
Статистический анализ взаимосвязи в Excel Учебное пособие Валентин Юльевич Арьков
© Валентин Юльевич Арьков, 2019
ISBN 978-5-0050-4525-6
Создано в интеллектуальной издательской системе Ridero
Предисловие
Предлагаемое учебное пособие позволяет освоить базовые методы исследования взаимосвязей в пакете Microsoft Excel. Все действия описаны подробно, шаг за шагом, с примерами и комментариями. Попутно можно улучшить навыки работы в Excel, что само по себе уже полезно как элемент современной компьютерной грамотности.
Данное учебное пособие представляет собой второй выпуск серии «Бизнес-аналитика и статистика в Excel». При выполнении работы советуем использовать знания и навыки, полученные при изучении первого выпуска под названием «Анализ распределения в Excel». Рекомендуем изучать материал последовательно — и в рамках данной работы, и в рамках данной серии.
Мы будем использовать простые условные обозначения и названия:
— жирный шрифт — названия функций и пунктов меню;
— ЗАГЛАВНЫЕ БУКВЫ — выделение основных терминов и ключевых данных;
— КНОПКИ — кнопки на экране компьютера;
— КЛАВИШИ — клавиши на клавиатуре компьютера.
В тексте описана работа в текущей англоязычной версии Microsoft Excel из пакета Microsoft Office 365. Далее будем называть этот программный продукт просто Excel. При указании функций и пунктов меню мы будем давать оба варианта — на английском и на русском языке. На рисунках будем давать примеры англоязычного интерфейса.
Введение
Взаимосвязи между явлениями бывают самые разные. В данном выпуске мы будем рассматривать самый популярный вид взаимосвязи между случайными величинами, когда текущее значение одной случайной величины Y В СРЕДНЕМ определяется значением другой случайной величины X. Вокруг этого предсказуемого среднего имеется случайный непредсказуемый разброс. Лучше всего, если этот разброс постоянного размаха, то есть «сигма» разброса не меняется. Это так называемая КОРРЕЛЯЦИОННАЯ ЗАВИСИМОСТЬ.
Эта две случайные величины называют по-разному:
X — факторный признак, фактор, независимая переменная, independent variable;
Y — результативный признак, результат, зависимая переменная, dependent variable.
На графике «иксы» откладывают по горизонтальной оси, а «игреки» — по вертикальной. В математике принято откладывать аргумент функции по оси X, а значение функции — по оси Y. В данном случае мы поступаем точно так же. Это намекает, что Y зависит от Х. Например, люди высокого роста в среднем весят больше. Поэтому рост можно будет обозначить через X, а вес — через Y.
Корреляционная зависимость изучается с помощью методов КОРРЕЛЯЦИОННОГО И РЕГРЕССИОННОГО АНАЛИЗА. Кроме того, здесь мы снова проведём СВОДКУ И ГРУППИРОВКУ ДАННЫХ, но не для изучения распределения, а для анализа взаимосвязи.
Отчёт о работе оформляется по общим правилам, которые мы уже описали в первом выпуске серии и которые (как мы надеемся) уже удалось освоить в процессе выполнения заданий. Поэтому повторять рекомендации не будем, а сразу займёмся делом.
Общие сведения
В данной работе мы будем исследовать взаимосвязь между случайными величинами статистическими методами.
Мы познакомимся с одним из самых известных видов взаимосвязи под названием КОРРЕЛЯЦИОННАЯ ЗАВИСИМОСТЬ, или просто КОРРЕЛЯЦИЯ. Можно сказать, что это «зависимость в среднем». Пример показан на рисунке ниже.
Корреляционная зависимость
На нашем рисунке видно, что с увеличением «икса» В СРЕДНЕМ увеличивается «игрек». Можно сказать, что здесь просматривается линия и разброс точек вокруг этой воображаемой линии. В этом случае говорят, что между «иксом» и «игреком» есть КОРРЕЛЯЦИЯ, или корреляционная зависимость, или корреляционная взаимосвязь.
Изображение того, как разбросаны точки по графику, называют по-разному:
— корреляционное поле;
— поле корреляции;
— диаграмма разброса;
— диаграмма рассеяния;
— «точечная диаграммма»;
— scatter plot.
Далее мы будем использовать название ДИАГРАММА РАЗБРОСА.
Корреляционная зависимость встречается в жизни. Вот некоторые примеры такой зависимости «в среднем»:
— рост и вес человека;
— площадь квартиры и её цена;
— уровень доходов и продолжительность жизни;
— доходы и расходы домашнего хозяйства;
— длина поездки и расход бензина;
— посещаемость занятий и оценка на экзамене.
Если рассматривать картину в целом, то здесь будет какая-то общая тенденция (прямая или кривая линия), а в каждом конкретном случае к ней добавляется случайный разброс, непредсказуемость, погрешность. По реальным данным можно оценить наличие (силу, степень, тесноту) взаимосвязи и даже построить уравнение такой зависимости. Такое уравнение даст нам только ориентир, среднюю картину и позволит делать приблизительные прогнозы.
Мы будем строить модель в виде одного уравнения, в котором есть один факторный признак и один результативный. Такая модель называется ПÁРНАЯ РЕГРЕССИЯ. Это означает, что у нас рассматривается ПАРА случайных величин, то есть в уравнении участвуют ДВЕ переменные.
Как и в предыдущей работе, вначале мы смоделируем исходные данные и познакомимся со статистическими методами. Затем мы возьмём реальные данные и применим к ним эти изученные технологии. Моделирование даёт идеальные, «красивые» данные, по которым можно начать обучение. Реальные данные всегда «угловатые», «шершавые», «некрасивые», неидеальные. Но это жизнь, и именно с реальными данными приходится иметь дело исследователям, инженерам, программистам, экономистам.
Модели описывают реальную жизнь очень приблизительно, но даже такое приближённое описание может быть полезно при решении реальных задач на производстве и в бизнесе. Слово ПРИБЛИЖЁННОЕ указывает, что есть некоторая погрешность и что наша модель, наше уравнение ПРИБЛИЖАЕТСЯ к реальной жизни. То есть близко, но не точно. И это уже лучше, чем полная неизвестность и неопределённость. А полной, абсолютной точности никогда не бывает. Даже на рынке можно поторговаться, и цена изменится, причём у разных покупателей получится по-разному. Так что, выходя из дома за покупками, человек только очень приблизительно может оценить предстоящие расходы.
Варианты задания
Варианты заданий представлены в таблице ниже. Здесь мы используем следующие условные обозначения.
X — факторный признак, или фактор, или независимая переменная. Мы моделируем Х как случайную величину с РАВНОМЕРНЫМ РАСПРЕДЕЛЕНИЕМ в указанном диапазоне.
E — случайная составляющая. Будем моделировать Е как случайную величину со СТАНДАРТНЫМ НОРМАЛЬНЫМ РАСПРЕДЕЛЕНИЕМ, то есть с нулевым средним и единичной дисперсией.
Y — результативный признак, или результат, или зависимая переменная. При моделировании мы вычисляем Y по формуле, в которой участвуют фактор X и случайность E. Коэффициент при случайной составляющей определяет её СИГМУ (стандартное отклонение) и, соответственно, разброс вокруг среднего.
n — объём выборки. Это количество изучаемых объектов (статистических единиц), например, людей, квартир или жёстких дисков. У каждого объекта будут свои значения X и Y. Например, у каждого человека будет своя пара значений: роста и вес. Можно сказать, что в нашем случае объём выборки — это число строк в таблице с данными, или число записей в базе данных, или КОЛИЧЕСТВО ПАР случайных чисел {X, Y}. Для каждого объекта будет своя пара чисел Х и Y. В нашей работе объём выборки равен 200 для всех вариантов.
Оформление отчёта подробно описано в предыдущем выпуске серии. Создадим новую рабочую книгу. Сохраним отчёт в файле с коротким информативным названием. Сделаем титульный лист отчёта и заготовку оглавления.
В данной работе мы будем вначале рассматривать линейную функцию, а затем нелинейную. Соответственно, у нас имеется две таблицы с вариантами заданий.
Выберем свой вариант задания и опишем его на новом листе отчёта.
Зарисовка линейной функции
Вначале надо представить себе, что представляют собой наши данные, как будет выглядеть график. Для этого сделаем зарисовку на бумаге — как в предыдущей работе.
Нам предстоит изобразить расположение нашей линии и форму диаграммы разброса — в самых общих чертах.
Зарисовка диаграммы разброса
Изобразим оси координат и займём нужное место на листе бумаги.
Масштаб на графике необязательно должен начинаться от нуля. Главное, чтобы диаграмма разброса занимала всё поле графика. Метки на осях — «красивые», круглые числа.
В нулевом варианте задания X изменяется в пределах от 1000 до 2000. По оси «икс» указываем крайние значения 1000 и 2000 в начале и конце оси.
Теперь оценим диапазон значений Y. Берём формулу для Y, пока без учёта случайности Е:
Y = 1400 +0,065 · X
Подставляем крайние значения X:
Y (1000) = 1400 +0,065 · 1000 = 2050
Y (2000) = 1400 +0,065 · 2000 = 2700
Выбираем масштаб по оси «игрек» от 2000 до 3000.
Получаем 2 точки, через них проводим прямую линию.
Добавим разброс вокруг линии. Для этого используем ПРАВИЛО ТРЁХ СИГМ: почти все значения случайной величины находятся в диапазоне «среднее плюс-минус три сигмы». Когда мы строим разброс вокруг линии, в роли среднего значения будет точка на линии.
В нулевом варианте случайный разброс равен 50 · Е. Случайная составляющая Е имеет единичную дисперсию. Сигма Е тоже будет равна единице, потому что сигма — это квадратный корень из дисперсии. Если умножить случайную величину Е на 50, то её сигма тоже увечивается в 50 раз. Стало быть, сигма равна 50, а три сигмы равно
3 · 50 = 150.
Вокруг первой и последней точек на графике строим разброс «плюс-минус три сигмы».
2050 — 150 = 1900
2050 +150 = 2200
2700 — 150 = 2550
2700 +150 = 2850
Проводим пунктиром две параллельные линии. Это будут границы случайного разброса.
Заполняем эту «полосу» точками — случайным образом.
Вот что мы ожидаем увидеть, когда смоделируем исходные данные — см. рисунок.
Зарисовка
Зачем в этой работе мы делаем зарисовку? При любых вычислениях нужно уметь ЗАРАНЕЕ ОЦЕНИВАТЬ и МЫСЛЕННО ПРЕДСТАВЛЯТЬ себе будущие результаты. Тогда сразу будут видны ГРУБЫЕ ОШИБКИ. И эти ошибки можно будет сразу же выявить и исправить. Ну а ошибки будут всегда.
Если не оценивать будущий результат, то можно легко сказать: «Это компьютер так посчитал». Проблема в том, что исходные данные вводит человек и результаты будет использовать тоже человек. Программу тоже написал человек, и не один. Поэтому ОТВЕТСТВЕННОСТЬ за результаты расчётов несёт не компьютер, а человек.
Зарисовка нелинейной функции
Вторая часть задания — это нелинейная функция второго порядка. Варианты заданий приводятся в таблице. Другие названия: квадратичная функция, парабола — см. формулу.
Уравнение параболы можно записать разными способами, поэтому нужно следить за тем, в каком порядке расположены члены уравнения.
Уравнение параболы
В первом примере степени аргумента расположены по убыванию. Во втором — по возрастанию. Как записать уравнение — не так важно. Главное — правильно прочитать те результаты, которые нам выдаст программа.
На новом листе отчёта опишем свой вариант задания. Напомним, что мы в качестве примера рассматриваем нулевой вариант.
Пределы изменения факторного признака: от 1000 до 3000.
Уравнение функции:
y = 7000 — 7 · x +0,002 · x2 +200 · e
Коэффициенты уравнения:
a0 = 7000
a1 = — 7
a2 = 0,002
s = 200
Коэффициент при случайной составляющей E обозначим буквой S, поскольку он определяет значение «сигмы».
Чтобы сделать зарисовку параболы, нужно определить два основных момента.
Вначале определим знак старшего коэффициента при второй степени фактора a2. Если коэффициент a2 положителен, то ветви параболы напрaвлены вверх. И наоборот.
В нулевом варианте старший коэффициент равен
a 2 = 0,002.
Коэффициент положительный, следовательно ветви параболы смотрят вверх.
Затем определим положение вершины параболы.
Вершина параболы
Докажите справедливость формул для нахождения координат вершины параболы, приравняв первую производную функции к нулю. Затем подставьте полученное значение х0 в уравнение параболы и упростите выражение.
Подставляем наши коэффициенты и находим координаты вершины — см. формулы.
Координаты вершины
Далее определим значения функции на границах диапазона значений — см. формулы.
Крайние значения
И наконец добавляем границы случайного разброса по «правилу трёх сигм». Сигма в нулевом варианте равна 200, соответственно, три сигмы равно 600. Добавляем и отнимаем 600 в каждой из трёх точек — см. формулы.
Делаем зарисовку и вставляем в отчёт, как описано в предыдущем выпуске. Цель этого упражнения — представить общую форму графика, а не демонстрировать художественный талант или способности к черчению.
Зарисовка
Исходные данные
Сгенерируем исходные данные — значения двух переменных x и y — в соответствии c вариантом задания. В качестве примера разбираем нулевой вариант. Используем функцию
Random Number Generation
Генерация случайных чисел
надстройки
Data Analysis
Анализ данных.
Подробности использования генератора мы уже описали в предыдущей работе. Числа округляем до целых.
Создаём столбец случайных чисел X.
Распределение — Равномерное
Левая и правая границы — 1000 и 2000.
Начальное состояние — 1234. Можно взять любые другие числа, но их нужно зафиксировать в отчёте, чтобы не использовать второй раз.
Настройки генератора
Полученные значения X округляем до целых и записываем в другой столбец. Для округления используем функцию
ROUND (number, num_digits)
ОКРУГЛ (число; число разрядов).
Обратим внимание, что в английской версии аргументы функции разделяют ЗАПЯТОЙ, а в русской — ТОЧКОЙ С ЗАПЯТОЙ. Причина в том, что в английской версии десятичный разделитель целой и дробной частей — точка, а в русской — запятая.
Пример результата генерации данных и округления можно видеть на рисунке ниже. В дальнейшей работе используются именно округлённые значения X и Y.
Сгенерированные данные
Вспомогательная случайная составляющая E поможет нам сформировать случайный разброс вокруг линии. Она имеет нормальное распределение с нулевым математическим ожиданием и единичным стандартным отклонением. Значения E следует сгенерировать в отдельном столбце с ДРУГИМ начальным состоянием генератора.
Программный генератор случайных чисел на самом деле создаёт ПСЕВДОСЛУЧАЙНЫЕ числа. Другими словами, они только кажутся случайными. Если задавать одно и то же начальное состояние генератора, мы получим одну и ту же последовательность «случайных» чисел.
Проведём опыт и убедимся, к чему приводят одинаковые настройки генератора. Сгенерируем столбцы Х и Е с одинаковым начальным состоянием генератора: 1234. Результат — на рисунке слева. Теперь сгенерируем Х и Е с настройками 1234 и 5678. Результат показан справа.
Влияние начального состояния
На левом графике можно видеть явную связь (точную функциональную зависимость) между случайными числами Х и Е — при одинаковой настройке генератора: 1234 и 1234. На этом графике просматривается кривая нормального распределения. Она используется для создания случайного числа с заданным распределением. Разные настройки 1234 и 5678 дают действительно независимые случайные числа. Учтём на будущее.
Выделим два столбца с готовыми данными — с заголовками. Вставим данные на новый лист. Выберем режим вставки значений из буфера обмена.
Вставка значений
При выборе режима вставки из буфера можно сразу увидеть результат на экране. Нажимаем кнопку
Values
Значения.
После вставки получаем числа вместо формул в ячейках таблицы. Теперь никакие наши действия не приведут к обновлению и изменению данных.
Диаграмма разброса
Пришло время посмотреть на график наших исходных данных. На диаграмме разброса каждая пара чисел Х и Y изображается отдельной точкой. Точки на графике НЕ СОЕДИНЯЮТ линиями. В примере «Рост — Вес» нет никакой связи между параметрами соседей по парте. Поэтому каждый человек — это отдельная точка на графике.
Выделяем два столбца с округлёнными значениями X и Y. Выбираем в меню:
Insert — Charts — Insert Scatter (X, Y) or Bubble Chart — Scatter — Scatter
Вставка — Диаграммы — Вставить точечную (X, Y) или пузырьковую диаграмму — Точечная — Точечная.
Вставка диаграммы разброса
По умолчанию диаграмма разброса выглядит не слишком привлекательно — см. график. Настроим оформление графика.
Диаграмма разброса по умолчанию
Настроим масштаб по осям, чтобы диаграмма заполняла всё поле графика. Дважды щёлкнем по горизонтальной оси. В диалоговом окне
Format Axis
Формат оси
выбираем раздел
Axis Options
Параметры оси.
Устанавливаем пределы по горизонтальной оси от 1000 до 2000.
Масштаб по оси
Щёлкнем по вертикальной оси и выберем такие значения, чтобы диаграмма разброса занимала всё место на графике.
Теперь настроим заголовки. Щёлкнем по графику и нажмём на кнопку
Chart Elements
Элементы диаграммы.
Это квадратная кнопка с символом ПЛЮС справа вверху.
Элементы графика
Отмечаем пункт
Axis Titles
Названия осей.
Заголовки осей
Отредактируем заголовки и укажем, где находятся наши «иксы» и «игреки». Для дальнейшего украшения развернём заголовок вертикальной оси на 45 градусов. Щёлкнем по заголовку вертикальной оси и выберем в меню:
Format Axis Title — Text Options — TextBox — Text Box — Text direction — Horizontal
Формат названия оси — Параметры текста — Надпись — Надпись — Направление текста — Горизонтально.
Далее установим чёрный цвет для точек-маркеров. Щёлкнем по маркерам и установим в меню чёрный цвет:
Format Data Series — Series Options — Fill & Line — Marker — Marker Options — Fill — Solid fill — Color — Black
Формат ряда данных — Параметры ряда — Заливка и границы — Маркер — Параметры маркера — Заливка — Сплошная заливка — Цвет — Чёрный.
Здесь же отключим обрамление маркеров:
Format Data Series — Series Options — Fill & Line — Marker — Marker Options — Border — No line
Формат ряда данных — Параметры ряда — Заливка и границы — Маркер — Параметры маркера — Граница — Нет линий.
После настроек диаграмма разброса должна выглядеть следующим образом — см. рисунок.
Оформленная диаграмма
Корреляционный анализ
Корреляционный анализ позволяет исследовать тесноту связи, то есть степень разброса точек вокруг линии. Чем ближе точки к линии регрессии, тем лучше ТЕСНОТА СВЯЗИ. Имеется в виду линия, которую МОЖНО построить в среднем по этом точкам. На самом деле при анализе взаимосвязи перед нами находятся только точки, а линии пока ещё НЕТ.
Теснота линейной связи оценивается с помощью КОЭФФИЦИЕНТА ЛИНЕЙНОЙ КОРРЕЛЯЦИИ r. Здесь говорится именно о ЛИНЕЙНОЙ связи и анализируется разброс вокруг будущей, возможной ПРЯМОЙ линии. Другими словами, мы выясняем, есть ли смысл в построении прямой линии в среднем по нашим точкам.
Коэффициент корреляции принимает значения от —1 до +1 включительно.
Знак коэффициента указывает на НАПРАВЛЕНИЕ связи — прямую или обратную связь. Положительная корреляция означает, что с увеличением фактора в среднем возрастает результативный признак. Это прямая связь. Отрицательная корреляция — это обратное направление связи, то есть снижение, убывание, падение графика. С увеличением фактора убывает результат.
Величина (модуль, абсолютное значение) коэффициента характеризует ТЕСНОТУ линейной связи. Чем ближе значение к единице, тем меньше разброс, тем ближе точки к прямой линии. Чем ближе коэффициент к нулю, тем сильнее разброс вокруг прямой. Традиционное толкование величины коэффициента корреляции приводится в таблице.
Возможна и другая ситуация — НЕЛИНЕЙНАЯ зависимость, которая тоже представляет собой отсутствие линейной связи. Нелинейной зависимостью является всё, что не является линейным, например, кривая или ломаная линия. В этом случае коэффициент линейной корреляции будет близок к нулю. Но при этом точки могут быть очень тесно расположены вокруг кривой или ломаной линии. Для анализа степени нелинейной связи используют другие коэффициенты корреляции. В данной работе мы ограничимся только анализом тесноты линейной зависимости.
Как и во многих других случаях, для вычисления коэффициента корреляции в Excel имеются несколько способов:
— надстройка;
— функции;
— формулы.
В следующих разделах мы рассмотрим все эти возможности, а затем сравним полученные результаты.
Надстройка
Вызываем модуль Корреляция статистической надстройки:
Data — Analysis — Data Analysis — Correlation
Данные — Анализ — Анализ данных — Корреляция.
Параметры корреляционного анализа
В диалоговом окне
Correlation
Корреляция
указываем следующие параметры:
Input — Input Range
Входные данные — Входной интервал.
В выбранном диапазоне ячеек должны быть два столбца значений X и Y.
Затем указываем расположение исходных данных:
Labels in first row
Метки в первой строке.
Выделяем значения в столбцах X и Y вместе с их заголовками. В этом случае в таблице с результатами анализа будут выводиться названия переменных.
Указываем, что наши исходные данные расположены по столбцам:
Grouped By — Columns
Группирование — по столбцам.
Обратите внимание, что здесь имеется в виду расположение данных по столбцам, а не статистическая группировка, хотя на экране и присутствует слово ГРУППИРОВАНИЕ. Как говорил Козьма Прутков: «Не верьте глазам своим». Мы пока что просто описываем исходные данные и даже не начинали заниматься группировкой.
Отмечаем первую ячейку, начиная с которой будут выводиться результаты анализа:
Output options — Output Range
Параметры вывода — Выходной интервал.
Результаты корреляционного анализа
На экран выводится таблица коэффициентов корреляции. На пересечении строки Y и столбца Х выводится искомый коэффициент. Единичные коэффициенты на диагонали — это корреляция переменной с самóй собой.
Чтобы получить больше разрядов в дробной части, увеличим ширину столбца.
Точное значение коэффициента
Функция CORREL / КОРРЕЛ
Второй способ вычисления коэффициента корреляции — это готовая функция
CORREL (array1, array2)
КОРРЕЛ (диапазон_x; диапазон_y).
Два обязательных аргумента — это диапазоны ячеек X и Y. Здесь «иксы» и «игреки» задаются по отдельности. Напомним, что в английской версии программы аргументы функции разделяют запятой, а в русской — точкой с запятой.
Вызов функции CORREL
Увеличиваем ширину столбца и сравниваем результаты расчётов с предыдущим разделом. Пока всё сходится.
Теперь на новом листе сгенерируйте данные с разным разбросом, то есть с разным множителем S в уравнении. Определите значение коэффициента корреляции. Подберите величину случайного разброса, чтобы получить
0,3
0,5
0,7
1,0.
В электронной таблице формулы пересчитываются автоматически, а графики сами обновляются при изменении данных. Поэтому можно будет легко подобрать нужный разброс. Скопируйте графики и соберите их на отдельном листе с комментариями — какая корреляция и какая это теснота связи. При вставке графиков используйте режим вставки как изображение — Picture (U), а не как исходный график. В этом случае картинки не будут изменяться и обновляться.
Формулы
Вычислим коэффициент линейной корреляции вручную с помощью формул Excel.
Вот соотношение для расчётов — см. формулу.
Коэффициент корреляции
Для вычислений нам понадобятся промежуточные расчёты. Найдём суммы «иксов», «игреков», их квадратов и произведений, которые участвуют в формуле. Для этого на новом листе организуем вспомогательную таблицу. Внизу столбцов подсчитываем суммы, воспользовавшись кнопкой экспресс-анализа.
Промежуточные суммы
Когда найдены необходимые суммы, можно вычислить коэффициент корреляции. Нам потребуется функция извлечения квадратного корня:
SQRT (number)
КОРЕНЬ (число).
Формула не слишком сложная. При вводе в ячейку она легко умещается на экране. Поэтому разбивать её на части не потребуется.
Коэффициент корреляции
Сравнение результатов
Копируем полученное значение на отдельный лист для сравнения с предыдущими оценками. Записываем комментарии и сообщаем, насколько похожи оценки, полученные разными способами. А также, о чём говорят величина и знак коэффициента r — см. таблицу выше.
Регрессионный анализ
Переходим к регрессионному анализу. В статистике и бизнес-аналитике РЕГРЕССИЯ — это линия, которую проводят В СРЕДНЕМ по точкам. Кроме изображения линии на графике, здесь рассматривается уравнение этой линии. Задача регрессионного анализа — построить линию регрессии и получить уравнение регрессии.
ЛИНИЯ РЕГРЕССИИ проходит по большому количеству точек именно В СРЕДНЕМ. Она может не пройти ни через одну точку. Но на графике будет видно, как линия проходит по местам сгущения точек. Можно даже провести такую линию «на глазок», просто приложив линейку к графику.
УРАВНЕНИЕ РЕГРЕССИИ описывает нашу линию, которая проходит по точкам в среднем.
Если у нас прямая линия, а «икс» входит в уравнение в первой степени, то это ЛИНЕЙНОЕ УРАВНЕНИЕ — см. формулу.
Линейная регрессия
Для проведения регрессионного анализа в Excel имеется несколько способов:
— элемент диаграммы;
— статистическая надстройка;
— функция LINEST (ЛИНЕЙН);
— формулы с матричными операциями.
Уравнение регрессии и соответствующая линия регрессии — это пример ПАРАМЕТРИЧЕСКОЙ модели. В такой модели участвует небольшое, ограниченное количество параметров. В нашем случае несколько коэффициентов уравнения.
Существует и второй тип моделей — НЕПАРАМЕТРИЧЕСКИЕ. В таких моделях вместо красивого уравнения используется таблица с неограниченным количеством чисел или множество точек на графике. И это количество может меняться. В нашей работе мы рассмотрим пример непараметрической модели регрессии под названием УСЛОВНОЕ СРЕДНЕЕ. Мы построим эту модель с помощью методов сводки и группировки данных — этот подход подробно рассматривался в предыдущей работе.
Элемент диаграммы
Самый простой способ получить уравнение регрессии и нанести линию регрессии на график — построить диаграмму разброса и вызвать встроенную, автоматическую функцию
Trendline
Линия тренда.
Название этой функции достаточно своеобразное. К нему тоже надо отнестись с пониманием. На самом деле ТРЕНД — это основная тенденция, общее направление при изменении значений во времени. Подробнее мы рассмотрим тренд в третьей работе на тему «Динамика». Фактически здесь строится линия регрессии. При построении линии тренда тоже используют методы регрессионного анализа, только вместо «иксов» берут моменты времени.
Слово РЕГРЕССИЯ здесь более подходящее, оно более универсальное, хотя и незнакомое для массового потребителя. Видимо, разработчики решили, что слово ТРЕНД более привычно для пользователей. Оно часто встречается в рекламе и даже в названиях некоторых товаров.
Щёлкнем по диаграмме разброса левой кнопкой мыши. Как показано на рисунке, справа от поля графика нажмём кнопку со знаком ПЛЮС:
Chart Elements
Элементы диаграммы.
Выбираем в качестве элемента графика
Trendline
Линия тренда.
Указываем линейную функцию:
Linear
Линейный.
Автоматическое построение регрессии
Есть и другой способ управлять элементами графика. Щёлкнем левой кнопкой мыши по графику и выберем в верхнем меню:
Design — Add Chart Element — Trendline — Linear
Конструктор — Добавить элемент диаграммы — Линия тренда — Линейный.
Добавление линии тренда
Добавим на график уравнение регрессии.
Design — Add Chart Element — Trendline — More Trendline options
Конструктор — Добавить элемент диаграммы — Линия тренда — Дополнительные параметры линии тренда.
В окне настройки элементов графика выбираем:
Format Trendline — Trendline options — Display Equation on chart
Формат линии тренда — Параметры линии тренда — показывать уравнение на диаграмме.
Вывод уравнения регрессии
На графике действительно появляется уравнение. Чтобы рассмотреть его получше, перетащим это уравнение мышкой на свободное место.
Уравнение регрессии на графике
Сравним полученное уравнение с нулевым вариантом задания. Значения коэффициентов похожи. Конечно, есть небольшое различие. Это случайная ошибка, вызванная случайным разбросом Е и ограниченным объёмом выборки N.
Условное среднее
Кроме линии регрессии, есть другой способ изучения той же зависимости — УСЛОВНОЕ СРЕДНЕЕ, то есть среднее при выполнении некоторого условия. Это среднее арифметическое значений результативного признака Y ПРИ УСЛОВИИ, что соответствующие значения факторного признака X попадают в заданный интервал.
Вот пример условного среднего: средний вес людей, у которых рост окажется в диапазоне от 160 до 170 см. Мы выбираем людей ростом от 160 до 170 см, измеряем их вес и находим среднее значение веса только по этой группе. Здесь рост — это факторный признак Х, а вес — это результативный признак Y. Мы получили средний «игрек», а условие определяли по «иксу».
На новом листе добавим интервалы группировки по X: нижние и верхние границы, а также среднее значение. Интервалы группировки выбираем точно так же, как описано в первой работе. Ссылка для скачивания пособия по первой работе приводится в конце данного выпуска.
В нашем примере возьмём 10 интервалов по 100 единиц, чтобы охватить диапазон значений от 1000 до 2000.
Для нахождения условного среднего можно использовать функцию
SUMIF
СУММЕСЛИ.
Функция позволяет вычислить сумму при выполнении заданного условия. Формат функции следующий:
SUMIF (range, criteria, [sum_range])
СУММЕСЛИ (диапазон; критерий; [диапазон_суммирования])
range — диапазон — диапазон ячеек;
criteria — критерий — условие;
sum_range — диапазон_суммирования — диапазон ячеек для суммирования. Если диапазон не указан, то суммируются значения из диапазона, указанного в первом аргументе.
Для определения средних значений фактора Х в каждом интервале группировки используем только два первых аргумента функции.
Рассмотрим примеры условных сумм — см. формулы.
Условные суммы
Первая формула вычисляет сумму значений фактора, не превышающих верхнюю границу первого интервала. Сюда попадут все значения из первого интервала, а также все точки, которые окажутся левее этого интервала.
Вторая формула определяет сумму значений фактора, попадающих во второй интервал.
В третьей формуле мы фиксируем номера строк для диапазона исходных данных с помощью символа $. Это позволит нам скопировать формулу и заполнить весь столбец.
Для упрощения расчётов мы определяем разность сумм значений, не превышающих верхние границы интервалов. В этом случае формулы получаются немного короче и понятнее. Мы уже использовали подобный приём в первой работе, когда определяли частоту попадания в интервал. Мы находили относительные частоты как разность соседних значений накопленной частоты.
Функция SUMIF
При вычислении среднего арифметического нужно поделить сумму значений на их количество.
Для определения количества элементов используем функцию
COUNTIF
СЧЕТЕСЛИ.
Формула для расчета условного среднего фактора Х получается довольно громоздкой — см. формулы.
Расчёт условного среднего
Изучите формулы и найдите следующие элементы:
— диапазон ячеек от А2 до А121 на листе 04;
— верхняя граница первого интервала на листе 05;
— верхняя граница второго интервала на листе 05.
Чтобы не запутаться, проведём наши расчёты по частям. Сначала найдём суммы и количества значений Х, не превышающих верхней границы. Затем определим разности соседних ячеек. Затем проведём деление и в результате получим среднее значение Х в каждом интервале группировки.
Вычисление условного среднего значения результативного признака Y немного сложнее. Здесь проверяется условие попадания факторного признака Х в интервал группировки, а сумма считается по столбцу результативного признака Y. Для этого используется третий аргумент функции SUMIF — см. формулу.
Условное среднее Y (X)
Для копирования формулы фиксируем номера строк с помощью знака $.
Вычисление условного среднего
После вычислений наносим линию условного среднего на диаграмму разброса. Для этого нам потребуется ломаная линия с маркерами точек.
Строим диаграмму разброса, как описано выше.
Выбираем второй ряд данных:
Select Data — Select Data Source — Add
Выбрать данные — Выбор источника данных — Добавить.
Добавляем новые данные для графика. В качестве значений x берём условные средние «иксы», а в качестве y — условные средние «игреки». На графике появляются новые точки.
Изменяем тип диаграммы: щёлкаем правой кнопкой по графику и выбираем комбинированный график:
Change Chart Type — Combo
Изменить тип диаграммы — Комбинированная.
Для исходных данных оставляем диаграмму разброса:
Scatter
Точечная.
Для условного среднего выбираем ломаную линию:
Scatter with Straight Lines
Точечная с прямыми отрезками и маркерами.
Для использовани единого масштаба на графиках снимаем выбор пункта:
Secondary Axis
Вспомогательная ось.
Если на графике будет две вертикальных оси, то будет свой масштаб для каждого набора данных. Такие графики будет невозможно сравнивать. Нам нужен общий, единый масштаб.
Комбинация графиков
В процессе настройки графиков можно видеть, как меняется изображение. При выборе данных для графиков мы не указывали названия рядов, поэтому они названы по умолчанию Series1 и Series2. Пока на графике не так много данных, это не доставляет неудобств. В следующей работе всё-таки придётся задать имена для каждого набора данных, чтобы легче было работать с несколькими графиками.
Как и раньше, настраиваем масштаб, заголовки, цвета. График готов.
Условное среднее на диаграмме разброса
Надстройка
Продолжаем строить модель связи в форме уравнения регрессии. Для его построения необходимо вычислить коэффициенты регрессии.
В этом разделе используем статистическую надстройку:
Data — Analysis — Data Analysis — Regression
Данные — Анализ — Анализ данных — Регрессия.
Линейная регрессия
После вызова надстройки анализа данных и выбора регрессионного анализа появляется диалоговое окно настройки параметров анализа:
Regression
Регрессия.
Указываем диапазоны ячеек для входных интервалов фактора X и результата Y. Обратите внимание, что в первой строке вводятся «игреки», а во второй — «иксы». Выделяем диапазоны ячеек с заголовками и указываем это в пункте
Labels
Метки.
В уравнении регрессии будет свободный член, поэтому убеждаемся, что сняли выбор пункта
Constant is Zero
Константа — ноль.
Указываем первую ячейку для вывода результатов
Output options — Output Range
Параметры вывода — Выходной интервал.
Ещё нас интересует график. Поэтому отмечаем пункт
Residuals — Line Fit Plots
Остатки — График подбора.
Регрессию иногда не слишком грамотно называют «подбор» или «подгонка». На самом деле это попытка перевести английский термин fit. В качестве упражнения предлагаем заглянуть в Википедию и ознакомиться с англоязычным разделом Curve fitting и его русскоязычным вариантом Приближение с помощью кривых.
Более грамотный перевод слова FIT — это АППРОКСИМАЦИЯ, то есть приблизительная замена сложной функции или большого массива данных упрощённой функцией. Слово «аппроксимация» буквально означает «приближение», или «приблизительная замена».
Для нас это пример того, какие проблемы возникают у переводчиков англоязычных программных средств. Для грамотного перевода требуется профессиональное, грамотное владение предметной областью и терминологией на обоих языках. Естественно, это слишком «дорого» и «нерентабельно».
Параметры регрессионного анализа
На экран выводится несколько таблиц и один график.
Результаты регрессионного анализа
Среди результатов регрессионного анализа нас будут интересовать прежде всего коэффициенты уравнения. Рассмотрим третью табличку поподробнее. Увеличим ширину столбцов. Для точного вывода всех доступных разрядов можно щёлкнуть по ячейке и взглянуть на строку формул.
Коэффициенты уравнения
В таблице коэффициентов имеется две строчки.
В первой строке выводится СВОБОДНЫЙ ЧЛЕН уравнения регрессии. Строка обозначена следующим образом:
Intercept
Y-пересечение.
Имеется в виду значение Y, при котором линия регрессии ПЕРЕСЕКАЕТ вертикальную ось координат. В нашем примере свободный член уравнения обозначен буквой a.
a = 1379.7259819748.
Во второй строке выводится КОЭФФИЦИЕНТ РЕГРЕССИИ:
X
Переменная X 1.
В нашем уравнении коэффициент регрессии, то есть коэффициент при «иксе», обозначен буквой b.
b = 0.664739003611188.
Второй результат анализа, который мы рассмотрим, — это график под названием Line Fit Plot. Имеется в виду графическое изображение ЛИНЕЙНОЙ АППРОКСИМАЦИИ. Predicted Y — это ЛИНЕЙНЫЙ ПРОГНОЗ, то есть оценка значения результативного признака по уравнению регрессии.
Диаграмма разброса и прогноз
Настроим масштаб по осям, увеличим график и отключим ЛЕГЕНДУ ДИАГРАММЫ — это условные обозначения в правой части графика. Пока у нас всего два ряда данных, нетрудно сообразить, кто есть кто.
Для исходных данных установим чёрные круглые маркеры вместо синих ромбиков.
Выбираем тип маркера большую точку (закрашенный кружочек):
Format Data Series — Series Options — Fill & Line — Marker — Marker Options — Built-in — Type — •
Формат ряда данных — Параметры ряда — Заливка и границы — Маркер — Параметры маркера — Встроенный — Тип — •.
Настраиваем заливку чёрным цветом:
Fill — Solid fill — Color — Black
Заливка — Сплошная заливка — Цвет — Чёрный.
Отключаем «границу» — обрамление маркера:
Border — No line
Граница — Нет линий.
Для линейного прогноза установим сплошную чёрную линию вместо оранжевых ромбиков:
Format Data Series — Series Options — Fill & Line — Line — Solid line
Формат ряда данных — Параметры ряда — Заливка и границы — Линия — Сплошная линия.
Устанавливаем цвет линии:
Color — Black
Цвет — Чёрный.
Оставляем только линию и убираем маркеры:
Marker — Marker Options — None
Маркер — Параметры маркера — Нет.
Задаём толщину линии:
Line — Width — 1 pt
Линия — Ширина — 1 пт.
И снова — проблема перевода. ШИРИНА чаще бывает у полосы или прямоугольника. ТОЛЩИНА ЛИНИИ звучит как-то более привычно. Но это, конечно же, дело вкуса — если работой занимается любитель, дилетант, то есть человек не является специалистом. Особенно, если переводить отдельные слова и не обращать внимание на окружающий текст, который называется КОНТЕКСТ.
Для специалистов, для серьёзной работы существуют СТАНДАРТЫ. И в стандартах есть грамотные названия, правильные ТЕРМИНЫ. Это язык конкретной профессии. Возьмём, к примеру, такой документ:
ГОСТ 2.303—68 ЕСКД. Линии.
Это отечественный государственный стандарт (сокращённо ГОСТ). Данный стандарт входит в Единую систему конструкторской документации (сокращённо ЕСКД). С конструкторскими чертежами работает инженер-конструктор. По сути, это изображение конструкции изделия, которое затем рабочие будут изготавливать на станках по этим чертежам. В данном стандарте есть только ТОЛЩИНА ЛИНИИ. Ознакомьтесь с текстом стандарта и обратите внимание на выражение ТОЛЩИНА ЛИНИИ.
Линейная регрессия
Пока что мы рассматриваем линейную регрессию, поэтому прямая линия получилась довольно приличная. Для нелинейной регрессии линию придётся рисовать совсем по-другому.
Нелинейная регрессия
Нелинейная регрессия — это построение уравнения связи и графика с использованием нелинейной функции. Другими словами, здесь работает всё, что не является линейным. Но только с одной оговоркой: уравнение должно выглядеть как сумма или разность. Тогда для каждого члена уравнения программа сможет подобрать коэффициенты.
В данной работе мы рассмотрим самые простые уравнения регрессии, в которых «икс» участвует не только в первой степени, но также в квадрате и в кубе — см. формулы.
Уравнения регрессии
Для построения нелинейной регрессии придётся создать вспомогательные столбцы нелинейных членов уравнения. Для параболы и кубической параболы необходимо в качестве входного интервала X выбрать соответствующие столбцы с разными степенями «икса». Эти значения желательно расположить в соседних столбах и выделить как один диапазон.
Обратите внимание на то, в каком порядке идут члены уравнения. По возрастанию или по убыванию степени «икса»? За этим нужно будет следить при формировании вспомогательных столбцов, при вызове функций регрессионного анализа и при чтении результатов.
Итак, на новый лист копируем исходные данные и добавляем колонку квадратов «икса» — рядом с «иксами» в первой степени. Будущие члены нашего уравнения регрессии называются красивым словом РЕГРЕССОРЫ. Это просто «участники» уравнения, для которых подбирают коэффициенты. В этом названии нет негативного оттенка, как и в слове РЕГРЕССИЯ. В статистике слово «регрессия» означает просто «зависимость в среднем». А вот в других дисциплинах регрессия может означать движение назад, противоположность прогрессу или возвращение в прошлое.
Для дальнейшей работы все столбцы регрессоров должны идти друг за другом. Тогда мы сможем выделить их как один диапазон ячеек. Так будет проще и понятнее.
Украсим заголовки столбцов со степенями «иксов». Выделяем показатель степени — цифру 2 — и вызываем форматирование, нажав кнопку
Font Settings
Настройки шрифта.
Это загадочная стрелочка в правом нижнем углу раздела
Font
Шрифт.
Форматирование текста
Появляется диалоговое окно настройки форматирования содержимого ячеек:
Format Cells
Формат ячеек.
Верхний индекс
Выбираем пункт
Superscript
Верхний индекс.
Нажимаем кнопку OK.
Форматирование заголовка столбца
Теперь заголовки столбцов со степенями «икса» легко читаются.
Исходные данные — регрессоры
Когда исходные данные подготовлены, вызываем надстройку и указываем входные данные, как показано на рисунке. По-прежнему, вначале указываем диапазон Y, а потом диапазон X в разных степенях. Заголовки столбцов пригодятся при расшифровке результатов. Поэтому выбираем пункт
Labels
Метки.
Начнём с построения параболы. Указываем в качестве факторных признаков два столбца «иксов» — в первой и второй степени.
Нелинейная регрессия
Выбираем автоматическое построение графика «аппроксимации»:
Residuals — Line Fit Plots
Остатки — График подбора.
На экране появляются два загадочных графика.
Графики аппроксимации
Чтобы понять, почему появилось два графика вместо одного, заглянем в исходные данные второй диаграммы. Щёлкнем правой кнопкой по графику и выберем
Select Data
Выбрать данные.
В этой диаграмме использованы два набора данных: y (исходные «игреки») и Predicted y (прогноз значений «игрека» по уравнению регрессии). В окне
Select Data Source
Выбор источника данных
выберем строчку y и нажмём
Edit
Изменить.
Данные для второй диаграммы
Рассмотрим, какие данные были выбраны для диаграммы. Нужные сведения выводятся в окне
Edit Series
Изменение ряда.
Выясняется, что по горизонтальной оси были выбраны квадраты «иксов».
Данные для второй диаграммы
Оставляем только первый график, а второй — удаляем. Теперь настроим наш график аппроксимации и рассмотрим его поподробней.
«График» параболы
Вместо ЛИНИИ регрессии можно видеть странную фигуру, которая утолщается в середине и сужается по краям. Причина в том, что соседние точки на графике соединяются отрезками. Но эти точки идут в том же порядке, как в исходной таблице, а там данные расположены в случайном порядке, не по возрастанию. Придётся кое-что подправить.
Скопируем столбец «иксов» и вставим на место столбца
Observation
Наблюдение
в таблицу
RESIDUAL OUTPUT
ВЫВОД ОСТАТКА.
Столбец Observation содержит порядковые номера i наблюдений в таблице исходных данных.
Третий столбец
Residuals
Остатки
нам для работы не потребуется — мы его просто удаляем.
Таблица прогнозов
Теперь у нас есть пары соответствующих «иксов» и «игреков». Отсортируем их по возрастанию. Для этого выделяем диапазон данных в столбцах Х и
Predicted y
Предсказанное Y.
Вызываем сортировку через верхнее меню:
Home — Editing — Sort & Filter — Sort Smallest to Largest
Главная — Редактирование — Сортировка и фильтр — Сортировка по возрастанию.
Сортировка по возрастанию
Сортировка ячеек выделенного диапазона выполняется по возрастанию чисел в первом столбце. Это значит, что «иксы» выстраиваются по возрастанию, а соответствующие им «игреки» перемещаются вслед за своими «иксами».
Отсортированные данные
Теперь изменим диапазоны ячеек для Predicted y в данных для графика:
Select Data — Select Data Source — Legend Entries (Series) — Predicted y — Edit.
Выбор данных — Выбор источника данных — Легенда — Предсказанное Y — Изменить.
Данные для Predicted y
Вместо столбца исходных «иксов» выбираем отсортированные «иксы» из вспомогательной таблицы. Диапазон для прогноза «игреков» оставляем тем же.
Отсортированные Predicted y
Теперь линия регрессии на графике стала похожа на линию. Поскольку мы генерировали исходные данные с помощью уравнения прямой линии, в наших точках особой «кривизны» не наблюдается. Так что мы видим участок параболы с очень небольшой кривизной.
График по отсортированным данным
Перейдём к уравнению регрессии. Надстройка выдаёт нам оценки коэффициентов уравнения. Заголовки строк указывают, к чему относится каждый коэффициент:
Intercept — свободный член уравнения;
x — «иксы»;
x2 — квадраты «иксов».
В исходной таблице мы сделали красивый заголовок для квадратов «икса» x2с помощью форматирования. Как видим, при выводе результатов регрессионного анализа форматирование потерялось и осталось только x2. Делаем вывод: заголовки должны быть такими, чтобы они хорошо читались как с форматированием, так и без форматирования.
Оценки коэффициентов
Берём коэффициенты и записываем уравнение регрессии. Нам понадобится несколько ячеек. Используем ссылки на ячейки с оценками коэффициентов.
Уравнение регрессии
Коэффициент при квадрате «икса» небольшой. С учётом величины квадрата «икса» получаем небольшой вклад в общий результат — на фоне остальных членов уравнения. Сравним вклад членов уравнения для среднего значения аргумента. Вычисления округлим до целых:
x = 1 500
x2 = 2 250 000.
Свободный член: 1 086.
Вклад х: 1,0733 * 1500 = 1 610.
Вклад х2: 0,000 137 * 1 500 * 1 500 = 308.
Относительный вклад х2:
308 / (1086 +1610 +308) * 100% = 10%.
Получается, что нелинейная часть уравнения даёт всего 10% изменения результативного признака.
Чтобы построить уравнение третьей степени, повторите описанные шаги для диапазона ячеек, дополнительно включающего столбец третьих степеней «иксов».
Функция LINEST / ЛИНЕЙН
Второй способ регрессионного анализа — готовая функция Excel. Коэффициенты регрессии можно найти с помощью функции
LINEST
ЛИНЕЙН.
Как и в предыдущем разделе, используем дополнительные столбцы со степенями «иксов». Скопируем исходные данные на новый лист. Значения регрессоров по-прежнему должны располагаться в соседних столбцах. При этом они указываются в виде диапазона как второй аргумент функции. В нашем случае формат вызова функции следующий:
LINEST (range_y, range_x)
ЛИНЕЙН (диапазон_y; диапазон_x).
Функция LINEST выводит результаты анализа в виде массива в несколько ячеек. Вызов этой функции снова потребует от нас выполнить несколько шагов. Напомним последовательность работы с формулой массива:
— ввести формулу в левую верхнюю ячейку диапазона;
— выделить весь диапазон ячеек;
— нажать клавишу [F2];
— нажать комбинацию клавиш [Ctrl + Shift + Enter].
Вначале вводим функцию LINEST в ячейку и указываем аргументы функции — диапазоны ячеек с исходными данными. Здесь тоже вначале идут «игреки», а потом «иксы». Всплывающая подсказка намекает, что у функции LINEST есть один обязательный аргумент и три необязательных — они указаны в квадратных скобках. Нам нужно указать два аргумента функции, как показано на рисунке.
Параметры функции LINEST
Как видим, при таком вызове функция даёт нам значение всего одного коэффициента. А в линейном уравнении их должно два.
Оценка одного коэффициента
Чтобы получить два коэффициента, проделаем описанные шаги для ввода ФОРМУЛЫ МАССИВА. Выделяем диапазон, состоящий из двух соседних ячеек F2 и G2. Вторая ячейка диапазона должна быть справа от первой!
Выделение диапазона из двух ячеек
Нажимаем клавишу [F2]. Обычно её используют для редактирования содержимого одной ячейки. Но теперь у нас было выделено две ячейки. На рисунке можно видеть, что выделение всё ещё охватывает две наши ячейки. Обратите внимание на зелёное обрамление вокруг ячеек F2 и G2. Получается что мы «редактируем» выделенный диапазон ячеек.
Результат нажатия [F2]
Наконец, нажимаем комбинацию клавиш:
[Ctrl + Shift + Enter].
Вокруг формулы появились ФИГУРНЫЕ СКОБКИ. Это говорит о том, что это формула массива.
Формула массива
При выборе любой ячейки диапазона можно видеть фигурные скобки фокруг формулы — см. рисунок.
Формула массива в каждой ячейке
Excel не позволяет изменить или удалить содержимое ячейки, если она входит в массив. При попытке внести изменения или удалить содержимое выводится сообщение:
You can’t change part of an array
Нельзя изменить часть массива.
Запрет изменений в массиве
При работе с массивом можно удалить только весь массив целиком. Выделим наш массив из двух ячеек и нажмём клавишу Delete. Массив удалён. Вернём результаты на место: нажмём кнопку отката Undo в левой верхней части окна программы. Можно также использовать комбинацию клавиш [Ctrl + Z].
Откат изменений
Повторим описанные шаги для построения уравнения регрессии второго и третьего порядка. Для параболы потребуется три коэффициента, а для кубической параболы — четыре. Соответственно, нужно будет вводить формулу массива на три или на четыре ячейки.
Чтобы можно было сравнить результаты, наведём порядок в представлении. Напомним, как выглядят уравнения регрессии — см. формулы.
Уравнения регрессии
Обратите внимание, что во всех трёх уравнениях номер (индекс) коэффициента — это степень, в которую возводится «икс». Поэтому придётся немного перестроить таблицу для коэффициентов.
Оценки коэффициентов
Получив оценки коэффициентов, можно записать уравнения регрессии.
Уравнения регрессии
Следующий шаг — графики. Нам нужно построить диаграмму разброса и нанести на неё линии регрессии.
Напомним, как построить диаграмму разброса:
Insert — Charts — Insert Scatter (X, Y) or Bubble Chart — Scatter — Scatter
Вставка — Диаграмма — Вставить точечную (X, Y) или пузырьковую диаграмму — Точечная — Точечная.
Добавляем набор данных для построения диаграммы разброса:
Select Data — Add
Выбрать данные — Добавить.
Настраиваем масштаб, указываем пределы значений по осям:
Format Axis — Axis options — Bounds — Minimum/Maximum
Формат оси — Параметры оси — Границы — Минимум/Максимум.
Устанавливаем тип маркеров — жирные точки:
Format Data Series — Series Options — Fill & Line — Marker — Marker Options — Built-in — •
Формат ряда данных — Параметры ряда — Заливка и границы — Маркер — Параметры маркера — Встроенный — Тип — •.
Устанавливаем чёрный цвет для заливки маркеров:
Format Data Series — Series Options — Fill & Line — Marker — Fill — Solid Fill — Color — Black
Формат ряда данных — Параметры ряда — Заливка и границы — Маркер — Заливка — Сплошная заливка — Цвет — Чёрный.
Диаграмма разброса
Чтобы нанести на график линию регрессию, сделаем вспомогательную таблицу. Первый столбец — десять значений «икс» от минимального до максимального. В соответствии с нашим вариантом задания, диапазон от 1000 до 2000. Для получения десяти значений берём шаг 100 единиц.
Вводим числа 1000 и 1100. Выделяем диапазон из этих двух ячеек и тянем вниз маркер заполнения. Вводим формулы для квадратов и кубов. Вычисляем прогнозы по уравнениям регрессии. Не забываем зафиксировать значения коэффициентов, нажав клавишу F4.
Данные для графиков
Добавляем данные для графиков. Настраиваем тип и цвет линий. Добавляем легенду. В этом случае легенда будет полезной. Она поможет различать наши три линии.
Вид нашего уравнения регрессии указываем при выборе данных для графика в окне Edit Series в строке Series name.
Вид уравнения регрессии
Получаем довольно прилично оформленный график. На нём есть исходные данные в виде точек. Три линии регрессии имеют разный цвет. Обозначения (легенда) приводятся справа от графика. На осях имеются заголовки и масштаб. У графика тоже есть заголовок. При таком оформлении можно понять, что тут нарисовано и как оно обозначено.
Линии регрессии
Система нормальных уравнений
Третий способ регрессионного анализа в Excel — это построение уравнения регрессии путём решения системы уравнений. Для этого мы будем использовать функции массивов для выполнения операций над матрицами.
Чтобы не запутаться, давайте определимся с названиями. В этом разделе мы используем два названия для одного и того же: массив, матрица и диапазон.
МАССИВ (термин из области программирования) — это особый тип данных. Переменная такого типа хранит несколько значений. Это элементы массива, к которым обращаются по одному или нескольким номерам (индексам). У массива может быть несколько измерений.
В пакете Excel мы будем работать с одномерными и двумерными массивами. Формулы массивов Excel работают с аргументами-массивами и могут выдавать результат тоже в виде массива. Формулы массивов вводят особым образом — мы с этим уже немного познакомились.
МАТРИЦА (термин из математики) — это прямоугольная таблица чисел. У матрицы может быть одно или два измерения. С матрицами выполняют различные действия, например, сложение и умножение.
Матрицы часто используют при решении систем уравнений. С матрицей можно работать и без компьютера — тогда это просто табличка с цифрами или буквами, записанными на бумаге. Если с матрицей работать в пакете программ, то её нужно будет хранить в переменной типа «массив».
С точки зрения Excel мы работаем с ДИАПАЗОНОМ ячеек. Мы указываем диапазон в качестве входного аргумента функции. Мы вводим функцию массива в диапазон ячеек, чтобы получить результат в виде массива. Мы используем функции массива для работы с матрицами.
Надеемся, что ситуация с массивами и матрицами немного прояснилась. Теперь разберёмся, как построить регрессию с помощью матриц.
Рассмотрим пример линейного уравнения. Это уравнение прямой линии. Чтобы найти коэффициенты такого уравнения регрессии, нам понадобится решить систему нормальных уравнений — см. формулы.
Система нормальных уравнений
Здесь неизвестными являются коэффициенты а0 и а1. Известными являются суммы «иксов» и «игреков» в разных видах, а также количество точек n. Для начала нам нужно будет подсчитать эти суммы.
Скопируем исходные данные на новый лист и добавим дополнительные столбцы для расчёта сумм.
Вспомогательная таблица
Выделяем нужные столбцы и находим суммы по этим столбцам с помощью кнопки экспресс-анализа
Quick Analysis
Быстрый анализ.
Использование экспресс-анализа подробно описано в первой работе. Ссылка на учебное пособие находится в конце данного выпуска.
Быстрый расчёт сумм
Указываем в заголовке последней строки, что здесь находится сумма.
Заголовок строки «Сумма»
Чтобы уместить наши расчёты на одном листе в пределах видимости, скроем середину большой таблицы исходных данных. Выделим «лишние» строки с 6 по 123, проведя мышкой с нажатой левой кнопкой по «серым» заголовкам строк и в контекстном меню выберем
Hide
Скрыть.
Для вызова контекстного меню как всегда используем правую кнопку мыши.
Скрываем лишние строки
Таблица со скрытыми строками стала более компактной. На скрытые строки намекает только двойная разделительная линия между строками 5 и 124. Если понадобится снова показать всю таблицу, можно выделить её (в нашем случае это строки от 5 до 124) и нажать
Unhide
Показать.
Таблица со скрытыми строками
На этом листе будет несколько таблиц, которые мы обведём рамочкой. Выделим нашу таблицу и выберем в верхнем меню:
Home — Font — Borders — Thick Outside Borders
Главная — Шрифт — Границы — Толстые внешние границы.
Обрамление таблицы
Появляется рамка, которая показывает, где находится наша таблица. Такое же обрамление мы сделаем и вокруг следующих таблиц (матриц) на этом рабочем листе.
Таблица с обрамлением
Исходные данные готовы.
Возьмём систему нормальных уравнений и запишем её в матричном виде. Получается одно матричное уравнение, в котором участвуют матрицы A, X и Y — см. формулы. Систему уравнений решаем путём умножения на обратную матрицу.
Решение матричного уравнения
Чтобы иметь перед глазами формулы для расчётов и чтобы не запутать читателя, выпишем основные соотношения на листе бумаги. Сфотографируем формулы и вставим их на текущий лист Excel. Набирать формулы — довольно долгое занятие. К тому же, надо иногда учиться писать от руки. Это очень полезно — развивает и руки, и голову.
Формулы для расчётов
Сформируем матрицы X и Y. Все необходимые суммы уже подсчитаны. Объём выборки n тоже известен. Это число строк в таблице исходных данных — в соответствии с вариантом задания. Используем ссылки на нужные ячейки. Рисуем рамки, чтобы выделить каждую матрицу.
Матрицы для системы уравнений
Для решения системы нормальных уравнений нам предстоит найти обратную матрицу для X и умножить её на матрицу Y. Для этого мы будем использовать две функции Excel по работе с матрицами — обращение и умножение.
Функция нахождения обратной матрицы (обращение матрицы) MINVERSE возвращает обратную матрицу для матрицы, которая хранится в указанном массиве:
MINVERSE (array)
МОБР (массив).
Функция умножения матриц MMULT находит произведение двух матриц, которые хранятся в указанных массивах:
MMULT (array1, array2)
МУМНОЖ (матрица1;матрица2).
Обе функции работают с массивами и выдают результат в виде массива.
Ввод функции массива выполняем так же, как и раньше. Печатаем следующее выражение и нажимаем ОК:
=MMULT (MINVERSE (C127:D128),C130:C131)
В текущей ячейке появляется одно число. Но результат решения системы — матрица А, столбец из двух ячеек. Поэтому выделяем вертикальный диапазон из двух ячеек, начиная с ячейки, в которую мы записали нашу формулу масива. Нажимаем клавишу F2, а затем комбинацию клавиш Ctrl + Shift + Enter.
Получаем результат решения системы уравнения — два числа, два коэффициента уравнения регрессии.
Решение системы уравнений
Зная коэффициенты, можно записать уравнение регрессии. Напомним, что первый элемент в матрице А — это а0, а второй элемент — а1. Уравнение регрессии записываем с помощью ссылок на эти две ячейки.
Уравнение регрессии
Переходим к графикам. Построим диаграмму разброса. Указываем диапазоны для «иксов» и «игреков». Однако на графике появляется всего две точки вместо 120.
Диаграмма разброса
Получается, что когда мы скрываем строки в таблице, эти данные не отображаются на графике. Нам хотелось бы держать все данные и графики перед глазами. Поэтому будем использовать для диаграммы разброса данные с другого листа, на котором отображены все 120 значений. Теперь на графике все точки на месте. Настроим тип и цвет маркера.
Диаграмма разброса
Добавим линию регрессии. Поскольку мы строим прямую линию, нам будет достаточно найти всего две точки. Сделаем вспомогательную табличку. Зададим два крайних значения «икс»: 1000 и 2000. Вычислим прогноз по уравнению регрессии для «игрека».
Вспомогательная таблица
Добавим этот массив как данные для графика. Настроим тип и цвет линии. Отключим маркеры.
Диаграмма разброса и линия регрессии
Рассмотрим построенный график и убедимся в правильности расчётов. Линия регрессии проходит в среднем по исходным точкам. Значит, грубых ошибок у нас нет.
На рисунке приводится окончательный вид нашей страницы отчёта. Здесь есть заголовки, формулы, таблицы, и график. Читателю будет легко понять, что и как было сделано.
Оформление отчёта
Далее самостоятельно постройте нелинейную регрессию второго и третьего порядка.
Уравнение второго порядка — «икс» участвует во второй степени. Система нормальных уравнений для регрессии второго порядка — см. формулы.
Регрессия второго порядка
Уравнение третьего порядка — «икс» участвует в третьей степени. Система нормальных уравнений для регрессии третьего порядка — см. формулы.
Регрессия третьего порядка
Нанесите линии регрессии на общий график.
Сравнение результатов
Сравним уравнения регрессии, полученные разными способами. Обратим внимание, насколько они похожи на исходный вариант задания.
На новом листе разместим свой вариант задания, а также уравнения, полученные разными способами.
Коэффициенты уравнений копировать не будем. Используем ссылки на те ячейки, в которых хранятся результаты расчетов.
Все уравнения представим в единой форме, например, в порядке возрастания показателя степени «икс».
Если всё сделано правильно, уравнения одного порядка, полученные разными способами, будут очень похожи друг на друга. Возможна небольшая разница в самых младших разрядах из-за вычислительных погрешностей.
Будет небольшое отличие полученных уравнений регрессии от варианта задания. Это погрешность из-за наличия случайной составляющей, которую мы добавили в исходные данные.
Связь уравнений Y (X) и X (Y)
В предыдущих разделах мы рассмотрели уравнение линейной регрессии «Y на X». Существует и второй вариант — обратное уравнение. Это регрессия «X на Y» — см. уравнения.
Уравнения регрессии Y (X) и X (Y)
Построим обратное уравнение с помощью надстройки. В качестве «иксов» указываем «игреки» и наоборот.
Чтобы найти коэффициенты уравнения регрессии X (Y), нам понадобится решить систему нормальных уравнений:
Система нормальных уравнений для X (Y)
Получаем следующее уравнение регрессии — см. формулы.
Оценки уравнений регрессии
Сформируем вспомогательную таблицу для построения прямой линии на графике. Выбираем крайние точки по Y: 2000 и 2700. Можно выбрать любые значения, выходящие за границы поля графика. Позже при настройке масштаба по осям на графике останется только видимая часть линий. Главное — занять нашей линией всё поле графика. Вычисляем значения X по уравнению регрессии.
Регрессия Y (X)
Наносим обе линии регрессии на диаграмму разброса.
Настроим тип графика для каждого набора данных. Выбираем в контекстном меню
Change Chart Type
Изменить тип диаграммы.
Устанавливаем комбинированный тип графика:
Combo
Комбинированная.
Выбираем тип графика — диаграмма разброса:
Scatter
Точечная.
Для линий регрессии Y (X) и X (Y) выбираем тип графика — ломаная линия:
Scatter with Straight Lines
Точечная с прямыми отрезками.
Чтобы оси координат были общими для всех графиков, снимаем отметки в колонке
Secondary Axis
Вспомогательная ось.
Выбор типа графиков
Настроим масштаб по осям и цвет линий.
Включаем вывод легенды на графике:
Chart Elements — Legend
Элементы диаграммы — Легенда.
В регрессионном анализе обнаружено одно интересное свойство. Наши прямые линии Y (X) и X (Y) должны пересекаться в точке {Хср, Yср}.
Чтобы продемонстрировать это свойство, возьмём первые уравнения из систем нормальных уравнения для Y (X) и X (Y). Поделим уравнения на n — см. формулы. Если сумму значений поделить на их количество, получится СРЕДНЕЕ ЗНАЧЕНИЕ. В наших формулах среднее обозначено чертой: «икс с чертой» и «игрек с чертой».
Точка пересечения линий
Можно видеть, что точка {Хср, Yср} является общей для обоих уравнений. Другими словами, уравнения линий регрессии выполняются для указанных значений.
Вычисляем средние значения X и Y. Наносим эту точку на график. Настраиваем тип и размер маркера, цвет заливки и границы.
Пересечение линий регрессии
Убеждаемся, что линии регрессии действительно пересекаются в указанной точке.
Второе примечательное свойство линейной регрессии — это взаимосвязь коэффициентов регрессии с коэффициентом линейной корреляции — см. формулы.
Взаимосвязь коэффициентов
Проверяем выполнение указанных соотношений.
Скопируем оба уравнения на отдельный лист и организуем расчёты.
Для извлечения квадратного корня используем функцию
SQRT
КОРЕНЬ.
Сравнение коэффициентов
Находим разность оценок коэффициента корреляции. Можно видеть, что эта разность практически равна нулю.
Анализ реальных данных
Мы познакомились с основными методами изучения взаимосвязи. Это корреляционный и регрессионный анализ. Далее мы применим рассмотренные методы к реальным данным.
Данные для работы будем загружать из глобальной сети интернет, причём это будут открытые и общедоступные данные. Никаких платных сервисов и закрытых подписок. Мы рассматриваем реальные примеры, в которых ЯВНО просматриваются некоторые закономерности.
Конечно, реальные данные отличаются от идеальных, смоделированных. Здесь появляются более сложные закономерности, распределения отличаются от стандартных, а уравнение связи может изменяться со временем.
Тем не менее, работа с реальными данными — это важный шаг в освоении материала. От студента потребуется способность отличать важные свойства от второстепенных подробностей, а также использовать здравый смысл при формулировке выводов.
Интернет-магазин
В соответствии с вариантом задания загрузите реальные данные о компьютерных компонентах с любого сайта компьютерного магазина, например, . Выберите не менее 10 ОДНОТИПНЫХ изделий с РАЗНЫМИ характеристиками. Постройте диаграмму разброса, проведите корреляционный и регрессионный анализ тремя способами. Установите, есть ли какая-то связь и можно ли ее описать уравнением.
Рассмотрим в качестве примера решение нулевого варианта. Будем анализировать зависимость цены от жёстких дисков для серверов от их размеров. В каждом варианте нужно выбрать самые важные параметры устройства, которые тесно связаны между собой.
Первое требование к исходным данным: выбирать ОДНОТИПНЫЕ изделия. Нет смысла сравнивать диски для массового применения и для серверов. Это разные типы изделий, разный уровень качества, надёжности и стоимости.
Второе требование к данным: должно быть РАЗНООБРАЗИЕ параметров в пределах одного типа. Разброс параметра должен быть как можно шире. В нашем случае, это объём диска.
Открываем сайт . Заходим в раздел Комплектующие для компьютеров и выбираем Жёсткие диски — HDD для серверов. HDD означает Hard Disk Drive, или жёсткий диск, или «винчестер».
Диски для серверов
В нашем случае выбор не слишком большой. В остальных вариантах нужно рассматривать массовые популярные комплектующие. Там выбор будет гораздо шире.
Результаты поиска приведены на рисунке. Найдено 8 дисков. Размеры от 600 гигабайт до 8 терабайт. По цифрам просматривается общая тенденция: большие диски стоят дороже. Но есть и отклонения от этой закономерности.
Результаты поиска
Вводим данные в Excel вручную. Пока данных немного, мы можем себе это позволить. Когда информации много, используют другие технологии импорта данных.
Второй вариант ввода данных — выделить текст на странице сайта, скопировать в буфер обмена и вставить на новом листе Excel. Результаты вставки из буфера показаны на рисунке. Здесь есть некоторые проблемы. При копировании страницы сайта через буфер нам достаются не только текстовые и числовые данные, но и элементы оформления и интерфейса. К тому же, некоторые ячейки объединены, что нарушает структуру таблицы.
Вставка из буфера
Для улучшения процесса копирования используем программу Punto Switcher. Она доступна бесплатно по адресу:
/
Punto Switcher
Программа позволяет автоматически переключать раскладку клавиатуры и конвертировать текст. В данной работе нам пригодится ещё одна полезная функция: вставка текста без форматирования.
Вставим данные из буфера в Excel без форматирования. Теперь мы получаем стандартное расположение ячеек электронной таблицы. Стандартный шрифт. И никаких лишних элементов.
Вставка без форматирования
Создадим копию листа и «очистим» данные. Удалим лишние столбцы. Оставим только размер и цену. Данные придётся скопировать в нужные ячейки вручную, потому что они находятся в разных строчках. Можно взять весь диапазон ячеек с ценами, вырезать его в буфер и вставить в нужное место таблицы. Удалим лишние строки. Сравним с исходной страничкой сайта и убедимся, что данные введены правильно. По дороге пропала одна строчка. Вводим данные вручную.
Обратите внимание на выравнивание содержимого ячеек. Первый столбец прижат влево — это текст. Второй столбец прижат вправо — это числа.
Исходные данные
Осталось избавиться от лишних букв. После каждого числа имеется пробел и буквы Тб. В нижней строке указаны гигабайты — нужно удалить буквы Гб и перевести число в терабайты, то есть поделить его на 1000.
Вызываем функцию поиска и замены. Нажимаем комбинацию клавиш [Ctrl + H]. Появляется диалоговое окно
Find and Replace
Найти и заменить.
В строке поиска
Find what
Найти
вводим символ пробела, знак вопроса (искать любой символ) и букву б.
Replace with
Заменить на
Оставляем пустым.
Нажимаем кнопку
Replace All
Заменить все.
В результате в первом столбце остались только числа. Первый столбец прижат вправо — теперь это числа.
Поиск и замена
Осталось вручную заменить 600 на 0.6. Напомним нашу «таблицу умножения»: в одном терабайте примерно 1000 гигабайт. Если быть точным, то вообще-то должно быть 1024. Но многие производители компьютерной техники используют множитель 1000. Ну а сами числа хорошенько округляют.
Теперь поработаем со вторым столбцом. Здесь цены в рублях. И это пятизначные числа. Тысячи и десятки тысяч рублей. Разделим на 1000. Получаем числа попроще.
Данные для анализа
Убираем второй столбец и оставляем только очищенные, предварительно обработанные исходные данные. Добавляем комментарии в духе «Что? Где? Когда?» Вставляем копию страницы сайта, чтобы можно было убедиться в правильности загрузки данных.
Переходим к анализу. Вначале построим диаграмму разброса. Пока всё делаем так же, как и в предыдущих разделах. Рассматриваем график. Разброс по объёму хороший. А вот цены слишком разные. Возможно, здесь собраны диски двух видов. И для каждого вида будет своя зависимость.
Все загруженные данные
Возвращаемся к исходному списку. Выясняем, что большинство дисков имеют следующие параметры:
— интерфейс подключения — SATA 6Гб/сек;
— размер диска — 3.5 дюйма;
— частота вращения 7200 оборотов в минуту.
Обзначение rpm расшифровывается как revolutions per minute, то есть оборотов в минуту.
Несколько дисков выпадают из общей картины. Это другой производитель и другой тип дисков — SAS. На досуге разберитесь, что такое SATA и что такое SAS.
Для обработки оставим только более-менее однотипные изделия одного семейства Ultrastar. Диаграмма разброса стала более привычной. Между делом ознакомьтесь с семействами Ultrastar и Gold. Конечно, для серьёзного анализа нужно взять данных побольше. И из разных источников. И учесть рекомендованные цены производителей.
Однотипные диски
То, что мы оставили для обработки, называется ОДНОРОДНЫЕ данные. Такие данные можно обрабатывать статистическими методами. А если у нас объекты разных типов, разных свойств, то статистика даёт совершенно дикие и никому не нужные результаты. Это всё равно, что взять взрослых людей ростом два метра и детей ростом полметра. Вычисляем средний рост: «метр с кепкой». Привозим в магазин одежду такого размера, а её никто не купит! Просто таких «средних» покупателей нет среди наших клиентов. Но зато можно найти самый ходовой размер для взрослых и для детей ПО ОТДЕЛЬНОСТИ. Вот такую одежду мы сможем продать. В статистике этот показатель называется МОДА. Это значение статистического признака, которое встречается чаще всего.
Итак, у нас осталось четыре диска. Находим коэффициент линейной корреляции. Получаем значение 0,9993. Это практически прямая линия. Почти никакого случайного разброса вокруг прямой.
Находим уравнение регрессии с помощью надстройки:
Y = 4,272 +1,558 X.
Можно записать это уравнение в «экономическом» стиле. То есть русскими словами:
Цена диска т.р. = 4,272 +1,558 • Объём диска Гб.
По уравнению регрессии строим вспомогательную табличку из двух точек.
Попутно найдём ЛИНЕЙНЫЙ ПРОГНОЗ. Это наш прогноз значения Y для выбранного значения X по линейному уравнению регрессии. В исходных данных нет диска на 4 Гб. Судя по нашему уравнению, он должен стоить примерно 10,5 тыс. руб.
Вспомогательная таблица
Наносим линию регрессии на диаграмму разброса. Точки почти лежат на прямой линии.
Линия регрессии
Рассмотрим ещё один популярный момент — «Цена за гигабайт». Во сколько обходится хранение данных на дисках разного размера? Просто поделим рубли на гигабайты. С увеличением объёма диска стоимость хранения данных падает. Так что для большого сервера могут оказаться более экономичными большие диски.
Стоимость хранения данных
Фондовый рынок
В этом разделе мы будем анализировать биржевые данные. Мы посмотрим, как выглядит взаимосвязь между котировками наиболее ликвидных акций и значениями соответствующего отраслевого индекса Московской биржи. Для этого нужно будет скачать два файла — котировки акции и отраслевой индекс (в соответствии с вариантом задания). Затем мы загрузим эти файлы в Excel и проведём корреляционный и регрессионный анализ.
Для начала ознакомимся с заданием. Создадим новый лист в рабочей книге Excel и опишем свой вариант задания.
В интернете есть много ресурсов, где можно бесплатно загрузить биржевые котировки — так называемые ИСТОРИЧЕСКИЕ ДАННЫЕ. Адреса могут со временем изменяться. Работа сайтов может быть нестабильной. Могут появляться новые источники данных.
В качестве примера рассмотрим три источника данных:
MOEX.RU
FINAM.RU
INVESTING.COM
В данной работе нас будет интересовать качество полученных данных и удобство их загрузки в Excel для дальнейшей обработки.
Финам
Откроем сайт компании «Финам» в браузере. Перейдём по ссылке Теханализ.
Сайт «Финам»
На открывшейся странице переходим по ссылке Экспорт котировок.
Ссылка на страницу экспорта
Выбираем Российские индексы в выпадающем списке.
Выбор индексов
В выпадающем списке инструментов выбираем IMOEX.
Выбор инструмента
Установим следующие настройки экспорта данных:
— интервал: диапазон дат 10 лет
— периодичность: 1 день
— разделитель полей: точка с запятой
— разделитель разрядов: нет
— формат записи: TICKER, PER, DATE, TIME, OPEN, HIGH, LOW, CLOSE, VOL
— добавить заголовок файла: да
Настройки экспорта
Нажимаем кнопку Получить файл. Сохраняем файл на диске и обращаем внимание, куда именно его сохранили. Ведь этот файл нам предстоит загружать в Excel.
Для начала ознакомимся с форматом файла. Откроем загруженный файл в текстовом редакторе Notepad (Блокнот). В первой строке находятся заголовки столбцов. Поля разделены точками с запятой. Целая и дробная часть числа разделены точкой. Напомним, что в английской версии Excel в качестве разделителя используется ТОЧКА, в русской версии — ЗАПЯТАЯ. Закрываем окно редактора.
Текстовый файл
Переходим в окно Excel и выбираем в меню
File — Open — Browse — Text Files
Файл — Открыть — Обзор — Текстовые файлы.
Загрузка текстового файла
Выбираем файл и нажимаем кнопку
Open
Открыть.
В окне
Text Import Wizard — Step 1 of 3
Мастер текстов (импорт) — шаг 1 из 3
устанавливаем пункт
My data has headers
Мои данные содержат заголовки.
Убеждаемся, что в разделе
Original data type
Формат исходных данных
указан формат данных
Delimited
(с разделителями).
Нажимаем кнопку
Next
Далее.
Мастер импорта — шаг 1
Результат импорта можно контролировать в нижней части диалогового окна мастера импорта
Preview of file
Предварительный просмотр файла.
На следующих шагах импорта эта часть окна будет называться
Data preview
Образец разбора данных.
По умолчанию в качестве разделителя полей установлен символ табуляции
Delimiters — Tab
Символом-разделителем является — табуляция.
На этом шаге программа не разделяет поля и рассматривает содержимое каждой строки как одну ячейку.
Мастер импорта — шаг 2
Установим точку с запятой в качестве разделителя:
Delimiters — Semicolon
Символом-разделителем является — точка с запятой.
Разделитель — точка с запятой
Убеждаемся, что в разделе предварительного просмотра появились столбцы.
Нажимаем кнопку
Next
Далее.
Выбранный формат данных для каждого столбца выводится в нижней части окна
Text Import Wizard — Step 3 of 3
Мастер импорта — шаг 3
в разделе
Data preview
Образец разбора данных.
По умолчанию для всех столбцов установлен общий формат
Column data format — General
Формат данных столбца — Общий.
Можно видеть, что столбец <DATE> рассматривается как целое число. Мы догадываемся, что в этом столбце записана дата в формате «год-месяц-день». Нужно сообщить об этом мастеру импорта.
Общий формат
Настроим формат даты. Выбираем столбец <DATE> и устанавливаем формат записи даты:
Column data format — Date — YMD
Формат данных столбца — дата — ГМД.
Формат даты
Теперь разберёмся с форматом дробных чисел. Нажимаем кнопку
Advanced
Подробнее.
Убеждаемся, что в качестве разделителя целой и дробной частей
Decimal separator
Разделитель целой и дробной части
установлена точка — как и в формате импортируемого файла.
Нажимаем кнопки ОК и
Finish
Готово.
Разделитель — точка
Файл загружен в Excel. Убеждаемся, что импорт прошёл успешно. Дата распознана как дата — это видно в самих ячейках и в строке формул. Числа с дробной частью распознаны как числа. Напомним, что числа по умолчанию выравниваются по правому краю ячейки, а такст прижимается влево.
Результаты импорта
Копируем страницу значений индекса в отчёт. Для выделения заполненных ячеек используем комбинацию клавиш Ctrl + Shift + Up и Ctrl + Shift + Down. Стрелки вверх и вниз позволяют не только перемещаться на одну строку, но и перейти в начало и конец заполненныго диапазона ячеек. Удаляем неинформативные столбцы — тикер, период, время. Делаем заголовок.
Значения индекса
Настроим формат вывода даты. Выделяем столбец дат. В контекстном меню выбираем
Format Cells — Number — Category — Date — Locale (location) — Russian
Формат ячеек — Число — Числовые форматы — Дата — Язык (местоположение) — русский.
Пример отображения даты в выбранном формате можно сразу же наблюдать в разделе
Sample
Образец.
Формат даты
Теперь даты выглядят более привычно: год-месяц-день. При этом в строке формул дата по-прежнему выводится в американском формате месяц/день/год — в английской версии пакета.
Формат даты
Построим биржевую диаграмму японских свечей. Выделяем столбцы <DATE>, <OPEN>, <HIGH>, <LOW>, <CLOSE>. Для биржевой диаграммы они должны идти именно в таком порядке. Можно также строить график без указания даты. В любом случае, в исходном наборе данных должны присутствовать все четыре цены.
Выбираем в верхнем меню
Insert — Charts — Insert Waterfall, Funnels, Stock, Surface, or Radar Chart — Stock — Open-High-Low-Close
Вставка — Вставить каскадную, воронкообразную, биржевую, поверхностную или лепестковую диаграмму — Биржевая — Биржевая (курс открытия, самый высокий курс, самый низкий курс, курс закрытия).
Построение свечного графика
Отключаем легенду. Вводим заголовок диаграммы.
Свечной график
Можно рассмотреть поведение графика за текущий год. Установим масштаб по горизонтальной и вертикальной осям, как показано на рисунке.
Масштаб
На графике видны регулярные перерывы. Возможная причина — отсутствие торгов по выходным дням. Но этот момент мы разберём чуть позже.
График за 2019 год
Затем получим котировки обыкновенных акций Сбербанка. Выбираем категорию МосБиржа акции или Мосбиржа топ. Затем выбираем инструмент Сбербанк.
Экспорт котировок Сбербанка
Для дальнейшей работы скопируем оба массива данных на новый лист — Индекс Мосбиржи и обыкновенные акции Сбербанка.
Проверим качество данных. Найдём разность соседних дат. Это шаг по времени, который должен быть постоянным. При экспорте биржевых данных мы выбрали дневные данные. Это значит, что шаг равен 1 дню. В случае выходных и праздничных дней шаг может увеличиться.
Создаём новый столбец:
Шаг — число дней между соседними строками.
Шаг по времени
Наши расчёты основаны на том, что Excel хранит дату как ПОРЯДКОВЫЙ НОМЕР ДНЯ, начиная с 1 января 1900 года. При выводе на экран применяется выбранный способ отображения даты, в нашем случае это ГГГГ-ММ-ДД. Мы можем изменить формат вывода, но содержимое ячейки при этом не меняется. Это по-прежнему порядковый номер дня. Когда мы находим разность соседних дат, мы фактически вычитаем одно целое число из другого. Результат — число дней между датами.
Посмотрим на календарь. Вызываем приложение Calendar. Выбираем 2009 год. Видим, что 17 и 18 января 2009 года — это выходные дни. А по выходным на бирже торгов нет. Так что между соседними рабочими днями будет шаг 1 день, а пятницей и понедельником — 3 дня.
Выходные дни
Чтобы увидеть порядковый номер дня, выделим ячейку с датой и выберем в контекстном меню
Format Cells — Number — Category — General
Формат ячеек — Числовые форматы — Число — Общий.
При выборе формата General мы увидим исходное содержимое ячейки. Наше число показано в разделе
Sample
Образец
диалогового окна
Format Cells
Формат ячеек.
Выясняется, что дата 11 января 2009 года на самом деле хранится как число 39824. То есть это 39824-й день от начала отсчёта (1 января 1900 года). При этом в строке формул та же самая дата выводится как 1/11/2009. Это американский формат MM/DD/YYYY. Сначала месяц, потом день и в конце — год.
Порядковый номер дня
Построим диаграмму разброса «Шаг по времени в зависимости от номера записи». Большинство значений равны 1 и 3. Но есть и долгие перерывы.
Шаг по времени
Подводим курсор к самой высокой точке и видим, что это пара чисел (497, 12). На 497 строке нашего массива данных разность дат составила 12 дней. Это новогодние выходные с 31 декабря 2010 года по 10 января 2011 года — см. рисунок.
Новогодние выходные
Сравним данные по индексу и выбранной ценной бумаге. Найдём разность дат наших двух массивов. Построим график разностей. Разность в пять дней обнаруживается в апреле 2016 года. Сравним эти даты.
Расхождение дат
При внимательном рассмотрении таблицы выясняем, что в данных о биржевом индексе есть данные за 23 февраля 2016 года, а в котировках акций Сбербанка эта строка отсутствует. Можно предположить, что в этот праздничный день торгов, скорее всего, не было. Получается, что в наших данных разница на один день. На этот сдвиг наложилась разница соседних дат.
Расхождение дат
Загрузите данные в соответствии со своим вариантом и проведите анализ массива. Какой шаг по времени в каждом массиве по отдельности? Есть ли разница дат в двух массивах? Зафиксируйте выводы на текущей странице отчёта.
Для анализа связи нам нужны пары значений, относящиеся к одним моментам времени. Должна быть синхронность. Качество данных нужно проверять. Как гласит народная мудрость, ДОВЕРЯЙ, НО ПРОВЕРЯЙ.
Проверим другие источники информации.
Московская Биржа
На сайте Московской Биржи есть возможность ознакомиться с историческими данными. Далее можно сравнить информацию биржи с данными из других источников — для контроля качества.
Для просмотра значений индекса Мосбиржи перейдём по ссылкам:
— Котировки — Индексы — MOEX Russia Index — Архив значений.
Выбираем настройки
Архив значений по дням
с 20.02.2016 по 26.02.2016.
Нажимаем кнопку
Показать.
Устанавливаем сортировку даты по возрастанию. Можно видеть, что данные за 23 февраля 2016 года отсутствуют.
Значения индекса
Сравните значения индекса IMOEX за 22 и 24.02.2016 на сайтах Финам и Мосбиржи.
Установите диапазон дат с 01.01.2009 по 31.08.2019.
Нажмите ссылку
Скачать данные в формате — CSV.
Изучите формат полученного файла в программе
Notepad
Блокнот.
Обратите внимание на диапазон дат в файле.
Загрузите данные в Excel.
Для просмотра котировок обыкновенных акций Сбербанка перейдём по ссылкам:
— Котировки — Акции — Сбербанк —Итоги торгов — Инструмент — Сбербанк SBER Сбербанк России ПАО ао.
SBER — кодовое обзначение финансового инструмента;
ПАО — форма организации, сокращение от Публичное акционерное общество;
ао — акции обыкновенные.
Устанавливаем даты:
Начало и Окончание.
Нажимаем кнопку
Обновить.
Проверим данные с 20 по 26 февраля 2016 года. Есть данные за 22 и 24 февраля. Между ними праздничный день 23 февраля.
Курс акций Сбербанка
Сравним данные, полученные на сайте компании «Финам» и на сайте Московской биржи — см. рисунок. Зелёным выделим совпадающие значения индекса, красным — отличающиеся. Появилась лишняя строка за 23 февраля 2016 года, заполненная значением закрытия предыдущего дня. Возможно, на момент эксперимента с экспортом котировок произошёл сбой на сервере. Делаем вывод на будущее: при получении данных из интернет следует контролировать качество и выборочно сверяться с оригиналом, то есть с сайтом Мосбиржи.
Сравнение данных
Ознакомьтесь с вариантами скачивания биржевых данных на сайте Мосбиржи.
Сравните значения котировок из разных источников за любую «сомнительную» дату. Опишите обнаруженные проблемы в отчёте.
Fusion Media
Ещё один источник данных можно найти по адресу:
investing.com.
Почитайте статью о портале investing.com в Википедии. Выясните, что это за компания и какие услуги на этом сайте имеются.
Переходим на указанный сайт и в строке поиска
Search the website
находим
IMOEX
Выбираем раздел
Historical Data
Прошлые данные.
В браузере отображается адрес текущей страницы сайта:
-historical-data
Настраиваем параметры загрузки, как показано на рисунке.
Time Frame — Daily
Дневные.
Начало и конец периода:
Custom dates.
Здесь проще всего вручную напечатать начальную и конечную даты:
Start Date — 01/01/2009
End Date — 08/31/2019
Здесь снова используется американский формат даты: месяц — день — год.
Нажимаем кнопку
Apply.
Проводим сортировку по возрастанию даты:
Date.
Для загрузки данных нажимаем кнопку
Download Data.
Настройки скачивания данных
Для скачивания данных может потребоваться бесплатная регистрация пользователя на сайте. Можно также войти на сайт через социальную сеть Facebook.
Скачивание данных
Загружаем файл и сохраняем его на диске. Не забываем выбрать рабочий каталог для сохранения файла. И запоминаем, куда сохранили файл — нам его ещё загружать предстоит.
Обращаем внимание, что это файл с расширением *.CSV. Это формат Comma Separated Values. Здесь запятые разделяют данные (то есть поля в пределах каждой строки, или записи). Другими словами, запятые указывают на расположение данных по столбцам.
Открываем файл в программе
Notepad
Блокнот.
Рассматриваем содержимое файла
MOEX Russia Historical Data. csv.
Все поля в кавычках. Десятичный разделитель — запятая. Разделитель полей —точка. Закрываем Блокнот.
Формат файла на английском
Двойным щелчком открываем файл в Excel и изучаем результаты. Судя по выравниванию, даты и числа распознаны корректно.
Файл открывается в Excel автоматически, без вызова мастера импортаимпорта. Причина в том, что формат CSV можно открыть в Excel без импорта и преобразований.
Загрузка файла на английском
Экспорт из английской версии сайта и загрузка в английскую версию Excel прошли успешно. Здесь наблюдается хорошая совместимость.
Рассмотрим заголовки столбцов:
Date — Price — Open — High — Low.
Здесь отсутствует цена закрытия Close, зато есть цена под названием Price, то есть Цена. Судя по всему, это и есть цена закрытия. Дело в том, что при анализе котировок самой важной считается именно цена закрытия. В некоторых случаях остальные значения практически игнорируют.
Переименуем заголовок Price и введём информативное название Close. Расставим столбцы в правильном порядке для построения графиков:
Date — Open — High — Low — Close.
Теперь проверим работу русской версии сайта. Для переключения языка щёлкнем по изображению флага в правом верхнем углу страницы. Выбираем в списке языков:
Русский.
Выбор языка
Обращем внимание на адрес страницы в браузере:
-historical-data.
В начале адреса появились буквы RU вместо WWW. В остальном всё без изменений.
Загружаем те же данные. Рассмотрим содержимое файла
Прошлые данные — Индекс МосБиржи. csv.
Все поля в кавычках. Десятичный разделитель — запятая. Разделитель полей — точка. Закрываем Блокнот.
Формат файла на русском
Открываем файл *.CSV в английской версии Excel. Судя по выравниванию содержимого ячеек, данные загружены как текст, а не как даты и числа. Текст выровнен по левой стороне. Даты тоже распознаны как текст.
Загрузка файла на русском
Проверьте, как загружаются в русскую версию Excel файлы, полученные через английскую и русскую версии сайта.
Переключаемся на английский язык и загружаем данные по котировкам акций Сбербанка — код бумаги: SBER. Выбираем тот же диапазон дат.
Проведём анализ шага по времени, как в предыдущих примерах.
Шаг по времени
Здесь тоже можно обнаружить расхождения по датам. Для анализа связи придётся пожертвовать частью данных. Удаляем строки, которые выпадают из общей картины.
Добиваемся нулевого расхождения по датам в обоих наборах данных — см. рисунок.
Нулевое расхождение дат
Данные «очищены», то есть приведены в некоторый порядок. Переходим к анализу связи между курсом акций и значениями индекса.
Копируем лист с биржевыми данными в отчёт. Для этого щёлкаем правой кнопкой мыши по вкладке листа и выбираем в контекстном меню Move or Copy.
Копирование листа
Вставим лист из текущей рабочей книги в другую книгу — а наш отчёт, последним листом. Переименуем лист для единообразия.
Копирование листа в другую книгу
Копируем даты и цену закрытия для обоих инструментов на новый лист.
Построим совмещённый график изменения во времени.
Совмещённый график
Настроим раздельный масштаб, чтобы лучше рассмотреть оба графика.
Изменение типа графика
Открывается диалоговое окно
Change Chart Type
Изменить тип диаграммы.
Выбираем комбинированный тип графика:
Combo
Комбинированная.
Устанавливаем для обоих графиков
Scatter with Straight Lines
Точечная с прямыми отрезками.
Включаем вторую вертикальную ось:
Secondary Axis
Вспомогательная ось.
Комбинированный график
Настраиваем диапазон значений по каждой оси. Устанавливаем заголовки по осям. Получаем более-менее информативную диаграмму — см. рисунок.
Комбинированная диаграмма
Можно видеть, что в целом направление изменения совпадает, хотя иногда котировки акций отклоняются от движения индекса.
Построим диаграмму разброса. Настраиваем заголовки, маркер, линию. Включаем построение линейной регрессии и вывод уравнения на экран.
Диаграмма разброса
Подобный анализ проводится при построении инвестиционного портфеля. Прочитайте статью Бета-коэффициент в Википедии.
Вызываем функцию CORREL и находим значение коэффициента линейной корреляции: r = 0.924. Это значение говорит о тесной положительной линейной связи между котировками акций и значением индекса.
Благодарности
Автор выражает глубокую признательность студентам, участвовавшим в подготовке данных методических указаний. Следующие студенты активно помогали в постановке лабораторных работ и составлении чернового варианта методических указаний:
— Корнеева Мария
— Кострюкова Анна
— Токарева Татьяна
— Муслимов Роберт
В тестировании учебных материалов, выявлении упущенных моментов и оценке трудоёмкости работ участвовали следующие студенты:
— Яковлева Виктория
— Исхаков Радмир
— Халиков Ильшат
— Мурадян Гарик
— Мухаметьянова Ольга
— Хайретдинова Ирина
— Макаров Владислав
— Макрушин Константин
— Портнов Владислав
В рамках проекта тестировщики общались с составителями, и после каждого очередного исправления текст становился всё более понятным.
Такое разделение труда позволило автору сосредоточиться на творческой части работы и увидеть картину в целом, не отвлекаясь на текущие вопросы.
Кстати, в процессе работы попутно выяснилось, насколько большой поток информации требуется обрабатывать для текущей координации проекта. Так что в следующий раз нам дополнительно потребуется куратор, который освоит управление проектом.
Послесловие
В данном выпуске мы познакомились с анализов взаимосвязи методами корреляционного и регрессионного анализа. Это второй выпуск в серии «Бизнес-аналитика и статистика в Excel». В нашей серии учебных пособий имеются следующие выпуски:
1. Анализ распределения. Сводка и группировка данных. Оценка формы распределения. Вычисление статистических показателей. Соответствующие разделы предмета: «Введение», «Распределение», «Статистические показатели», «Сводка и группировка», «Статистические графики». В конечном счёте мы построим графики (гистограмму и кумуляту), а также оценим значения показателей — таких как «сигма».
2. Корреляционный и регрессионный анализ. Статистическое изучение взаимосвязи. Соответствующий раздел предмета: «Взаимосвязь явлений», «Фондовые индексы». Мы узнаем, что прямую линию можно провести через любое количество точек, если делать это «в среднем». А ещё нам предстоит выяснить, как связаны между собой различные отрасли экономики — если посмотреть на них глазами Московской биржи.
3. Анализ динамики. Компоненты рядов динамики. Скользящие средние. Уравнение и линия тренда. Соответствующий раздел предмета: «Динамика». Здесь мы рассмотрим составные части динамики (изменения во времени) и биржевые графики, на которых наносят общую тенденцию (тренд).
4. Бизнес-аналитика на основе сводных таблиц. Соответствующий раздел предмета: «Бизнес-аналитика». Это одновременно и самый простой, и самый сложный раздел, потому что настройка таблиц делается визуально, через меню, а внутри спрятаны уже изученные статистические методы: сводка и группировка, показатели, взаимосвязь, динамика и т. д. Снаружи мы в конечном счёте увидим «приборную панель» руководителя предприятия — такую же, как приборная панель автомобиля.
Каждый метод анализа данных вначале рассматривается на примере смоделированных данных, а затем с использованием реальных данных из интернет.
Список литературы
1. Статистика: Учебник для вузов / Под ред. И.И.Елисеевой. — СПб.: Питер, 2010. — 368 с.
2. Теория статистики: Учебник / Р.А.Шмойлова, В.Г.Минашкин, Н.А.Садовникова, Е.Б.Шувалова; под ред. Р.А.Шмойловой. — М.: Финансы и статистика, 2014. — 656 с.
3. Практикум по теории статистики / Р.А.Шмойлова, В.Г.Минашкин, Н.А.Садовникова; под ред. Р.А.Шмойловой. — М.: Финансы и статистика, 2014. — 416 с.
4. Вадзинский Р. Н. Статистические вычисления в среде Excel. Библиотека пользователя. — СПб.: Питер, 2008. — 608 с.
5. Пустыльник Е. И. Статистические методы анализа и обработки наблюдений. — М.: Наука, 1968. — 288 с.
6. ГОСТ 2.303—68 ЕСКД. Линии.
С текстом стандарта можно ознакомиться в интеренете, например, по адресу:
-2-303-68-eskd
7. Арьков В. Ю. Анализ распределения в Excel: Учебное пособие.— [б.м.]: Издательские решения, 2019.— 158 с.
Первый выпуск серии.
Бесплатный доступ к электронной версии:
/

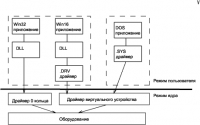




Комментарии к книге «Статистический анализ взаимосвязи в Excel», Валентин Юльевич Арьков
Всего 0 комментариев