которые сразу же установили WIP-лимиты, сообщают об ускорении роста мощности и организационной зрелости и увеличении коммерческих показателей благодаря регулярным частым релизам высококачественного программного обеспечения. Напротив, команды, пренебрегающие введением WIP-лимитов, обычно сталкиваются с проблемами и демонстрируют лишь незначительные улучшения.
Распределение мощности
Установив WIP-лимиты для всего рабочего потока в системе, можно задуматься о распределении мощности по типам единиц работы или классам обслуживания.
На рис. 10.3 изображена стена карточек из главы 6 с WIP-лимитами по столбцам – всего 20 карточек. Мощность распределена по типам работы: 60 % идет на запросы изменений, 10 % – на элементы поддержки и 30 % – на производственные текстовые изменения.
Рис. 10.3. Стена карточек с «плавательными дорожками» для каждого типа единиц работы с указанными для каждой дорожки WIP-лимитами
Это соответствует таким значениям WIP-лимитов для каждой «плавательной дорожки»: 12 для запросов изменений, 2 для элементов поддержки и 6 для производственных текстовых изменений.
Распределение мощности позволяет гарантировать обслуживание для каждого типа работы, введенного в канбан-систему, и должно производиться в соответствии с примерным спросом для каждого типа работы. Таким образом, чтобы разумно распределить WIP-лимиты для каждого типа работы по «плавательным дорожкам», важно провести некоторый анализ предъявляемых требований.
Выводы
• WIP-лимиты должны быть согласованы с заинтересованными лицами из других подразделений и высшего руководства на основе общего консенсуса.
• Возможно и одностороннее установление WIP-лимитов, однако позднее, когда система окажется под стрессом, эту позицию будет трудно защищать.
• WIP-лимиты для рабочих задач должны устанавливаться как среднее количество элементов на одного-двух человек или на небольшую команду, работающую над единым проектом.
• Обычно лимит задается из расчета 1–3 единицы на 1–2 человек или на команду.
• Лимиты для очереди должны быть достаточно небольшими – обычно такими, чтобы амортизировать естественную (случайную) вариативность в размере элементов и длительности задач.
• Бутылочные горлышки нужно снабдить буфером.
• Размер буфера должен быть минимальным, но при этом достаточным для обеспечения оптимальной производительности в бутылочном горлышке и устойчивого распределения рабочего потока по системе.
• Все WIP-лимиты можно изменять эмпирически.
• Канбан – это эмпирический процесс.
• Не нужно тратить слишком много времени, пытаясь определить идеальный WIP-лимит; просто возьмите приблизительное значение и работайте. При необходимости внесете изменения позже.
• Можно отказаться от лимитов для более поздних этапов работы.
• Нужно убедиться, что отказ от лимитов на некоторых этапах рабочего процесса не приводит к образованию бутылочных горлышек либо появлению чрезмерных операционных или координационных расходов при релизах.
• После установления WIP-лимитов распределяйте мощность по типам единиц работы.
• Для каждого типа единиц работы часто используются «плавательные дорожки», для каждой из которых задается свой WIP-лимит.
• Распределение мощности требует проведения сравнительного анализа спроса на разные типы работы, вводимые в канбан-систему.
Глава 11 Формирование соглашений об уровне обслуживания
Все мы знакомы с идеей разграничения классов обслуживания. Любой, кто регистрировался на рейс в аэропорту, знает: пассажиры, больше заплатившие за билет или пользующиеся преимуществами программы лояльности покупателей, могут воспользоваться экспресс-очередью, что существенно сэкономит их время. Иногда эти привилегии распространяются и на очереди на досмотр в аэропорту, и на пользование специальным бизнес-залом, и на экспресс-посадку в самолет. Клиенты, которые больше платят или регулярно тратят деньги на услуги компании, имеют более высокий класс обслуживания.
Эта идея известна в сфере программного обеспечения и IT-систем, в частности, при исправлении ошибок, особенно возникших в продуктивной среде. Мы разделяем ошибки по степени серьезности (воздействия) и приоритету (срочности). Очень серьезные и высокоприоритетные ошибки устраняются немедленно. Они получают другой, более высокий класс обслуживания по сравнению с остальными задачами. Чтобы устранить серьезную ошибку в продукте, мы откладываем в сторону другую работу, привлекаем максимальное количество людей и часто составляем отдельные планы для срочной отладки, патча или релиза, разрешающих проблему.
Эту идею можно применить и в более общих случаях, что сулит преимущества как в вопросах деловой гибкости, так и при управлении рисками. Некоторые запросы требуется выполнить намного быстрее других, а иные имеют большую ценность по сравнению с прочими. Назначая разные классы обслуживания для различных типов работы, мы обеспечиваем клиентам высокий уровень гибкости и оптимизируем экономические выгоды для себя.
Классы обслуживания повышают удобство при классификации работы, чтобы обеспечить приемлемые уровни удовлетворенности покупателя по оптимальной с экономической точки зрения цене. Быстро определив для элемента класс обслуживания, мы устраняем необходимость проводить детальную оценку или анализ. Правила, связанные с классом обслуживания, влияют на то, как элементы втягиваются в систему, и определяют приоритет в системе. Классы обслуживания дают возможность применить к расстановке приоритетов и смене приоритетов задач, находящихся в работе, подход, основанный на самоорганизации, оптимизации ценности и рисков.
Типичные определения классов обслуживания
Классы обслуживания обычно определяются на основе ожидаемого экономического эффекта. Стикеры разного цвета, каталожные карточки или талоны назначаются для каждого класса и четко идентифицируют класс обслуживания для любого запроса, как показано на рис. 11.1. Отдельные «плавательные дорожки» на стене карточек определяют соотнесенность с классом обслуживания.
Рис. 11.1. Стена карточек с цветными карточками, соответствующими классам обслуживания
Каждый класс обслуживания имеет собственный набор правил, который влияет на то, в каком порядке обрабатываются элементы при прохождении через канбан-систему. Класс обслуживания явно соответствует обещанию, данному заказчику. Ниже приведен краткий набор определений классов обслуживания. Хотя этот набор не является точным воспроизведением тех, что используются в конкретных реализациях Канбана, это довольно точное обобщение классов обслуживания в данной сфере.
В этом наборе примеров предлагается четыре класса обслуживания, а в целом их количество не должно превышать шесть. Если классов больше, то управлять ими сложно. Количество классов обслуживания должно быть небольшим, чтобы все заинтересованные лица – члены команды и внешние игроки – могли их запомнить, но достаточным для обеспечения гибкости при обработке запросов пользователей.
Ускоренный класс обслуживания
Ускоренный класс обслуживания (другое название – «серебряная пуля») хорошо известен в области производства. Типичен такой сценарий: продажники пытаются выполнить квартальный план, а у клиента есть бюджет, который требуется потратить к концу финансового года. Клиент долго откладывает решение о приобретении, но наконец делает выбор как раз к концу текущего финансового года. Заказ размещается, но возможен только в случае поставки до дедлайна. Производитель соглашается с ценой и количеством и принимает заказ, который должен быть выполнен, доставлен и представлен к оплате ранее последнего дня квартала. Такой заказ обычно поступает в работу через офис вице-президента по региональным продажам и снабжается запросом на ускорение работы в связи с жесткими временными рамками и своей ценностью.
Способность ускорять обслуживание дает поставщику возможность в трудных обстоятельствах удовлетворить потребности покупателя. Однако ускорение работы над заказами оказывает негативное влияние на цепочки поставок и системы распределения. В промышленности и организации управления производством известно, что ускорение работы увеличивает как объем незавершенного производства, так и время выполнения других, неускоренных заказов. Бизнесу предстоит сделать выбор, стоит ли ценность конкретной продажи альтернативных издержек, связанных с откладыванием других заказов, и дополнительных издержек на незавершенное производство. Если компанией хорошо управляют, то выгоды ускорения превзойдут издержки, вызванные более длительным временем выполнения (и влекущие потенциальные потери заказа), и затраты на выросший объем незавершенного производства.
Промышленные компании часто устанавливают правила, ограничивающие число ускоренных запросов. Нередко также назначают фиксированное число так называемых серебряных пуль, которые региональный вице-президент по продажам может одобрить за определенный период. Таким образом, термин «серебряная пуля» стал служить синонимом ускорения производства или распределения.
К сожалению, ситуацию усложняет то, что термин «серебряная пуля» уже использовался в области разработки ПО. Фред Брукс называл так конкретное изменение в технологии или процессе, которое создает существенное (в десять и более раз) повышение производительности программиста. Поэтому я рекомендую название «ускоренный класс обслуживания». Правда, компании, которые занимаются промышленным производством, или организации, где руководство знакомо с промышленностью, явно предпочитают термин «серебряная пуля». В этом нет ничего плохого, если представители индустрии понимают разницу в значениях.
Класс обслуживания «фиксированная дата поставки»
В середине февраля 2007 года в мой офис пришел разработчик и спросил, знаю ли я о проблеме с сервисной платформой, которую мы использовали для работы с кредитными карточками. Я ответил «нет», и он объяснил ситуацию. Судя по всему, поставщик обнаружил, что поддерживать кодовую базу слишком сложно, поскольку разработчики добавляли все новые функции к платформе – это обычное дело. Чтобы удовлетворить спрос на новые функции в 2006 году, они полностью заменили платформу новой системой, имевшей совершенно другой интерфейс прикладного программирования (API).
Об этом проинформировали всех клиентов и за 15 месяцев предупредили, что прежняя система будет выключена после 31 марта 2007 года. Иными словами, если не обновить системы для использования новой платформы, то 1 апреля 2007 года мы будем отрезаны от интернет-торговли. Это влекло за собой существенные неудобства для бизнеса, который большую часть выручки получал от продаж в интернете, не говоря уже об ощущениях владельца фирмы. У нас оставалось всего шесть недель, чтобы внести необходимые изменения и выпустить новый код. Карточка на эту работу поступила в нашу канбан-систему. Дополнительная информация на карточке должна была привлечь внимание к затратам и ущербу от опоздания, а также позволить команде самостоятельно ускорить обработку элемента и обеспечить своевременное выполнение задания.
С таким запросом мы сталкивались не впервые. До этого поступил запрос на интеграцию IT-систем от приобретенной нами компании. Назначенная «фиксированная дата» была выработана исходя из обоснования приобретения, где указывалась существенная экономия с 1 февраля того же года.
Судя по всему, возникает своего рода тезис, или шаблон: некоторые запросы связаны с крупными контрактными обязательствами, другие – с нормативными требованиями (обычно исходящими от федерального правительства), а еще часть – со стратегическими инициативами, например с приобретением другого бизнеса.
Подобные запросы были связаны с серьезными затратами на отсрочку, прямыми или косвенными, которые обычно укладывались в одну из двух категорий: 1) наступал день, когда компания подвергалась штрафу (или иному финансовому наказанию) – прямая, конкретная потеря денег из собственного кармана, связанная с нормативными обязательствами или сроками, прописанными в контракте; 2) требовалось прекратить какую-то деятельность, например продажу определенного вида товара или работу в какой-либо сфере юрисдикции, вплоть до выполнения требований. Второй тип расходов относится к косвенным – это расходы по упущенной возможности, потенциально утраченной выручке за период отсрочки. Оба типа отражены на рис. 11.2.
Рис. 11.2. Два вида расходов из-за отсрочки для класса обслуживания «фиксированная дата поставки»
Организации, связанные с календарными сезонами, например школы и колледжи, обычно жестко ограничены в сроках. Если вы работаете в таком секторе, как образование, то ваши клиенты могут либо заказывать оборудование в фиксированное время, либо вообще не делать заказа: когда вы не укладываетесь в их «окно», сделка срывается. Все, что имеет «окно запуска», задаваемое культурными традициями или условиями поставки, обладает бoльшими расходами из-за отсрочки, поэтому подобные задания нужно расценивать как класс обслуживания «фиксированная дата поставки», если будущий дедлайн согласуется с временем выполнения начиная с текущего момента.
Стандартный класс
Большинство элементов, обладающих определенной степенью срочности, нужно расценивать как элементы стандартного класса обслуживания. Правила и соглашение об уровне обслуживания для единицы стандартного класса могут меняться в зависимости от типа единицы работы. Одна распространенная схема дизайна канбан-системы разграничивает единицы работы по размеру на мелкие, средние и крупные. Можно предложить различные сроки обслуживания для элементов стандартного класса разного размера.
Например, мелкие элементы обычно обрабатываются в течение четырех дней, средние – за месяц, а большие – за три. Элементы стандартного класса, как правило, имеют осязаемые издержки из-за отсрочки, которые можно подсчитать (хотя не всегда в валютном эквиваленте). Издержки из-за отсрочки нередко возникают быстро – во время релиза запроса. Чаще всего они непосредственные: если бы у нас была эта функция сегодня, прибыль мы получили бы уже завтра!
Нематериальный класс
Возможно, имеет смысл ввести четвертый, самый низкий класс обслуживания. Я долго пытался подобрать подходящее название для него и остановился на слове «нематериальный». Конечно, не идеальный вариант, поэтому, возможно, в следующем издании этой книги термин изменится. Элементы нематериального класса могут быть важными и ценными, но материальных издержек из-за отсрочки, связанной с ними, в ближайшем будущем не предвидится. Итак, издержек из-за отсрочки в течение срока, за который можно реализовать элемент, не ожидается. Запросы, которые относятся к этому классу, часто имеют потенциально фиксированную дату сдачи, установленную, однако, в далеком будущем: это, например, замена платформы.
В 2005 году Microsoft запустила SQL Server 2005 – последнюю версию своего сервера баз данных RDBMS. Версия 2005 года сменила версию 2000 года, которая отслужила свое. От Microsoft как от ведущего игрока индустрии требовалось поддерживать продукты на протяжении десяти лет после их ввода в эксплуатацию. Таким образом, поддержка SQL Server 2000 должна была продолжиться до 2010 года. Это давало клиентам пятилетнюю отсрочку на замену кода, несовместимого с новыми версиями платформы, – до 2005-го или даже 2010 года. Следовательно, в 2005-м или 2006 году замена кода базы данных – хранимые процедуры, код хранения объектов – не первоочередная задача. Издержек из-за отсрочки в эти годы не произойдет. Но со временем, пока код не изменяется, возможные издержки нарастают. Становится все сложнее работать с другими продуктами, поскольку их обновленные версии требуют обязательной совместимости с SQL Server 2005. Все больше факторов побуждают перейти на новую платформу. К 2009 году вопрос стал неотложным, поскольку вскоре Microsoft собиралась прекратить поддержку предыдущего продукта, и если не произвести обновление, то бизнес останется со старыми машинами и не поддерживаемыми больше операционными системами и соответствующей инфраструктурой. Если это слишком большой риск, то код необходимо обновить. Проблема замены платформы встречается довольно часто: команды разработки ПО сталкиваются с ней постоянно. Всегда есть желание сразу начать работу и вовремя ее завершить, но необходимость произвести обновления обычно отступает перед более срочными или важными задачами. Иными словами, замена платформы, которая обладает сравнительно низкими непосредственными издержками из-за отсрочки, отходит на второй план из-за заданий, отсрочка по которым ведет к более крупным и непосредственным издержкам.
Можно предложить класс обслуживания, который позволит быстро начинать такую работу, или ресурсы, чтобы убедиться, что задание завершено. Но гарантий по времени может и не быть. К тому же это как раз такая работа, которую легко отложить в сторону, если появляются более срочные задачи. Чтобы иметь резервы для обработки ускоренного запроса, должна быть работа с низкой стоимостью отсрочки, которая откладывается в сторону при поступлении ускоренного запроса. И этот резерв как раз обеспечивается элементами нематериального класса.
Правила для классов обслуживания
Визуализация, которую мы делаем на канбан-доске, должна давать возможность сразу определить класс обслуживания для задачи. Как уже говорилось, чаще всего используются либо карточки разных цветов, либо разные «плавательные дорожки» на стене карточек. Некоторые команды добавляют такие «украшения», как звездочки, прикрепленные к карточке. «Плавательная дорожка» для ускоренных запросов тоже встречается часто. Выбор визуализации классов обслуживания остается за вами. Цель – убедиться, что любой сотрудник в любой день может применить простые принципы расстановки приоритетов, связанных с классами обслуживания, чтобы принять качественное решение без надзора или вмешательства руководства.
Ниже приведены примеры правил расстановки приоритетов для четырех определенных ранее классов обслуживания. Разумеется, каждая реализация определения классов обслуживания уникальна и правила их использования будут отличаться от данных примеров. Представленные правила основаны на эмпирических свидетельствах и довольно точно отражают ситуации в реальных командах.
Правила для ускоренного класса обслуживания
• Для ускоренных запросов используются белые карточки.
• Разрешается обработка только одного ускоренного запроса за раз. То есть ускоренный класс обслуживания имеет WIP-лимит 1.
• Квалифицированные сотрудники должны немедленно вытягивать ускоренные запросы. Вся другая работа приостанавливается до окончания обработки ускоренного запроса.
• На любой стадии рабочего процесса разрешается превышение WIP-лимита с целью приема ускоренного запроса. Для ускоренного запроса мощность не оставляется в резерве.
• При необходимости планируется специальный (внеочередной) релиз, чтобы как можно быстрее реализовать ускоренный запрос.
Правила для класса обслуживания с фиксированной датой поставки
• Для элементов с фиксированной датой поставки используются фиолетовые карточки.
• Требуемый дедлайн записывается в правом нижнем углу карточки.
• Элементы с фиксированной датой поставки подвергаются анализу, может проводиться оценка масштаба и усилий для определения времени выполнения. Если элемент слишком большой, то он может быть разбит на менее крупные. Каждый менее крупный элемент после этого оценивается независимо, чтобы понять, соответствует ли он определению элемента с фиксированной датой поставки.
• Элементы с фиксированной датой поставки хранятся в бэклоге, пока не будут выбраны для поступления во входящую очередь в то самое время, когда они могут быть выполнены в срок, учитывая изначальную оценку.
• Элементы с фиксированной датой поставки вытягиваются раньше других, менее рискованных элементов. В нашем примере они вытягиваются раньше элементов стандартного или нематериального классов обслуживания.
• Элементы с фиксированной датой поставки должны соотноситься с WIP-лимитом.
• Элементы с фиксированной датой поставки поступают в очередь на релиз, когда они закончены и подготовлены к релизу. Они выпускаются в соответствии с календарем релизов непосредственно перед дедлайном.
• Если работа над элементом с фиксированной датой поставки задерживается и возможность успеть к желаемой дате оказывается под угрозой, то класс обслуживания может быть повышен до ускоренного.
Правила для стандартного класса обслуживания
• Для элементов стандартного класса обслуживания используются желтые карточки.
• Расстановка приоритетов среди элементов стандартного класса обслуживания производится по заранее оговоренному механизму – например, голосованием. Обычно они ставятся в очередь на основании издержек из-за отсрочек или ожидаемой ценности.
• Для элементов стандартного класса, вытянутых в систему, используется алгоритм FIFO (в порядке поступления). Обычно когда есть выбор, член команды вытягивает самый старый элемент стандартного класса, если отсутствуют элементы ускоренного класса или с фиксированной датой поставки.
• Элементы стандартного класса поступают в очередь на релиз, когда они закончены и подготовлены к релизу. Они выпускаются в ближайшем запланированном релизе.
• Оценка для определения количества усилий или времени выполнения не проводится.
• Элементы стандартного класса могут быть проанализированы по размеру и разделены на мелкие (несколько дней работы), средние (неделя или больше) и крупные (несколько месяцев). Крупные элементы можно разбивать на более мелкие, каждый из которых может ставиться в очередь и обрабатываться отдельно.
• Элементы стандартного класса обычно реализуются в течение x дней после выбора, выполнение в срок составляет m процентов.
Типичное соглашение об уровне обслуживания для стандартного класса может включать 30-дневное время выполнения с 80 %-ным выполнением в срок. Иными словами, за 30 дней должны быть выполнены четыре запроса из пяти.
Нематериальный класс обслуживания
• Для элементов нематериального класса обслуживания используются зеленые карточки.
• Расстановка приоритетов среди элементов стандартного класса обслуживания производится по заранее оговоренному механизму – например, голосованием. Они обычно поступают в очередь на основании оценки долгосрочного негативного воздействия или издержек из-за отсрочки.
• Элементы нематериального класса вытягиваются в систему по ситуации. Члены команды могут выбрать любой элемент нематериального класса независимо от даты его поступления, если элементы более высоких классов отсутствуют.
• Элементы нематериального класса поступают в очередь на релиз, когда они закончены и подготовлены к релизу. Они выпускаются в ближайшем запланированном релизе или их придерживают для интеграции с другими элементами.
• Оценка для определения количества усилий или времени выполнения не проводится.
• Крупные элементы нематериального класса допустимо разбивать на более мелкие, каждый из которых может ставиться в очередь и обрабатываться отдельно.
• Обычно элемент нематериального класса откладывается ради обработки ускоренного запроса.
• В случае с элементами нематериального класса предоставление соглашения об уровне обслуживания может оказаться необязательным. Если оно все же необходимо, то должно иметь менее жесткие ограничения, чем предлагаемые для элементов стандартного класса: например, 60 дней с 50 %-ным выполнением в срок.
Соглашение об уровне обслуживания
В приведенном примере целевое время выполнения для стандартного класса обслуживания установлено и составляет, например, 28 дней (4 недели). Идея задавать целевое время выполнения вместе с показателем выполнения в срок – это альтернатива индивидуальному подходу ко всем элементам, который предполагает оценку и обязательство успеть к определенному моменту для каждого из них. Соглашение об уровне обслуживания позволяет избежать дорогостоящих (например, оценки) и не пользующихся доверием (например, принятие на себя обязательств) мероприятий и распределить риск, собрав большое количество запросов и дав обещания только об общей производительности в форме доли работ в процентах, завершенных в срок. Не пообещав то, что вряд ли сможем выполнить, мы не рискуем потерять доверие потребителей. Таким образом, важно донести до клиентов, что целевое время выполнения для стандартного класса обслуживания – это именно цель!
Чтобы определить целевое время выполнения, следует опираться на предыдущие данные. Если их нет, то постарайтесь сделать предположение, близкое к истине. После этого внесите сроки выполнения (от изначального выбора до релиза) в статистический пакет управления процессами или инструмент отслеживания в канбане, который поддерживает статистическое управление процессами (например, Silver Catalyst), и установите верхнюю контрольную отметку (граница плюс 3-сигма) в качестве целевого времени выполнения. Так вы получите оптимальное время, в которое наверняка сможете уложиться в обычных условиях, а задержки связаны только с реальными проблемами, возникающими из-за систематических погрешностей (подробнее об этом – в главе 19).
Если предыдущий абзац показался вам трудным для понимания, то можно сформулировать иначе: необходимо, чтобы время выполнения было достижимым, но при этом планка должна быть задана достаточно агрессивно для сохранения командой концентрации. Скорее всего, ваши рабочие единицы будут отличаться по размерам, сложности, риску и уровню требуемой компетенции. Разным будет и время выполнения. Это совершенно нормально. Если, проведя анализ предыдущих данных, вы видите, что около 70 % заданий выполняется в течение 28 дней, а оставшиеся 30 % растягиваются еще на 100 дней, то вполне разумно сделать целевым временем именно 28 дней.
По опыту знаю, что использование классов обслуживания – это очень мощная техника. В 2007 году примерно 30 % всех запросов моей команды выполнялось позже целевого времени выполнения. Мы учитывали это в показателе «доля выполнения в срок». Он никогда не превышал 70. И несмотря на такое низкое соответствие дедлайнам, жалоб поступало очень мало. Причины очевидны: все важные элементы, сопряженные с высоким риском или большой ценностью, всегда выполнялись вовремя. Поэтому заказчики были уверены, что опаздывающие элементы будут готовы через 2–4 недели, поскольку релизы выходили регулярно.
Ускоренный класс обслуживания и класс с фиксированной датой поставки обеспечивали постоянное своевременное выполнение важных элементов. В то же время элементы, имевшие стандартный класс, обычно отставали всего на 1–2 релиза (14 или 28 дней соответственно). Клиенты чувствовали доверие к каденции релизов, и оно было вполне заслуженным. Мы неизменно выпускали релиз каждую вторую среду. Поскольку издержки из-за отсрочки выполнения многих элементов стандартного класса (а также нематериального класса, который в то время еще не был выделен) были невелики, клиенты сосредоточивались на уже сделанном и планировали будущие элементы, не беспокоясь из-за того, что работа над ними все еще идет.
Результат был значительный, поскольку Канбан и классы обслуживания серьезно изменили психологию клиента и природу взаимоотношений и ожиданий. Теперь клиенты были настроены на долгосрочное сотрудничество и производительность всей системы, а не на своевременность доставки одного или нескольких элементов. Это дало команде разработки возможность сосредоточиться на самом важном и не тратить время на решение проблем, порожденных низким уровнем доверия между ними и клиентами.
Назначение класса обслуживания
Класс обслуживания для элемента должен быть назначен, когда этот элемент поступает во входящую очередь. Если речь идет об ускоренном запросе, то это должно быть очевидно: элемент поступает вместе с явным требованием обработать его как можно быстрее. Обосновывать это призвана модель, демонстрирующая возможности или иллюстрирующая существенные убытки, которые возникнут, если запрос не обработать в срок. Не исключено, что такие убытки уже были, что типично для серьезных производственных ошибок.
Если для элемента установлена фиксированная дата поставки, то это тоже должно быть очевидно. Возможно, этот запрос связан с новыми требованиями регулятора, выдвинутыми соответствующим независимым органом, или с сезонной природой бизнеса клиента. Если элемент относится к классу с фиксированной датой поставки, то дедлайн обычно известен, выглядит реалистично (например, время выполнения вдвое превосходит типичное целевое время выполнения для стандартного класса), а элемент уже подвергнут оценке, чтобы запустить его в работу в оптимальный срок для обеспечения сдачи вовремя.
Сложнее, если элемент относится к стандартному или нематериальному классу. У элементов стандартного класса обычно имеются функции стоимости упущенной возможности, которые вступают в силу немедленно, – например, если бы сегодня у нас была такая-то функция, то уже завтра мы начали бы получать прибыль. Поэтому желательно реализовать эти элементы как можно быстрее. Но отсрочка не грозит такими же потерями, как для элементов с фиксированной датой поставки или для ускоренных запросов.
Нематериальные элементы обычно бывают важными и ценными, но цена упущенной возможности для них относится не к ближайшему будущему. Момент, когда расходы начинают ощущаться, наступает через несколько кварталов или лет. Таким образом, он выходит за рамки непосредственного планирования, составляющего два или три цикла разработки: например, если наше текущее время выполнения – 28 дней, то горизонт планирования – примерно три месяца. Элементы, грозящие упущенной возможностью или ощутимыми издержками в течение этого срока, должны относиться к стандартному классу, а элементы, связанные с выгодами или издержками, величина которых будут понятна только через несколько кварталов или лет, поступают в нематериальный класс.
Использование классов обслуживания
Классы обслуживания должны быть определены для каждой канбан-системы. Правила, связанные с каждым классом обслуживания, следует объяснить всем членам команды. Посетители ежедневных стендапов должны оценить и понять принципы использования классов обслуживания. Для этого желательно, чтобы количество этих классов было сравнительно небольшим – от четырех до шести. Именно потому, что каждый член команды должен помнить распределение по классам обслуживания, знать их значение и использование, количество правил для каждого класса тоже должно быть невелико, а сами правила – простыми. Определения нужны точные и недвусмысленные. Неплохо, когда на каждый класс приходится не более чем по шесть правил.
Вооружившись пониманием классов обслуживания и знанием связанных с ними правил, команде следует получить полномочия для самоорганизации рабочего потока. Рабочие единицы должны проходить по системе так, чтобы коммерческая ценность и клиентская поддержка оставались оптимальными, а удовлетворенность клиентов от выпускаемых программ – максимальной.
Распределение мощности по классам обслуживания
На рис. 11.3 представлена канбан-система, общий WIP-лимит для которой равен 20. Классы обслуживания обозначены карточками четырех цветов. Белые карточки ускоренного класса не учитываются в общем WIP-лимите, но ограничены одним элементом за раз. Таким образом, они (если есть в наличии) вносят 5 %-ный вклад в общую мощность, доводя реальное количество незавершенных заданий до 21. В этом примере фиолетовые карточки для элементов с фиксированной датой поставки составляют 20 % от общего количества. Это значит, что на доске может быть только четыре фиолетовые карточки в один и тот же момент, однако присутствовать они могут в любом столбце. Желтые элементы стандартного класса составляют 50 % всей мощности, а остальные 30 % отведены зеленым элементам нематериального класса.
Рис. 11.3. Стена карточек, демонстрирующая распределение мощности по классам обслуживания
Сейчас, когда мы распределили мощность по разным классам обслуживания, деятельность по пополнению входящей очереди осложняется, поскольку надо учитывать доступную мощность для каждого класса. На рисунке видно, что есть место для одного элемента с фиксированной датой поставки и трех – нематериального класса. Это порождает множество вопросов. Что если у нас нет сейчас спроса на элемент с фиксированной датой поставки? Как быть? Возможно, заполнить свободное место элементом стандартного класса? Но нужно ли в таком случае переводить этот элемент в класс с фиксированной датой поставки? Или продолжать обрабатывать его как элемент стандартного класса? А не является ли все это нарушением правил распределения мощности?
Эти разумные вопросы отражают повседневные проблемы использования канбан-системы. Более того, на них нет правильных и неправильных ответов, все зависит от конкретной ситуации.
Из выбранного распределения можно понять, что в данной отрасли присутствует существенное количество элементов с фиксированной датой поставки, к тому же серьезные запасы мощности зарезервированы за нематериальными элементами. Возможно, это связано с реализацией каких-то крупных инициатив с более длительными сроками выполнения, например заменой платформы. Или же отрасль связана с существенными рисками. Не исключено, что количество ускоренных запросов или элементов с фиксированной датой поставки растет из-за сезонной природы спроса. Чтобы правильно отреагировать на такой спрос и не вызвать роста неудовлетворенности клиентов, мы и выделяем больше мощности на нематериальные элементы за счет элементов стандартного класса. Тем самым в системе создается больше резерва.
Если же говорить о том, как поступить, когда во входящей очереди образуется место для элемента с фиксированной датой поставки, а их нет, то в первую очередь следует учесть риски, характерные для данной отрасли. Если спрос на элементы с фиксированной датой поставки в целом значителен, а связанные с этим издержки высоки (и риск, соответственно, тоже), то, возможно, лучше оставить место свободным. Разумно также зарезервировать мощность в ожидании поступления следующего элемента с фиксированной датой поставки. Если риски малы, то мы можем заполнить свободное место элементом стандартного класса. Когда же появляется элемент с фиксированной датой поставки, можно либо приостановить работу над элементом стандартного класса, либо временно превысить WIP-лимит. Все эти решения окажут свое влияние на время выполнения, долю выполнения в срок, распространение вариативности времени выполнения, удовлетворенность пользователя и управление рисками. Решения придется принимать самостоятельно, и потребуется время, прежде чем вы накопите достаточно опыта, чтобы делать наилучший выбор для команды, проекта и организации в целом.
Распределение мощности – это еще одна стратегия в канбан-системе. Если вы считаете, что распределение не соответствует спросу, то внесите в него изменения: поменяйте правила и соответствующие WIP-лимиты.
Выводы
• Классы обслуживания – это удобный метод оптимизации удовлетворенности клиентов.
• Единицам работы должен быть приписан класс в соответствии с их важностью для бизнеса.
• Классы обслуживания должны получить четкое визуальное отображение: для этого можно использовать как карточки разных цветов, так и разные «плавательные дорожки» на стене карточек.
• Следует определить набор правил управления для каждого класса обслуживания. Только для тех классов обслуживания, которые связаны с более рискованными элементами, можно привлекать такие затратные действия, как оценка.
• Членам команд следует объяснить классы обслуживания и связанные с ними правила.
• Некоторые классы обслуживания должны иметь целевое время выполнения.
• В случае установления целевого времени выполнения необходимо отслеживать долю заданий, выполненных в срок.
• Классы обслуживания дают возможность для самоорганизации, предоставляют членам команды полномочия и освобождают время руководства для того, чтобы сконцентрироваться на процессе, а не на ежедневной текучке.
• Классы обслуживания меняют психологию клиентов.
• Если классы обслуживания используются должным образом в сочетании с регулярной каденцией релизов, то поступает мало жалоб, даже когда значительное количество элементов реализуется позже целевого времени выполнения.
• На каждый класс обслуживания должна выделяться мощность канбан-системы.
• Доля мощности, выделенной на каждый класс обслуживания, должна согласовываться со спросом.
Глава 12 Показатели и доклады для руководства
Хотя сама суть Канбана состоит в том, что его вторжение в цепочку создания ценности, рабочие функции и сферы ответственности, а также вызываемые им изменения должны быть минимальны, он все же действительно меняет взаимодействие команды с партнерами – внешними заинтересованными лицами. Поэтому в Канбане для отчетов используются немного другие показатели, чем при традиционном или гибком подходе к управлению проектами. Система непрерывного потока, характерная для Канбана, подразумевает, что нам не очень важно, «по графику» ли движется проект и следует ли он определенному плану. Главное – показать, что канбан-система предсказуема и работает как положено, а организация обладает деловой гибкостью, сосредоточена на потоке работы и развивается на пути к постоянным улучшениям.
Ради предсказуемости нужно продемонстрировать, насколько хорошо мы работаем в соответствии с обещаниями для классов обслуживания, правильно ли обрабатываются рабочие элементы и как работа соотносится с целевым временем выполнения, если таковое установлено, какова доля заданий, выполненных в срок. Для каждого из индикаторов мы хотим отследить тенденции развития во времени, чтобы установить распространение вариативности. Чтобы показать непрерывные улучшения, нужна средняя тенденция к улучшению. Для демонстрации повышения предсказуемости надо предъявить уменьшение распространения вариативности и повышение доли заданий, выполненных в срок.
Отслеживание WIP
Но прежде чем мы перейдем к производственным показателям, хочу отметить: наиболее фундаментальный показатель должен демонстрировать, что канбан-система работает нужным образом. Для этого нам требуется кумулятивная диаграмма потока, которая показывает количество незавершенных заданий на каждой стадии системы. Если канбан-система работает как надо, то полосы на диаграмме выглядят равномерно и имеют стабильную высоту. Диаграмма на рис. 12.1 демонстрирует, насколько хорошо команда соблюдает WIP-лимиты.
Рис. 12.1. Пример кумулятивной диаграммы потока из канбан-системы (за 2007 год)
Мы видим, что незавершенные задания (средняя, более светлая полоса) растут в середине этого периода времени. В начале WIP-лимит, как и положено, равняется 27. В конце этого периода в связи с изменением количества персонала WIP-лимит составляет 21. Можно увидеть и среднее время выполнения, посмотрев на горизонтальную составляющую диаграммы.
Время выполнения
Следующий показатель, который нас интересует, демонстрирует то, насколько предсказуемо наша организация выполняет обещания в соответствии с определением классов обслуживания. Этот показатель – время выполнения. Если элемент был ускорен, то насколько быстро нам удалось провести его от заказа к производству? Если элемент относился к стандартному классу, успели ли мы выпустить его в соответствии с целевым временем выполнения? Нагляднее всего эти данные демонстрирует спектральный анализ времени выполнения, который учитывает целевое время выполнения и соглашение об уровне обслуживания для класса обслуживания (рис. 12.2). Отчеты о среднем времени выполнения имеют смысл для учета общей производительности (рис. 12.3), но не очень полезны в качестве индикатора предсказуемости и как средство информирования о возможностях улучшения.
Рис. 12.2. Пример спектрального анализа времени выполнения
Рис. 12.3 Пример тенденции среднего времени выполнения
Спектральный анализ гораздо полезнее, поскольку информирует об элементах, которые не уложились в целевое время, а также о других статистических выбросах. В примере, показанном на рис. 12.4, имеет смысл провести анализ глубинных причин того, почему целый ряд элементов не был реализован за целевое время. Если эти причины будут устранены, то доля заданий, выполненных в срок (то есть в соответствии с ожиданиями), должна вырасти.
Рис. 12.4. Пример отчета, демонстрирующего среднее время выполнения и долю заданий, выполненных в срок
Доля заданий, выполненных в срок
Опыт подсказывает, что полезно отчитываться о числе заданий, выполненных в срок за последний месяц и за текущий год. Возможно, вы захотите отчитываться и по производительности год к году (или по сравнению с тем же месяцем прошлого года) для сопоставления. Поэтому желательно брать данные за 13 месяцев.
В показатель «Доля заданий, выполненных в срок» можно включить элементы класса обслуживания с фиксированной датой. В этом случае вы получаете ответ на вопрос, был ли элемент выпущен вовремя. Но записанное время выполнения само по себе не так интересно, как сравнение предварительной оценки времени выполнения с фактическим временем.
Такая оценка демонстрирует предсказуемость команды и успешность ее работы с элементами класса обслуживания с фиксированной датой. Помните, что эти элементы подвергаются анализу и оценке. Доля выполненных в срок элементов с фиксированной датой – это фактор, определяющий качество изначальной оценки.
Разумеется, самый важный показатель – был ли элемент выпущен до дедлайна.
Точность оценки – это, в свою очередь, индикатор эффективности системы. Если известно, что оценки грешат неточностью, то команде придется раньше начинать работу над элементами с фиксированной датой, чтобы гарантированно успеть к сроку. Это нельзя считать оптимальным вариантом. Общую производительность с точки зрения ценности и пропускной способности можно улучшить, повысив качество оценки.
Пропускная способность
Пропускная способность измеряется в количестве элементов (или их ценности), реализованных за указанный период, например за один месяц. Пропускная способность представляется в виде тенденции, как показано на рис. 12.5. Цель состоит в ее постоянном увеличении. Пропускная способность близка к такому показателю agile-методологий, как «скорость». Он показывает, сколько пользовательских историй закончено за данный период (или сколько очков за пользовательскую историю набрано). Если вы не используете такие agile-техники, а занимаетесь обработкой других элементов – например, элементов функциональных требований, запросов изменений, пользовательских сценариев, – то считать можно и в них.
Рис. 12.5. Пример столбиковой диаграммы пропускной способности
Важно иметь на руках общее количество. Когда ваша команда станет более зрелой и опытной, можно будет отчитываться и по относительному размеру – например, по общему числу очков за пользовательскую историю, функциональных очков и других единиц измерения. В достаточно опытной организации можно отчитываться по ценности выполненной работы в долларовом эквиваленте. Правда, на момент написания этой книги мне известно только об одной такой команде.
Данные о пропускной способности используются в Канбане с совершенно иными целями, чем скорость в типичной среде гибкой разработки. Пропускная способность не применяется для предсказания количества выполненных элементов за период или для принятия обязательств по объемам производства. Это лишь индикатор того, насколько хорошо действует система (команда и организация) и идет ли постоянное развитие. Обязательства в Канбане принимаются по времени выполнения и целевым датам выполнения. Пропускная способность может быть использована в более крупных проектах для приблизительной оценки времени выполнения с учетом буферов, нейтрализующих вариативность.
Проблемы и блокированные рабочие элементы
Диаграмма проблем и блокированных рабочих элементов – это кумулятивная диаграмма потока, где отражены возникшие препятствия. Она объединена с графиком количества заблокированных незавершенных заданий (рис. 12.6). Эта диаграмма демонстрирует, насколько хорошо организация справляется с выявлением блокирующих проблем и их влияния, сообщением о них и борьбой за их устранение.
.
Рис. 12.6. Пример диаграммы проблем и заблокированных рабочих элементов
Если доля заданий, выполненных в срок, низка, то на этой диаграмме должны быть соответствующие подтверждения того, что серьезные препятствия были обнаружены, но не исправлены достаточно быстро. Эту диаграмму полезно использовать повседневно, чтобы предупреждать руководителей о затруднениях и их последствиях. Кроме того, она может быть и долгосрочным документом, показывающим, насколько хорошо организация справляется с решением проблем и облегчением рабочего потока. Это показатель ее способностей в данной сфере.
Эффективность потока
Хороший индикатор для бережливого производства, показывающий степень эффективности системы, – отношение времени выполнения ко времени контакта. В производстве время контакта – это время, которое сотрудник проводит непосредственно за работой. В области разработки ПО измерить этот показатель очень трудно. Однако в большинстве систем отслеживания можно выявить отношение времени, выделенного отдельному сотруднику, ко времени блокирования и нахождения в очереди. Таким образом, хотя сообщение об отношении времени выполнения к выделенному времени не дает точной картины эффективности системы, оно вполне может показывать, каков потенциал для улучшения (рис. 12.7).
Рис. 12.7. Пример отношения времени выполнения к выделенному времени
Пусть вас не пугает, что изначально отношение равняется, например, 10: 1. Я был на многих конференциях, где докладчики, представлявшие самые разные сферы деятельности – от строительства самолетов до проектирования медицинского оборудования, – сообщали о таких же показателях.
Судя по всему, в интеллектуальной работе мы исключительно нерезультативны и неспособны проявить гибкость, которая требуется для эффективного превращения идеи или запроса в работающий продукт.
Показатель эффективности потока не очень полезен с точки зрения повседневности, однако тоже может стать индикатором непрерывного совершенствования.
Первоначальное качество
Ошибки влекут за собой дополнительные издержки и влияют на время выполнения и пропускную способность канбан-системы. Полезно отчитываться о количестве ошибок, которых удалось избежать, в процентном отношении к общему числу WIP и пропускной способности. Со временем желательно довести число ошибок до нуля, как показано на рис. 12.8.
Рис. 12.8. Диаграмма количества дефектов на функцию
Критическая нагрузка
Критическая нагрузка показывает, сколько элементов остается в работе из-за исходно плохого качества, поскольку имеют либо производственные дефекты, либо новые функции, которые были востребованы клиентской службой из-за неудобства в использовании или невозможности предугадывать потребности пользователей. Критическая нагрузка со временем должна падать, и это хороший индикатор роста зрелости организации и умения ее руководителей мыслить системно.
Выводы
• Записывайте WIP по кумулятивной диаграмме потока, чтобы ежедневно следить за WIP-лимитами.
• Записывайте время выполнения для каждого обработанного элемента и сообщайте как о среднем времени выполнения, так и о спектральном анализе для каждого класса обслуживания.
• Время выполнения – это индикатор деловой гибкости.
• Отслеживайте отношение ориентировочного времени выполнения к реальному для элементов класса обслуживания с фиксированной датой поставки.
• Сообщайте о доле заданий, выполненных в срок, как индикаторе предсказуемости.
• Препятствия блокируют рабочий поток и негативно сказываются на времени выполнения и доле заданий, выполненных в срок; сообщайте о блокирующих проблемах и количестве заблокированных рабочих элементов посредством кумулятивной диаграммы потока с наложенным на нее графиком заблокированных элементов. Используйте ее, чтобы показать свою способность выявлять проблемы и быстро их решать.
• Эффективность потока – это отношение времени выполнения ко времени, выделенному на работу. Показатель демонстрирует эффективность организации в обработке новых заданий и служит вторичным индикатором деловой гибкости. Он также демонстрирует потенциал для совершенствования, доступный без изменения методов работы.
• Исходное качество – показатель количества ошибок, обнаруженных тестировщиками в пределах системы. Он указывает на то, сколько мощности теряется из-за плохого изначального качества.
• Критическая нагрузка – показатель, сообщающий о доле работы, созданной ошибками в системе. Он говорит о мощности, которая могла быть использована для работы над новыми, создающими ценность функциями.
Глава 13 Масштабирование канбана
До сих пор примеры и истории о внедрении Канбана, представленные в этой книге, касались исключительно поддержки программ – небольших системных изменений, выходивших в быстрых и частых релизах. Есть множество систем, которые нуждаются в поддержке, и многие читатели, занимающиеся разработкой ПО, найдут здесь полезные советы и планы действий. В сфере IT важную роль играют также обслуживание и эксплуатация, где тоже распространены системы заданий на краткосрочные работы. Канбан-подход очень полезен и в этом случае. Однако есть и другие отрасли, в которых нормой считается разработка проектов существенного масштаба. Если вы, читая эту книгу, задаетесь вопросом, зачем и как использовать Канбан в работе над крупными проектами и всем портфелем проектов, то надеюсь, глава 5 убедила вас: Канбан приводит к значительным положительным культурным сдвигам. Преимущества, которых можно достичь благодаря Канбану, настолько желательны, что нельзя не задуматься над тем, как совместить его с большими проектами.
Крупные проекты сопровождаются заметными проблемами. Многие требования должны быть реализованы и выпущены одновременно. До первого релиза обычно проходит много времени – порой несколько месяцев. Возрастает и число участников команды. Параллельно ведутся работы в самых разных направлениях. Нужно объединить большие куски заданий, хотя не все они имеют отношение к разработке ПО. Например, документацию и дизайн программного пакета нередко требуется интегрировать в итоговую сборку программ до выхода релиза.
Как справиться с этими проблемами?
Ответ прост: вспомнить о главных принципах Канбана – ограничении числа незавершенных заданий и вытягивании работы при помощи визуальной сигнальной системы. Помимо этого, стоит учесть принципы бережливого программирования, agile-принципы, а также особенности рабочего потока и процессов, которые внедрены на текущий момент. Итак, мы хотим установить WIP-лимиты, использовать средства визуального контроля и сигналов и вытягивать работу, только когда обладаем достаточной мощностью. Однако нужны также переносы небольших пакетов, расстановка приоритетов по ценности, управление рисками, прогресс при неполной информации, создание культуры высокого доверия и оперативный и адекватный ответ на изменения, которые происходят в течение проекта.
При работе над большим проектом, как и в случае с обычным обслуживанием, нужно достичь соглашения по поводу каденции расстановки приоритетов для пополнения входящей очереди. Следует учесть, что чем чаще происходят собрания, тем лучше. Но вернемся к принципам. Каковы операционные и координационные издержки на обсуждение с маркетологами или руководителями направлений следующих элементов очереди? На другом конце цепочки создания ценности у вас будет несколько точек интеграции или синхронизации, необходимых для релиза, а не единая точка релиза. Поэтому, исходя из главных принципов, оцените операционные и координационные издержки интеграции и синхронизации и установите каденцию. Чем она чаще, тем лучше. Кроме того, спросите себя: «Что нужно для демонстрации на совещании с руководством последних выполненных задач и их интеграции при подготовке релиза?»
Затем переходите к соглашению по WIP-лимитам. Принципы при этом также не изменяются. Не менее полезны классы обслуживания, которые помогут вам справляться с изменениями на протяжении всего проекта.
Иерархические требования
Вам понадобится также определить типы рабочих единиц для проекта. Во многих крупных проектах есть иерархические требования, нередко даже трех уровней. Требования могут также различаться по типам: пользовательские требования, поступающие со стороны бизнеса, и требования продукта, которые предъявляют команды техников, архитекторов или службы контроля качества. Впоследствии требования иногда делятся на функциональные и нефункциональные (связанные с качеством обслуживания). Даже в рамках гибкой разработки ПО клиент может оформить требования в виде эпиков, которые затем распадаются на пользовательские истории, а иногда и на более низкоуровневые задания или мелкие элементы, так называемые песчинки. Мне доводилось видеть, как эпики раскладывались на архитектурные истории, которые, в свою очередь, делились на пользовательские истории.
Разработка на основе функционала тоже имеет три типа требований: для функций, наборов функций (или заданий) и тематических областей.
Командам, адаптирующим Канбан для крупных проектов, полезно установить разные типы единиц работы для различных уровней иерархии. Например, эпики – это один тип единицы работы, а более мелкие пользовательские истории – другой. В более традиционном проекте к одному типу будут относиться клиентские требования, к другому – требования продукта, а к третьему, более мелкому, – функциональные.
Обычно команды отслеживают два верхних уровня на канбан-доске. Мне не встречались команды, пытавшиеся применить Канбан ко всем трем уровням. Некоторые современные электронные инструменты поддерживают иерархические требования, которые позволяют пользователю ориентироваться в разных уровнях, но отображают в любой момент только два из них.
Если есть третий, самый низкий уровень (например, задачи в agile-проектах), то такие задачи обычно не отслеживаются на стене карточек проекта или в канбан-системе, используемой командой. Однако индивидуальные разработчики предпочитают их отслеживать. Так поступают небольшие межфункциональные команды в своей локальной системе. Но не стоит выносить это на общую доску проекта или демонстрировать менеджерам и партнерам по цепочке создания ценности. Причина в том, что самый низкий уровень малоинтересен с точки зрения цепочки создания ценности и общей производительности. Самый низкий уровень обычно сосредоточен на деятельности как таковой, а не на создании пользовательской ценности и функционала.
Сейчас получил распространение вариант Канбана для личного использования, который отстаивают Джим Бенсон и другие эксперты. Личный Канбан используется дома и – на индивидуальном уровне – в офисе или в небольших группах по два-три человека, которые вместе трудятся над одним и тем же набором рабочих единиц. Пока трудно сказать, встроится ли личный Канбан в более широкую отрасль знаний или станет самостоятельной дисциплиной.
Разделение поставки ценности и вариативности рабочих единиц
Поскольку большая часть Канбан-команд отслеживает только два верхних уровня требований, появилась идея о том, что верхний, наименее детализированный уровень требований обычно описывает какую-либо неделимую единицу ценности, создаваемую для рынка или клиента. Эти эпики, или пользовательские требования, часто писали так, чтобы после реализации их можно было вывести на рынок. Если же продукт уже обслуживался, то запросы можно было обрабатывать и выпускать в индивидуальном порядке. Иногда этот уровень требований в Канбан-сообществе именуется «минимальной коммерчески ценной функцией» (Minimal Marketable Feature, MMF). Небольшая терминологическая путаница связана с тем, что MMF была определена Денном и Клиланд-Хуань в книге Software by Numbers, причем их определение не вполне соответствует используемому на практике. Поэтому я использую понятие «минимальный коммерчески ценный релиз» (Minimal Marketable Release, MMR), которым обозначаю ряд функций, воспринимаемых клиентом как единый набор и достаточно полезных, чтобы оправдать издержки релиза.
Бессмысленно считать MMR единым элементом, проходящим через канбан-систему. MMR состоит из множества рабочих единиц. Это понятие оправданно с точки зрения операционных издержек релиза, а не организации рабочего потока. В некоторых случаях небольшая, но очень ценная новая функция, вносящая существенные изменения, имеет достаточный экономический смысл, чтобы выпустить ее отдельным релизом. В то же время опыт подсказывает, что «первая MMR всегда большая», поскольку в первый релиз новой системы должны быть включены все необходимые функции для выхода на рынок и вся инфраструктура для их поддержки. Размер MMF (или MMR) может различаться на два-три порядка. Тип рабочей единицы, составные части которой отличаются в тысячу раз, сложно реализовать.
Канбан-системы не считают ценностью такие вариации в размере. Они требуют крупных буферов и излишка WIP для восстановления равномерности потока, иначе время выполнения будет слишком разниться. Крупные буферы и увеличение WIP ведут к росту времени выполнения и потере деловой гибкости. Но альтернатива еще хуже! Если не ввести буфер под вариативность размеров, то время выполнения будет существенно варьировать. В этом случае не удастся указать целевое время выполнения по соглашению об уровне обслуживания, к которому мы будем по большей части успевать выполнить задание. Это приведет к ухудшению предсказуемости и потере доверия к системе. В результате разработки канбан-системы вокруг идеи MMF, скорее всего, будет утрачена деловая гибкость, а также предсказуемость, доверие между IT-отделом и бизнесом, что может вызвать разочарование в самой идее Канбана.
Но если использовать MMR для ускорения результата, сочетая его с более мелкими и детальными типами единиц работы, это поможет свести к минимуму расходы и приведет к максимальной удовлетворенности пользователя результатом релиза.
Команды могут перейти на этот подход, сосредоточившись на таких методах анализа, которые приводят к выработке более низкого уровня требований, например пользовательских историй или функциональной спецификации. Эти требования обычно небольшие, детализированные и мало отличаются друг от друга по размеру. Идеальный вариант – от половины дня до четырех дней работы.
В одном крупном проекте каждый крупный рабочий элемент под названием «требование», отслеживаемый при помощи зеленых карточек, распадался в среднем на 21 более мелкую «функцию», которым присваивались желтые карточки. Хотя функции описывались в основном с точки зрения клиентской ценности, анализ показал, что они имеют небольшие и почти одинаковые размеры. Если бы это был agile-проект, его уровни соответствовали бы эпикам (зеленого цвета) и пользовательским историям (желтого цвета).
Небольшие, более детализированные элементы облегчают рабочий поток, повышают предсказуемость пропускной способности и времени выполнения, а более крупные элементы на верхнем уровне доски позволяют контролировать количество достаточных для релиза и выхода на рынок требований, реализуемых в любой момент времени.
Взяв на вооружение этот двухъярусный подход, мы отделили создание ценности от вариативности размеров и усилий, затрачиваемых на ее создание.
Полезно задать WIP-лимиты на обоих уровнях. На основании нескольких проектов мы сделали вывод, что оптимальнее всего приставить небольшие межфункциональные команды к каждому высокоуровневому требованию. Эти команды вытягивают все более мелкие и детализированные элементы, относящиеся к крупному требованию, и без задержек проводят их по всей доске, пока требование не закончено и не готово для интеграции или релиза. Затем команда берется за другое крупное требование. При этом всегда остается возможность в зависимости от размера следующего элемента, над которым предстоит работа, добавить людей в команду либо, наоборот, убрать лишних специалистов.
Двухуровневые стены карточек
Первые команды, использовавшие Канбан в работе над крупными проектами, имели дело с двухуровневыми стенами карточек (пример – на рис. 13.1).
Рис. 13.1. Фотография двухуровневой доски
На этой фотографии крупные требования обозначены зелеными карточками. Они движутся слева направо, переходят в различные состояния: «бэклог», «предложено» (анализ), «в работе» (проектирование и разработка), «устранено» (тестирование) и «закрыто».
Требования в работе показаны в верхней части центрального раздела стены. В свою очередь, они разбиваются на множество более мелких функций, которым соответствуют зеленые карточки. Функции проходят из одного состояния в другое: «предложена» (анализ), «в работе» (проектирование и кодирование), «устранено» (тестирование) и «закрыто».
Состояния, которые проходят функции, напоминают состояния высокоуровневых требований, но это не обязательно: вы можете распределять их как вам удобно. Удобнее всего придерживаться текущего положения дел: не стоит менять процесс, если этого можно избежать.
Желтые карточки привязываются к породившим их зеленым: на желтые карточки наклеиваются ярлыки, где указаны ID зеленых.
В подобных случаях возможно ограничить WIP на обоих иерархических уровнях, но все желтые карточки группируются в один пул. У меня пока не хватает данных по отрасли, чтобы определить, насколько успешна эта стратегия, но в данном случае она не сработала.
Введение «плавательных дорожек»
Связь более детализированных желтых карточек с породившими их крупными требованиями очень важна. Кроме того, имеет смысл задать WIP-лимиты на более низком уровне в пределах конкретной кроссфункциональной команды. Чтобы облегчить реализацию этого подхода, некоторые команды внесли новшество в систему стены карточек и ввели «плавательные дорожки».
На рис. 13.2 высокоуровневые требования, которым соответствуют зеленые карточки, проходят через те же состояния – то есть бэклог, «предложено», «в работе», «устранено» и «закрыто». Однако средний раздел отличается по внешнему виду от рис. 13.1. Крупные требования, находящиеся в работе и представленные желтыми карточками, вертикально сгруппированы слева по центру. От каждой из этих зеленых карточек отходит «плавательная дорожка», разделенная на те же состояния, что и у более детализированных желтых функций. Количество «плавательных дорожек» и составляет WIP-лимит для крупных клиентских и рыночных требований, а WIP-лимит для низшего уровня теперь можно задать для каждой «плавательной дорожки» по желанию команд. Столбец справа от вертикальной колонки зеленых требований содержит имена постоянно прикрепленных к ним членов команды. На маленьких оранжевых карточках, прикрепленных к желтым, указаны имена специалистов, работающих сразу над несколькими проектами, например дизайнеров пользовательского интерфейса или архитекторов баз данных.
.
Рис. 13.2. Фотография двухуровневой доски с «плавательными дорожками»
Этот вариант стены карточек с «плавательными дорожками» означает, что клиентскими и рыночными WIP мы управляем вертикально, а WIP для низковариативных функций рассматриваются горизонтально. Такой формат оказался очень популярным и получил широкое распространение.
Альтернативный подход к борьбе с вариативностью трудозатрат
Еще один подход нейтрализации вариативности трудозатрат – это создание разных типов рабочих единиц для разного размера единиц. Для этого можно задать «плавательные дорожки» для единиц каждого размера (типа). WIP-лимиты в этом случае должны задаваться для каждого столбца в каждой дорожке, то есть для каждой ячейки на стене карточек. Поскольку вариативность по каждой дорожке мала (ведь все единицы имеют примерно одинаковый размер), дорожки должны проходить по потоку относительно гладко. Это способ борьбы с вариативностью без применения двухъярусной системы.
Введение классов обслуживания
Два наиболее очевидных метода визуальной дифференциации карточек на стене – это использование разных цветов и «плавательных дорожек». Однако в крупных проектах у каждой карточки есть три атрибута, о которых необходимо сообщить: это тип единицы работы, уровень иерархии и класс обслуживания. Стоит заметить, что в нашем примере (рис. 13.2) было принято решение завести разные типы единиц работы для различных иерархических уровней, а также применить и цвета, и «плавательные дорожки» для обозначения самих уровней. То есть для иерархии фактически использовались два метода визуализации, а это обычно приводит к перегрузке.
Когда помимо типа и уровня в иерархии требований нужно показывать еще и класс обслуживания, имеет смысл применить разные цвета для различных классов обслуживания. Если типы используются не для привязки к иерархическому уровню, а, например, для отображения ошибок и дефектов или для того, чтобы отнести ценность к критической нагрузке, тогда, возможно, стоит попробовать другой подход – ввести для обозначения типа иконку или стикер, прикрепляемый к карточке, воспользоваться цветом для типа и иконкой либо стикером для класса обслуживания (например, серебряной звездочкой для ускоренного запроса).
Еще проще назначить цвета для различных целей – иерархического уровня, типа и класса обслуживания. Этот подход, при котором цвет не привязан к строго определенному атрибуту, оказался приемлемым для пользователей канбан-системы и очень эффективен с точки зрения доступных вариантов визуализации.
Системная интеграция
В некоторых крупных проектах над разными компонентами системы работает несколько команд, и результаты их деятельности впоследствии требуют интеграции. Часть этих компонентов нуждается в специфическом оборудовании или прошивке либо не поддается современным методикам непрерывной интеграции. Когда появляются компоненты, которые должны быть интегрированы, следует определить интеграционную точку на основании планирования крупных высокоуровневых требований. Такая точка и будет фиксированной датой поставки для сдачи этих взаимозависимых компонентов. Это позволяет каждой команде независимо друг от друга продвигаться вперед по канбан-системе, но при необходимости координировать свои действия в работе над взаимозависимыми элементами. Опоздание со сдачей одного элемента может привести к серьезным отсрочкам в рамках всего проекта. Высокие издержки из-за отсрочки дают основание рассматривать такие случаи как элементы с фиксированной датой поставки.
Управление общими ресурсами
Для крупных проектов и портфелей проектов характерно использование общих ресурсов узких специалистов в таких областях, как, например, архитектура программ и баз данных, управление базами данных, тестирование взаимодействия с пользователем, дизайн пользовательского интерфейса и аудит безопасности программного обеспечения. В Канбане установилось три метода работы с общими ресурсами.
При использовании первого метода к некоторым единицам работы прикрепляются дополнительные, более мелкие оранжевые карточки. На них пишется имя специалиста – например, «Сэнди, архитектор корпоративных данных». Даже при самом низком уровне вмешательства такой простой визуализации работы специалиста, не выделенного специально для этого проекта, достаточно, чтобы скоординировать его деятельность. Если одно и то же имя появляется на нескольких карточках, может возникнуть вопрос, как этот человек собирается одновременно справляться с множеством заданий. Возникает дискуссия, после которой возможна смена тактики (нужно ли, чтобы вся работа проходила через одного человека?) или переход на следующий уровень.
Следующий уровень предполагает понимание того, что общие ресурсы не будут доступны по первому требованию. Визуализируется это так: элементы, требующие внимания специалиста (оранжевые карточки), помечаются как блокированные, пока он не начнет активно над ними работать. Это ведет к началу работы над проблемой, которая приводит к высвобождению специалиста, участвующего сразу в нескольких проектах. Кроме того, это сигнал руководству, что доступность данного ресурса может оказаться проблематичной и стать потенциальным бутылочным горлышком.
Высший уровень управления общими ресурсами – это создание собственной канбан-системы для данного ресурса. Например, собственную канбан-систему может получить архитектура корпоративных данных, тестирование взаимодействия с пользователем, безопасность программ и т. д. Каждая команда или специалист независимо друг от друга анализирует спрос на свою работу и устанавливает типы рабочих единиц на основе источника запроса, а также классы обслуживания на основе приоритетности и требуемого ответа. После анализа спроса устанавливаются правила распределения мощности.
На этом уровне возникает архитектура для обслуживания запросов на разработку самих программ. Каждая группа внутри организации предлагает собственный набор сервисов, которые реализуются в виде соглашений об уровне обслуживания для различных классов обслуживания и типов единиц работы. После этого клиенты общих ресурсов подают рабочие запросы, фиксируя их в бэклоге. Эти запросы поступают в очередь и оттуда вытягиваются для обработки, как и описано в этой книге. Если запросы от конкретного клиента обрабатываются недостаточно быстро, то может начаться обсуждение, удачно ли спроектирована система и не изменить ли правила распределения мощности и назначения класса обслуживания. Это может даже послужить основанием для перегруппировки или дополнения рабочего состава.
Выводы
• Крупные проекты должны выполняться в соответствии с ключевыми принципами Канбана.
• WIP-лимиты, каденция приоритетов, каденция релизов и классы обслуживания остаются полезными и в крупных проектах.
• Крупные проекты обычно имеют иерархические требования, эти уровни иерархии следует моделировать при помощи типов единиц работы.
• Обычно команды отслеживают два верхних уровня иерархии требований на стене карточек и задают WIP-лимиты на одном или обоих уровнях.
• Верхний уровень требований, как правило, моделирует клиентские и рыночные требования, составляющие неделимые элементы, которые потенциально могут быть выпущены отдельным релизом.
• Второй уровень требований обычно имеет клиентоцентрический характер и анализируется так, чтобы требования были детализированными и имели примерно одинаковый размер.
• Этот второй уровень детализированных требований облегчает рабочий поток, так как снижает вариативность в вытягивающей канбан-системе.
• Чтобы визуализировать оба отслеживаемых уровня требований, потребуется двухуровневая стена карточек.
• Популярный метод демонстрации иерархии и облегчения задания WIP-лимитов – так называемые плавательные дорожки.
• Крупные WIP ограничиваются количеством «плавательных дорожек».
• Детализированные WIP при желании можно ограничить на каждой «плавательной дорожке».
• Как правило, на каждую «плавательную дорожку» назначаются небольшие межфункциональные команды.
• Спрос на общие ресурсы можно визуализировать при помощи небольших стикеров, прикрепляемых к обычным рабочим элементам.
• Необходимость ожидания общих ресурсов можно подчеркнуть при помощи стикеров блокирования (в нашем случае розовых), прикрепленных к исходным карточкам рабочего элемента.
• Общие ресурсы должны разработать собственные канбан-системы.
• Сеть канбан-систем для общих ресурсов в портфеле проектов можно считать архитектурой для обслуживания запросов на разработку ПО.
Глава 14 Операционный обзор
До совещания
Половина восьмого утра, вторая пятница марта 2007 года. Я пришел на работу так рано, потому что сегодня у нас в отделе четвертый ежемесячный анализ производственного процесса. Со мной Рик Гарбер, менеджер нашей группы процессов разработки ПО. Рик будет координатором совещания – он отвечает за повестку. Сейчас он распечатывает раздаточный материал для сегодняшнего анализа, который состоит примерно из 70 слайдов презентации в PowerPoint. Когда он заканчивает, мы направляемся в Harbor Club в деловой части Сиэтла с коробкой раздаточного материала на сто человек. Совещание назначено на 8:30 утра, но завтрак подается с восьми. Приглашены все сотрудники моей организации и компании моего коллеги Эрика Арнольда. Однако поскольку некоторые из них работают в Индии, другие – в других штатах США, а кое-кто не может посетить совещание по личным причинам, присутствует обычно человек восемьдесят.
Приглашены также мой босс, директор Corbis по информационным технологиям, и другие представители старшего руководства – наши партнеры по цепочке создания ценности. Среди членов внешних команд больше всего представителей отдела эксплуатации сетей и систем, которым руководит мой коллега Питер Тутак. Это и неудивительно, ведь им предстоит восстанавливать системы и устранять ошибки, поэтому наши промахи скажутся прежде всего на них. Они также подвергаются наибольшему влиянию, когда мы выпускаем новые релизы. Поэтому они активно участвуют в совещаниях.
Группа начинает собираться, все стараются успеть к завтраку. Зал находится на верхнем этаже сиэтлского небоскреба, откуда открывается прекрасный вид на город, гавань, пирсы и Эллиотт-Бэй[8]. В зале стоят круглые столы, за каждым – от шести до восьми человек. В одном конце зала – прожектор и кафедра. Рик действует в строгом соответствии с расписанием. Каждому выступающему дается примерно восемь минут, чтобы показать свои четыре-пять слайдов. Предусмотрены несколько отрезков времени на случай непредвиденных задержек, вызванных вопросами и обсуждениями. Я начинаю совещание с коротких вступительных замечаний: прошу всех мысленно вернуться к концу января и вспомнить, чем мы тогда занимались. Я напоминаю всем, что мы должны сейчас проанализировать работу организации за февраль. Рик подобрал отличную картинку из архивов компании, которая символизирует основную тему месяца и помогает вспомнить о том, чем мы тогда занимались.
Сразу задайте деловой тон
Я передаю слово Рику, который рассказывает о действиях за последний месяц и их текущем статусе. Затем слово берет наш финансовый аналитик, она представляет резюме производительности компании за месяц. Вот причина, по которой мы откладываем наши встречи до второй пятницы следующего месяца, – этого времени достаточно, чтобы подвести финансовые итоги месяца. Аналитик разъясняет детали бюджета для двух центров затрат – моего и Эрика. Мы рассматриваем соотношение запланированного бюджета и реального, а также планы работы сотрудников. Обсуждаются открытые заявки, а членам команды предлагается выдвигать кандидатов на имеющиеся вакансии. Благодаря первому этапу встречи все ее участники получают представление о том, насколько хорошо идут дела у команды разработки и каким образом она укладывается в бюджет. Это помогает понять, есть ли у нас резервы для покупки мониторов с плоским экраном, новых компьютеров и т. д. Мы начинаем с финансовых показателей, чтобы напомнить всем членам команды, что компания наняла их заниматься бизнесом, а не развлекаться, набирая на клавиатуре единицы и нолики ради собственного удовольствия.
Приглашение гостей расширяет аудиторию и создает дополнительную ценность
Следующий докладчик – наш гость, вице-президент другого подразделения. Я уже понял: если мы хотим, чтобы наши партнеры по цепочке создания ценности интересовались нами, нужно проявить интерес к ним и пригласить на встречу. По регламенту гостю отводится 15 минут, которыми он и воспользовался: мы прослушали презентацию, касающуюся отдела сбыта – того подразделения бизнеса, которое выполняет заказы клиентов и занимается доставкой продукта. Хотя бизнес Corbis делается в основном через интернет и заказы выполняются в электронной форме, не все, что предлагает наша фирма, доставляется посредством скачивания. Целый отдел занят удовлетворением более сложных заказов, поступающих из различных источников – от профессиональных рекламных агентств до медиакомпаний. Мой коллега Эрик Арнольд попросил гостя оплатить общий завтрак, чтобы удержать наши расходы в пределах допустимого. За несколько месяцев наша команда узнала о многих аспектах бизнеса, а руководителям компании стало известно о том, чем мы занимаемся, как это делаем и насколько интенсивно трудимся над решением проблем. В результате через девять месяцев топ-менеджеры рассуждали о том, как хорошо управляется IT-команда, и о необходимости остальным подразделениям следовать нашему примеру.
Основная повестка
Когда приглашенный докладчик закончил, мы перешли к основной части совещания. Каждый менеджер за восемь минут должен был представить данные о производительности своего отдела. Затем последовала информация об обновлениях по конкретным проектам от отдела управления программным продуктом. Руководитель каждой команды в течение пяти минут рассказывал о своих показателях. Использовался формат, изложенный в главе 12: приводились сведения о доле ошибок в продуктах, времени выполнения, пропускной способности, эффективности прироста ценности. В некоторых докладах особое внимание уделялось тем аспектам производственного процесса, по которым требовалось больше информации. Затем следовали вопросы, комментарии и предложения из зала.
Ежемесячный анализ производственного процесса, проходивший в марте 2007 года, был особенно интересным. Первый прошел в декабре, пришли почти все. Людям было любопытно, и впоследствии они говорили: «За всю карьеру не встречал такой прозрачности» или «Это было очень интересно». Один из самых полезных отзывов звучал так: «Хорошо бы, чтобы в следующий раз нам предложили не холодный, а горячий завтрак». Мы с этим согласились. В следующем месяце народ говорил: «Да, еще один отличный месяц. Спасибо за горячий завтрак!» А на третьем собрании некоторые спрашивали: «Зачем так рано вставать?» или «Думаете, это не пустая трата времени?»
На четвертой встрече мы анализировали серьезную проблему: компания приобрела бизнес в Австралии, и IT-отдел должен был выключить все IT-системы австралийской дочерней структуры, перевести всех 50 пользователей на системы Corbis. Дату выполнения запроса назначили произвольно, но он был срочным. Дата была связана с экономией на масштабах, которая должна была частично отбить сумму покупки, так что опоздание грозило издержками. Запрос поступил в очередь на обслуживание как единый элемент. По размеру он мог соответствовать даже десяти карточкам, но мы назначили для него всего одну. Эффект от поступления в канбан-систему такой монстрообразной рабочей единицы хорошо известен в промышленности. Система забивается, и время выполнения всего того, что следует за этим элементом, значительно увеличивается. Так и произошло. Время выполнения выросло с 30 до 55 дней. Теория массового обслуживания также утверждает, что сокращение журнала ожиданий при полной загрузке требует значительного времени. Мы выяснили: чтобы вернуться к целевому времени выполнения, понадобится пять месяцев.
Вдобавок у нас был релиз, который требовал срочной отладки.
И внезапно в зале зазвучали вопросы, комментарии и горячие споры. Наконец-то, после трех месяцев скучной позитивной информации, было что обсудить. Сотрудников поразило, что мы, руководители, готовы открыто обсуждать проблемы и их решения. Оказалось, что операционный обзор вовсе не сводится к демонстрации успехов. Никто из сотрудников больше не спрашивал, зачем нужны такие совещания.
В завершение Рик подытожил все меры, которые должно принять руководство в связи с вопросами, прозвучавшими этим утром, и поблагодарил всех присутствующих за участие в совещании. Половина одиннадцатого – пора возвращаться в офис.
Ключ для перехода к бережливым принципам
Нужно многое понять, прежде чем начинать говорить об анализе производственного процесса. В первую очередь, я верю, что операционный обзор – это краеугольный камень, ключ для перехода к бережливым принципам и внедрению Канбан-метода. Это объективный, основанный на данных ретроспективный анализ производительности организации. Он превыше любого конкретного проекта и задает ожидания объективного, основанного на данных количественного управления, а не более субъективного, несистематического, качественного управления, которое утвердилось как более распространенный метод, если смотреть на предысторию agile-проектов и итерационных подходов. Анализ производственного процесса порождает цикл обратной связи, который ведет к росту зрелости компании и непрерывному совершенствованию на организационном уровне. Я твердо верю, что он необходим для успешного перехода к бережливым принципам и agile-методологиям.
Подходящая каденция
Безусловно, операционный обзор должен происходить ежемесячно. Если назначать его чаще, то сбор данных станет слишком обременительным, а так как анализ требует времени, желательно проводить его не слишком часто. Уложиться в два часа сложно, а если совещание не опирается на данные, приведенные в отчетах и диаграммах, то это вообще невозможно. Субъективно воспринимаемое, проводимое бессистемно масштабное совещание не уложится в такой срок. Типичная ретроспектива по проекту занимает более двух часов, поэтому провести ретроспективу в масштабе всей организации, используя анализ плюсов и дельта-анализ, за два часа невозможно. Один из секретов сокращения продолжительности совещаний в том, чтобы придерживаться объективных данных. Повестка должна быть жесткой, и ее следует неуклонно соблюдать.
Иногда анализы производственного процесса проводят реже, чем раз в месяц, например ежеквартально. Мне доводилось участвовать в таких мероприятиях, когда я работал в подразделении персональных систем связи в Motorola. И я убедился, что это отчетно-аналитические собрания руководства, а не встречи в масштабе всей компании, направленные на постоянное совершенствование и формирование организационной зрелости. Раз в квартал – это слишком редко для того, чтобы программа совершенствования действительно заработала. Данные быстро устаревают: пока дело дойдет до следующего ежеквартального анализа, им исполнится четыре месяца. Это слишком долгий срок, чтобы ограничиться единственным совещанием, – такой анализ выглядит поверхностным. Отчеты и показатели часто связаны с запаздывающими индикаторами и сводятся к информированию руководства о том, как производительность соотносится с планом.
Ежеквартальные совещания кажутся привлекательными из-за якобы более высокой эффективности: всего одно двухчасовое собрание раз в квартал, а не раз в месяц. К тому же это дешевле: всего четыре совещания в год вместо двенадцати. После того как в начале 2008 года я покинул Corbis, мой бывший босс из экономии уменьшил каденцию операционного обзора с ежемесячной до ежеквартальной. Прошло три квартала, этот руководитель тоже ушел из компании, а новые менеджеры посчитали, что ценность совещаний невелика, и решили их отменить. Судя по всему, через несколько месяцев производительность организации существенно сократилась, а уровень зрелости, как сообщается, упал примерно с четвертого до второго – от «управляемого на основе количественных данных» до просто «управляемого».
Из этого следует несколько выводов. Утрата цикла обратной связи снизила возможности для рефлексии и адаптации, которые могли привести к улучшениям. Отказ от совещания, направленного на анализ объективной производительности организации, явился сигналом о том, что руководство больше не интересуется производительностью. Результатом стал существенный шаг назад в отношении зрелости организации и производительности с точки зрения предсказуемости, качества, времени выполнения и пропускной способности.
Демонстрация ценности менеджеров
Операционный обзор также показывает сотрудникам, чем занимаются менеджеры и как они могут создавать ценности для работников. Он помогает обучать работников думать как менеджеры и понимать, когда нужно вмешаться, а когда стоит отступить, предоставив команде самоорганизоваться и самостоятельно решить проблемы. Операционный обзор вырабатывает уважение между работниками умственного труда и их менеджерами, а также между разными уровнями руководства. Рост уважения порождает доверие, стимулирует сотрудничество и повышает социальный капитал организации.
Фокус на организации содействует кайдзену
Хотя ретроспективы по индивидуальным проектам всегда полезны, операционный обзор в масштабе всей организации помогает институционализации изменений, улучшений и процессов. Благодаря ему улучшения получают вирусное распространение по организации, и рождается небольшое внутреннее соперничество между проектами и командами, которое заставляет всех повышать производительность. Команды хотят продемонстрировать, как они могут помочь организации улучшить предсказуемость, увеличить пропускную способность, сократить время выполнения, снизить издержки и повысить качество.
Более ранний пример операционных обзоров
Операционные обзоры придумал не я. Они характерны для многих крупных компаний. Но я научился проводить их объективно и масштабно, когда в 2001 году работал в Sprint PCS. Мой руководитель, вице-президент и генеральный менеджер sprintpcs.com, учредил их примерно с теми же целями. Он хотел повысить зрелость своей организации – подразделения, состоявшего из 350 человек, отвечавшего за сайт, всю электронную коммерцию и онлайновую поддержку клиентов в компании Sprint, занимавшейся сотовой связью. В sprintpcs.com операционный обзор проводился каждую третью пятницу месяца в два часа дня. Он продолжался два часа, участвовали около 70 старших сотрудников и менеджеров соответствующего подразделения, приглашались также директора или старшие менеджеры наших партнеров по цепочке создания ценности. Часто бывали и высшие руководители, в том числе директор по маркетингу и вице-президент по стратегическому планированию. Формат очень походил на то, что было позднее реализовано в Corbis. Все проводилось исключительно на основании объективных данных. Каждый менеджер представлял собственные данные. Открывалось совещание финансовой информацией. Расписание было распланировано и четко соблюдалось. После совещания все уходили домой пораньше, тем более что была пятница. Совещание проводилось не на территории офиса, а в кампусе местного колледжа. Хотя методы гибкой разработки ПО в целом давались sprintpcs.com тяжело, операционный обзор был ключевым элементом в развитии зрелости организации и совершенствовании управления ею. Он демонстрировал сотрудникам, что менеджеры знают, как руководить, а сотрудники и руководители направления имеют возможность показать высшему руководству, чем они могут помочь и где менеджерам необходимо вмешаться, чтобы повысить эффективность. На основании двух экспериментов, проведенных за последнее десятилетие, я убедился, что операционные обзоры – это необходимый элемент успешного перехода к бережливым или agile-принципам и жизненно важный компонент развития зрелости организации.
Выводы
• Операционный обзор проводится в масштабе всей организации.
• Операционный обзор должен придерживаться объективных данных.
• Каждый отдел сообщает свои данные.
• Презентации должны быть короткими и в основном содержать показатели и индикаторы вроде тех, о которых говорилось в главе 12.
• Начинать нужно с финансовой информации: это подчеркивает, что разработка ПО – часть более обширного бизнеса, а хорошее управление имеет большое значение.
• Ежемесячное проведение операционных обзоров – оптимальный вариант. Более частые совещания обременительны с точки зрения времени, сбора и подготовки данных. Если проводить их реже, то они становятся менее ценными.
• Совещания должны быть короткими – желательно около двух часов.
• Операционный обзор нужно использовать для порождения цикла обратной связи и побуждения к постоянному совершенствованию на уровне организации или подразделения.
• Операционный обзор показывает сотрудникам, какую ценность могут добавлять в их жизнь и чем занимаются эффективные менеджеры.
• Эффективный операционный обзор создает взаимное доверие между менеджерами и сотрудниками.
• Внешние заинтересованные лица, посещая операционные обзоры, видят, как функционируют группы IT и разработки, узнают об их проблемах. Это усиливает доверие и сотрудничество.
• Операционные обзоры должны рассматривать негативные данные и проблемы не реже, чем подчеркивать успехи команд, добившихся хороших результатов.
• Проведение выездных совещаний, вероятно, помогает сосредоточить внимание присутствующих.
• Хорошая организация питания на таких встречах идет на пользу посещаемости.
• Участие высшего руководства сигнализирует о том, что организация серьезно рассматривает вопросы производительности и непрерывного совершенствования.
• Проявление серьезного интереса к производительности, непрерывному совершенствованию и управлению на основе количественных данных жизненно необходимо для развития культуры кайдзен среди сотрудников компании.
• Есть свидетельства того, что операционный обзор ведет к повышению уровня зрелости организации.
• Предложения по улучшению должны быть записаны как меры, которые предстоит принять руководству; реализация этих предложений рассмотрена в начале ближайшего и последующих совещаний.
• Менеджеры должны нести ответственность и демонстрировать систематическую работу над предложениями.
Глава 15 Начало перехода на канбан
Начало работы с Канбаном не похоже на те меры, которые вы, возможно, предпринимали в прошлом. Важно заложить основания для долгосрочного успеха. Для этого нужно сначала понять цели Канбан-подхода к изменениям. Главное при переходе на Канбан – это управление изменениями. Все остальное вторично.
Культурные изменения, а не инициатива сверху
В главе 5 описано, как Канбан оптимизирует существующий процесс после ряда пошаговых эволюционных изменений. Процесс оптимизации уже существующей модели ведет к повышению зрелости организации и позволяет впоследствии провести более крупные стратегические улучшения. Поэтому маловероятно, что перехода на Канбан удастся добиться при помощи инициативы сверху – например, назначив специальную программу обучения. Это существенно отличается от планирования и управления типичным переходом к agile-методологиям. На самом деле подход к управлению изменениями, используемый при переходе на agile-методы, мало отличается от предшествовавших подобных инициатив, например, основанных на модели CMMI или предполагающих введение Rational Unified Process. Инициатива по внедрению изменений в этом случае оказывается масштабным проектом, продуманным и распланированным заранее. Это особый вид управляемых изменений, при котором сначала определяется и оценивается текущий процесс, а затем выбирается один из agile-методов из учебника. После этого планируются меры по обучению и наставничеству, которые призваны помочь команде перейти от текущего метода к вводимому agile-процессу. Когда все заканчивается и внедряется новый процесс, проводится следующая оценка, которая должна продемонстрировать принятие новых методов. С Канбаном все происходит не так. В этом случае инициатива не планируется, не проводится никаких оценок и никто не говорит в конце: «Ну вот, мы перешли на agile!» Вообще конца как такового нет. Руководство управляет непрерывным процессом, проводя пошаговые изменения. В результате команда постепенно приходит к культуре кайдзен.
Действительно, обучение необходимо. Члены команды и другие заинтересованные лица должны понимать базовые принципы – например, взаимоотношения между WIP и временем выполнения, основанные на том, что строгие WIP-лимиты повысят предсказуемость времени выполнения. Возможно, понадобится провести краткий анализ вероятных путей совершенствования – устранения бутылочных горлышек, брака и вариативности. Когда потенциал для совершенствования выявлен, можно провести обучение новым навыкам и методам. Например, если основной источник брака – это программные ошибки, то стоит обучить команду разработчиков методам, которые существенно снижают количество ошибок и повышают качество кода: непрерывной интеграции, модульному тестированию и парному программированию.
Однако не нужно тратить слишком много времени на обучение. Прежде всего добейтесь консенсуса по поводу введения Канбана и начните пользоваться этим методом. Цель этой главы – попытаться заложить основы для успешного перехода на Канбан. В ней приводятся 12 простых шагов, необходимых для того, чтобы начать.
Хотя основная цель Канбана – вносить изменения при минимуме сопротивления, могут быть и иные задачи. Но изменения ради изменений бессмысленны: эти иные задачи должны отражать подлинные нужды бизнеса – например, предсказуемое создание высококачественного товара. Цели, перечисляемые здесь, – это примеры. Конкретные цели различаются для разных организаций. Первый шаг в процессе перехода – определить, для чего вы вводите Канбан в организации.
Основная цель для нашей канбан-системы
Мы переходим на Канбан, потому что считаем, что он дает возможность лучше производить изменения. Канбан изначально стремится изменить как можно меньше. Поэтому первая цель – это изменения с минимальным сопротивлением.
Цель 1. Оптимизация существующих процессов
Существующие процессы будут оптимизированы благодаря визуализации и ограничению числа незавершенных заданий, что стимулирует изменения. Поскольку существующие роли и степени ответственности не изменятся, сопротивление сотрудников будет минимальным.
Вторичные цели нашей канбан-системы
Мы знаем, что Канбан позволяет воплотить в жизнь все шесть элементов рецепта успеха (главу 3). Однако можно немного переформулировать цели и расширить некоторые пункты рецепта, чтобы каждый из них помогал добиться больше одной цели.
Цель 2. Высококачественные релизы
Канбан позволяет сосредоточиться на качестве, поскольку ограничивает число незавершенных заданий и дает возможность определить правила приемлемости, прежде чем единица работы будет переведена на следующий этап процесса. Эти правила могут включать критерии оценки качества. Если, например, мы строго-настрого запрещаем отправлять пользовательские истории на приемочный тест, пока не пройдут все остальные тесты и не будут устранены ошибки, мы тем самым заставляем конвейер простаивать, пока история не будет исправлена так, что можно продолжить работу. Если команда недостаточно знакома с Канбаном, то не стоит устанавливать такое жесткое правило, но какие-то критерии качества, привлекающие внимание команды к разработке хорошего кода, почти не содержащего ошибок, должны присутствовать.
Цель 3. Повышение предсказуемости времени выполнения
Нам известно, что количество WIP непосредственно связано с временем выполнения и есть корреляция между временем выполнения и нелинейным ростом количества ошибок[9]. Поэтому имеет смысл задавать WIP-лимиты. Будет гораздо легче работать, если мы ограничим число незавершенных заданий фиксированной цифрой. Это позволит установить предсказуемое время выполнения, а число ошибок должно уменьшиться.
Цель 4. Повышение удовлетворенности сотрудников
Хотя об удовлетворенности сотрудников часто и много говорят в большинстве компаний, она редко относится к приоритетам. Баланс работы и жизни – это не просто уравновешивание количества часов, которое человек проводит в офисе, и времени, оставшегося для семьи, друзей, хобби, пристрастий и увлечений. Это еще и вопрос надежности. Например, сотрудник, любящий искусство, хочет посещать художественные курсы в местной школе. Они проходят по средам, начинаются в половине седьмого вечера и рассчитаны на десять недель. Может ли ваша команда твердо обещать, что этот человек каждую среду будет вовремя уходить с работы и успевать на занятия?
Обеспечение оптимального баланса работы и жизни сделает вашу компанию более привлекательным работодателем на местном рынке, поможет мотивировать сотрудников и придаст членам команды дополнительную энергию, благодаря которой они на месяцы или даже на годы сохранят высокий уровень производительности. Ошибочно считать, что лучший вариант добиться высокой производительности среди работников умственного труда – это перегрузить их работой. Если строить планы на несколько ближайших дней, то это может оказаться верной тактикой, но через неделю или две все разладится. Никогда не перегружать свои команды и обеспечивать оптимальный баланс работы и жизни – это правила хорошего бизнеса.
Цель 5. Создание резервов для дальнейшего совершенствования
Третий элемент рецепта успеха – баланс между требованиями и пропускной способностью – может помочь членам команды избежать перегрузки и создать для них оптимальный баланс работы и жизни. Но у него есть и побочный эффект: он формирует резервы в цепочке создания ценности. В вашей организации должно быть бутылочное горлышко.
Оно есть в каждой цепочке создания ценности. Пропускная способность всей цепочки ограничена пропускной способностью бутылочного горлышка, независимо от того, в каком месте цепочки оно находится. Поэтому, когда вы устанавливаете баланс между входящими запросами и пропускной способностью, вы сознательно создаете простои в каждой точке цепочки создания ценности, за исключением этого бутылочного горлышка.
Большинство менеджеров, услышав о времени простоя, приходят в ярость. Их учили стремиться к максимальному использованию сотрудников (или, иначе говоря, к эффективности), поэтому им кажется, что если создается простой, то необходимы изменения, сокращающие расходы. Возможно, это верно, но важно понимать значение резервов.
Резервы можно использовать, чтобы уменьшить время отклика на срочные запросы и обеспечить плацдарм для совершенствования процесса. Без резервов у членов команды не будет времени размышлять над своей работой и путями ее улучшения, обучаться новым методам, совершенствовать свои инструменты, навыки и умения. Без резервов системе недостает гибкости для реагирования на срочные запросы или последние изменения, а бизнесу – тактической гибкости.
Цель 6. Упрощение расстановки приоритетов
Когда команда способна сосредоточиться на качестве, задать WIP-лимиты, часто выпускать релизы и сбалансировать нагрузку и пропускную способность, она обретет надежную, достойную доверия мощность и станет настоящей машиной по производству программ! Своего рода программным заводом, если хотите. Как только эта мощность установлена, бизнесу следует воспользоваться ею как можно лучше. Это требует такого метода расстановки приоритетов, при котором коммерческая ценность будет максимальной, а риски и расходы – минимальными. Наиболее желательна такая схема приоритетов, которая оптимизирует производительность бизнеса (или его технологического подразделения).
В области разработки программ и управления проектами схемы расстановки приоритетов развиваются с начала появления программных проектов – уже примерно 50 лет. Большинство схем просты. Например, они классифицируют приоритеты как высокие, средние и низкие. Однако для бизнеса это не имеет значения. Несколько более сложные схемы стали использоваться после появления agile-методов разработки ПО – это, например, MoSCoW (Must have – «необходимо»; Should have – «стоило бы»; Could have – «может быть»; Won’t have – «не нужно»). Другие методы, например разработка на основе функционала, пользовались упрощенной и модифицированной техникой анализа Кано, популярной среди японских компаний. Кто-то продолжал защищать строгий нумерованный порядок (1, 2, 3, 4…) на основе коммерческой ценности или технического риска. Однако эта схема часто вызывает конфликт между элементами высокого риска, которые должны оказаться в первом ряду, и элементами высокой коммерческой ценности, которые тоже должны оказаться в первом ряду.
У всех этих схем есть один основной недостаток: в ответ на изменения, вызванные рынком или развитием событий, необходимо расставлять приоритеты заново. Представьте, что у вас есть бэклог с 400 требованиями по приоритетам, расставленными в порядке от 1 до 400, и вы выпускаете пошаговые релизы, используя один из agile-методов разработки с ежемесячными итерациями. Каждый месяц вам придется заново расставлять приоритеты в бэклоге едва ли не для всех 400 элементов.
Опыт показывает, что расстановка приоритетов руководителями отделов сулит проблемы. Причины очень просты: на рынке и в деловой среде слишком много неопределенности. Трудно предсказать будущую относительную ценность элементов; непонятно, когда понадобится тот или иной элемент и какой из них важнее сделать прежде всего. Если вы просите руководителя расставить приоритеты в бэклоге технологических системных требований, то вы тем самым задаете ему слишком много вопросов, ответы на которые к тому же непонятны. А когда люди не уверены в ответе, они обычно реагируют нервно: могут действовать слишком медленно, отказаться от сотрудничества, чувствовать себя некомфортно. Они могут впасть в ступор, постоянно менять мнение, нарушать планы проекта и попусту тратить время команды, реагируя на изменения внесением поправок в ходе работ.
Необходима такая схема расстановки приоритетов, которая позволяет максимально откладывать принятие конкретных обязательств и задает простые вопросы, на которые легко ответить. Канбан делает это, предлагая руководителям отделов заполнить пустые места в очереди, твердо гарантируя время выполнения и приводя показатель доли заданий, выполненных в срок.
У нас уже есть шесть благородных и полезных целей канбан-системы. Во многих случаях этого достаточно. Однако я вместе с другими ранними последователями Канбана выяснил, что возможны и желательны две другие, еще более благородные цели.
Цель 7. Обеспечение прозрачности дизайна и работы системы
Когда я впервые начал использовать канбан-систему, я верил в необходимость прозрачности незавершенных процессов, пропускной способности и качества, поскольку понимал, что это создает доверие клиентов и руководства. Я обеспечивал прозрачность, демонстрируя, где именно в системе находится запрос, когда он может быть выполнен и каково его качество. Прозрачности добивались и в отношении производительности команды. Мне хотелось внушить клиентам уверенность в том, что мы работаем над их запросом, и объяснить, когда он может быть выполнен. К тому же я хотел разъяснить руководству наши методы работы и вызвать доверие к себе как к менеджеру и к моей команде как к крепкой профессиональной группе разработчиков.
Эта прозрачность дала и иной, неожиданный эффект. Прозрачность в рабочих запросах и производительности – это прекрасно, но когда она распространяется и на процесс работы, это еще лучше. Она позволяет всем участникам процесса видеть результаты их действий или бездействия. В итоге люди становятся более рассудительными, готовы менять свое поведение, чтобы повысить производительность системы в целом и сотрудничать над требуемыми изменениями в правилах, персонале, уровнях кадрового состава и т. д.
Цель 8. Создание процесса, способствующего возникновению организации высокой степени зрелости
Для большинства высокопоставленных руководителей бизнеса, к которым я сейчас обращаюсь, эта цель буквально воплощает их пожелания и ожидания в отношении организаций, связанных с разработкой технологий. Прежде всего они нуждаются в предсказуемости в сочетании с деловой гибкостью и хорошим управлением.
Руководители бизнеса хотят давать обещания своим коллегам по совету директоров и по исполнительному комитету, акционерам, клиентам, рынку в целом – и выполнять их. Успех на уровне высшего руководства во многом зависит от доверия, которое, в свою очередь, требует надежности. Высшие руководители стремятся минимизировать риски, чтобы выдавать предсказуемые результаты.
Вдобавок они понимают, что в современном мире изменения происходят все быстрее. Появляются новые технологии, глобализация меняет рынки труда и потребительские рынки, вызывая большие колебания спроса (на продукт) и предложения (рабочей силы). Изменяются экономические условия, конкуренты модифицируют стратегию и предложения на рынке. Вкусы рынка становятся иными, поскольку население стареет, становится богаче и приближается к среднему классу. Поэтому лидеры бизнеса хотят, чтобы он был гибким, стремятся быстро реагировать на перемены и пользоваться всеми возможностями.
И прежде всего они хотят того, что лежит в основе всего этого, – хорошего управления. Они желают демонстрировать, что средства инвесторов тратятся с умом, расходы находятся под контролем и риски, которым подвергаются инвестиционные портфели, распределяются оптимально.
Поэтому им необходимо, чтобы их организации, занимающиеся разработкой технологий, имели большую прозрачность. Они хотят понимать истинное состояние проектов и при необходимости вмешиваться, чтобы помочь. Хотят, чтобы организация управлялась более объективно и факты сопровождались данными, показателями и индикаторами, а не случайными историями и субъективными оценками.
Все эти желания соответствуют организации, действующей на том уровне, который определяется институтом SEI как четвертый или пятый уровень зрелости по пятибалльной шкале модели CMMI. Четвертый и пятый уровни этой шкалы считаются уровнями высокой зрелости. Ее достигли очень немногие независимо от того, подавали ли они заявку на формальную сертификацию SCAMPI[10]. Поэтому неудивительно, что большинство руководителей крупных технологических компаний недовольны результатами своих команд разработчиков, потому что уровень зрелости организации часто не совпадает с желаемым.
Знайте цели и формулируйте преимущества
Итак, у нас есть набор целей для канбан-системы. Нужно знать эти цели и уметь формулировать их, потому что, прежде чем начать работу с Канбаном, следует достичь соглашения с заинтересованными лицами в цепочке создания ценности. Канбан изменит тип взаимодействия с другими группами в нашей компании. Если от заинтересованных лиц требуется согласиться на предлагаемые изменения, то нам нужно уметь сформулировать преимущества, которые их ожидают.
Ниже представлено пошаговое руководство по внедрению канбан-системы для одной цепочки создания ценности в организации. Оно разработано на основе реального опыта и прошло проверку у нескольких ранних последователей Канбана – как тех, кто следовал этим шагам и преуспел, так и тех, кто осознал, что их недостаточную удачу можно было предотвратить, если бы они имели возможность воспользоваться этим руководством.
Руководство призвано, в частности, привлечь внимание к различиям между Канбаном и более ранними методами гибкой разработки. Канбан с самого начала требует вовлеченности в процесс всех участников цепочки создания ценности и менеджеров среднего и даже высшего звена. Принятие Канбана как инициативы снизу, если предварительно не была достигнута договоренность с менеджерами, напрямую не относящимися к данной команде, принесет ограниченные результаты и не даст бизнесу существенных выгод.
Некоторые считают, что такое количество шагов выглядит устрашающе и что если бы они начали с чтения руководства, то отказались бы от внедрения Канбана. Надеюсь, что в книге даны подробные объяснения этих шагов и полезные советы, выработанные на основе опыта именно в этой области.
Шаги для начала действий
1. Определите набор целей внедрения Канбана.
2. Составьте схему цепочки создания ценности (последовательности всех действий, которые предпринимает организация по разработке, чтобы удовлетворить запрос клиента или заинтересованного лица) (см. главу 6).
3. Определите точку входа, которую вы хотите сделать контрольной. Определите действия, предшествующие этой точке, и заинтересованных лиц выше по цепочке создания ценности (см. главу 6). Например, если вы хотите контролировать требования, поступающие к дизайнерам перед выпуском, то такими заинтересованными лицами могут быть менеджеры продукта.
4. Определите точку выхода, после которой вы не претендуете на контроль. Определите действия, следующие за этой точкой, и заинтересованных лиц ниже по цепочке создания ценности (см. главу 6). Возможно, вам не обязательно контролировать итоговую доставку продукта.
5. Определите типы рабочих единиц на основе типов рабочих запросов, поступающих от заинтересованных лиц выше по цепочке (см. главу 6). Есть ли разделение на типы, чувствительные и нечувствительные ко времени выполнения? Если да, то задумайтесь о введении классов обслуживания (см. главу 11).
6. Проанализируйте спрос на каждый тип рабочих единиц. Понаблюдайте за темпами их поступления и вариативностью. Чем обусловлена вариативность? Возможно, она сезонная или приурочена к каким-то событиям? Какие риски связаны со спросом подобного типа? Должна ли система справляться со средним или пиковым спросом? Насколько в этом случае важно не допустить опоздания работы или ее недостаточной надежности? Создайте профиль риска для такого типа спроса (см. главу 6).
7. Назначьте встречу с коллегами выше и ниже по цепочке создания ценности – это может быть одно большое или много мелких совещаний (подробнее – ниже в этой главе):
а) – обсудите правила, касающиеся мощности того элемента цепочки создания ценности, который вы хотите контролировать, и договоритесь о WIP-лимите (см. главу 10);
б) – обсудите и установите с партнерами выше по цепочке создания ценности механизм координации входа – например, регулярное совещание по расстановке приоритетов (см. главу 9);
в) – обсудите и установите с партнерами ниже по цепочке создания ценности механизм координации релиза – например, регулярный релиз ПО (см. главу 8);
г) – возможно, потребуется ввести разные классы обслуживания для рабочих запросов (см. главу 11);
д) – договоритесь о целевом времени выполнения для каждого класса обслуживания рабочих единиц. Такая договоренность известна как соглашение об уровне обслуживания, и о ней идет речь в главе 11.
8. Подготовьте доску (стену) карточек для отслеживания работ в цепочке создания ценности, которую вы контролируете (см. главу 6 и главу 7).
9. При желании заведите электронную систему для отслеживания и подготовки отчетов о ней же (см. главу 6 и главу 7).
10. Договоритесь с командой о проведении ежедневного стендап-совещания возле доски, пригласите на них коллег выше и ниже по цепочке создания ценности, но не поощряйте их вмешательства (см. главу 7).
11. Договоритесь о регулярном проведении ретроспективного анализа производственного процесса, пригласите на него коллег выше и ниже по цепочке создания ценности, но не поощряйте их вмешательства (см. главу 14).
12. Обучите команду работе с доской, WIP-лимитами и вытягивающей системой. Это весь набор изменений, который их коснется. Должностные обязанности останутся прежними. Действия – тоже, как и управление, и объекты. Процесс для них также не изменится, за исключением того, что им придется соблюдать WIP-лимиты и вытягивать работу на основании классов обслуживания, а не получать ее сверху.
Канбан предполагает иной тип сделки
Канбан требует от команды разработчиков заключить с деловыми партнерами сделку иного типа. Чтобы понять это, нужно сначала рассмотреть типичные и широко используемые альтернативы.
В традиционном управлении проектами обязательства принимаются на основании трех сдерживающих факторов: объема, расписания и бюджета. После определенного этапа оценки и планирования выделяется бюджет на привлечение ресурсов, затем определяется объем требований и расписание.
Agile-управление проектами, однако, не дает таких смелых и четких обещаний. Дата окончания работы – примерно через несколько месяцев – может быть определена, но общий объем никогда не устанавливается. Он может определяться приблизительно, но детали никогда не фиксируются.
Нередко заранее оговаривают бюджет (среднемесячные зарплаты), чтобы привлечь к работе фиксированные ресурсы. Agile-команда действует итеративно, предоставляя обновления функциональности за время коротких, ограниченных по времени итераций (или спринтов). Обычно они занимают от одной до четырех недель. В начале каждой из этих итераций проводят оценку и планирование, после чего берут обязательства. Часто обозначают и объем, но если команда не может выполнить обязательство в срок, то жертвуют именно объемом, а дата окончания остается неизменной. На итерационном уровне гибкая разработка похожа на традиционное управление проектами. Ключевая разница состоит в договоренности о том, что в случае форс-мажорных обстоятельств объем будет сокращен. Менеджер проекта традиционного типа имеет в этом случае возможность выбрать, чем пожертвовать – объемом или расписанием, добавить ресурсы или принять смешанное решение.
Канбан предполагает иной тип сделки. Он вообще не берет обязательств, основанных на чем-то неопределенном. Типичный вариант Канбана предполагает соглашение о регулярных релизах высококачественного работающего ПО – например, каждые две недели. Внешним заинтересованным лицам предлагается полная прозрачность рабочего процесса и, при желании, визуализация ежедневного прогресса. Кроме того, они получают возможность выбирать самые важные новые элементы для разработки.
Частота процесса выбора обычно превышает частоту выхода релизов – как правило, раз в неделю. Хотя некоторые команды достигли уровня, когда выбор производится по запросу или очень часто (ежедневно либо раз в неделю).
Команда обещает сделать все, что может, и выпустить как можно больше работающих программ, а также постоянно прилагать усилия по совершенствованию количества, частоты и времени выполнения. Помимо того, что такая команда дает бизнесу невероятную гибкость, поскольку есть возможность выбирать элементы для разработки в очень небольших количествах, дополнительная гибкость достигается в расстановке приоритетов посредством введения нескольких классов обслуживания. Эта идея подробно описана в главе 11.
Канбан не обещает выполнить определенный объем работы к назначенному дню. Он дает обязательства в соответствии с соглашениями об уровне обслуживания для каждого класса обслуживания в сочетании с обязательствами по выпуску надежных регулярных релизов, прозрачности, гибкости работы и расстановки приоритетов, а также по непрерывному совершенствованию качества, пропускной способности, частоты релизов и времени выполнения. Канбан, кроме того, дает обязательства по уровню обслуживания, минимизируя риски по сборке большого количества элементов. Тщательно продуманная канбан-система дает обещания только относительно того, что действительно имеет ценность для клиентов. В свою очередь, команда запрашивает долгосрочные обязательства от клиентов и партнеров по цепочке создания ценности: сохранять постоянные деловые отношения, при которых команда разработки неуклонно стремится повысить уровень обслуживания путем улучшения качества, пропускной способности, частоты релизов и времени выполнения. Поскольку клиент соглашается на постоянное долгосрочное сотрудничество и предпочитает оценивать общий уровень обслуживания, а не заставлять команду сосредоточиваться на четкости реализации конкретного элемента, система может работать.
Традиционный подход к принятию обязательств по масштабу, расписанию и бюджету свидетельствует о разовом характере соглашения. Он предполагает, что дальнейших отношений не будет, и показывает низкий уровень доверия.
Канбан-подход основан на предположении, что команда будет единой и продолжит поддерживать отношения с клиентом в течение долгого времени, а также на повторяемости заказов. Канбан требует высокого уровня доверия между командой разработчиков и партнерами по цепочке создания ценности. Считается, что все верят в пользу формирования долгосрочного партнерства, которое должно обладать высокой эффективностью.
Обязательства в Канбане предполагают, что все в цепочке создания ценности заботятся о производительности системы: количестве и качестве выпускаемых программ, частоте релизов и времени их выполнения. Канбан просит партнеров по цепочке создания ценности придерживаться концепции подлинной деловой гибкости и соглашаться на совместную работу по ее достижению. Это существенно отличает Канбан от более ранних agile-подходов к разработке ПО.
Установив изначально характерные для Канбана отношения с партнерами выше и ниже по цепочке создания ценности, вы берете общее обязательство по производительности на системном уровне и закладываете основы культуры непрерывного совершенствования.
Переговоры по внедрению канбана
Критический этап внедрения Канбана – успешные переговоры по достижению этого иного типа сделки. Во время таких переговоров устанавливаются правила совместной игры по разработке ПО, которых мы и собираемся придерживаться. Жизненно необходимо, чтобы партнеры по цепочке создания ценности принимали участие в их установлении, поскольку им нужно будет следовать в дальнейшем, чтобы условия были соблюдены, а исход соответствовал целям и намерениям.
Седьмой из двенадцати шагов в процессе внедрения Канбана предполагает встречу с партнерами выше (отделы маркетинга и бизнеса, откуда поступают требования) и ниже (отделы системных операций и ввода в эксплуатацию или организации по продажам и доставке) по цепочке создания ценности. Нам нужно обсудить с ними правила относительно WIP, расстановки приоритетов, релизов, классов обслуживания и времени выполнения. Набор принципов, который мы согласуем с этими партнерами, определит правила совместной игры по разработке программного обеспечения. Трудно обсуждать каждый из этих пяти элементов изолированно друг от друга, поскольку они взаимосвязаны. Поэтому, хотя мы понимаем, что нужно задать правила относительно каждого из пяти элементов, переговоры будут идти по кругу, так как участники станут постоянно предлагать новые варианты. Например, если запланированное время выполнения неприемлемо, то, возможно, удастся ввести другой класс обслуживания, который будет предлагать меньшее время выполнения для определенных типов рабочих запросов. Пять элементов – WIP, расстановка приоритетов, релизы, классы обслуживания и время выполнения – это своего рода рычаги, за которые можно дергать, чтобы повлиять на производительность системы. Суть в том, что нужно знать, как именно тянуть за эти рычаги, и обсуждать варианты, чтобы прийти к соглашению, которое будет эффективно работать.
WIP-лимиты
В Дании я познакомился с менеджером по разработке, который рассказал, что у его сотрудников в среднем одновременно находятся в работе семь с половиной задач. Это чересчур много. Сомневаюсь, чтобы кто-то приветствовал подобную многозадачность. На его месте я бы использовал этот факт для переговоров и начал бы с заявления, что в среднем члены команды вынуждены параллельно выполнять семь с половиной заданий. Я указал бы на то, какое влияние это оказывает на время выполнения и предсказуемость, и пригласил бы коллег и других заинтересованных лиц подумать над тем, каково оптимальное число заданий. Некоторые, возможно, предложили бы одно задание на человека. Вероятно, так и есть, но это слишком агрессивный выбор. Что если задание будет заблокировано? Разве не требуется возможность переключиться на альтернативу? Не исключено, что кто-то другой высказался бы за два задания одновременно или в пользу трех. Скорее всего, будут предлагаться именно варианты от одного до трех. Если в команде десять разработчиков и вы сможете договориться о двух заданиях, одновременно выполняемых одним человеком, то получаете в итоге WIP-лимит на команду, равный 20.
Есть и другие варианты. Допустим, вы хотите, чтобы в команде работали попарно. А два задания на пару при общей численности десять программистов соответствуют WIP-лимиту, равному 10. Возможно также, что вы используете метод более тесного сотрудничества – например, разработку по функционалу или функциональные бригады. В этом случае небольшие группы по пять-шесть человек работают над одной MMF, пользовательской историей или одним пакетом функций (как в FDD), то есть над тем, что также называется рабочим пакетом главного программиста (CPWP – Chief Programmer Work Package). Команда функциональных разработчиков может договориться и ограничить число CPWP тремя на команду из десяти разработчиков. (CPWP обычно оптимизируется для эффективности разработки на основании архитектурного анализа домена и содержит от 5 до 15 очень детализированных функций.)
Итак, мы поговорили с заинтересованными лицами о WIP-лимите. Мы обсудили, какой должна быть разумная многозадачность по отношению к предсказуемости релизов и ожидаемому времени выполнения. Достижение договоренности с партнерами о WIP-лимитах крайне необходимо. Хотя WIP-лимиты можно объявить и в одностороннем порядке, привлечение других заинтересованных лиц и достижение консенсуса устанавливает общие обязательства – теперь все должны придерживаться одинаковых правил. В будущем такие обязательства могут стать бесценными. Настанет день, когда партнеры попросят нас взять дополнительную работу. Они обязательно так сделают, потому что им покажется это важным и ценным. Они будут руководствоваться самыми благими намерениями. Но мы сможем ответить им, что у нас есть заранее оговоренный WIP-лимит и его надо уважать. Система к тому времени, вероятно, будет полной, и согласие взять дополнительный элемент будет означать превышение WIP-лимита. Поэтому наш ответ должен звучать так: «Мы охотно взяли бы новую работу, потому что понимаем, как она важна для вас. Но вы ведь знаете, что у нас есть заранее оговоренный WIP-лимит. Вы участвовали в этом решении и понимаете, почему мы его приняли. Мы хотим сохранить предсказуемость и своевременность обработки запросов. Чтобы взяться за ваш запрос, нам придется отложить в сторону другие. Какой из элементов, которые сейчас находятся в работе, мы, по-вашему, должны отложить, чтобы взяться за новый?»
Не включи мы партнеров в процесс принятия решения по WIP-лимиту, подобный ответ был бы невозможен. Они продолжали бы нас уговаривать. После этого вытягивающая система со всеми WIP-лимитами распалась бы и вся организация повернула бы обратно к выталкивающей системе планового производства.
Чтобы успешно взаимодействовать в Канбан-разработке ПО, правила игры должны быть установлены общим решением всех заинтересованных лиц.
Расстановка приоритетов
Мы хотим договориться и о механизме пополнения очереди. Обычно это достигается решением о проведении регулярного совещания по пополнению системы и определением механизма выбора новых элементов. Разговор можно начать так: «Если нам нужно будет спросить вас: “Какие два элемента вы хотите видеть реализованными через сорок два дня?” – то как часто вы сможете встречаться с нами, чтобы отвечать на этот вопрос? Надеемся, что такие совещания будут занимать не более получаса».
Поскольку вы предлагаете очень конкретную тему, задаете прямой вопрос и обещаете, что время совещания будет минимальным, обычно партнеры выше по цепочке быстро соглашаются на сотрудничество. Нередко удается договориться о еженедельных встречах. Более частые совещания характерны для отраслей с ускоренным темпом деятельности – например, массмедиа, где циклы релизов очень частые.
Релиз
Затем нужно договориться примерно о том же с партнерами ниже по цепочке. То, какая именно каденция релизов является целесообразной, очень зависит от отрасли или ситуации. Если речь идет о веб-программах, то их нужно поставлять на группу серверов. Реализация такой программы включает копирование файлов и, возможно, обновление схемы баз данных с последующим переносом данных с одной версии схемы на другую. Для переноса данных, вероятно, понадобится собственный код, а его выполнение может занять некоторое время. Чтобы вычислить общее время реализации, нужно учесть количество серверов и файлов для копирования, время на безопасное закрытие систем и их перезагрузку, на перенос данных и т. д. Иногда это занимает несколько минут, а порой – несколько часов или дней. В других отраслях нередко приходится создавать физические носители – DVD, упаковывать их в коробки и поставлять по физическим каналам, направляя распространителям, дилерам, розничным операторам или уже существующим корпоративным клиентам. Могут быть задействованы и другие виды деятельности – например, печать бумажных инструкций или обучение сотрудников отделов продаж и техподдержки. Иногда для этих людей нужно разрабатывать и отдельную программу обучения.
Например, в 2012 году я принимал участие в релизе первого из обновлений мобильной телефонной сети Sprint PCS. Это обновление на пути к технологии 3G называлось lxRTT. На рынок оно вышло как PCS Vision и включало выпуск примерно 15 новых аппаратов с 16 новыми функциями, которые использовали высокоскоростные возможности передачи данных новой сети. У Sprint в США была розничная сеть, где работали 17 тысяч человек. Примерно столько же было в кол-центрах, которые занимались технической поддержкой пользователей. И участники розничного канала продаж, и сотрудники техподдержки должны были пройти обучение, чтобы запуск нового сервиса стал эффективнее. Я в шутку предположил, что оптимальнее всего закрыть все на пару дней, вывезти всех на ночь в Канзас-Сити и арендовать стадион команды «Канзас-Сити Чифс», на котором и провести двухчасовую презентацию в PowerPoint на больших экранах в обоих концах стадиона. Возможно, это был самый эффективный, но, конечно, неприемлемый способ. Вряд ли клиенты одобрили бы 48-часовое отсутствие поддержки на время обучения операторов технологии следующего поколения. А двухдневное отсутствие продаж по розничному каналу явно не помогло бы годовому бюджету.
Была разработана программа обучения, проведена подготовка инструкторов. Создали также программу обучения региональных сотрудников розничных продаж и работников кол-центров. Инструкторы обучали их в течение шести недель в составе небольших групп и в нерабочее время. Расходы на это были огромными: во-первых, шесть недель – это много, а наиболее эффективно пользоваться полученными знаниями сотрудники могли тоже в течение примерно шести недель. Если бы мы не уложились в окно запуска нового сервиса, то обучение пришлось бы повторить, а запуск отложить как минимум еще на шесть недель.
Если сфера вашей деятельности – что-то вроде телефонных сетей, то вам известно, что каденция релизов в ней не очень частая. Когда операционные расходы на релиз включают шесть недель обучения, релизы с интервалом чаще чем в год противопоказаны.
Желаемый результат – это самая частая каденция релиза из осмысленных. Поэтому начните с вопроса: «Если мы предлагаем вам высококачественный код с минимумом ошибок, который выходит в адекватном виде и при этом обеспечивается прозрачность относительно его сложности, а также надежность поступления, то как часто вы сможете выводить его на рынок с точки зрения здравого смысла?» Это вызовет обсуждение использованных вами определений, и понадобится еще раз убеждать партнеров. Однако следует стремиться к результату, который приводит к наибольшей деловой гибкости и не создает излишнюю нагрузку ни на одну часть системы.
Время выполнения и классы обслуживания
Когда разговор заходит о времени выполнения, полезно привести накопленные данные по предыдущей производительности. В идеале хорошо иметь данные по времени выполнения и инженерному времени. В примере с Microsoft (глава 4) было известно, что время выполнения составляет примерно 125 дней на устранение ошибок первой степени срочности и 155 дней – на ошибки остальных степеней. Главное, что мы можем отсюда почерпнуть, – это наличие двух классов обслуживания. Ошибки первой степени в какой-то форме обрабатывались раньше. Возможно, формальных правил не было, но так уж выходило, что ошибки первой степени устранялись быстрее.
Зная это, мы можем предложить два разных класса обслуживания с самого начала. Вынесем на рассмотрение внешних заинтересованных лиц вопрос о назначении двух классов обслуживания и принятии отдельного целевого времени выполнения для каждого из них.
Также из предыдущих данных известно, что в среднем инженерная работа занимала 11 дней, а при самом высоком качестве работ – 15. Поэтому мы решили предложить 25-дневное время выполнения, считая с момента выбора элемента из входящей очереди. Больше никаких научных данных не потребовалось. А теперь представьте психологический эффект от этого: в бизнесе привыкли, что работа занимает четыре-пять месяцев, а мы предлагали 25 дней. Разница в том, что мы говорили о 25 днях как о времени выполнения, не учитывая ожидание в очереди, а 155 дней включали и его. Тем не менее это выглядело фантастическим улучшением. Неудивительно, что представители бизнеса согласились.
Есть и другие варианты. Можно взять предыдущие данные по инженерной работе и разместить их на графике статистического контроля процессов. Это даст вам верхний контрольный лимит (или 3-Sigma). Возможно, вы захотите немного буферизовать этот верхний лимит, чтобы нейтрализовать внешнюю вариативность. Но если вы так поступаете, нужно честно признаться в этом партнерам и показать, что вы провели соответствующие вычисления.
Еще одна альтернатива – спросить, в каком уровне ответной реакции нуждается бизнес. Лучше всего это сделать в контексте задания классов обслуживания. Например, если вам говорят: «Нам нужен релиз через три дня», спросите: «Все ли элементы нужно реализовать за три дня?» Чаще всего ответ будет отрицательным. Это даст возможность запросить определение типов запросов, которые должны быть реализованы в течение трех дней. После этого можно создать класс обслуживания для данного типа заданий. Повторите процесс для оставшихся заданий.
В итоге должно получиться расслоение рабочих запросов на несколько уровней, которым и будут соответствовать разные классы обслуживания. Не исключено, что на каждом уровне встретятся задания, которые потребуют примерно одинаковых издержек из-за отсрочки. Подробнее создание классов обслуживания и идея функций издержек из-за отсрочки описаны в главе 11.
Целевое время выполнения, которое вы устанавливаете для каждого класса обслуживания, должно быть именно целью, а не обещанием. Вы обещаете сделать все от вас зависящее, чтобы уложиться в целевое время и сообщить о выполнении в срок, установленный в соглашении об уровне обслуживания для каждого класса обслуживания. В некоторых ситуациях, чтобы договориться о том, что время выполнения в соглашении об уровне обслуживания – это цель, а не обязательство, может не хватить доверия. Если приходится согласиться с тем, что время выполнения в соглашении об уровне обслуживания считается обязательным, следует ради безопасности установить буфер. Это укажет на то, что низкий уровень доверия выливается в прямые экономические расходы.
Выходные критерии для обсуждений с партнерами таковы: вы добились консенсуса по WIP-лимитам по всей цепочке создания ценности, достигнуто соглашение о координации расстановки приоритетов и используемом для нее методе и такое же соглашение о координации и методах сдачи работы, имеется определение набора соглашений об уровне обслуживания, включающее целевое время выполнения для каждого класса обслуживания.
Выводы
• Можно выделить как минимум восемь целей внедрения Канбана в вашей организации.
• Улучшайте производительность, внося в процесс усовершенствования, которые будут встречены с минимальным сопротивлением.
• Сдавайте высококачественную работу.
• Время выполнения должно оставаться предсказуемым благодаря контролю числа незавершенных заданий.
• Создайте оптимальные условия для членов команды, улучшив их баланс работы и жизни.
• Внесите в систему резервы, сбалансировав нагрузку и пропускную способность.
• Обеспечьте простой механизм расстановки приоритетов, при котором обязательства откладываются, а варианты долго остаются возможными.
• Обеспечьте прозрачную схему, чтобы были видны возможности для роста. Тогда будут возможными сдвиги в сторону культуры большего сотрудничества, которые приведут к непрерывному совершенствованию.
• Боритесь за процесс, дающий предсказуемые результаты, деловую гибкость, хорошее управление и переход к тому, что Институт по разработке программного обеспечения называет организацией высокой зрелости.
• Важно определить цели и уметь формулировать преимущества введения Канбана, чтобы достичь консенсусного соглашения с другими заинтересованными лицами.
• Следуйте пошаговому 12-этапному руководству по введению Канбан-процесса.
• Канбан предполагает иной тип сделки с внешними заинтересованными лицами и владельцами бизнеса. Это сделка, основанная на долгосрочных отношениях и обязательствах по производительности на системном уровне.
• Привлечение внешних заинтересованных лиц к договору о базовых элементах канбан-системы позволяет заручиться их сотрудничеством.
• Основные правила, касающиеся WIP-лимитов, целевого времени выполнения, классов обслуживания, расстановки приоритетов и релизов, – это правила совместной игры по разработке программного обеспечения.
• Привлечение внешних заинтересованных лиц к сотрудничеству позволит рассчитывать на их помощь позже, когда система подвергнется серьезным нагрузкам.
Часть IV Совершенствование
Глава 16 Три типа возможностей для совершенствования
Главы 6–15 рассказывают о том, как создать канбан-систему и поддерживать ее работу и как принять на вооружение Канбан-подход к управлению изменениями и совершенствованию. Оставшаяся часть этой книги описывает, как обнаружить возможности для совершенствования, что с ними делать и как выбрать между разными возможностями.
В главе 2 приводятся пять ключевых практик, которыми должна обладать организация, использующая Канбан. Пятая по счету связана с использованием моделей для определения, оценки и стимулирования возможностей по совершенствованию. Вариантов много. В этой главе речь пойдет о трех распространенных моделях и некоторых их разновидностях: о теории ограничения систем и ее пяти направляющих, об идее бережливого мышления (Lean Thinking), которая определяет ненужные действия как экономические затраты, а также о некоторых вариантах, сводящихся к определению и снижению вариативности. Возможны и другие модели. Уже проходят эксперименты с такими моделями, как теория реальных опционов и управление рисками. Ниже приводятся примеры, которые можно использовать как точку отсчета. Хотелось бы, чтобы вы взяли эти методы на вооружение, поскольку они действительно работают, а впоследствии расширяли горизонты знаний и изучали другие модели, позволяющие командам создавать усовершенствования.
Бутылочные горлышки, устранение потерь и снижение вариативности
Каждая из этих моделей совершенствования подробно исследовалась и разрабатывалась в соответствующей области знаний. В каждой из них присутствует свой стиль представлений о теории непрерывного совершенствования. В Канбане я постарался синтезировать все три школы и дать обзор того, как выявлять возможности совершенствования и реализовывать усовершенствования при внедрении каждой модели.
В каждой из трех школ, описанных выше, есть группа лидеров, конференции, собственный набор знаний и опыта, группа последователей. Любая компания может влиться в одну или сразу в несколько таких школ. Преимущество в данном случае – это умение показать, как Канбан-метод может открыть возможности совершенствования в любимом стиле вашей организации. Широкий набор парадигм для улучшения и инструментов, из которых можно выбрать, должен обеспечить высокий уровень гибкости при изменениях. Те, кто хорошо знаком с методологиями непрерывного совершенствования, могут пролистать эти страницы и перейти сразу к главе 17. А всем, кому интересен анализ доступных методов, а также сведения из литературы и истории, оставшаяся часть главы будет полезна.
Теория ограничения
Теория ограничения была разработана Элияху Голдраттом и опубликована впервые в уже упоминавшемся бизнес-романе «Цель» в 1984 году. За последние 25 лет вышло несколько редакций «Цели», в последних из которых была более четко обрисована теоретическая структура, известная как «пять направляющих шагов».
Пять направляющих шагов – основа непрерывного совершенствования в теории ограничений. Это так называемый процесс непрерывного совершенствования (POOGI, Process Of OnGoing Improvement). Теория ограничений (или TOC) вообще полна аббревиатур. Как ни странно, пять направляющих шагов – исключение. Эти названия не сокращаются до ПНШ.
В 1990-е годы в рамках теории ограничений разработан метод анализа глубинных причин и управления изменениями, известный как мыслительные процессы (он же TP, Thinking Processes). Причина в осознании консультантами, придерживающимися ТОС, того факта, что их ограниченный успех в работе с клиентами вызван сопротивлением изменениям и недостаточно умелым управлением ими.
Казалось, что пять направляющих шагов успешно работают только с проблемами потока, а многое из того, что возникает на рабочем месте, не слишком вписывается в эту парадигму. Так возникли TP. Профессиональная подготовка и программа обучения для консультантов по ТОС сместилась от использования пяти направляющих шагов и применения этой концепции (например, «барабан-буфер-канат») к использованию ТР. Поэтому многие члены сообщества, говоря о ТОС, имеют в виду ТР, а не пять направляющих шагов. Бывая на конференциях по ТОС, могу с уверенностью сказать, что использование пяти направляющих шагов кажется сейчас своего рода утраченным искусством.
Сообщество ТОС, насколько я могу судить, склоняется к принятию существующих парадигм и не ставит их под сомнение. Поэтому решение ТОС для управления проектами – критическая цепь – развилось из парадигмы тройного ограничения (объем, бюджет и сроки) и модели графика зависимостей для организации задач в проекте. Эта модель не подверглась никаким сомнениям, пока я не опубликовал свою первую книгу Agile Management for Software Engineering, где высказал критику в адрес парадигмы управления проектами и предположил, что лучше моделировать проекты как цепочку создания ценности и проблему потока, к которым применять впоследствии пять направляющих шагов. Благодаря этому стало возможно использовать все знания в области бережливого управления, основанные на понятии потока, и совместить их с представлением о бутылочных горлышках, характерном для пяти направляющих шагов. Синтез ТОС с бережливым управлением привел к улучшению производительности проектов и всей организации и заложил основания для зарождения Канбана.
Я утверждал, что любой процесс или рабочий поток, предполагающий разделение труда, можно определить как цепочку создания ценности, а любую цепочку создания ценности – как имеющую поток. Бережливое управление и производственная система Toyota по сути выстроены вокруг этого принципа. Если любая цепочка создания ценности обладает потоком, то к ней можно применить пять направляющих шагов. Таким образом, пять направляющих шагов – это вполне удовлетворительный POOGI, и TP не требуется, если не использовать его в качестве инструмента управления изменениями. У меня отношения с TP не сложились. Как видно из этой книги, управление изменениями я предпочитаю осуществлять при помощи Канбана.
Пять направляющих шагов
Пять направляющих шагов – это простая формула процесса непрерывного совершенствования. Вот они.
1. Определить ограничение.
2. Решить, как максимально использовать это ограничение системы.
3. Подчинить все остальные составляющие системы решению, принятому на шаге 2.
4. Ликвидировать ограничение.
5. Избегать инерции, определить следующее ограничение и вернуться к шагу 2.
Шаг 1 предлагает найти бутылочное горлышко в цепочке создания ценности.
Шаг 2 призывает определить потенциальную пропускную способность этого бутылочного горлышка и сравнить ее с тем, что происходит на самом деле. Как вы увидите, бутылочное горлышко редко работает на полную мощность (можно даже сказать, что этого никогда не происходит). Поэтому задайтесь вопросами: «Как максимально использовать бутылочное горлышко? Что нужно изменить, чтобы реализовать его потенциал?» Это соответствует слову «решить» на шаге 2.
Шаг 3 предлагает внести все необходимые изменения, чтобы воплотить в жизнь идеи шага 2. Это может быть связано и с изменениями где-то в другом месте цепочки создания ценности, которые тоже служат тому, чтобы извлечь максимум из бутылочного горлышка. Действия, направленные на максимальное увеличение мощности бутылочных горлышек, и называются их использованием.
Шаг 4 предполагает, что, если бутылочное горлышко работает на всю мощь, но не обеспечивает достаточной пропускной способности, нужно, чтобы ее повысить, расширить ограничение. Шаг 4 предлагает внедрить улучшения для повышения мощности и пропускной способности, чтобы существующее бутылочное горлышко было ликвидировано, а ограничение системы переместилось куда-нибудь еще по цепочке создания ценности.
Шаг 5 требует от нас терпения: нужно дать изменениям время на стабилизацию и затем определить новое бутылочное горлышко в цепочке создания ценности и повторить процесс. В результате получается система непрерывного совершенствования, в которой пропускная способность постоянно возрастает.
Если правильно внедрить пять направляющих шагов, то организация сможет развить культуру непрерывного совершенствования
О том, как определять бутылочные горлышки и работать с ними при помощи пяти направляющих шагов, читайте в главе 17.
Бережливое управление, TPS и устранение потерь
Бережливое управление – концепция, появившаяся в начале 1990-х годов благодаря книге Джеймса Вумека, Дэниела Джонса и Дэниела Руса «Машина, которая изменила мир»[11], в которой описывались принципы работы производственной системы Toyota (TPS). Поначалу литература о бережливом управлении не смогла определить, что управление вариативностью является неотъемлемой частью TPS. Это стало известно благодаря системе глубинных знаний Деминга.
Также бережливое управление пало жертвой неверных интерпретаций и упрощенчества. Многие консультанты по бережливому управлению ухватились за идею устранения потерь и обучали бережливому управлению просто как средству избежать их. Получалось, что все рабочие действия делятся на создающие и не создающие ценность. Последние, влекущие за собой потери, подразделяются на необходимые и излишние. Излишние действия предлагалось исключить, а необходимые – сократить. Хотя такое использование бережливого управления для совершенствования вполне возможно, оно может привести к недополученной прибыли и оставляет в стороне идеи ценности, цепочки создания ценности и потока, характерные для бережливого управления.
Канбан позволяет реализовать все аспекты бережливого подхода и дает инструменты для оптимизации получаемой ценности, поскольку сосредоточивается не только на устранении потерь, но и на управлении потоком.
В главе 18 рассказывается о том, как определить ведущие к потерям действия и что с ними делать.
Система деминга и «шесть сигм»
Эдвардс Деминг считается одним из трех отцов-основателей движения по контролю качества в XX веке. Однако его вклад самый существенный.
Он внес усовершенствования в статистический контроль процессов (СКП) и разработал на его основе технику управления, которую назвал системой глубинных знаний. Его система призвана не позволять менеджерам принимать плохих решений, заменяя их лучшими решениями – основанными на статистике, объективными, часто противоречащими интуиции. Деминга вполне заслуженно называют едва ли не лучшим исследователем в области менеджмента в XX веке. Его работы привели к развитию науки о менеджменте из статистического контроля процесса и контроля качества.
Деминг оказал значительное влияние на японскую философию управления, и его работы по СКП и системе глубинных знаний стали краеугольным камнем TPS.
Хотя СКП взяли на вооружение многие Канбан-команды, отличающиеся высокой зрелостью (например, в инвестиционном банке BNP Paribas в Лондоне), его обсуждение выходит за рамки этой книги. Предполагаю рассмотреть его в моей следующей работе – о продвинутых Канбан-техниках.
Однако принципы понимания вариативности систем и рабочих заданий, лежащие в основе СКП, очень полезны. Предшественник Деминга Уолтер Шухарт разделил вариативность выполнения задач на две категории: случайные причины и выявляемые причины. Впоследствии Деминг переименовал эти категории в обычные причины и особые причины, признав во втором издании своей «Новой экономики», что сделал это «в основном по педагогическим соображениям». Никакого новшества с изменением терминов не связано. Понимание вариативности и ее влияния на производительность и развитие умения распределять вариативность по двум указанным категориям – это необходимые для менеджера навыки. Научиться предпринимать соответствующие управленческие действия на основании понимания типов вариативности необходимо для программы непрерывного совершенствования. И бережливое управление, и теория ограничений высоко ценят необходимость понимания вариативности для дальнейшего совершенствования, даже если оно проходит под лозунгами управления бутылочными горлышками или устранения потерь.
В главе 19 объясняется, как распознать обычные и особые причины вариативности, предлагаются советы по соответствующим управленческим действиям. Та же тематика присутствует в главе 20. В ней описано, как научиться такому управлению проблемами, которое реагирует на вариации, вызванные выявляемыми причинами, чтобы как можно быстрее устранить подобные проблемы, сохранить ход потока и оптимизировать создаваемые ценности. Заметим, что без познаний в области управления вариативностью и концентрации на борьбе с этими вариациями работа с потоком будет неэффективной. Бережливое управление без идей Деминга – это управление без понимания вариативности, а следовательно, и без концентрации на поддержке потока. Учитывая, что в ранней литературе по бережливому управлению отсутствовали понимание вариации и любые отсылки к системе глубинных знаний Деминга, легко понять, почему в привычку вошло отношение к бережливому управлению как к процессу устранения потерь.
Идеи Деминга глубоко укоренились в Японии: TPS использует систему глубинных знаний и СКП для выявления локальных возможностей для улучшения. В США на основе идей Деминга появилась еще одна концепция – «шесть сигм». Она зародилась в Motorola, но широкую известность приобрела благодаря компании General Electric, которой руководил Джек Уэлч.
Концепция шести сигм пользуется СКП для определения вариаций с обычными и особыми причинами. Затем она применяет процесс, подобный описанному Демингом, чтобы исключить вариации с особыми причинами на глубинном уровне и воспрепятствовать их повторному возникновению, а затем сократить число вариаций с обычными причинами, чтобы сделать процесс, рабочий поток или систему более предсказуемыми.
В отличие от TPS, основанной на инициативе снизу, при которой наделенные полномочиями сотрудники делают сотни и тысячи мелких улучшений в рамках культуры кайдзен, концепция шести сигм выросла в административно-управленческий метод, предполагающий меньше доверия и возможностей для улучшения. Он обычно внедряется на стратегическом уровне и применяется к конкретным независимым проектам. Руководитель проекта носит титул обладателя черного пояса и должен иметь многолетний опыт освоения этой методологии, благодаря чему и заслужил свой статус. Поскольку Канбан использует идеи Деминга и обеспечивает инструментарий и прозрачность, необходимые для рассмотрения вариативности и ее последствий, он может быть использован для запуска как программы усовершенствования, основанной на кайдзен, так и программы, использующей концепцию шести сигм.
Совмещение канбана с культурой вашей компании
Если ваша компания управляется в соответствии с концепцией шести сигм, Канбан поможет внедрить инициативы шести сигм в программы, системы, разработку продукта или IT-организацию. Если ваша компания относится к бережливым, то Канбан идеально в нее впишется. Он поможет развить бережливую инициативу для программ, систем, разработки продукта или IT-организации. Компаниям, использующим теорию ограничений систем, Канбан поможет начать программу управления ограничениями (устранения бутылочных горлышек) для систем, разработки продукта или IT-организации. Но, возможно, вам придется перестроить вытягивающую систему в виде системы «барабан-буфер-канат», а не в виде канбан-системы. Поскольку Канбан развился из варианта системы «барабан-буфер-канат», я уверен, что это сработает. Однако разъяснения, как смоделировать цепочку создания ценности и задать WIP-лимиты для системы «барабан-буфер-канат», выходят за рамки этой книги.
Выводы
• Канбан требует привлечения моделей для определения возможностей усовершенствования.
• Канбан поддерживает как минимум три типа методов непрерывного совершенствования: управление ограничениями (устранение бутылочных горлышек), устранение потерь, управление вариативностью (а также СКП и система глубинных знаний).
• Канбан позволяет определить бутылочные горлышки и полностью воплотить пять направляющих шагов из теории ограничений.
• Канбан позволяет визуализировать приводящие к потерям действия, его можно использовать для полного разворачивания бережливой инициативы для программ, систем, разработки продукта или IT-организации.
• Канбан обеспечивает инструментарий для использования системы глубинных знаний Эдвардса Деминга и статистического контроля процессов. Он применяется для внедрения кайдзен-инициативы или инициативы в рамках концепции «шесть сигм».
Глава 17 Бутылочные горлышки и ограниченная доступность
Вашингтон SR-520 – это шоссе, которое связывает Сиэтл с его северо-восточными пригородами Кирклендом и Редмондом. Основная артерия для жителей пригородов, работающих в центре города, а также для сотрудников Microsoft и других базирующихся в этих пригородах высокотехнологичных компаний (например, AT&T, Honeywell и Nintendo), которые живут в городе и ездят на работу в обратном направлении. Каждый день в течение восьми часов дорога представляет собой бесконечную пробку – бутылочное горлышко в обоих направлениях. Если после обеда встать на мосту, который пересекает шоссе по Северо-Восточной 76-й улице в небольшом пригороде Медина (недалеко от дома Билла Гейтса на берегу озера Вашингтон), и посмотреть на восток, то видно, как пробка ползет на запад, по направлению к городу, медленно карабкаясь на холм из Бельвью, прежде чем распадается на две полосы, пересекая понтонный мост в Сиэтл. Скорость пробки, движущейся вверх по холму, составляет примерно 15 километров в час, и машины в потоке постоянно останавливаются. Если вы пересечете улицу и посмотрите на запад, на небоскребы Спейс-Нидл и Олимпик-Маунтинс в центре Сиэтла, то увидите гладкое движение со скоростью около 80 километров в час. Что за волшебство творится прямо у вас под ногами, почему скорость так резко меняется, а поток из рваного делается гладким? Дело в том, что прямо перед мостом дорога сужается с трех полос до двух – нужно пересечь озеро по понтонному мосту. Крайняя правая полоса шоссе предназначена для автомобилей с двумя и более пассажирами. Она занята общественным транспортом – автобусы ездят в город и из него – и некоторым количеством личных автомобилей. Эти машины вливаются в другой поток, чем вызывают замешательство и замедляют движение. На протяжении нескольких километров перед мостом в шоссе вливается еще несколько дорог, что увеличивает загруженность шоссе в пиковое время. В результате поток имеет рваный ритм и очень низкую скорость.
Планируя безопасность дорожного движения, специалисты беспокоятся о дистанции между машинами. В идеале она должна быть достаточной, чтобы отреагировать на изменения и при необходимости срочно и безопасно остановиться. Это расстояние зависит от скорости и времени реакции. Правила рекомендуют «дистанцию» в две секунды. На языке бережливого производства это идеальное время такта между машинами. Если у нас есть две полосы и две секунды между машинами, то максимальная пропускная способность дороги – 30 машин на полосу в минуту, то есть 60 машин в минуту. Это верно независимо от скорости машин. Не выполняются эти правила только в экстремальных случаях – для очень малых скоростей и для очень высоких, существенно превышающих ограничение в 80 километров в час, установленное на SR-520. Таким образом, пропускная способность (которая в управлении транспортными потоками называется емкостью, что приводит к некоторым недоразумениям) составляет 3600 машин в час.
Но если встать на мосту и посчитать, сколько машин проходит под ним примерно в пять вечера в рабочий день, вы заметите, что на понтонный мост в сторону Сиэтла заезжает менее 10 машин в минуту. Несмотря на высокий спрос, дорога работает менее чем на одну пятую своей потенциальной пропускной способности! Почему?
Понтонный мост через озеро Вашингтон – это бутылочное горлышко. Все мы понимаем, что это значит. От ширины бутылочного горлышка зависит скорость, с которой можно наполнить или опустошить бутылку. Из широкого горлышка вода льется быстро, но в таком случае велик риск все пролить. Если горлышко узкое, то вода льется медленнее, но точность в этом случае выше. Бутылочные горлышки ограничивают потенциальную пропускную способность – в нашем случае от 60 машин в минуту, то есть 3600 в час, до менее чем 10 машин в минуту, то есть 600 в час.
Бутылочное горлышко в потоке проекта находится в любом месте, где выстраивается очередь на обработку заданий. В случае с шоссе SR-520 эта очередь состоит из автомобилей, ждущих въезда на мост в 11 километрах к востоку. В разработке ПО это может быть любая очередь заданий, с которыми еще не начали работать, или заданий в работе: требования, ожидающие анализа, результаты анализа, которые нужно проектировать, разрабатывать и тестировать, протестированные задания, которые нужно выпускать, и т. д.
Как уже говорилось, SR-520 в пиковое время, когда оно пользуется наибольшим спросом, работает примерно на 20 % от своего потенциала. Чтобы полностью разобраться в этом, нужно понять, как максимально использовать потенциал бутылочных горлышек и каким образом на него влияет вариативность. Этому посвящена данная глава, а также глава 19.
Ресурсы ограниченной мощности
SR-520 в районе моста Северо-Восточной 76-й улицы – ресурс ограниченной мощности. Она составляет 60 автомобилей в минуту в двух полосах. Дорога, ведущая к этому отрезку, имеет три полосы, так что участники движения вынуждены перестраиваться, чтобы пересечь озеро по древнему понтонному мосту, который был спроектирован 50 лет назад и рассчитан на две полосы. В то время этого вполне хватало – никакого бутылочного горлышка не предвиделось. Восточные пригороды были небольшими поселениями, так что пересекать мост приходилось редко, притом в основном в город, а не в обратную сторону, как сейчас.
Увеличение мощности
С точки зрения ограниченности ресурсов можно провести аналогию между SR-520 и девушкой – дизайнером пользовательского интерфейса в команде по производству ПО, отвечающей за проектирование всех экранов, на которых происходит взаимодействие с пользователем. Дизайнер работает усердно, но ее мощности не хватает, чтобы покрыть все потребности проекта. Естественная реакция большинства менеджеров – нанять кого-то ей в помощь. В теории ограничений Элияху Голдратта такое решение называется «расширением ограничений»: мы добавляем мощности, и бутылочное горлышко устраняется.
В случае с SR-520 эквивалентом будет замена понтонной переправы через озеро Вашингтон новым мостом с тремя полосами движения в каждую сторону. Чтобы сохранялось равновесие, это должен быть мост с одной полосой для загруженного транспорта и велодорожкой, а также с двумя полосами для всех участников движения. Именно этим собирается заняться Министерство транспорта штата Вашингтон. Мост будет стоить сотни миллионов долларов, на его возведение понадобится около десяти лет. На момент написания этой книги строительство даже не началось.
Оказывается, увеличение мощности ограниченного ресурса – это крайний вариант. Расширение бутылочного горлышка стоит времени и денег. Если, например, нанимать второго дизайнера пользовательского интерфейса, то надо найти не только средства на его зарплату, но и бюджет на сам процесс найма, который может включать комиссионные для агентов по подбору персонала. Пока мы рассматриваем резюме и проводим собеседования с кандидатами, тормозится ход текущего проекта. А наш самый драгоценный ресурс, та самая девушка – дизайнер пользовательского интерфейса с ограниченной мощностью, будет вынуждена отрываться от работы по проекту, чтобы читать резюме, отбирать кандидатов, проводить собеседования. В результате ее возможности заниматься дизайном сокращаются, как и потенциальная пропускная способность всего проекта. Именно из-за таких ситуаций появился закон Фреда Брукса, который гласит: «Если проект не укладывается в сроки, то добавление рабочей силы только еще больше задержит его». Наблюдения Брукса были основаны на отдельных случаях, а сейчас можно дать научное объяснение этого феномена; в производстве ПО, по крайней мере, в последние 35 лет установилось понимание того, что при наборе дополнительных сотрудников проект замедляется.
Загрузка и защита
Вместо того чтобы немедленно расширять бутылочное горлышко, теряя время и деньги, замедляя процесс, лучше сначала найти возможность полностью использовать мощность этого ресурса. Например, мы выяснили, что SR-520 в пиковое время имеет пропускную способность лишь в 20 % от своего потенциала. Что нужно предпринять, чтобы ее повысить? Давайте немного пофантазируем. Если бы пропускная способность в час пик достигала своего максимума – 3600 машин в час, пришлось бы заменять существующий мост новым? А стало бы время поездки достаточно коротким, чтобы налогоплательщик штата Вашингтон предпочел видеть свои налоги потраченными на более насущные нужды, например на книги для школьных библиотек? Может быть!
Но как использовать весь потенциал дороги? Источник проблемы – это водители. Скорость их реакции и действия, которые они предпринимают, очень разнообразны. Когда машины съезжают с полосы для загруженного транспорта, автомобили в средней полосе должны притормозить и освободить место для съезжающих. Некоторые водители реагируют медленнее остальных, кто-то жмет на тормоза более яростно, а в результате движение становится непредсказуемым. Часть водителей, которых нервирует неустойчивое движение в полосе перед ними и снижение скорости по сравнению с соседней левой полосой, решают перестроиться в нее. Эффект повторяется. Все машины замедляют ход, но пропускной способности вредит не это. Самое важное – расстояние от одной машины до другой. Для равномерного движения желателен двухсекундный зазор между транспортными средствами[12]. Однако человеческий фактор означает, что машины не тормозят и не ускоряются равномерно, так что расстояния между ними расходятся. Разное время реакции отдельных людей, нажимающих на педали газа и тормоза, и время реакции двигателей, трансмиссий и коробок передач в автомобилях означает, что расстояния продолжают расширяться и создается пробка. Вариативность системы оказывает огромное влияние на пропускную способность.
Устранение этой проблемы увлекает нас в сказочную с точки зрения управления автомобилем страну, хотя некоторые немецкие производители уже проводят подобные эксперименты. Системы, которые используют радары и лазеры для оценки дистанции между автомобилями и позволяют сохранить равномерность движения, могут снять вариативность, существующую на SR-520. Такие системы способны эффективно замедлять поток автомобилей, сохраняя интервал между ними. В результате пропускная способность трассы остается высокой. Однако исключение вариативности в отношении частных автомобилей имеет свои пределы. Чтобы обеспечить низкую вариативность транспорта, нужно связать пассажирские автомобили вместе и поставить их на рельсы. Вот, собственно, причина того, почему массовый скоростной железнодорожный транспорт более эффективно, чем автомобильный, справляется с задачей быстрой перевозки большого количества людей.
Но есть и хорошая новость: в нашем случае ресурсы ограниченной мощности сталкиваются с вариативностью, с которой мы способны кое-что сделать. В этой книге много говорится о координационных усилиях и организационных расходах на работу по созданию ценности. Если у нас есть дизайнер пользовательского интерфейса с ограниченной мощностью, то мы можем поручать ей только работу, создающую ценность, минимизируя количество нецелевых и бесполезных действий.
Например, в 2003 году у меня была команда тестировщиков с ограниченной мощностью. Чтобы максимально ее использовать, я начал поиск других, резервных ресурсов и нашел их в лице бизнес-аналитиков и менеджеров проекта. Тестировщики были освобождены от бюрократической деятельности, например заполнения табеля учета рабочего времени. От них не требовалось и планирование будущих проектов. Мы дали аналитикам возможность разрабатывать планы тестирования следующих итераций и проектов, в то время как тестировщики занимались исключительно тестированием текущих заданий.
Еще лучше (хотя тогда это не пришло мне в голову) – разработать профиль риска для требований, которые должны быть протестированы только профессиональной командой тестировщиков. Требования, не соответствующие установленным критериям, могут быть протестированы сотрудниками других функциональных отраслей, которые выступают в данном случае в качестве тестировщиков-новичков. Это могут быть, например, бизнес-аналитики. Такой метод «раздвоения», использующий профиль риска, служит хорошим способом оптимизировать использование бутылочного горлышка, продолжая контролировать риски проекта.
Долгосрочным решением могут стать инвестиции в автоматизацию тестов. Ключевое слово в этом предложении – «инвестиции». Если вы говорите о них, то обычно имеете в виду расширение бутылочного горлышка. Привлечение дополнительных ресурсов – не единственный метод расширения мощности. Полезная и естественная стратегия для этого – автоматизация. Сообщество agile-программистов за последнее десятилетие многое сделало для развития автоматизации тестирования. Обычно стоит смотреть на автоматизацию как на стратегию расширения. Однако у автоматизации есть и замечательный дополнительный эффект: она снижает вариативность, поскольку повторяющиеся задания и действия воспроизводятся с цифровой точностью. Итак, автоматизация снижает вариативность процесса и может помочь оптимизировать использование мощности следующего бутылочного горлышка.
Еще один способ добиться максимального использования нашего дизайнера пользовательского интерфейса – обеспечить ей постоянный прогресс в текущей деятельности. Если дизайнер сообщает, что по каким-то причинам ее работа заблокирована, то менеджер проекта и, при необходимости, вся команда должны дружно взяться за проблему и решить ее. Таким образом, для эффективного использования бутылочных горлышек с ограниченной мощностью необходимы высокие способности организации к определению и решению проблем.
Если текущую работу блокируют сразу несколько проблем, то те из них, которые угрожают ресурсу ограниченной мощности (в нашем случае – дизайнеру пользовательского интерфейса), должны получить наивысший приоритет. Для эффективного, производительного разрешения проблем, таким образом, необходимо знать, где находится ресурс ограниченной мощности, и при необходимости давать ему приоритет.
Прозрачность канбан-системы помогает определить местонахождение ресурсов ограниченной мощности (бутылочных горлышек) и влияние проблем, препятствующих нормальному рабочему потоку в этой точке системы. Если все участники проекта будут понимать системный характер проблем в бутылочном горлышке, то вся команда с готовностью перейдет к решению проблемы. Высшее руководство и внешние заинтересованные лица, имеющие серьезные причины надеяться, что релиз выйдет вовремя, тоже охотнее выделят свое время, осознав его ценность и то влияние, которое окажет быстрое разрешение проблемы.
Развитие способности организации прозрачно отслеживать прогресс и готовить отчеты по проектам с использованием канбан-системы жизненно важно для повышения производительности. Прозрачность дает понять, каковы бутылочные горлышки и препятствия, а следовательно, ведет к оптимальному использованию доступной мощности для создания ценности благодаря общекомандной концентрации на поддержании потока.
Еще один метод, часто применяемый для обеспечения максимальной загрузки ресурса ограниченной мощности, состоит в том, чтобы убедиться: ресурс никогда не простаивает. Если вдруг ресурс ограниченной мощности оставляют без работы из-за проблемы, неожиданно возникшей выше по цепочке – например, аналитик запросов заболел, – это непозволительная трата времени и средств. Или, предположим, внезапно ограничение снимается. Либо большая часть требований отзывается заказчиком, решившим внести стратегические изменения. Пока команда ждет разработки новых требований, дизайнер пользовательского интерфейса простаивает. Что если действия выше по цепочке по своей природе крайне вариативны? Это обычная ситуация при выявлении требований и разработке. Таким образом, темпы поступления заданий оказываются неравномерными. Причин, по которым ресурс ограниченной мощности может простаивать из-за временного недостатка работы, много. Вариативность темпов поступления новых заданий в очередь (в нашем примере – к дизайнеру пользовательского интерфейса) можно нейтрализовать посредством буфера. Буферизация увеличивает общее число заведенных в системе заданий на работу. С точки зрения бережливого управления добавление буфера заданий приводит к потерям времени, поскольку увеличивает период выполнения. Однако преимущества в пропускной способности, которые обеспечивает равномерный поток работы, проходящий через ресурс ограниченной мощности, обычно ценнее. Вы сделаете больше работы, несмотря на немного удлинившееся время выполнения и слега увеличившееся число заданий в работе.
Использование буферов для защиты от простоя ресурса – бутылочного горлышка – часто называют защитой бутылочного горлышка, или просто защитой. Прежде чем задумываться о расширении бутылочного горлышка, нужно попытаться максимально его использовать и установить защиту для реализации его полного потенциала.
Наш пример в области управления движением – трасса SR-520, чья пропускная способность составляет менее 20 % от потенциальной, – достаточно заурядный для интеллектуальной деятельности, например анализа требований и разработки ПО. Часто благодаря максимальному использованию бутылочного горлышка можно добиться более чем четырехкратного увеличения пропускной способности.
В примере с Microsoft из главы 4 благодаря более правильному использованию и защите бутылочного горлышка результаты улучшились в два с половиной раза. Это устранило вариативность системы. Причем не было потрачено никаких денег, например на расширение бутылочного горлышка.
Подчинение ограничению
Как только вы решили, как использовать и защищать ресурс ограниченной мощности, может понадобиться подчинить остальные элементы этим ограничениям, чтобы система работала максимально эффективно.
Давайте вернемся к нашим фантазиям о транспортной системе будущего. Теперь мы решили не строить новый мост через озеро Вашингтон, а снабдить все машины, едущие в час пик по SR-520, новой системой управления скоростью, которая регулирует трафик на одиннадцатикилометровом участке шоссе при помощи радара и беспроводной связи. Эта новая система будет работать своего рода круиз-контролем и заменит управление педалями газа и тормоза. Стимул к установке новой системы на частные автомобили – налоговые льготы. Как только система появится на достаточном количестве автомобилей, она начнет действовать, так что машинам, не оснащенным ею, придется либо искать альтернативный маршрут, либо не ездить в час пик. Результатом станет более равномерный поток движения и возросшее использование мощности бутылочного горлышка. Предполагаю, что такая система при достаточной эффективности сможет вернуть узкому месту около 50 % утраченной мощности. Иными словами, она повысит пропускную способность шоссе SR-520 в пиковое время в два с половиной раза.
Итак, что мы сделали в этом примере? Подчинили право водителей самостоятельно определять и контролировать скорость передвижения более высокой общей цели – ускорению времени поездки благодаря повышению пропускной способности при движении через мост. В этом вся суть синхронизации: чтобы улучшить загрузку бутылочного горлышка, надо изменить что-то еще.
Тем, кто знаком с теорией ограничений, часто кажется бессмысленным тот факт, что изменения, необходимые для повышения производительности бутылочного горлышка, должны производиться не в нем самом. Рецензируя мою первую книгу{20}, известный член agile-сообщества разработки ПО предположил, что использование теории ограничений в качестве подхода к совершенствованию приведет к тому, что все участники команды захотят стать частью ресурса – бутылочного горлышка. Ведь так они получают максимум внимания руководства. И подобная ошибка вполне естественна. На самом деле, как ни странно, большая часть действий по управлению бутылочными горлышками проводится вдали от них. Многие изменения связаны со снижением избыточной нагрузки на бутылочное горлышко, чтобы увеличить его пропускную способность. Следует обязательно стремиться к максимальному использованию мощности бутылочного горлышка и соответствующему увеличению пропускной способности, а следовательно, и к сокращению времени выполнения проекта, принимая меры по всей цепочке создания ценности, но, как правило, не к бутылочному горлышку.
Ресурсы с ограниченной доступностью
Ресурсы с ограниченной доступностью – это, строго говоря, не бутылочные горлышки. Но они обычно выглядят как бутылочные горлышки, и действия, которые мы совершаем, чтобы компенсировать ожидание, похожи на меры, предпринимаемые для узких мест. Любой водитель, стоявший на светофоре, понимает идею ограниченного доступа. Остановившись на красный свет, машина не может ехать дальше. Остановка вызвана не ограничением мощности самой трассы, а правилом, которое позволяет автомобилям, движущимся по другой дороге, пересечь перекресток.
Более показательный пример, особенно по отношению к сквозной теме нашей главы – дорожному движению в штате Вашингтон, – это система паромов, которая действует в заливе Пьюджет и соединяет полуострова Китсап и Олимпик с материком в районе Сиэтла. Здесь три паромные переправы: две из них отправляются из Сиэтла в Бремертон и Бэйнбридж, а моя любимая SR-104 переправляет машины из Эдмондса на восточной стороне в Кингстон на западной. На карте паромный маршрут считается частью дороги SR-104. Здесь часто пишут «дорожная пошлина», вместо того чтобы прямо сказать «тут вам надо сесть на паром». Специалисты-транспортники считают паром дорогой с ограниченной доступностью.
Подъезжая к переправе, вы платите определенную сумму, после чего вас просят подождать. Обычное время ожидания в очереди – около 30 минут: парому требуется около получаса, чтобы пересечь залив Пьюджет, затем 10–15 минут уходит на разгрузку транспортных средств и примерно столько же – на погрузку новых перед отплытием. Как правило, паромная компания использует два судна, поэтому отправление происходит примерно каждые 50 минут. В часы пик на маршруте иногда появляется третий паром, что сокращает время ожидания примерно до 35 минут.
Большую часть времени паромы ходят с почти полной загрузкой, но система ограничена не мощностью. Скопление машин в зоне ожидания – в буфере – и затем загрузка на паром для отплытия (пакетная передача) не говорят о том, что мощность ресурса ограничена. Это свидетельствует об ограниченной доступности. Паромы отходят всего раз или два в час и способны вместить около 220 машин.
В часы пик, например в пятницу днем, паромная система действительно ограничена мощностью. Когда такое случается, количество машин, прибывающих к переправе, начинает превышать вместимость судна. Мощность составляет около 300 машин в час. Автомобили встают в очередь за зоной ожидания, перед пунктом оплаты. Во время пикового спроса образуется пробка, которая растягивается по Кингстону или Эдмондсу на три километра. И тут мало что можно сделать – просто надо ждать. Расширить ограничение при помощи другого парома не так-то просто. Расписание отправлений призвано обеспечить должный уровень обслуживания за достаточное время. Постоянное наличие избыточной мощности слишком дорого обойдется налогоплательщикам штата, которые и оплачивают паромную переправу.
Возвращаясь к разработке ПО и интеллектуальной деятельности, можно сказать, что ограничение доступности часто является проблемой в случае с общими ресурсами или сотрудниками, выделенными для решения множества задач. Как мы уже знаем, многозадачность в офисе в принципе невозможна: на самом деле мы просто часто переключаемся с одной задачи на другую. Если нас просят одновременно работать над тремя проблемами, то мы сначала занимаемся одной, затем переключаемся на вторую, а после на третью. Когда кто-то ждет окончания первого задания, пока мы работаем над вторым или третьим, мы становимся ресурсом с ограниченной доступностью с точки зрения ожидающего (и первого задания).
Один из известных мне примеров ограниченной доступности связан с билд-инженером. В компании существовало правило, что только члены команды управления конфигурациями могли собирать код и отправлять его в тестовую среду. Это была конкретная стратегия управления рисками, основанная на предшествующем опыте: разработчики часто проявляли небрежность и собирали такой код, который разрушал тестовую среду. А тестовая среда нередко была общей для нескольких проектов, так что негативное воздействие плохой сборки оказывалось существенным. Технологический отдел не очень хорошо справлялся с координацией на программном уровне, и возникала вероятность того, что одна команда и один проект работали с общими IT-системами, что могло повлиять и на другой проект.
Координационная функция – знать, что происходит на техническом уровне кода между проектами, – возлагалась на отдел управления конфигурациями. Эту задачу выполняли билд-инженеры. Они отслеживали, какое влияние оказывают изменения на данную программную сборку, и отвечали за безопасность тестовой среды, чтобы ее недоступность не повлияла на все остальные проекты.
Обычно на проект назначался свой билд-инженер, член общего пула ресурсов команды управления конфигурациями. Однако потребность одного проекта в подготовке сборок для тестирования не могла обеспечить полную загрузку билд-инженера: это занимало всего час-два в день. Поэтому билд-инженеры трудились в режиме многозадачности: их назначали на несколько проектов и поручали другие обязанности.
Например, в Corbis Дуг Буррос был назначен билд-инженером на проект технической поддержки. Но одновременно выполнял и две другие задачи: создавал новые среды и сопровождал существующие. Как инженер по управлению конфигурациями, он должен был поддерживать актуальность сред, то есть следить за обновлением оперативной системы, применением патчей и обновлений для серверов баз данных и межплатформенного программного обеспечения, системных конфигураций, топологии сети и т. д. Примерно час в день у него занимало выполнение функций билд-инженера – обычно с десяти до одиннадцати утра. Если разработчики в три часа дня обнаруживали, что им необходима тестовая сборка, приходилось ждать до начала следующего рабочего дня. Билд-инженер был ресурсом с ограниченной доступностью. Работа блокировалась, и, поскольку техническое обслуживание выполнялось при помощи канбан-системы, задания быстро выстраивались в очередь по всей цепочке создания ценности, вызывая простой других сотрудников.
Интересно, что меры по решению проблем ресурсов с ожиданием доступа в потоке очень похожи на меры для ресурсов ограниченной мощности.
Загрузка и защита
Прежде всего следовало понять, что Дуг – это ресурс с ограниченной доступностью, и выявить влияние, которое оказывает этот фактор. Задания выстраивались в очередь за время недоступности билд-инженера, потому что канбан-лимиты были жестко определены. Он стал источником вариативности в потоке, значит, следовало организовать буфер заданий перед Дугом. При этом требовался достаточно большой буфер, чтобы поток продолжал двигаться, но не настолько, чтобы Дуг превратился в ресурс с ограничением мощности. Я поговорил с ним, и оказалось, что он легко может собирать до семи элементов за час своей работы в этой должности. Поэтому мы создали буфер с канбан-лимитом, равным семи, дали знать об этом всем участникам цепочки создания ценности и начертили на стене карточек новый столбец под названием «Сборка готова». Общий WIP-лимит системы увеличился примерно на 20 %, но это принесло результат. Хотя сборки были ресурсом с ограниченной доступностью, действия выше по цепочке могли обеспечивать равномерный поток работы в течение дня. В результате существенно повысилась пропускная способность, а время выполнения сократилось, несмотря на увеличение WIP-лимита. Мы также решили изменить график Дуга: вместо одного часа подряд два раза по полчаса. Их можно было разнести по времени: тридцать минут утром и столько же – днем. Это облегчило бы поток и снизило давление на буфер для ожидания доступа. Возможно, от этого размер буфера уменьшился бы до двух или трех, что повысило бы WIP-лимит всего на 10 % и привело к сокращению времени выполнения для всей системы.
Чтобы решить проблемы, связанные с ограниченной доступностью, нужно думать о том, как облегчить доступ. Идеальная цель – превратить ресурс с ограниченной доступностью в постоянно доступный.
Подчинение ограничению
Как уже говорилось, подчинение ограничениям обычно включает в себя изменение правил применительно ко всей цепочке создания ценности с целью максимально загрузить бутылочное горлышко. Какие варианты были в случае с нашим ресурсом с ограниченной доступностью – билд-инженером?
Первый вариант – пересмотреть правило, по которому Дуг вынужден был выполнять три различные функции. Насколько оптимален такой выбор? Я поговорил с его менеджером. Оказалось, что инженеры в ее команде предпочитали разнообразие заданий и даже нуждались в нем, чтобы сохранять интерес к работе. Кроме того, поскольку от членов команды требовалось выполнять системные сборки, заниматься обслуживанием системы и обязанностями билд-инженера, у них формировался обширный спектр навыков. Этот пул ресурсов сохранял гибкость, что давало менеджеру гораздо больше вариантов и помогало избегать появления бутылочных горлышек, которые могли бы возникнуть, будь участники команды узкими специалистами. Обширный спектр ответственности нравился сотрудникам и с точки зрения карьерных перспектив, а также будущего резюме. Они не хотели переходить на выполнение узкоспециализированных заданий. Поэтому предложение остаться только билд-инженерами не нашло бы понимания.
Другой вариант – отказ от идеи многозадачности и полное вовлечение Дуга в работу команды технического обслуживания. Это сулило ему массу свободного времени. Он просиживал бы в ожидании работы, как пожарный в ожидании пожара. Перевод Дуга в режим постоянного ожидания, разумеется, решил бы все проблемы с потоком, но разве это был бы разумный выбор?
Бюджет мог не выдержать набора новых сотрудников в команду управления конфигурациями, которые занялись бы сборкой системы и обслуживанием вместо Дуга. Ведь пришлось бы просить у руководства деньги на оплату труда нового работника, из-за которого другой сотрудник бoльшую часть времени простаивал бы. Каково это с точки зрения управления рисками?
Чтобы определить это, нужно проанализировать расходы из-за задержек в области технического обслуживания и сравнить затраты на привлечение нового специалиста с расходами на другие действия по поддержанию равномерного потока. Оказалось, что не так уж много элементов в очереди на техническое обслуживание имели стратегически значимую стоимость расходов из-за задержек. Поэтому идея иметь сотрудника, простаивающего в ожидании заданий ради оптимизации потока, выглядела нежизнеспособной. Действия по использованию ресурса, предполагающие добавление буфера работы для управления потоком, показались оптимальнее и дешевле.
Обсуждая, что делать с Дугом как с ресурсом с ожиданием доступа, мы добрались до правила, согласно которому эту работу могли исполнять только билд-инженеры. Было решено рассмотреть возможность отменить это правило, чтобы разработчики могли сами собирать код и передавать его в тестовую среду. Но эту идею отвергли, поскольку у организации не было надежного альтернативного способа координировать технические риски между проектами. Один из вариантов – назначение на проект отдельной тестовой среды – отклонили по экономическим причинам, к тому же в кратко– и среднесрочной перспективе он был нежизнеспособен. Оптимальным решением по прежнему считалось выполнение функции билд-инженеров членами команды управления конфигурации.
Увеличение мощности
Однако буферизация и увеличение WIP-лимита – временное решение проблем. Это всего лишь тактический ход, хотя и эффективный, и он имел свою цену. Канбан-система высветила бутылочное горлышко, характеризующееся необходимостью ожидания доступа, и дала возможность команде подробно обсудить его причину и возможные варианты решения. Дискуссия завершилась пониманием того, что выполнение функции сборки кода человеком – не лучший вариант. Можно ли автоматизировать процесс сборки? Ответ был утвердительным, хотя такое действие влекло за собой серьезные затраты. Нужно было развивать существенные возможности в управлении конфигурациями и межпроектную координацию. К тому же на определенный период требовалось пригласить специалистов по автоматизации, чтобы они создали систему и запустили ее.
Автоматизация заняла шесть месяцев, на восемь недель были приглашены два подрядчика. Общие финансовые расходы составили примерно 60 тысяч долларов. В результате, однако, Дуг избавился от необходимости производить сборку, которая была доступна в любой момент, когда это требовалось разработчикам. На этом этапе уже можно было исключить буфер и сократить WIP-лимит системы. Это, в свою очередь, привело к небольшому уменьшению времени выполнения.
Автоматизация оказалась способом увеличить мощность существующего ресурса с ограниченной доступностью. Добавление мощности, то есть второго инженера, было плохим вариантом.
Исследовалась и другая возможность, связанная с автоматизацией, – виртуализация сред. Она уже активно использовалась в нашей отрасли, однако в то время все наши тестовые среды оставались физическими. Виртуализация не входила в возможности организации. Но будь она возможна, тестовые среды было бы легко конфигурировать и восстанавливать, что сократило бы отрицательное влияние сборки на среду. В управлении рисками это называется компенсационными мерами. Они дали бы возможность подготавливать выделенные среды для проекта, чем снизили бы или исключили риск того, что сборка повредит конфигурацию для другого проекта.
Итак, буферизация была использована как краткосрочная, тактическая стратегия загрузки, а автоматизация – в качестве долгосрочной стратегии увеличения мощности.
Теперь вспомним пример с паромом из Эдмондса в Кингстон. Какое расширение возможно здесь? В данный момент штат Вашингтон рассматривает два варианта. Один из них – заменить нынешний устаревающий флот паромов новыми, более крупными и эффективными судами. Кроме того, в Вашингтоне часто применяются понтонные мосты. Два из них – через озеро Вашингтон, в том числе и тот, который составляет часть SR-520 (возможно, это самый длинный такой мост в мире), а еще один ведет через канал Худ и является частью шоссе SR-104. Сейчас рассматривается возможность постройки нового, рекордного по длине моста через залив Пьюджет, продолжающего SR-104 и полностью заменяющего паромную переправу. Планируемый мост не только решит проблему ограниченной мощности в пиковое время, но и устранит проблемы ограниченной доступности, которые мешают рассматривать все паромные переправы как вариант организации движения. Этот мост будет способствовать экономическому росту полуостровов Китсап и Олимпик. Возможно, лет через пятьдесят в другой книге будет обсуждаться понтонный мост на трассе SR-104 через залив Пьюджет, который тоже назовут бутылочным горлышком и ресурсом ограниченной мощности во время пикового движения.
Выводы
• Бутылочные горлышки сдерживают и ограничивают поток работы.
• Бутылочные горлышки бывают двух типов: с ограничением мощности – неспособностью выполнять больше работы, и с ограничением доступности – ограниченной мощностью из-за ограниченной (но обычно предсказуемой) доступности.
• Мы управляем бутылочными горлышками в соответствии с пятью направляющими шагами теории ограничений.
• Повышение мощности бутылочного горлышка называется расширением.
• Действия, направленные на увеличение мощности ресурса с ограниченной мощностью, обычно отличаются от действий, направленных на увеличение мощности ресурса с ограниченной доступностью.
• Увеличение мощности может происходить за счет добавления ресурсов, автоматизации или изменения правил, в результате чего ресурс с ограниченной доступностью становится постоянно доступным.
• Действия по увеличению мощности обычно затратны с точки зрения денег и времени и нередко требуют стратегических вложений в оптимизацию процесса.
• Часто на практике бутылочные горлышки демонстрируют мощность существенно ниже теоретической.
• Пропускную способность бутылочного горлышка можно повысить до уровня теоретического ограничения, предприняв действия по загрузке и защите ресурса.
• Защита, как правило, заключается в добавлении буфера незавершенных заданий перед бутылочным горлышком. Это верно как для ресурсов с ограниченной мощностью, так и для ресурсов с ограниченной доступностью.
• Загрузка обычно обеспечивается изменением правил, контролирующих работу ресурса – бутылочного горлышка.
• Для обеспечения загрузки могут использоваться классы обслуживания.
• Подчинение ограничению – это действия, проводимые в других местах цепочки создания ценности для обеспечения желательных действий по обеспечению загрузки или защите. Обычно это изменение правил.
• Действия по загрузке, защите и подчинению ограничению часто просты и недороги, поскольку в основном связаны с изменениями правил. Таким образом, максимизация пропускной способности бутылочного горлышка благодаря его полной загрузке может рассматриваться как тактическое усовершенствование процесса.
• Несмотря на тактический характер повышения загрузки бутылочного горлышка, выгоды от этого могут быть существенными. Часто удается добиться повышения пропускной способности в два с половиной и даже пять раз (а также соответствующего сокращения времени выполнения), притом даром или с незначительными расходами и всего за несколько месяцев.
• Необходимо сначала стремиться к полной загрузке и только потом пытаться увеличить мощность ресурса.
• Нередко тактические действия по загрузке и подчинению ограничению производятся в то же время, что и внедрение плана стратегических изменений по расширению ограничения в долгосрочной перспективе.
Глава 18 Экономическая модель бережливого производства
Потери (или по-японски муда, дословно – мусор) – термин, применяемый в бережливом производстве (и производственной системе Toyota) для действий, в ходе которых не добавляется ценность для конечного продукта. Метафора «потери» оказалась сложной для принятия работниками интеллектуальной сферы. Часто трудно признать потерями такие задачи или действия, которые действительно влекут за собой накладные расходы, но при этом необходимы либо желательны для выполнения работы по созданию ценности; например, ежедневные стендапы нужны для координации большинства команд. Такие встречи сами по себе не прибавляют ценности конечному продукту, так что с технической точки зрения это «потери», но признать это многим практикам гибкой разработки сложно. Вместо того чтобы погружаться в ожесточенные споры о потерях, я решил найти другую подходящую парадигму и другой язык – вызывающий меньше эмоций и не вводящий в заблуждение.
Переосмысление «потерь»
Следуя за такими авторами, как Дональд Рейнертсен, я адаптировал понятия из сферы экономики и называю «ведущие к потерям» действия расходами. Расходы подразделяются на три основные абстрактные категории: операционные расходы, координационные расходы и «ошибочная» нагрузка (Failure Load). Категории показаны на рис. 18.1.
Рис. 18.1. Модель экономических расходов для бережливой разработки ПО
Рис. 18.1 показывает, что в течение определенного времени в ходе итерации или проекта производится множество действий по созданию ценности. Эти действия окружены операционными и координационными расходами. Действия, создающие ценность, могут быть заменены так называемой ошибочной нагрузкой – то есть работой, которая заключается либо в переделке, либо в требованиях, появившихся из-за неудачной реализации предыдущих требований.
Эти расходы подробнее обсуждаются в следующих параграфах. Буду описывать их при помощи простого примера – покраски забора вокруг моего дома в Сиэтле.
Операционные расходы
Забор состоит из 21 секции. Потребительская ценность создается, если секция забора покрыта морилкой. Полная потребительская ценность получается, когда все секции покрашены с обеих сторон.
Прежде чем начать работу, нужно было найти материалы. Для этого я поехал в магазин Home Depot. Кроме того, требовалось подготовиться: провести мелкий ремонт забора, его шлифовку, подрезку деревьев и кустов, чтобы можно было пройти к забору. Все эти действия не создают ценность. Заказчику неинтересно, что мне нужно ехать в Home Depot и это требует времени.
Более того, все это раздражает, потому что начало и окончание проекта в результате откладываются. Все эти действия отсрочивают начало работы, создающей ценность.
Итак, чтобы начать работу, создающую ценность, необходимо провести несколько подготовительных мероприятий.
Могут понадобиться и другие действия: например, планирование, оценка и определение ожиданий. Клиенту может быть представлена стоимость работы и дата ее выполнения. (В данном случае будем считать, что клиент – моя жена.)
Когда дело наконец доходит до покраски, выясняется, что с 42 секциями забора (если считать обе стороны) невозможно управиться за один подход. Приблизительная скорость работы – четыре секции в час. Поэтому было решено разбить задачу на шесть этапов. Если бы речь шла о разработке ПО, мы бы назвали их итерациями или спринтами; в производстве это партии. Перед тем как начинать каждый этап покраски, также требовался ряд подготовительных мер. Надо было переодеться, доставить материалы: я переносил краску, кисти и другие инструменты из гаража к месту работы и только после этого начинал красить.
Итак, и проекты, и итерации предполагают подготовительные мероприятия.
Поработав пару часов, я обычно чувствовал потребность в перерыве. Допустим, наступало время обеда. Однако я не мог все бросить и начать есть. Сначала нужно было закрыть банку с краской, вымыть кисти либо бросить их в емкость с водой, чтобы они не засохли, пока меня нет. Потом требовалось привести себя в порядок – помыть руки и переодеться. И только после этого я отправлялся обедать.
По окончании проекта у меня может остаться немного морилки, а в Home Depot принимают обратно полные банки и возвращают за них деньги. Поэтому требуется еще одна поездка.
Итак, как итерации, так и проекты предполагают завершающие мероприятия.
С экономической точки зрения подготовительные и завершающие мероприятия – это операционные расходы. Каждое действие, создающее ценность, имеет связанные с ним операционные расходы. Клиент чаще всего их не видит, редко ценит и относится в лучшем случае со смешанными чувствами. Его можно заставить оплатить эти расходы, но он предпочел бы этого не делать. Наверняка вам приходилось приглашать мастера чинить стиральную или посудомоечную машину и платить за вызов 90 долларов. Это операционные расходы. Возможно, вы бы предпочли заплатить меньше или выбрали сантехника, который не берет плату за вызов? Операционные расходы не создают ценности. Они необходимы, но с точки зрения концепции бережливого управления считаются потерями.
Итак, два первых типа потерь – это операционные расходы: подготовительные (или начальные) и завершающие (или конечные).
Если вернуться к проблемам разработки ПО, то становится понятно, что у всех проектов есть свои подготовительные меры: планирование проекта, планирование ресурсов и набор персонала, бюджетирование, оценка, планирование рисков, планирование связи, приобретение необходимых мощностей и т. д. Большинство проектов имеют также завершающие мероприятия, тоже ведущие к операционным расходам: доставка товара потребителям, завершение работы со средами, ретроспективы, обзоры, аудиты, обучение пользователей и т. д.
Операционные расходы есть и у итераций: планирование итераций и выбор элементов бэклога (или рассмотрение требований), вероятно, оценка, бюджетирование, привлечение ресурсов и настройка сред. В то же время возможны операционные расходы на интеграции, поставку, ретроспективы и завершение работы со средами.
Координационные расходы
Координация необходима, если два или более человек пытаются вместе достичь общей цели. Чтобы улучшить координацию между людьми, мы изобрели язык и коммуникативные системы. Когда мы хотим встретиться с друзьями, чтобы вместе выпить, перекусить и посмотреть кино, мы несем координационные расходы. Все электронные письма, СМС и звонки, которые необходимы для организации встречи, относятся к координационным расходам.
Итак, координационные расходы на проект – это любые действия, связанные с общением и планированием. Когда сотрудники команд проекта жалуются, что не могут заниматься работой, которая приносит ценность, – например, анализом, разработкой или тестированием, – поскольку вынуждены вести переписку, они выполняют ряд координационных задач. Чтение каждого письма и ответ на него – это координационная деятельность. Если они жалуются, что не могут заниматься работой, которая приносит ценность, – например, анализом, разработкой или тестированием, – поскольку постоянно находятся на встречах, то это тоже координационная деятельность.
Любая форма встречи – это координационное мероприятие, включая любимые agile-сообществом стендапы. Исключение составляют совещания, которые ставят задачей получение ценности для потребителя. Если три разработчика собираются у доски и моделируют проект кода, который собираются реализовать, то это не координационная деятельность, а деятельность по созданию ценности. Дело в том, что она порождает информацию, необходимую для реализации функциональности, значимой для клиента.
Рассмотрим разработку программного обеспечения и систем как процесс поступления информации. Он начинается с отсутствия данных, а наличие полной информации соответствует работающей программе, функциональность которой отвечает потребностям и целям клиента. Тогда любая информация, поступающая в интервале между начальной и конечной точками и продвигающая нас на пути к созданию работающей функциональности, считается добавляющей ценность.
Если члены команды собираются для получения информации, создающей ценность, – дизайна, теста, части анализа, участка кода, – то такая встреча относится не к координационным расходам, а к работе по созданию ценности.
Однако если члены команды собираются для обсуждения статуса, распределения заданий или планирования, что помогает скоординировать действия и рабочий поток, то такая встреча – это координационные расходы и она должна считаться влекущей потери. Поэтому необходимо искать способы сократить или исключить координационные встречи.
Таким образом, пятиминутный стендап лучше 15-минутного, если в результате достигается одинаковый уровень координации. То же самое можно сказать про 15– и 30-минутные стендапы.
Можно попытаться сократить координационную деятельность, найдя другие, более эффективные способы координации работ.
Один из вариантов – дать членам команды полномочия для самоорганизации. Административно-командный тип управления, при котором сотрудники встречаются для предварительного распределения заданий, ведет к потерям. Самоорганизация обычно сокращает координационные затраты на проект. Однако для успешной работы требуется информация. Методы, используемые в Канбане (например, визуальный контроль цепочки создания ценности и визуализация работы на досках с карточками, в электронных инструментах и отчетах), дают достаточно информации для координации, что облегчает самоорганизацию и снижает координационные расходы на проект. Использование классов обслуживания и их визуализация разноцветными карточками или треками на доске наряду с соответствующими наборами правил для каждого класса обслуживания позволяет команде самостоятельно планировать работы и автоматизировать расстановку приоритетов. Иногда это называется самоускорением (я связываю этот термин с Элияху Голдраттом и управлением буферами).
Чем больше информации доступно членам команды, тем больше полномочий можно предоставить команде и тем меньше потребуется координационной деятельности. Позвольте прозрачности работы, потока, процесса и правил по управлению рисками заменить координационные действия. Сокращайте потери, активнее используя прозрачность.
Как узнать, что та или иная деятельность влечет за собой расходы
Как выяснилось, многие затрудняются с определением деятельности, вызывающей потери. Например, некоторые сторонники agile-методов считают, что ежедневные стендапы создают ценность. Я не разделяю этого мнения. Не могу представить себе клиента, которого волнует вопрос, проводит ли команда совещания на ходу. Клиентам нужна функциональность, которая воплощает их цели, поставляется в срок и обладает высоким качеством. Им совершенно безразлично, нужны ли для этого команде ежедневные совещания на ходу.
Так как определить приводящие к потерям операционные или координационные расходы?
Думаю, нужно спросить себя: «Если эта деятельность действительно создает ценность, то стоит ли тратить на нее больше времени?»
Спросите защитников Scrum, которые абсолютно убеждены, что стендапы создают ценность, не пора ли проводить их два раза в день или увеличить длительность с 15 минут до получаса. Наверняка все они ответят отрицательно. Я возражаю им: «Но ведь если стендапы действительно создают ценность, то увеличение времени должно пойти на пользу!»
Это лакмусовая бумажка, которая демонстрирует различия между настоящей деятельностью по созданию ценности и операционными или координационными расходами. Обработка большего количества клиентских требований определенно создает ценность. Можно отвести на эту обработку больше времени, и клиенты будут рады заплатить. Планирование точно не создает никакой ценности. Клиент не станет платить больше за дополнительное планирование, если может этого избежать.
Итак, спросите себя, стоит ли тратить на это больше времени? Задайте тот же вопрос другим людям, выполняющим свои задачи. Если ответ отрицательный, то подумайте, как сократить до минимума время и энергию, которые тратятся на эти задачи, или как сделать их более эффективными, тем самым сократив длительность, частоту или количество.
Иногда сложно определить, к операционным или координационным расходам относится данный вид деятельности. Некоторые задачи на первый взгляд подходят под обе категории. С этим я постоянно встречаюсь, обучая Канбану. Как и участникам занятий, я предлагаю вам не тратить силы, пытаясь осознать различия. Важно то, что вы определили деятельность как не создающую ценность (а следовательно, приносящую потери) и понимаете: эту деятельность нужно сократить или исключить в рамках программы по непрерывному совершенствованию.
«Ошибочная» нагрузка
«Ошибочная» нагрузка – это требования потребителя, которых можно избежать, если предыдущий релиз был высокого качества. Например, большое количество звонков в службу поддержки ведет к расходам. Если бы программный, технологический продукт или услуга имели высокое качество, были удобными, интуитивно более понятными и подходящими для целей пользователя, то звонков поступало бы меньше. Это позволило бы компании сократить персонал кол-центра, тем самым снизив расходы.
Множество звонков в службу поддержки приводит, как правило, к большому количеству задач по исправлению дефектов промышленной среды. При выборе функций, которые должны быть реализованы в проекте или итерации, руководство должно выбирать между новыми идеями и дефектами. Последние – это не только программные ошибки. К ним относятся удобство использования и другие нефункциональные проблемы, такие как плохая производительность, задержки при высокой нагрузке или в определенных сетевых условиях и т. д. Исправление дефекта промышленной среды по нефункциональным требованиям может выглядеть как новая функциональность (например, дизайна нового экрана), но это не так. Речь идет об «ошибочной» нагрузке. Дизайн нового экрана появился из-за того, что в прошлом релизе возникли проблемы с удобством эксплуатации.
«Ошибочная» нагрузка не создает новой ценности, а восполняет ту, которая осталась нереализованной после прошлого релиза. Вероятно, предыдущий релиз продукта или сервиса не справился с запланированной функцией. Хотя это бывает связано и с вариативностью или непредсказуемостью рынка, отчасти этот дефицит функционала возник из-за проблем предыдущих релизов. Ошибка в продукте не дает пользоваться какой-либо функциональностью, поэтому потенциальный потребитель либо не приобретает его, либо выбирает конкурирующий.
Итак, нарисовалась неясная картина. «Ошибочная» нагрузка все равно создает ценность. Но важно понять, что ценность к этому моменту уже должна быть создана. Снижение «ошибочной» нагрузки уменьшает возможные расходы из-за отсрочек. Сокращенные расходы означают, что прибыль начнет поступать раньше. Снижение «ошибочной» нагрузки значит, что можно обратить всю доступную мощность на новую функциональность, позволяет бизнесу работать в нескольких нишах рынка и предлагать больше продуктов, порождает больше возможностей и может сократить состав команды, что приведет к уменьшению прямых расходов.
Выводы
• Потери можно разбить на три основные абстрактные категории: операционные расходы, координационные расходы и «ошибочная» нагрузка.
• Концепция «потерь» является метафорой.
• Метафора потерь подходит не для всех случаев, поскольку часто потери необходимы, хотя и не создают конкретной ценности. В результате я заменил ее экономической моделью расходов.
• Чтобы определить, действительно ли данный вид деятельности влечет потери, спросите себя: «Стали бы мы при возможности отводить на него больше времени?» Если ответ отрицательный, то такая деятельность является той или иной формой потерь.
• Операционные расходы подразделяются на два типа: подготовительная деятельность и завершающая, или релизная, деятельность.
• Координационные расходы – это работа, цель которой – распределить задания между сотрудниками, спланировать встречи или скоординировать действия двух и более людей, направленные на достижение общей цели.
• «Ошибочная» нагрузка – это новая работа, создающая ценность, являющаяся следствием предыдущих неудачных действий (например, программного дефекта, плохого дизайна или внедрения), которые привели к неполноценному использованию продукта потребителем, невыполнению ключевой функции или существенному повышению количества обращений в службу поддержки.
• На работу над задачами «ошибочной» нагрузки тратится мощность, которую можно было использовать для реализации новых, инновационных, создающих дополнительную ценность функций, приносящих прибыль.
• Быстрое превращение идей в работающий, готовый для использования код увеличивает потенциальную ценность и минимизирует потери.
Глава 19 Источники вариативности
Вариативность в промышленных процессах изучается с начала 1920-х годов. Пионером в этой области был Уолтер Шухарт. Его методы заложили основу движения по управлению качеством и стали базой как для производственной системы Toyota, так и для метода «шесть сигм», обеспечивающих качество и непрерывное совершенствование. Методы Шухарта были взяты на вооружение, развиты и дополнены Эдвардсом Демингом, Джозефом Джураном и Дэвидом Чемберсом. Их работы вдохновили Уоттса Хамфри и основателей Института технологий разработки ПО Университета Карнеги – Меллон, которые считали, что изучение и систематическое снижение вариативности сулит большие преимущества для разработчиков.
Шухарт, Деминг и Джуран опубликовали множество работ по исследованию вариативности и ее использованию в качестве техники управления, а также как основания для программы усовершенствований. Кроме того, существует немало публикаций, рассказывающих о методе количественной оценки, известном как статистический контроль процессов (СКП) и ставшем основным средством изучения вариативности и борьбы с нею. Теперь СКП взят на вооружение и командами, использующими Канбан. Однако СКП и его применение считается более серьезной темой, к которой мы обратимся в одной из следующих книг. Здесь же только затронем проблему вариативности.
Шухарт разделял вариативность и вариации в производственных показателях на два типа – внутреннюю и внешнюю.
Внутренние источники вариативности – это вариации, которые находятся под контролем задействованной системы. В рамках Канбан-подхода к IT и разработке ПО мы определяем систему как процесс, который задается набором правил, управляющих ее эксплуатацией. Эти правила могут подвергнуться влиянию изменений, вносимых сотрудниками, командой или руководством. Изменения в правилах трансформируют и эксплуатацию системы, и ее производительность. Тем самым изменения в определении процесса – это изменения, которые затрагивают внутренние источники вариативности. Забавно, что такие внутренние вариации Шухарт назвал случайными. Слово «случайный» предполагает, что вариации имеют непредсказуемый характер, что является прямым следствием структуры системы. Но не предполагается, что непредсказуемость равномерно распределена или укладывается в рамки нормального распределения. Изменения в структуре процесса, вызванные изменениями внутренних правил, повлияют на медианное распределение, его распространение и форму.
Приведем пример. Отбивающий в бейсболе обладает коэффициентом ударов (известным также как средний уровень), который показывает, как часто он наносил удары, приводившие как минимум к взятию первой базы. У разных отбивающих разные коэффициенты, обычно они колеблются от 0,1 до 0,35. В любой день такой игрок может продемонстрировать показатели ниже своего среднего коэффициента ударов. Это зависит от ряда факторов: выбора питчера[13], коэффициента успешности ударов других игроков, а также от специфики подач.
Если изменить правила бейсбола так, чтобы соотношение шансов было в среднем в пользу отбивающего и не в пользу питчера, то средний коэффициент для отбивающих вырастет и лучшие игроки смогут достичь показателя, превышающего 0,5. Это пример модификации системы ради изменения случайных вариаций внутри нее.
Теперь приведем пример из области разработки. Пусть внутренняя, случайная вариация – это количество ошибок на строчку кода, требование, задачу или на единицу времени. Среднее количество, распространение и распределение ошибок или дефектов можно изменить, поменяв инструменты и процессы – допустим, введя модульное тестирование, непрерывную интеграцию и дружеские экспертизы программ.
Определение процесса, которое используется в вашей команде и выражено в виде правил, отражает правила совместной игры по разработке ПО. Они определяют источники и количество внутренних вариаций. Ирония состоит в том, что «случайные» вариации на самом деле находятся под полным контролем команды и руководства, которые могут изменять правила и процессы, тем самым влияя на источники внутренней вариативности.
Внешние источники вариативности – это события, происходящие вне зоны ответственности данной команды или ее руководителей. Это случайности, вносимые другими командами, поставщиками, потребителями, а также иные случаи «божественного вмешательства», как это называют в страховании: например, двухнедельный простой сервера, вызванный наводнением, в свою очередь, связанным с необычно сырой и ветреной погодой. Внешние источники вариативности требуют к себе особого подхода. Правила их не затрагивают, но можно учредить процесс, который эффективно справится с внешними вариациями. Отрасль знаний, относящаяся к этой сфере, называется управлением проблемами и рисками. Шухарт назвал внешние вариации «выявляемыми». Он имел в виду, что специалист (или группа специалистов) с легкостью укажет источник проблемы и даст его полное описание. Например: «Случилась буря, пошел сильный дождь, и наш сервер затопило». Вариации с выявляемыми причинами лежат вне сферы контроля конкретной команды или руководства, но их можно предсказать, составить план и разработать процедуры для того, чтобы с ними справиться.
Внутренние источники вариативности
Установленные процессы разработки ПО и управления проектами в сочетании со зрелостью организации и возможностями членов команды определяют количество внутренних источников вариативности и ее уровень.
Напомню, что Канбан – это не вариант жизненного цикла разработки ПО и не процесс управления проектами. Это метод управления изменениями, который требует перемен в существующем процессе – например, определения лимита незавершенных задач.
Размер единицы работы
Метод анализа, используемый для разделения требований и подготовки их к разработке, обладает собственным уровнем вариативности. Один из источников этого – размер единиц работы. В первых работах, описывающих метод экстремального программирования, пользовательские истории характеризуются как записанное на карточке повествовательное описание функции, которая должна быть внедрена и передана конечному пользователю. Единственное ограничение – размеры карточки. Считалось, что создание пользовательской истории могло длиться от полудня до пяти недель. За пару лет в лондонском сообществе выработался шаблон написания пользовательских историй.
Как <пользователь>, я хочу <функцию>, чтобы <создать некую ценность>.
Использование шаблона привело к стандартизации написания пользовательских историй. Один из авторов такого подхода, Тим Маккиннон, в 2008 году сообщил мне, что, по его данным, в среднем на создание пользовательской истории требуется 1,2 дня, а вариативность составляет от половины суток до примерно четырех дней.
Это конкретный пример сокращения случайных вариаций при методе экстремального программирования, когда команде предлагается стандартизировать написание пользовательских историй по определенному шаблону. Тем самым Тим изменил правила игры. В исходных правилах устанавливалось, что члены команды должны писать пользовательские истории на карточках в свободной форме. Теперь же карточки сохранялись, но требовалось следовать определенному шаблону изложения. Очевидно, что подобные изменения находятся в сфере влияния и контроля местных менеджеров. Для системы они являются внутренними. Размер пользовательской истории контролируется случайными вариациями.
Смешение типов единиц работы
Когда ко всем задачам относятся одинаково, к тому же приписывая их к одному типу, наблюдается большая вариативность размеров, усилий, риска или других факторов. Разбивая задачи на определенные типы, можно по-разному работать с последними, что обеспечивает большую предсказуемость.
Например, в сообществе экстремального программирования были разработаны определения типов для разных размеров историй. Они получили названия «эпик» и «песчинка». Эпик – это более крупная история, для работы с ней может понадобиться несколько человек и не одна неделя, а песчинка – небольшая история, которую могут реализовать один или два разработчика всего за несколько часов. Приняв такую номенклатуру – «эпик», «история», «песчинка», – мы получаем три разных типа. Для каждого из них разброс вариативности будет ниже, чем если бы все задания трактовались как относящиеся к одному типу.
В обычном отделе разработки ПО может решаться несколько типов задач. Например, работа по созданию новой потребительской ценности под названием «функция», «история» или «пользовательский сценарий». (Как уже говорилось, они могут быть стратифицированы по размеру, подтипу домена или профилю риска.) Или работа по устранению «производственных ошибок» и «внутренних ошибок». А может быть, и работа по обслуживанию – «рефакторинг», «переделка архитектуры» или просто «обновление».
Операционные системы, базы данных, платформы, языки, API и сервисные архитектуры со временем меняются. Для работы с этими изменениями нужно обновлять и код.
Используя методы определения разных типов единиц работы, мы можем изменить медиану и разброс вариативности, увеличив предсказуемость в системе для конкретного типа работы.
Еще одна стратегия по увеличению предсказуемости – назначение общей WIP-мощности для отдельных типов. Например, в моей команде обслуживания в Corbis были разрешены только две единицы IT-обслуживания одновременно. Это ограничивало мощность, потраченную на API и обновления базы данных. Такая стратегия особенно полезна, когда типы разделяются по размеру или требуемым усилиям – как, например, эпик, история или песчинка. Назначив конкретную мощность для каждого типа, вы сможете поддержать чуткость системы и увеличить предсказуемость.
Представьте себе команду, использующую канбан-доску, на которой отражен лимит в два эпика, восемь обычных историй и четыре песчинки. В работе два эпика. В очереди освобождается место для обычной истории, но в бэклоге ни одна из них не готова к началу работы. Команда должна решить, начать ли работу с эпиком (или песчинкой) либо придерживаться ранее заявленных типов, что вызовет простой.
Если начать эпик, а через несколько дней в бэклоге окажется обычная история, то они не смогут сразу же приступить к работе над ней. Это увеличит разброс времени выполнения для обычных историй.
Лучше начать работу над песчинкой, которая будет окончена еще до того, как появится следующая обычная история. В данном случае отрицательное влияние отсутствует, а пропускная способность увеличивается. Однако если сотрудникам не повезет и они не смогут закончить более мелкий элемент до того, как на подходе окажется следующая история, то время выполнения для обычных историй увеличится, хотя и не так значительно, как в случае с эпиком. Возможности повысить пропускную способность стоит предпочесть предсказуемость и управление рисками, поскольку владельцы бизнеса и высшее руководство особенно ценят предсказуемость. Она порождает и сохраняет доверие, которое в agile считается высшей ценностью. Этого не произойдет, если делать больше работы с меньшей степенью надежности.
Смешение классов обслуживания
Рассмотрим классы обслуживания, описанные в главе 11. Можно предположить, как скажется на вариативности смешение элементов. Если организация страдает от излишков ускоренных запросов, то они внесут существенную долю случайности во все остальные задания, увеличив среднее время выполнения и разброс вариативности, что снизит предсказуемость для всей системы.
Ускоренные запросы – это внешние вариации, поэтому они будут описаны в следующем разделе.
Если спрос на остальные классы обслуживания сравнительно устойчив, то время выполнения для каждого класса нужно строго соблюдать. Медиана и разброс вариаций должны быть измеримы и оставаться примерно постоянными, что обеспечивает предсказуемость. Этого можно достичь, если бэклог велик и в нем есть ассортимент задач каждого класса. Задайте WIP-лимит для каждого класса обслуживания. Это обеспечит сохранение медианы и разброса вариативности для каждого класса, так что система будет предсказуемой.
Если спрос переменен – например, существует лишь несколько элементов с фиксированной датой поставки, которые носят сезонный характер, – то нужно принять меры либо по формированию спроса, либо по контролю над ним. Например, можно объявить о сезонных изменениях в WIP-лимитах для каждого типа в соответствии с ожидаемым изменением спроса или об изменениях правил вытягивания задач, связанных с поступающими в работу классами обслуживания. Это необходимо, чтобы нейтрализовать значительные изменения спроса.
Рассмотрим пример команды с WIP-лимитом в 20 единиц, из которых 4 приходятся на единицы с фиксированной датой поставки, 10 – на элементы стандартного класса и 6 – на единицы нематериального класса. Можно либо установить правило, что этих более мелких лимитов нужно строго придерживаться, либо ослабить жесткость, чтобы стандартный или нематериальный элемент мог занимать место элемента с фиксированной датой поставки, когда сезонный спрос на такие элементы недостаточен. В разное время года эти правила могут меняться ради общего экономического выигрыша и обеспечения большей предсказуемости системы.
Нерегулярный поток
Нерегулярный поток работы может быть вызван как внешними, так и внутренними источниками вариативности. Каждый отдельный элемент, входящий в канбан-систему, будет отличаться от других как по природе, так и по размеру, сложности, профилю риска и требуемым усилиям. Такая естественная разница приведет к тому, что у вашего потока появятся приливы и отливы. Канбан-система справляется с ними естественным образом, как только вводятся WIP-лимиты. Однако еще большая вариативность, вызванная иными причинами, например разными размерами единиц работы, шаблонами спроса, смешением типов и классов обслуживания и внешними источниками, требует буферизации, которая могла бы нейтрализовать приливы и отливы задач в системе. При повышенной вариативности системы могут потребоваться дополнительные буферы, а WIP-лимиты, возможно, придется увеличить. Рост WIP-лимитов приведет к увеличению времени выполнения, но сглаживание потока должно снизить вариативность. Таким образом, увеличение WIP-лимита для придания потоку равномерности удлинит среднее время выполнения, но снизит разброс этого времени. Это предпочтительнее, поскольку менеджеры, владельцы и даже клиенты ценят предсказуемость больше, чем случайно удавшееся сокращение времени выполнения или повышение пропускной способности.
Переработка
Переработка, связанная как с внутренними ошибками, замеченными и исправленными до релиза, так и с производственными ошибками, внесенными в новую работу по созданию потребительской ценности, влияет на вариативность. Если доля ошибок известна, регулярно подсчитывается и остается почти на одном уровне, то можно так отладить систему, чтобы она успешно с этим справлялась. Подобная система будет экономически неэффективной, зато надежной. Недостаток предсказуемости получается, когда доля ошибок оказывается неожиданной. Незапланированная переработка ввиду ошибок увеличивает время выполнения, обычно повышает разброс вариаций и существенно снижает пропускную способность. Судя по всему, очень сложно даже планировать определенную долю ошибок (например, восемь ошибок на пользовательскую историю), не говоря уж о том, чтобы уметь точно предсказать их размер и сложность. Лучшая стратегия по снижению вариативности из-за ошибок – неустанно стремиться к высокому качеству и выдавать результат, содержащий очень мало оплошностей.
Внесение изменений в жизненный цикл разработки ПО может серьезно повлиять на долю ошибок. Использование дружеской экспертизы, парного программирования, модульных тестов, автоматизированных платформ тестирования, непрерывной (или очень частой) интеграции, небольших размеров пакетов, четко определенной архитектуры и хорошо продуманного, слабо связанного дизайна кода существенно уменьшит число ошибок. Изменения, непосредственно влияющие на долю ошибок и опосредованно повышающие предсказуемость системы, находятся под контролем как местного руководства, так и самой команды.
Внешние источники вариативности
Внешние источники вариативности лежат вне сферы прямого контроля процесса разработки ПО или метода управления проектами. Некоторые из них поступают из других областей бизнеса или цепочки создания ценности: их причиной, например, могут быть поставщики или клиенты. Среди других внешних источников есть элементы физического мира, которые не так-то легко предугадать, предсказать или контролировать, – например, отказ техники или неблагоприятные погодные условия.
Двойственность требований
Плохо прописанные требования и бизнес-планы и отсутствие стратегического планирования, предвидения или другой задающей контекст информации способны привести к тому, что член команды не сможет принять решение, а следовательно, и закончить свой кусок работы. Единица работы из-за невозможности принять решение оказывается блокированной. Для прояснения ситуации требуется новая информация, которая поможет члену команды принять правильное решение, так что незавершенные задания направятся дальше, к своему завершению.
Чтобы сократить негативное влияние подобной блокировки, команде и непосредственному руководству нужно внедрить эффективные процедуры управления проблемами и их разрешения, что описано в главе 20.
По мере того как команда и организация взрослеют, можно заняться анализом первопричин и их устранением. Блокирующие проблемы, вызванные двусмысленными требованиями, решаются непосредственным воздействием на аналитические процессы, которые используются в разработке требований, и совершенствованием способностей и навыков тех, кто эти требования создает. Подобные меры нуждаются в привлечении других подразделений и менеджеров, а также в желании бизнеса совершенствоваться.
В 2007 году в Corbis это достигалось постепенно. Сначала внедрили канбан-систему – визуальную доску и электронное средство отслеживания. Вместе с этим пришла прозрачность. Бизнес оказался сильнее вовлечен в процесс разработки ПО и в наблюдение за производительностью этого подразделения. Создавались отчеты, демонстрирующие количество нерешенных проблем и заблокированных единиц работы, а также среднее время разрешения этих задач. (Рис. 12.6. Отчет о проблемах и заблокированных единицах работы)
Когда требование проделало путь до приемочного тестирования, но было отвергнуто, поскольку оказалось ненужным бизнесу, команда ответила на это, выделив на доске мусорную корзину и прикрепив к ней талон, как показано на рис. 19.1. После этого руководство попросило создать несколько электронных отчетов о работе, которая поступила в систему, но не смогла проделать весь путь по ней (рис. 19.2).
Рис. 19.1. Доска с мусорной корзиной
Рис. 19.2. Отчет о непринятой и отмененной работе, демонстрирующий незавершенные рабочие единицы за прошлый месяц
Сочетание прозрачности, отчетности и сознания ответственности за отрицательное влияние (в том числе экономическое) неудачных требований привело к тому, что бизнес сознательно изменил поведение. Изначально отчет о потерях, который демонстрировал эффект от неудачных требований, содержал от пяти до десяти единиц в месяц. К пятому месяцу он опустел. Бизнес понял: если относиться к созданию требований внимательнее, то можно будет не разбрасываться мощностью. Они добровольно согласились сотрудничать, чтобы добиться лучших системных результатов. В итоге удалось исключить первопричины выявляемых вариаций из-за плохо написанных требований или неудачно определенной контекстуальной информации.
Хотя команда разработки ПО приняла меры по достижению большей прозрачности и ответственности, они не затронули процесс разработки требований. Просто процесс управления проблемами и их решения нейтрализовал негативное влияние блокирующих вопросов: команда стала ответственнее и сократила время разрешения проблем. В результате снизилось отрицательное влияние на среднее время выполнения и разброс вариативности. Прозрачность и отчетность привели к внешним изменениям процесса, что устранило первопричину проблемы.
Это один из примеров того, как локально предпринятые меры косвенно влияют на вариации с выявляемой причиной.
Ускоренные запросы
Ускоренные запросы – результат внешних событий, таких как неожиданный заказ клиента, или неполадок во внутренних процессах компании, например коммуникативной ошибки, которая приводит к слишком позднему обнаружению какого-то важного требования. Ускоренные запросы – это вариации с выявляемыми причинами, поскольку причина запроса всегда известна, а следовательно, «выявляема».
В промышленном производстве ускорение считается отрицательным фактором. Оно влияет на предсказуемость других запросов, увеличивает среднее время выполнения и разброс вариативности, а также сокращает пропускную способность. Данные, полученные за 2007 год в Corbis, показали, что это верно и для процессов разработки ПО: ускорение нежелательно, даже если проводится с целью создания ценности.
Необходимость в ускорении можно сократить. Увеличение резервной мощности благодаря усовершенствованию пропускной способности, автоматизации или увеличению ресурсов повысит способность к реагированию. Более короткое время выполнения, высокая прозрачность и организационная зрелость – все это снизит необходимость в ускорении. Хорошие команды, усвоившие Канбан-подход, обычно не злоупотребляют ускоренными запросами. Например, в Corbis за весь 2007 год их было всего пять.
Как и в случае с плохо написанными требованиями, можно надеяться, что прозрачность процесса и полная информация о пропускной способности, времени выполнения и доле выполнения в срок повлияет на поведение партнеров выше по цепочке. Есть вероятность, что спрос будет сформирован так, чтобы с самого начала было понятно: требование лучше выполнить в рамках обычного класса обслуживания, а не в виде ускоренного запроса.
Один из способов вызвать такие изменения – договориться об ограничении числа ускоренных запросов, которые могут быть обработаны в любой момент. В Corbis этот лимит равнялся одному. Отказывая бизнесу в возможности ускорить все подряд, вы заставляете партнеров выше по цепочке (из отдела продаж или маркетинга) искать возможности и эффективно их оценивать. Если продажники получают комиссию, которая рассчитывается на основе получаемой прибыли, то невозможность ускорить запрос сильно ударит по ним.
Если это происходит из-за превышения WIP-лимита на ускоренные запросы, то в будущем они постараются собрать больше информации и вовремя разместить запрос, чтобы он мог попасть в обычный класс обслуживания. Это еще один пример внутренних мер, которые можно предпринять для косвенного влияния на выявляемые причины вариации. Изменение в системном дизайне, которое призвано сократить внутренние случайные вариации, оказывает влияние и на внешние вариации с выявляемыми причинами.
Нерегулярный поток
Уже упоминалось, что нерегулярный поток работы бывает вызван вариациями и со случайными, и с выявляемыми причинами. Вариации с выявляемыми причинами, воздействующие на поток, приводят к заблокированным заданиям.
Часто причинами заблокированных по выявляемым причинам задач становятся двусмысленные требования, а также очередь на доступ к общей среде или общему специалисту.
Блокированные рабочие единицы требуют строгой дисциплины и опыта в управлении проблемами и их разрешении, о чем говорится в главе 20. Есть два способа решения проблемы заблокированных рабочих единиц.
Первый восстанавливает поток за счет времени выполнения и даже качества. Вы можете восстановить поток, увеличив общий WIP-лимит – либо установив буфер напрямую, либо задав менее жесткие правила ограничения незавершенных задач: например, 3, а не 1,2 элемента в среднем на человека. Больший WIP-лимит подразумевает, что, пока одна задача блокирована, члены команды могут работать над остальными. Такой подход рекомендуется недостаточно зрелым организациям. Эффект от него прост и лишен драматизма. Время выполнения будет больше, но во многих отраслях это не составляет проблемы. Сильнее может оказаться и разброс вариативности, так что время выполнения окажется менее предсказуемым. Однако благодаря использованию канбан-системы оно все равно будет более предсказуемым, чем раньше. Главный недостаток использования больших WIP-лимитов в том, что так почти (или совсем) не создается внутренней напряженности, которая вызвала бы обсуждения и внедрение улучшений. Нет стимула к совершенствованию, эффект канбана как катализатора утрачивается.
Второй подход связан с неукоснительным проведением политики управления проблемами и их разрешения и, по достижении зрелости команды, с переходом к анализу и устранению первопричин, а также внесению улучшений, направленных на предотвращение вариаций с выявляемыми причинами в будущем. При таком подходе WIP-лимиты, размеры буфера и действующие правила остаются достаточно жесткими, и если задача блокируется, то это останавливает всю работу. Простой сотрудников, назначенных на блокированную задачу, повышает ответственность за блокирующую проблему. После этого может начаться массовая атака на проблему, что, как было установлено, стимулирует простаивающих членов команды думать о первопричинах и возможных изменениях в процессе, которые смогут сократить или исключить возможность новой подобной проблемы. Как показывает практика, сохранение жестких WIP-лимитов и проведение мероприятий по управлению проблемами и их разрешению позволяет создать культуру непрерывного совершенствования. Впервые я столкнулся с этим в Corbis в 2007 году, но есть и другие данные, полученные в 2009 году в таких компаниях, как Software Engineering Professionals (Индианаполис), IPC Media и BBC Worldwide (обе из Лондона). Сейчас уже достаточно информации, позволяющей предположить, что Канбан действительно способствует появлению культуры, сосредоточенной на непрерывном совершенствовании. Среди постоянно появляющихся элементов процесса, которые можно привести в пример, – готовность устанавливать жесткие правила WIP, маркировать работу как заблокированную, позволять потоку останавливаться, вызывая простой, и заниматься управлением проблемами и их решением в качестве устоявшейся организационной практики. Результат – сосредоточение на анализе и устранении первопричин и постепенное внедрение усовершенствований, которые снижают вариации с выявляемыми причинами и помогают распространению культуры непрерывного совершенствования.
Доступ к среде
Доступ к среде – типичный вид проблемы с выявляемой причиной, которая может оказать существенное влияние на поток, пропускную способность и предсказуемость. Отказ среды часто останавливает весь рабочий поток. С помощью канбан-системы эта проблема и ее воздействие становятся нагляднее. Простой, вызванный заданием WIP-лимита, стимулирует совместные действия по ее решению. Когда коллеги выше по цепочке, например разработчики и тестировщики, помогают операторам системы восстановить среду, такое поведение часто называется роением. Роение – это ситуация, когда вся команда собирается вместе и работает над единственной проблемой до полного ее разрешения. Природа Канбана позволяет командам сосредоточиться на времени выполнения, пропускной способности и потоке на протяжении всей цепочки создания ценности. Соединив усилия всех групп на разных отрезках цепочки создания ценности для достижения общей цели, мы порождаем стимул, чтобы наброситься на проблему со всех сторон, целым «роем». Все выигрывают от того, что простаивающие сотрудники добровольно помогают решить проблему, которая воздействует на них, даже если это выходит за рамки их должностных обязанностей.
Другие рыночные факторы
В октябре 2008 года вслед за крахом Lehman Brothers и ряда других драматических событий в финансовом секторе банки и инвестиционные компании таких ведущих финансовых центров, как Лондон и Нью-Йорк, стали отменять или видоизменять IT-проекты, находившиеся в разработке. Причина была в том, что их мир рушился и они боролись за выживание как могли. Внезапно выяснилось, что нужно лучше понять собственную – и общерыночную – ликвидность. Оказалось, что предлагать новейшие или экзотичные товары и услуги неактуально. Рынок больше не интересовался инвестициями. Осенью 2008 года финансовые предприятия беспокоились исключительно о собственной платежеспособности или ее отсутствии.
Это конкретный пример того, насколько серьезно могут измениться проектные портфели и требования к проекту в процессе работы. Необходимость реагировать на подобные изменения обычно отвлекает команды, что приводит к существенным потерям в пропускной способности, значительному увеличению времени выполнения, а нередко и к потере качества, отсутствию предсказуемости, поскольку команде нужно справиться с хаосом, который рыночные колебания вносят в проект.
Разумеется, эти события относятся к вариациям с выявляемыми причинами. Их требуется нейтрализовать при помощи стратегии и тактики управления рисками. Существуют достаточно серьезные наработки по вариациям с выявляемыми причинами, или событийному риску. Наличие опыта в управлении рисками как часть общей цели повышения зрелости организации улучшит предсказуемость разработки как при использовании Канбана, так и без него. Однако канбан-системы демонстрируют большую предсказуемость при хорошем управлении рисками. Это порождает внутрисистемное доверие.
В канбан-системах есть и другие элементы, которые помогают при управлении рисками. Так, WIP-лимит снижает риск, поскольку в любое время в работе находится лишь небольшое число задач. Назначение WIP-лимитов для отдельных типов рабочих единиц и классов обслуживания позволяет управлять рисками и нейтрализовать вариации с выявляемыми причинами. Появляются и другие стратегии. Судя по всему, выйдут в свет и новые книги, где будут подробно описаны передовые методы внедрения Канбана и современные тактики управления рисками.
Некоторые материалы по управлению рисками в канбан-системах, появившиеся в результате использования Канбана, я представлял на конференциях в 2009 году. Они доступны в интернете.
Трудности с координацией
Еще один распространенный источник вариаций с выявляемой причиной, который блокирует работу и лишает поток равномерности, – это координация с внешними командами, заинтересованными лицами и ресурсами. Обычная реакция на проблемы координации – планирование совещаний с регулярной каденцией. В определенных случаях это очень эффективное решение, но оно не всегда возможно.
Поток может быть прерван ограничениями, которые установлены правительственными органами или нормативными документами, требующими проведения аудита или утверждения документа. Люди, которые должны выполнять эту функцию, часто недоступны или не располагают свободным временем.
Сначала вариации с выявляемыми причинами такого рода нужно нейтрализовать, повысив осведомленность сотрудников и обратив общее внимание на этот фактор при помощи наглядности и прозрачности. Маркировав элементы как заблокированные и наглядно продемонстрировав источник блокировки, руководство, команда и другие участники цепочки создания ценности осознают воздействие этих координационных проблем.
Такое осознание должно привести к поведенческим изменениям, улучшающим ситуацию.
Одна из возможных тактик – изучение правительственных и регуляторных норм с целью определить, что именно должно подвергнуться оценке, одобрению, аудиту и изучению. Если предположить, что существуют разные профили риска, которые дают возможность распределить задания на две категории – «необходимо согласовать» и «необязательно согласовывать», – то для разбивки задач можно использовать типы рабочих единиц либо классы обслуживания. После этого стоит задать отдельные WIP-лимиты как для типов, так и для классов для обеспечения равномерности потока.
Выводы
• Изучение вариативности в промышленных процессах началось в 1920-е годы с Уолтера Шухарта. В середине и конце XX века его дело продолжили и развили Эдвардс Деминг, Джозеф Джуран и Дэвид Чемберс.
• Изучение вариативности и связанный с ним метод статистического анализа лежит в основе производственной системы Toyota (а следовательно, и бережливого управления) и метода «шести сигм» для совершенствования процесса.
• Работы Эдвардса Деминга и Джозефа Джурана – главный источник вдохновения для Института технологий разработки ПО Университета Карнеги – Меллон и модели зрелости возможностей (современное название – «интегрированная модель зрелости», или CMMI).
• Шухарт разделил источники вариативности на две категории: внутренние для процесса или системы и внешние для процесса или системы.
• Внутренние вариации называются вариациями со случайными причинами.
• Внешние вариации называются вариациями с выявляемыми причинами.
• В цепочке создания ценности жизненного цикла разработки ПО может быть много источников вариаций со случайными причинами. Типичные примеры – размер рабочей единицы, тип, класс обслуживания, нерегулярный поток и переработка.
• Список источников вариаций с выявляемыми причинами, возможно, бесконечен. Типичные примеры – двусмысленные требования, ускоренные запросы, доступность среды, нерегулярный поток, рыночные факторы, факторы персонала и проблемы с координационной деятельностью.
• Вариации со случайными причинами можно контролировать, задав правила, определяющие жизненный цикл разработки ПО и используемые процессы управления проектами.
• Вариациями с выявляемыми причинами можно управлять, развив способности к управлению проблемами и их разрешению, а также способности к управлению рисками. Такие вариации можно сократить или ликвидировать благодаря анализу и устранению первопричин.
• Канбан-системы приводят к более благоприятным экономическим результатам, если с ними сочетается умелое управление событийными рисками.
• Канбан также предлагает дополнительные способы управления рисками – например, назначение WIP-лимитов для классов обслуживания и типов рабочих единиц, использование профилей риска для разбивки задач на типы или классы и действия в соответствии с ними.
• Предстоит еще много работать над передовыми стратегиями и тактиками управления рисками в Канбане – это станет темой следующей книги.
Глава 20 Управление проблемами и правила эскалации
Когда работа в нашей канбан-системе оказывается заблокированной, обычно на стене к карточке, содержащей причины блокировки, прикрепляется розовый стикер. В электронных системах могут существовать и другие способы визуализации факта блокировки: например, карточки обводят красной рамкой. Предпочтительно, чтобы функции электронной системы позволяли отдельно указывать причины блокировки или связывать проблему с пользовательскими запросами, которые зависят от решения этой проблемы.
Я заметил, что некоторые новички в использовании Канбана считают заблокированные задачи бутылочными горлышками. Это неверно. Заблокированная задача действительно образует затор, ограничивающий поток. Но он не относится к бутылочным горлышкам, описанным в главе 17, так как это не ресурс ограниченной мощности и не ресурс с ожиданием доступа. Точно так же пробка – это вовсе не бутылочное горлышко. Чтобы возобновить поток жидкости из бутылки, надо попросту вынуть пробку.
Считать заблокированные задачи бутылочными горлышками даже опасно, поскольку это ведет к неправильному подходу к решению проблемы. Блокированные задачи – это вариации с особой причиной. Их единственное сходство с бутылочными горлышками – желаемый результат. В обоих случаях нам нужно решить определенную проблему, чтобы снова сделать поток равномерным.
Заблокированные задачи требуют от организации умелого управления проблемами и способности решать их, чтобы быстрее возобновить поток, а также осуществлять анализ первопричин и устранять их, чтобы те же проблемы не возникали вновь. О последнем навыке говорилось в главе 19 (устранение вариаций с особыми причинами). А управление проблемами обсудим в этой главе.
Управление проблемами
Недостаточно просто отметить задачи как заблокированные. Однако многие первые инструменты гибкой разработки ПО давали лишь эту возможность. Знать, что задача, пользовательская история, функция или сценарий заблокированы, полезно. Но наблюдая за командами программистов со всего мира, я пришел к следующему выводу: понимать, что нечто заблокировано, – это еще не значит уметь разблокировать.
Важно указать причину блокировки и считать разблокирование приоритетной задачей, даже если это создает ложную нагрузку. К задаче имеет смысл привязывать отдельную сущность – «проблему». «Проблемы» визуализируются, например, при помощи розовых карточек (рис. 20.1). Им должен быть присвоен номер и определен ответственный исполнитель – обычно это менеджер проекта.
Рис. 20.1. Розовая карточка, описывающая блокирующую проблему (или препятствие) и прикрепленная к пользовательскому запросу на изменение, которое эта проблема затрагивает
Когда сотрудник, занимающийся пользовательским запросом, не может продолжить работу, он должен отметить задачу как заблокированную, прикрепить к ней розовую карточку с перечнем причин блокировки и создать «проблему» в электронной системе управления задачами. «Проблема» должна быть связана с исходной задачей (рис. 20.1). Вот некоторые примеры: двусмысленность требований (причем эксперт, который мог бы немедленно устранить двусмысленность, недоступен); требуется создание среды, а инженер, который может этим заняться, недоступен; для работы с задачей нужен узкий специалист, но он болен, находится в отпуске или отсутствует в офисе по иным причинам.
Как уже говорилось в главе 7, тема поддержания равномерного потока должна быть основной на ежедневных встречах команды. Команде следует сосредоточиться на обсуждении блокировок и прогресса в решении проблем. Особое внимание нужно уделять розовым карточкам. Задавайте вопросы о том, кто работает над устранением проблемы и каковы их успехи, нужно ли эскалировать проблему и если да, то кому.
Простаивающих членов команды следует мотивировать на то, чтобы они добровольно взялись устранять проблемы, коллективно обсуждали их и помогали решать, тем самым восстанавливая равномерность потока. Команда с мощной самоорганизацией именно так и будет действовать, люди сами захотят помочь. Но если такой самоорганизации пока нет, то менеджеру проекта придется назначить членов команды для решения проблем.
Проблемы нужно фиксировать, как и все остальные задачи. В информацию для их отслеживания необходимо включить даты начала и окончания работы и ссылку на все затронутые пользовательские запросы. При этом одна проблема может блокировать несколько других задач. Это еще одна причина, чтобы учитывать проблемы как независимые задачи и создать отдельный тип задач – «проблема».
Выбирая электронный инструмент для визуализации канбан-системы, убедитесь, что он позволяет оформлять проблемы как задачи или настроен так, чтобы можно было создать новый тип задачи – «проблему», и задать его отражение в виде розовых или красных карточек.
Эскалация проблем
Если команда не может самостоятельно справиться с ситуацией или для этого требуется другая сторона, которая в данный момент недоступна, то проблему нужно передать выше по инстанции – старшему руководителю или в другой отдел.
Организация должна создать и согласовать механизм эскалации проблем. Без него поддержание и восстановление потока после блокировки усложняется.
Налаженный механизм эскалации – это задокументированные правила и процедуры передачи проблем. В главе 15 говорилось о том, как эффективна совместная разработка организационных правил. Правила эскалации тоже следует выработать совместно, и необходим консенсус между всеми подразделениями, участвующими в цепочке создания ценности. Кроме того, правила эскалации должны быть известны всем работникам, а документ (или сайт), где они описываются, – доступен всем членам команды. Никакой двусмысленности в отношении эскалации проблемы не допускается. Потратив время на определение способов эскалации и создание соответствующих правил, команда обретает понимание того, куда адресовать проблемы. Это уменьшает время принятия решения, кому именно эскалировать проблему, и создает у этих вышестоящих сотрудников понимание, что они непосредственно участвуют в процессе разрешения проблем. Руководители должны взять ответственность за решения на себя. Это поможет поддерживать поток и минимизировать расходы из-за простоя (или компенсировать расходы быстрой поставкой).
Учет проблем и отчетность по ним
Как уже говорилось, проблемы нужно фиксировать как задачи и выделять в собственный тип. Для визуализации проблем обычно используют розовые и красные карточки или стикеры (рис. 20.2). Дата начала, дата окончания, ответственный сотрудник, описание проблемы и ссылки на заблокированные задачи и пользовательские запросы – вот минимальный набор требований к визуализации проблем (рис. 20.3).
Рис. 20.2. Доска, на которой показано несколько блокирующих проблем, влияющих на различные функции
Рис. 20.3. Кумулятивная диаграмма потока с наложенным графиком проблем
Полезными для учета могут оказаться также трудозатраты по решению проблемы, история назначения сотрудников, информация о пути эскалации проблемы, предполагаемое время разрешения, оценка негативного влияния и предлагаемые варианты устранения первопричин, препятствующие повторному возникновению проблемы.
Хотя розовые карточки на доске наглядно демонстрируют, сколько задач заблокировано на данный момент, полезно также фиксировать проблемы и сообщать о них иными способами. Кумулятивная диаграмма потока с указанием количества заблокированных задач – хороший визуальный индикатор возможностей организации по оперативному решению проблем.
Тренд по количеству заблокированных задач показывает, насколько компания развила способность к анализу и устранению первопричин – умению ликвидировать вариации с особыми причинами. Табличная форма отчета о текущих проблемах, назначенных сотрудниках, статусе, предполагаемой дате решения проблем, затронутых задачах и потенциальном негативном влиянии на бизнес тоже может оказаться полезной в крупных проектах.
Такие отчеты следует готовить к операционному обзору, на котором выделяют время для обсуждения возникновения и становления возможностей организации в области управления проблемами и их решения, а также анализа и устранения первопричин. Организация должна понимать вред избыточной нагрузки, возникающей из-за блокирующих проблем. Это позволит принимать объективные решения о возможностях совершенствования и осознать вероятные преимущества инвестирования в устранение первопричин для предотвращения вариаций с особыми причинами.
Выводы
• Канбан-системы должны иметь особый тип задач – «проблема», который используется для учета проблем, блокирующих другие задачи, создающие ценность для потребителей.
• В обиход вошло использование розовых или красных стикеров на стене карточек для визуализации проблем.
• Розовые карточки прикрепляются к заблокированным задачам.
• Способность организовать эффективный процесс идентификации и устранения проблем необходима для поддержания равномерности потока.
• Заблокированные задачи и проблемы – это не бутылочные горлышки. Их нужно считать вариациями с особыми причинами, а не ресурсами ограниченной мощности или ресурсами с ожиданием доступа.
• Управление проблемами должно стать главной темой ежедневных встреч команд.
• Своевременная эскалация проблем – неотъемлемая часть умения управлять ими.
• Правила эскалации должны быть четко определены и задокументированы, а члены команд – иметь к ним доступ.
• Правила эскалации гораздо эффективнее, если совместно разработаны всеми подразделениями, участвующими в цепочке создания ценности.
• Проблемы должны фиксироваться электронно.
• Отчеты на основе электронных данных облегчат повседневное управление проблемами и их решение в крупных проектах.
• Использование кумулятивной диаграммы потока с наложенным графиком проблем позволяет визуализировать развитие способностей к управлению проблемами и их решению и к анализу и устранению первопричин.
Благодарности
Каждая изданная книга – это результат серьезных усилий по координации и управлению проектом, в которое вовлечена целая команда, и роль автора здесь ограниченна. И эта книга не вышла бы в свет без упорного труда Дженис Линден-Рид и Вики Роулэнд. Я хочу сказать им спасибо за безграничное терпение и настойчивость, благодаря которым рукопись попала в печать несмотря на жесткий дедлайн (и высокие расходы из-за отсрочки).
Хотелось бы также упомянуть Дональда Рейнертсена, который предложил попробовать Канбан и предоставил площадку для публичного выступления по этому поводу. Спасибо ему за теплые слова в предисловии и за создание жизнеспособного сообщества в Lean Software & Systems Consortium.
Я благодарю Карла Скотлэнда, Джо Арнольда, Аарона Сандерса, Эрика Уиллеке, Криса Шинкла, Олава Маассена, Криса Мэттса и Роба Хэтэуэя. Энтузиазм этих ранних последователей Канбана привел к созданию процветающего ныне сообщества и вирусному распространению этого метода по всему земному шару. Без их поддержки на мою рукопись не было бы спроса, а Канбан остался бы малоизвестным методом, применяемым в нескольких компаниях на северной части Тихоокеанского побережья США. Никто не знал бы о прекрасном новом подходе, который теперь взят на вооружение командами по всему миру – от стартапов из пяти человек в Камбодже до нидерландских страховых агентств с трехсотлетней историей, от крупных нефтяных компаний в Бразилии до поставщиков-аутсорсеров в Аргентине, а также медиакомпаний в Лондоне, Лос-Анджелесе, Нью-Йорке и по всему миру. Усвоение Канбана – это свершившийся факт, и он не стал бы реальностью, если бы не случайная встреча специалистов в августе 2007 года в Вашингтоне на конференции Agile 2007.
Эта книга не была бы такой интересной и полезной без тщательно продуманных комментариев и конструктивных отзывов многих рецензентов. Особенно я хотел бы отметить Дэниэла Ваканти, Грега Бруэма, Кристину Скаскив, Криса Мэттса, Брюса Маунта, Норберта Винкларета и Дженис Линден-Рид. Все они написали рецензии на первые версии рукописи, что привело к ее существенной реструктуризации. В результате книга стала гораздо лучше: ее проще читать и понимать и она дольше останется важным инструментом для сообщества.
Также в ходе создания этой рукописи – с 2009 по 2010 год – многие члены сообщества делились своими отзывами и предлагали поправки, которые я внимательно анализировал. Благодарю Джима Бенсона, Маттиаса Болена, Джошуа Кериевски, Криса Симмонса, Денниса Стивенса, Арне Роока, Маттиаса Скарина, Билла Барнетта, Олава Маассена, Стива Фримена, Дерика Бейли, Джона Хейнца, Лилиан Нийбур, Си Алхира, Сиддхарту Говиндараджа, Расселла Хили, Бенджамина Митчелла, Дэвида Джойса, Тима Уттормарка, Аллана Келли, Эрика Уиллеке, Алана Шэллоуэя, Элиссон Вейл, Максуэлла Килера, Гильерме Аморина, Рени Элизабет Пиль-Фриис, Ниса Хойста, Карла Скотлэнда и Роберта Хэтэуэя.
Хочу сказать спасибо и своему неутомимому офис-менеджеру Микико Фуджисаки, которая заправляет делами в компании David J. Anderson & Associates и без которой у меня так и не нашлось бы времени написать эту книгу.
Мой старый друг и коллега Пуджан Рока любезно предложил проиллюстрировать обложку. Пуджан – талантливый художник комиксов и автор двух значительных книг о менеджменте. Больше узнать о нем и его публикациях можно на сайте /.
Сообщество с таким энтузиазмом встретило мою работу о Канбане, что последовали предложения перевести ее на другие языки. Я хотел бы поблагодарить Жана Пиккара де Мюллера, Андреа Пинту, Эдуардо Бобсина, Арне Роока, Маса Маэда и Хироки Кондо, которые уже работают над французским, португальским (в бразильском варианте), немецким, испанским и японским переводом. Уверен, что их усилия будут способствовать распространению Канбана по всему миру, расширению сообщества и росту энтузиазма по поводу этого метода в различных регионах.
Я хотел бы выразить признательность Николь Кохари, Крису Хефли, Дэвиду Джойсу, Томасу Бломсету, Джеффу Паттону и Стиву Риду – они поделились иллюстрациями, использованными в этой книге.
Наконец, я хочу поблагодарить своего друга Драгоша Думитриу, который теперь работает в Avanade, и свою команду Corbis: Даррена Дэвиса, Ларри Коэна, Марка Гротте, Доминику Деграндис, Троя Мадженниса, Стюарта Коркорана, Рика Гарбера, Кори Ладаса и Дайану Коломиец. Без этих людей Канбан бы не состоялся. Их усилия по внедрению и использованию этого метода создали основу для примеров и историй, на которых мы учились и в итоге видоизменяли и адаптировали решения для новых, более сложных ситуаций. Без них не было бы книги, сообщества, растущего числа довольных потребителей, имеющих возможность регулярно и быстро получать высококачественные программы в нужное время и в нужном месте, с определенной гибкостью и в соответствии со спросом их отрасли и пользовательской базы.
Наше путешествие в Канбан продолжается, и я надеюсь, что эта книга убедила вас принять в нем участие.
Дэвид АндерсонВ процессе популяризации Канбана где-то в Европе, апрель 2010 годаОб авторе
Дэвид Андерсон – основатель учебных заведений Lean Kanban University и David Anderson School of Management, помогающих руководителям и менеджерам добиваться лучших результатов с помощью передовых методик. Он создатель Ассоциации руководителей agile-проектов (Agile Project Leadership Network, APLN), один из отцов Lean Software and Systems Consortium и модератор нескольких онлайн-сообществ по бережливому и гибкому программированию.
У Андерсона 30-летний опыт работы в технологичных компаниях. Он внедрял гибкие методы управления в таких компаниях, как Motorola и Microsoft.
Дэвид был первым, кто использовал Канбан в разработке ПО, – в 2005 году.
Эту книгу хорошо дополняют:
Scrum. Революционный метод управления проектами
Джефф Сазерленд
Управление продуктом в Scrum
Роман Пихлер
Постигая Agile
Эндрю Стеллман и Дженнифер Грин
Сноски
1
Теория ограничений – популярная методология управления производством, разработанная в 1980-е годы Элияху Голдраттом, в основе которой лежит нахождение и управление ключевым ограничением системы, которое предопределяет успех и эффективность всей системы в целом. Прим. ред.
(обратно)2
WIP – work in progress, число незавершенных задач. Прим. ред.
(обратно)3
Chief Executive Officer – главный исполнительный директор (генеральный директор). Прим. ред.
(обратно)4
Ошибкой первого рода называется ошибка, состоящая в опровержении верной гипотезы. Ошибкой второго рода называется ошибка, состоящая в принятии ложной гипотезы. Прим. ред.
(обратно)5
В Канбане обычно используются теория ограничения систем, системное мышление – понимание вариативности по Эдвардсу Демингу, и концепция муда (потери) из производственной системы Toyota. Модели, используемые в Канбане, постоянно развиваются, а в некоторых реализациях применяются идеи и из других областей – например, социологии, психологии или управления рисками. Прим. ред.
(обратно)6
В сообществе экстремального программирования были разработаны определения типов для разных размеров историй. Они получили названия «эпик» и «песчинка». Эпик – это более крупная история, для работы с ней может понадобиться несколько человек и не одна неделя. Прим. ред.
(обратно)7
Голдратт Э., Кокс Дж. Цель: процесс непрерывного улучшения. М.: Попурри, 2014.
(обратно)8
Залив, на берегу которого расположен Сиэтл. Прим. ред.
(обратно)9
В момент написания книги ученые начали исследовать отношения между временем выполнения и объемом внесенных ошибок. Надеюсь, что в 2010 году уже будут опубликованы какие-то научные работы, которые подтвердят мое убеждение, что время выполнения связано с количеством ошибок нелинейным образом.
(обратно)10
Standard CMMI Appraisal Method for Process Improvement – стандартный метод сертификации CMMI для совершенствования процесса. Прим. перев.
(обратно)11
Вумек Дж., Джонс Д., Рус Д. Машина, которая изменила мир. М.: Попурри, 2007.
(обратно)12
В некоторых районах Калифорнии нормальным, но не идеальным с точки зрения безопасности считается время 1,4 секунды.
(обратно)13
Питчер – это игрок, который выполняет наиболее трудную оборонительную функцию в бейсбольной команде. Прим. ред.
(обратно)(обратно)Комментарии
1
Anderson, David J. Agile Management for Software Engineering: Applying the Theory of Constraints for Business Results. Upper Saddle River, NJ: Prentice Hall, 2003.
(обратно)2
Beck, Kent. Extreme Programming Explained: Embrace Change. Boston: Addison Wesley, 2000. Издание на русском языке: Бек К. Экстремальное программирование. СПб.: Питер, 2002.
(обратно)3
Beck, Kent et al., “The Principles Behind the Agile Manifesto.” . Перевод на русский язык: .
(обратно)4
Goldratt, Eliyahu M. What is this thing called The Theory of Constraints and How should it be implemented? Great Barrington, MA: North River Press, 1999.
(обратно)5
Anderson, David J., and Dragos Dumitriu, “From Worst to Best in 9 Months: Implementing a Drum-Buffer-Rope Solution in Microsoft’s IT Department,” Proceedings of the TOCICO World Conference, Barcelona, November 2005.
(обратно)6
Belshee, Arlo. “Naked Planning, Promiscuous Pairing and Other Unmentionables.” 2008 Agile Conference, подкаст .
(обратно)7
Hiranabe, Kenji. “Visualizing Agile Projects Using Kanban Boards.” InfoQ, August 27, 2007. -kanban-boards.
(обратно)8
Hiranabe, Kenji, “Kanban Applied to Software Development: From Agile to Lean,” InfoQ, January 14, 2008. -lean-agile-kanban.
(обратно)9
Augustine, Sanjiv. Managing Agile Projects. Upper Saddle River, NJ: Prentice Hall, 2005.
(обратно)10
Highsmith, Jim. Agile Software Development Ecosystems. Boston: Addison Wesley, 2002.
(обратно)11
Тест Nokia Test приписывается Басу Водде, а здесь описан вариант Джеффа Сазерленда, который принял его на вооружение и внес существенные изменения: -test-where-did-it-come-from.html.
(обратно)12
Beck et al., “The Principles Behind the Manifesto.” .
(обратно)13
Jones, Capers. Software Assessment Benchmarks and Best Practices. Boston: Addison Wesley, 2000.
(обратно)14
Ambler, Scott. Agile Modeling: Effective Practices for Extreme Programming and the Unified Process. Hoboken, N.J.: Wiley, 2002.
(обратно)15
Chrissis, Mary Beth, Mike Konrad, and Sandy Shrum. CMMI: Guildelines for Process Integration and Product Improvement, 2d ed. Boston: Addison Wesley, 2006.
(обратно)16
Sutherland, Jeff, Carsten Ruseng Jakobsen, and Kent Johnson. “Scrum and CMMI Level 5: A Magic Potion for Code Warriors.” Proceedings of the Agile Conference, Agile Alliance/IEEE, 2007.
Jakobsen, Carsten Ruseng and Jeff Sutherland. “Mature Scrum at Systematic.” Methods & Tools, Fall 2009. .
(обратно)17
Larman, Craig and Bas Vodde. Scaling Lean & Agile Development: Thinking and Organizational Tools for Large-Scale Scrum. Boston: Addison Wesley, 2008.
(обратно)18
Willeke, Eric, with David J. Anderson and Eric Landes (editors) Proceedings of the Lean & Kanban 2009 Conference. Bloomington, IN: Wordclay, 2009.
(обратно)19
Beck et al, Principles Behind the Agile Manifesto, 2001, .
(обратно)20
Anderson, David J. “New Approaches to Risk Management.” Agile 2009, Chicago, Illinois, -NewApproachestc.html.
(обратно)(обратно)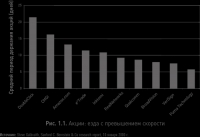






Комментарии к книге «Канбан. Альтернативный путь в Agile», Дэвид Андерсон
Всего 0 комментариев